基于多源時空分析的復雜活動識別方法
2020-07-20 06:16:16崔海英方亞東郎瑞祥
計算機工程與設計 2020年7期
王 方,崔海英,方亞東,郎瑞祥,葉 劍+
(1.浪潮集團有限公司 浪潮云信息技術有限公司,山東 濟南 250010;2.中國科學院計算技術研究所,北京 100190)
0 引 言
用戶基本活動識別一般是指識別用戶的行走、奔跑、站立等簡單活動,與基本活動識別相比,復雜活動識別(high-level activity recognition,HAR)主要識別吃飯、工作、運動等日常生活活動,復雜活動識別提供了更加豐富的用戶情境信息,同時也大大增加了活動識別的難度[1]。
不同的復雜活動識別方法往往考慮不同的因素,例如將加速度傳感器配置在人體多個位置從而考慮人體不同部位的加速度;用手機采集用戶附近WiFi列表、地理位置、用戶環境聲音、加速度等。在眾多的相關因素中,時空軌跡被證明是與用戶復雜活動相關的關鍵因素[1-4]。該因素對于過濾用戶的活動有重要的作用,此處的過濾作用主要指根據時空軌跡特征可以排除部分不會發生在某個地點的活動。例如,當用戶在工作單位時,他可能會在工作、會議等,但是不會發生做飯、家務等活動。為此,以運動軌跡的時空特性為基礎,研究復雜活動識別方法具有重要意義。
1 相關工作
用戶的復雜活動由簡單活動組成。所以對于復雜活動識別的過程通常,首先通過先識別簡單活動,基于識別的簡單活動進而完成復雜活動識別。簡單活動識別首先將原始數據按照固定時間間隔劃分為段,進而識別每段對應的簡單活動。文獻[5]提出了一種利用智能手機的加速度計數據和機器學習算法對運動進行分類的系統,該文利用特征提取和選擇技術對簡單或識別優化,該方法可以識別和分類動態和靜態物理用戶活動,利用特征選擇,減少所需特征的數量,從而在保持分類精度的同時降低模型的復雜度,同時比較了SVM、KNN、kStar等多種機器學算法的優劣。文獻[6]提出了一種基于光學HR(心率)傳感器和三軸腕部磨損加速度計的活動監測框架。系統基于一種著名的監督分類算法——隨機森林,利用了標簽校正、信號分割、特征提取、參數檢測和特征約簡等數據處理方法,對坐、站、家庭活動等進行識別。文獻[7]采用LDA模型分析訓練數據包含的話題,將話題概率分布相似的段合并,通過比較段與用戶標簽來識別復雜活動。該類方法存在的問題在于簡單活動種類較少,只包含基本的快走,慢走,站立等活動。這并不足以區分很多復雜活動,比如用戶的工作和吃飯都是以坐這個簡單活動構成的;用戶的步行通勤和購物都是以慢走這個主要活動構成的。因此,種類過少的簡單活動并不能很好區分復雜活動。
