基于無線傳感器網(wǎng)絡的步態(tài)識別
2020-07-20 06:16:12謝曉蘭徐承星
計算機工程與設計 2020年7期
關鍵詞:實驗
謝曉蘭,徐承星
(桂林理工大學 信息科學與工程學院,廣西 桂林 541004)
0 引 言
物聯(lián)網(wǎng)通過信息傳感設備如射頻識別(RFID)[1]、紅外線[2]、全球定位系統(tǒng)[3]和激光掃描儀[4]采集對人類有用的信息,連接到互聯(lián)網(wǎng)并以進行通訊、識別、定位、跟蹤、監(jiān)控和管理。Wifi作為一種強大的感知信息的媒介,具有普及面廣泛、組網(wǎng)方便且傳輸速率高的優(yōu)點[5]。
近年來,使用特定的設備,通過連接Wifi可以采集到從發(fā)送點到接收點的無線信道信息(CSI)[6],它是物理層的信息,描述了信號在每條傳輸路徑上的衰弱因子,即信道增益矩陣H,它對環(huán)境的變化比較敏感,通過對這一信號的分析可以完成許多任務,例如步態(tài)識別[7]。盡管目前已經(jīng)可以通過分析CSI進行室內(nèi)定位或者手勢分析,但其表現(xiàn)卻往往因復雜的實驗條件而惡化,此外,需要大量數(shù)據(jù)的支撐。本文利用Wifi技術對人的身份識別問題進行了研究,我們處理以下問題:在采集一些人的信息之后,如果進來一個人,我們是否能識別出這個人是否屬于之前保存過的其中一個。我們在這項工作中的目標是使用基礎設施來實現(xiàn)低成本的部署,并且盡量降低計算成本。Wifi傳感需要收集CSI信號以描述無線網(wǎng)絡,不同的人行走在同一路徑上其表現(xiàn)在CSI上的值必然不同,當一個人在走廊上有規(guī)律的走動時,采集到其CSI,在去噪處理以后可以反映人的步態(tài)信息,通過分析CSI的變化識別這個人。
調(diào)查發(fā)現(xiàn)許多研究者使用深度學習的方式提取CSI特征并生成模擬的步態(tài)信號,這當然極大加速了識別過程,但其生成的數(shù)據(jù)集與原生環(huán)境訓練的數(shù)據(jù)集是有偏差的。且現(xiàn)有研究在許多場景下判斷錯誤的概率較大,這是不能容忍的,因為沒有辦法能彌補判斷錯誤的損失。
無線信道一般用信道的沖擊響應來對信道[8]的多徑效應進行描述,在線性時不變的假設條件下,信道沖擊響應可用下式表示
(1)
其中,ai為第i條路徑的幅度衰減;θi為第i條路徑的相位偏移;τi為第i條路徑的時間延遲;n為傳播的路徑總數(shù);δ(τ)為狄利克雷脈沖函數(shù)。
信道的頻率響應可以用下式表示
z(k)=||z(k)||ej∠z(k)
(2)
其中,z(k) 為第k個子載波的信道狀態(tài)信息CSI; ||z(k)|| 為第k個子載波的幅度; ∠z(k) 為第k個子載波的相位。
目前,常用的步態(tài)識別有兩種方式:①視頻圖像處理,系統(tǒng)由通用的視頻設備和計算機硬件組成,采用數(shù)字視頻和數(shù)字圖像處理技術,包括模板匹配、亞象素以及運動估值等技術來識別、跟蹤標志點的運動,這種方式需要攝像頭的支持,并且侵入性高;②無線感知技術,這種方式的精確度依賴于數(shù)據(jù)處理算法,且數(shù)據(jù)量大。本文關注第二種方式,以不同的視角上進行觀察,步態(tài)表征都會因各種條件變化而產(chǎn)生顯著的影響如:觀察的角度、人類的穿著、信道的通信條件。研究者創(chuàng)建的識別系統(tǒng)主要使用建立模型的方法來提取步態(tài)特征,但建立模型需要使用各個視角的視圖,這會使得整體結構臃腫且計算費用昂貴,在特征提取方面,深度學習或人工神經(jīng)網(wǎng)絡獲得了廣泛采用,但其高度依賴于大量訓練樣本。由文獻[9]可以得知,可以通過統(tǒng)計信號波峰波谷的數(shù)量來近似計算出人的移動路程,這是因為伴隨著人的移動,信號的傳輸距離也會發(fā)生變化,人體反射的信號會增強或削弱接收端接收的信號,這也是CSI在走廊上會表現(xiàn)出周期性變化的原因。
