適應立體匹配任務的端到端深度網絡
2020-07-18 03:30:38徐士彪張曉鵬
計算機研究與發展 2020年7期
李 曈 馬 偉 徐士彪 張曉鵬
1(北京工業大學信息學部 北京 100124)2(中國科學院自動化研究所 北京 100190)

Fig. 1 Architecture of PSMNet[13]圖1 PSMNet網絡結構[13]
立體匹配(stereo matching)是計算機視覺領域中的經典問題.相比激光測距等方法,立體匹配能夠低成本從雙目圖像中便捷恢復場景深度,在自動駕駛、機器人避障、立體圖像智能編輯等領域具有重要應用價值[1-5].近年來,深度學習(deep learning)受到廣泛關注,并在諸多計算機視覺任務中取得顯著成功[6-8].鑒于此,國內外研究者嘗試設計用于立體匹配的深度網絡[9-10].相比傳統方法,深度學習模型尤其是端到端模型,能夠在學習大量數據的基礎上得到更準確的視差結果[11-15].
然而,現有深度網絡尚存在諸多不足:現有網絡的特征提取模塊多源自于求解其他問題的網絡模型,對立體匹配任務特性考慮不足,冗余度高;3D卷積常用于立體匹配的視差計算,性能優越.然而,3D卷積復雜度高,難以實現大卷積核運算,現有網絡多采用小卷積核3D卷積,感受野范圍受限.
針對上述問題,提出改進的端到端神經網絡模型.該模型以當前性能優異的金字塔立體匹配網絡(pyramid stereo matching network, PSMNet)[13]為基準方法,對其核心模塊,包括特征提取模塊和3D卷積匹配模塊,進行改進.所提出特征提取模塊專為立體匹配問題所設計.相比現有特征提取網絡,結構更簡潔,能夠在保持結果精度前提下分別以90%和25%的幅度大幅減少參數量與計算量.在視差計算模塊中,提出分離3D卷積,相比現有3D卷積復雜度低.因此,可實現大卷積核運算以擴充感受野,從而提高立體匹配準確度.在SceneFlow數據集上驗證了所提出方法的優異性能,并通過對比實驗從準確度、計算成本等方面驗證2個模塊的有效性.
1 整體網絡架構
本文所提出網絡以PSMNet為基準網絡,因此,先簡要說明PSMNet網絡結構,再給出本文網絡設計.
PSMNet網絡結構如圖1所示.首先,提取立體圖像特征,用于構建匹配成本特征體(cost volume).之后,通過3D卷積運算計算視差.在立體圖像特征提取過程中,PSMNet使用類似ResNet[16]的網絡結構,再使用空間金字塔池化(spatial pyramid pooling, SPP)結構[13,17]融合多尺度特征增強特征表達.然后將特征連接形成匹配成本特征體.在視差計算部分,PSMNet網絡包括2種版本網絡,分別是多次殘差級聯Basic的3D卷積網絡和使用Stackhourglass結構[18]的3D卷積網絡.
本文在PSMNet網絡結構基礎上提出改進的立體匹配網絡架構.如圖2所示.首先,從立體匹配問題特性出發,提出簡潔的特征提取網絡SimpleResNet,替換PSMNet網絡中的特征提取部分.之后,提出用于視差計算的具備大感受野的分離3D卷積層,替換PSMNet網絡的Basic結構中的3D卷積層.