文獻[8,9]考慮用戶的活動受其周圍用戶影響,不同社區用戶間存在相似性。因此借助相鄰用戶以及相似社區來識別當前用戶活動。文獻[8]提出了一種“眾包”方法,通過發現目標用戶和社區用戶之間的類相似性,結合用戶依賴模型和一般模型的優點,為HAR構建個性化模型,該方法使用集體數據來匹配個人數據,其中的關鍵是使用目標用戶的稀缺標簽數據,根據類的相似性選擇其他用戶數據的子集,而不是使用所有其他用戶的數據構建模型,從而構建個性化模型。文獻[9]使用軌跡相似度和用戶活動區域相似度計算用戶的關系強度從而構建關系網絡,然后提取相應的社區特征訓練基于社區的活動分類器,并根據個人的數據訓練個人活動分類器,將兩個分類器結果融合作為最終的結果。該類方法存在的問題在于當用戶量很大時,構建關系網絡是一個計算復雜性很高的任務,模型訓練需要較長的時間。
文獻[2,10-12]綜合考慮時空因素,采集多源數據,利用多源數據的不同特點,構造合適的框架,識別用戶復雜活動。文獻[2]使用手機和心電監護儀作為數據采集設備,分別采集了WiFi,GPS坐標,環境聲音等數據,并提出了一個啟發式算法對活動識別。該方法對睡眠、工作兩個活動的識別率很高,但是對于鍛煉、吃飯、外出等活動的識別率都比較低。文獻[10]提出了一種基于成本敏感的GPS活動識別模型,以提高少數活動的識別的準確性,從而反映出用戶的個人偏好,是一種側重于提供平衡結果的方法,采用成本敏感的隱馬爾可夫模型進行識別。文獻[11]在活動識別時考慮了加速度、GPS和聲頻等信息,并利用GPS信息估算出磁場信息,同時提出兩種版本的支持向量機(SVM)分類器算法。文獻[12]設計了一個啟發式的活動識別框架,共需訓練31個分類器,根據數據的不同,選擇某個合適的分類器進行預測。由于該方法需要訓練的分類器眾多,大大增加了模型訓練的工作量。該類方法中,時空特征只是作為分類器眾多特征中的一維,并未考慮時空軌跡對活動的過濾作用。
為此,本文提出了一種基于ROA復雜活動識別方法,該方法充分利用時空軌跡對交通方式識別的重要作用以及對用戶復雜活動的過濾作用,使得每個ROA內復雜活動具有較強的規律性并且復雜活動的種類小于待識別活動全集的種類,因此有助于提高分類器對復雜活動的識別率。與文獻[5-7]所述的方法不同,本文并未識別簡單活動,而是根據相關特征直接識別復雜活動。與文獻[8,9]所述的方法不同,該類方法使用用戶時空軌跡來衡量用戶的關系強度構造關系網絡,本文并不需構造復雜的關系網絡,從而在計算復雜度上低于這些算法。與文獻[2,10-12]所述的方法不同,該類方法一般利用時空軌跡提取速度,獲取地理位置的類別等,并將這些信息作為分類器的一維特征輔助復雜活動識別,本文則是利用時空軌跡將數據劃分為ROA,基于ROA識別復雜活動。同時,本文中提到的分類器并不局限于某種特定的分類器,每個ROA可以根據實際情況采用相同或者不同的分類器。
