基于重排序的迭代式實體對齊
2020-07-18 04:12:22曾維新唐九陽
計算機研究與發展 2020年7期
曾維新 趙 翔,2 唐九陽,2 譚 真 王 煒
1(國防科技大學信息系統工程重點實驗室 長沙 410073)2(地球空間信息技術協同創新中心(武漢大學) 武漢 430079)3(新南威爾士大學計算機科學與工程學院 澳大利亞悉尼 2052)
近年來,涌現出一大批知識圖譜(knowledge graph, KG),諸如YAGO[1],DBpedia[2],Knowledge Vault[3],NELL[4]以及中文的CN-DBpedia[5],Zhishi.me[6]等,這些大規模知識圖譜在問答系統、個性化推薦等智能服務中起到重要作用.此外,為滿足特定領域相關需求,衍生出越來越多的領域知識圖譜,如醫療知識圖譜(1)https:flowhealth.com和科學知識圖譜(2)https:www.aminer.cnscikg.在知識圖譜構建過程中,無法避免地需要在覆蓋率和正確率間作權衡.而任何一個知識圖譜都無法達到完備或者完全正確.
為提升知識圖譜的覆蓋率及正確率,一種可行方法是從其他知識圖譜中引入相關知識,因為以不同方式構建得到的知識圖譜間存在知識的冗余以及互補.例如從網頁上抽取構建的通用知識圖譜中可能僅包含藥品的名字,而更多的信息可在基于醫療數據構建的醫療知識圖譜中找到.為將外部知識圖譜中的知識整合到目標知識圖譜中,最重要的一步是對齊不同的知識圖譜.為此,實體對齊(entity alignment, EA)任務[7]被提出并受到廣泛關注.該任務旨在找到不同知識圖譜中表達同一含義的實體對.而這些實體對則作為鏈接不同知識圖譜的樞紐,服務于后續任務.
目前,主流實體對齊方法[7-21]主要借助知識圖譜結構特征判斷2實體是否指向同一事物.這類方法假設不同知識圖譜中表達同一含義的實體具有類似的鄰接信息.在人工構建的數據集上,這類方法取得了最好的實驗結果.但最近一項工作[20]指出,這些人工構建的數據集中的知識圖譜比真實世界的知識圖譜更加稠密,而基于結構特征的實體對齊方法在具有正常分布的知識圖譜上效果大打折扣.
事實上,通過分析真實世界知識圖譜中的實體分布可知,超過半數的實體只與一兩個其他實體相連.這些實體被稱為長尾實體(long-tail entities),占據了知識圖譜實體的大部分,使得圖譜整體呈現較高的稀疏性.這也符合人們對真實世界知識圖譜的認知:只有很少一部分實體被經常使用并具有豐富的鄰接信息;絕大部分實體很少被提及,包含微少的結構信息.因此,當前基于結構信息的實體對齊方法在真實世界數據集[20]上的表現不盡人意.
此外,標注數據的缺乏也大大限制了實體對齊的效果.為將不同知識圖譜的表示向量映射到同一空間,需要足夠的標注數據作為鏈接.然而,已知的實體對數量是有限的.為解決此問題,部分方法[8,10]提出采用迭代訓練(iterative training, IT)從測試集結果中選出高置信度實體對(confident pairs)用作下一輪訓練,但存在易引入錯誤樣本[8]以及效率過低[10]等問題.此外,在具有真實世界度數分布的數據集上,這些迭代訓練框架只能引入少量高置信度實體對,無法帶來明顯的效果提升.
鑒于此,為克服當前方法的不足之處,本文提出結合實體結構特征以及實體名特征,實現初步的實體對齊.其中實體結構特征向量由圖卷積神經網絡(graph convolutional network, GCN)生成,而實體名特征向量則由平均詞向量(averaged word embedding)表示.由于實體名與結構信息相互補充,且實體名不受實體節點度數的影響,此基本框架能大幅提升長尾實體的對齊結果,進而優化整體對齊效果.
此外,針對標注數據的缺乏,在本文基本實體對齊框架上,設計了一種基于課程學習(curriculum learning, CL)的迭代訓練策略,在保證訓練效率的同時,能顯著提升實體對齊的效果.該方法受課程學習思想的啟發,以實體節點度數為衡量指標,將度數較高的實體視為簡單課程,長尾實體視為困難課程,以從簡至難的方式將高置信度實體對加入到訓練集中,優化迭代訓練方式,提升結構特征表示準確性,并使得模型訓練更容易達到最優.