研究使用多個實驗模板,組合成一個樣本集,每個實驗模板都將用于對比任意活動的測試數(shù)據(jù)。每個測試信號通過DTW算法映射到所有的模板,然后使用DT-kNN算法來判斷測量結果的分類。數(shù)據(jù)是在較為理想的實驗情況下采集的,單人在實驗環(huán)境下的運動可以近似看作一個平穩(wěn)過程,為了保證每條數(shù)據(jù)足夠干凈,我們預先篩選了數(shù)據(jù)。
1 相關工作
本節(jié)包括本文針對所研究的問題使用的技術,第一部分包括研究人員推薦使用的方法,與本文的對比、差異;第二部分包括傳感器網(wǎng)絡、特征和系統(tǒng)框架。
最近的研究中有使用不同的方法對CSI進行濾波和結果分析,例如:文獻中推薦使用單一的DTW算法來進行分類[12],該工作還考慮了DWT技術減少了實驗數(shù)據(jù)數(shù)量,研究針對相似數(shù)據(jù)進行了誤差糾正。有做類似工作的研究人員使用SRC[13]或SVM算法對數(shù)據(jù)進行分類,即獲取對人類的不同動作在同一時刻的CSI值;有研究者[14]使用小波變換同時提取信號的時域和頻域特征;針對室內(nèi)定位任務,有研究者采用引入多種策略的方式對CSI進行濾波并抑制誤差干擾,使用kNN算法進行分類[15],取得了良好的效果并替代了現(xiàn)有的方案;針對同樣的任務,文獻[16]提出可信載波的思想,通過對信號鏈路進行分析,使用相位特征實現(xiàn)室內(nèi)定位,理論上該思想同樣適用于步態(tài)識別;此外,有研究者使用多層神經(jīng)網(wǎng)絡進行特征的提取,這種方法更加復雜和耗時。總體來看,更多的研究者使用CSI子載波中的一部分而不是全部進行研究[17]。考慮到類似的網(wǎng)絡結構,著重從時域特征上研究識別方法,利用CSI的時域特性開發(fā)了一種快速的步態(tài)識別網(wǎng)絡。認真研究了幾種分類方法后發(fā)現(xiàn):由于在濾波之后不同人的數(shù)據(jù)不一定會表現(xiàn)出完全相似的特性,除了DTW算法得到的相似度之外,可以通過增加能夠選取的特征值的種類來有效降低識別錯誤的概率。
構建的無線傳感器網(wǎng)絡是通過無線局域網(wǎng)形成的一個封閉的系統(tǒng),intel 5300網(wǎng)卡用于采集局域網(wǎng)覆蓋區(qū)域中的信息,之后將信息發(fā)送給觀察者進行處理。局域網(wǎng)、用戶和觀察者構成了整個無線傳感器網(wǎng)絡,布置如圖1所示。

圖1 無線傳感器網(wǎng)絡
通過專用設備采集到CSI,使用3*3的MIMO,但只取出一個包里的一個值,對每個子載波而言,多個包的時間序列值就是一個CSI stream,在協(xié)助者開啟采集數(shù)據(jù)后,用戶以自然速度通過走廊,結束采集后協(xié)助者將數(shù)據(jù)發(fā)送給觀測者,并將數(shù)據(jù)分成測試數(shù)據(jù)集和模板數(shù)據(jù)集,模板數(shù)據(jù)集即樣本集,所有采集到的數(shù)據(jù)都要經(jīng)過預處理的過程,在預處理之后計算其表面特征值。