2 復雜活動識別
2.1 算法框架
基于ROA復雜活動識別方法的算法框架如圖1所示。訓練階段,首先使用ROA提取算法從傳感器數據流中提取ROA,基于不同的ROA,分別訓練相同或不同的分類器。識別階段,首先,判斷待識別的數據屬于哪個ROA,然后選擇相應的分類器進行分類,分類的結果即為復雜活動識別的結果。當用戶到達了一個他以前從未到過的地方時,由于缺乏有效的歷史數據,判斷當前數據的ROA將產生較大的誤差,這種情況下,可以通過比較ROA屬性的相似性來選擇合適的ROA。同時,用戶一天的識別結果就可以組成用戶該天的活動模式。活動模式對活動識別具有重要意義:活動模式提供了一個活動之前活動和之后活動的信息,這樣的信息使得可以根據活動之間的聯系來對識別的結果進行合理調整;并且用戶的活動模式具有規律性,例如用戶在工作日的活動模式是相對固定的,在非工作的活動模式也是相對固定的。這樣的規律性使得可以把活動規律當作用戶活動識別的先驗知識,提高活動識別的準確率。關于活動模式的應用,我們將在未來的工作中繼續探究,本文我們將著重討論ROA的提取及分類器的訓練。
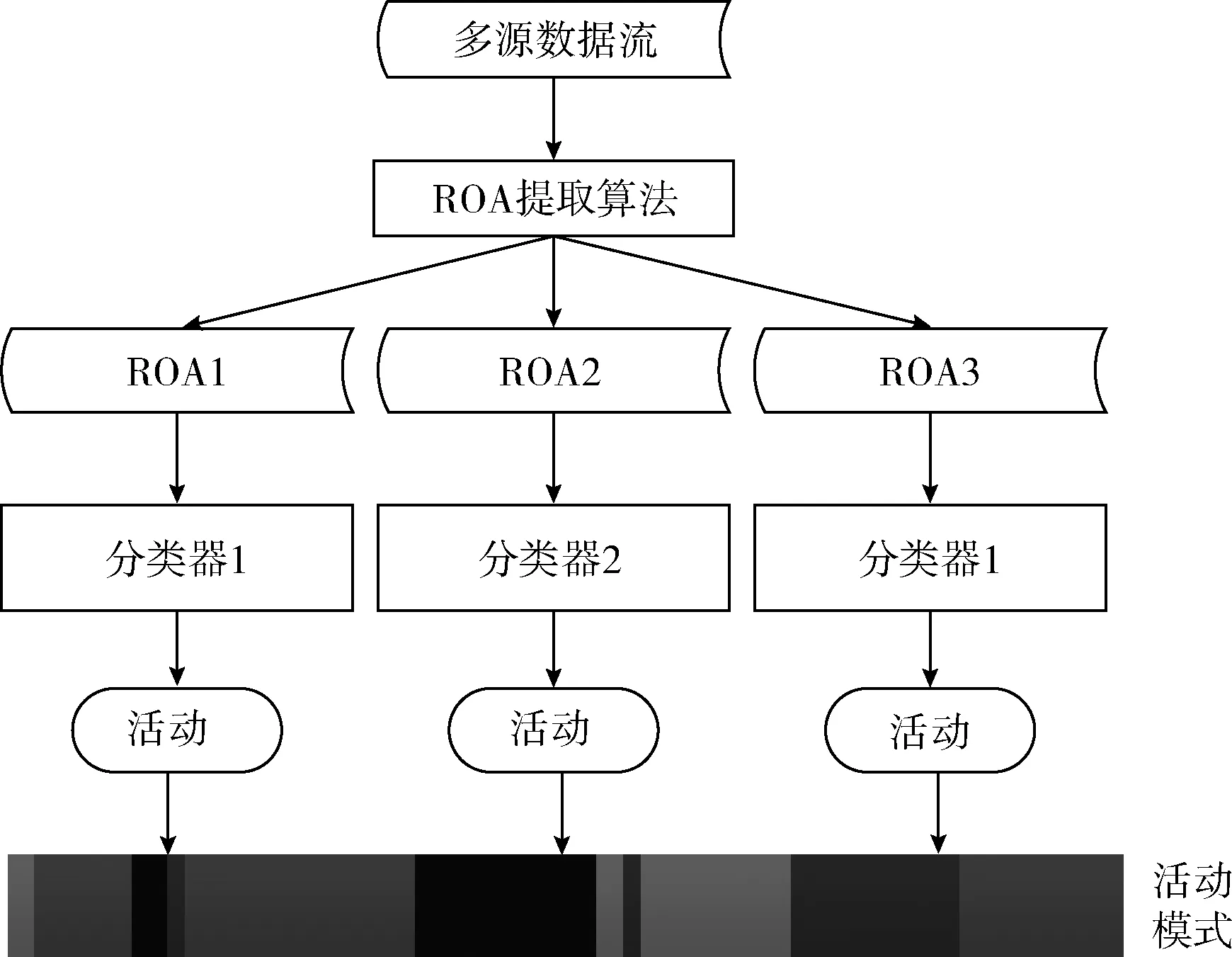
圖1 基于ROA復雜活動識別方法框架
2.2 ROA提取算法
時空軌跡對復雜活動的過濾作用主要體現在用戶不同ROA的活動種類相對較少并具有較強的規律性。本文提出了兩種ROA提取算法,第一種是基于密度聚類的ROA提取算法,此算法基于用戶長時間停留的區域GPS數據采樣及WiFi列表數據采樣的密度將會大于用戶以某種交通方式經過的區域,因此采用密度聚類可以從數據中提取ROA。然而,用戶的差異性和地點的差異性對密度聚類的參數具有較大的影響,使得密度聚類方法的參數不容易確定,同時,密度聚類算法具有較高的時間復雜度,面對大量數據時,需要較長的訓練時間。因此,本文提出了基于濾波的ROA提取算法。用戶的ROA是由若干道路連接在一起的,當用戶以某種交通方式通過道路時,GPS坐標變化率將會高于用戶長時間停留的ROA,因此采用濾波的方式,識別道路上的數據,并對非道路上的數據進行合理的合并,可以從數據中提取ROA。該算法相對于基于密度聚類的ROA提取算法而言,用戶差異性和地點差異性對參數影響較小,同時具有較低的算法復雜度。
2.2.1 基于密度聚類的ROA提取算法
