基于擴展Bcp指數的領域主題發展態勢可視分析①
2020-07-25 11:36:40余敏櫧單桂華陸忠華
計算機系統應用 2020年7期
王 楊,余敏櫧,單桂華,田 東,陸忠華
1(中國科學院計算機網絡信息中心,北京 100190)
2(中國科學院大學,北京 100049)
通常,某個學科領域的頂級會議和期刊上所發表的論文代表著世界在該領域內的最新研究成果.該領域的研究人員都會對其中的前沿技術和高水平論文非常感興趣.因為這些會議和期刊所發表的論文代表著世界在該領域的最新研究成果.他們時刻關注著該領域的研究主題及其研究趨勢,渴望了解其中高被引論文、熱點主題和高度活躍的作者.分析并掌握領域研究熱點及前沿技術的發展態勢,對于科學家的研究工作、管理者的科技政策制定、甚至是研究生選題都具有重大的指導意義.
要研究領域主題的發展態勢,首要的問題就是如何從論文中提取領域中的主題.主題可以用一組關鍵詞來解釋.要提取領域中的主題,本文需要首先獲取關鍵詞.顯然,論文作者在其文章中提供的關鍵字是一個方便直接的來源.然而,有的論文并沒有作者提供的關鍵字,特別是在早期發表的論文中[1].還有相當一部分作者都認為有時作者提供的關鍵字并不能很好地表示論文的主題.為了解決這些問題,一種有效的方法是從論文的標題、摘要甚至全文中提取關鍵詞.然而,單個單詞的字關鍵詞往往存在歧義.例如,“network”一詞既可能指社交網絡也可能指神經網絡.因此,也有必要提取包含詞組形式的關鍵詞而不是單個單詞.在獲取領域關鍵詞以后,主題就可以通過用一組語義相關性高的關鍵詞來定義,即對關鍵詞進行分類.目前關鍵詞提取及分類方法主要有兩種,一種是通過人工來篩選關鍵詞并定義分類,比如邀請領域專家來打分.這種方式的優點在于精確度高、類別含義明確易懂,缺點是普適性比較差,每個會議、期刊或論文數據庫都有自己的分類標準,大多時候很難將一種來源的文獻按另一種來源的分類方法一一對應.當關鍵詞數量龐大的時候,人工方法的時間成本會變得巨大.另一種方法是通過自然語言處理及聚類算法對關鍵詞自動提取并聚類,這種方法的優點在于普適性很強,不論什么來源的論文,都能通過一套算法自動實現提取及分類.而且,計算機算法在處理大量關鍵詞的時候的具有人工無可比擬的優勢.其缺點在于提取到的關鍵詞的質量跟算法的優劣有直接關系.并且聚類結果是否有明確含義,還需要人工進行驗證.
對于領域主題,現有的科學文獻分析大都集中于使用傳統的文獻計量學方法,如統計論文數量和被引情況,建立被引用次數網絡和合著網絡等等.本文需要通過更高階的指數來揭示更深層次的現象和規律.而高階指數文獻計量結合可視分析技術正是當前文獻研究領域的熱點研究方向之一.
本文的工作正是基于關鍵詞提取、主題聚類、高階指數計量和可視分析技術研究領域主題發展態勢.本文的主要貢獻包括:
(1)本文使用提取的詞組而不是單詞作為關鍵詞.這些詞組是用自然語言處理的方法從標題和摘要中提取出來的.基于這些關鍵詞,本文使用LDA和共現關系來研究領域論文中的主題分布.
(2)將可視分析與文獻計量學相結合,分析領域主題的發展歷史、現狀和趨勢.本文提出一種擴展的Bcp指數用以描述發展狀態,并據此來判斷一個主題或關鍵詞發展狀態.同時,本文將Bcp指數應用于判斷一篇論文的被引用狀態,并將論文按引用狀態分為“延遲承認”型、“長盛不衰”型以及“其他類型”.在此基礎上,本文優化了經典的論文推薦方法.本文還建立了一個作者的合作網絡,以便挖掘一個主題的研究社團.
(3)本文開發了一個交互式可視化分析系統VISExplorer,支持科學文獻的主題發展態勢展示、趨勢分析、社團發現和論文推薦.
1 相關工作
1.1 科學文獻中的主題提取
主題提取技術已經被廣泛地應用于文獻分析.典型的主題抽取技術包括共詞分析和LDA[2]的概率方法.
共詞分析是根據關鍵字、標題、摘要乃至全文中的詞的共現關系來提取主題的[3-7].與本文的工作最相關的研究有:Coulter 等[8]在軟件工程領域的工作、Hoonlor 等[9]對計算機科學文獻的普查工作、Liu 等[10]的基于人機交互的文獻分析以及Isenberg 等[1]對IEEEVIS論文數據的分析.
LDA是Blei 于2003年提出的,是一種廣泛應用于主題抽取和文本分類的概率模型.許多工作[11-15]都致力于解釋LDA提取的主題.Sievert 等[15]還開發了一個LDA模型的交互式可視化軟件LDAvis.
共詞分析可以清楚地揭示關鍵詞與主題之間的關系,但這種方法主要依賴于人工對主題進行提取.而使用LDA 則更為方便,也不需要太多的人工操作.但是,LDA提取的主題可解釋性不高.本文中,本文將這兩種技術結合在一起.本文用LDA 從關鍵詞中提取主題,并用共詞分析來顯示主題和關鍵詞之間的關系.
1.2 文獻計量學文獻分析方法
文獻計量學中有關文獻分析的經典方法包括被引用次數分析、共引分析、合著分析、影響力分析和評估等等.本文將分析重點放在被引用次數分析和評估的基礎上,找出領域發展模式和重要的論文.
近年來,在通過被引用次數尋找領域發展模式方面做了大量工作.為了找到“延遲承認”模式的論文,Ke 等[16]系統地分析了自20世紀以來在自然科學和社會科學領域發表的2200多萬篇論文的被引用次數.Van Raan 等[17,18]利用被引用次數分析研究了1980-1994年《Science》的被引用次數,尋找物理、化學、工程和計算機科學領域的論文模式.Ke 等[16]提出了B指數來識別符合“睡美人”模式的論文.Du 等[19]擴展了B指數,提出了一種Bcp指數,Bcp指數能比B指數更準確地識別“延遲承認”類型的論文.本文參考Du的思想,提出一種擴展的Bcp指數來識別更多類型的論文.