在啟動一個識別任務時,假定不知道樣本集里有多少種模板也不知道每個模板中有多少樣本,根據(jù)測試數(shù)據(jù)的特征使用類中心向量法對整個樣本集進行裁剪,再將測試數(shù)據(jù)與整個樣本集中的每一條數(shù)據(jù)進行DTW[18,19]擬合,這個一對一的過程被執(zhí)行許多次。將每一對匹配的特征值導入kNN算法進行選擇,決策方式為多數(shù)表決法,最后對結果進行判斷以確定這個匹配結果是可信的。這個流程混合使用了DTW算法和kNN算法并且加入了策略,我們將這一流程稱為DT-kNN。
實驗的依據(jù)與特征值選取方案基于3條基礎:①一個人經(jīng)過同一條走廊的步態(tài)信息反映到CSI上的值不同,因為他多次行走的軌跡不完全一樣;②不同人經(jīng)過同一條走廊的步態(tài)信息反映到CSI上的值不同,這是由于不同的人身高、體重、姿勢等各方面的差異所導致的;③人類在同一條走廊上行走反映到CSI上的波形有相似的變化規(guī)律。根據(jù)文獻中的考量,一條有效的CSI波形中的一個周期(從一個波峰、波谷到下一個波峰、波谷)時間內(nèi)可以看作人體移動的距離是固定的。
步態(tài)識別流程如圖2所示。
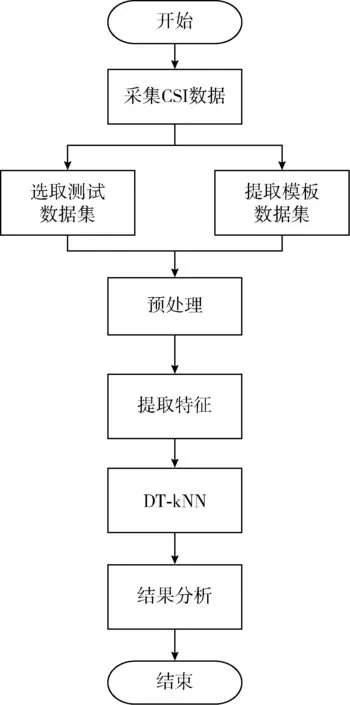
圖2 步態(tài)識別流程
研究最終選取以下5個特征作為提取的特征值:
(1)平均周期長度差:由于人的移動速度不一樣,經(jīng)相同路徑的時間也不同,它是人運動速率的一種表征;
(2)峰值差:如果能夠統(tǒng)一每個人運動的起始時間與結束時間,那么對應點的峰值可以看作每個人在特定點的一種表征;
(3)谷值差:同上;
(4)丟失率:這個特征值反映了測試數(shù)據(jù)與一個模板的差距。為測試數(shù)據(jù)模擬一條該模板的預測數(shù)據(jù),計算測試數(shù)據(jù)上每一個點與預測值之間的距離,距離大于該點平均絕對誤差(MAE)指標的點記為丟失,計算丟失數(shù)占全部數(shù)據(jù)的比率;
(5)DTW相似值:使用DTW算法計算模板與測試數(shù)據(jù)間的相似度并且給出兩條曲線的對應關系,該值越小則相似度越高。
所需要的5個特征值中的前3個特征值在預處理之后可以得到,在匹配階段計算另外兩個特征值。
具體的匹配的步驟如下:
(1)裁剪整個樣本集;
(2)使用DTW算法對測試數(shù)據(jù)與一個樣本集中的每一條數(shù)據(jù)分別進行擬合,這一步不僅可以輸出一對數(shù)據(jù)的整體相似度,還找到了兩條曲線之間點對點的對應關系;
(3)按照模板將樣本集中的數(shù)據(jù)歸類。對于每一個模板,根據(jù)第(2)步得到的對應關系,找到測試數(shù)據(jù)上一個點對應該模板所有數(shù)據(jù)上的對應點,對它們進行算數(shù)平均,作為該點的預測值,所有這些預測值組成一條新的預測數(shù)據(jù);
(4)使用同樣的方法,對于測試數(shù)據(jù)上的一個點,根據(jù)第(2)步得到的對應關系,取一個模板中每條數(shù)據(jù)上對應點的值計算該點的實際平均絕對誤差(MAE),該值反映了同一個人的步態(tài)測量誤差的真實情況,該值越低表明一個人的步態(tài)信息越穩(wěn)定,若該值較大,則表明環(huán)境因素的影響較為明顯,MAE指標計算公式如下
(3)
將測試數(shù)據(jù)與預測數(shù)據(jù)上對應點的值做絕對值運算,結果大于該點MAE指標的點記為丟失,統(tǒng)計丟失的值占總數(shù)的百分比,記為丟失率;
