水泥回轉窯故障診斷方法研究
2020-08-03 02:56:30谷雨,艾紅
自動化儀表 2020年7期
谷 雨,艾 紅
(北京信息科技大學自動化學院,北京 100192)
0 引言
水泥回轉窯是熟料煅燒系統中的主要設備[1],其工作環境惡劣、熱工參數眾多,故障頻發。及時、準確地診斷回轉窯故障,對保護人員和設備安全、提高生產效率具有重要意義。20世紀90年代,回轉窯故障診斷方法多依賴測試分析儀器[2]。這些方法對儀器的性能要求高、需求量大、成本較高。隨著大數據時代的到來,基于智能算法的大數據分析開始應用于回轉窯的故障診斷中[3-10]。
回轉窯具有多變量、非線性、難建模的特點。神經網絡能夠表達工程中一些難以用數學方法準確建模的復雜非線性系統,免疫進化網絡理論分類器(immune evolutionary network classifier,IENC)算法則可以較好地明確分類邊界,提高分類精度。采用D-S證據理論進行決策融合,能夠充分結合二者優點,有效避免單一算法在故障診斷中的“一票否決制”,得到更精確的診斷結果。
1 水泥生產工藝及常見故障
水泥生產工藝分為干法工藝和濕法工藝兩種。濕法工藝因能耗高被逐步淘汰。目前,水泥生產多以干法工藝為主。新型干法水泥生產工藝主要包含三個部分:生料制備、熟料煅燒及水泥制成。其工藝流程如圖1所示。

圖1 新型干法水泥生產工藝流程圖
回轉窯故障類型及原因如表1所示。

表1 回轉窯故障類型及原因
2 相關理論介紹
2.1 免疫進化網絡理論分類器
免疫系統是人體重要的防衛網絡,可以識別和清除外來入侵的抗原,維持機體的穩定與平衡。人工免疫系統是一種計算或信息系統,通過模仿生物免疫系統的原理和機制,解決一些工程問題。它具有強大的學習和記憶能力、模式識別能力以及良好的魯棒性,能夠通過細胞間的相互抑制和激勵維持動態平衡[11]。
IENC流程如圖2所示。

圖2 IENC流程圖
IENC的工作原理主要包含以下幾個步驟:生成種群、親和度計算、克隆及變異、形成各類細胞池、細胞池內網絡抑制和細胞池間網絡抑制。最終通過將測試樣本與各類細胞池中的抗體進行親和度比較,確定抗原類別。
2.2 D-S證據理論
A.P.Dempster于1967年提出利用上、下限概率解決多值映射問題的基本構架,后經Shafer進一步完善,形成了D-S證據理論,可解決不確定性問題。
故障診斷中的各種故障模式ω1,ω2,…,ωn構成一個并集Ω={ω1,ω2,…,ωn},稱為辨識框架。其元素具有互斥且窮舉的特征。
定義1 設Ω為辨識框架,若集函數m,2Ω→[0,1](2Ω為Ω的冪集)滿足[12]:
m(φ)=0
(1)

