一種基于K-Core獲取進程流行度識別異常進程的算法及仿真
2020-07-17 07:12:38李智宏王瑤
科技創新導報 2020年14期
李智宏 王瑤
(中國移動通信集團海南有限公司 海南海口 570125)
近年來,大規模網絡攻擊和信息安全事故層出不窮,涉及的領域越來越廣,造成的危害也越來越大[1]。2006年末,“熊貓燒香”事件轟動全國,進近兩個月的時間,病毒感染無數門戶網站,上百萬臺電腦感染,凡是中了病毒的電腦,頁面上都會顯示一張熊貓手中握著香的圖片[2]。2010年7月,“震網”(Stuxnet)蠕蟲攻擊事件浮出水面,震網病毒感染了全球超過20萬臺電腦,摧毀了伊朗濃縮鈾工廠1/5的離心機,只靠U盤傳播的震網病毒,破壞了伊朗的核計劃[3]。2017年5月“WannaCry”勒索病毒肆虐,短短一個月的時間就席卷全球150多個國家,中毒者要支付大量贖金來解鎖自己的電腦文件,如果沒有備份,只能乖乖支付贖金,或者放棄治療,經濟損失高達80億美元[4]。網絡攻擊和安全事件已經逐步由黑客炫耀技術轉變為黑客對經濟利益的追逐,轉變為國家之間綜合實力的競爭。
無論是病毒、木馬還是蠕蟲,絕大多數的入侵行為都是通過攻擊特權進程或者創建特權進程來破壞業務系統的安全性,特定進程通常需要完成有限的、特定的、惡意的行為,因此其行為在時間和空間上比其他業務程序更加異常,如不會像系統進程、業務進程一樣在絕大部分主機上存在,只在被入侵的主機上少數存在。基于此,本文介紹了一種基于K-Core來對進程流行度進行排序的算法,根據流行度獲取業務系統主機進程白名單庫及疑似惡意進程庫,來幫助用戶識別主機異常進程。
1 背景及研究現狀
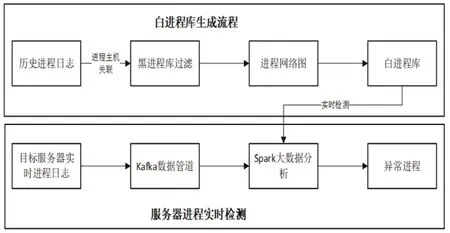
圖1 異常進程檢測流程圖
進程是系統動態執行操作的基本單位,服務器中的進程不僅是程序的動態實現,還包括對資源的調度和分配活動。服務器中任何惡意程序的執行都會啟動相應的異常進程,如木馬病毒、蠕蟲、僵尸網絡和DDoS攻擊等惡意攻擊都會事先在服務器中安插后門進程。如果能在惡意程序執行初期檢測出服務器中的相應異常進程,并采取一定的措施,就能避免遭受更大的損失。
目前對網絡攻擊的主要防護手段是防火墻和入侵檢測技術。防火墻作為內網和外網的一道警戒線,有效地阻擋了大部分的惡意攻擊。但防火墻的功能具有較大局限性,它的防御策略是靜態的,且只能阻擋來自于外網的攻擊。入侵檢測技術有效的彌補了防火墻的缺陷,它可以監控主機狀態以判斷用戶行為是否正常。進程監控是網絡安全技術的重要實現環節,許多入侵檢測系統和殺毒軟件都會有監控主機進程的功能。然而入侵檢測技術對于異常進程檢測的時效性較差,且忽略了進程的全局特性。