(5)將得到的特征值進行歸一化處理,將所有參數(shù)分別加權后使用kNN算法對結果進行篩選。
2 步態(tài)識別策略
使用3根發(fā)射天線3根接收天線,取出56個中的30個子載波,并使用了每個CSI子載波上的5個特征作為后期處理的參數(shù):平均一個周期的持續(xù)時間;峰/谷值差;丟失率;樣本數(shù)據(jù)與模板數(shù)據(jù)的DTW相似度。在提取特征前,每個給定的測試或模板數(shù)據(jù)都要經(jīng)過預處理。
2.1 預處理
由于實驗環(huán)境不可避免的會受到各種因素的干擾,我們無法得知干擾源產(chǎn)生的響應,因此,采用下面的方法對原始信號進行處理。
預處理部分由4個單元組成:收集原始無線信道指標;對數(shù)據(jù)進行濾波、去跳變、平滑處理并輸出新的數(shù)據(jù);截取一部分數(shù)據(jù)并輸出新數(shù)據(jù);提取表面特征值。在一段時間內(nèi)采集到的CSI數(shù)據(jù)中,可以將采集到的數(shù)據(jù)的每條子載波的幅度值獨立的提取出來。用戶平均需要步行10次才能收集可用的數(shù)據(jù),一次步態(tài)無線記錄動作持續(xù)時間為 10 s 到12 s,從一個環(huán)境中收集10個用戶的一共500次完整的步態(tài)數(shù)據(jù)大約需要8個小時。在采集足夠的數(shù)據(jù)后,我們進行去跳變,低通濾波與加權平滑處理優(yōu)化數(shù)據(jù),然后再提取圖像上可量化的原始信號數(shù)據(jù)的屬性:波峰值、周期均值、波谷值。
臨界頻率計算公式[20]
(4)
實驗用的設備可以采集到全部56個OFDM子載波中的30個,以1 KHZ的采樣速率采集大約10 s一個人的步態(tài)數(shù)據(jù),進行初步處理后的數(shù)據(jù)集在圖像上比原始數(shù)據(jù)集更加清晰,但仍然需要對其進行截取,目的是移除人類起步時加速度的影響,步驟如下:
(1)定義一個時間長度,該長度用來規(guī)范截取的連續(xù)時間長度,我們設定它為5,表示截取的時間長度為5 s;
(2)波形周期計算:計算輸入里產(chǎn)生每個峰值的周期并記錄;
(3)設置一個起始位置,經(jīng)過一段時間后人體將近似位于該點上,模板的起點以該點為準,考慮到人起步的速度較快,我們設定該位置為3,表示該點距離起點的距離為3 m,根據(jù)子載波波長將距離換算成時間;
(4)選擇5 s內(nèi)連續(xù)周期時間段里的值作為可用的輸出,記錄并提取平均周期長度,峰值,谷值,這些值代表了模板數(shù)據(jù)的統(tǒng)計特性。
流程如圖3所示。

圖3 數(shù)據(jù)截取流程
2.2 DTW(dynamic time warping)算法
當人的運動路徑相同時,被選擇的兩條時間序列的形狀相似,但由于人運動速率的不同,導致它們在橫軸上不對齊。在比較兩條序列的相似度之前,需要將其中一個(或者兩個)序列在時間軸下扭曲,使用DTW算法可以有效實現(xiàn)這種扭曲。
使用DTW的目的有二:其一是它本身可以輸出兩個數(shù)據(jù)集的相似度,為后面的結果判定提供一個有力的證據(jù),其二是為了找到測試數(shù)據(jù)與模板數(shù)據(jù)的一一對應關系。設測試數(shù)據(jù)為M,對比樣本為N,測試數(shù)據(jù)長度為m,樣本長度為n建立m*n的矩陣l,約束可以用下面條件表示:
