基于信息熵的適應性隨機測試用例生成算法分析
2020-07-09 22:13:09孫德剛
現代信息科技 2020年2期
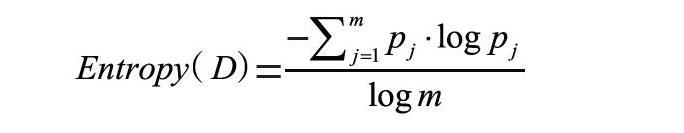
摘? 要:文章對適應性隨機測試理論基礎進行分析,并在信息熵基礎上對測試用例算法加以闡述,主要包括信息熵指標、算法應用、實證實驗三項內容,通過文章研究可知,Entropy算法與其他算法相比,無論在高維還是低維空間情形下,均具有良好的失效檢測能力。
關鍵詞:信息熵;適應性隨機測試;算法
中圖分類號:TP301.6? ? ? 文獻標識碼:A 文章編號:2096-4706(2020)02-0030-02
Abstract:This paper analyzes the theoretical basis of adaptive random testing,and explains the test case algorithm based on information entropy. It mainly includes three items:information entropy index,algorithm application,and empirical experiments. According to the research in this paper,Entropy algorithm and other compared with the algorithm,it has a good failure detection ability in both high-dimensional and low-dimensional space situations.
Keywords:information entropy;adaptive random test;algorithm
0? 引? 言
在信息時代背景下,計算機軟件在技術產業得到廣泛應用,對軟件質量與可靠性提出嚴格要求,軟件測試的地位不斷提升。在軟件測試過程中,測試用例選擇十分重要,對測試效果具有直接影響。對此,應盡量采用典型用例,在信息熵的基礎上采用適應性測試用例,引入FSCS-ART經典算法,提高揭錯能力。
1? 適應性隨機測試的理論基礎
1.1? 隨機測試
在軟件測試方面,隨機測試的應用范圍較為廣泛,測試時無需掌握程序中的內部結構與軟件需求,只需在輸入空間內部采用偽隨機數生成器,便可對數據點進行自動化測試,具有成本低、自動化程度高、實施簡便等特點。現階段,軟件種類不斷增加,Unix工具集、Java程序、Windows GUI應用軟件等在測試活動中得到普遍應用,還可與其他軟件測試方法綜合使用,如組合測試、回歸測試等等。隨機測試具有預測性,通過統計意義可對其檢測能力進行分析,在此基礎上的改進算法也隨之產生。
1.2? FSCS-ART算法
在隨機測試中,該方法屬于第一個具體算法,受到軟件工程領域的廣泛關注。該算法適用于輸入值為數值型的待測程序,利用用例候選策略,將候選用例與已測用例為標準,對多樣性進行判斷。在本文研究中,將該項指標定義為distance指標。據研究結果可知,在低維輸入域中,ART中的F-measure值與隨機測試相比降低,這意味著測試的失效檢測力得到極大提升。
1.2.1? distance指標
該指標的具體定義為:給定候選用例集CS,其取值范圍在c1,c2,c3,…,cs之間,以用例ci為例,指標計算公式為:
dis tance(ci)=dist(ci,η(ci,TS))
式中,TS代表的是已測用例集合;dist(ci,η(ci,TS))定義為數值程序中兩個用例間的歐式距離;η(ci,TS)代表的是在TS集合中,與ci距離最近的用例。由上述公式可知,候選用例的指標主要是與全部已測用例之間距離最小的數值,該數值越大,意味著與已測用例的距離越長,區分度也就越大。因此,在ART算法中,dis tance的數值越大,說明候選用例中的優先級越高。
1.2.2? 算法流程
在ART算法中,應將每次產生的候選用例、執行用例分別用兩個集合進行存儲,將CS與TS集合進行初始化處理。首先,從整個輸入域中選出一個用例,當執行用例中無實效情況時,可將其輸入到TS集合中,在第3~10行中循環,形成新的用例。在生成下一個用例之前,首先在輸入域中隨機生成s個候選用例,并將其存儲在CS集合中。隨機選出用例ci,i的范圍在1~s之間,對其與TS集合中用例的最小距離進行計算,得出dis tance值,將其應用到后續實測用例中。對上述流程不斷重復,直至與停止條件相符合,從而達到挖掘失效或已測用例數目預定值的目標[1]。
2? 基于信息熵的隨機測試用例算法分析
本文站在失效檢測效果的視角,在高維環境下對ART算法進行改進,提出新的算法—FSCS-Entropy算法,以此獲得更加理想的用例分布結果。同時,將信息熵與距離兩項指標引入其中,對候選用例與已測用例的分散度進行繪制,以此降低邊緣處用例優先級,使算法的失效檢測性能得到進一步提升。
