基于多源域遷移學習的腦電情感識別
2020-07-20 06:16:10婁曉光陳蘭嵐宋振振
計算機工程與設計 2020年7期
婁曉光,陳蘭嵐,宋振振
(華東理工大學 信息科學與工程學院 化工過程先進控制和優化技術教育部重點實驗室,上海 200237)
0 引 言
情感智能[1]是人與人之間交流過程中不可或缺的一部分,情感狀態識別是情感研究工作中的核心內容。相較于其它方法,腦電信號靈敏度較高,能夠無視被試的情感偽裝,能直接反映與情感變化相關的大腦內在狀態,因此越來越受到研究者的青睞。Li Mi等[2]提取腦電5個頻帶的能量信息作為特征,計算不同頻帶下導聯與情感的相關性,分析得出與情感狀態強相關的腦區與頻帶。
傳統的機器學習中要求訓練數據和測試數據必須服從獨立同分布的約束條件,然而腦電信號存在很強的個體差異性,不同被試即使表達相同情感對應產生的腦電特征也不盡相同,而遷移學習放寬了訓練數據和測試數據服從獨立同分布的限制[3],所以利用遷移學習可將從先前被試身上學到的知識或模式應用到另一個新被試上,挖掘出源域被試和目標被試間共享的信息,最終構建適應目標被試數據分布的模型。
對于單源域遷移學習,如果領域間的相關性較低,直接遷移可能會產生負遷移現象[4],并且在進行跨被試情感識別時往往存在多個源域被試數據,因此可以利用多源域遷移學習來彌補單源域遷移學習的不足。目前鮮有文獻從樣本和特征兩個層面對待遷移的多源域數據進行優化的報道,本文提出用多源域選擇(multi-source domain selection,MDS)與遷移特征選擇(transfer feature selection,TFS)相結合的方式得到適宜遷移的數據,在此基礎上利用基于適配正則化線性回歸的遷移學習算法[5](adaptation regularization regularized least squares,ARRLS)對跨被試的情感數據進行建模。
1 情感識別總體框架
針對多源域遷移學習問題,一種做法是將所有源域合并為一個大源域,另一種做法是將每個源域單獨考慮,訓練多個子模型并將之集成。前者忽略了不同源域間的差異性導致建立的模型性能較差,后者需要建立多個遷移模型,往往計算時間過長,且其中存在與目標域相似度較低的源域個體,其模型在集成過程中會影響總體的識別精度。因此多源域數據的優化選擇及集成學習是一個值得研究的問題。Liu等[6]在全局層面將不同域視為一個整體并縮小源域與目標域間的差異,在局部層面分析不同域間的關系以最大化分類性能。K Vogt等[7]對多個源域賦予不同權重,使模型合理利用源域間的信息,以促進目標域的學習。
