基于關聯規則的漏洞信息數據挖掘系統設計
2020-07-23 06:28:29馬強
現代電子技術 2020年5期
關鍵詞:數據挖掘
馬強
摘? 要: 針對當前漏洞信息數據挖掘系統挖掘效率過低、不具備實時查詢能力的問題,設計一種基于關聯規則的漏洞信息數據挖掘系統。對系統的硬件進行重點設計,硬件分為數據處理層、數據挖掘層、數據存儲層和數據查詢層四個層次。數據存儲層利用HBase數據庫存儲數據,數據挖掘層負責讀、寫和挖掘三項工作,顯示層采用MVVM框架,以模塊化的方式綁定數據,填寫標簽。根據硬件設計結果給出軟件流程,軟件分為數據量化、可量化的數據子集抽取和模糊聚類三步。為檢測系統的實際應用效果,與傳統數據挖掘系統進行對比實驗,結果表明,設計的數據挖掘系統能夠在短時間內挖掘出大量的漏洞信息數據,挖掘效率更高。
關鍵詞: 關聯規則; 漏洞信息; 數據挖掘; 挖掘系統; 數據漏洞; 信息關聯
中圖分類號: TN915.08?34; TP393? ? ? ? ? ? ? ? ? ? 文獻標識碼: A? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)05?0082?04
Design of vulnerability information data mining system based on association rules
MA Qiang
(Department of Computer Science, Changzhi University, Changzhi 046011, China)
Abstract: In view of the low efficiency and lack of real?time query ability in the current vulnerability information data mining system, a vulnerability information data mining system based on association rules is designed. The design is focused on the system hardware, which consists of data processing layer, data mining layer, data storage layer and data query layer. In the data storage layer, the HBase database is used to store data. The task of reading, writing and mining are performed in the data mining layer. The MVVM framework is adopted for the display layer, which binds data in a modular manner and fills in the label. The software flow, which consists of data quantization, quantifiable data subset extraction and fuzzy clustering, is given according to the hardware design. The system is compared with the traditional data mining system to test the application effect. The results show that the designed data mining system can mine a large number of vulnerability information data in a short time, and the mining efficiency is higher.
