基于TextRank 和簇過濾的林業文本關鍵信息抽取研究
2020-07-07 06:09:10陳志泊李鈺曼馮國明師棟瑜崔曉暉
農業機械學報 2020年5期
陳志泊 李鈺曼 許 福 馮國明 師棟瑜 崔曉暉
(1.北京林業大學信息學院,北京100083;2.中國聯合網絡通信集團有限公司,北京100033;3.中國電信系統集成有限責任公司,北京100035)
0 引言
隨著互聯網與人工智能技術的飛速發展,我國傳統林業也逐步向“智慧林業”邁進。對于網絡上數量呈爆發式增長的林業文本來說,如何節省閱讀時間、從中準確獲取與林業領域有關的信息具有重要的研究意義[1-2]。
文本關鍵信息應包含關鍵詞和信息類型。目前大多數的林業文本并沒有標注關鍵詞,早期的關鍵詞抽取是通過人工標注、借助人類的專業知識完成的,工作任務十分繁重。隨著計算機技術的發展,借助計算機程序抽取關鍵詞成為更好的選擇[3-6]。關鍵詞抽取主要分為有監督和無監督兩類[7]。由于有監督算法標注成本高,且存在過擬合的問題,近年來,無監督關鍵詞抽取算法得到廣大科研人員的青睞。常見的無監督關鍵詞抽取方法有3 種:基于統計特征[8-9]、基于詞圖模型[10-12]和基于主題模型[13]的關鍵詞抽取。基于統計特征的關鍵詞抽取算法[14-15]將文本詞語的統計信息記為特征信息,如詞頻特征、逆文檔頻率特征、長度特征、位置特征等,再對特征信息進行相應的量化處理,最后抽取出文本關鍵詞。其缺點是忽略了詞語之間的相互關系,效果有時并不理想。基于主題模型的關鍵詞抽取算法[16-17]認為每個文本都對應著一個或多個主題,而每個主題都會有相對應的詞分布,通過分布信息得到文本與詞的關聯情況,進而得到文本關鍵詞,以LDA 隱含主題模型為經典代表。其缺點是模型需要大量的數據訓練,對于內容較短的文本不敏感,且計算復雜度較高,所以提取效果有時并不理想。基于詞圖模型的關鍵詞抽取算法通過融合詞語特征信息達到優化提取效果的目的,是目前應用最廣的無監督提取方法[18]。因此,融合詞語的特征信息[19-23]、優化詞圖模型、提高抽取效果具有重要的研究價值。僅抽取關鍵詞不能完整且直觀地表達文本內容,因而需要借助信息類型來完善。對于詞語的信息類型,如果文本有嚴格的記述特征,則可以通過分析記述結構進而抽取到相應的屬性[24-27],但大多數文本沒有良好的記述結構,故采用此方法相對困難。因此,如何確定詞語的信息類型具有現實意義。
本文采用合理的公式抽取關鍵詞,通過改進TextRank 算法、歸并聚類、簇過濾等,獲取到高品質的詞語集合,進而進行信息類型的判定,將關鍵詞和信息類型結合,實現對林業文本的關鍵信息抽取。
1 實驗方法
1.1 相關技術原理
1.1.1 詞語特征
關鍵詞抽取是指從文檔中獲取有代表性的詞語,用以反映文檔的主題和核心內容。衡量詞語的重要性,不能從單一角度考慮。通常用詞頻特征、位置特征等[28-29]特征來衡量。文獻[30]已對基于詞頻-逆文檔頻率特征、長度特征、詞語首次出現的位置特征以及詞跨度特征等4 個方面關鍵詞抽取公式進行了相關研究,基于此,本文在該基礎上加入標題特征,如果詞語出現在標題中,標題特征值記為1.5,反之記為1。詞語綜合權重值計算公式為

式中 Wtf——詞頻 l——詞長
Widf——逆文檔頻率
s——詞語首次出現的位置
t——詞語最后一次出現的位置
n——文本詞匯總數
θ——標題特征值
其中WtfWidf為詞頻-逆文檔頻率特征,lbl 為長度特征,1+e-s為詞語首次出現的位置特征,1 +(t -s)/n為詞跨度特征。
1.1.2 相似性度量
將關鍵詞用Word2Vec 向量化表征,根據向量之間的相似度聚為若干簇。相似性度量方法有:歐氏距離、曼哈頓距離、切比雪夫距離、閔可夫斯基距離、馬氏距離、余弦相似度、漢明距離等。本文通過設置閾值,計算向量間的余弦相似度對向量進行歸并聚類,向量余弦相似度Wcos計算公式為