(2)
則稱m為框架Ω上的基本信任分配(basic probability assignment,BPA)。
定義2 如果m1分別是兩個定義在m2上的BPA函數,則定義m=m1?m2為組合后的BPA函數[13]:
(3)
(4)
式中:k為規范化因子,反映了證據間的沖突程度大小。k=1時,證據間的沖突最大。此時,式(3)的分母為0,Dempster規則失效。
3 算法實現
故障診斷流程如圖3所示。
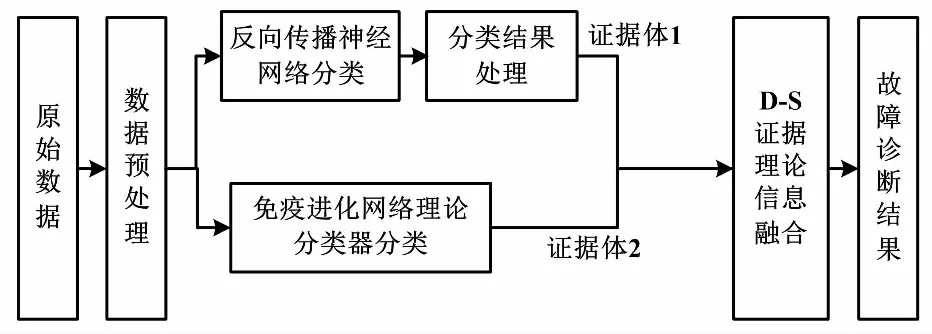
圖3 故障診斷流程圖
算法具體流程如下。
Step 1:構建反向傳播(back propagation,BP)神經網絡模型,設置輸入層、隱含層和輸出層的節點個數,初始化權值閾值。
Step 2:將訓練樣本數據進行歸一化處理并輸入BP神經網絡進行訓練,將歸一化后的測試數據輸入訓練好的網絡得到診斷結果。
Step 3:將訓練樣本數據做歸一化處理。
Step 4:設定每類的抗體種群規模N及迭代次數P,產生(0,1)間的隨機數,構成初始抗體群A。
Step 5:將訓練樣本數據作為抗原,依次提呈并進行免疫學習。
Step 6:計算初始抗體群中所有抗體與當前提呈的抗原間的親和度。親和度計算方法如式(5)所示。
(5)
式中:fij為提呈第i個抗原進行免疫學習時,初始抗體群中的第j個抗體與該抗原的親和度;n為特征參數的數目,即抗體的長度。
Step 7:按照親和度從大到小排序,選親和度最高的m個抗體克隆。設置最高克隆數目NC,每個抗體的克隆數目按照親和度由高到低、克隆數目由NC依次衰減50%得到。親和度越大的抗體克隆數目越多,可得到克隆之后的抗體細胞群C。
Step 8:設置變異率矩陣α,使抗體向識別抗原的方向進化。親和度大的抗體變異率小,按照式(6)對抗體細胞群C進行變異。
C*=C-α×(C-Ctraini)
(6)
式中:C*為變異后的抗體細胞群;Ctraini為第i個抗原traini擴增后的矩陣,其擴增后與α和C具有相同的維度。
Step 9:計算抗體細胞群C*中的所有抗體與當前抗原的親和度,從大到小排序,優選一定百分比的抗體作為記憶細胞,放入當前抗體所屬類別的記憶細胞池Mt中。其中t=1,2,…,T,T為待分類的類別數,判斷樣本學習是否結束。若沒有結束,則返回Step 5。
Step 10:在T個記憶細胞池Mt中單獨進行網絡抑制,設定記憶細胞池內網絡抑制的閾值σ1,按照式(7)進行記憶細胞池內的網絡抑制。
(7)

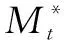
Step 12:提呈測試集,計算測試集中每一個抗原與T個記憶細胞池中的所有記憶細胞間的親和度,取出親和度最高的前K個抗體,計算各類別的占比,得到證據體2。
Step 13:將BP神經網絡模型的診斷結果作相應處理,使之滿足式(1)、式(2)所述的D-S證據理論應用的基本條件,得到證據體1。
Step 14:采用Dempster合成法則,依據式(3)、式(4)合成證據體1和證據體2,得到新的基本信任分配,并據此得到最終診斷結果。
4 實例分析
4.1 故障類型及數據
研究數據來源于某水泥廠中控室的SQL數據庫,數據為不同時段水泥生產現場傳感器實時采集的部分正常數據及故障數據,包含10個特征參數,涉及窯前結圈、窯后結圈、窯內結球、跑生料和預熱器塌料5種故障類型,相應的回轉窯產能為3 500 t·d-1。研究選擇的故障均為從數據變化上能夠區分類別的故障。而回轉窯運行時發生的其他類型的故障如紅窯等,還需要結合筒體掃描儀觀測的圖像來判斷。
部分特征參數的正常范圍及故障時的變化如表2所示。

表2 部分特征參數的正常范圍及故障時的變化
表2中:預熱器塌料故障時,會出現窯主電機電流瞬時增大、窯尾負壓瞬時減小的情況,但數值變化的總體趨勢不變。
每類故障數據包含故障初始時的監測數據和嚴重故障時的監測數據。故障初始時,某些特征參數的數值會出現波動異常或趨勢異常的情況。但由于故障不嚴重,數值還處于正常范圍中,與故障發生前正常運行時的數據相比偏大或者偏小。而故障情況加劇后,某些參數的數值會偏離或嚴重偏離正常范圍。
由于不同特征參數數值間存在較大差異,因而需要對數據進行歸一化處理,縮小樣本數據范圍。歸一化公式為:
(8)
式中:min(Xj)和max(Xj)分別為所有正常數據樣本中各特征參數的最小值和最大值。
部分歸一化后的樣本數據如表3所示。5種故障樣本的歸一化均以正常樣本中各特征參數的最值為標準。當某特征參數異常變化且偏離正常范圍時,歸一化結果就會超出[0,1]區間范圍。

