教育領域反饋文本情感分析方法及應用研究
2020-07-09 08:20:02歐陽元新王樂天蒲菊華
計算機教育 2020年6期
歐陽元新,王樂天,李 想,蒲菊華,熊 璋
(北京航空航天大學 計算機學院,北京 100191)
0 引 言
2019 年2 月,中共中央、國務院印發了《中國教育現代化2035》,強調“因材施教”“知行合一”,其十大戰略任務之一“加快信息化教育時代變革”提出利用現代技術加快推動人才培養模式改革,實現規模化教育與個性化培養的有機結合。教學的最終目的始終是為了促進學習者的學習。不同學習者的學習需求千差萬別,如何應對學生的個體差異,真正做到“因材施教”的個性化教學(學習),一直是擺在每個教育工作者面前的課題。在面對范圍更大、層次更復雜的學習者時,如何獲得其對課程的直觀反饋,進而動態調整課程教學組織顯得尤為重要。
自然語言是人類表達信息的主要途徑之一,以自然語言表述的文本信息存在于教學活動的各個環節之中。觀點挖掘和情感分析是分析用戶觀點、反饋、評估、態度和個人情感的研究領域。過去的15 年里,作為情感計算和自然語言處理的子任務,關于主觀性和情感分析的研究已經取得了蓬勃的發展[1]。情感分析在通常情況下不會單獨使用,其結果會作為更高層次應用的一項特征輸入。情感分析技術的作用是檢測文本表達出的情感狀態。這些狀態序列可以通過模式識別的方式提取出情感變化特征,作為預測用戶情感狀態的依據。通過對課程反饋文本信息進行情感分析,可得到學生對當前課程有效的情感反饋,并以此為依據,實時調整教學方案、優化教學方法,實現更為精準化和個性化的教學。
1 教育領域反饋文本情感分析
情感指的是一種態度、想法或感性的判斷,用來描述觀點中蘊含的褒義或貶義的情感傾向。情感和觀點都是人主觀意愿的一種表達,但二者之間存在明顯的區別,觀點偏重于人對于某一個事物形成的具體看法,情感更側重于人內在的某種情感[2]。
教育數據挖掘(Educational Data Mining)是一個重要的研究領域,通過觀察學生的表現,了解學生的學習情況來改善教育環境。但是僅僅通過學期末獲得的學生成績等反饋數據,不能給已經參加完該課程學習任務的學生帶來幫助。為了使正在學習中的學生同樣受益,需要實時進行數據處理與分析,并快速給出反饋,幫助教師理解學生的學習行為和所遇到的不同問題。
教育領域反饋文本情感分析是一個致力于從反饋文本中提取情緒和觀點的任務。情感可以是消極的或者積極的,不同的情感對應于不同的意見和建議。無論是在線下還是線上課堂,教師都可以通過對反饋文本的情感分析對課堂中的情緒狀態獲得快速的宏觀了解。這些情緒信息可以輔助教師定位到課程安排、知識體系、教學方法等方面上的問題,進而改善教學質量、提高學生學習效率。將情感分析技術應用于學生課程反饋自動化分析,在緩解教師工作壓力的同時,還可有效提高教學質量。