式中 X、Y——任意兩個不同的向量
‖X‖、‖Y‖——X、Y 向量的模
1.1.3 TextRank 算法
TextRank 算法是一種用于文本的基于圖的排序算法,通過對圖結構的迭代計算實現詞語的重要性排序[31-33]。優點是不需要事先對文檔進行相關的學習訓練。基本原理如下:
設G(V,E)是由給定文本的詞匯所構成的圖結構,V 為圖節點集合,E 是圖邊集合。對于文本中的任一Vi,基于TextRank 算法得到權值Wi計算式為
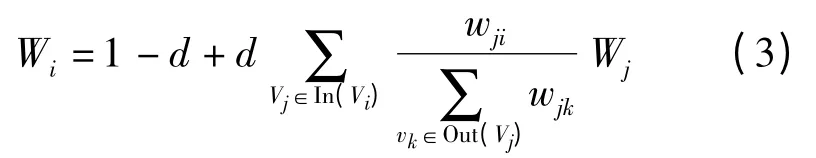
式中 d——阻尼系數,取值為0 ~1
In(Vi)——指向節點Vi的所有節點的集合
Out(Vj)——節點Vj指向的所有節點的集合
wji、wjk——節點Vj到節點Vi、Vk的邊的權重
Wj——節點Vj的權值
但最初TextRank 算法在應用時,忽略了詞語本身的特征信息,使各節點初始值均等,且節點權重均勻轉移。
因此,本文在原有TextRank 算法的基礎上進行改進,考慮詞語特征,將由關鍵詞抽取公式計算得到的綜合權值作為節點的初始值,并用詞語向量間的余弦相似度作為邊的初始值,構建帶權無向圖結構,此時對于文本中的任一Vi,權值Wi計算公式為

式中 join(Vi)——節點Vi相連的所有節點的集合
1.1.4 簇過濾
對于向量歸并聚類形成的簇來說,需要通過合理的品質評價指標對簇的品質進行過濾。本文從簇元素分布的均勻性、簇的規模、簇的普適性3 個角度考慮,設計簇品質評價公式,通過對相關參數的調整,過濾得到品質比較好的簇集合。
某核電廠取排水設計對漁業資源經濟價值影響分析………………………………………………… 楊帆,傅小城(3-65)
(1)簇元素分布的均勻性(Balance)
簇中元素分布均勻性指標B 的計算公式為
式中 Av——簇中節點元素權值的平均值,反映數據的集中性特征
St——簇中節點元素權值的標準差,反映數據的波動性特征
標準差St越小,說明元素的權重分布越均勻,說明簇中有用的元素越多。標準差St相同時,需要借助平均值Av來判定。當St/Av越小,元素分布越均勻,依據取倒數且分母不為零的原則設計公式,得出B 值越大,簇元素分布越均勻。
(2)簇的規模(Scale)
簇的規模S 指簇中所含元素的數量,計算公式為

式中 μ——簇中元素的個數
(3)簇的普適性(Universality)
普適性指標U 是指簇中元素來源的文章數,計算公式為

式中 N0——簇中元素來源的文章數
簇中元素來源的文章數越大,即N0越大,U 越大,說明簇的普適性越好。
(4)簇品質(Quality)評價公式
從簇元素分布的均勻性、簇的規模、簇的普適性3 個角度考慮簇的品質Q,計算公式為

式中 λ1、λ2——參數
Q 由兩部分組成:簇的總體水平和簇的普適性,通過調節參數,權衡各指標所占的權重。說明在不同規模下,均勻程度的增大對簇的品質的提升是不同的;規模越大,提升越大。所以簇品質對均勻程度的偏導為規模的單增函數,可得

式中函數f、g 均為單增函數。為方便計算,設

因此,簇的總體水平由簇元素分布的均勻性和簇的規模兩部分組成,可記為λ1BS。
1.2 提取流程
針對數量龐大的林業文本,采用“關鍵詞+信息類型”的表示方式,提出基于改進TextRank 和簇過濾的林業文本關鍵信息抽取方法,通過合理的方式對林業文本進行關鍵信息抽取。提取流程如圖1所示,具體步驟為:
(1)林業文本預處理,包括引入領域詞典對文本進行分詞、引入停用詞表對文本進行去停用詞等操作。
(2)依據關鍵詞抽取公式,抽取文本綜合權值排名前30 的詞語,部分結果如圖2 所示。