最后,不難發現,將實體名用平均詞向量表示,雖然提升了其易操作性,但平均化過程難免會造成一定程度上的語義損失,進而無法完全表示實體名的語義信息.為此,提出基于詞移距離(word mover’s distance, WMD)的重排序模型,即在前2步生成的實體排序結果上,利用詞移距離模型進一步挖掘實體名信息,并與結構信息結合,優化實體對齊效果.
本文的主要貢獻有3個方面:
1) 設計了一個融合結構特征和實體名特征的實體對齊基本框架.在此之上,提出基于課程學習的迭代訓練策略,通過改變高置信度實體對添加方式,使得訓練過程更容易達到最優.
2) 采用詞移距離模型將前序對齊結果進行重排序,以充分挖掘實體名信息,提升對齊準確性.
3) 利用跨語言和單語言實體對齊數據集驗證本文提出方法的有效性.而實驗結果也證實了本文提出的模型取得了比當前最好方法更好的效果.
1 相關工作
由于不同知識圖譜間具有知識的互補性,通過引入外部知識圖譜中的相關知識,能夠大大提升目標知識圖譜的覆蓋率以及正確率.在此過程中,最重要的1步便是對齊知識圖譜.其中,實體對齊任務旨在找到不同知識圖譜中表示同一事物的實體,在近年來得到廣泛研究.
傳統的實體對齊方法[22-23]多依賴本體模式對齊,利用字符串相似度或者規則挖掘等復雜的特征工程方法[24]實現對齊,但在大規模數據下準確率及效率顯著下降.而當前實體對齊方法[7,13,25]大多依賴知識圖譜向量,因為向量表示具有簡潔性、通用性以及處理大規模數據的能力.這些工作具有相似框架:首先利用TransE[7-8,12],GCN[11]等知識圖譜表示方法編碼知識圖譜結構信息,并將不同知識圖譜中的元素投射到各自低維向量空間中.接著設計映射函數,利用已知實體對對齊這些向量空間.有些方法[9-10,20]通過在數據準備階段融合不同知識圖譜中的元素,進而直接將不同知識圖譜映射到同一向量空間.最后根據向量空間中實體之間的距離或者相似度,生成實體對齊結果.
上述方法僅考慮到實體在全局中的結構表示,為充分利用實體的局部結構信息,文獻[15]提出為每一個實體構建1個主題圖(topic graph),進而直接將局部結構信息融入實體表示中,并將實體對齊問題轉化為主題圖之間的圖匹配問題;類似地,文獻[17]同樣也指出之前的方法忽略了鄰接子圖信息,并稱其能為實體對齊提供更多的線索,因此提出基于鄰接信息的注意力表示模型,利用注意力機制對實體鄰接信息加權求和得到實體的結構表示;此外,文獻[14]提出多通道圖神經網絡,從多個角度生成面向實體對齊的知識圖譜嵌入向量.每一個通道能學到不同的加權方法,并從基于自注意力的知識圖譜補全和基于跨圖譜注意力的互斥實體剪枝這2個角度生成知識圖譜表示,最后通過池化操作進行結合.
除了生成并優化結構表示之外,部分方法[9,11,13]提出引入屬性信息以補充結構信息.文獻[9]提出利用屬性類型生成屬性向量;而文獻[11]則將屬性表示成最常見屬性名的one-hot向量;最近,文獻[13]設計了字符嵌入模型以充分挖掘屬性值信息,并借此將不同知識圖譜中的實體向量映射到同一空間.這類工作均假設圖譜中存在大量屬性三元組;但文獻[26]指出,在大多數知識圖譜中,69%~99%的實體至少缺乏1個同類別實體具有的屬性.類似地,雖然實體描述也能提供文本特征[12],但這類信息在大多數知識圖譜中也是缺乏的.這也限制了這些方法的通用性以及在處理長尾實體時的有效性.
還有一些工作[8,10]注意到標注數據的不足限制了模型效果,進而提出迭代訓練方法,從對齊結果中選出高置信度實體對以擴增訓練集.文獻[8]根據結構向量空間中實體間距離選擇高置信度實體對,并采用直接對齊以及軟對齊2種方式將這些實體對加入到訓練集中.但直接對齊易引入錯誤樣本,而軟對齊則會增加模型訓練復雜度;文獻[10]提出自舉訓練(bootstrapping)框架,在選擇高置信度實體對時,設計了全局優化目標以提升高置信度實體對的準確率.但全局優化過程過于復雜,大幅降低了實體對齊的效率.而本文設計的基于課程學習的迭代訓練策略,以從簡至難的方式將高置信度實體對加入到訓練集中,優化迭代訓練方式,在保證訓練效率的同時,顯著提升實體對齊的效果.