本文構建的情感識別模型如圖1所示。首先對原始信號濾波并提取差分熵特征[8],其次利用MDS-TFS-ARRLS算法構建情感識別模型。該模型的構建分為4個步驟,前兩步主要解決“什么樣的知識適合于遷移”的問題,即對待遷移的多源域數據進行優化;后兩步主要解決“知識如何遷移”的問題,即采用合適的遷移學習及集成學習算法。第一步利用多源域選擇算法(MDS)全面度量目標域與其對應的各個源域的相似性大小,從多個源域中過濾掉可能會導致負遷移現象的部分源域,保留最優的源域集合,降低僅用單一源域數據進行遷移帶來的風險,同時節約計算成本;第二步利用遷移特征選擇算法(TFS)從多個源域中尋找共同有效的特征子集,增強特征推廣性,從而使數據具有更好的遷移能力;第三步利用適配正則化線性回歸算法(ARRLS)構建多個遷移學習模型,最后根據每個模型所對應的源域與目標域間的相似性大小分別賦予其不同權重建立集成遷移學習模型。
下面對MDS-TFS-ARRLS算法中各個環節分別進行介紹。

圖1 情感識別模型總體框架
2 算法介紹
2.1 多源域選擇算法(MDS)
本文提出了一種多源域選擇算法(multi-source domain selection,MDS),該算法目的在于通過領域間相似性的度量,從多個源域中篩選出與目標域較為相似的源域集合。考慮到僅從域-域層面度量相似性具有片面性,因此該算法又從樣本-域層面度量相似性大小。MDS算法首先計算域-域和樣本-域兩個層面的相似性,然后將這兩個層面的相似性值組成源域和目標域的聯合相似度矩陣,并使用K-means算法對聯合相似度進行聚類,自適應選取最優源域集合。其中,域-域相似性是基于領域間整體均值的差異,樣本-域相似性是基于所有目標域樣本到源域的距離之和。MDS算法的計算過程如圖2所示,下面分別對相似性的計算和最優源域集合的選取做出介紹。
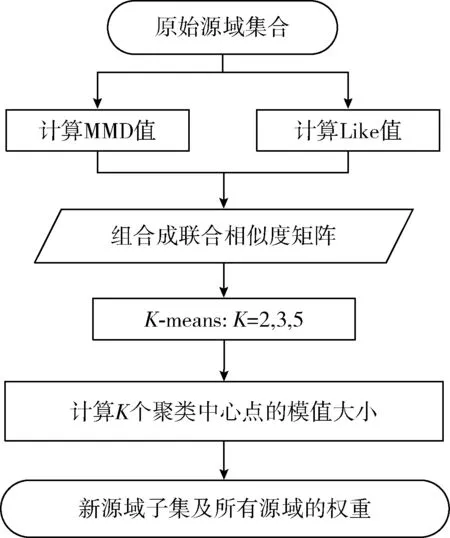
圖2 MDS算法流程
2.1.1 域-域相似性計算
領域間整體數據差異在于兩者概率分布的不同導致數據分布的不同,常用的概率分布距離度量函數有相對熵[9]、布雷格曼散度[10]和最大均值差異(maximum mean discre-pancy,MMD)[11]。前兩種方法計算通常需要估計其分布密度,而最大均值差異可以用不同領域在無限維核空間中的均值差異來近似,計算相對簡單且效率高,因此該方法的使用最為廣泛。本文采用MMD將源域和目標域數據嵌入到共享的可再生希爾伯特空間中,在該空間中兩者間的均值差異代表相似度大小。MMD計算值越大代表領域間相似性越大。