近年來,機器學習(尤其是深度學習)方法逐漸成熟。此類方法通過對文檔進行監督訓練可以得到能夠有效預測文檔情感極性的神經網絡;使用端到端訓練方式可以快速利用大量的文本數據而不依賴人工分析;預訓練深度語言模型的興起使得所有自然語言處理任務都有了強大的語言表示模型基礎,便于構建具體的應用模型并快速投入到實際應用中。
Piryani 等人對情感分析技術的綜述文獻中有統計表明,機器學習方法在當前情感分析研究中占主導地位,約67.2%的文獻采用了機器學習方法進行研究,其余的才是基于規則與情感詞典的方法。然而教育領域的情況正相反,后者仍然廣泛地應用于教育領域研究中,并且占據了主導地位[3]。考慮到深度學習方法有數據依賴強、模型規模大、可解釋性差等先天缺點,結合傳統方法與深度學習方法可以使兩者更好地互補、發揮優勢。
2 MOOC評論文本情感分析方法
大規模開放式在線課程(MOOC)是線上教育的產物,是教育領域中的一個相對較新的發展模式。雖然與傳統教室相比,在線課程具有各種獨特的優勢和改變教育系統未來的潛力。但是,MOOC 教育模式仍然存在明顯短板[4],從教學的角度來看,大多數MOOC 使用視頻實現從教師到學生的內容傳遞,缺少教師與學生之間的直接互動,導致教師缺少視覺或聽覺上的提示來區分沮喪與熱情的學生。
大多數MOOC 提供課程論壇作為交流和學習的工具,發表與回復課程評論是學生與授課教師或其他學生互動的主要途徑。其中,課程評論是最典型的反饋文本形式。MOOC 的產生帶動了大量課程和課程評論的產生,這些評論都是學生抒發自身情感和表達觀點的載體。Tucker 等人發現,學生在論壇發言表現的情感傾向與其在MOOC 平臺的學習表現有一定程度的正相關性[5]。由于可以獲得大量的課程評論數據,針對MOOC 的數據挖掘及情感分析技術應用相對更為成熟,傳統的樸素貝葉斯、最大熵和支持向量機等技術都已被證明可以很好地與在線情感數據配合使用,也獲得了不錯的效果。MOOC 平臺使用情感分析技術,能夠基于學生用戶對課程的情感傾向判別,快速且準確地從海量評論文本中篩選出價值較高的反饋信息,進而實現用戶退課預警、個性化課程推薦等。教師則可以根據學生的反饋動態調整教學安排,以滿足學生的個性化學習需求。
2.1 實驗數據集的構建
從中國大學MOOC 收集11 個課程大類、1 768 門課程的評論數據并進行一定的人工標注,構建了一個量化的中文教育領域情感極性數據集,在此基礎上展開學生反饋文本情感分析研究。被評論課程所屬的具體領域見表1。由于語料所處的大領域與細分領域均會對情感分類中運用的自然語言處理工具產生影響,本文在數據集中融合了多種領域的文本,嘗試在跨細分領域的數據集上驗證模型的情感分類效果。
數據集中的每一個評論會有一個用戶給出的1~5 分的打分,其中5 分樣本占據了總評論數據的84%,3 分及以下評分樣本的數量僅占據總評論數據的3.8%。為了避免這種不平衡數據導致的模型偏見,從完整數據集構建相對平衡的子集用于模型的構建與訓練,具體方法如下:從用戶打分為5 分的樣本中提取了15 000 條評論作為正樣本(積極情感)數據,并對用戶打分為1~3分的6 731 條評論進行人工標注,最終篩選出負樣本(消極情感)評論4 148 條,與正樣本中的15 000 條數據共同構成實驗數據集(見表2)。