圖1 關鍵信息提取流程Fig.1 Key information extraction process

圖2 部分抽取結果Fig.2 Part of extraction results
(3)對抽取的關鍵詞用Word2Vec 向量化表征,并計算兩兩向量的余弦相似度。
(4)設置閾值,向量余弦相似度大于閾值的兩個詞之間連線,間距小于閾值的2 個詞之間不連線,以相似度為邊的權值,以步驟(2)計算出的權值作為節點的初始權值,進而構造圖模型,應用TextRank算法,得到了綜合考慮詞與詞關系的關鍵詞最終權值。
(5)利用圖結構中詞語的節點值和相應的詞向量進行加權求和,得到圖中心。計算兩兩圖中心的余弦相似度,設置閾值,余弦相似度大于閾值的圖進行合并,歸并聚類得到初始簇。
(6)對簇中的節點值進行標準化處理,依據設計好的簇品質評價公式,對初始簇進行品質評價,設置閾值,進行過濾操作。
(7)對過濾后的簇應用TextRank 算法,經過迭代收斂得到最終簇集合,對最終形成的簇集合進行信息類型的判定。
(8)計算關鍵詞向量和各簇心之間的余弦相似度,通過比較,得到關鍵詞的信息類型。最終得到文本的關鍵信息:關鍵詞+信息類型。
2 實驗及方法驗證
2.1 實驗環境
本文所提出的算法模型采用Python 編程實現,本實驗所有的模型訓練計算機環境主要參數為Intel Corei5-8250U CPU @ 1.6 GHz 1.80 GHz,內存為8.00 GB。
2.2 實驗數據
本文所采用的實驗數據為與林業政策和新聞相關的文本,數據分別來自中國林業新聞網、林業信息網、林業產業網等林業相關網站,經數據預處理后共2 000 篇,其中400 篇文本進行了關鍵詞人工標注。
2.3 評價指標
2.3.1 聚類評價指標
所采用的評價指標有3 個:緊密度、間隔度、聚類綜合評價指標。
(1)緊密度(Compactness,CP)
每一個簇中各元素到簇心的平均距離越小,說明聚類效果越好。實驗選用向量的余弦距離,因此CP 越大,說明聚類效果越好。

其中

式中 Cp——緊密度
xi——簇中第i 個關鍵詞向量
wi——第i 簇的簇心向量
Ωi——第i 簇的關鍵詞集合
k——簇的個數
(2)間隔度(Separation,SP)
各簇中心兩兩之間的平均距離越遠說明簇間聚類效果越好。實驗選用向量的余弦距離,因此間隔度越小,說明聚類效果越好。
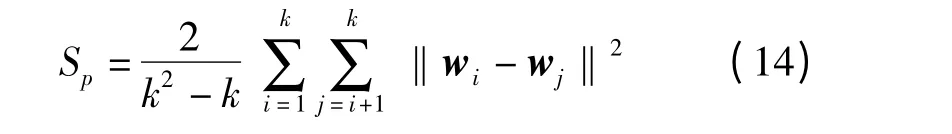
式中 Sp——間隔度
wj——第j 族的簇心向量
(3)聚類綜合評價指標(F1-Measure,F1)

式中 N1——簇元素為1 的數量
N——簇的數量
2.3.2 關鍵詞抽取效果評價指標
第1 類評價指標有3 個:準確率(Precision,P)、召回率(Recall,R)和綜合評價指標(F-Measure,F),公式為

式中 X——正確抽取到的關鍵詞數
Y——錯誤抽取到的關鍵詞數
Z——屬于關鍵詞但未被抽取到的詞數
第2 類評價指標為針對有序的關鍵詞抽取結果的評價指標,包括平均倒數等級(Mean reciprocal rank,MRR)和二元偏好度量(Binary preference measure,Bpref)。其中,MRR 用來度量每個文檔第1個被準確提取的關鍵詞的排名情況,而Bpref 則用來度量提取結果中錯誤提取的詞語的排名情況,具體的計算公式為

式中 D——所有文檔的集合
rd——第1 個正確提取結果的排序
Q1——正確的關鍵詞的集合
|F0|——排列在正確提取詞r∈Q1之前提取的錯誤詞的數目
|E|——所有提取詞的數目
2.4 實驗結果及分析
依據兩兩向量間的余弦相似度,對單個文本構建圖模型時,需要設置合理的閾值。實驗結果如表1 所示。此時部分指標隨閾值變化趨勢如圖3 所示。

表1 單個文本構建圖模型閾值參數Tab.1 Parameters of single text built graph model

圖3 各指標變化趨勢(單個文本)Fig.3 Trend of each index (single text)
由表1 及圖3 可以看出,當閾值大于等于0.4時,CP 和SP 逐步趨于穩定,且當閾值等于0.4,F1最大,說明聚類效果最好。因此,單個文本構建圖模型閾值參數設置為0.4。
單個文本形成穩定的圖結構后,要對所有的圖進行歸并聚類形成初始簇,需要設置合理的閾值。實驗結果如表2 所示。此時部分指標隨閾值變化趨勢如圖4 所示。
由表2 及圖4 可以看出,當閾值在0.5 ~0.7 之間時,CP 趨于穩定;雖然SP 呈遞增趨勢,但要綜合CP 來設定閾值參數。閾值為0.5 時,CP 為0.929 0,SP 為0.050 2,此時簇的數量N 為1 194,F1值最大,為0.848 0。因此,歸并聚類時閾值參數設置為0.5。
對簇進行過濾時,要進行品質評價。此時需要討論參數λ1和λ2,將λ1在0.1 ~0.9 的取值分別記為序號1 ~9,實驗結果如表3 所示。