(1)即l1=(1, 1) 和le=(m,n), 1≤e≤(m+n)。 這限定了所選擇路徑的起點和終點。
(2)對于所選擇路徑上的任意點有l(wèi)k-1=(a’, b’), 2≤k≤e-1, 則該路徑的下一點lk=(a, b) 滿足條件a-a’≤1, b-b’≤1。 即某點只能與相鄰點對齊。
(3)對于路徑上的任一點lk-1=(a’, b’), 則下個點lk=(a,b) 滿足0≤a-a’ 和0≤b-b’。 這保證了所選路徑的單調(diào)性。
條件(2)、(3)由于保證了格點的單調(diào)性約束和連續(xù)性約束,路徑上點(i,j)的下一跳有(i+1,j),(i,j+1)或者(i+1,j+1)這3種選擇。
規(guī)整代價最小的路徑可以由如下公式來表示
(5)
分母中的k主要是用來對不同的長度的規(guī)整路徑做補償。目的是找到使兩個時間模板距離度量最短時候的點對點對應關系,也就是最相似的那個卷曲,這個最短的距離也就是這兩個時間序列的距離度量。
自定義一個變量γ(i,j) 用于保存累計距離,從l上的起點(0,0)處匹配序列M和N,從(0,0)開始每到一個新的節(jié)點,累計前一節(jié)點的距離數(shù)值。到達終點(m,n)時γ(m,n) 即匹配曲線的相似度。把匹配的對應關系的數(shù)值寫到一個新的矩陣中,累積距離γ(i,j) 可以按下面的方式表示
γ(i,j)=l(i,j)+
min{γ(i-1,j-1),γ(i-1,j),γ(i,j-1)}
(6)
由已介紹方法得到兩條序列對應點的距離關系,使用回溯法找到使得沿路徑的積累距離達到最小值的路徑。由于在矩陣1中保存了兩條序列對應點間的距離,尋找特征點的對應點時,矩陣所經(jīng)過的路徑即是兩條序列對應的坐標。
2.3 DT-kNN算法
kNN算法的核心是通過對樣本周圍的k個樣本進行分類,選擇出現(xiàn)頻率最高的類別作為該樣本的類別。我們首先使用類中心向量的策略對該分類方法進行改進:前期對樣本集進行剪裁以降低算法的空間和時間開銷,在使用DTW進行匹配后,分類時對各種指標進行加權處理,k值在測試階段給出。
類中心向量策略設置如下:對特征值進行歸一化,根據(jù)測量信號與樣本的兩個特征(波峰值,波谷值)對樣本集進行剪裁,需要在測試階段給出兩個閾值p、q的值,這兩個值用于裁剪整個樣本集。裁剪的思路和p、q的取值思路如下:測量信號的平均波峰值與樣本的平均波峰值做絕對值運算,用測量信號的平均波谷值與樣本的平均波谷值做絕對值運算,當平均波峰值差與樣本峰值的比大于p或者平均波谷值差與樣本信號谷值的比大于q時,直接將該樣本從樣本集中刪除,本文在測試階段給出p和q的合理默認值。
我們的目的是通過使用這一策略使樣本集縮減約50%,在有效減少了后期DTW的計算成本的情況下,kNN算法的性能降低可以忽略不計。在本文中縮減樣本集降低了DTW算法的計算量,DTW算法的結果則會作為kNN算法的參數(shù),我們將這一些步驟融合為DT-kNN算法。
由于kNN算法總是能得到一個確定的類別,在分類結束之后,我們還需要對每一項指標進行綜合判斷,以確定該數(shù)據(jù)是否不屬于任何模板,方法步驟如下:
設定兩個閾值x和y,這兩個參數(shù)值用于否定匹配結果,這兩個參數(shù)的值在實驗的測試階段給出,x、y的取值思路參考以下兩個特征值:平均周期長度和DTW相似度。如果測試數(shù)據(jù)與模板數(shù)據(jù)的特征值差異過大,則這兩個數(shù)據(jù)的類型不匹配,我們將兩個數(shù)據(jù)間相同類型的特征值相除,用大的值除以小的值,得到平均周期差異a,DTW相似度差異b;當a的值大于x或者b的值大于y時,我們認為兩個數(shù)據(jù)間的差異過大了,因此判定兩個數(shù)據(jù)不屬于同一類型,經(jīng)過這一步被判否的數(shù)據(jù)被認為沒有已知模板與之匹配。如果將參數(shù)x或y的值設定得過小,則許多正常的數(shù)據(jù)容易被判定為假;如果參數(shù)x或y的值設定得過大,則許多異常的數(shù)據(jù)容易被判定為真。在測試階段給出x和y的合理的默認值。
DT-kNN算法設置如下,結構如圖4所示:
(1)使用類中心向量策略裁剪樣本集;
(2)對測試數(shù)據(jù)與樣本集中的數(shù)據(jù)使用DTW算法;
(3)為所有歸一化后的屬性值加權,默認值為:平均周期長度差:0.3,峰值差:0.1,谷值差:0.1,DTW相似值:0.4,丟失率:0.1;
(4)單獨計算待測試數(shù)據(jù)與各個樣本之間的距離并依照距離數(shù)值的大小排序;
(5)根據(jù)之前的排序選取距離最小的k個樣本,取這些樣本中相同類型最多的模板類型作為預測結果,進行最終判定。
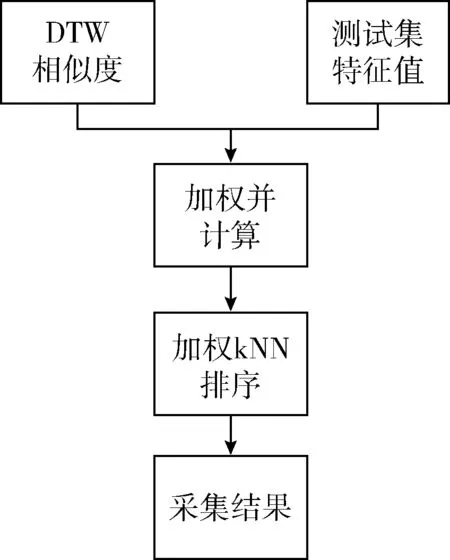
圖4 DT-kNN算法流程
找到測試數(shù)據(jù)與模板數(shù)據(jù)的對應關系后,任務為尋找測試數(shù)據(jù)集中的每一個特征值與所有模板數(shù)據(jù)集中的對應特征值的距離,使用曼哈頓距離作為距離度量的方式
(7)
2.4 與已有方法的理論分析
我們認真研究了幾種常用的步態(tài)識別策略,分析了本系統(tǒng),CSI-SRC系統(tǒng),LBR系統(tǒng)在本實驗環(huán)境下的時間空間復雜度,并進行了對比,計算過程如下:
本系統(tǒng)所使用DT-kNN的算法中,待測數(shù)據(jù)長度為m,單次匹配數(shù)據(jù)的長度為n,樣本集大小為u,特征維數(shù)為v,s為子載波數(shù)。
DTW算法的時間復雜度為m+(n-1)+(n-1)*(m-1)+n*m+n*m=O(3*n*m)=O(m*n), 空間復雜度為O(m*n), kNN算法的時間復雜度為O(u),由于兩個算法是相對獨立的,且u為定值,DT-kNN算法總時間復雜度為O(m*n) 總空間復雜度為O(m*n); SRC系統(tǒng)需要考慮稀疏矩陣的約束條件,對于m*n的矩陣,要將其變換到滿足約束條件,需要進行n*logm2次操作,時間復雜度為O(1*n*logm2), 空間復雜度為O(m*n); LBR算法時間復雜度為O(s*(m+m*n)), 由于s為定值,時間復雜度為O(m*n), 空間復雜度為O(m); 見表1。
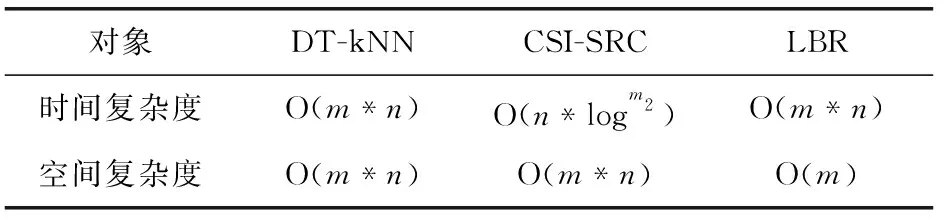
表1 時空復雜度對比
SRC與DT-kNN都主要使用了時域屬性作為識別依據(jù),在預處理部分SRC使用插值處理的方案,這種方案成本更低;在預處理部分,LBR使用了小波變換以取得頻域屬性,在隨機匹配方面DT-kNN在數(shù)據(jù)分析方面不會因為少量誤差而導致判斷錯誤,這是LBR所不具備的。本系統(tǒng)的時間復雜度與LBR接近,由于現(xiàn)在系統(tǒng)一般運行在云服務器上,空間成本可以忽略,本系統(tǒng)選擇犧牲了少量時間成本以換取更高的準確度。
3 實驗與分析
基于DT-kNN算法對人類步態(tài)進行識別,對參數(shù)進行調(diào)節(jié)測試識別效果,更換實驗環(huán)境測試系統(tǒng)的可移植性,以識別率作為主要指標對3種系統(tǒng)進行評價。