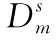
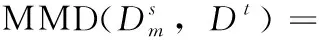
(1)
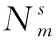
(2)
其中,Ki,j=〈φ(xi),φ(xj)〉, 本文中采用線性核。L矩陣可由式(3)求得
(3)
2.1.2 樣本-域相似性計算
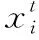
(4)

(5)
2.1.3 聯合相似性度量及聚類
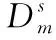
(6)
本文利用K-means算法對相似度特征聚類,并將聚類數K取為2、3、5來分別確定其不同大小的最優源域集合。并進一步根據相似度向量的模值大小計算最優源域集合中每個源域的權重ωm。ωm計算公式如下
(7)
2.2 遷移特征選擇算法(TFS)
為了進一步降低后續遷移學習的計算成本、提高識別精度,本文使用遷移特征選擇算法篩選出適宜遷移的特征子集,該算法由兩個階段組成,其計算流程如圖3所示。
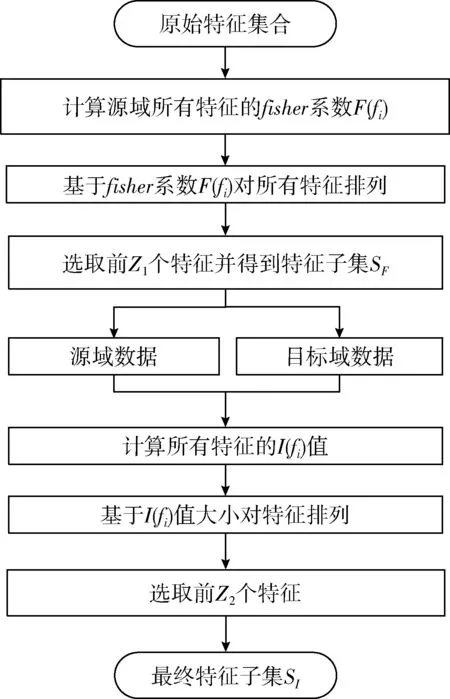
圖3 TFS算法流程
首先計算源域中每個特征對應的Fisher Score[13]值,Fisher Score屬于過濾型特征選擇算法,具有計算速度快適用性強的優點。該算法通過度量樣本中類間散度與類內散度的關系,判斷特征與類別標簽間的相關性。本文根據Fisher Score準則選取具有鑒別力的特征集合。Fisher Score的計算公式如下
(8)
其中,C為樣本類別數,特征fi的平均值為μi,nj為第j類樣本個數,μij和σij為第j類樣本特征fi的平均值與標準差。
遷移特征選擇算法第二部分通過衡量特征與域標簽之間的相關性來選取源域與目標域之間更具一致性的特征。通常特征選擇利用互信息來定義特征與類別標簽間的相關性[14],本文通過互信息來衡量特征與域標簽之間的相關性,源域數據標簽為S,目標域數據標簽為T。