基于錨節點可靠路由的IMS電話呼叫分揀方法①
2020-07-25 01:46:48趙金城
計算機系統應用 2020年7期
羅 威,趙金城,宋 江,江 凇,丁 儀,劉 銳
1(南京南瑞信息通信科技有限公司,南京 210003)
2(國網江蘇省電力有限公司 信息通信分公司,南京 210024)
3(南京郵電大學 通信與信息工程學院,南京 210003)
1 引言
過去電力系統的行政交換網以電路交換為主,為日常行政辦公提供優質的語音,傳輸等通信業務.隨著業務的不斷增加,現有的程控設備已不能滿足發展的需求,國網公司近年來逐步在全國推廣IMS技術[1].
電力公司現有的IMS系統基本可以滿足企業員工的正常通話的需求,但是公司不能獲取終端的詳細通話記錄和將通話記錄保存到公司的后臺數據庫中,無法提供給員工們查詢來電信息[2].對于傳統的路由協議仍存在的傳輸時延長、路由發送成功率低、鏈路斷裂頻繁等問題,Sukdea Yu 等[3]提出了一種貪婪邊界優勢路由(GBSR).當節點面向局部最大值時,節點生成邊界優越圖而不是生成平面圖,恢復模式中的數據包可以使用圖形盡可能快地從恢復模式中退出.但其是在鏈路路由斷裂的條件下,再進行路由的恢復,這樣的恢復具有很大的時延性.Bilal 等[4]提出了FMHR算法,該算法在基于貪婪算法選擇最遠的下一跳同時,還考慮到下一跳節點的速度和方向,增加了鏈路的相對穩定性.但方向很難精確確定,這也將大大增加計算負載和額外開銷.
通過查閱相關資料,能夠完全適配于IMS體統的路由協議很少,根據現有路由協議的缺點,提出一種一種基于錨節點可靠路由協議(RRCP),可以降低路由故障和數據丟失的頻率,同時保持較低的路由開銷,在源節點和目的節點之間建立更穩固的路由.
2 基于IMS的監控系統
如圖1,該系統首先將域外和域內的通話流量鏡像到一個端口,存儲到流量捕獲模塊中;然后把捕獲的流量利用SIP協議進行解析處理,獲得一些必要的報文參數[5];接著分析和處理呼叫數據記錄,生成通話記錄;最終可以將用戶的通話記錄保存到公司的后臺數據庫中,便于提供給終端系統查詢.IMS的監控系統架構如圖2.
方法流程為:
S1:將P-CSCF端口及AGCF端口的流量通過端口鏡像技術保存到一個端口上.域內的用戶通過交換機連接到P-CSCF端口,域外的用戶通過交換機連接AGCF端口,用戶的通話流量存在各自對應的端口中,流量不能同時保存到一個端口,這樣就不能很好地處理端口的流量.所以將P-CSCF和AGCF端口通過交換機連接到鏡像端口,然后利用端口鏡像技術監聽流量的數據包,并將網絡數據流傳遞給流量捕獲模塊,這時所需要處理流量可以同時保存到一個鏡像端口中,然后將其映射到IMS外的通話記錄分揀服務其中,可以方便地進一步處理數據.