3.1 測 試
數(shù)據(jù)集是在實驗室走廊里收集的30名用戶的步態(tài)信息,每個用戶以正常速度在走廊往一個方向上通過發(fā)射器和接收器30次,共收集了900個數(shù)據(jù)包,每個數(shù)據(jù)里有30條子載波,我們選擇其中兩條子載波進行驗證,每個子載波被接收了9(3*3) 次。受試者有不同的身高、體重和體型。
在實驗期間,識別率即正確分類的概率作為主要的度量方式,實驗的主要結果分為兩部分:改變實驗條件后對本文方法的評估、使用其它方法替代本文分類方法后的效果評估。
我們需要確定4個閾值p,q,x和y的大小,并且確認同一個人的數(shù)據(jù)屬性是否穩(wěn)定,不同人的數(shù)據(jù)差異是否明顯。我們測試了5個不同的人,每個人作為一個對象,分為對象1,對象2,對象3,對象4和對象5,對象欄表示第幾個對象與第幾個對象進行對比,我們將一個人的一組數(shù)據(jù)與5個人(包括自己)的數(shù)據(jù)分別進行5次匹配并取平均,歸一化后的結果見表2。

表2 對比匹配
平均周期差反映了人的步行速度,而DTW匹配值則對整個步行過程進行了圖形評價,這些指標能夠被普遍的從每一對匹配的數(shù)據(jù)中提取,從表2中可以看出,為同一個人進行比對的各項指標普遍維持在較低的水平,而不同的人進行比對的各項指標的差別則相對較大,因此我們選擇的特征值是有效的。
我們發(fā)現(xiàn),不同的人進行匹配得到的平均周期差與DTW相似值都較大,均峰值差與均谷值差則不太明顯。對數(shù)據(jù)特征進行分析,選定閾值p和q使得通過類中心向量法裁剪的樣本大約為樣本集的一半;選定閾值x和y使得錯誤判定被有效地篩選出來的同時正確的判定不受影響,對這5組數(shù)據(jù)的原始測量值進行計算,經(jīng)過測試,我們選定合理的參數(shù)值,閾值參數(shù)p為0.13,q為0.16,x為1.37,參數(shù)y為2.04,kNN中k的取值為7;
3.2 實驗結果分析
實驗分為4個部分:
(1)識別成功率隨著標記模板、模板數(shù)據(jù)集數(shù)量的變化;
(2)為實驗一改變DT-kNN方法里特征值的權重;
(3)將實驗環(huán)境換至無人的房間內(nèi),其它參數(shù)不變的情況下進行第一個實驗;
(4)使用本文方法,與SRC或LBR的對比評估。
算法中初始默認權重值如下:平均周期差0.4,均峰值差0.1,均谷值差0.1,DTW相似度0.3,丟失率0.1。
3.2.1 識別成功率隨著標記模板數(shù)量的改變與樣本集的變化實驗
測試集選取6個模板中的數(shù)據(jù);每個樣本集選取10個模板,每個模板選取5條樣本。保持測試集不變,當每個模板中的樣本數(shù)量逐漸增加到20個時,測量識別率的變化;保持測試集不變,增加樣本集中模板的個數(shù)到16個,測量識別率的變化。結果如圖5所示。
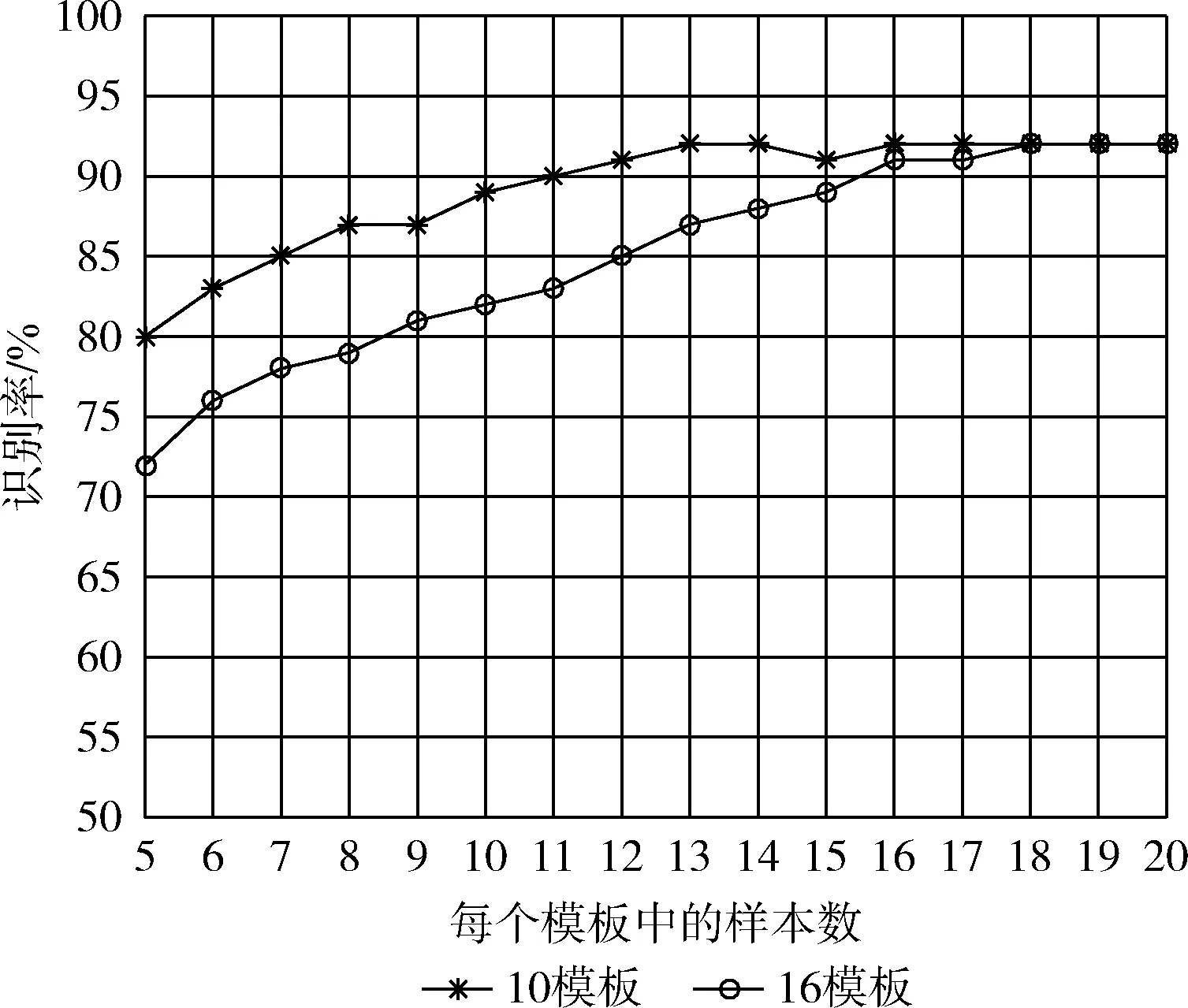
圖5 無干擾模板數(shù)量/樣本數(shù)量變化
當模板中數(shù)據(jù)個數(shù)較少時,識別率較低;增加從環(huán)境收集的模板數(shù)據(jù)數(shù)量可以持續(xù)改善識別率;兩種情況的識別率都將收斂于一個穩(wěn)定值,且當模板數(shù)量較少且模板數(shù)據(jù)數(shù)量較多時識別率收斂的速度更快,識別效果更好。