常用的相關性度量方法有Pearson相關系數和Spearman相關系數,但上述兩種方法只能度量變量間的線性關系,而互信息可以衡量非線性關系,并且對噪聲信號具有很好的魯棒性。此外,Pearson和Spearman相關系數的計算要求源域和目標域樣本具有相同的實驗采集順序,而利用互信息沒有該限制。互信息值越大代表兩組變量越相關,因此互信息值I(fi) 越小代表特征fi與域標簽間的相關性越小,則在該特征表示下,領域間的差異較小。樣本x, y的概率密度與聯合概率密度計算互信息
(9)
圖4為利用互信息計算特征與域標簽相關性示意圖,根據每個特征互信息的值對其排序,選取相關性較小的部分特征組成最終特征集合,該特征集合不僅具有良好的可分性,且能夠更好地反映出源域與目標域數據間的共享信息。
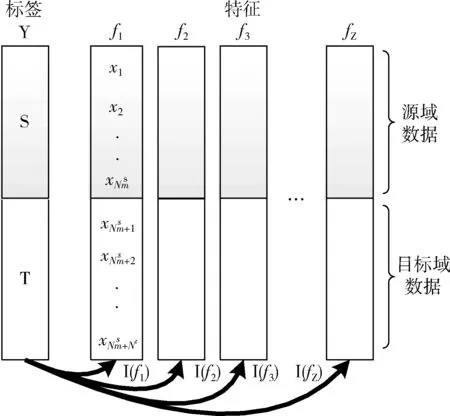
圖4 特征與域標簽相關性計算
2.3 適配正則化線性回歸算法(ARRLS)
遷移學習根據遷移的方式不同可分為:基于實例遷移、基于特征遷移、基于參數遷移和基于相關知識遷移。本文采用一種基于特征的遷移學習——適配正則化線性回歸算法(ARRLS)[5],該算法同步優化結構風險泛函、聯合分布距離、流形不一致性等學習準則[4],同時能夠縮小領域間的數據結構差異。其學習框架如式(10)所示
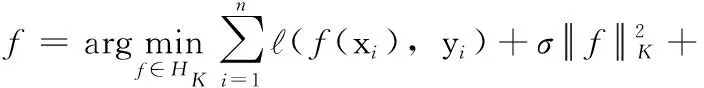
(10)
3 實驗及結果分析
3.1 實驗數據
實驗環境:Intel(R) Core(TM) i7-8750H CPU @2.20 GHz,8 G內存,64位Windows10系統,算法的實現采用64位MATLAB R2016b。
本文以公開數據集SEED(SJTU Emotion EEG dataset)作為研究對象。根據國際10-20系統,使用62個通道的ESI-NeuroScan系統記錄腦電信號,采樣頻率為1000 Hz。該數據集了記錄了15名被試(包括7名男性8名女性)觀看不同類型視頻片段所采集的腦電數據。每名被試參加3次實驗,時間間隔約為1周,共得到45組測試數據。被試觀看的視頻片段共分為3個不同情感類別,分別為Positive,Neutral,Negative[15],每次實驗過程中視頻開始前有一個5 s提示,表示視頻的開始,視頻結束后會有45 s的自我評估,最后有15 s的休息時間,觀看時長約為4 min。