Keywords: association rule; vulnerability information; data mining; mining system; data vulnerability; information association
0? 引? 言
目前整個社會已經進入了“互聯網+”時代,各類數據以指數型方式增長,如果能夠在這些復雜的數據中找到有效的關聯規則,就能夠解決諸多數據方面的問題[1]。數據挖掘系統是基于上述理念研發的新型設備,該系統將統計學、數據庫、機器學習等理論融合到一起,確定數據之間的關聯規則[2]。關聯規則挖掘在數據挖掘中有著獨特的優勢,進行關聯數據規則挖掘能夠分析出數據項目之間的頻度關系,從而得到更加準確的數據挖掘結果[3]。
漏洞信息數據是數據類型之一,隨著數據量的增加,漏洞之間存在的某些規則就會變得更加明顯,利用數據挖掘系統能夠更好地處理漏洞信息,確定漏洞信息的位置,預測漏洞產生的時間,并及時解決[4]。當前大部分漏洞信息數據挖掘系統是在單機上進行工作的,處理過程過于依賴單機,處理能力十分有限,一旦單機內存不足,處理效率就會迅速降低,在解決大規模漏洞信息數據挖掘這一方面存在很大的局限性[5]。
在這種情況下,本文基于關聯規則設計了一種新的漏洞信息數據挖掘系統,重點研究了如何提高漏洞信息數據挖掘效率,以并行化改進的方式提高計算速度。最后在大數據和較小支持度的環境下,利用HBase數據庫測試了設計的數據挖掘系統的工作效果[6]。本文研究的漏洞信息數據挖掘系統不僅能夠尋找到舊漏洞,也能夠發現舊漏洞和新漏洞之間的關聯,在漏洞危害預防領域發揮著重要作用。
1? 基于關聯規則的漏洞信息數據挖掘系統硬件設計
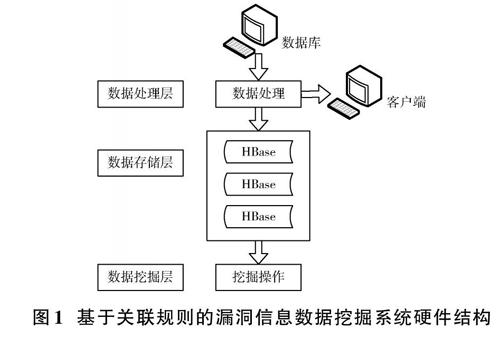
本文設計的漏洞信息數據挖掘系統在Hadoop云平臺上運行,得到的所有數據最終都會被遷移到HBase數據庫中,漏洞信息數據挖掘結果展示方式為可視化展示,同時加入了實時查詢功能[7]。
對系統的硬件結構進行分層設計,具體層次包括數據處理層、數據挖掘層、數據存儲層和數據查詢層,能夠有效地處理數據庫中的所有漏洞信息,提高數據庫安全[8]。
系統硬件內部擁有大量工作節點,即使有少部分工作節點失效,也不會影響整個系統的正常運行。除此之外,本文還加入了擴展型設計,當處理的漏洞信息數據增加時,系統會自動增加工作節點,確保系統的工作容量。
硬件結構如圖1所示。
1.1? 數據存儲層設計
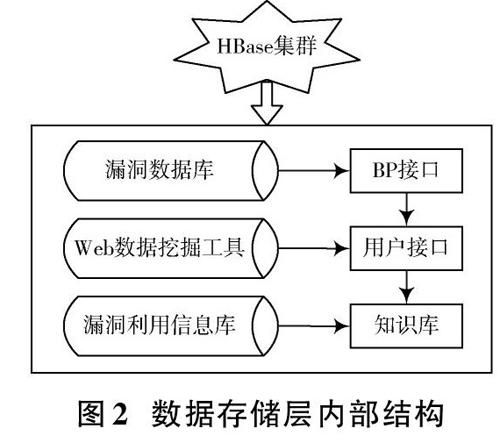
HBase數據庫的整體思路都是基于Hadoop演化而來的,是Hadoop的子項目之一。HBase的底層存儲支撐結構為Hadoop,上層結構的編程框架使用的是MapReduce編程框架[9]。HBase數據庫屬于非關系型數據庫,具有很強的分布能力和擴展能力,十分適合漏洞信息數據挖掘工作。
數據存儲層內部結構如圖2所示。
分析圖2可知,本文設計的數據存儲層可以存儲大量的半結構化數據和非結構化數據,這對漏洞信息的存儲有較大幫助[10]。
由于漏洞信息種類繁多,所以許多漏洞信息中的數字編號是不全的,傳統挖掘系統只能記錄信息量詳細的漏洞數據,導致大量漏洞數據丟失。HBase數據庫能夠詳細地記錄這些不確定數據漏洞,通過多項分析補充漏洞信息[11]。
HBase數據庫支持動態增加數據模式,數據更新或維護時,不需要再像傳統漏洞信息數據挖掘系統一樣停機運行,提高了運行效率。HBase數據庫采用緊密記錄方式存儲漏洞信息數據,避免浪費存儲空間[12]。