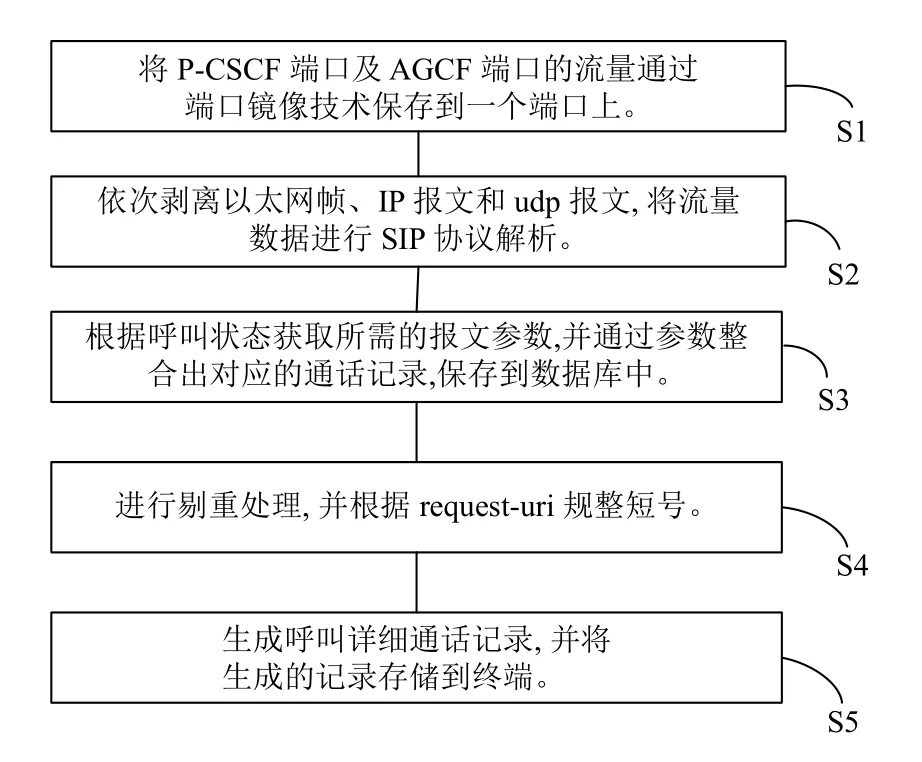
圖1 IMS的監控系統流程示意圖
S2:依次剝離以太網幀、IP報文和udp報文,將流量數據進行SIP協議解析.
S3:根據呼叫狀態獲取所需的報文參數,并通過參數整合出對應的通話記錄,保存到數據庫中.要想生成完整的呼叫通話記錄(CDR),使用SIP協議解析的字段信息較多,并且呼叫狀態的不同所需解析的報文字段也不一樣.
當接收到Invite 請求時,并且有ACK進行響應請求,表明該呼叫正常接通,此時SIP協議會解析From字段的標簽參數和To字段的標簽參數,From和To標簽參數是最小32位寬的真正隨機數,可以識別主叫方和被叫方,然后通過獲取calling Number和called Number提取到通話的主叫號碼和被叫號碼.在這次呼叫應答過程中,解析獲取Call ID字段的值,Call ID是給定時間內IMS 域內的唯一ID,可以識別出此次會話的唯一連接.當在這次Invite 請求響應結束接收到Bye 消息時,表明這個會話正常結束,利用SIP協議解析報文獲得request Time、start Time和end Time等標簽.其中,request Time、start Time和end Time分別記錄通話的請求、開始和結束時間,start Time 僅在通話正常接通的情況下記錄.這時就會生成一條臨時的通話記錄存儲到數據庫中.
當接收到Invite 請求時,若沒有ACK 響應請求,會通過SIP解析出響應消息狀態碼,若是480、486、487,則表示對方沒有接聽電話.此時解析出From字段的標簽參數和To字段的標簽參數,依然可以判斷出主叫方和被叫方,然后通過獲取的calling Number和called Number提取到發起會話的主叫號碼和被叫號碼,最后利用SIP協議解析報文獲得request Time標簽,可以獲知主叫方發起會話請求的時間.此時也會生成一條臨時的通話記錄保存到數據庫中.
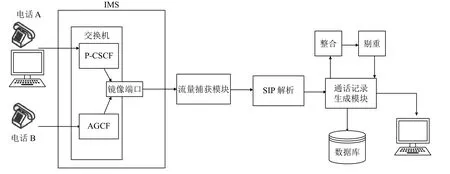
圖2 IMS的監控系統架構圖
S4:通過在IMS 核心網集中分揀一個用戶下的所有終端電話呼叫SIP 信令,合并同一身份對應的多終端來電信息后生成的呼叫數據記錄.進行剔重處理,并根據request-uri 規整短號.上一步中生成的通話記錄臨時保存到數據庫中,當同一個用戶再次向一個用戶發起同樣的請求時,首先通過From和To標簽判斷主被叫,然后利用Call ID進行強識別,若Call ID 相等的話,則該條通話記錄不會被保存到數據庫中,以達到剔重的效果.如果sip header 中的From標簽和To標簽中都是短號的話,則會從request-uri 頭域取長號前綴,來補齊短信.
S5:合并同一身份對應的多終端來電信息后生成的呼叫數據記錄,生成呼叫詳細通話記錄,并將生成的記錄存儲到終端.經過上述步驟,本系統利用表格將生成的呼叫詳細通話記錄存儲到終端,以方便用戶可以查詢通話記錄.