文獻[20]指出當前實體對齊數據集中的知識圖譜比真實世界中的知識圖譜更加稠密.在具有正常分布的數據集上,存在大量長尾實體,此時結構信息只能發揮有限作用,而外部信息(屬性、實體描述等)也往往缺失.因此,需要設計針對長尾實體的對齊方法.目前,暫未發現直接解決此問題的措施.而本文提出的基本實體對齊框架,由于利用了廣泛存在但又不受實體節點度數影響的實體名特征,能在一定程度上提升長尾實體對齊效果.此外,基于實體度數的迭代訓練框架以及基于詞移距離模型的重排序,均能在很大程度上緩解長尾實體問題.
2 問題定義與總框架
本節主要介紹實體對齊任務的定義以及本文所提出的框架.
2.1 基本定義
給定某一實體,尋找其在另一知識圖譜中對應實體的過程可視為排序問題.即在某一特征空間下,計算給定實體與另一知識圖譜中所有實體的相似程度(距離)并給出排序,而相似程度最高(距離最小)的實體可被視為對齊結果.
當前,實體對齊任務面臨2個方面的挑戰:
1) 已知實體對能夠鏈接不同知識圖譜,在實體對齊過程中起到不可或缺的作用.但其數量往往有限,進而限制了當前實體對齊模型效果;
2) 文獻[20]指出,在正常分布的數據集中,長尾實體占據較大比例,使得在之前工作中廣泛使用的結構信息無法充分發揮作用.
針對上述缺陷,本文做出3項改進:
1) 提出基于課程學習的迭代訓練方法,挑選高置信度實體對用于下一輪訓練,解決訓練數據過少問題;
2) 充分利用實體度數信息,通過課程學習從簡至難展開訓練;
3) 采用不受實體度數影響的實體名特征并進行2階段排序,提升長尾實體對齊效果.具體模型框架圖1所示.相關符號表1所示.
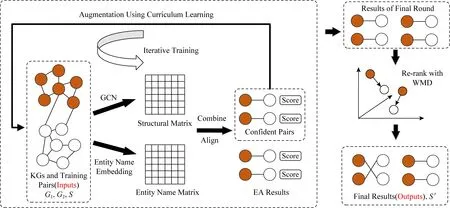
Fig. 1 Our proposed EA framework圖1 本文實體對齊框架
2.2 總框架
如圖1所示,本工作首先設計了1個基本的實體對齊框架:利用圖卷積網絡學習實體結構向量,生成結構特征矩陣(structural matrix),并將實體名字表示為平均詞向量,生成實體名特征矩陣(entity name matrix).進一步結合2種向量生成實體表示向量,并根據表示向量的相似程度,實現實體對齊(combine & align);接著提出基于課程學習的迭代訓練框架(iterative training),從易至難地選擇高置信度實體對加入到訓練數據中(augmentation using curriculum learning),優化實體結構表示并不斷提升實體對齊效果;最后,利用詞移距離模型(re-rank with WMD)對前一步輸出結果(results of final round)重排序,融合更精準的實體名信息,進一步提高實體對齊的效果.

Table 1 Notation表1 符號表
3 實體對齊基本框架
本節主要介紹實體對齊的基本框架,包括實體結構特征和實體名特征以及如何有效結合不同特征進行實體對齊.
3.1 實體結構特征
本文采用GCN[27]捕捉實體鄰接結構信息并生成實體結構表示向量.
GCN基本結構:GCN是一種直接作用在圖結構數據上的卷積網絡,通過捕捉節點周圍的結構信息生成相應的節點結構向量.GCN的輸入是實體的特征矩陣X∈Rn×P,以及圖的鄰接矩陣A.輸出是融入了結構信息的特征矩陣Z∈Rn×F.n代表圖譜中節點的數目,而P和F分別代表輸入和輸出矩陣特征的維度.

實體對齊中GCN設置:在實體對齊任務中,利用GCN生成實體結構向量.本文構建了2個2層的GCN,各用來處理1個知識圖譜并生成相應的實體向量.其中初始特征矩陣X從L2正則化的截尾正態分布中抽樣得到,并通過GCN各層訓練更新,進而充分捕捉知識圖譜中的結構信息并生成輸出特征矩陣Z.值得注意的是,特征矩陣的維度一直設置為ds(P=F=dl=ds),而2個GCN在2層中共享特征矩陣W1和W2.關于GCN初始特征陣X的設置,在6.4節中有詳細討論與分析.
