基于強化學習的海克斯棋博弈算法研究與實現
2020-07-04 02:27:37張芃芃孟坤楊震棟
智能計算機與應用 2020年3期
張芃芃 孟坤 楊震棟


摘要:本文旨在研究如何將強化學習模型合理地應用在海克斯棋博弈算法中,并給出程序實現方案。以蒙特卡洛樹搜索生成數據集訓練卷積神經網絡的方式,使得模型能夠在不斷自我對弈的過程中,修正自身選擇動作的策略,更新模型參數,從而達到提升棋力的目的。實驗結果表明,通過強化學習算法能夠準確地評估海克斯棋的局面,并有效地選擇有利的落子位置,使得海克斯棋博弈系統獲得高質量的決策能力。
關鍵詞: 強化學習; 蒙特卡洛樹搜索; 海克斯棋; 計算機博弈
【Abstract】 The purpose of this paper is to study how to apply reinforcement learning model to the algorithm of Hex game reasonably, and give the program implementation scheme. In this way, the convolution neural network can be trained by using the data set generated by the Monte Carlo tree search, so that the model can enhance chess skills by modifying the strategy of its own choice of action and updating the model parameters in the process of continuous self playing. The experimental results show that the reinforcement learning algorithm can accurately evaluate the situation of Hex game, and effectively select a favorable moves, so that Hex game system gains high-quality decision-making ability.
【Key words】 ?reinforcement learning; Monte-Carlo tree search; Hex game; computer game
0 引 言
隨著人工智能的興起,人們對計算機博弈的研究日趨深入,計算機博弈算法也已越來越多地被應用在各棋種上。海克斯棋是近年來比較流行的計算機博弈棋種之一,現已成為中國大學生計算機博弈大賽的競技項目[1]。其規則很簡單:博弈的雙方依次在菱形的棋盤上落子,當任意一方最先將自己的兩條邊界用己方的棋子連接起來,則該方獲勝。