1.3 科學文獻的可視分析
Chuang 等[4]使用Jigsaw[20]工具和CiteVis 工具[21],并基于IEEE VIS可視化論文的數據集vispubdata[22],構建了用于主題模型診斷的機器學習模型.Latif 等[23]開發了一個結合文本分析和可視化的交互式論文可視化系統,以生成IEEE VIS論文的作者文字簡介.Guo等[24]使用迭代設計的可視化分析工具分析基于主題的意義構建框架和實驗,以確定主題設計的意義,從而促進使用可視化生成研究想法.Federico 等[25]回顧了專利和論文的交互分析和可視化方法,并根據數據和任務兩個方面對文獻可視分析方法進行分類。
近年來,與本文的工作類似的是Isenberg 等[22]的工作.基于作者提供的關鍵字,他們展示了1990~2015年間發表在IEEE可視化會議系列(現在稱為IEEE VIS)上的論文的綜合的多通道的分析結果.他們對這些關鍵字進行了多次人工編碼,進而找到更高級別的關鍵字主題集合,然后使用共詞分析和策略圖來研究主題的發展態勢.然而,有將近30%論文沒有作者提供的關鍵字,他們只是簡單地把這些論文從數據中剔除出去.而且,他們的工作依賴于大量人工編碼工作,這種分類只適合于研究IEEE VIS 會議的論文,對于其他刊源的數據集,這種人工分類并不合適,而且對于更大量的數據會耗費巨大的時間成本.本文的方法是從標題和摘要中提取關鍵字,將它們與作者提供的關鍵字相結合,使用LDA 代替人工工作提取主題,運用文獻計量學的方法對主題和論文模式進行識別.相較而言,本文的方法具有更高的效率和可擴展性.
2 需求分析
本文的用戶群是處于研究生涯不同階段的研究人員,可以分為兩類:新手研究人員和經驗豐富的研究人員.
新手研究人員是指那些剛開始自己研究生涯的研究人員.他們正處于研究生涯的早期階段,對自己的研究領域了解不足.他們迫切需要知道本領域包括哪些研究主題? 每個主題研究什么技術? 每個主題發展的歷史和趨勢是什么? 哪些文章是必讀的關鍵文章? 等等.這些信息可以幫助他們快速定位關鍵文章,用最少的精力較深入地了解感興趣的研究方向,選擇最合適的研究方向.
有經驗的研究人員是指已經積累了某領域相當研究經驗的研究人員.他們正處于研究生涯的中期,對自己領域內的各種研究方向有較深的理解.這些研究人員基本都有一兩個主要的研究主題,他們經常需要這些主題的最新動態,以尋找其中某些關鍵問題的解決方案.他們需要知道這些主題是近幾年的發展態勢如何? 最活躍的作者有哪些? 有沒有與自己的研究類似的重要論文發表? 這些信息有助于激發新的研究思路.
綜上所述,可以歸納出4個主要需求:
需求1:在宏觀上展示主題分布.用戶可以在此基礎上選擇自己的感興趣的研究主題,進行深入了解和分析.
需求2:分析主題的發展趨勢.對于一個主題,用戶渴望了解該主題的研究熱點以及相關重要論文.因此,需要一種有效合理的評價方法來評價該課題的發展態勢.
需求3:顯示每個主題中作者的合作關系.一個領域的研究人員通常希望與該領域的其他同行進行交流,尤其是對高被引或高產出的作者尤為關注.此外,研究社團可以幫助用戶挖掘更多更精準的合作機會.
需求4:用戶需要高效便捷地探索領域信息.為了滿足上述要求,需要一個交互式的可視化系統.系統包含領域主題分布、趨勢分析、作者合作關系和重要論文推薦等功能.系統必須根據每次交互更新可視化內容,以便用戶能夠實時獲得聚焦主題的各維度信息.
3 數據處理
主題是本文分析的基本信息,通常由作者提供的關鍵字表示.然而,并不是所有的論文都有這樣的關鍵詞,特別是那些在IEEE VIS 早期被接受的文獻[22].Isenberg 等發現,2000年以前IEEE VIS論文的關鍵詞覆蓋率不到70%.為了充分利用這10年的論文數據,本文從論文的標題和摘要中提取關鍵詞,并在此基礎上提取主題.
3.1 數據來源
本文收集了1990~2018年IEEE-VIS 接收的3067篇完整論文.這些論文數據來源于vispubdata、IEEE VIS 官方網站、IEEE Xplore和Microsoft Academic.每篇論文包括標題、作者、發表年份、會議、摘要、被引用次數等.其中大部分論文包含了作者提供的關鍵字、IEEE關鍵詞、INSPEC控制索引和ISNPEC 非控制索引.
3.2 關鍵詞提取
本文設計了一套關鍵詞提取流程,從標題和摘要中自動提取包含詞組的關鍵字.流程由4個主要模塊組成.
M1:預處理模塊.這一模塊主要用于生成和清理用于提取關鍵詞和主題的語料庫.將每一篇論文的標題和摘要合并為一個文檔,這樣的3067個文檔就構成了語料庫,并通過將所有單詞統一為小寫以及刪除特殊字符等方法來清理語料庫.
M2:短語提取模塊.這一模塊使用NLTK 對語料庫中的詞性進行標記與分詞.NLTK是一個提供許多自然語言處理方法的Python庫.接下來,基于n-gram模型生成2-gram,3-gram,···,6-gram 并提取名詞詞組.這些名詞詞組,與作者提供的關鍵字、IEEE關鍵字、ISNPEC的控制索引和非控制索引,一起組成了關鍵詞候選集.鑒于在論文中的大多數核心關鍵詞的長度都不超過6個單詞,本文將提取詞組的最大長度設置為6.通過這種方法,本文從3067篇論文中共提取出6754個核心關鍵詞組.
M3:共現矩陣生成模塊.這一模塊計算關鍵詞候選集中,任意兩個關鍵詞的共同出現在一篇論文中的次數,并將其存放到6754×6754 大小的共現矩陣中.
M4:關鍵詞過濾.這一模塊根據過濾條件,結合共現矩陣,從關鍵詞候選集中選擇較重要的關鍵詞,將一些不重要的關鍵詞過濾掉.本文設置了3個過濾條件:
(1)每個關鍵詞都與一個以上的其他關鍵詞有共現關系(過濾掉孤點);
(2)對于每個關鍵詞,包含它的論文數不小于5篇;
(3)任意2個有共現關系的關鍵詞的共現次數不小于2次.
經過過濾后的關鍵詞就是本文所研究的領域關鍵詞候選集.通過少量的人工干預,即可產生較高質量的關鍵詞集合,具體方案在第5.2節說明.

表1 β=0.27時的選詞結果,列出了每一個主題詞頻排名前3的代表詞
3.3 主題提取
本文使用LDA模型從領域關鍵詞集合中自動提取主題.LDA是一種廣泛應用于文本分類的基于概率的機器學習方法,是一種典型的詞袋模型.它把一篇論文看作一個詞袋,詞與詞之間沒有詞序信息.因此,可以把一篇論文看作是由若干在論文中出現過的領域關鍵詞所組成的詞袋.將這些論文詞袋輸入到genism庫的LDA模型中,并設置主題數量,即可得到相應的主題.