在基于密度聚類的ROA提取算法中,首先對WiFi列表進行了基于Jaccard距離的密度聚類,將每個類中的GPS坐標統一修正為該類中所有GPS坐標的平均值,進而對修正后的GPS數據進行基于歐氏距離的密度聚類。聚類結果中,每一個類即為一個ROA,所有非類內點視為一個ROA,非類內點所對應的ROA一般為道路上的點。算法偽代碼如算法1所示。
算法1: 密度聚類ROA提取算法。
輸入: GPS數據GPSData, WiFi列表數據WiFiData
輸出: ROA標簽ROATag
WiFiDistance←GetDistance(WiFiData, “jaccard”)
WiFiCluster←DBSCAN(WiFiDistance,eps,minPts)
WiFiClusterTag←WiFiCluster.tag
FOR(iINunique(WiFiClusterTag))
IF(i!= 0)
index←which(WiFiClusterTag==i)
GPSData[index, 1] ←mean(GPSData[index, 1])
GPSData[index, 2] ←mean(GPSData[index, 2])
GPSDistance←GetDistance(GPSData, “euclidean”)
GPSCluster←DBSCAN(GPSDistance,eps,minPts)
ROATag←GPSCluster.tag
RETURNROATag
之所以采取先對WiFi列表聚類修正GPS數據再對GPS聚類的原因是,在某些建筑物中,由于建筑物結構使得建筑物內GPS信號時有時無,這樣情況下產生的GPS定位結果誤差非常大,如果直接使用GPS密度聚類,無法將這些數據采樣聚在一起,產生錯誤,如圖2所示。圖2中每個非圓的圖形代表一個聚類。圖2(a)中,右下角十字,叉,菱形為同一地點的GPS采樣,由于信號問題導致有較大的偏差而無法聚在一起。WiFi的輻射距離相對較小,所以,使用WiFi數據聚為一類的數據,實際的GPS位置不會相差太大,因此采用WiFi聚類修正數據采樣的GPS坐標。如果只使用WiFi聚類,由于某些建筑沒有WiFi信號,導致會丟失這些建筑物的聚類,如圖2(b)所示。圖2(b)中右下角較為分散的點因為WiFi采樣一致而被聚集在一起,但是右上方和左方的聚類由于沒有WiFi信號而丟失。所以,采取了使用WiFi聚類修正GPS坐標再對GPS聚類的方法,結果圖2(c)所示。圖2(c)中左方和右上方的聚類沒有丟失,右下方點經過WiFi修正而聚為一類。
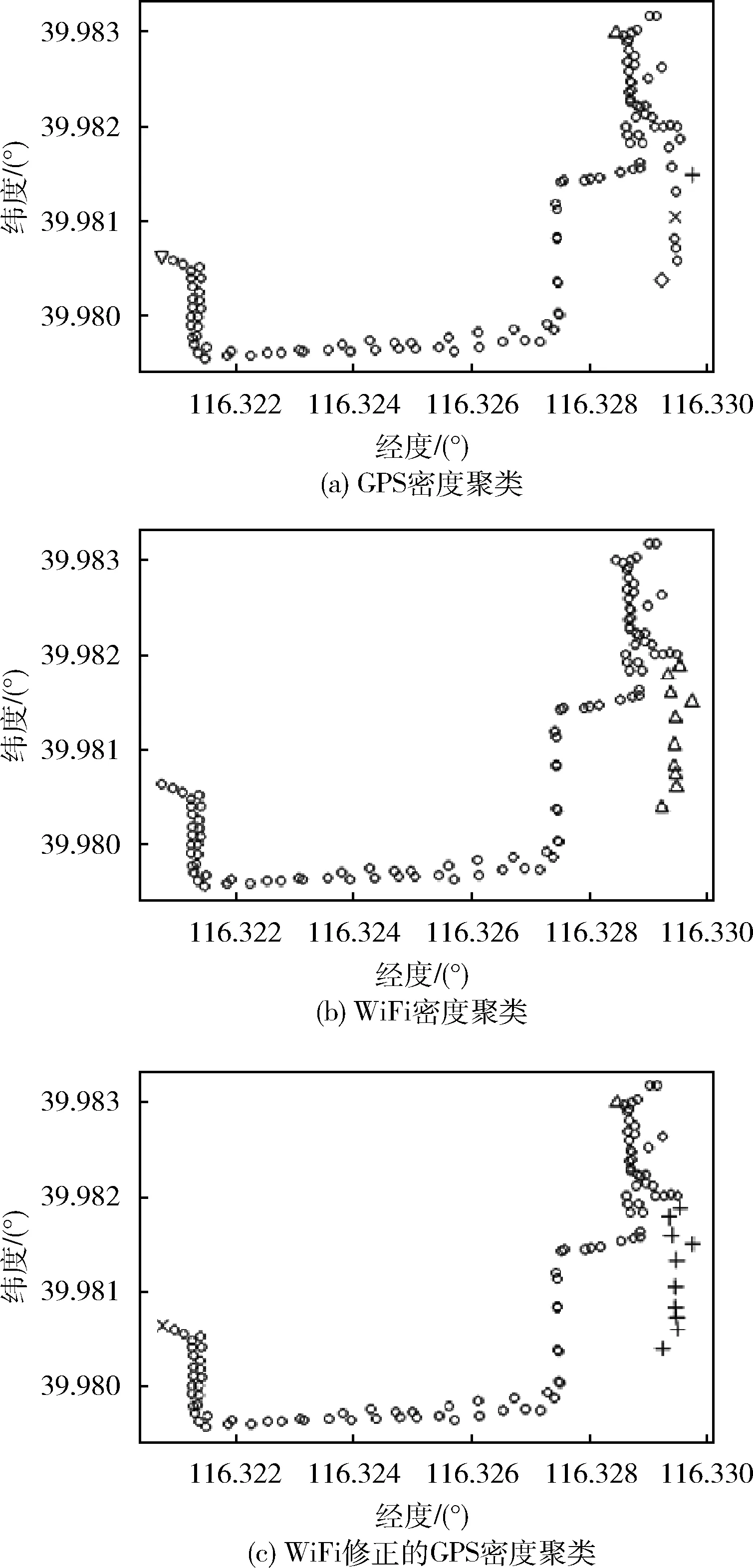
圖2 基于密度聚類的ROA提取算法