表3 部分歸一化后的樣本數據
4.2 水泥回轉窯故障診斷
對原始數據作歸一化處理,縮小數據范圍。將歸一化之后的數據分為訓練數據和測試數據兩部分,其中訓練數據630組、測試數據270組。
4.2.1 BP神經網絡故障診斷
用MATLAB進行仿真,構建BP神經網絡模型,相關參數設置為:學習率0.09,迭代次數5 000,精度0.05,輸入層、隱含層、輸出層神經元個數分別為10、40、6,輸出結果采用“n中取1”的編碼方式。“100000”為正常,“010000”為窯后結圈,“001000”為窯前結圈,“000100”為窯內結球,“000010”為跑生料,“000001”為預熱器塌料。
BP神經網絡的部分仿真結果如表4所示。
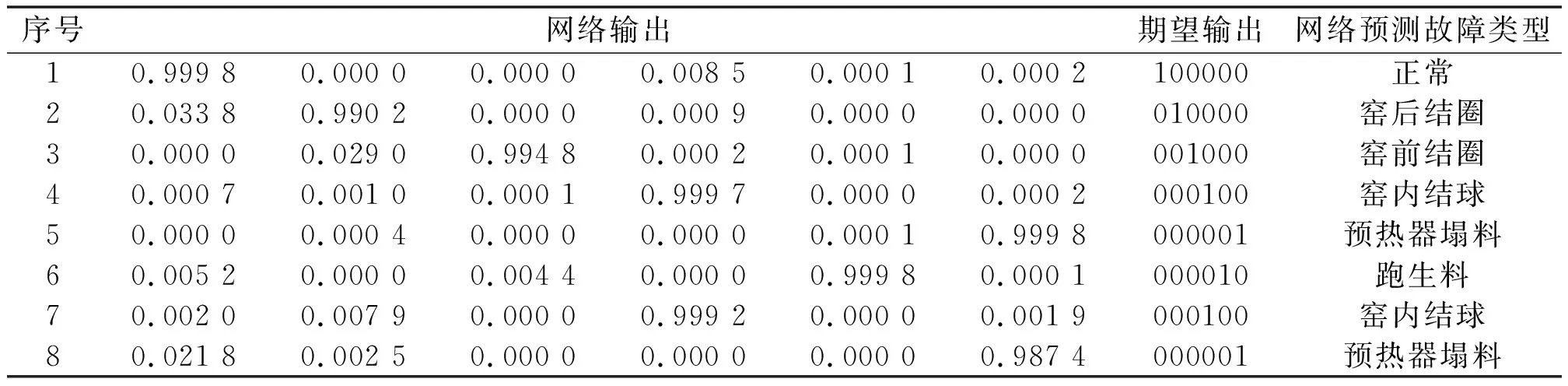
表4 BP神經網絡的部分仿真結果
4.2.2 基于免疫進化網絡理論的分類器故障診斷
用MATLAB進行仿真,構建IENC模型,提呈訓練樣本進行免疫學習。參數設置為:每類初始抗體數目為30,抗體長度為10,訓練代數為10,最大克隆數目為32,克隆選擇百分比為25%,記憶細胞池內網絡抑制閾值為0.1,記憶細胞池間網絡抑制閾值為0.25,最近鄰法則中K=13。迭代完成后得到6個記憶細胞池,分別對應于正常和5種故障類型。輸入測試數據,按照式(5)計算每組測試樣本與所有記憶細胞池中抗體間的適應度值,并由大到小排序。記錄適應度最大的前K個抗體所屬的記憶細胞池類別,并統計每類的占比情況。若某類型的占比高于84%,則判定當前測試樣本為該類型故障。IENC算法的部分仿真結果如表5所示。

