基于Hadoop的大數據處理系統分析與研究
2020-07-09 22:13:09盧愛芬
現代信息科技 2020年2期

摘? 要:針對當前很多醫院或者企業在面對龐大數據處理過程中存在能力缺乏的問題,研究提出基于Hadoop的數據分析系統,該系統能夠用于醫院輔助診斷以及數據比較分析,同時該系統融合多節點分布式計算技術,能夠依據醫院患者醫檢結果生成初步診斷結果,可顯著改善傳統醫療過程中數據信息處理效率較低的問題。
關鍵詞:Hadoop;大數據處理系統;大數據分析
中圖分類號:TP311.13? ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)02-0109-03
Abstract:In view of the lack of ability of many hospitals or enterprises in the process of huge data processing,this paper proposes a data analysis system based on Hadoop,which can be used for hospital auxiliary diagnosis and data comparative analysis. At the same time,the system integrates multi node distributed computing technology,it can generate preliminary diagnosis results according to the medical examination results of the patients in the hospital,which can significantly improve the low efficiency of data information processing in the traditional medical process.
Keywords:Hadoop;big data processing system;big data analysis
0? 引? 言
近年來,互聯網技術以及計算機技術的發展,在一定程度上改變了人們的日常生活和工作方式,使人類社會逐漸進入了大數據時代,使醫療信息化逐漸加速,根據有關部門統計數據顯示,在2018年,我國醫療信息化建設共投入資金300多億元,同時多種醫療信息數據量擴大,且呈現爆炸增長的方式,過去主要是通過數據倉庫的方式進行儲存,相應的醫院信息系統由于受到硬件等多種因素的影響,對于一些數據量較大的非結構化數據在處理過程中很容易出現問題,無法獲得良好的儲存能力和計算效果。因此本研究在當前大數據背景下設計了Hadoop的數據分析系統,能夠更好地幫助企業或者醫院實現數據整合加工和定性分析。
1? 大數據及其處理技術
最早的大數據是由全球麥肯錫公司提出的,大數據是指能夠超出常規數據庫或者數據處理能力,被迫采用一些非常規方式的數據集,同時大數據具備四大特點,包括較大的體量、處理速度較快、具有多種類別、具有較強的可靠性,能夠通過分布式可擴展儲存的方式實現數據的管理查詢,目前很多研究機構雖然已經具備大量數據,然而由于缺乏高效分析手段,同時數據倉庫維護過程的成本逐漸升高,因此目前很多企業廣泛應用基于Hadoop結構的分布式文件系統。Hadoop是一種大規模數據處理的重要分布式系統架構,其核心為MapReduce編程以及HDFS的編程模式,其中HDFS是一種主/從式架構,具有較強的容錯性。