2.2.2 基于濾波的ROA提取算法
在基于濾波的ROA提取算法中,首先根據GPS坐標及采樣頻率求出GPS坐標的變化率。由于用戶在道路上可能因為某些原因會停止前進,同時,某些建筑物會發生GPS坐標的偏移產生GPS變化率的突變,因此首先采用平滑濾波器對GPS變化率進行平滑濾波,可以根據數據的不同情況采用平滑線性濾波器或統計排序(非線性)濾波器,本文采用了均值濾波器。對平滑濾波后的數據低通濾波,此時,標記為1的點組成用戶長時間停留的數據段,標記為0的點為道路上的點。接下來需要將屬于同一個ROA的數據段進行合并。對當前每個數據段計算一個平均值,當兩個數據段的平均值小于一定閾值時,將兩個數據段進行合并,合并完成即為ROA提取結果。算法偽代碼算法2所示。
算法2: 濾波ROA提取算法。
輸入: GPS數據GPSData
輸出: ROA標簽ROATag
GPSChangeRate←GetGPSChangeRate(GPSData)
GPSSmoothRate←SmoothFilter(GPSChangeRate)
GPSTag←LowPassFilter(GPSSmoothRate)
ROAMean←NULL
GPSList←NULL
FOR(iIN1:length(GPSData))
IF(GPSTag[i] == 1)
GPSList.add(GPSData[i])
ELSE
IF(GPSList!=NULL)
ROAMean.add(mean(GPSList))
GPSList←NULL
ROATag←mergeROA(GPSTag,ROAMean)
RETURNROATag
2.3 復雜活動識別方法
完成ROA提取后,需要為每個ROA訓練一個分類器。特別的,當根據訓練數據判定某個ROA為平凡ROA時,對該ROA不訓練分類器,而直接使用該平凡ROA對應的復雜活動作為識別的結果。本文將從分類器數據采集及分類器設計兩個方面介紹分類器的訓練。
(1)數據采集。數據采集階段,需要獲取盡可能多的與用戶復雜活動相關的特征,不同數據采集設備能獲取到的數據不同,本文采用的智能手機作為數據采集的設備,因此,將以智能手機為例對數據采集的特征進行探討。本文中采集的數據主要是:①時間。用戶的復雜活動往往受到時間的約束,例如,用戶在固定的時間上班,固定的時間下班,固定的時間吃飯等;②x、y、z方向的加速度。不同的復雜活動往往對應不同的加速度變化率,當用戶睡眠時,加速度的變化率趨近于0,而當用戶運動時,加速度值變化劇烈;③是否是工作日。用戶在工作日的活動規律是與非工作日的活動規律不同的;④手機模式、是否在充電。