用于投稿和評審論文的Precision Conference System(PCS)系統將關鍵詞分成14大類,Isenberg 等人[1]在經過多名專家多次研討后將關鍵詞分成16類,本文取平均值,將主題數量設為15個.通過LDA模型得到了15個主題及其關鍵詞分布,并使用Sievert[15]定義的顯著性公式來選擇每個主題的關鍵詞:
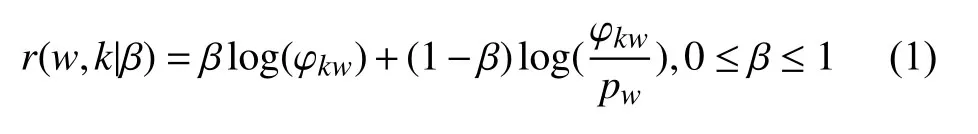
其中,r(w,k|β)是關鍵詞w和主題k的相關度.φkw是w屬于k的概率.pw是w在預料庫中的邊緣概率.β是平衡公式加號前后兩部分的系數,它是作為調節選詞歸屬度優先還是詞頻優先的重要參數.β=1時,選詞標準就完全按照歸屬大小度選擇.β=0時,選詞標準就變為完全按照詞頻大小選擇.表1是β=0.27時的選詞結果,列出了每一個主題詞頻排名前三的代表詞.
4 基于文獻計量學的主題發展態勢分析
本節將闡述如何通過文獻計量學方法來分析主題.根據第3節的需求,本文重點研究領域主題的發展態勢.主題發展態勢是一個主題的研究歷史和研究現狀的表現,主要反映在該主題相關的論文數量、論文質量、歷年趨勢、研究人員規模等指標上.
4.1 基于被引用趨勢的主題/論文分類
本文把一篇論文的生命期定義為從論文發表時刻到當前時刻的這段時期.一篇論文可以根據其生命期內的被引用次數分布情況來揭示其受關注程度.同理,一個主題的歷年被引用次數可以通過將所有與該主題相關的論文的歷年被引用次數相加來計算.一個主題的歷年研究熱度變化反映在其生命期內的被引用次數分布情況.論文/主題的歷年被引用次數分布情況可以將分為6個子類型.
子類型1:引用集中在生命期的后期,早期引用較少.這說明,論文發表/主題發展初期,很少有人關注.隨著時間推移,它的價值被慢慢發現,并被大家廣泛認可.這意味著這篇文章或這類主題的研究內容可能是具有顛覆性或超前性的,經過長期的沉寂,在當前具有很強的研究價值.圖1(a)所示為子類型1的歷年被引用曲線的示例形狀.
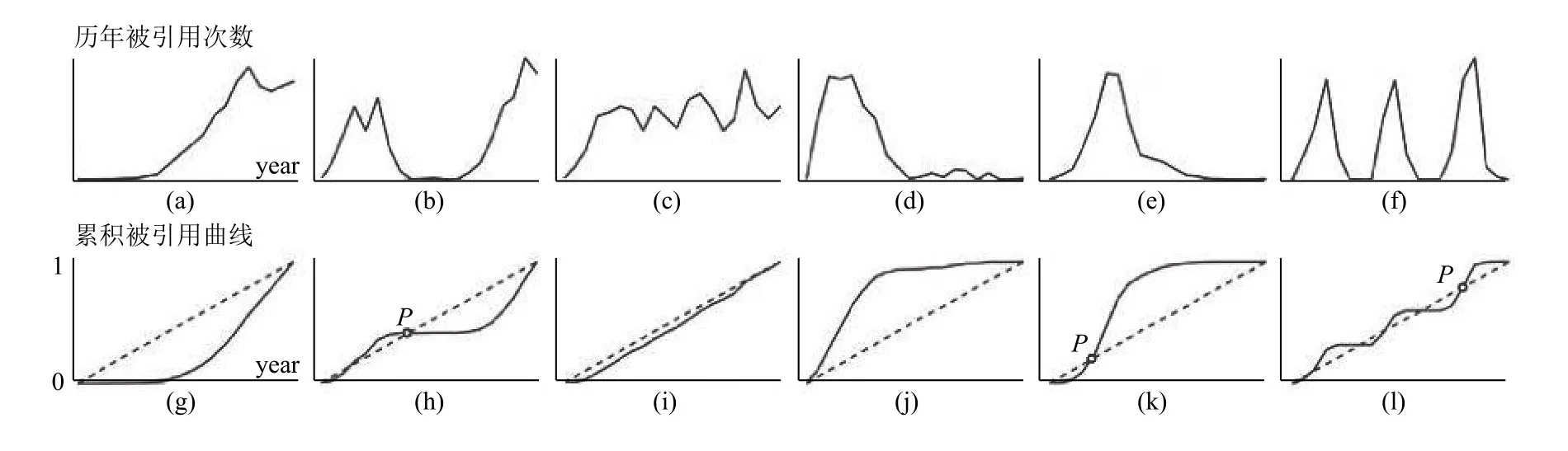
圖1 6類被引用曲線形狀和對應的累積被應用曲線形狀
子類型2:引用集中在生命期的早期和晚期,中期引用較少.這意味著論文發表/主題發展之初就廣受關注,但隨后關注度慢慢下降,在沉默了一段時間后,它又開始逐漸引起人們的注意.這說明該論文/主題所涉及的研究內容在發表之初就顯示出很高的研究價值,但由于當時技術或知識上的不足,相關研究遇到了瓶頸.然而,經過一段時期后,由于知識的積累或技術的突破,滿足了繼續推進研究的必要條件,這些研究內容再次成為研究熱點.這種類型的論文/主題在當前也具有很大的研究價值.圖1(b)所示為子類型2的歷年被引用曲線的示例形狀.
子類型3:引用次數歷年分布相對平均,無大波動.這說明論文/主題具有很強的生命力,在其生命期內每年都能保持穩定的被引用率.一般來說,這些論文或主題所涉及的內容都是經典或基礎的研究.圖1(c)所示為子類型3的歷年被引用曲線的示例形狀.
子類型4:引用集中在生命周期的早期,后期的引用很少.這表明論文/主題自發表以來受到了廣泛的關注,但隨著時間的推移,逐漸失去了人們的關注.這意味著論文/主題中提到的研究內容現在已經過時、逐漸被遺忘,或已達到成熟狀態.圖1(d)所示為子類型4的歷年被引用曲線的示例形狀.