表1 MOOC 實驗數據集評論領域及評分分布
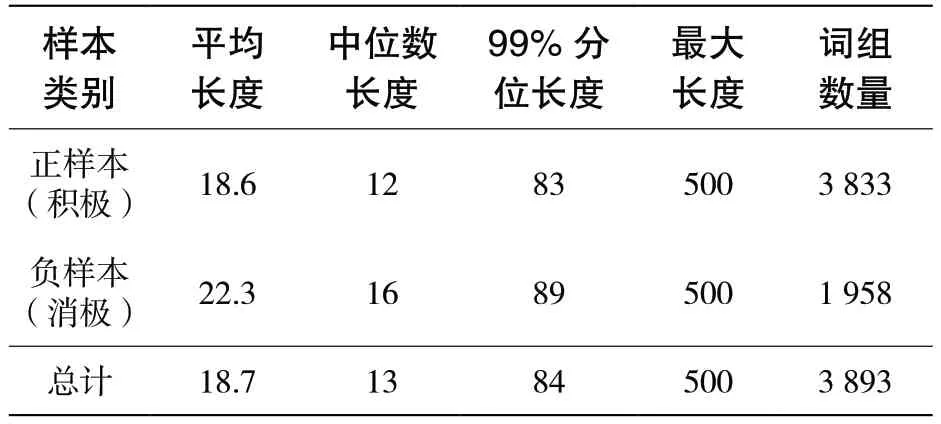
表2 MOOC 評論文本統計信息
從表2 中可以看出,評論負樣本的平均句長、中位數樣本句長與99%分位樣本句長都相比正樣本長一些,說明負樣本中潛在的語義信息更豐富,也更有可能包含對于課程改進有價值的評價與觀點。由于MOOC 平臺的限制,評論的最大長度均為500 個字符,因此樣本最大長度均為500。圖 1 所示為數據集中不同分位的文本平均長度折線圖。
2.2 基于裁切語言模型與注意力機制的情感分析方法
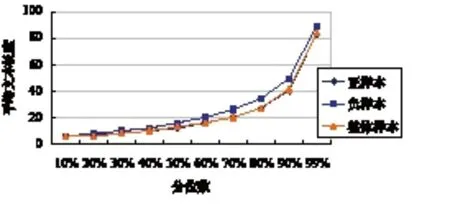
圖1 數據集中不同分位的文本平均長度
B E RT(Bidirectional Encoder Representation from Transformers)是由Google Brain提出的一種預訓練深層語言模型,訓練自BooksCorpus 與Wikipedia 語料,共計約320 億詞的文本。其架構為多層編碼器堆疊而成的棧式結構,每一個編碼器都由自注意力層、全連接層與殘差連接組成。BERT 模型性能提高的代價是愈發復雜的模型結構和陡增的參數數量,由此進一步導致了訓練、預測時間成本的增長。此外,深層語言模型生成的詞向量可能無法進一步和下游網絡進行良好的協同工作。
與其他領域公開數據集不同,MOOC 評論文本以短文本為主。此類短文本分類是一種典型的分類特征抽取任務,更適合使用簡單模型進行特征抽取。因此本文提出并訓練得到一種基于注意力池化機制的裁切BERT 與卷積神經網絡情感分析模型[6],嘗試將淺層BERT 詞向量與卷積神經網絡相結合,并在卷積操作后、池化操作前引入自注意力模塊,使得該模型結構在MOOC 評論的情感分類任務上可以達到基礎BERT 模型的效果,但模型大小與性能消耗可以大大降低,整體模型工作原理如圖2 所示。實驗結果表明,本方法在中國大學MOOC 評論文本數據集上,情感二分類(積極、消極)準確率可達92.8%。
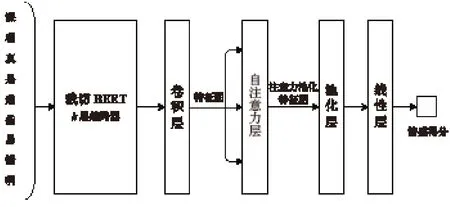
圖2 基于注意力池化機制的裁切BERT 與卷積神經網絡情感分析模型
3 從線上至線下的遷移應用
在線下課程教學中,同樣可以通過情感分析技術實現學生情感自動化分析,及時發現學生情感波動,適時調整課程的教學模式與方法,以進一步提高教學質量。計算機導論與倫理學是北京航空航天大學開設的面向計算機專業的新生專業先導課程,于2008 年獲評國家級精品課。本文通過調查問卷的方式收集了2 078 條來自選課學生的課堂反饋數據,并對正負樣本(積極/消極情感)進行了人工標注作為線下測試數據集(統計信息見表3),嘗試將本文提出的MOOC 評論文本情感分析方法應用到計算機導論與倫理學線下教育應用中。