3 基于錨節點的可靠路由優化算法
在上一節基于IMS的監控系統S3 流量捕捉模塊中,流量當前IP報文通過預測鏈路生命期之后的候選中繼節點的存在來識別更可靠的鏈路進行轉發.
因此本章提出路由優化的協議(RRCP)主要包括3個方面:路徑選擇、下一跳轉發機制和預測中繼節點的優化.首先是路徑選擇方面,在實際數據轉發之前增加一個選擇路徑的過程,將端到端的連通概率作為轉發路徑的依據.其次是下一跳轉發機制的優化,不采用基于貪婪算法選擇最遠下一跳,而是選擇最靠近下一個錨點的鄰居節點作為下一跳節點.最后是預測中繼節點方面,先確定下一個中繼節點并計算出鏈路生命期.再對當前中繼節點的鄰居節點進行位置預測,隨后判斷鄰居節點在鏈路生命期內是否離開了當前中繼節點的通信范圍,若離開了當前中繼節點的通信范圍,則當前中繼節點發送阻塞的消息給起始錨節點,錨節點立刻選擇另一條最短路徑.
3.1 路徑選擇機制
當源節點S 開始發送數據分組之前,首先要進行轉發路徑的選擇,即構建通往目的地節點D的路由路徑.因此源節點S 首先發送路徑發現請求的報文信息,源節點的速度向量以及目的節點的位置等均被記錄到廣播報文的報頭中[6].接收到廣播報文的鄰居節點,計算離上一跳節點的連接概率.
假設n條路徑中的某一條路徑Path(i)由k條鏈路構成,每條鏈路的協助連通概率為Pl,其中l=1,2,3,···,k,則該Path(i)的連通概率為:
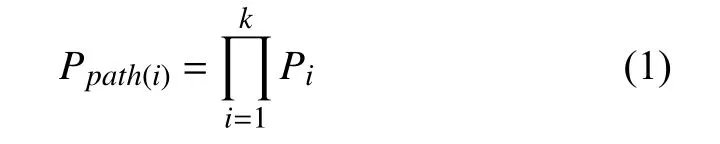
轉發路徑發現請求的每個節點通過其自己的數據重寫報文分組中的“前節點的速度向量”字段.如果節點的速度向量的方向與“前節點的速度向量”字段不同(即非平行),則節點將錨點添加到廣播包,錨節點包含當前節點的坐標和先前節點的坐標以及它們各自的速度矢量[7].當廣播路徑通過新的交叉時,則將另一個錨節點添加到分組[8].最后,當廣播到達目的地時,目的地節點到源節點的整個路徑被記錄為一組中間錨節點.
目的節點D在接收到多條路徑的信息后,目的地節點D 選擇一條協助連通概率最高的路徑作為最優路徑[9].隨后路由答復從目的地節點D發送回源節點S.路由答復是單播分組,其包含目的地的坐標和速度向量、一組錨節點信息以及其他一些到達目的地的路上路由請求收集到的信息.當源節點S 接收到路由答復后,記錄下路徑信息并可以開始發送數據分組.
3.2 下一跳轉發機制
該路由方案采用了錨節點,源節點接收到目的地節點關于這組錨節點的速度矢量、位置等信息.當前中繼節點在選擇下一跳的時候,并不采用傳統的貪婪算法將數據分組轉發到地理上更接近目的地的鄰居節點,而是選擇最靠近下一個錨點的鄰居節點.
為了避免多次嘗試逐漸接近下一個錨節點,每次轉發的節點檢查其位置和下一個錨點的位置是否分開小于節點覆蓋范圍的一半.如果是,則標記該錨點,并且選擇下一個錨節點作為下一個轉發節點;如果不是,則繼續該過程,尋找下一個鄰居節點直到分組到達其目的地節點[10].
3.3 預測候選中繼節點方法
假設錨節點為在報文傳輸途中路徑的交點處,定義兩個錨節點之間的路段為鏈路[11];在傳輸過程中,錨節點接收到數據分組,選擇最靠近的鏈路,將分組轉發給此鏈路;如果錨節點發現所選擇的鏈路阻塞,則選擇最接近下一個錨點的鏈路[12,13].如圖3所示,在最接近下一個錨節點的鏈路(即鏈路1)上出現阻塞的示例場景.在這種情況下,錨點節點A在從中繼節點接收阻塞消息之后,將重新規劃路由到的下一個最接近下一個錨節點的鏈路2.