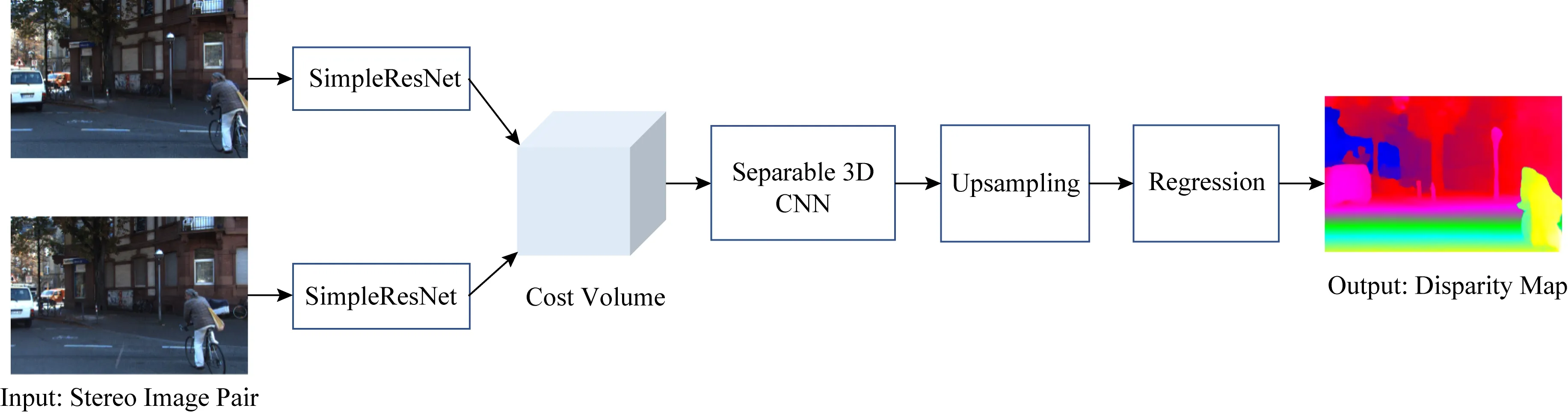
Fig. 2 Architecture of the proposed task-adaptive network for stereo matching圖2 本文適應立體匹配任務的網絡結構
2 適用立體匹配的特征提取結構
PSMNet網絡的特征提取部分使用了類似ResNet網絡的結構.但是,ResNet網絡原是針對圖像分類任務所設計.圖像分類與立體匹配2個任務之間存在較大差別.
首先,圖像分類屬于平移不變任務,要求即使輸入圖像發生平移變換,輸出分類結果不變.與圖像分類不同,立體匹配需要平移敏感,即當輸入圖像有空間移動時對應結果也應該有相應變化.其次,圖像分類需要提取高度抽象的特征用于表達語義信息,以對圖像內容類型做出準確判斷.但是,立體匹配求解過程并不需要語義級別特征.事實上,立體匹配需要求解2張圖像上像素點之間的對應關系.因此,要求網絡在不同空間位置提取的特征具有更多局部細節描述能力.
具體而言,在分類任務中,通常采用較深的特征提取網絡,并傾向采用大的感受野.網絡越深,感受野越大,可用的全局信息越多.同時,感受野足夠大,才能夠提取出具有平移不變性的特征.而且,隨著網絡層數的加深,提取到的特征更抽象,也更能夠表征圖像語義.但是,在立體匹配任務中,增大感受野將降低網絡所得特征的差異性.特征圖上相近位置的特征將因為大的感受野所導致的對應圖像區域重疊度大而變得相似,特征自身位置信息也變得模糊.
綜上,立體匹配任務對于高抽象程度的語義特征沒有需求.采用較低抽象程度的特征更便于區別不同空間位置的像素.抽象特征不僅難以帶來顯著的性能提升,而且其獲取需要較深層次網絡結構.而較深網絡意味著更多的參數量與計算量.因此,直接將原本用于處理圖像分類任務的網絡結構用于立體匹配不夠合理.
鑒于上述事實,本文設計了專用于立體匹配任務的特征提取網絡.在該網絡中,通過限制卷積核大小以減少感受野;同時,簡化卷積網絡結構,在大幅減少參數量的同時增加網絡能夠提取的細節信息的比重,使提取的特征具有更強的差異性,更便于鑒別不同空間位置的像素.鑒于所提出的特征提取網絡是依據立體匹配特性針對ResNet網絡進行簡化得來,將其稱為SimpleResNet網絡.其具體結構如表1所示.其中,H和W分別表示輸入圖像高和寬.網絡參數表示方法與ResNet網絡相同[16].例如Conv2_x殘差單元包含4組2層卷積操作. 其中,第1層卷積操作的卷積核尺寸為3×3,輸出通道為64;第2層卷積操作的卷積核尺寸為1×1,輸出通道為32.

