親緣關系預測系統
2020-07-15 13:31:12王鑫,李悅,文豪,范虹*,劉京*
生命科學研究 2020年3期
關鍵詞:系統
王 鑫,李 悅,文 豪,范 虹*,劉 京*
(1.陜西師范大學計算機科學學院,中國陜西西安710119;2.公安部物證鑒定中心北京市現場物證檢驗工程技術研究中心現場物證溯源技術國家工程實驗室,中國北京100038)
目前,我國親緣關系鑒定大多使用常染色體短串聯重復(short tandem repeat,STR)遺傳標記位點[1~3]。在刑事偵查領域,通過對Y-STR進行檢驗,可以開展家系排查和輔助父系親緣鑒定,從而為案件偵查提供線索[4]。遺憾的是,Y-STR只能針對父系親屬,無法對母系親屬進行排查[5],而近年來半同胞、舅甥、姑侄等復雜親緣關系鑒定訴求不斷增加,現有的鑒定方法已遠遠無法滿足物證鑒定的需要。隨著全基因測序技術的發展,使用全基因單核苷酸多態性(single nucleotide polymorphism,SNP)數據進行親緣關系預測的技術應運而生并快速發展[6~7],解決了當下遇到的這一難題。該技術旨在通過親緣關系預測算法,基于全基因SNP測序數據計算某個群體中所有存在的親緣關系對。
早在2011年這些親緣關系預測算法就已經有報道[8],且這些軟件如Plink/KING均為國外免費開源軟件。Plink是一款用于基因組關聯分析的開源軟件,具有基因組數據格式轉換、基礎基因組信息統計、LD(linked dimorphisms)計算、共祖片段IBD(identical by descent)距離計算等功能[9],在親緣關系預測中主要使用該軟件進行數據歸一化處理,為后續算法軟件提供原始輸入文件。KING是一款使用全基因SNP數據精確推斷任何一對個體親緣關系等級的軟件,可計算高達4級的親緣關系,支持接受Plink轉換后的二進制格式文件[10]。
然而,這一技術的原有預測流程十分繁瑣,需要對全基因組數據進行預處理,并使用Plink軟件將文件轉化為二進制,再使用KING軟件計算出親緣關系等級;如果需要知道其實際親屬關系,還要按照親緣關系等級判斷方法逆向還原。鑒于此,本文提出并開發了一套具有極強交互性的分析系統——親緣關系預測系統(Kinship Prediction System Version 1.0,KPS v1.0),該系統的處理流程界面化、自動化、簡單化,可以自動預處理全基因組數據,并將最終結果自動繪制成家譜圖。
KPS v1.0極大地簡化了親緣關系預測的流程,不需要操作人員熟練掌握數據處理腳本語言和生物信息學軟件,顯著降低了操作難度,提高了分析效率,為物證鑒定工作提供了更好的服務,在人類遺傳學、法醫遺傳學等領域有重要的應用價值。
1 KPS v1.0簡介
1.1 系統開發平臺和運行環境
軟件開發平臺為Ubuntu 18.04操作系統,Python語言v3.6版本,運行環境為安裝了瀏覽器的Windows 7及其以上操作系統。
1.2 系統設計思路