表5 IENC算法的部分仿真結果
4.2.3 D-S證據理論信息融合及結果分析
采用D-S證據理論融合兩種算法的診斷結果。D-S證據理論使用時應滿足式(1)、式(2)的條件。因此,在信息融合前需要將BP神經網絡的診斷結果表達為正常和5種故障類型的基本概率分配形式,且滿足所有故障類型的概率之和為1、空集的概率為0的條件。BP神經網絡的輸出結果按照式(9)進行處理:
(9)
BP神經網絡、IENC及信息融合方法得到的各類故障的診斷效果對比如圖4所示。
測試樣本中:標號為0~45的樣本屬于正常工況,標號為46~90的樣本為窯后結圈故障,標號為91~135的樣本為窯前結圈故障,標號為136~180的樣本為窯內結球故障,標號為181~225的樣本為跑生料故障,標號為226~270的樣本為預熱器塌料故障。
由圖4可知,BP神經網絡對于正常工況、窯后結圈和預熱器塌料故障的診斷效果較差,無法對某些樣本作出正確的診斷,相應類別的故障發生概率偏低。

圖4 各類故障的診斷效果對比圖
對于部分能夠判斷故障類別的樣本,其診斷精度還達不到要求,概率低于84%。IENC算法無法較好地診斷正常工況、窯后結圈和窯前結圈故障,存在較多的誤判現象。診斷得到的部分樣本所屬故障的發生概率低于50%。針對上述問題,采用D-S證據理論對兩種算法的診斷結果進行信息融合,較好地彌補了兩種算法存在的不足。
算法準確率對比如圖5所示。
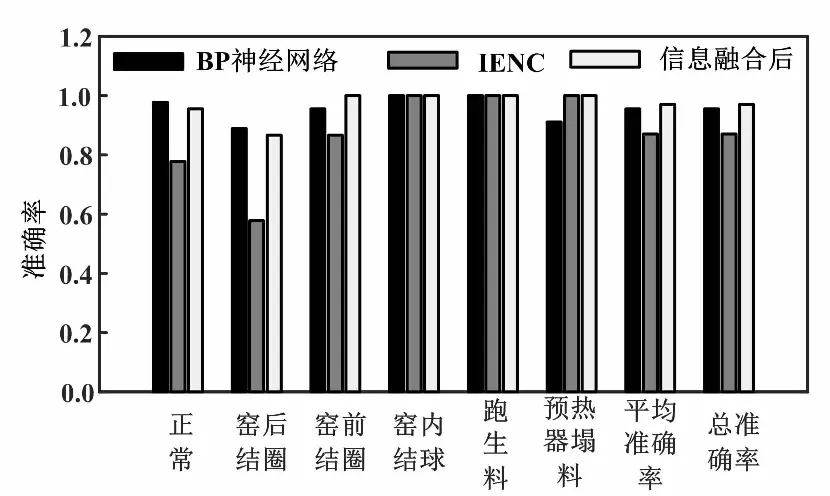
圖5 算法準確率對比圖
由圖5可知,對于正常工況和窯后結圈故障,信息融合后的正確率略低于BP神經網絡,但遠高于IENC的正確率。對于窯前結圈故障,信息融合后的正確率高于其他兩種方法。對于窯內結球和跑生料故障,三種方法正確率相同。對于預熱器塌料故障,信息融合后的正確率與IENC相同,且遠高于BP神經網絡的正確率。綜合各類故障的診斷效果,得到三種方法故障診斷的平均準確率。對比結果表明,經過D-S證據理論進行信息融合后的平均準確率要高于BP神經網絡和IENC兩種算法的平均準確率,信息融合后每種故障類型的診斷正確率也接近甚至高于兩種算法診斷正確率的較高值。
5 結論
本文針對水泥回轉窯故障診斷中存在故障信息獲取不全、不同時刻故障表征存在差異的問題,以及單一算法診斷能力有限的問題,提出了一種基于決策融
合的故障診斷方法。通過采用D-S證據理論融合BP神經網絡和IENC兩種模型的診斷結果,實現更加精確的故障診斷。與傳統方法相比,該方法充分利用了IENC算法在分類上的優勢,采取細胞抑制策略劃分不同故障類別的邊界,提高分類的準確率;采用決策融合的方法,使結果更加可靠。仿真試驗表明,采用該方法后的分類正確率顯著提升。
猜你喜歡
裝備制造技術(2020年3期)2020-12-25 05:22:30
汽車維修與保養(2019年7期)2020-01-06 03:30:42
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