Table 1 Architecture Parameters of SimpleResNet表1 SimpleResNet網絡結構參數
為方便與PSMNet網絡的特征提取部分進行對等比較以驗證本文推論,本文在SimpleResNet網絡中保留了PSMNet特征提取部分所用ResNet網絡的整體結構,只依據推論做出2方面修改:限制了非下采樣且具有重復結構層的卷積核大小;大幅度消減重復網絡結構.如此,限制感受野和減少層數的同時保持網絡整體結構不發生改變.具體地,只保留PSMNet中Conv_1與Conv3_x中的卷積核原尺寸,其余卷積核減少至1×1大小;去除Conv1_x,Conv2_x,Conv3_x模塊中的重復卷積結構;將原特征提取部分的48層卷積層減少至14層.重復結構和層數減少量依據實驗得來.
相比PSMNet網絡的特征提取結構,Simple-ResNet網絡復雜度和計算量減少顯著:原特征提取網絡約有300萬個參數,SimpleResNet網絡參數減少至不足20萬個,減少量超過90%.所作簡化操作均源自前述推論:立體匹配并不需要過大感受野和高度抽象的語義信息,如ResNet網絡這類層次深、感受野覆蓋范圍大的結構,對于立體匹配任務而言存在極大冗余.因此,所提出方法并不會因為網絡深度的大幅度減小而對立體匹配準確度有較大影響.后續通過實驗驗證了該觀點.
3 分離3D卷積(separated 3D CNN)
在端到端立體匹配深度網絡中,3D卷積能夠在優化匹配成本特征體的同時實現視差計算.與前段網絡部分以提取特征為目的不同,此段網絡的目的是利用鄰域信息優化已提取的成本特征,以減少視差中錯誤離散值的出現.
鑒于采用更大鄰域范圍內的約束將更有利于優化成本特征,傾向在網絡中應使用較大卷積核.然而,3D卷積計算復雜度高,擴大3D卷積核將帶來巨大的參數量增加.
為了克服3D卷積計算在擴大感受野時的參數量爆炸問題,提出分離3D卷積層結構.圖3(a)是正常的3D卷積層,圖3(b)是所提出的分離3D卷積層.分離3D卷積將3D卷積分解為1次長與寬維度的2D卷積與1次視差維度的1D卷積.普通3D卷積參數量為m2×c(m為卷積核寬高,c表示類型數),而使用分離3D卷積的參數量是m2+c.當m與c增長時,后者參數量增長遠小于前者.

Fig. 3 3D convolution and separated 3D convolution圖3 3D卷積與分離3D卷積
此外,考慮到與分類任務不同,立體匹配任務中輸入圖像分辨率大,訓練時每批數據數量較少,不適合在分離3D卷積后接批量歸一化(batch normali-zation, BN)操作.因此,本文使用分離3D卷積搭配群組歸一化(group normalization, GN)層替代PSMNet里的3D卷積和BN層結構.
4 實驗與結果
本節通過實驗驗證所提出方法和模塊.首先,介紹所用數據集、評價標準與網絡訓練過程.然后,通過消融實驗驗證本文方法和模塊的有效性.之后,通過與當前優秀方法進行性能比較與分析,證明本文方法的先進性.最后,通過對比基準網絡PSMNet,證實所提出網絡在時間、顯存占用方面的優勢.