KPS v1.0親緣關系模塊主要涉及前端界面和后臺計算兩大部分。后臺計算主要是基于Python語言將4個功能進行模塊化串聯設計并編程,包括輸入數據格式預處理、基于Plink軟件的數據二進制轉換、基于KING軟件的親緣關系等級計算、親緣關系等級與實際親屬關系的轉換等。前端界面包括了批次名稱錄入、數據錄入、數據類型選擇、檢測平臺選擇、親緣關系結果查看等功能。具體結構如圖1所示。后端部分的模塊化串聯設計可以降低程序的耦合度[11],簡化程序設計、調試和維護等操作,前端界面易于用戶使用和直觀查看結果。
1.3 系統實現
1.3.1 親緣關系預測方法

圖1 親緣關系模塊流程圖Fig.1 The kinship module flowchart
親緣關系預測是通過計算全基因SNP數據的共祖片段大小判斷親緣關系的遠近[12]。KPS v1.0系統主要基于KING軟件計算親緣關系等級,并根據親緣關系等級圖推導其實際親屬關系。本系統中親緣關系分為4級,親緣關系等級圖如圖2所示。親緣關系等級判斷方法:父母子女之間的親緣關系為一級,兩兩個體親緣關系等級為每個個體到共祖父母親緣關系的加和[13]。
1.3.2 親緣關系等級計算
當系統輸入完成后,前端會將輸入數據傳遞給后臺,后臺只需新建一個Celery[14]任務,并將其放置到Redis[15]任務緩沖隊列末尾,此時多核CPU會同時從隊列中讀取任務并執行,用戶提交完任務即可隨時在任務列表中查看任務狀態。任務處理示意圖如圖3所示。
每一個Celery任務都會定義一個親緣關系計算函數,并保存該任務的輸入數據。親緣關系計算函數首先根據批次數據類型的不同調用不同的接口,并基于pandas庫[16],將批次文件與相應的檢測平臺索引文件轉化為MAP和PED格式[17]文件,接著自動調用后臺腳本(集成了Plink和KING軟件),基于數據預處理結果計算得到本批次親緣關系等級對,并將其寫入服務器指定文件。
1.3.3 系統輸入與輸出
系統輸入需要用戶填寫新建任務的批次名,選擇批次文件的數據類型和檢測平臺,并上傳批次壓縮包文件。其中檢測平臺有兩種,對應兩種SNP索引文件,每個文件保存多個SNP位點信息。數據類型也有兩種:個體數據和原始數據。原始數據為個體基于某種檢測平臺測序直接得到的堿基對序列文本;個體數據為個體基于某種監測平臺測序得到的基因型表格文件,直觀展示了個體在某個SNP位點處的基因型。上傳的批次壓縮包文件包含多個個體的測序數據,所有測序數據格式保持一致。

圖2 親緣關系等級圖Fig.2 The kinship degree tree
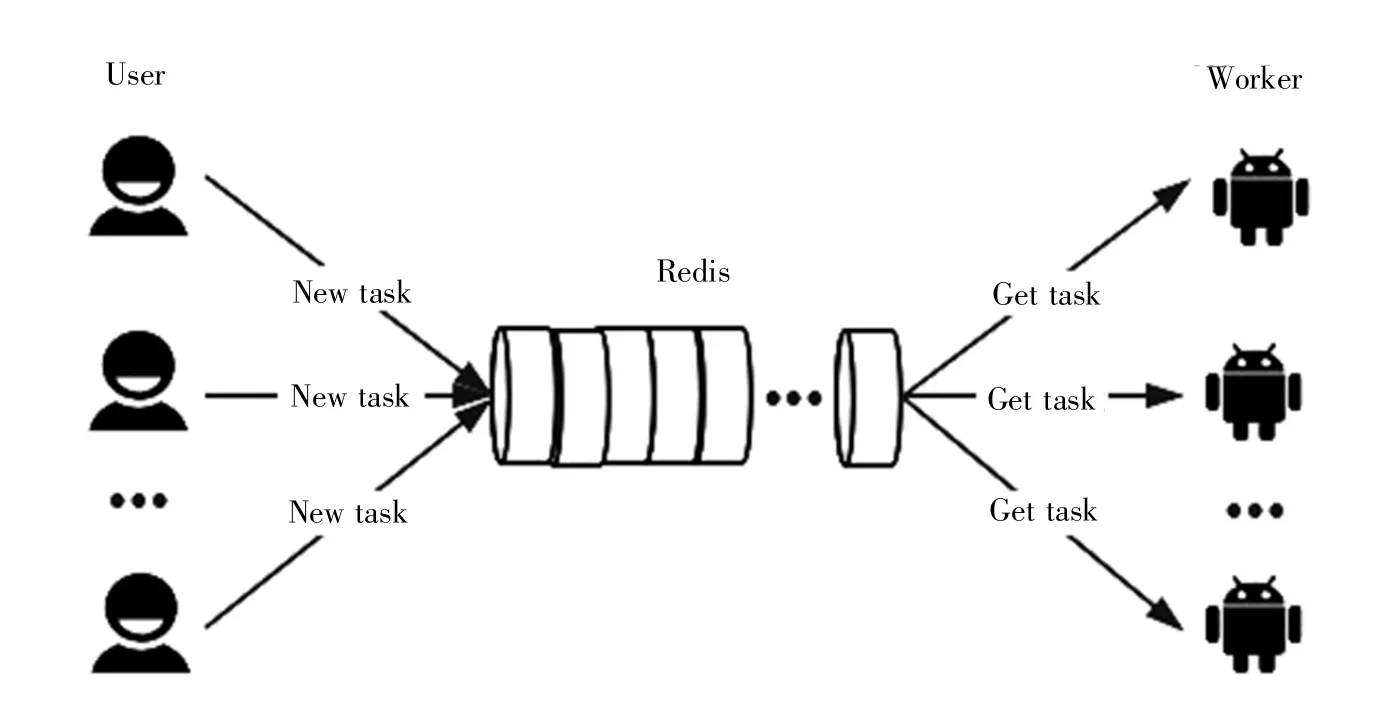
圖3 任務處理示意圖Fig.3 Task processing diagram
任務計算成功后,用戶可在頁面查看親緣關系對列表,列表中顯示批次中所有存在的親緣關系對及其對應的親緣關系等級,點擊某一對親緣關系,系統會自動基于親緣關系等級圖計算這對樣本可能存在的實際親屬關系,并將結果繪制為家譜圖供用戶直觀查看。
1.4 系統特點
KPS v1.0包含以下5個方面的特點:1)支持導入群體原始基因型數據;2)自動識別輸入批次內樣本個數,若樣本個數小于2,則運行失敗;3)若計算時發生異常,如用戶新建任務時選錯數據類型或檢測平臺,任務直接會顯示運行失敗;4)可一次性提交多個批次進行計算,自動識別電腦CPU核數,將任務自動分配到單個CPU計算,提升運算效率;5)可基于親緣關系等級計算結果自動繪制家譜圖供用戶直觀查看。