數據存儲層中的存儲單元不僅能夠通過Row確定,也可以通過Column確定,根據時間順序排列所有的漏洞信息數據,排序方式為倒序,處于最頂端的漏洞數據就是漏洞信息數據挖掘系統最后挖掘出來的數據[13]。
本文設計了3個HBase數據庫,提供了超大存儲量空間,數據庫內部擁有多個類型節點,Master節點負責寫,Slave節點負責讀,這種明確的分工方式可以更好地部署數據,不需要額外操作。存儲層將會得到由數據構建成的兩個表格,一個是輸入表格,另一個是輸出表格,表格格式如圖3所示。
為更好地輸出表格信息,系統提供多個插入接口,與HBase數據庫連接,每個插入接口還設定了導出接口,方便信息配置,配置的信息主要包括初始化對象、主機IP、節點IP以及各類端口號等。為了加快數據存儲速度,本文還在存儲層中加入了regions平衡數據負載,加大數據吞吐量。經過上述調整后,有效地緩解了數據存儲層的工作壓力。
1.2? 數據挖掘層設計
應用關聯規則設計了數據挖掘層,在Hadoop平臺上以并行化的方式運行,能夠同時挖掘大量的漏洞信息數據,支持MapReduce訪問模式,入庫端負責挖掘層的寫操作,查詢端負責挖掘層的讀操作。
數據挖掘層會將一個大的漏洞信息數據挖掘任務分成多個子任務,分割數量要根據平衡數據數量來確定,數據挖掘層結構如圖4所示。
圖4中的數據讀輸入內部依靠的是Key?Value存儲系統,通過該存儲系統將所有的漏洞信息數據統一成TableMapper
數據寫輸入會將得到的所有結果記錄到一個表格中,以記錄時間命名。
挖掘操作利用C?apriori算法,將所有的漏洞信息集合成頻繁項集,確定頻繁項集中數據的關聯規則,得到挖掘結果。
1.3? 顯示層設計
以圖形的方式將漏洞信息數據挖掘系統挖掘到的結果在圖形用戶界面顯示,本文設計的顯示層具有查詢和檢索功能,每一次挖掘結果都會生成一份綜合分析報告。顯示層采用的框架為MVVM框架,以模塊化的方式綁定數據,填寫標簽,前臺和后臺負責不同的工作。
顯示層執行流程如圖5所示。
分析上述流程圖可知,為了使初始化掃描更加全面,所有的漏洞信息數據都要生成Scan格式,通過新建的Scan對象確定被檢測的所有漏洞信息數據是否需要進一步檢索。分析漏洞信息數據是否滿足檢索條件,如果滿足檢索條件,則會被存入到Valuefilter文件中;如果不滿足檢索條件,則會被存到Getscanner文件中。所有的漏洞信息數據可以利用HBase數據庫查詢,借助多類型表達式篩選,不符合篩選條件的數據,將不會展示給客戶。顯示層主要功能為顯示漏洞信息之間的關聯度。
顯示界面如圖6所示。
除了界面顯示之外,還有切分表顯示和BLOCK索引顯示,確保實時全面地向用戶顯示漏洞信息,查詢速度也可以提高至毫秒。
2? 基于關聯規則的漏洞信息數據挖掘系統軟件設計
設置的漏洞信息數據挖掘系統軟件環境如下:Ubuntu 12.04操作系統、JobTracker服務節點、Slave TaskTracker服務節點、HBase集群。節點的設置情況如表1所示。
根據上述節點表格和設計的漏洞信息數據挖掘系統硬件,給出軟件流程圖,如圖7所示。
觀察圖7可知,本文設計的漏洞信息數據挖掘系統執行過程可以細分為如下三個步驟:
1) 數據量化。將得到的數據漏洞信息進行量化處理,分析漏洞信息的所屬類型,并根據漏洞危害進行等級分類。
2) 將可量化的數據子集抽取出來。對數據的詳細信息進行記錄,形成一個固定的視圖。
3) 模糊聚類。利用關聯規則判斷漏洞發展趨勢,利用模糊聚類的方法將連續值轉換成模糊量,從而確定數據挖掘系統的挖掘結果。
3? 驗證實驗
3.1? 實驗目的
為了檢測本文研究的基于關聯規則的漏洞信息數據挖掘系統的實際應用效果,與傳統挖掘系統進行對比,對實驗結果進行分析。
3.2? 實驗參數設置
設置實驗參數如表2所示。
3.3? 實驗結果與分析