子類型5:引用集中在生命周期的中期,早期和后期很少.這意味著論文/主題在發表之初沒有被注意到,隨著時間推移,它的價值逐漸被發現和認識,過了一段時間,又失去了研究價值.這意味著論文/課題中涉及的研究內容現在也已過時或研究已達到成熟.圖1(e)所示為子類型5的歷年被引用曲線的示例形狀.
子類型6:引用次數多次漲落,波動較大.在實際中,只有總被引次數很少的論文/主題會出現這種情況.那些重要的高被引文章或主題基本都不屬于這種類型.因此,本文不予討論.圖1(f)所示為子類型6的歷年被引用曲線的示例形狀.
這6個子類型還可以進一步合并為3大類:
第I類:子類型1和子類型2的論文/主題總是包含最先進的技術或研究熱點,對研究人員最有價值.這兩種子類型的論文/主題的共同點是,它們的被引用次數在生命期后期明顯上升.本文把這兩個子類型合并成第I類.
傳統花卉審美情致的差異,在文人的詩歌、繪畫、生活中都有較為豐富的資料記載。廳堂擺花如能充分挖掘園林主人及其友人這種審美沖突帶來的趣味性和差異性,或許能更好的展現單個園林自身的特定主題,也為賞花者增添一些樂趣。
第II類:子類型3的論文/主題一般涉及基礎知識或技術.這對研究人員,特別是新手研究人員也非常重要.這類論文/主題的歷年被引用情況相對穩定,在生命期內沒有顯著的上升或下降趨勢.本文將子類型3歸為第II類.
第III類:子類型4、子類型5和子類型6的論文/主題所包含的技術或知識通常是成熟的或過時的.這類論文/主題的引用在生命期后期明顯減少,甚至消失.本文將這3個子類型合并為第III類.
4.2 論文/主題類型識別
在第4.1節中,我們根據論文/主題生命期內的被引用次數分布定義了3大類型和6個子類型.但是,如何通過數學方法自動判斷一篇論文或一個主題屬于哪一類?在Du 等[19]的研究中,對子類型1的論文提出了一套基于累積被引用曲線的判別方法.本文擴展了這一思想,使之能滿足判斷所有類型.
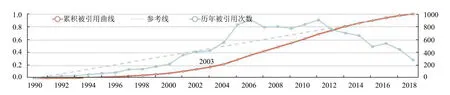
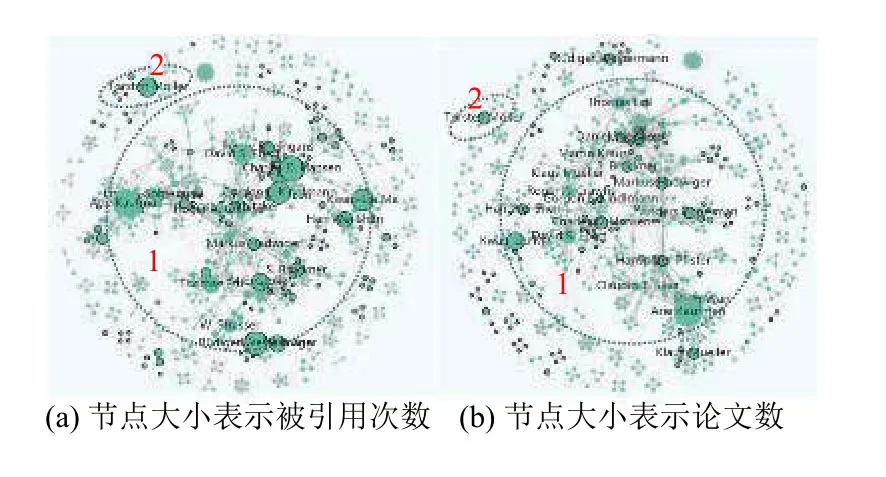
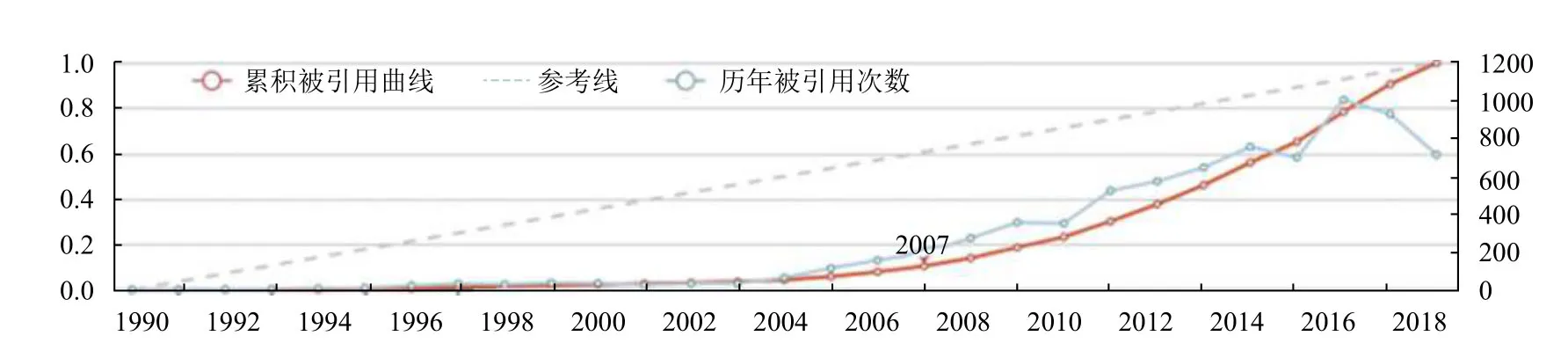
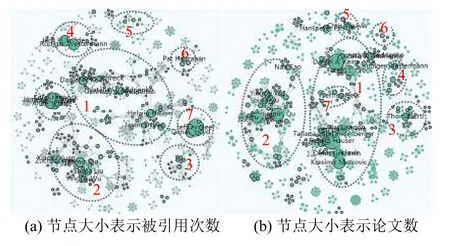
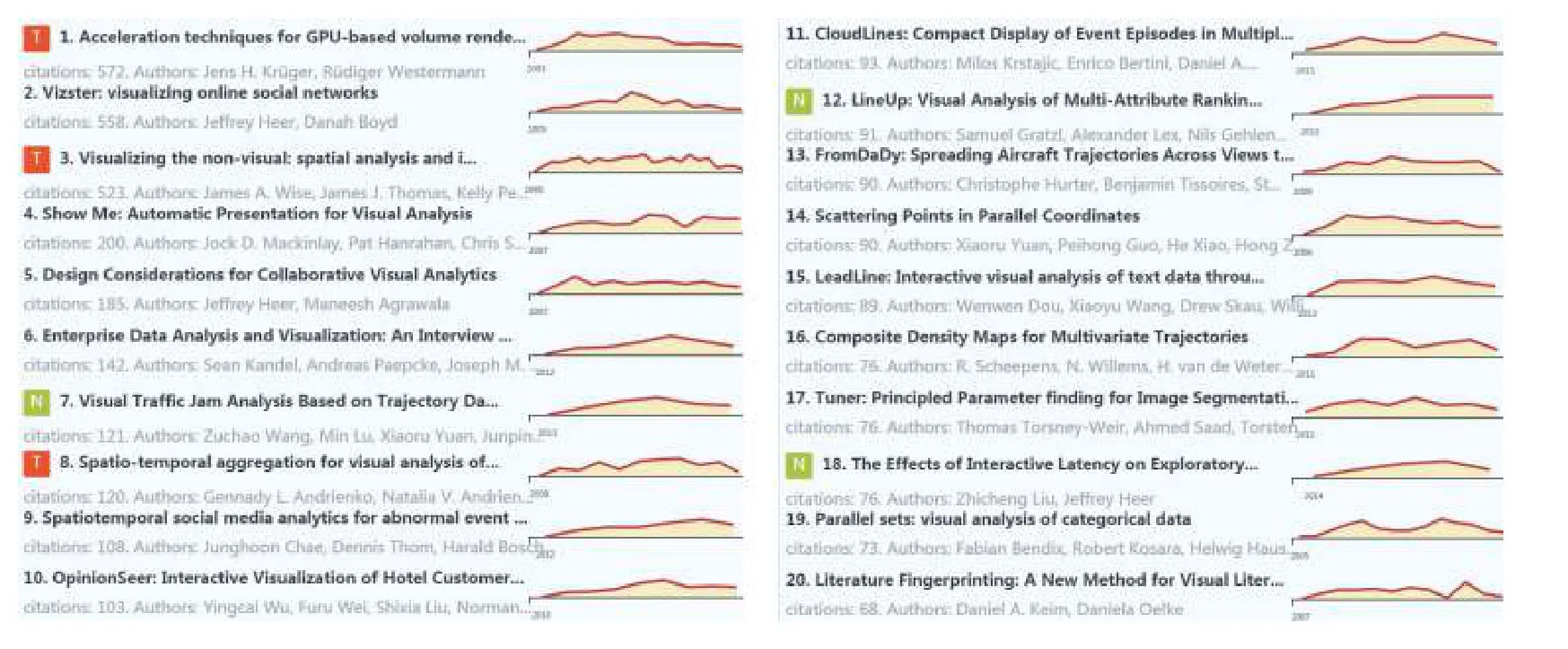
對于任意時間段[t1,t2],t1 在這個公式中,Ci表示論文/主題在第i年的被引次數,由公式(3)可知,論文/主題的歷年累計被引次數單調遞增.當t1是發表年份,t2是當前年份時,f(t1)是論文/主題發表年份的被引次數,通常f(t1)=0.f(t2)是迄今為止該論文/主題的總被引用次數. 為了消除每篇論文總被引次數差距過大而產生的影響,我們將式(3)除以f(t2)進行標準化: 式(4)就是本文接下來要重點研究的累積被引用曲線. 定義從 (t1,c(t1))到(t2,c(t2))的直線為參考線,用公式表述為: 從定義可以看出,與參考線相對應的論文/主題的歷年被引用次數是恒定的.也就是說,如果一篇論文/主題每年有相同的被引用次數,其累積被引用曲線與其參考線重合.累積被引用曲線位于參考線上方的區域意味著該論文/主題的被引用次數總體趨勢在此期間持續上升.累積被引用曲線位于參考線以下的區域意味著該論文/主題的被引用次數總體趨勢在此期間持續下降.6個子類型的累積被引用曲線的示例形狀如圖1(g)至圖1(l)所示. 除去起點和終點,累積被引用曲線與參考線的交點是論文/主題被引用次數從上升到下降或從下降到上升的轉折點.在本文中,當提到“交點”時,指的是除兩條曲線的起點和終點之外的交點.這些交點可分為兩種類型: A型:對于累積被引用曲線與參考線的交點(t,c(t)),t可能不是整數.設ti是整數年,t∈[ti,ti+1].如果c,則將交點(t,c(t))分類為A型.例如圖1(h)中的交點P.A型交點始終是論文/主題被引用次數的總體趨勢即將由降到升的關鍵點,即這類交點所對應的時間點往后一段時間內,論文/主題被引用次數的總體趨勢必然會上升. B型:對于累積被引用曲線與參考線的交點(t,c(t)),如果c(ti) 基于上述這些定義,就可以分析I-III類論文/主題的累積被引用曲線和參考線的特征.為了便于表達,將累積被引用曲線和參考線交點P(tp,c(tp))定義為靠近終點(t2,c(t2))的最后一個交點,即最近一次發生趨勢大變化的關鍵點.如果累積被引用曲線和參考線沒有交點,則P就是起點(t1,c(t1)). 對于第I類:其累積引用曲線(帶參考線)如圖1(g)(h)所示.這一類的主要特點是:累積被引用曲線在P與終點(t2,c(t2))之間的部分位于的參考線下方,且這部分累積被引用曲線和參考線圍成的區域面積較大.如果有交點,則P是類型為A的交點. 對于II型:其累積被引用曲線(帶參考線)如圖1(i)所示.