本文取每名被試第1次實驗所得的15組實驗數據作為分析使用。將初始腦電信號降采樣至200 Hz,并將每1 s的實驗數據作為一個樣本,最終每名被試數據可得到3394個樣本。在5個頻帶上(delta:1 Hz-3 Hz, theta:4 Hz-7 Hz, alpha:8 Hz-13 Hz, beta:14 Hz-30 Hz, gamma:31 Hz-50 Hz)分別提取腦電信號的差分熵特征[11],因此,每個樣本共有5×62(頻帶×導聯)=310維特征。其中差分熵的計算公式如下所示
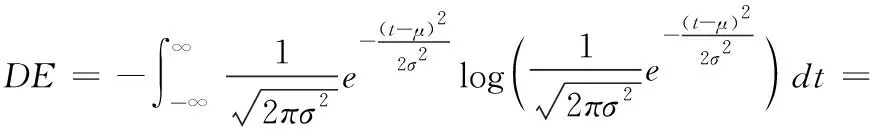
(11)
其中,t表示來自EEG信號的子帶信號,設該信號服從高斯分布N(μ,σ2)。 文獻[16]中證明原始觀測信號經過帶通濾波后,其子帶信號的時間序列大致遵循高斯分布。
3.2 ARRLS算法性能分析
由于源域與目標域數據分布不同,如果直接從源域中劃分出數據作為驗證集確定算法的參數,通常會導致較差的測試集實驗結果[10]。因此本文在一定范圍內進行了參數搜索,展示和對比了每種算法的最佳結果。這里SVM采用Lin開發的工具包LIBSVM[18],其懲罰參數c在{2-5~25}內搜索最優結果,最終本文設置c=4。 TCA算法中γ,λ在{2-5~25}內分別搜索最優結果確定γ=1,λ=1。 ARRLS算法中參數采用基于分層網格搜索的優化方法。首先將λ,γ參數在{2-5~25}內搜索分別設置λ=1,γ=1, 其次將σ在 {0.001,0.01,0.1,0,1,10} 內搜索后確定σ=0.1, 迭代次數設置為5。
表1中比較了ARRLS、SVM和TCA這3種算法的平均識別精度,圖5則更為詳細地展示了這3種算法的個體識別精度。從表1中可以看出,ARRLS在兩種核函數下均具有最優的平均實驗結果,且遷移學習算法在跨被試實驗中實驗結果強于SVM分類器。從圖5中可看出ARRLS算法在大多數個體上具有出色的識別精度。綜合分析上述實驗結果,由于SVM分類器算法僅利用訓練集數據構建模型,而該模型并不能適配于測試集數據分布,因此難以取得理想實驗結果。TCA算法雖然將數據投影到核空間中減少不同被試間邊緣分布差異,但未能考慮到被試間條件分布也存在差異,并且未能同時優化損失函數與流形正則化,從而導致結果仍然不理想。ARRLS同時最小化損失函數、聯合概率分布函數、流形正則化,因此ARRLS方法在平均和個體識別結果上均表現良好且更穩定。但從表1中可以看出ARRLS算法雖然識別精度高,但存在計算時間過長的問題。
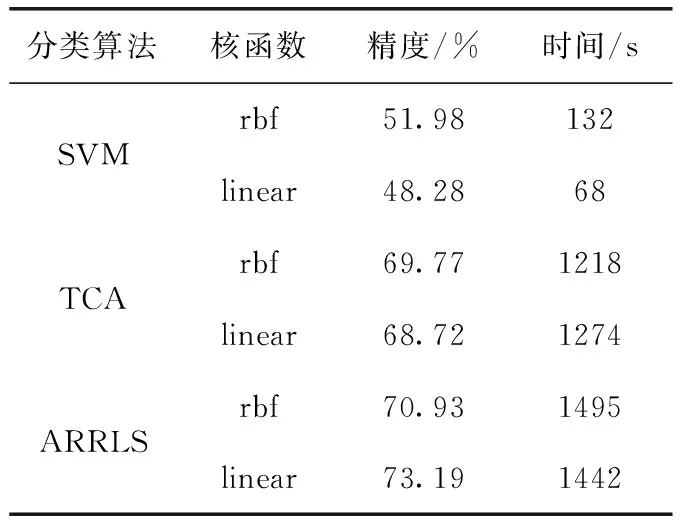