4.1 數據集與訓練過程
使用SceneFlow數據集完成網絡的訓練與對比實驗.SceneFlow數據集[11]屬于大型合成數據集,共計包含35 454對訓練用立體圖像數據與4 370對測試用立體圖像數據.每對數據都提供了稠密真值信息與相機參數信息.數據集中所有圖像分辨率均為960×540.SceneFlow數據集按照場景內容分為3個子數據集,分別是FlyingThings3D,Driving,Monkaa.其中,Flying-Things3D子數據集的場景包含大量漂浮的隨機類型物體,圖像內物體較多,細節內容較為豐富;Driving子數據集是在模擬汽車駕駛過程中所抓取,其內容是開闊的街道場景;Monkaa子數據集的場景內容是深林環境中的猴子,其中有較多近距離物體,即存在較多視差值較大的區域.
本文實驗使用端點誤差(end-point-error, EPE)作為量化指標評.端點誤差是真值與估計視差值之間的平均歐氏距離.其計算為
(1)
其中,d與gt分別表示視差的估計值和真值,N是參與計算的像素總數,n是指示變量.EPE評價指標分值越低表示方法性能越好.
在Pytorch框架下構建網絡.在Ubuntu操作系統下完成網絡訓練.訓練所使用GPU為單個NVIDIA GeForce TITAN X Pascal.
網絡使用Smooth L1距離作為監督訓練的損失函數.需要注意的是,所提出網絡和PSMNet網絡相同,均設置視差上限為192.該值適用于大部分實用情形.但是,SceneFlow數據集中存在部分數據視差真值超過該上限.為避免此部分數據的干擾,訓練過程只取用視差真值小于等于192數據參與計算損失函數回傳.訓練損失函數:
(2)
其中:
其中,dn與gtn分別表示第n點的網絡估計視差值與視差真值,N′表示視差真值小于等于192的像素點總數.
網絡每次訓練數據批量大小設置為3.訓練過程是端到端訓練,無需其他后處理方法.針對數據集中每對圖像以原尺寸輸入網絡,訓練學習率設置為0.001,在SceneFlow數據集上使用Adam優化方法[19]訓練10輪.Adam方法參數為β1=0.9,β2=0.999.訓練時間持續約40 h.
4.2 消融實驗與分析
在SceneFlow測試集上通過消融實驗測試所提出網絡的核心模塊,包括特征提取模塊SimpleResNet和分離3D卷積模塊Globalconv.結果如表2所示.
用ResCNN+Basic+BN表示PSMNet網絡的原始基礎結構.SimpleResNet+Basic+BN表示使用本文提出的特征提取模塊SimpleResNet代替PSMNet中的特征提取模塊ResCNN.從替換前后的EPE數值可看出:相比ResCNN,所提出特征提取網絡結構SimpleResNet網絡參數降低超過90%(見第3部分分析)的情況下,依然能夠保持較低的EPE.

Table 2 EPEs of PSMNet and Our Networks表2 本文網絡與原網絡EPE對比
進一步地,以PSMNet網絡性能最佳的組成結構ResCNN+SPP+Stackhourglass+BN為基準方法驗證所提出的特征提取網絡.表2中SimpleResNet+Stack hourglass+BN是用所提出特征提取網絡替換原特征提取網絡.從表2實驗數據看:在此框架下,所提出特征提取網絡在參數量減少情況下,EPE更低.
為驗證所提出分離卷積的效果,在SimpleResNet+Basic+BN基礎上,使用所提出的分離3D卷積替換Basic中所用到的普通3D卷積,記作SimpleResNet+Globalconv+BN.從表2可以看出:相比普通3D卷積,分離3D卷積能夠有效降低誤差.表2中SimpleResNet+Globalconv+GN方法是用分離3D卷積加GN層替換了SimpleResNet+Basic+BN中原屬于PSMNet的后2部分.從結果可看出:該方法的EPE相比SimpleResNet+Basic+BN的EPE,降低約12%的相對量.該實驗說明:所提出分離3D卷積搭配GN操作相比普通3D卷積搭配BN操作,性能顯著更佳.