圖2 異常進程檢測流程
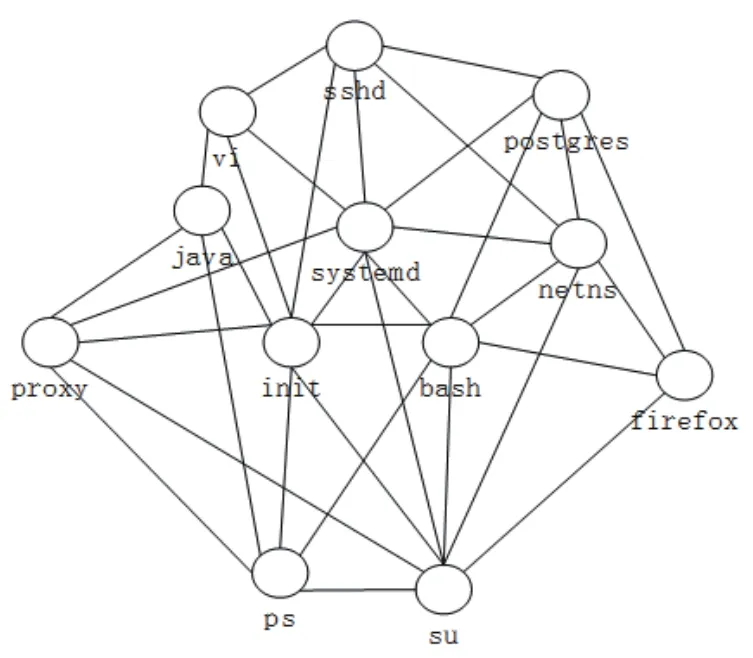
圖3 進程網絡圖

圖5 進程無向圖

圖7 原始進程無向網絡圖
針對現有異常進程檢測技術和工具存在的缺陷,本文的目的在于提供一種檢測服務器中異常進程的方法與裝置,提高異常進程檢測的時效性。具體解決的技術問題如下。
(1)部署采集器,采集目標服務器中的進程日志;
(2)基于黑進程庫對歷史進程日志進行篩選,隨后采用K-Core算法訓練,通過劃定閾值產生白進程庫;
(3)基于白進程庫,利用大數據平臺對目標服務器中的進程日志進行實時且高效的合法性判決。
2 一種基于K-Core的異常進程檢測的算法

圖4 K-Core算法分解示例圖

圖6 進程流行度分析運算圖
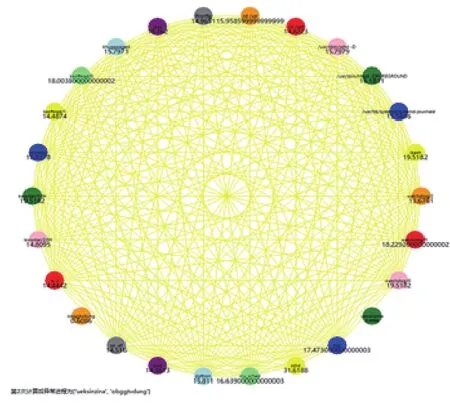
圖8 執行兩次過程圖

圖9 執行25次結果圖
本文介紹一種自動對采集到的進程按照流行程度進行排序的算法,該算法能夠自動生成進程白名單和疑似異常進程,有效擺脫了“過分依賴人”束縛的同時,能夠有效應對大數據和云計算發展過程中設備數量眾多帶來的進程數量巨大的問題。