此外,構建矩陣A:首先考慮到知識圖譜中存在多種關系,為每一個關系r定義正向重要度和反向重要度.其中正向重要度fun(r)是包含關系r的所有三元組中不重復頭實體的數目與包含關系r的所有三元組的數目的比值;反向重要度ifun(r)則是包含關系r的所有三元組中不重復尾實體的數目與包含關系r的所有三元組的數目的比值.接著定義矩陣A中元素
不同知識圖譜的實體結構向量并不在同一空間中,因此需要利用已知實體對S將它們對齊到同一空間中.具體的訓練目標為最小化下述損失值

(1)


3.2 實體名特征
區別于當前主流的僅基于結構特征的方法,本文提出同時利用文本特征進行對齊.具體地,采用實體名這一文本形式,考慮到:1)實體名常被用來標識實體并廣泛存在;2)通過比較實體名,能直觀的判斷2實體是否相同;3)其不受訓練集規模的影響,具有較強的穩定性.


3.3 特征融合
考慮到結構特征和名字特征分別從結構和語義2個不同的方面對實體進行刻畫,可進一步結合以提供更全面的對齊線索.具體地,2實體e1∈G1和e2∈G2之間的距離為
D(e1,e2)=αDs(e1,e2)+(1-α)Dn(e1,e2),
(2)
其中,α是用來調整2種特征權重的超參數.在特征融合后的空間下,和目標實體e距離D最近的實體將被視為e的對應實體.對超參數α的討論詳見6.4節.
4 基于課程學習的迭代訓練框架
已標注數據的數量是有限的,無法有效地將不同知識圖譜的向量映射到同一空間中,進而限制了實體對齊的效果.因此,本文提出將具有高置信度的實體對齊結果從簡至難地添加到下一輪訓練數據中,迭代式地擴增訓練集規模并提升實體對齊結果.本節首先介紹基本迭代訓練框架,接著闡述如何將課程學習的思想運用到迭代框架中以優化訓練效果.
4.1 迭代訓練框架
每一輪迭代訓練的輸入為待對齊知識圖譜和已對齊實體對(訓練集),輸出為對齊結果和擴增后訓練集.一種最簡單的擴增方式是,對于G1中的每一個待對齊實體e1,假設G2中距離其最近的實體為e2;而對于e2來說,G1中距離其最近的實體正好也為e1,那么可認為(e1,e2)為高置信度實體對,并將其添至訓練數據中.但在此過程中,無法避免地會引入一部分錯誤的實體對,進而對后續訓練造成負面的影響.而一旦加入了錯誤實體對,很難再次評估這些實體對的正確性或是將其從訓練數據中移除[28].
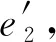
值得注意的是,在本文設計的迭代訓練框架中,當測試集中高置信度實體對加入到訓練集后,將不會出現在下一輪的測試集中,即測試集中實體數量是不斷減少的.這在一定程度上能夠提升測試集中剩余實體的對齊效果,因為其候選實體數目與原始相比大幅減少.而在文獻[8,10]中,高置信度實體對加入到訓練集后,仍會出現在下一輪的測試集中.實驗結果表明,本文提出的迭代訓練框架能帶來更好的效果.
4.2 基于課程學習的迭代策略
課程學習主要思想是模仿人類學習的特點,由簡單到困難學習,這樣能使得模型更容易找到局部最優,同時加快訓練速度[29].在實體對齊任務中,課程的難易程度可由實體節點度數高低來刻畫:度數較高的實體具有更為豐富的結構信息,更容易對齊;而對齊度數低的長尾實體則相對而言頗具難度.為此,在迭代訓練過程中,首先添加容易的實體對,再加入較難的實體對,從而實現由易至難地對模型進行訓練,使得訓練更容易達到最優.
具體地,假設有從簡至難的δ個課程,c1,c2,…,cδ,分別代表從大到小的一系列實體節點度數值,那么在每一次迭代訓練得到的高置信度實體對中,只選擇節點度數大于c1的加入到訓練集中,并保持該條件一直循環迭代訓練,直到符合要求的實體對數目低于給定閾值θ2時,停止該課程難度的訓練.
在接下來的訓練中,調整課程難度,將條件改為從高置信度實體對中選擇度數大于c2的加入到訓練集中,并保持該課程難度一直循環迭代訓練,直到符合要求的新增實體對數目低于給定值θ2時,停止該課程難度的訓練.最后重復上述步驟,遍歷剩下的課程難度c3,c4,…,cδ.需要注意的是,對于不同課程難度下的迭代訓練,均采用4.1節中介紹的方法.
基于課程學習的迭代訓練通過優化高置信度實體對的添加方式,生成更準確的實體表示向量,進而提升對齊效果.這也通過第6節的實驗結果得到驗證.
5 基于詞移距離模型的重排序
基于課程學習的迭代訓練框架已大幅提升實體對齊的準確率,在此基礎上,提出進一步挖掘實體名信息,采用詞移距離模型對前序結果進行重排序,優化實體對齊效果.