表1 不同分類算法的情感識別結果

圖5 單個個體識別準確率
此外,通過圖6可以看出同一目標域對應的不同源域在使用ARRLS算法時分類結果相差較大。圖5中分別選取被試1,2作為目標域。當被試1作為目標域時,被試2,3,12作為源域時識別精度較低。當被試2作為目標域時,被試3,12作為源域時識別精度較低。當存在部分識別率較低的源域被試時,若直接對所有源域的識別結果投票將會導致最終模型識別率變低。針對上述存在的兩個不足,本文進一步提出結合樣本選擇和特征選擇的多源域遷移學習算法。
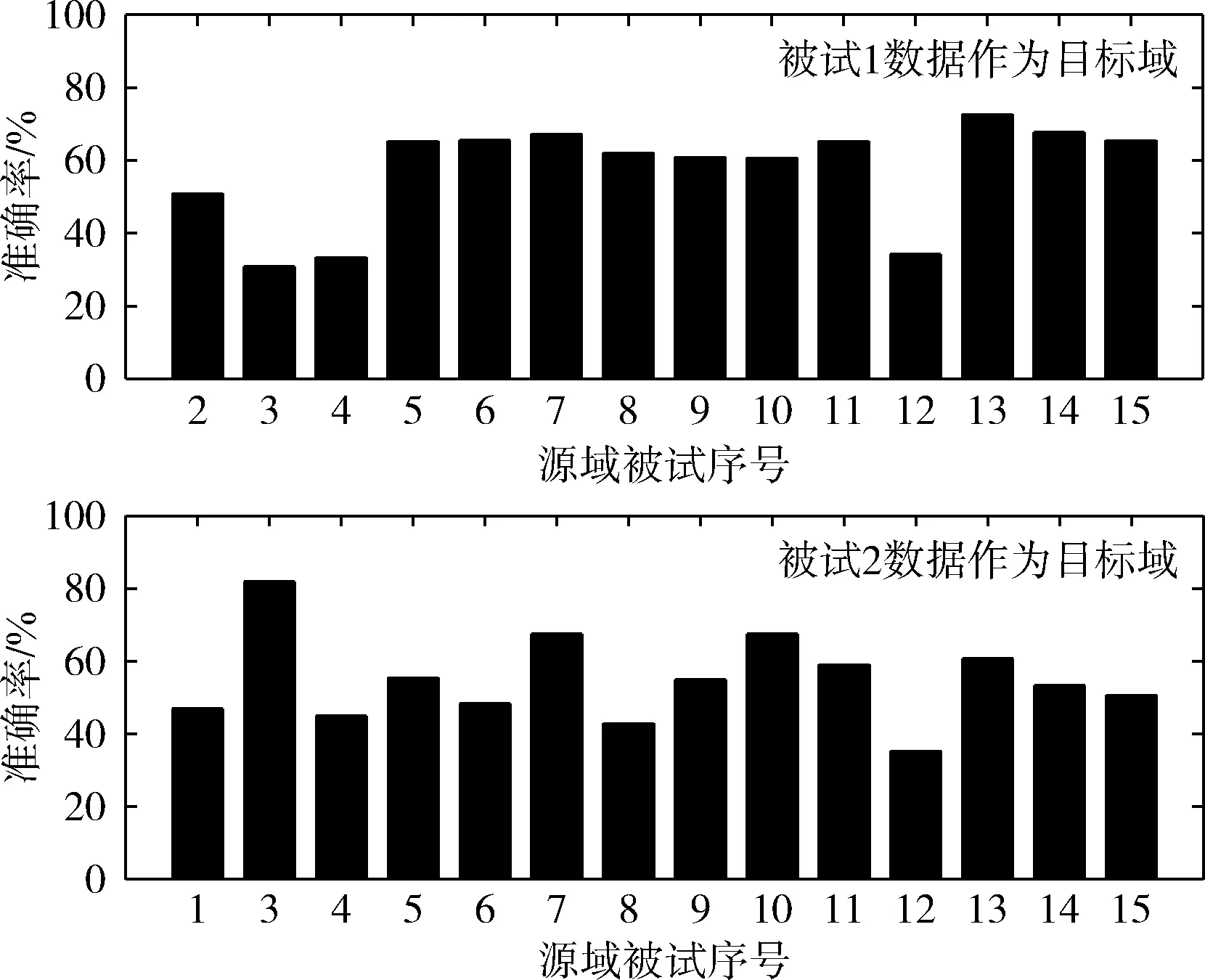
圖6 被試1,2作為目標域時不同源域的分類結果
3.3 MDS算法性能分析
為了提升識別效率同時提升模型性能,本文通過MDS算法衡量出源域與目標域間相似性的大小,保留具有良好遷移能力的源域。圖7是一名被試作為目標域,在K=2,3,5時14個源域被試根據相似性大小進行聚類的示意圖。
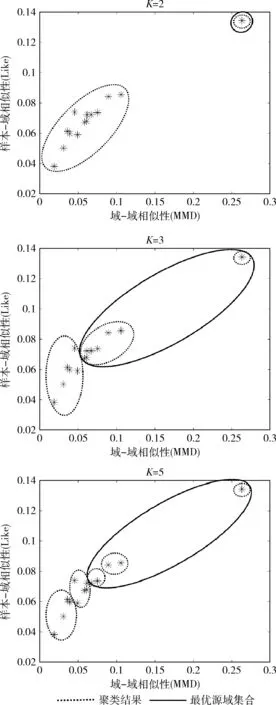
圖7 MDS算法實驗結果
被試間相似度大小可以由圖中每名被試的對應點到原點的距離直觀看出,距離原點越遠則相似性越高。從圖6中可以得出,不同源域被試與目標域被試間的MMD值和Like值差異較大。K-means算法根據聯合相似度的大小將原始源域集合聚類,不同的K值得到的聚類結果也不相同,本文選取距離零點距離較遠的集合作為最優子集來避免出現負遷移現象。當K=2時,保留形心模值較大的集合中所包含源域,此時聚類效果較為極端,所選取的最優源域集合僅包含1名被試數據。當K=3時,保留形心模值最大的2類包含的源域,此時最優源域集合有8名被試組成。當K=5時,保留形心模值最大的3類包含的源域,此時聚類結果適中,最優源域集共有5名被試數據集組成。
3.4 TFS算法性能分析
由于原始數據中存在部分與標簽無關且影響遷移效果的特征,因此本文采用TFS算法去除這些特征。TFS算法首先計算出所有特征權重值F(fi),并根據權重值對所有特征排序。式(12)為當維度為d時的特征權重占比率rate的計算公式,其中Z為特征總體維度,F(fi)為特征fi的Fisher Score大小
(12)
本文考慮到數據信息的完整性與計算成本控制,選取占比率為0.85時所對應的最優子集SF,特征維度d=100。對SF中的所有特征計算互信息I(fi)大小,并將由小到大排序,選取最終特征子集SI。圖8為Fisher Score與TFS算法在不同維度下的實驗結果圖。