需要注意的是:以上對比方法(除PSMNet網絡性能最佳的組成結構外),以及本文方法均未加入SPP結構.既是為了方便與PSMNet中基礎方法(不含SPP結構)對比,也是因為SPP結構將破壞SimpleResNet網絡局部性特征提取能力.
4.3 橫向對比實驗與分析
所提出方法與其他現有深度學習立體匹配方法在SceneFlow測試集上的EPE對比如表3和圖4所示.其中Ours為本文性能最佳方法,對應表2中的SimpleResNet+Stackhourglass+BN.從表3和圖4可見:相比其他5種方法,PSMNet網絡效果最佳;而相比PSMNet網絡,本文方法在大幅度降低特征提取模塊參數的同時,EPE更低.

Table 3 EPEs of Our Networks and Other Methods表3 本文網絡與其他網絡方法EPE對比
圖5是采用SimpleResNet+Stackhourglass+BN方法與PSMNet方法在ScenenFlow數據集上所得視差結果.如圖5所示,本文方法與PSMNet網絡在大部分區域表現相近,均能夠得到與真值相近的結果.但是在方框標示的物體內部的連續區域,PSMNet網絡所得結果出現明顯錯誤,而所提出方法結果基本無誤.

Fig. 4 Visualized EPEs of our network and other methods圖4 本文網絡與其他網絡方法EPE可視化對比

Fig. 5 Disparity maps obtained by our network and PSMNet圖5 本文網絡與PSMNet網絡視差計算結果
4.4 計算成本分析
表4和圖6給出了所提出方法和基準方法的時間與顯存開銷的實驗數據.在此實驗中,所有方法在每批次訓練過程中統一采用1張輸入圖像.從表4和圖6中可以看出:本文方法SimpleResNet+Basic比基準方法ResCNN+Basic減少了約0.4 GB顯存占用.同時,單次訓練速度加快約0.1 s,提升量為25%.相較Basic方法,使用Globalconv模塊顯存增量約為0.7 GB.顯存占用增長是由于Globalconv模塊所用更大的卷積核以及所增加的中間緩存所導致.其中,由中間緩存帶來的顯存占用增長占比更多.在實際使用中可以通過及時釋放中間緩存以釋放更多的顯存.Basic結構使用相同大小的卷積核會因為顯存不足而無法運行.

Table 4 Computation Time and Memory Costs of Different Networks
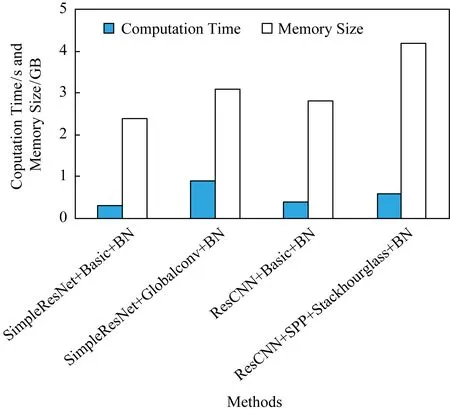
Fig. 6 Visualized time and memory costs of different networks圖6 各網絡計算時間開銷與顯存占用可視化對比
改進后Globalconv模塊相比Basic方法時間增長較為明顯.這是因為分離卷積后,在視差維度上將卷積核擴大至覆蓋所有視差的同時,需要對原特征填補較大區域,該操作帶來較多額外耗時.
5 結 論
在分析現有端到端立體匹配網絡不足之處的基礎上,提出了改進的立體匹配深度網絡.首先,根據立體匹配任務特性設計了新的特征提取結構.該結構在減少90%參數量的同時,能夠保持穩定的網絡性能.之后,提出了分離3D卷積運算.相比傳統3D卷積,該運算能夠在增大卷積核尺寸擴大感受野的同時抑制參數量的增加,從而提高視差計算的精度.
所提出網絡也存在不足之處.例如分離3D卷積需要額外的填補操作、增加了較多額外耗時.本文將在未來工作中著手解決該問題.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