2.1? 信息熵指標
該指標的主要作用在于解決信息量化度量問題,在信息工程領域應用較為普遍。在相關理論中,熵可對樣本集合純度進行衡量。假設集合D中第j類樣本占比為pj,其中j的取值范圍在1~m之間,則集合D信息熵的計算公式為:
如若集合中的樣本類型為兩種,信息熵與樣本比例之間的變化呈曲線分布。當集合內不同樣本發生概率均衡,也就是pj的數值為1/m時,集合中的信息熵數值處于最大值;當信息熵的最小值為0時,則意味著集合內部存在一類樣本,其純度較高[2]。
2.2? 算法應用
針對FSCS-EntropyA算法進行分析,在該算法正式運行之前,應事先對各相關變量進行設置,即候選用例集大小,用s表示;待測程序的輸入域,用R表示;準則k值以及輸入域維度,用d表示。在算法應用過程中,先對TS和CS集合進行初始化,隨后在程序中輸入域中隨機選擇一個數據點,將其當作首個測試的用例,在待測程序中實施。對于首個新用例來說,如若沒有發現失效情況,則在3~15行中反復循環,生成大量新用例,直至與停止條件相符合。當測試用例中均沒有成功檢測出失效時,可將其傳入到TS集合中,在生成后續用例之前,先將其輸入到域內,隨機出現s個候選用例,并將其存入CS集合內。對于CS集合來說,其中包括的候選用例均為ci,先要對集合TS中的現有用例最短距離進行計算,將其記為dis tance(ci),然后利用該指標從CS集合中對最優k個候選用例進行選擇,將其納入到CS集合中,在第10~13行的位置對CS進行遍歷。針對任意候選用例ci來說,可首先找出與之相距2d的鄰居,將其記為Top-2d(ci),按照ci與上述鄰居用例之間的距離進行計算,得出entropy指標。最后,利用CS集合中的最大entropy數值候選用例對后續測試用例進行計算。
在EntropyB算法的應用中,輸入參數、初始操作與EntropyA之間的操作相同,IE大多數流程也較為相近,二者的不同之處在于B算法主要對CS集合中的各個候選用例ci進行計算,從中找出與之相距2d的鄰居用例,用Top-2d表示,在此基礎上對鄰居用例間的距離進行計算,得出entropy指標,最后通過該指標從集合CS中選出最佳k用例,使其擁有最大值,應用到后續實測用例之中[3]。
2.3? 實證實驗
為了對Entropy算法在不同場景中的應用效果進行分析,本文提出以下實驗問題:在失效實際程序中,Entropy算法與典型ART相比測試效果存在何種區別。
2.3.1? 實驗設置
在實證實驗方面,本文采用25個經典程序,并采用Java語言進行實現,前14個程序由ACM收集算法提供,在適應性隨機測試中得到普遍應用。在高維程序中,line、calDay與complex分別對點、線段、三角形之間的位置關系進行確定。對于上述幾何程序來說,輸入參數為點坐標、線段端點,select程序是從無序數組中取出的第k個最大元素,最后程序為tcas西門子防撞系統。對于不同的實際程序來說,失效率屬于近似值,為了描述便利,采用F-measure指標對不同算法檢測效果進行衡量。
2.3.2? 失效檢測效果
對高維實驗結果進行對比可知,Entropy算法的檢測效果與ART算法相比較差。通常情況下,前者中的measure數值均小于后者的對應值,將二者的p-value進行進一步對比可知,對于大多數實際程序來說,p-value數值均超過0.05,這意味著二者在失效檢測能力方面無明顯差異。另外,在plgndr程序中measure數值為552.76、binaryGCD程序中measure數值為1345.71,Entrop算法中measure數值為845.50,但是在ART算法中,三者對應的數值分別為603.19、1626.94與998.72。由此可見,在上述程序中,Entropy算法中的measure數值低于ART算法,且p-value的數值低于0.05,這充分表明Entropy算法具有較強的失效檢測能力。此外,在低維程序中,與ART算法相比,Entropy算法的數值較低,且二者p-valur遠遠低于0.05,同樣說明該算法在低維狀態下的檢測能力。
3? 結? 論
綜上所述,在軟件測試領域中,自動化測試在操作性、效率等方面具有更多優勢。在眾多測試用例生成方式中,隨機測試更加簡單高效、易于實現,應積極將Entropy算法應用到高維或者低維空間情形中,使失效檢測效果得到進一步提升,為軟件測試開展提供充足的技術支持。
參考文獻:
[1] 李萬慶,李彥蒼.求解復雜優化問題的基于信息熵的自適應蟻群算法 [J].數學的實踐與認識,2005(2):134-139.
[2] 納春寧.基于圖像信息熵的自適應Harris角點檢測算法 [J].內蒙古農業大學學報(自然科學版),2013,34(5):141-144.
[3] 余紹蓉,尹益輝,徐兵,等.基于信息熵理論的隨機—模糊可靠性分析方法探討 [J].機械強度,2006(5):695-698.
作者簡介:孫德剛(1978.04-),男,漢族,山東德州人,高級工程師,學士學位,研究方向:教育信息化、軟件開發。