2 系統應用
2.1 樣本來源
測試樣本共計37份,來自實驗室4名志愿者家系,涵蓋1~4級親緣關系。所有樣本提供者均簽署知情同意書且實際親緣關系均基于樣本來源者自述。
2.2 系統準確性評估
將4名志愿者家族的實際親緣關系分別繪制家譜圖,與系統預測結果進行對比,比較結果如圖4所示。系統對A、B、C、D 4個志愿者家族的163對親緣關系進行了計算,預測準確率分別為92.73%、93.94%、100%、90.48%,平均準確率達到94.29%,其中一級親緣關系和四級親緣關系的預測準確率均為100%。雖然將8對二級親緣關系預測為三級親緣關系,2對三級親緣關系預測為四級親緣關系,但對總預測的163對親緣關系而言,錯誤率僅為6.13%,表明親緣關系預測系統具有可觀的準確性。
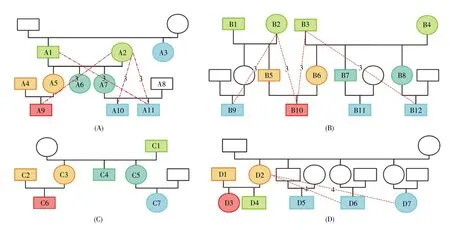
圖4 實際親緣關系與預測親緣關系對比圖(A)志愿者A;(B)志愿者B;(C)志愿者C;(D)志愿者D。圖中方框和圓圈分別代表家族中的男性和女性,檢測的個體已為其編號,未檢測的個體未編號。不同顏色代表不同的親緣關系等級(參考圖2的親緣關系等級圖),紅色標注的個體代表本人,未用顏色標注的個體為未檢測的或與本人無實際親緣關系的個體。虛線表示實際親緣關系與系統預測親緣關系不相符的親緣關系對,其上面的數字代表系統預測的親緣關系等級。Fig.4 The comparison between actual kinship and predicted kinship(A)Volunteer A;(B)Volunteer B;(C)Volunteer C;(D)Volunteer D.The boxes and circles represent the males and females,respectively.The individuals with numbers are tested,and the ones without numbers are not tested.Different colors represent different kinship degrees which are consistent with Fig.2.The individuals in red mark represent themselves,and the unmarked ones are undetected or have no actual kinship with the red-marked individual.The dotted line indicates the kinship pair whose actual kinship doesn’t match the kinship predicted by the system,and the number above it represents the kinship degree predicted by the system.