在普通的PC端大量部署,進而能夠實現多數據節點對大量數據集的分塊儲存有效管理,除此之外,HDFS能夠為系統提供一次訪問,寫入多次讀取的模式,確保數據一致性,能夠適用于當前處于大數據時代背景下高吞吐需求,而MAP和Reduce是由谷歌研發的一種重要分布式程序模型,是通過化簡和映射這兩個環節來實現大數據處理,首先在映射函數中不改變原有數據的前提下,能夠將大文件切割形成的小文件構建獨立元素實現逐步映射,并創建多種列表實現映射,將處理結果保存之后可以利用化簡函數將所映射出的文件根據函數值進行合并或者縮減,將大量不同結構或不相關數據進行特征提取后,將結果保存至指定的途徑中。
2? 系統結構設計
針對當前醫院實現數據信息化建設的情況,本研究提出的大數據分析系統框架主要由三個部分構成,分別是數據層、訪問控制層和應用層,其具體的系統結構功能如下:在該結構中,根據層次結構原則,數據層是最底層,可將現有數據系統所提交的文件通過切割的方式保存至Hadoop數據節點中,進而能夠有效控制文件分片管理和負載;中間層為控制訪問層,主要是由命名節點命名各種文件和數據節點關系以及空間鏡像之間的關系,運算中心可以通過節點調取的方式提供重要的原數據信息,能夠對原數據進行映射化簡處理,指導相應的文件進行讀寫,并將處理結果反饋到應用層中;系統最高層為應用層,可為用戶提供文件界面,窗口用戶通過該界面能夠下達訪問控制層指令,并接收系統最終提交的輔助診斷報告和分析結果。
3? 系統功能設計和實現
該系統與傳統的信息系統,如果兩者能夠實現協同運行,對現有單節點數據庫儲存多種數據方式及分布式儲存管理,通過運算中心調用的映射化簡算法,進而能夠對龐大數據實現高效分析處理,以及為醫生提供確切的輔助診斷信息。從數據儲存功能來看,數據層是安裝了一系列Linux系統,由普通PC端和現有信息化系統數據庫共同構成的,由于Hadoop分布式文件系統在眾多由PC端所構成的節點群中運行,所以能夠對原有數據實現分布管理導入。
當前很多醫院采用的信息管理系統是由電子病歷系統、影像歸檔系統共同構成的,其中電子病歷系統可用于患者基本情況檢查結果、診斷結果等一些結構化數據的儲存,而影像歸檔系統可用于多種數字影像,聲音等非結構化的數據的儲存。在Hadoop項目中,除了HDFS和映射化簡編程模型之外,還包括非結構化數據基礎所構架的hive以及非關系數據庫HBase,傳統數據儲存倉庫與HDFS之間重要的數據導入工具及Sqoop等模塊。
在利用分布式處理原始醫療數據之前,首先需要進行節點命名并安裝HBase以及hive,利用Sqoop工具能夠將所提供的Java API與現有的數據庫進行有效連接,導入多種數據之后,判斷其是否屬于結構化數據,如果系統判斷其為結構化數據時,可以利用Sqoop工具通過接口進行hive的連接,然后判斷數據查詢與數據對應的列表是否存在,如果不存在則需要創建新表進行hive的儲存,如果該列表已經存在,需要有系統自行判斷數據量是否超過額定值,如果沒有超過額定值可以直接進行儲存,如果超過需要進行分區再次存入。當所儲存的數據為非結構化數據時,可以利用Sqoop工具通過JDBC接口與HBase進行連接,提交插入后得到請求響應之后能夠對Base表進行掃描和定位插入,同時實現時間設置,能夠將數據插入特定的HBase數據庫中,數據寫入HBase的具體步驟為:由客戶端開發庫啟動相應的數據節點,并向上層命名節點發起請求,命名節點會檢查所創建的文件是否存在,或者具體創建人員的使用權限,一旦檢查成功會為其創建文件,如果檢查失敗會提出異常報警信息,當RPC獲得請求響應之后,由客戶端開發庫將所需要寫入的文件切割成多種小文件,之后再向命名節點申請blocks,能夠將HDFS與本地文件數據快實現映射列表,并且通過報告的方式提交命名節點,該命名節點之后能夠向客戶端返回數據節點的配置信息,由客戶端根據節點地址IP管道的方式,按照順序寫入相應的數據塊節點中,當HDFS寫入全部的原始數據后,命名節點能夠將所有數據信息,包括文件屬性、塊列表、數據結點與列表之間文件之間的關系,提交到相應的運算中心中,此時運算中心可以根據所設計的算法模式對該文件進行讀寫和分析。