表2 圖結構歸并聚類閾值參數Tab.2 Parameters of merged cluster of graph structure
由表3 可以看出:當λ1為0.7,λ2為0.3 時,CP為0.968 0,SP 為0.057 2,此時簇的數量N 為234,說明能對簇進行有效過濾,此時F1為0.887 1,綜合評價最好。因此,歸并聚類時閾值參數λ1、λ2分別設置為0.7、0.3。

圖4 各指標變化趨勢Fig.4 Trend of each index

表3 品質評價公式參數Tab.3 Parameters of quality evaluation
為了驗證本文過濾方法的有效性,將過濾前的狀態記為狀態1,采用本文過濾方法過濾后的狀態記為狀態2,并與文獻[34]提出的基于聚類顯著程度的定量過濾指標對簇進行過濾的方法作對比,并記為狀態3,對比實驗采用上述評價指標,結果如表4 所示,結果說明簇品質公式能有效對簇的品質進行評價,本文過濾方法是行之有效的。同時對最終簇的元素來源文章數進行了統計,來源文章數規模最大為21,最小為4。

表4 簇數量統計Tab.4 Numbers of clusters
對簇進行信息類型標注,部分標注結果如表5所示。

表5 部分標注結果Tab.5 Part of results
為了進一步驗證本文方法在抽取關鍵詞方面的有效性,將TF-IDF、TextRank 以及文獻[10 - 11,35 -36]中相應的關鍵詞抽取方法分別作為對比實驗。將上述模型按提及次序分別記為模型1 ~6,將本文方法記為模型7。實驗數據為已進行關鍵詞標注的400 篇林業文本。實驗結果如表6 所示。
通過實驗結果可以看出,本文所提方法在MRR、Bpref、準確率和綜合評價指標上均取得了最好的效果,在召回率方面取得了較好的效果,說明本文所提關鍵詞抽取公式具有很好的關鍵詞抽取能力。

表6 對比實驗結果Tab.6 Results of comparative experiments
2.5 測試
2.5.1 測試流程
為了進一步驗證本文所提出的關鍵信息抽取方法的有效性,開展了相關的測試實驗工作,測試流程如圖5 所示。

圖5 測試流程圖Fig.5 Test process
具體步驟如下:①文本預處理,對文本進行分詞、去停用詞等操作。②依據關鍵詞抽取公式,抽取權重排名前30 的詞語。③對抽取的關鍵詞進行向量化表征。④通過計算比較關鍵詞向量和各簇心之間的距離,得到關鍵詞、最相似簇、最大相似度的三元組,根據最大相似度對30 個三元組進行降序排序,取前10 個。以最相似簇的標注類型作為詞的信息類型,最終得到文本的關鍵信息:關鍵詞+信息類型。
2.5.2 測試實例
選取一篇新的與林業政策新聞相關的文章,文章的部分內容如圖6 所示。
2.5.3 測試結果抽取最大相似度排名前10 的詞語,結果如表7所示。

圖6 測試文章的部分內容Fig.6 Part of test article

表7 測試結果Tab.7 Test results
結果表明本文所提方法能從“關鍵詞+信息類型”兩部分表示文本關鍵信息,內容表述基本清晰,且具有很好的代表性和可讀性。
3 結束語
為了使抽取的關鍵詞綜合特征明顯,通過綜合考慮詞長、詞跨度、標題等特征,將計算的綜合權值作為詞語特征值,通過構建融合詞語特征、引入邊權重的圖模型對TextRank 算法進行改進。經迭代收斂、歸并聚類得到穩定的簇集合,對其過濾得到高品質的詞語信息類型集合。實驗表明,本文方法相對于其他關鍵詞抽取方法具有更高的關鍵詞抽取能力,最終形成的信息類型集合在緊密性、間隔性、綜合評價指標上均表現良好。隨機針對一篇林業政策新聞類的文本進行測試,結果表明,從“關鍵詞+信息類型”兩部分考慮,本文方法能有效提取出該文本的關鍵信息,說明本文提出的基于改進TextRank和簇過濾的林業文本關鍵信息抽取方法是有效的。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