表1 系統與人工預測所需時間的比較Table 1 Time comparison between system and manual prediction
2.3 系統效率評估
在不同樣本數下,對系統的計算時間和原始人工預測方法所需時間進行了統計,結果見表1。從預測所需時間來看,系統將預測效率提升了200多倍。同時由表中數據可知,系統運行時間與一個批次內的樣本數和親緣關系對數正相關,并且更易受批次內樣本數的影響,因為系統需要計算所有樣本的兩兩親緣關系,最終輸出有親緣關系的樣本對,但人工預測所用時間主要受批次內親緣關系對數的影響,因為大多數時間主要用在最終親緣關系結果的統計與家譜圖的繪制。總之,系統的開發節省了大量人力物力資源,極大提高了親緣關系預測的效率,為物證鑒定工作提供了更好的工具。
3 討論
KPS v1.0是一個完整的Web系統,需要部署在服務器上,用戶使用只需通過瀏覽器訪問即可。系統支持多用戶使用、人臉識別登錄、個人信息管理、用戶管理、任務管理及親緣關系查看等功能。同時,系統開發完畢已打包為完整的Docker鏡像,只需在服務器上安裝Docker容器即可實現一鍵部署[18],解決了以往項目部署難的問題。目前,系統在測試完成后就部署在線上投入使用,各個功能都得到了物證鑒定部門工作人員的認可,為物證鑒定工作帶來了方便,同時也極大地提高了親緣關系預測效率,實現了系統的開發意義。
本文僅著重介紹了系統親緣關系的預測模塊。需要指出的是,KPS v1.0后臺是基于Plink和KING軟件計算的,系統最終計算得到的親緣關系對與KING軟件計算結果一致,目的是將以前人工預處理數據的流程和人工繪制家譜圖的流程交由計算機來完成,這樣不僅節省了人力物力資源,而且大大地提升了分析效率。同時,以往每臺計算機每次僅執行一個批次計算,一直要等到計算完畢才可進行下一批次的計算,這樣大大浪費了多核CPU的資源,而KPS v1.0使用異步任務處理機制妥善解決了這一難題,保證每臺計算機可以并行處理多個批次計算,達到CPU最高利用率,用戶提交完批次無需等待,不僅可隨時查看批次計算狀態,還可直接計算下一批次,這樣使計算效率得到了質的提升,并且也方便了用戶使用。
值得注意的是,目前國內對親緣關系這一方向的研究甚少[13],而KPS v1.0的親緣關系計算軟件也大都來源于國外,在部分國內人群中的應用可能具有一定的局限性;同時,KPS v1.0系統只是針對本項目組前期采集的四大志愿者家族的37份測試樣本進行了測試,結果雖然很可觀,但無法直接用來推斷實際案件,直接確定嫌疑人,只能作為參考,輔助物證鑒定工作。
總之,KPS v1.0使用簡單,界面直觀,顯著降低了使用門檻,而且將多種流程實現了程序自動化,幫助物證鑒定工作人員提高了計算效率,在人類遺傳學、法醫遺傳學中為更多研究人員/分析人員提供了方便。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