造成這種結果的原因是:在算法不能持續(xù)改善的情況下,大量增加模板數(shù)量降低了不同模板之間的差異性,伴隨著模板數(shù)據(jù)數(shù)量的增加,每個模板的特性變得更加穩(wěn)定,差異性也更加清晰的顯現(xiàn)出來了。因此,模板數(shù)據(jù)較少時識別率低,當模板數(shù)據(jù)數(shù)量增加到一定值,識別率將不再提升。
3.2.2 改變DT-kNN方法里特征值的權重效果實驗
設置如下:每組的測試集選取3個模板中的數(shù)據(jù)。樣本集選取10個模板,其中包含當前測試數(shù)據(jù)所屬于的模板,每個模板選取5條樣本數(shù)據(jù)。改變參數(shù)的權重測量識別率的變化,見表3。
設置不同權值會對識別率產(chǎn)生較大的影響丟失率對識別率的影響因素較大,平均周期長度和DTW相似度的權重增加也會有效增加識別率,這與預測是一致的。
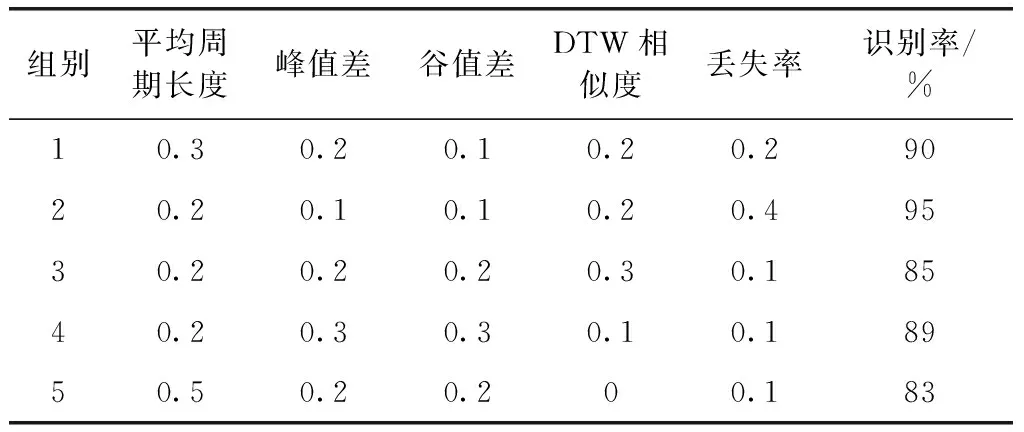
表3 改進型kNN算法中不同權重對識別率的影響
3.2.3 將實驗環(huán)境換至無人的房間內(nèi),其它參數(shù)不變的情況下進行第一個實驗
采用同樣的方法在不同環(huán)境下進行的實驗,結果如圖6所示,與3.2.1的實驗結果相比,識別率下降了,提高模板內(nèi)數(shù)據(jù)的數(shù)量仍然有效提高了識別率,這意味著我們構建的系統(tǒng)理論上是可移植的,但需要重新定義特征值的選取方法以適應新環(huán)境。
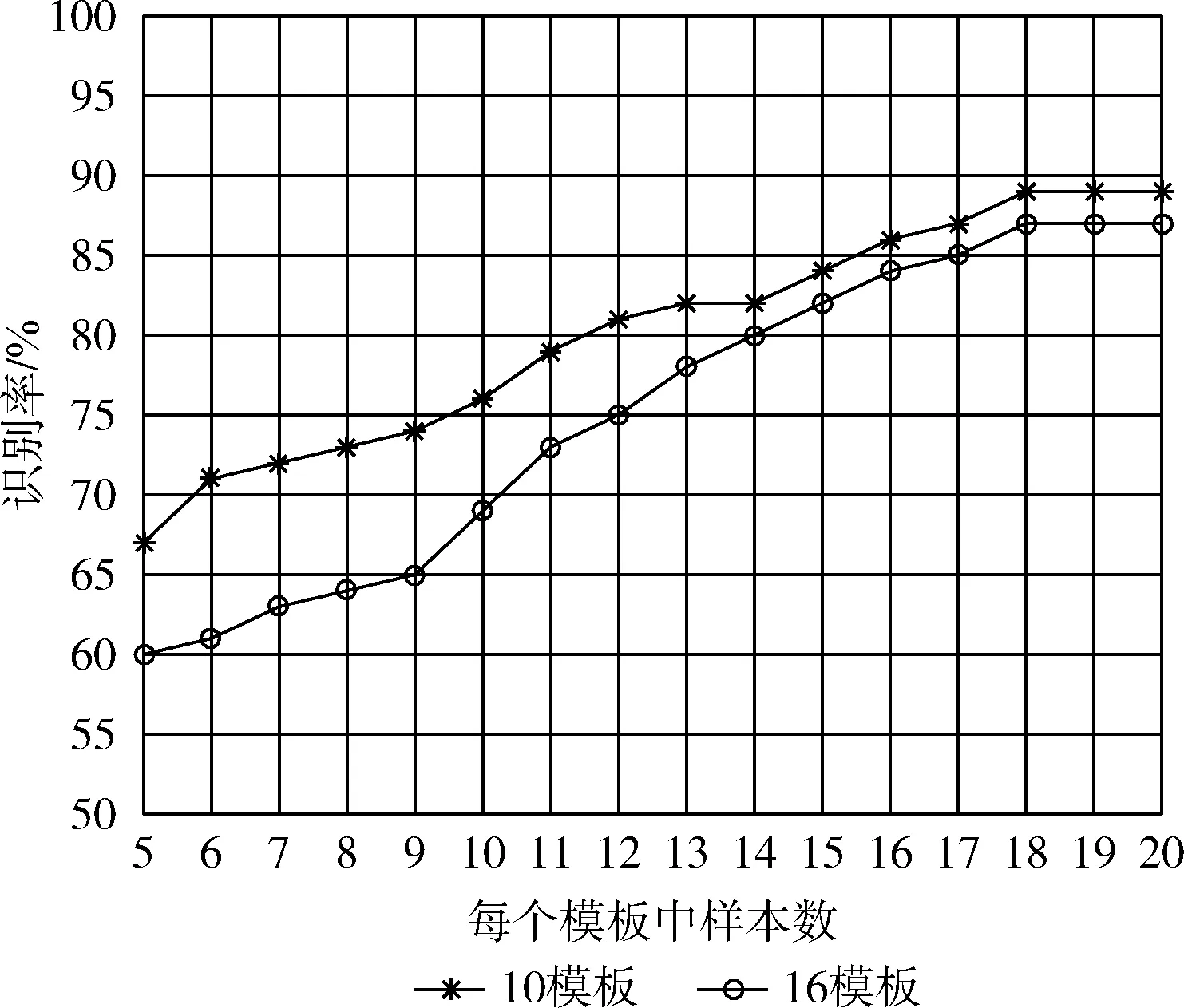
圖6 室內(nèi)無干擾模板數(shù)量/數(shù)據(jù)集數(shù)量變化
3.2.4 使用本文方法,與SRC或者LBR的對比評估
進一步評估該系統(tǒng)的性能,采用了另外兩種分類方法SRC或LBR替換DT-kNN進行分類,在相同環(huán)境下復現(xiàn)不同方法,識別率對比如圖7所示,設置了幾種不同的實驗環(huán)境,一個人在待測環(huán)境5 m外正常走動標記為輕度干擾,一個人在待測環(huán)境3 m內(nèi)正常走動標記為重度干擾,每個字母代表的含義如下:A走廊無干擾,B走廊輕度干擾,C走廊重度干擾,D實驗室無干擾,E實驗室內(nèi)輕度干擾。采用16個模板,每個模板中有15個樣本。
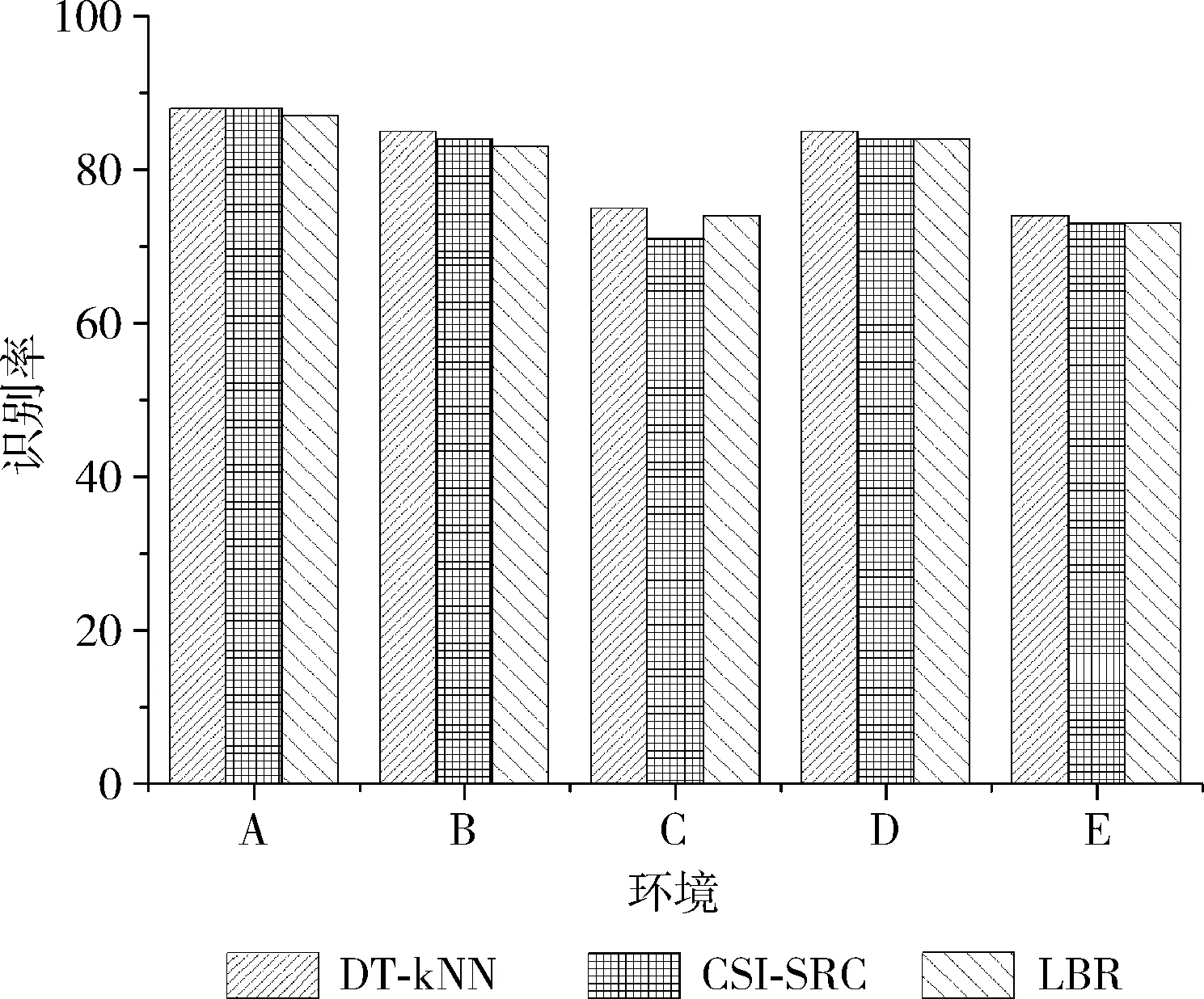
圖7 3種方法識別率對比
無論實驗環(huán)境在室內(nèi)還是在走廊,采用DT-kNN的識別率都高于另外3種,偶爾持平,這驗證了所選擇的數(shù)據(jù)截取方案和特征值選取方案的有效性。
4 結束語
本文提出了一種低成本可移植步態(tài)識別系統(tǒng),對采集到的信息公平的使用可靠的數(shù)據(jù)處理方法抽取出不同數(shù)據(jù)具有的特征,使用改進后的kNN算法降低了計算成本。在所有實驗中,我們確保訓練和測試數(shù)據(jù)集不同。現(xiàn)有方法給出正確結果的概率達到92%。隨著模板數(shù)據(jù)樣本數(shù)量的增加,識別率得到有效提高。結果表明,該系統(tǒng)可以在小規(guī)模環(huán)境下有效對人類步態(tài)進行分類,與文獻[12-14]中已經(jīng)提出的方法相比,在模板人數(shù)較少時,方法的識別率與之區(qū)別不大,當提高模板的數(shù)量后,方法的性能下降約為9.6%,比其它方法更優(yōu)。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