表1 主機-進程統計表

表2 進程關聯統計表
2.1 異常進程檢測流程
本文提出一種主機異常進程檢測算法(見圖1),并將算法封裝成一種檢測裝置。整個裝置分為兩個白進程庫生成和異常進程實時檢測兩個單元,第一個單元是根據歷史進程數據,自動生成進程流行度序列,基于序列生成進程白名單和疑似名單,第二個單是對實時采集進程進行實時檢測,識別出疑似異常進程。
2.2 異常進程識別功能模塊介紹
本文提出的異常進程檢測裝置包含四大功能模塊,分別是進程日志采集模塊、白進程庫生成模塊、進程日志傳輸模塊以及異常進程檢測模塊。
2.2.1 進程日志采集模塊
監控服務器關于內核的偽文件系統中的進程信息文件夾,并實時將內核創建的進程寫入進程日志文件,進程信息包括進程的創建和銷毀、進程的運行狀態和運行時間、資源占用情況和進程訪問網絡資源情況。
設置時間窗口定時獲取服務器中所有進程的快照并寫入進程日志文件,所述進程包括系統進程、第三方服務程序啟動的進程和用戶啟動的進程。
2.2.2 白進程庫生成模塊
首先,根據黑進程庫對進程歷史日志進行篩選,過濾出顯著的異常進程。針對剩余進程日志,構建如圖3所示的進程網絡圖,在服務器中比較流行的進程對應的頂點在進程網絡中的重要性較高。因此找出服務器進程網絡中的重要頂點,即可找出服務器中的合法進程,進而建立白進程庫。具體檢測流程如圖2所示。
利用K-Core算法計算進程網絡圖各頂點的Core值,Core值高于閾值的頂點對應的進程為合法進程,并寫入白進程庫,步驟如下:
(2)找出網絡中“度值”最小的頂點,其“度值”為k,然后取,然后依次剪除度為k的節點,這些被剪除的節點對應的K-Core值為;
(4)重復步驟(2),直到網絡中所有節點均被剪除,即可得到頂點的重要性分組。
2.2.3 服務器進程日志傳輸模塊
利用數據管道如Kafka,從目標服務器獲取進程數據并傳輸到大數據分析平臺。如圖4所示,實時輸入目標服務器的所有進程數據,經過Kafka傳輸,Spark大數據平臺分析,然后向用戶實時輸出異常進程的相關信息。
2.2.4 異常進程檢測模塊
在大數據平臺上利用白進程庫實時檢測目標服務器異常進程,并從服務器進程日志中抽取異常進程的特征信息,包括進程啟動時間、運行時間、資源占用情況、狀態、文件關聯和用戶關聯信息等。
3 算法仿真及實驗結果
在上文提到的四個模塊中,白進程庫生成模塊是本文的核心,為了更便于理解這一部分將已一個示例說明異常進程及白名單庫生成的全過程,并利用python對采集到的進程樣本進行仿真實驗。
3.1 基于K-Core算法識別異常進程示例
兩個進程若存在在同一臺主機上,說明進程有聯系,統計所有兩兩進程同時出現的次數,如表2所示。
根據表2繪制對應進程無向圖如圖5所示。
利用K-Core[5-8]對進程流行度進行排序(見圖6),首先排除在外的是E節點,E節點排除后還要考慮對其他進程節點的影響,本文中按照70%的影響因子計算刪除節點對其他節點的影響。
經過K-Core算法計算后主機進程重要性排序為(A、C)、D、B、E。大部分主機都存在的是系統進程、業務進程的可能性較高,而只有少部分主機存在的進程為異常進程的可能性高,基于這個原則,設定一定的閾值,將重要性排序靠前的納入進程白名單庫,而重要性排序靠后的納入疑似異常進程庫,告警進行人工核實。
3.2 python仿真結果
為了驗證算法的有效性,本文挑選一個25臺服務器規模的小型業務系統,25臺服務器共采集到503個進程采集其進程進行利用python進行效果仿真,實驗結果如圖7~圖9所示。
最終試驗結果顯示,該小型業務系統流行度較高的進程為bash、kworker、watchdog、kthreadd這些為系統進程,因此納入白名單庫。而流行度較低的疑似異常進程為ueksinzina、obggtvdung這種只有少數兩臺管理服務器才安裝的業務進程,雖然在本文中不是異常進程,但是在大型應用場景,該類只有少數主機才存在的進程需要納入疑似異常進程進行人工核實。
3.3 仿真結論
經過仿真實驗,可以看到本文提出的識別異常進程的算法具有一定的可行性,能夠對業務系統主機進程根據流行程度進行排序,重要性排序靠前的進程的確為業務正常進程,重要性排序靠后的進程雖然不是異常進程,但是流行程度較低。
本文提出的基于K-Core主機異常進程識別算法的與現有技術相比,具有以下幾個先進性,首先文章將圖計算方法應用于服務器異常進程檢測,其次可通過無監督的方式產生服務器進程白名單庫以及疑似異常進程庫,最后結合大數據平臺能夠實時分析大量服務器上的進程日志并提取異常的進程相關信息。
4 結語
本文介紹了一種構建“服務器—進程”的網絡拓補圖,并基于K-Core算法對主機節點流行度進行排序構建進程白名單和識別異常進程的算法,并提取小型業務系統主機進程對算法進行驗證,實驗結果表明本文將圖計算方法應用于異常進程識別,算法簡單有效,能夠準確識別流行度較高的業務進程、系統進程,并發現流行度較低的疑似惡意進程。
目前算法僅在小型業務系統進行驗證,隨著云計算、物聯網技術的發展,主機規模成倍劇增,下一步作者將進一步研究將算法應用于大量服務器進程日志場景中。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
中國外匯(2019年20期)2019-11-25 09:54:58
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
海峽科技與產業(2016年3期)2016-05-17 04:32:12
民主與科學(2014年3期)2014-02-28 11:23:03