如圖2所示,詞移距離模型旨在衡量不同句子間的差異性,其表示為1個句子中所有詞的嵌入向量需要移動到達另一個句子中所有詞的嵌入向量的最小距離值[30].與平均詞向量間的距離相比,詞移距離能更好地刻畫句中每個詞對整個句子的影響,避免了平均操作造成的語義損失.然而,由于需要計算詞級別的距離,該模型耗時較長,不適用于大規模數據.為此,并未在一開始就使用該方法計算實體名之間的距離,而是利用其對前序結果進行重排序.具體算法細節可參見文獻[30].
具體地,在基于課程學習的迭代訓練結束后,對于測試集中的每一個待對齊實體,保留另一個知識圖譜中距離其最近的h個實體,并將其作為輸入送入到詞移距離模型中,重新計算實體名空間下實體間的距離.最后利用更新后的實體名距離,結合式(2),計算得到新的實體間距離以及重排序后的對齊結果.

Fig. 2 Word mover’s distance model圖2 詞移距離模型
6 實驗與結果
本節首先介紹實驗的基本設置,包括參數設置,數據集、對比方法以及度量指標.接著展示在跨語言實體對齊以及單語言實體對齊2個任務上的實驗結果.隨后進行特征分析以驗證各個模塊的有效性.最后通過案例分析,對本文框架有更清晰的認識.
6.1 參數設置及度量指標
對于實體結構特征,ds=300,τ=3,訓練300輪,為每個正例生成5個負例.對于實體名特征,利用fastText[31]預訓練詞向量生成實體名向量,而跨語言詞向量則通過MUSE獲得.其中fastText向量采用CBOW模型訓練得到,維度為300(即dn=300),字符長度為5,窗口大小為5,負正例比為10.通過驗證集上實驗,將設置超參數α=0.3.對于基于課程學習的迭代訓練框架,θ1=0.03,θ2=20.c1,c2,…,cδ={10,6,4,2,0}且δ=5.詞移距離模型中,h=100.
采用Hits@k(k=1,10),以及平均排序倒數(mean reciprocal rank, MRR)作為衡量指標.對于測試集中的每一個實體,根據與該實體之間的距離D,從低至高地將另一個知識圖譜中的實體進行排序.Hits@k反映了前k個實體中包含正確實體的比例.特別地,Hits@1代表對齊的準確率.MRR表示正確實體平均排名的倒數.雖然Hits@1是最重要的衡量指標,Hits@10可被視為對Hits@1的補充.假設某種方法未能成功將正確實體排為距離最近實體,但若其將正確實體排為距離前10近實體,那么這種方法至少好于未將正確實體排為距離前10近實體的方法.MRR亦能提供類似的信息補充.注意到,高的Hits@k和MRR值代表更好的實驗結果,實驗中的Hits@k由百分數表示.
6.2 數據集及對比方法
本文將在EN-FR,EN-DE2個跨語言實體對齊數據集以及DBP-WD,DBP-YG2個單語言實體對齊數據集上測試提出的方法[20].詳細數據集信息如表2所示.值得注意的是,文獻[20]指出,之前構建的實體對齊數據集中的實體節點度數分布整體偏高,并不符合真實世界知識圖譜情況,而其構建的數據集則具有正常分布以及更高的對齊難度.

Table 2 Statistics of Triples and Entities表2 三元組及實體統計信息
此外,與7種方法進行對比:
1) MTransE[7].最先提出采用知識圖譜嵌入(TransE)進行實體對齊的方法.
2) IPTransE[8].采用迭代訓練框架提升對齊效果.
3) BootEA[10].設計了一種基于對齊的知識圖譜嵌入方法以及自舉策略.
4) JAPE[9].利用屬性信息對結構信息進行優化.
5) GCN-Align[11].利用GCN生成實體向量,并與屬性向量相結合以對齊實體.
6) RSNs[20].采用基于殘差學習的循環神經網絡來有效捕捉知識圖譜內部以及知識圖譜間的長距離關系依賴.
7) GM-Align[15].為每個實體構建1個局部的實體圖以捕捉更多的局部信息.實體名信息用來初始化整個框架.
6.3 實驗結果
表3展示了實驗結果.在第1組只采用結構信息的方法中(MTransE,IPTransE,BootEA,RSNs),BootEA及RSNs取得了更好的實驗結果.這是因為BootEA利用了針對實體對齊任務設計的知識圖譜表示向量,并且其提出的自舉策略也能提升對齊結果.而RSNs通過挖掘長距離依賴關系以解決鄰接結構信息的局限性,進而提升整體對齊效果.然而在所有數據集上,這些方法的Hits@1值均未超過50%,揭示了只利用結構特征的不足之處.