某些用戶的手機模式、充電狀態是與用戶的活動有關系的,例如某些用戶習慣睡前將手機調為靜音或震動模式,有些用戶習慣睡眠的時候對手機充電等;⑤用戶最近使用的5個App。由于智能手機的功能越來越強大,越來越多的人使用手機娛樂,學習,點外賣等,這時候,用戶使用的App一定程度上與用戶的復雜活動有關系。⑥GPS坐標。獲得用戶軌跡,提取ROA。⑦WiFi列表。用戶直連WiFi和信號強度最強的15個WiFi MAC地址列表,提取ROA。
(2)分類器設計。由于不同分類器適用于不同的場景,為了發揮不同分類器在不同場景下的優勢,本文分別為不同的ROA訓練了kNN,SVM,決策樹,樸素貝葉斯4種分類器。ROA提取算法會影響最優分類器的選擇,本文在兩種ROA提取算法的基礎上,分別實現了上述的4種分類器。最優分類器與數據的特點具有比較密切的關系,無法根據ROA的特點直接選擇最優分類器,由于留一交叉驗證可以很好驗證模型的泛化能力,本文采用留一交叉驗證選擇最優分類器。本文統計了所有ROA中,最優分類器的比例。在65%的ROA中,SVM是最優分類器,在32%的ROA中,決策樹是最優分類器,3%的ROA中,樸素貝葉斯是最優分類器,沒有任何ROA,kNN是最優分類器。因此,本文選擇了SVM和決策樹作為復雜活動識別的分類器。
3 實驗結果及分析
本文將從比較基于密度聚類的ROA提取算法和基于濾波ROA提取算法的優劣以及驗證ROA提取算法可以提高活動識別的準確性兩個方面進行實驗。為了比較兩種ROA提取算法的優劣,首先本文對兩種ROA提取算法的時間復雜度進行了嚴格的推導,比較兩種算法時間復雜度的區別。然后分別使用兩種ROA提取算法對相同的數據提取ROA,并使用相同的分類模型對活動進行識別,使用活動識別準確性來評價ROA提取算法準確性。為了驗證ROA提取算法可以提高活動識別準確率,本文分別使用先提取ROA再分類的方法和直接分類的方法對相同的數據進行了實驗,通過對比兩種方法活動識別的準確率來驗證ROA提取算法的效果。
3.1 實驗數據集
我們在Android智能手機上實現了數據采集App來進行數據采集。數據采集App會以后臺進程的形式使用 0.1 HZ 的頻率進行數據收集,這樣一個相對較低的頻率使得數據采集App不會嚴重影響用戶手機的續航能力。數據標注方面,一部分研究者采用的是用戶開始活動時點擊活動開始,結束是點擊活動結束,用戶點擊按鈕的時間即為活動的起始時間。實際使用過程中,本文發現,這種標注方式往往因為用戶忘記標注活動結束而導致數據產生錯誤。因此,本文采用了用戶在自己方便的時刻進行標注的方式,標注的時候用戶可以選擇活動的起始時間,從而減少錯誤標簽的產生。大部分志愿者表示,這種標注方式對用戶的正常生活干擾較小,友好性更強。