這一類的主要特點是累積被引用曲線緊貼參考線或基本重合. 對于III型:其累積被引用曲線(帶參考線)如圖1(j)(k)(l)所示.不屬于前兩種類型的論文/主題都歸為類型III.這一類的主要特點是:累積被引用曲線在P和終點(t2,c(t2))之間的部分位于參考線上方.如果有交點,則P是類型為B的交點. 根據Du 等[19]的研究,為Bcp指數可定義為:對于任何非零引用論文,(c(t2)?c(t1))/(t2?t1)是參考線l(t)的斜率.對于任意t∈[t1,t2],計算l(t)?c(t)的值.然后,將這些值加在t=t1和t=t2之 間,得到Bcp指數. 指數可以用公式表示為: 從式(6)可以看出,Bcp的值是累積被引用曲線位于參考線下的面積減去累積被引用曲線位于參考線上的面積.因此,若累積被引用曲線位于參考線下的面積大,則Bcp>0,反之,Bcp<0. 從累積被引用曲線上的點(t,c(t))到參考線的距離.D(t)可以定義為從該點到參考線的垂線段的長度.D(t)可通過以下公式計算: 最大距離記為: 注意到這時間不是被引用次數中變化最大的時間,而是被引用次數累積到由量變產生質變的時間. 根據上述定義和公式,我們可以通過Bcp指數來識別論文/主題的類型.累積被引用曲線上最有趣的區域是最后一個交點P和終點(t2,c(t2))之間位于參考線下方的區域.該區域表示近年來論文/主題的被引用次數呈上升趨勢,其所涉及的研究內容是熱點. 對于I類論文/主題,計算tp和t2之間的Bcp指數.顯然,Bcp>0,Bcp值越大,面積越大,說明上升期的持續時間或范圍也越大.為了區別于II型,累積被引用曲線與參考線之間的最大距離D(tD)不應太小.所以本文設置了一個閾值來篩選D(tD),此時D(tD)大于閾值. 對于II類論文/主題,其特點是累積被引用曲線緊貼參考線或幾乎重合.所以D(tD)不應該太大.此時D(tD)小于閾值. 對于III論文/主題,不符合前兩種類型的論文/主題即為此類,此時tp和t2之間的Bcp指數為負值,D(tD)大于等于閾值. 表2中列出了這3類論文/主題的Bcp和D(tD)的特征. 表2 不同類型的Bcp特征 在眾多論文中,研究人員更關注那些高被引論文.在高被引論文中,研究人員更關注I類和II類論文.這兩類論文更具有重要的現實研究價值.因此,本文主要推薦第I類和第II類論文. 本文推薦第I類和第II類論文,并按總被引用次數降序排列.但是,按照總被引次數降序排列存在不足:被引次數較低的老文章可能會排在被引次數較低的新文章前.如一篇發表了20年的文章被引5次,一篇發表了2年的文章被引5次,用戶會更傾向于閱讀后者.因此,設置了一個限制來優化推薦列表,即每個推薦的論文必須滿足以下兩個條件之一: 條件1.這篇論文的總被引用次數足夠高.被高度引用的論文一直是研究人員最關心的論文.高被引論文的定義根據實際需要而有所不同.本文設置推薦論文的總被引次數不小于所有I類和II類論文的平均被引用次數. 條件2.這篇論文年均被引用次數足夠多.本文用年均被引用次數作為指標,是因為對于新發表的論文(生命期≤5年),生命期很短,總被引用次數不大,將其與生命期長的論文相比沒有意義.因此,為了消除生命期長短的影響,盡可能推薦有價值的新發表論文,本文設置推薦論文的年均被引用次數不小于所有I類和II類論文的平均年均被引用次數. 根據上述分析方法和思想,本文設計實現了一個交互式可視化分析系統VISExplorer.如圖2所示,該系統由6個版塊組成:領域主題總覽(a)、關鍵詞分布與分類(b)、被引用趨勢曲線(c)、合著網絡(d)和論文推薦(e). 主題和關鍵詞是本文分析的基礎.用LDA模型提取的主題可以看作是高層次的主題,而構成主題的關鍵詞可以看作是低層次的主題.主題的分布和趨勢可以通過關鍵詞的分布和趨勢來反映.因此,本文使用主題和關鍵詞作為切入點,幫助用戶找到他們想要的信息. 如圖2(a)所示,主題總覽由4部分組成:a1 用于調整關聯度 β;a2為主題選擇區域;a3 顯示所選主題的關鍵詞分布,a4為搜索框.在a2中,本文可以通過主題編號來選擇某一主題,該主題前30個最顯著的關鍵詞將顯示在a3中,并按顯著性由大到小進行排序.每次調整 β,a3 將重新排序.在a4中,用戶可以輸入自己感興趣的關鍵詞進行模糊查詢,進而選擇相關關鍵詞進行下一步分析. 圖2 VISExplorer系統界面 為了使用戶能夠對整個IEEE VIS論文中所有主題的總體分布及關系一目了然.我們需要清楚地展現兩點:關鍵詞和主題之間的關系以及關鍵詞之間的關系.前者是展示LDA提取的主題結果.后者是展示關鍵詞內部的共現關系,即共詞分析. 基于上述考慮,我們使用共詞網絡來表示關鍵詞內部的關系,如圖2(b)所示.每個節點代表一個關鍵詞,節點大小表示該關鍵詞相關的論文數量.兩個節點之間的邊表示這兩個關鍵詞有共現關系,邊的厚度與共現次數成正比.根據本文提出的分類方法,我們將所有關鍵詞分類為I、II、III類,并用不同的顏色來表示不同的類型.