第2組方法采用了實體屬性特征來補充結構特征,但JAPE 與GCN-Align均未取得比第1組更好的效果,這可歸因于屬性信息效果的局限性.此外,這2種方法中使用的結構特征模型均不如BootEA以及RSNs.
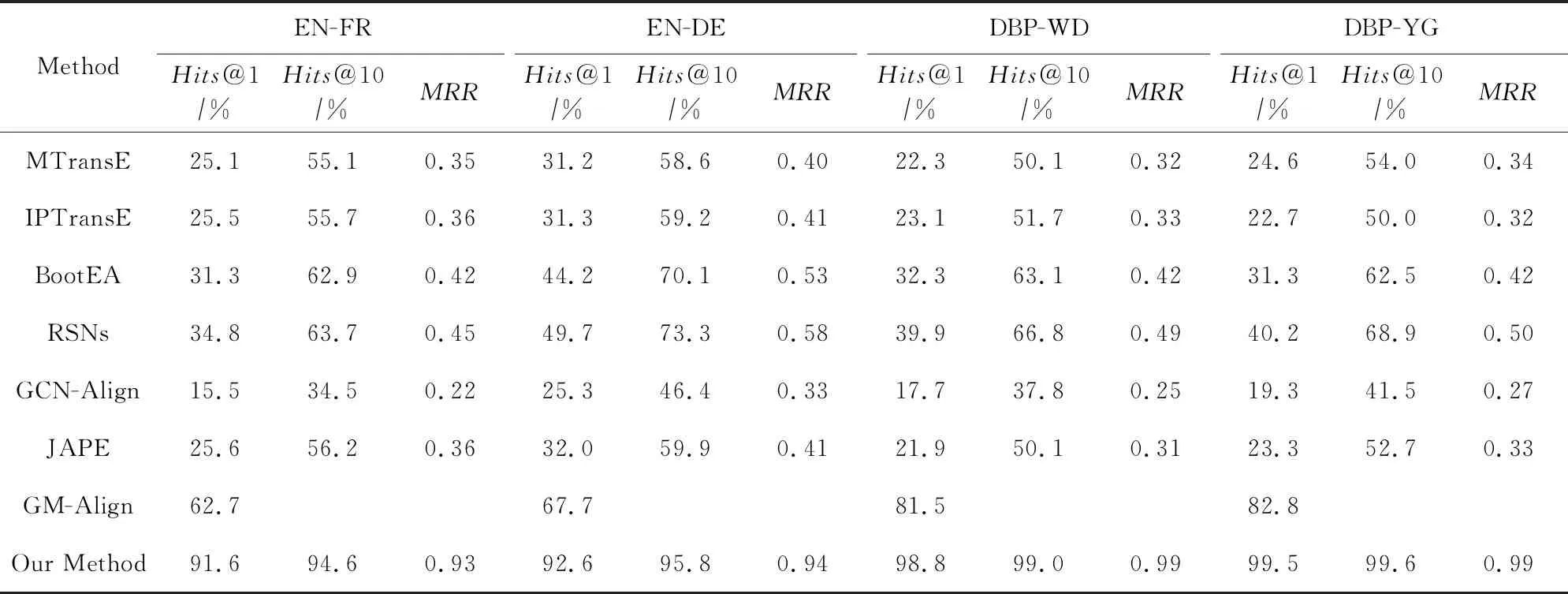
Table 3 Entity Alignment Results表3 實體對齊結果
第3組方法利用了實體名信息,與第1組相比,大大提升了對齊效果,證明了實體名信息的重要性,特別是對于長尾實體.此外,本文提出的方法與GM-Align相比,在Hits@1指標上取得了近20%的提升,并且所有指標均逾九成,展示了整體框架的有效性(對實驗結果大幅提升的原因分析可參見6.5節).其中單語言數據集上的結果要優于跨語言對齊結果,因為單語言下的實體名信息更有助于判斷實體的等價性.
需要注意的是:GM-Align無法給出沒有有效實體名字向量的實體的對齊結果,因此認為GM-Align不能對齊這些實體.由于無法知曉這些實體的具體排序結果,因而表3中未提供其Hits@10和MRR值.
6.4 參數分析
此節對超參數α以及GCN初始特征矩陣X進行實驗分析.
如3.3節指出,超參數α旨在調整結構和文本特征權重.為分析其對實驗效果的影響,在驗證集上進行了相關實驗.如圖3所示,只使用文本特征(α=0)已取得較高實驗結果(在所有數據集上均超過60%).當α增加時,Hits@1結果有一定幅度的提升,并在α≈0.3時達到最優效果.當結構特征占據更大比重時(α>0.3),整體對齊結果開始逐步下降,并在α=1時達到最低值.