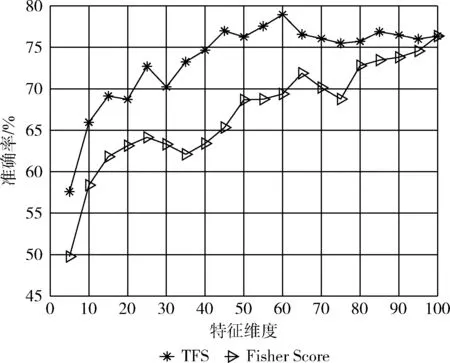
圖8 特征選擇實驗結果
從圖8中可以看出,利用Fisher Score與TFS算法實驗精度在初始階段會隨著所選特征數量的增加而提高,且TFS識別效果明顯優于Fisher Score,這說明TFS算法成功選出對遷移有效的特征并排在特征序列的前列。但TFS算法所選特征維度達到一定維度后,其精度逐漸開始下降,這說明隨著后續與域標簽強相關的特征加入集合中,源域與目標域間的差異性也隨之增加,影響遷移效果,從而降低識別精度。
3.5 MDS-TFS-ARRLS算法性能分析
為了最大限度提升計算效率和分類效果,本文將MDS、TFS和ARRLS算法相結合進行實驗,并將之與其它組合方式做出對比。ARRLS、TFS-ARRLS、MDS-ARRLS和MDS-TFS-ARRLS分別對應遷移學習,特征選擇+遷移學習,多源域選擇+遷移學習,多源域選擇+特征選擇+遷移學習4種情況,這4種方式在linear核情況下的實驗結果見表2。
從表2中可以看出,僅使用ARRLS算法可以得到73.19%的準確率,但所用的時間為1442 s,計算效率過低。TFS-ARRLS算法對所有源域進行特征選擇,在60維下分類,從表中可以看出由于去除冗余特征即降低特征維度,使計算時間在一定程度上有所減少,減至703 s,同時準確率也提高至78.96%。MDS-ARRLS算法為使用多源域選擇后再分類,隨著K值的不同對應的樣本保留率也不同。當K=2時,選取的樣本為原始的35%,所得準確率略微低于原始準確率。當K=3或5時,所選樣本數量相對增加,其對應的準確率都高于原始值,并且可以看出3種K值的計算時間都大幅縮減。MDS-TFS-ARRLS算法中,同時兼顧了特征選擇和樣本選擇兩個方面,進一步提升識別效率與識別率。當K=2時,雖然計算時間最短,但由于去除了過多樣本信息,相較于TFS-ARRLS,計算準確率降低了1.39%。K=3時,對應準確率為79.92%,相較于原始準確率提高6.73%,計算效率提高3.84倍。K=5時,兼顧了分類準確率和計算效率兩個方面,其分類準確率提高6.35%同時計算效率提高5.02倍。
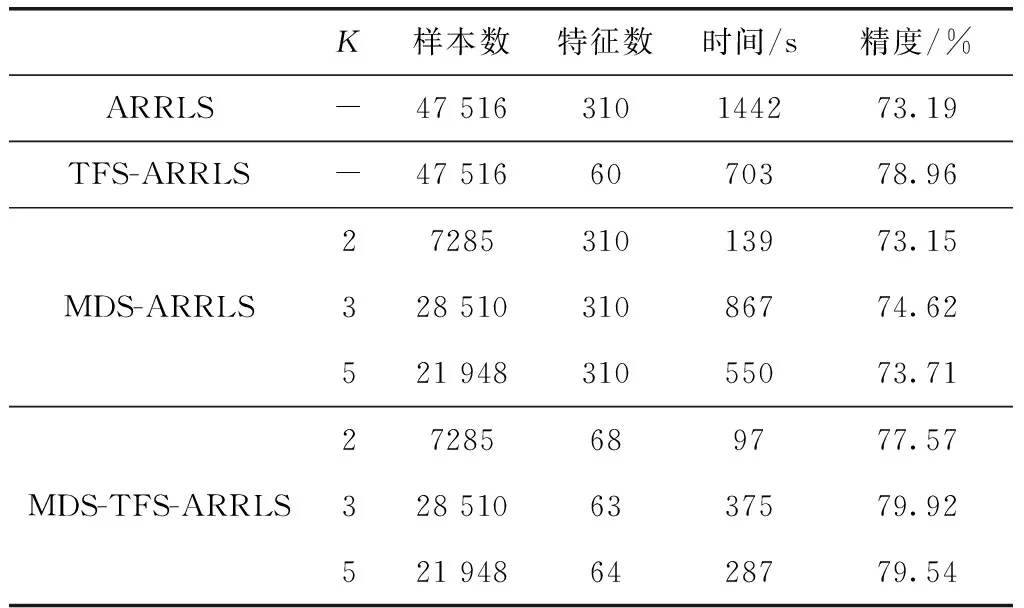
表2 4種遷移學習算法實驗結果