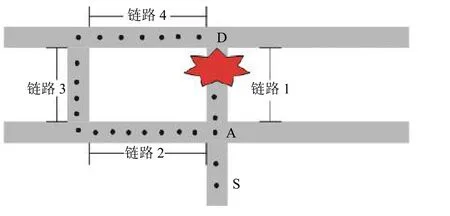
圖3 阻塞發生情況模型圖
具體算法的實施方法流程可以分為以下4個步驟:
步驟1.當前中繼節點將最接近下一個錨節點的目的地確定為下一個中繼節點,并計算出此鏈路的生命期.Pn和Pc分別表示新選擇的中繼節點和當前中繼節點.使用鄰居表中的信息,Pc將最接近下一個錨節點的節點確定為下一個中繼節點Pn,根據Pc和Pn的位置及速度信息可以估計出此鏈√路的生命期it_expire.
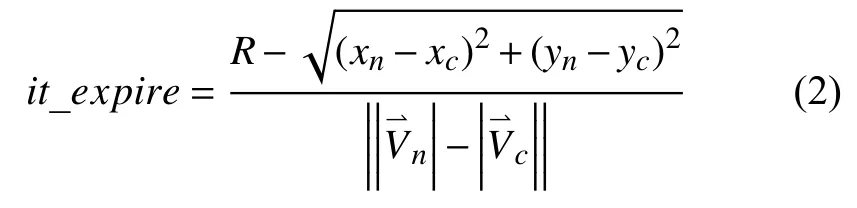
步驟2.對當前中繼節點的鄰居節點進行位置預測.
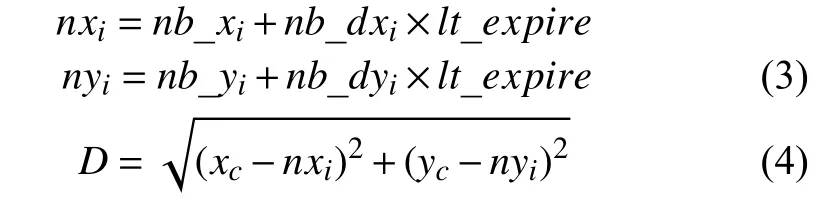
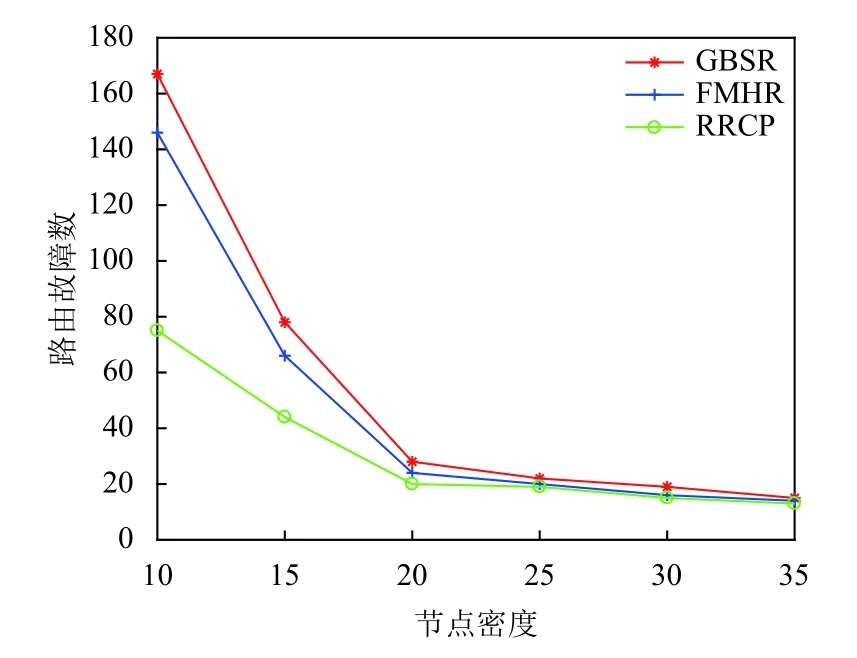
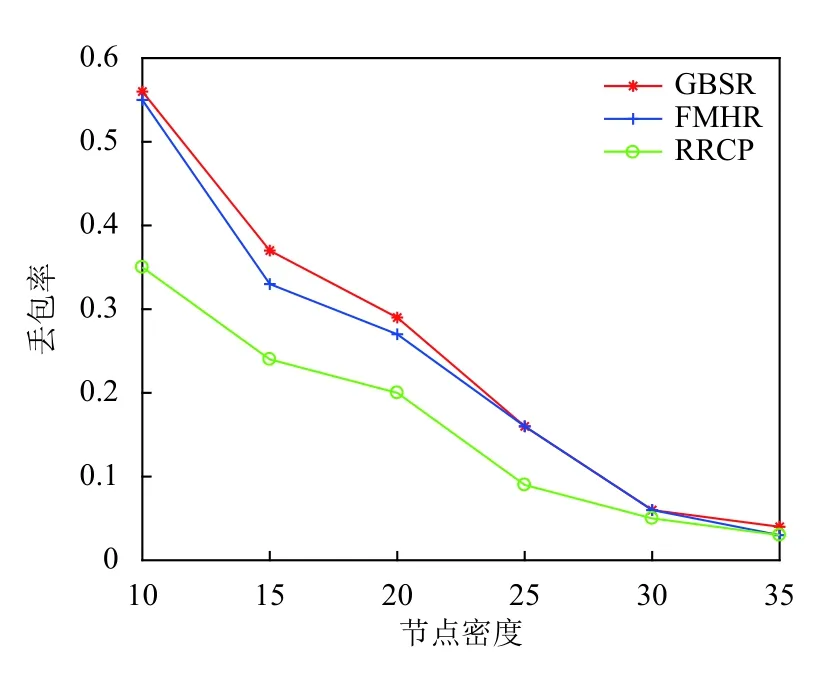
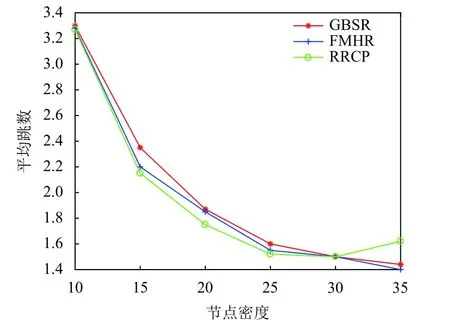
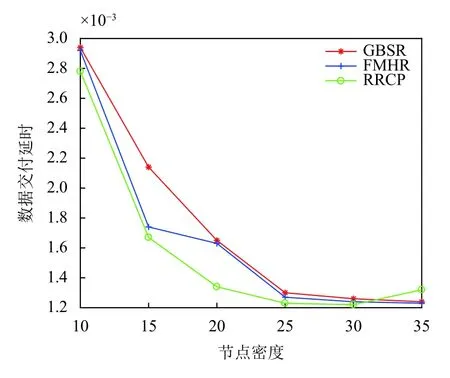
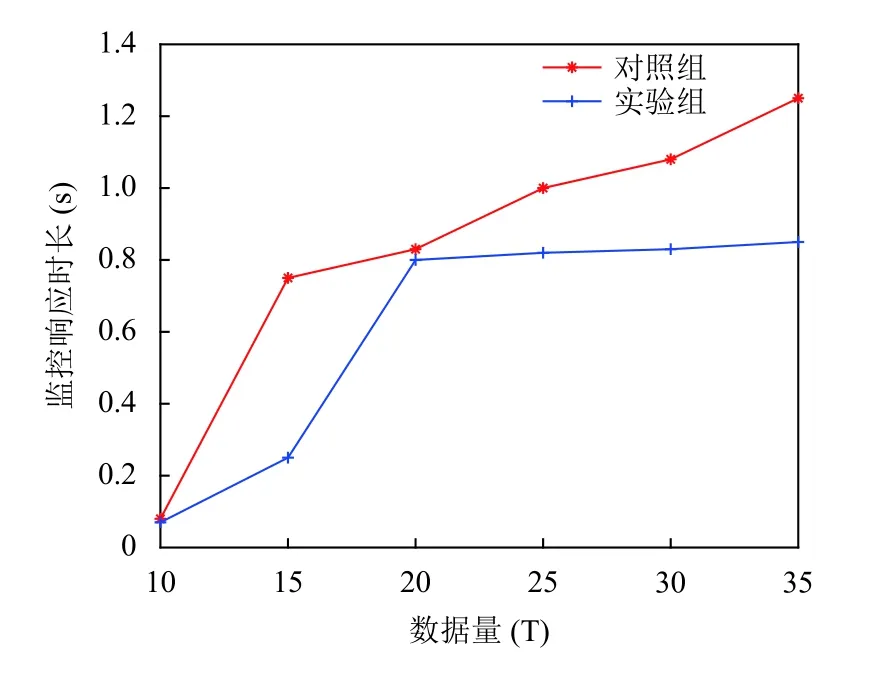
步驟3.通過式(3)對Pc的鄰居節點i的位置進行預測:通過式(4)計算此時鄰居節點i與Pc的位置之間的距離.若D 步驟4.在it_expire到期前,定義一個預定間隔,每過一次預定間隔,Pc便重新檢測阻塞的鏈路上是否依舊是D≥R,若發現D 本文利用的網絡仿真工具是OMNeT++軟件.