在數據儲存以及數據庫設計過程中,基于Hadoop的大數據分析系統在數據儲存過程中主要利用HBase數據庫,同時在儲存數據庫時能夠按照一定標準完成數據庫設計,為后續實現數據庫擴展奠定基礎。在hive數據庫中相對應的數據表能夠按照內部、外部表形式儲存,由于hive在內部數據表創建過程中,可將目標數據信息移動到指定路徑,并刪除相對應的內部數據,因此,這對于數據的錯誤操作保護以及安全性來說是有利的。本研究中我們按照用戶信息表創建進行hive儲存方式創建。具體的代碼如下所示:
Create? external? table? ? ?//創建外部數據存儲表
User_info(user_id? int , user_name? string ,
user_password? string )? ? ?//指定關鍵詞和存儲類型
Row? format? delimited? ? //指定行格式限定
Fields? terminated? by ,? ?//指定分隔符
Stored? as? textfile? ? ? ?//指定文件存儲類型
Location? ‘/data/report/ user_info;? ? //指定文件存儲位置
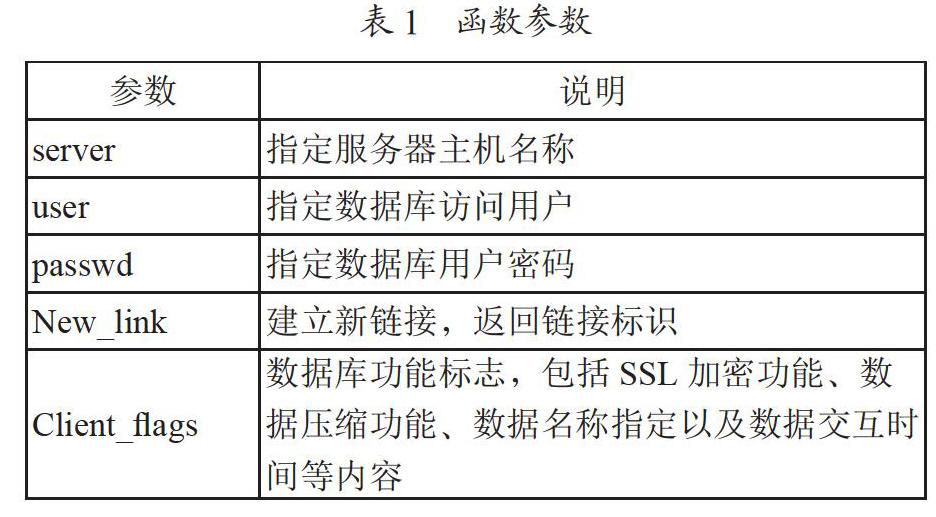
完成上述代碼執行之后,需要將指定文件上傳到相對應的文件夾中,然后系統能夠自動生成統一路徑,每一個hive儲存數據表有唯一路徑,在后續數據改變時只需要找到相對應的文件夾就可完成操作。在數據庫部署過程中,大數據分析系統中數據庫選擇和充電是重要的環節,數據庫是一種數據儲存的重要程序,其與API是一種獨立的且可用于數據的儲存訪問。在本研究中,我們以數據庫作為數據管理系統,首先在數據庫安裝過程中,由于該數據系統屬于開源系統,可以直接在網站下載,為便于數據庫服務器的后期管理,實現用戶訪問控制和數據庫查詢,本研究,我們采用的是MySQL RPM版本完成數據庫安裝,需要檢查其是否可正常運行,通過執行代碼ps-efl grep mysql確認其安裝的正確性,如果無法正常運行,則需要啟動下列指令:root@host# cd/usr/bin./safe_mysqld。在數據庫管理方面,為便于實現數據庫管理,需要添加數據庫用戶,通過改指令實現數據庫啟動,利用Database changed開啟寫入功能,利用寫入修改后的用戶信息,包括用戶種類、賬戶、密碼等,同時需要指定用戶權限,將其作為數據庫的管理員,包含選擇、升級等多種權限,完成用戶設定之后,可以利用選擇鍵對數據庫信息進行查詢。除這些方法之外也可以采用GRANT的方式實現用戶設置。在數據庫的鏈接中,可以安裝MySQL利用PHP的mysql_connect()指令實現數據庫鏈接,具體函數參數如表1所示。
當完成鏈接后會返回相應標志,構建數據庫連接之后需要以下指令[(用戶名)@host]#mysql-u root-p,實現數據庫用戶的指定,完成連接后會返回鏈接信息。用戶使用結束之后可以根據指令實現終端連接或者鏈接關閉。
4? 輔助診斷和數據功能的設計