從表3中給出當K=3時,MDS-TFS-ARRLS在不同維度下的識別精度與計算時間的變化情況,當保留較多特征時,其計算精度相對較高,但其計算成本同時也隨之提高。在實際應用中可以根據實際所需選取合適的特征集合大小。
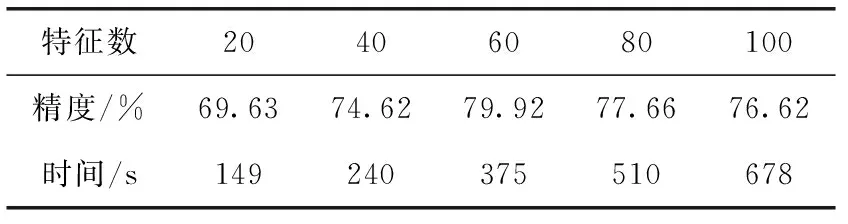
表3 MDS-TFS-ARRLS算法最終選取不同維度結果
綜合上述實驗結果,本文所提出的MDS-TFS-ARRLS算法可以有效提高計算效率且提高分類準確率。
3.6 同類結果對比
將本文提出的方法與同樣采用SEED數據集的其它方法的實驗結果作對比,見表4。文獻[19]使用深度信念網絡(deep belief network,DBN)選取最優電極組合,得到67.84%的分類精度;文獻[20]從腦電信號中提取18種線性和非線性腦電特征,并從中自動選取與情感最相關的特征信息,利用支持向量機達到83.33%的識別率。這兩篇同類研究分別利用深度學習和淺層機器學習算法建立模型,但都沒有應用遷移學習從本質上減小源域與目標域間數據分布差異。文獻[21]中采用辨別圖正則化極限學習機(GELM)來識別隨時間變化的穩定模式,該文研究同一個被試跨天情感識別,因此訓練集與測試集差異小于本文,最終分類精度為79.28%。文獻[22]使用最大獨立性領域自適應算法(maximum independence domain adaptation,MIDA),以差分熵作為特征取得72.31%的分類精度;文獻[23]使用TCA遷移學習方法,但訓練集設置為隨機取出的5000個樣本,通過將數據降至30維取得69.44%的精度。上述兩篇文獻雖然都采用了遷移學習算法,但相較于本文,并未考慮多源域選擇算法去除會引起負遷移的源域。
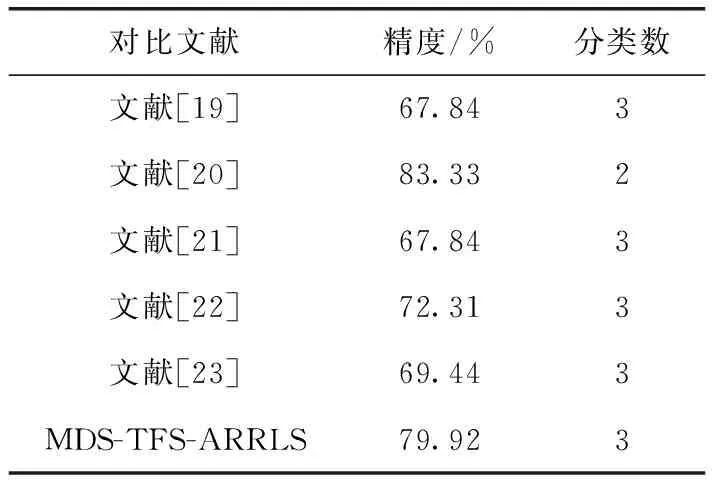
表4 同類研究對比
4 結束語
本文提出一種將多源域選擇(MDS)、遷移特征選擇(TFS)和適配正則化線性回歸(ARRLS)結合建立模型的方法,并將其應用到跨被試情感識別中。該模型考慮到目標域與源域間相關性,用多源域選擇來合理選擇樣本信息;其次考慮到特征自身與類別標簽和域標簽間的相關性,使用遷移特征選擇算法去除冗余特征;最后對多個遷移學習分類模型集成。結果表明,本文算法可以去除數據集中的無關樣本與特征,具有良好的計算效率,該算法相比于其它方法具有更優的跨被試情感識別能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