實驗設置基于3 km×3 km的數據傳輸情景:5條橫向和5條垂直的數據傳輸通道.數據沿著給定的傳輸路徑行進,直到它們到達交叉傳輸口,然后以相等的概率隨機地在可用方向之一(直行,向右或向左)中繼續傳輸.實驗的參數設置如表1所示. 此算法由路由故障數、丟包率、數據交付延時、平均跳數這4個度量衡量,并根據GBSR和FMHR路由協議來評價所提出的基于錨節點的可靠路由優化協議的性能[14,15].根據實驗參數設置完畢后,接下來分別對GBSR和FMHR路由協議以及RRCP協議進行仿真,仿真的變量是節點密度,用recordScalar函數輸出程序中4種度量參數的值.根據仿真結果在Matlab中畫出節點密度與4種度量參數的關系. 表1 實驗參數設置 圖4顯示路由故障的數目隨著節點密度的增長而減小,當節點密度小于20個/km時,RRCP協議與GBSR和FMHR協議相比有更低的路由故障.在更密集部署的網絡的情況下,這3種協議的性能在路由故障方面相似.圖5顯示丟包率隨著節點密度的增長而減小.當節點密度小于30個/km時,RRCP協議與GBSR和FMHR協議相比有更低的丟包率,在更密集部署的網絡的情況下,這3種協議的性能在丟包率方面無太大差別.圖6顯示平均跳數隨著節點密度的增長而減小.也就是說,當網絡密集節點密度對GBSR、FMHR協議或RRCP協議沒有顯著的影響.但是當節點大于30個/km時,GBSR和FMHR路由協議顯示出比RRCP協議稍微更小的平均跳數.圖7顯示數據分組的延時主要取決于數據包傳輸過程中的跳數.對于GBSR、FMHR協議和RRCP協議,數據交付延時隨著節點密度的增加而減小.