用戶可以使用鼠標滾輪來放大和縮小圖形,也可以通過點擊或圈選節點來選擇他們感興趣的關鍵詞. 根據共現關系而形成的共詞網絡具有明顯的聚類效果.一個主題中具有相似語義或相似意義的關鍵字聚集在一起成為主題關鍵詞群.節點尺寸大的關鍵詞表示了主題的主要研究內容,并始終處于主題關鍵詞群的中心附近.不經常出現的關鍵詞通常位于主題關鍵詞群的邊緣. 此外,該共詞網絡可用于檢驗關鍵詞提取效果.本文基于n-gram模型提取關鍵詞容易產生多余的關鍵詞,如flow field visualization關鍵詞會產生flow field和field visualization關鍵詞.但在該共詞網絡中,flow field和field visualization 這類多余的關鍵詞會緊緊圍繞flow field visualization分布,通過肉眼很容易發現.因此,通過該共詞網絡可以發現關鍵詞提取過程中存在的問題,輔助參數的設置,以得到質量較好的關鍵詞集合. 當用戶選定關鍵字/主題以后,將顯示該關鍵字或主題的所有出版物每年的累積被引用曲線、參考線和歷年被引用次數曲線.這里我們使用雙軸折線圖來繪制趨勢曲線,如圖2(c)所示.在[0,1]范圍內的左Y軸是累積被引用曲線和參考線的縱軸.在(0,+)范圍內的右Y軸是歷年被引用次數曲線的縱軸.這3條曲線共用一條表示時間跨度的X軸.紅色實線為累積被引用曲線,灰色虛線為參考線,藍色實線為歷年被引用次數曲線.圖中還使用針型圖標來標記累積被引用曲線上到參考線距離最大的點. 當用戶選定關鍵詞/主題以后,本文采用力導向布局來展現其相關作者的合著網絡,如圖2(d)所示. 圖中每個節點表示選定主題/關鍵詞的一個作者.如果兩位作者共同撰寫了一篇該主題/關鍵詞相關的論文,則會在相應的節點之間連條邊.邊寬與兩位作者合著的論文數成正比.本文采用兩種不同的規則來映射節點的大小:論文數量和被引用次數,用戶可以根據實際需求選擇. 作者合著網絡可以用來挖掘研究社區的分布.由于同一篇論文的作者之間有相互關系,這些作者的節點構成一個完全子圖.子圖之間通過共同節點合并在一起,形成更大的社區.社區中節點越大,代表的論文越多或被引用次數越多,這些通常是社區中的核心專家.如果某個節點作者的論文出現在論文推薦列表中,則將該節點用黑色描邊,描邊寬度與該作者被推薦的論文數量成正比. 當用戶選定關鍵詞/主題以后,會在“論文推薦”版塊中列出包含該關鍵詞/主題的所有重要論文,如圖2(e)所示.這些重要論文是根據5.4節中的方法對所有論文進行分類篩選后的結果.圖中同時也列出了論文的標題、被引用的次數、作者等信息,并嵌入了每篇論文歷年被引用次數曲線.圖中還使用含有字母的小圖標來標記獲獎論文或最近五年內發表的新論文.標題前帶有字母T的小圖標表示本文獲得了IEEE VIS 大會的“Test of time”獎.標題前面帶有字母B的小圖標表示該論文獲得了當年的“Best paper”獎.標題前帶有字母N的小圖標表示這篇論文是一篇最近五年內新發表的論文. 論文推薦列表使得用戶可以輕松瀏覽相對重要和有價值的論文,并根據曲線圖觀察論文歷年被引用次數的變化. 本文從IEEE VIS 大會1990~2018年間收錄的3067篇論文的標題和摘要中提取了1799個關鍵詞和15個主題.基于這些關鍵詞和主題,本節以真實案例為背景,詳細闡述如何通過VISExplorer 來分析和展示可視化領域的主題分布、發展趨勢、作者關系和重要論文. 1799個關鍵詞及其共現關系如圖3所示.圖中綠色的節點很少,這說明第II類的關鍵詞數量很少.絕大部分關鍵詞屬于第I類和第III類.從圖中可以明顯看出,關鍵詞分布有3個非常明顯的聚類(a),(b)和(c). 圖3中(a)區域具有代表性的關鍵技術是尺寸較大的節點,包括:visual analysis、case study、user study、information analysis 等,這些關鍵技術基本上都屬于信息可視化和可視分析范疇. 圖3中(c)區域具有代表性的關鍵技術包括:volume rendering、computational geometry、flow visualization、vector field、medical image processing、computational dynamic 等,這些關鍵技術基本上都屬于科學可視化范疇. 圖3中(b)區域具有代表性的關鍵技術包括:interactive system、computational modeling、feature extraction、computer display 等,這些關鍵技術基本上都屬于可視化共性技術. 從圖3中還可以看出,(c)區域中的節點幾乎都屬于第III類,這意味著近年來對傳統科學可視化技術(如體繪制、矢量場和特征提取)的引用在下降.這表明科學可視化的大部分技術的研究已經逐漸成熟或者遇到瓶頸.