在患者來醫院就診的過程中,通常需要開展一系列的醫療檢查,由于不同患者體質不同,對于同一疾病在檢查過程中也會根據患者檢查中成像數據差異進行自動診斷,因此當患者接受醫療檢查之后,還需要經過一段時間入院觀察才能夠確定最終疾病類型。具體算法順序為:首先在映射算法上,工作人員需要打開患者的電子病歷文件,并且能夠確定文件是非空集,未結束則采取循環字符串讀取的方式到變量str中,如果str為年齡,Then數據值為年齡值,當str為診斷結果時,value1為病癥名稱,我們可將(key1,value1)寫入相應的中間文件中,如果str為診斷結果時,之后key2為病癥名稱,可以將(key2,value2)作為醫療數據,可以修改str為病癥名稱和所對應的醫療檢查項目,value2是該項目對應的意見結果數據,能夠將該病對應的一些項目分別形成key2和value2,并寫入中間文件中。在化簡算法中需要首先創建hash表ht,當k值為整數時,key與key1對應年齡段以及value1等于value+1,將其寫入ht中,當k值為字符串類型時,此時如果value大于max,那么則有max=value,如果當key為key2時,value等于max,則此時需要將(key,value)寫入hIt中,如果value低于min時,此時min等于value等于key2,value等于min,可以將ht中的每一個(key,value)寫入最終結果分析文件中,由于映射算法提供的key值與value存在不同數值類型,而hash table可用于多種類型的key和value值的識別,需要創建hash表可用于最終結果處理。該系統進行統計分析過程中,首先需要判斷所收到的配置是否為整數,如果是整數,需要按照數值大小依次排序并歸入對應年齡中,然后對該年齡段和對應癥狀構成新的配置,判斷該值是否儲存于ht中,如果不存在則需要在ht中加入key值,如果已經存在,需要將key值對應的value值輸入,當接收到key值時,如果該值為字符串類型,判斷key對應的value值是否高于目前max最大值,如果是,則需要將max替換為value,如果判斷key值對應value值小于min最小值時,需要將min替代為value,反復進行數據比對,可實現某一疾病不同患者醫療檢查項目數據的匯總,最終能夠對所有患者疾病項目數據值區間進行提取,形成一種醫療輔助檢測模板。
5? 系統性能測試
為了能夠進一步測試該系統的運行效果,在本研究中共設置20個數據節點,隨機挑取不同年齡段的電子病例,共計5萬多份,實現數據統計分析,數據統計如表2所示。
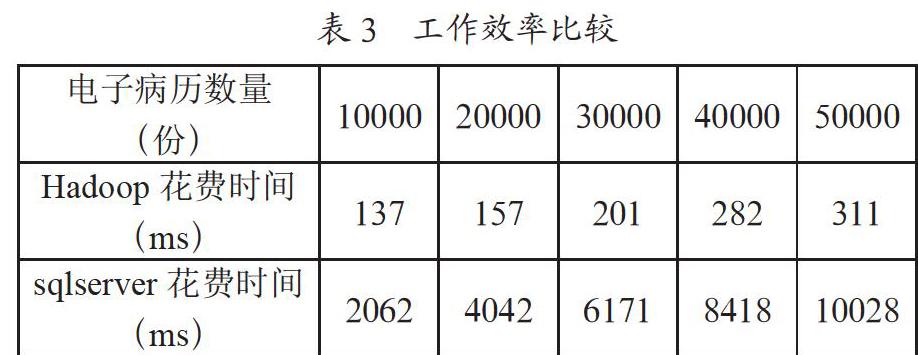
最后與醫院現有的信息化數據庫進行比較,將該系統與原有系統利用函數記錄時間實現工作效率進行比較,在數據處理過程中兩種系統比較表如表3所示。
通過實驗我們可以發現,隨著目前醫院電子病歷數量的增加,采用傳統單節點數據庫處理,耗時呈現線性關系,然而利用基于Hadoop的大數據分析處理系統時,在處理中采用分布式數據分析方法能夠顯著節約時間。
6? 結? 論
本研究提出了基于Hadoop的數據分析系統,能夠對該系統工程進行分析設計,進而該系統運用到醫療系統時可為醫療輔助診斷提供可操作性的映射。簡化上,相比原系統來說能夠簡化診斷流程、實現龐大數據的快速處理。最后通過實驗驗證的方式證明該系統相比傳統單一節點數據庫具有較高的運行效率。
參考文獻:
[1] 陳臣.基于Hadoop的圖書館非結構化大數據分析與決策系統研究 [J].情報科學,2017,35(1):24-28.
[2] 王衛鋒,楊林.基于Hadoop的郵政寄遞大數據分析系統設計與實現 [J].中國科學院大學學報,2017,34(3):395-400.
[3] 王麗紅,劉平,于光華.基于Hadoop的對俄貿易大數據分析系統研究 [J].電腦知識與技術,2018,14(1):20-22.
作者簡介:盧愛芬(1975.09-),女,漢族,湖南郴州人,就職于軟件教研室,專任教師兼教研室主任,講師,研究生,碩士,研究方向:軟件工程。