Fig. 3 Analysis of parameter α圖3 超參數α分析
由此可知,結合結構和文本特征確實能提升整體對齊結果.相對于結構特征,文本特征能提供更多的對齊線索.此外,對GCN訓練過程中初始特征矩陣X進行分析,具體結果如表4所示:

Table 4 Analysis of GCN Initialization Matrix表4 GCN 初始化特征矩陣分析
在本文設置中,X通過隨機初始化得到,具體從L2正則化的截尾正態分布中抽樣生成,并通過GCN各層訓練更新,進而使得輸出矩陣能充分體征結構信息.另一種思路是將初始特征矩陣X設置為有意義的特征信息,并通過GCN各層訓練更新,根據結構信息在各個節點之間交換特征,進而學到更有用的表示.為驗證這2種不同思路的有效性進行對比實驗,具體結果如表4所示.
考慮到實體對齊任務中特征的局限性(絕大多數情況下僅存在結構和文本特征),將初始特征矩陣X設置為實體名向量矩陣(有意義的特征信息),并送入GCN中進行更新.而利用最終輸出矩陣生成的對齊結果(GCN-Feature)的確好于隨機初始化特征矩陣X后的對齊結果(GCN-Random).
然而,融合GCN生成的結構特征矩陣與實體名特征矩陣后的實驗結果表明,將初始特征矩陣X設置為實體名向量矩陣(有意義的特征信息)的對齊結果(Combine-Feature)并不如隨機初始化的結果(Combine-Random),即便相關參數已在驗證集上調到最優.這表明通過隨機初始化特征矩陣X,能夠使得GCN學到更“純粹”的結構信息,這也在文獻[27]中得到印證.在實體對齊任務上,將這樣學到的結構信息與其他特征信息融合,比將其他特征信息作為GCN的初始特征進行學習訓練以及融合更加有效.
當然,可以認為將X設置為實體名向量矩陣學習得到的結構特征矩陣,在后續與實體名向量矩陣結合過程中存在信息冗余,進而導致Combine-Feature結果較差.但在整個對齊過程中用到的特征只有結構特征與實體名特征,因而在此條件下,Combine-Random是比Combine-Feature更好的一種解決方案.
6.5 結果討論與特征分析
通過表3可以明顯看出,本文提出的方法要遠好于現有方法.為對實驗結果進行深入分析,首先驗證各個特征的有效性以及其對實驗結果帶來的提升.
具體地,表5中給出了結合了結構信息和實體名信息的基本實體對齊模型(Basic)、基本迭代訓練框架(Basic+IT)、基于課程學習的迭代訓練框架(Basic+IT-CL)以及基于詞移距離的重排序模型(Basic+IT-CL+WMD)的相關實驗結果.
1) 基本實體對齊模型(Basic).不難看出,結合了結構和實體名信息的基本實體對齊模型已取得了比RSNs, GM-Align等方法更好的效果,如Basic在EN-FR上取得了70.5%的Hits@1值(如表5所示),而GM-Align僅取得62.7%(如表3所示).這不僅體現了實體名這一特征的重要性,也揭示了本文提出的特征融合方法要優于之前的模型.具體案例如表6所示.
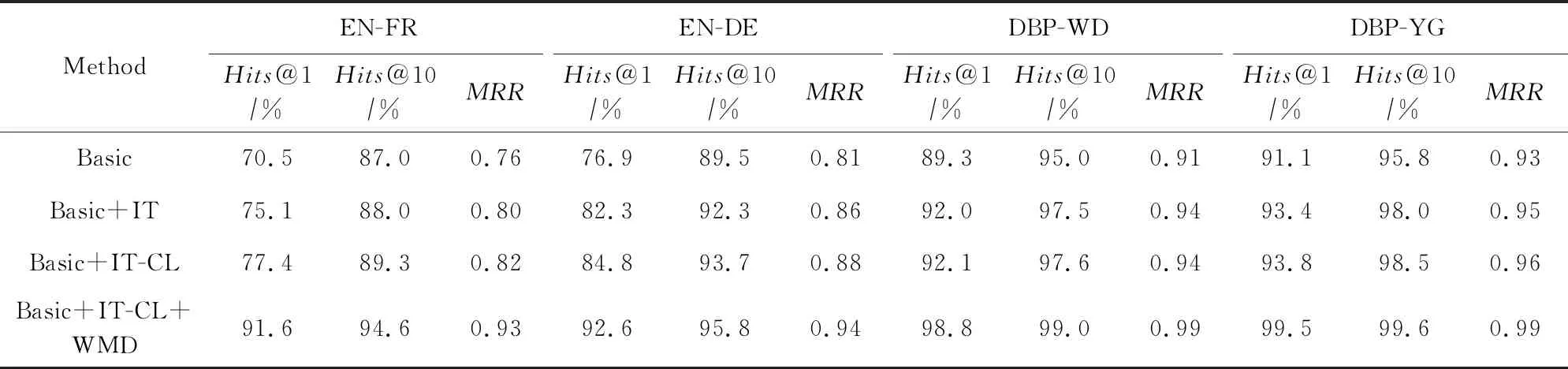
Table 5 Feature Analysis of Our Method表5 本文模型的特征分析

Table 6 Case Study of Entity Pair (Guerre De Laponie,Lapland War)表6 關于實體對(Guerre De Laponie,Lapland War)的案例分析
2) 基本迭代訓練框架(Basic+IT).與基本實體對齊模型(Basic)相比,本文提出的迭代訓練框架進一步提升了各項指標,證實了擴增訓練數據對整體對齊效果產生的正面影響,以及高置信度實體對選擇方法的有效性.