強化學習也稱增強學習[2],是一類在自身智能體不斷摸索和嘗試的過程中,依靠環境帶來的反饋更新自身決策方式的機器學習算法。當智能體模型做出某種動作后產生了有利的狀態,則對模型進行獎勵,反之則進行懲罰。以此不斷迭代,最終使模型具有高質量的決策能力。本文將強化學習模型合理地應用在海克斯棋博弈算法中,使得模型能夠通過不斷自我對弈,提升棋力。
1 強化學習模型算法設計
海克斯棋是一種完全信息博弈,能夠通過模擬大量對局來學習優良的落子選擇方法。受AlphaGo Fan[3]和AlphaGo Zero[4]的算法啟發,在模型的核心部分使用價值-策略網絡二合一的卷積神經網絡,使其輸入原始棋盤,輸出該局面輸贏概率作為價值評估,同時輸出每個落子位置獲勝的概率分布作為策略評估。首先采取隨機落子的方式,使用蒙特卡洛樹搜索[5]生成大量對局樣本,用監督學習的方式,根據最后的勝負結果、棋面狀態以及走法的模擬來訓練神經網絡。以局面最終輸贏訓練價值網絡的同時,用局面每個落子位置獲勝頻率分布訓練策略網絡。然后將這個模型加入到新建立的對手池中,并在從對手池中隨機選擇一個模型和最新模型進行對弈的過程中,同樣通過蒙特卡洛樹搜索模擬生成對局,從而產生對弈數據,對神經網絡進行訓練。并在將訓練完成的模型加入到對手池中后,再利用新的模型繼續模擬對弈,繼而持續進行從對手池中選擇模型對弈的過程,以此迭代出一個效果最佳的模型。
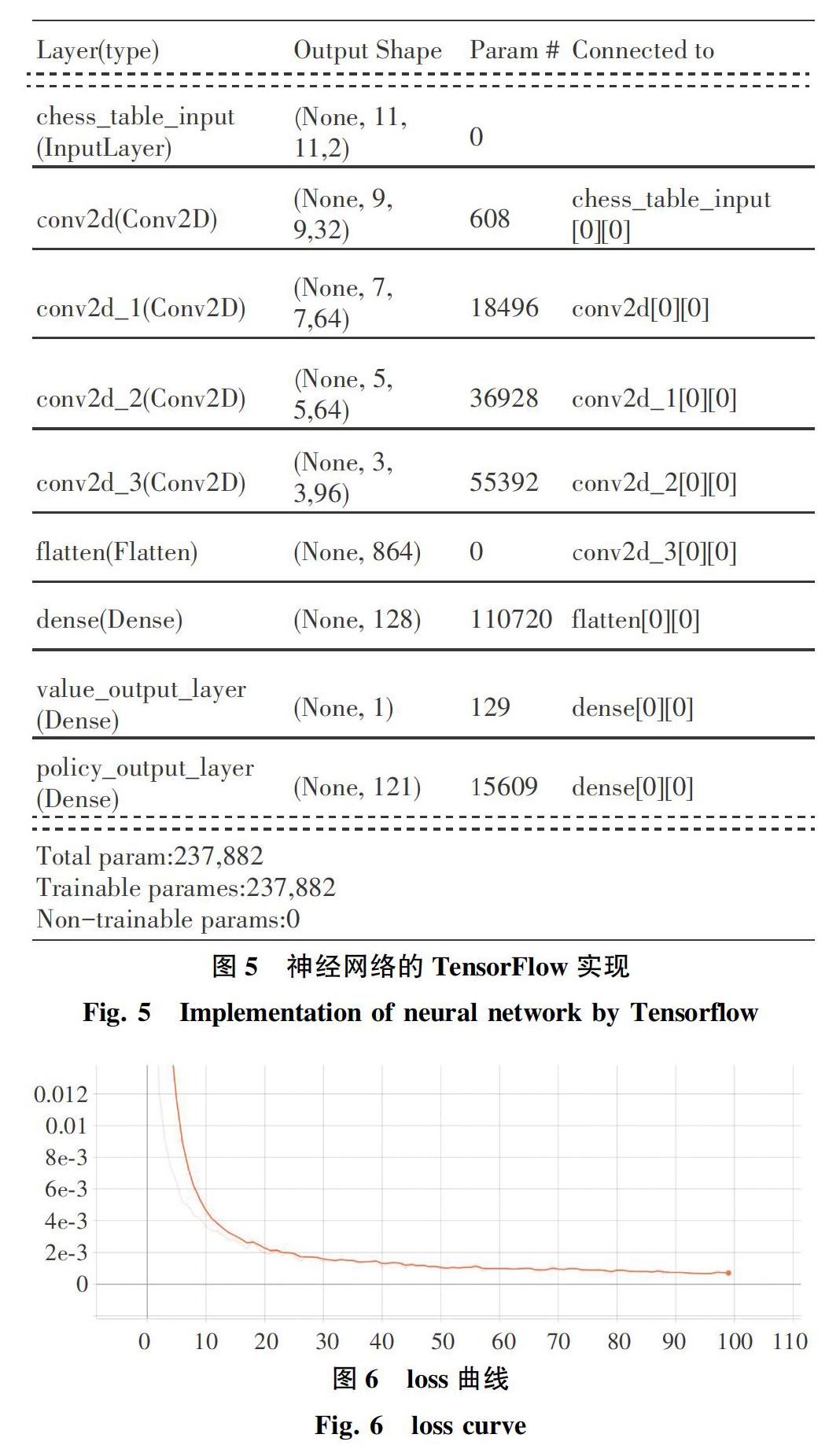
1.1 神經網絡的設計
使用神經網絡的目的在于能夠對于給定的海克斯棋局面做出準確估價的同時,給出最佳的落子位置。因此選擇多輸出的卷積神經網絡,使其同時具有價值輸出和策略輸出。
對于一個大小為11×11的海克斯棋局面來講可以抽象成一個11×11×2的三維張量,作為模型的輸入。其中,最低的維度用來區分棋盤上每一個位置的落子情況。考慮到3×3大小的卷積核剛好能夠覆蓋到任何一個方向上的雙橋[6],使得神經網絡能夠描述和考慮對局面影響較大的特定布局模式。因此在樣本輸入網絡后,首先通過一個含有32個3×3卷積核的卷積層,再依次通過2個含有64個3×3卷積核的卷積層,然后通過一個含有96個3×3卷積核的卷積層,接著通過含有128個神經元的全連接層,最后通過一個神經元輸出價值評估,通過一個含有121個神經元的全連接層輸出策略評估。另外,所有的卷積層均使用線性整流函數作為激活函數,以保證在訓練過程中誤差反向傳播的高效進行。神經網絡結構圖如圖1所示。
1.4 自我對弈的訓練過程
模型決策效果的提升主要依賴于自我對弈生成數據集來訓練網絡的過程,這需要維護一個對手池,用來存放模型的歷代版本。由于不同模型僅在網絡參數上存在區別,因此在對手池中存放模型等價于存放網絡參數。故首先將監督學習訓練完成的網絡參數放入對手池中,每次從中隨機選取一個網絡參數組成模型后作為最新加入對手池的網絡參數所組成模型的對手,進行多次雙循環對弈,將對弈過程中的局面用其勝負結果標注其價值,并使用蒙特卡洛樹搜索獲得其策略標簽。再用新生成的數據集訓練當前的網絡,以此獲得新一代的網絡參數,并放入對手池中,繼續自我對弈。模型自我對弈過程的數據流圖如圖3所示。