共7名志愿者參與了本次的數據采集,身份既有老師也有學生。他們有著不同的生活習慣和活動地點,從而保證了數據的多樣性。每名志愿者收集了為期3周的活動數據,最后一共收集了130天的活動數據,共3120個小時,涉及活動標簽743個,平均每個志愿者106個活動標簽。
3.2 ROA提取算法的比較
本文在嘗試了眾多分類模型后,發現SVM和決策樹是眾多分類模型中性能最好的兩個。因此本文采用了濾波提取ROA和SVM(Filter+SVM)、濾波提取ROA和決策樹(Filter+DT)、聚類提取ROA和SVM(Cluster+SVM)以及聚類提取ROA和決策樹(Cluster+DT)4種模型進行比較。本文使用數據集中前兩周的數據作為訓練集,分別對4種模型進行了訓練,使用最后一周的數據作為預測集,得到了模型預測的結果。根據模型預測結果和數據采集時用戶真實的活動標簽,計算了4個模型對各種活動識別的準確率、召回率以及F-score,如圖3所示。圖3中對于學習和睡覺兩種活動而言,濾波算法和聚類算法具有接近的F-score,對于吃飯、運動、家務和交通而言,濾波算法的F-score大于聚類算法的F-score。因為用戶差異性和地點差異性會影響聚類算法參數的選擇,導致部分數據被劃分到錯誤的ROA導致活動識別產生錯誤。而濾波ROA提取算法參數受用戶差異性和地點差異性影響較小,故取得了相對較高的F-score。
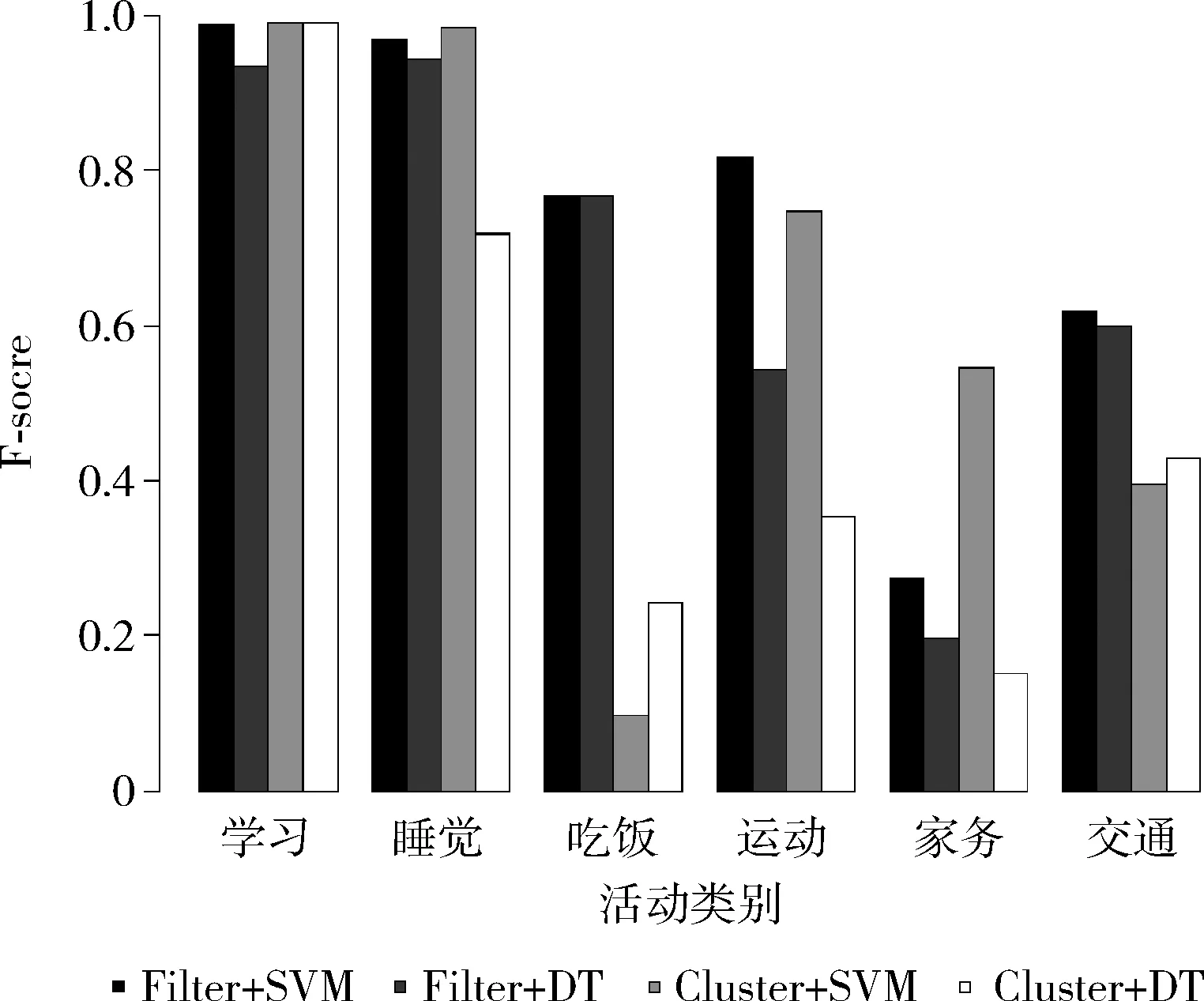
圖3 兩種ROA提取算法的對比
3.3 基于ROA復雜活動識別方法的準確性
因為基于濾波的ROA提取算法具有較高的準確性,因此本文采用了濾波ROA提取算法和SVM(Filter+SVM)、濾波ROA提取算法和決策樹(Filter+DT)、不提取ROA的SVM(SVM)、不提取ROA的決策樹(DT)這4種模型進行比較,同樣采用前兩周的數據作為訓練集,后一周的數據作為預測集,計算了4種模型的準確率、召回率和F-score。如圖4 所示。圖4中,無論針對什么活動,加上ROA提取算法的模型F-score都大于不提取ROA直接分類的模型。極端的,對于睡覺這種活動,不提取ROA的情況下F-score為0,而提取ROA后,F-score超過90%。這表明ROA提取算法對于提高活動識別準確性具有明顯作用。
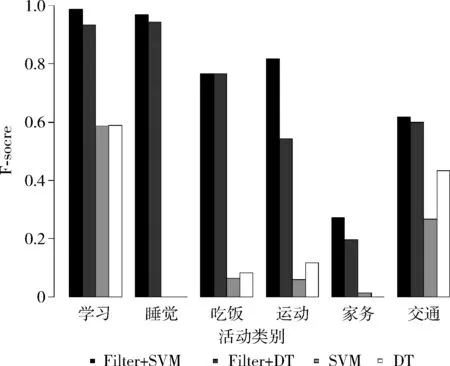
圖4 有ROA提取算法與無ROA提取算法的對比