也就是說,當網絡密集,節點密度對GBSR、FMHR協議或RRCP協議沒有顯著的影響.但是當密度大于30個/km時,GBSR和FMHR協議顯示出比RRCP協議稍微更小的數據交付延時. 圖4 路由故障數 圖5 丟包率 圖6 平均跳數 圖7 數據交付延時 以上驗證了本文算法的優越性,還需對監控系統進行功能性測試.如圖8所示,使用RRCP協議后,較傳統的IMS監控系統,在監控響應時長上有較大改善.實驗組與對照組同時對相同的信息量進行監控,分別記錄系統在處理10、15、20、25、30、35 TB數據量后,系統監控的響應時長,實驗中保證實驗組與對照組處理參數相同,其結果如圖8所示. 圖8 監控響應時長對比 分析圖8可知,在對監控響應時長對比中,信息處理數據量的不斷增加,實驗組與對照組的監控響應時長也都不斷增加,而當數據量達到35 TB時,實驗組最高時長為0.85 s,對照組最高時長為1.25 s.因此可以看出,優化了路由協議后,監控響應時長得到有效降低. 本文研究電力物聯網IMS和路由協議的網絡特性,提出了一種基于錨節點可靠路由的電力IMS電話終端呼叫記錄集中分揀方法,此方法一方面給員工帶來便利,提高了工作效率,另一方面該系統IP報文傳輸中所采用的RRCP路由協議,具有開銷少、傳輸數據丟包率低、通信鏈路穩定的優點,最后我們還利用OMNeT++軟件對改進的路由協議進行驗證,實驗證明提出的路由優化協議在路由的故障數,丟包率,數據交付延時,平均跳數上顯示出更好的性能,并在實際的監控系統測試中監控響應時長有效降低.4 性能分析與評價
4.1 路由算法仿真實驗
4.2 IMS監控系統的測試
5 結論與展望