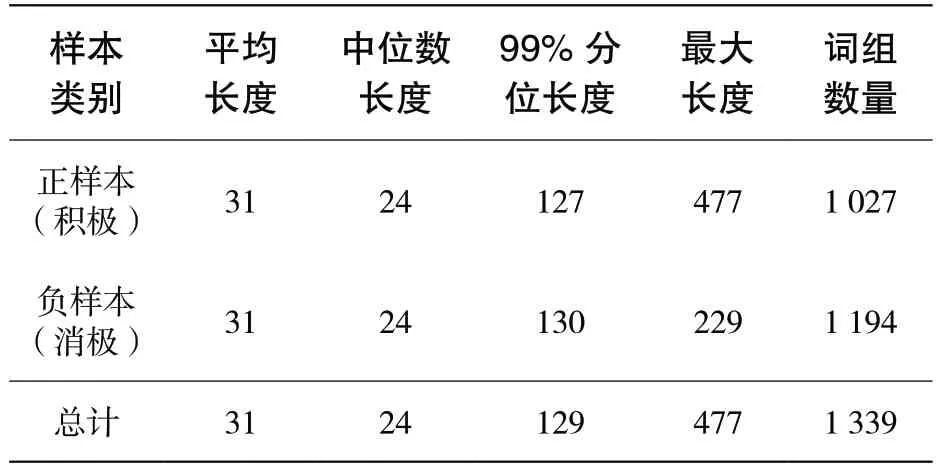
表3 線下課程課堂反饋文本統計信息
從文本長度上看,課堂反饋文本同MOOC評論同屬于短文本。與MOOC 評論相比,由于課堂反饋問卷更為正式,因此課堂反饋中的文本長度相對較長。不同于MOOC 數據集中負樣本平均長度較長,本課程評論數據集文本平均長度為31,中位數文本長度均為24,99%分位長度為129,正負樣本間的文本長度沒有體現出明顯的差異,這表明正負樣本沒有過大的信息量差異,但正樣本中的一個極長的反饋文本,使得正樣本最大長度遠大于負樣本最大長度。此外,線上數據存在大量的無意義單字,而課堂反饋數據不存在該情況。
將通過中國大學MOOC 評論數據集訓練得到的情感分析模型應用于對線下課堂反饋文本的情感分析中,具體實驗結果見表4。
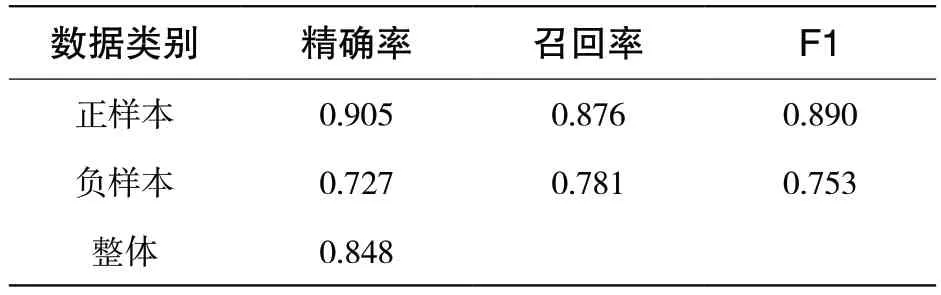
表4 裁切復合模型在課堂反饋數據集上實驗結果
由實驗結果可以看出,該模型在課堂反饋數據集上精確率達到84.8%,表明通過MOOC 評論數據訓練得到的情感分析模型對于課堂反饋文本也具有較好的情感分類能力,但由于該數據集中同樣存在正負樣本不平衡的現象,導致模型存在偏見,使模型對正負樣本的區分體現出一定的差別。因此,模型在對正負樣本的區分上仍然體現出了與在MOOC 評論數據集上相似的現象,即對正樣本分類性能(90.5%)較對負樣本(72.7%)分類性能更優。不同于MOOC 數據負樣本含有較正樣本更多的信息量,線下數據中的正負樣本間沒有明顯的信息量差異,這也會對分類預測產生一定的影響。
在線下課堂教學中,受制于一對多的教授方式,教師無法及時了解每名同學的情緒狀態。以開展教學改革研究的計算機導論與倫理學課程為例,每年的選課學生在300~400 人之間,讓教師僅僅通過課堂上的互動,很難照顧到所有的選課學生。應用自動化分析手段后,教師可以通過對學生反饋文本的情感分析,快速獲得學生的情緒狀態,實現對課程安排、知識體系、教學方法等方面的針對性調整,進而改善教學質量、提高學生學習效率。另一方面,將相關方法集成到課程互動平臺中,亦可根據分類預測的結果,實現對學生評論的個性化反饋和學習內容推薦。
4 結 語
使用MOOC 評論文本作為訓練集,對線下課程課堂反饋文本情感分析進行嘗試,雖然存在模型偏見現象,模型仍能將線上MOOC 環境學習到的分類特征很好地應用至線下課堂反饋文本上,這表明線上MOOC 環境和線下課堂環境的語義信息、語言情感特征是相似的,語言模型及其連接的神經網絡均可以有效地在線上、線下環境應用之間遷移。本文的主要工作目前集中于對反饋文本的語句級情感分析,下一步將繼續開展屬性級情感分析(即觀點挖掘)方面的研究和應用工作。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