表1中,列出了不同模型對各項活動識別的F-score,其中“所有”代表所有活動的F-score。從模型角度而言,Filter+SVM和Cluster+SVM的結果較好,并且相對接近,兩種模型在識別不同的活動時各有優劣,但Filter+SVM的訓練速度更快。Filter+DT的效果次于前兩者,差別不大。SVM和DT與其它有ROA提取算法的模型效果相差甚多,再次驗證了ROA提取算法有效提高了活動識別準確性。從活動的角度而言,學習、睡覺、運動、吃飯4種活動F-score較高,而家務、交通這兩種活動F-score較低。本文對家務的定義是在家里發生的除了學習、睡覺、吃飯、運動以外的活動。由于家務的定義相對寬泛,并且用戶在家里并不會隨身攜帶手機,而經常將手機放置在某個地方從事家務,因此,對家務的識別率較低。借助室內定位技術和智能家居技術輔助識別家務將可能提高家務的識別率。對于交通而言,其錯誤的識別一般發生在用戶離開座位但尚未離開建筑物或用戶進入建筑區但尚未達到自己座位的時候。比如用戶學習后離開建筑物步行一段時間進入餐廳吃飯,模型將離開座位但尚未離開教學樓和進入餐廳尚未到達座位的數據分別識別為學習和吃飯,而用戶往往將這部分數據標記為交通。由于實際生活中,活動的切換并沒有嚴格的界限,因此,模型對這部分數據的預測并不能認為是錯誤的,并且對實際的應用也不會產生太大的影響。因此,本文認為模型在這種情況下產生的誤差是可以接受的。

表1 不同模型對各種活動識別的F-score
4 結束語
為了解決移動場景中的復雜活動識別問題,本文提出了一種基于ROA的復雜活動識別方法。該方法利用了時空軌跡對復雜活動的過濾作用,從數據中提取ROA,使得每個ROA中復雜活動種類相對較少,構成相對簡單,規律性較強。在此基礎上,該方法在不同的ROA上,可以使用不同分類模型對復雜活動進行區分,充分發揮不同分類模型在不同場景下的長處,大大提高了模型的魯棒性。最后,本文基于現實生活中收集的數據進行了實驗。實驗結果表明,本文提出的基于ROA復雜活動識別方法可以明顯提高復雜活動識別的準確率。
下一步,我們將從兩個方面繼續我們的工作,首先我們將考慮當用戶到達一個新的位置,在沒有有效歷史數據的情況下怎樣提高活動識別的準確性。進一步的,我們將考慮活動模式對活動識別的重要作用,用戶活動一般具有較強的規律性和聯系性,充分考慮活動模式將有助于提高用戶活動識別的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
海峽姐妹(2018年3期)2018-05-09 08:20:40
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