同時,醫學圖像處理(medical image processing)的節點為I型,這意味著醫學圖像處理在當前仍然保持著良好的研究熱度.區域(a)中的節點大多為第I類,這說明目前在信息可視化和可視分析領域的研究熱度普遍很高.區域(b)中的第I類和第III類節點數量差別不大,所以對于可視化共性技術而言,其研究熱度相對平穩.交互系統(interactive system)、特征提取(feature extraction)和計算建模(computational modeling)是當前可視化共性技術的研究熱點. 本文首先選擇volume rendering (體繪制)作為第一個案例進行深入分析.圖4顯示了體繪制技術的趨勢曲線.通過累積被引用曲線,可以看出累積被引用曲線與參考線之間的最大距離發生在2003年.這表明,2003年以后,體繪制論文的引用量發生了質的飛躍.2012年前后,累積被引用曲線與參考線產生交點,這表明自此以后,人們對體繪制技術的研究興趣逐漸減弱.歷年被引用次數曲線證實了這一趨勢. 圖4 volume rendering (體繪制)相關論文的累計被引用曲線、參考線和歷年被引用次數曲線 從圖4中,可以看出體繪制技術的發展經歷了3個階段. 第1階段為1990~2003年.在這一階段,體繪制技術經歷了技術積累期.在這一階段,其相關論文的被引用次數逐年增加. 第2階段為2004~2012年.在這一階段,體繪制技術經歷了一個繁榮時期.其相關論文的被引用次數量在這一階段初期迅速上升,并在之后繼續保持高被引用狀態. 第3階段從2013年開始至今.在這一階段,大多數的體繪制技術研究日趨成熟或者遇到瓶頸,有些可能已經過時.其相關論文的被引用次數逐漸下降.圖5(a)和圖5(b)顯示了所有發表過體繪制相關論文的作者的合著網絡.圖5(a)中的節點大小表示被引用次數,圖5(b)中的節點大小表示論文數.可以看出,圖5(a)和圖5(b)具有相同的網絡結構.Arie E.Kaufman、David S.Ebert、Charles D.Hansen、Tomas Ertl、Han Wei Shen和Kwan Liu Ma 等構成了與體繪制相關的主要研究社區,如圖5(a)和(b)中的區域1.他們之間的合作程度、相關的論文數和被引用次數都很高.其他較小的社區,如圖5(a)和圖5(b)中的區域2所示,如Torsten Móller 社區,也有大量的論文和被引用次數. 圖6顯示了根據第4.4節中闡述的規則推薦的體繪制相關的前20篇重要論文.其中,第一篇論文“Acceleration techniques for GPU-based volume rendering”于2018年獲得Scivis“Test of time”獎.從列出的20篇論文中,可以看到,這些論文都至少是10年前出版的. 圖5 體繪制相關作者的合著網絡 本文選擇visual analysis(可視分析)作為第二個案例進行深入分析.圖7顯示了可視分析技術的趨勢曲線.通過圖7,可以看到從累積被引用曲線到參考線的最大距離發生在2007年.這表明,2008年以后,體繪制論文的引用量發生了質的飛躍,比相同的體繪制質變時間晚了5年.而在整個可視分析的生命期中,累積被引用曲線與參考線之間沒有交點,說明可視分析技術的被關注度一直在增長.歷年被引用次數曲線也證實了這一趨勢. 從圖7中可以看出,可視分析技術的發展經歷了兩個階段. 圖6 Volume rendering 相關的前20 推薦文章 圖7 Visual analysis (可視分析)相關論文的累積被引用曲線、參考線和歷年被引用次數曲線 第1階段為1990~2007年.在這一階段,可視分析經歷了長期的技術積累.將近15年,可視分析技術每年的被引用次數都不高. 第2階段從2008年開始至今.在這一階段,可視分析技術經歷了它的繁榮時期.在這一時期內,相關論文的被引用次數逐年迅速上升.越來越多的研究人員發現并認識到可視分析的重要性,相關技術發展迅速,受到越來越多的關注和應用. 圖8(a)和圖8(b)展示了發表可視分析相關論文的所有作者的合著網絡.圖8(a)中的節點大小表示被引用數量,圖8(b)中的節點大小表示論文數量. 從圖8(a)和圖8(b)中,可以看到可視分析中有兩個相對較大的社區.Helwig Hauser、Kresimir Matkovic、Daniel A.Keim、Tobias Schreck 等構成了最大的社區,如圖8(a)(b)區域1所示.Huamin Qu、Xiaoru Yuan、Shixia Liu和Yingcai Wu構成了第二大社區,如圖8(a)(b)區域2所示.兩個社區內的作者高度合作.這兩個社區都有大量的論文和被引用次數. 圖8 Visual analysis相關作者的合著網絡 一些小社區也有大量的論文和引用,例如8(a)(b)區域4.有些社區發表了許多論文,但引用率不高,如8(a)(b)區域3和區域5.而8(a)(b)區域6和區域7則獲得了較高的被引用次數,卻沒有發表很多的論文.