根據上述參數進行實驗,選用本文研究的漏洞信息數據挖掘系統和傳統數據挖掘系統,同時對漏洞信息數據進行挖掘,記錄在相同時間內兩個系統挖掘的數據數量,根據挖掘結果對兩種系統的性能進行具體分析。
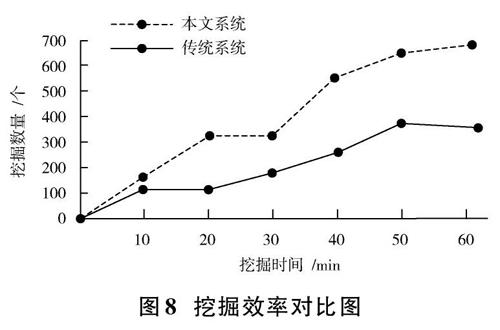
得到的實驗結果如圖8所示。
觀察圖8可知,在相同時間內,本文系統挖掘的漏洞信息數據數量遠遠超過傳統挖掘系統挖掘的漏洞信息數量。當挖掘時間為10 min時,傳統挖掘系統和本文挖掘系統的挖掘能力差距較小,傳統挖掘系統挖掘的漏洞信息數量為100個,本文挖掘系統挖掘的漏洞信息數量為150個;當挖掘時間為30 min時,傳統挖掘系統和本文挖掘系統的挖掘能力差距較為明顯,傳統挖掘系統挖掘的漏洞信息數量為180個,本文挖掘系統挖掘的漏洞信息數量達到300個;當挖掘時間為60 min時,傳統挖掘系統和本文挖掘系統的挖掘能力差距十分明顯,傳統挖掘系統挖掘的漏洞信息數量為300個,本文挖掘系統挖掘的漏洞信息數量達到600個。
由于傳統挖掘系統使用的挖掘算法過于單一,所以在短時間內只能處理單個類型的漏洞信息數據,而本文設計的挖掘系統將多種算法融合到一起,所以在相同的處理時間內本文系統能夠處理多種類型的漏洞信息數據,提高了處理速率。
綜上所述,本文基于關聯規則設計的漏洞信息數據挖掘系統具有很強的數據挖掘能力,能夠在短時間內挖掘出大量數據,工作效率高,處理能力強,具有市場發展空間,在計算機安全管理中發揮著重要作用,值得大力推廣與使用。
4? 結? 語
本文在前人研究的漏洞信息數據挖掘的基礎上,利用關聯規則設計了一種新的漏洞信息數據挖掘系統,重點設計了數據存儲層和數據挖掘層,通過實驗驗證了系統的可行性。本文的研究數據挖掘系統對于網絡信息整理、網絡信息分析都有著重要意義,但是本文引用的算法在計算過程中存在一些弊端,未來需要進一步加強。
參考文獻
[1] 張輝.基于關聯規則的運動訓練生化指標數據挖掘系統設計[J].現代電子技術,2018,41(7):183?186.
[2] 宋麗萍,韋建國.基于關聯規則挖掘技術的學生數據分析系統的設計與實現[J].長沙大學學報,2017,31(2):58?61.
[3] 許學添,鄒同浩.基于弱關聯挖掘的網絡取證數據采集系統設計與實現[J].計算機測量與控制,2017,25(1):123?126.
[4] 張奧多,張昕,李怡婷.基于關聯規則的餐飲服務智能推薦系統[J].廣西科技大學學報,2017,28(3):117?123.
[5] 劉豐年.基于數據挖掘技術的教學質量評價系統開發[J].安陽工學院學報,2017,16(6):76?80.
[6] 雷學鋒.基于關聯規則的礦井監控數據挖掘分析[J].煤炭技術,2017,36(11):289?291.
[7] 楊珍,耿秀麗.基于FCM與關聯規則挖掘的產品服務系統規劃分析[J].軟件導刊,2017,16(11):137?140.
[8] 趙紀濤,王婷.教育大數據環境下基于關聯規則的答卷分析模型研究[J].現代計算機,2017(10):44?47.
[9] 陳宏.基于關聯規則挖掘算法的用電負荷能效研究[J].電子設計工程,2017,25(4):79?82.
[10] 張延旭,胡春潮,黃曙,等.基于Apriori算法的二次設備缺陷數據挖掘與分析方法[J].電力系統自動化,2017,41(19):147?151.
[11] 楊世海,李濤,陳銘明,等.基于數據挖掘的智能電網在線故障診斷與分析[J].電子設計工程,2017,25(1):136?139.
[12] 馮卓慧,馮前進.基于關聯規則的再犯罪特征分析[J].浙江理工大學學報(社會科學版),2017,38(1):57?60.
[13] 林媛.非結構化網絡中有價值信息數據挖掘研究[J].計算機仿真,2017,34(2):414?417.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