3) 基于課程學習的迭代訓練框架(Basic+IT-CL).與基本迭代框架(Basic+IT)相比,課程學習策略在EN-FR和EN-DE數據集上帶來了超過2%的Hits@1值提升,證明其能使得迭代訓練模型達到更優的效果.而其在單語言實體對齊數據集上的效果則不太明顯,因為單語言數據集中絕大部分實體在前幾輪便被添至訓練數據中,而改變加入順序對整體結果影響不大.
4) 基于詞移距離的重排序模型(Basic+IT-CL+WMD).最后,與基于課程學習的迭代訓練框架(Basic+IT-CL)相比,基于詞移距離的重排序模型使得Hits@1指標有了顯著提升,特別是在跨語言實體對齊數據集上.這驗證了進一步挖掘實體名信息確實能帶來對齊準確率的提升.至此,所有數據集上的各項指標均達到了90%以上,展現了本文提出方法性能的優越性.
由上述分析可見,與當前其他方法相比,本文提出的基本實體對齊模型、基于課程學習的迭代訓練框架以及基于詞移距離的重排序模型均能帶來實驗結果的提升.其中結合了實體名信息的基本實體對齊模型帶來的效果提升最為明顯(奠定了基礎),而其他幾個模塊(特別是基于詞移模型的重排序)則進一步大幅優化對齊結果.此外,使用詞移距離模型,迭代訓練策略等算法帶來效果提升的具體量化分析可參見表5的實驗結果.而本文代碼(4)https:github.comDexterZengCL也已公開供讀者復現與驗證.
6.6 案例分析
通過案例分析進一步揭示各個模塊對最終結果的影響.如表6所示,以En-Fr數據集中的(Guerre De Laponie, Lapland War)實體對為例,分別給出只使用結構特征(Our-SE)、只使用實體名特征(Our-NE)、基本對齊框架(Our-Basic)以及整體框架(Our Method)生成的與Guerre De Laponie最接近實體.通過結果分析可知,Our-SE旨在找到與Guerre De Laponie(Lapland War)相關的實體,但并不知道尋找方向,因此返回的最相關結果中既包含戰役,也包含軍事行動以及有名軍官.Our-NE則抓住了關鍵詞Guerre(War),因此其生成的最相關實體的名字中均包含War,但這些戰役大部分甚至不是在第二次世界大戰發生.
充分結合結構特征與實體名特征,Our-Basic將Lapland War排到了第2,因為其既與第二次世界大戰相關,本身也是1次戰役.但Our-Basic仍將錯誤實體Siege of Malta(World War II)排到第1.這個錯誤進一步被后續基于課程學習的迭代訓練以及詞移距離模型消除,而本文提出的方法最終為Guerre De Laponie找到正確的對應實體Lapland War.
此例充分展現了本文提出的實體對齊框架能夠有效結合不同特征及策略,以提升實體對齊的準確率.
7 總 結
針對知識圖譜結構信息在真實世界數據集上匱乏的問題,本文將不受實體節點度數影響的實體名信息與結構信息結合,構建實體對齊基本框架.此外,注意到標注數據的不足限制了模型效果,設計基于課程學習的迭代訓練方法,由易至難地擴增訓練數據,提升對齊準確度.最后,在前2步基礎上,利用詞移距離模型進一步挖掘實體名信息,對前序結果重排序,進而生成最終的對齊結果.該模型在廣泛使用的實體對齊數據集上取得了最好的效果.
后續工作將主要研究關系對齊、融合降噪等知識圖譜對齊的余留問題,并構建高效可行的知識圖譜融合系統.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