圖9顯示了根據第4.4節中闡述的規則推薦的可視分析相關的前20篇重要論文.除第1篇論文外,第3篇論文“Visualizing the non visual spatial analysis and interaction with information from text documents”,曾在2016年獲得了Inforvis的“Test of time”獎.第8篇論文“Spatio-temporal Aggregation for Visual Analysis of Movements”,獲得了2018年“Test of time”獎.值得注意的是,在這20篇論文中有13篇是在最近10年內(2008年之后)發表的,其中3篇是在最近5年內發表的,這意味著可視分析技術的更新速度遠遠快于體繪制技術. 圖9 visual analysis相關的前20推薦文章 為了評估VISExploer的實用性和有效性,本文邀請了可視化領域的研究人員對本文的系統進行實用測試.這些人中包括學生、教師、教授.每個人都在使用后寫了對系統的反饋,并提出了大量很有價值的建議.本節將列出其中兩條反饋. 反饋1:“通過選擇主題和關鍵詞,我可以了解關鍵詞之間的關系、發展狀況和值得閱讀的論文列表.與現有的通用搜索引擎或文獻檢索庫相比,系統推薦的論文列表更具代表性.作為對可視化領域尚了解不深的新手,我可以通過閱讀經典論文來了解可視化.推薦論文列表中的論文都是最具里程碑意義的論文,可以防止我盲目地在文檔庫中搜索,從而節省大量的時間和精力.此外,我建議增加對新發表的綜述型論文的推薦,這樣可以幫助新手快速了解可視化技術.” 反饋2:“主題趨勢分析和作者網絡與實際需求密切相關.論文推薦也很有意義.這個系統不僅推薦了具有里程碑意義的老文章,而且推薦出了優秀的新文章.很感激.作者網絡可以快速定位領域專家并觀察他們之間的合作情況.我的建議是,這個系統可以增強關鍵字搜索的功能.允許用戶根據自己的興趣或實際需要自由搜索各種關鍵字組合.此外,如果系統能夠支持更多的論文數據源,那就更好了.” 本文提出了滿足領域主題發展態勢分析相關實際問題的解決方案,并在此基礎上開發了一個交互式可視化分析系統VISExplorer,并利用該系統,對IEEE VIS大會1990~2018年收錄的3067篇論文的主題發展態勢進行了研究.本文還邀請了不同類型的研究人員來評估VISExplorer系統.分析結果和用戶反饋證明了該系統的有效性和實用性. 本文的工作仍存在一些局限性.首先,由于一個領域、一個主題或一篇論文都可能涉及多種技術.本文以關鍵詞提取算法來提取關鍵詞,在關鍵詞質量上是不夠的.因此,在未來工作中,我們需要設計一個自動關鍵詞檢測系統,將關鍵詞提取算法輔以可視分析技術來提煉高質量的關鍵詞.第二,本文只從標題和摘要中提取關鍵詞,這可能不能完全反映論文所涉及的所有關鍵技術,因為并不是論文的所有關鍵技術都會出現在標題和摘要中.因此,今后我們將嘗試以論文全文作為語料庫進行關鍵字提取.第三,我們需要研究更多論文類型識別方法,用以識別特別類型的論文,如評論、綜述等等,這將有助于用戶獲取更精準的建議.

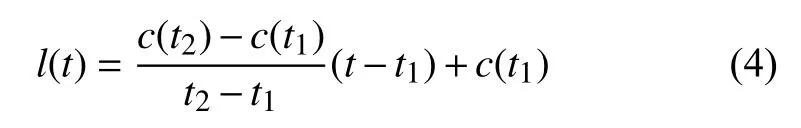
4.3 Bcp指數
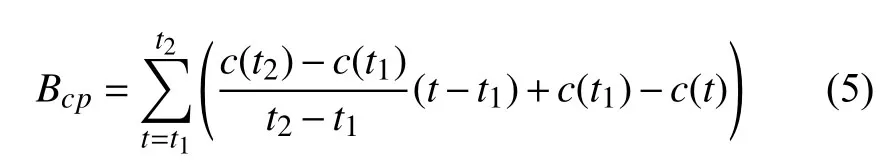
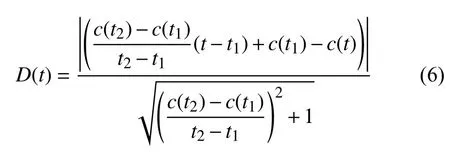
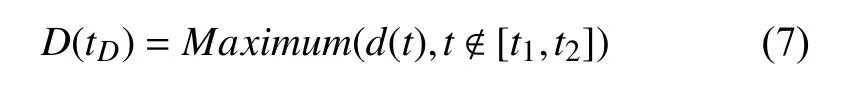

4.4 論文推薦
5 可視化設計
5.1 研究主題總覽
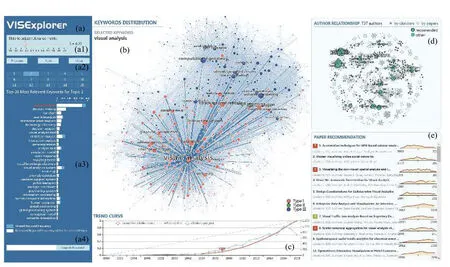
5.2 關鍵詞分布和分類
5.3 歷年趨勢
5.4 作者合作網絡
5.5 論文推薦
6 案例分析
6.1 關鍵詞分布和分類
6.2 關鍵技術:Volume rendering (體繪制)
6.3 關鍵技術:Visual analysis (可視分析)

6.4 用戶反饋
7 總結與展望
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50體育科技文獻通報(2022年3期)2022-05-23 13:46:54云南化工(2021年8期)2021-12-21 06:37:54遼金歷史與考古(2021年0期)2021-07-29 01:06:54民用飛機設計與研究(2020年4期)2021-01-21 09:15:02海洋信息技術與應用(2020年1期)2020-06-11 12:43:56科技傳播(2019年22期)2020-01-14 03:06:54傳媒評論(2019年4期)2019-07-13 05:49:14民用飛機設計與研究(2019年4期)2019-05-21 07:21:24電子制作(2018年18期)2018-11-14 01:48:24
