基于特征分析的職工離職預測
2020-06-21 08:10:18
科技與創新 2020年11期
(上海大學 悉尼工商學院,上海 200444)
1 引言
隨著現代科技的不斷發展,企業所處的環境在不斷變化,企業本身也在不斷變化。在現代競爭激烈的社會中,職工離職的現象越來越普遍。很多企業認為員工流失所造成的成本只包括離職成本和招聘成本,卻忽視了職工離職引起的其他流動成本,比如重要客戶的流失、商業機密的泄露、企業競爭力的下降等。在如此情況下,公司的人力資源部門應該如何減少職工的離職傾向,從而降低公司經營成本是極其具有現實意義的[1]。
國內外學者對于職工的離職現象開展了大量的研究工作[2-4],主要包括三大方向,即職工離職因素研究、降低職工離職率的措施研究和職工離職的預測研究。目前與本文研究方向類似的,即關于職工離職預測的研究,主要是基于機器學習的方法,著眼于模型算法的比較和探討,忽視了對數據處理的研究。然而,目前一些比較成熟的機器學習模型算法,都對被處理的數據集合有一定要求,比如較好的完整性、較少的冗余性等。但現實海量數據中無意義的成分居多,嚴重影響了模型的性能和效果。因此,本文的重難點在于如何對原始數據提取并挖掘有效特征,突出數據預處理技巧對職工離職預測模型性能的影響,以彌補現有研究中對數據處理部分的忽視。
2 數據來源
本文數據來自于IBM Watson Analytics 分析平臺分享的數據,共1 470 條記錄,35 個字段信息。原始數據集描述的是影響員工流失的因素,對字段信息的詳細說明如表1所示。
3 數據處理與分析
對各特征數據統計發現,數據存在高度傾斜和一些無用的唯獨特征,還存在很多屬性變量等。因此,在建模之前需要對數據進行處理[9]。
3.1 處理數據不可用
經過統計分析發現,數據集中存在兩個常量特征,它們是Over18 和StandardHours。數據集中還存在一個無關特征,即EmployeeNumber。顯而易見,他們對模型決策來說是無用的維度,為了模型計算更快,應刪除這些變量。
3.2 特征處理
3.2.1 新特征構建
3.2.1.1 LM_Involved(是否為中低參與度)
通過對原數據中JobInvolvement 列的分析,發現工作參與度低的員工和工作參與度中等的員工的流失率相對較高。因此構建新特征LM_Involved,該特征屬性值為0 和1。若員工的工作參與度為中或低,則該員工LM_Involved 特征取值為1,否則為0。
3.2.1.2 like_moving(是否熱衷換公司)→Time_in_each_comp_level(每家公司工作年數)
通過生活經驗猜測,有些員工頻繁跳槽是為了在不斷嘗試的過程中尋求最適合自己的工作。基于此,構建了like_moving 新特征。以工作過4 家公司為閾值,若員工工作過的公司超過4 家,則該員工被定義為熱衷換公司的人,該員工的like_moving 特征將被賦值為1,否則為0。
圖1 為新特征like_moving 與員工流失率關系圖。通過圖1 柱狀圖高度分析得出,熱衷換公司的員工流失率為0.21,非熱衷換公司的員工流失率為0.14%。0 類與1 類在流失率中的差距不顯著,猜想可能的原因是一些員工是由于自身工齡長導致在很多家公司工作過,并不是因他熱衷換公司。因此提出特征Time_in_each_comp,該特征的計算公式為(員工年齡-20)/(工作過的公司+1),得到該員工在每個公司工作的平均年數,由此得到Time_in_each_comp。再對平均年數離散化,得到Time_in_each_comp_level。新特征Time_in_each_comp_level 的屬性值為0、1、2。若平均年數小于3 年,則Time_in_each_comp_level 取值為0;若平均年數小于12 年,則取值為1;其余為2。
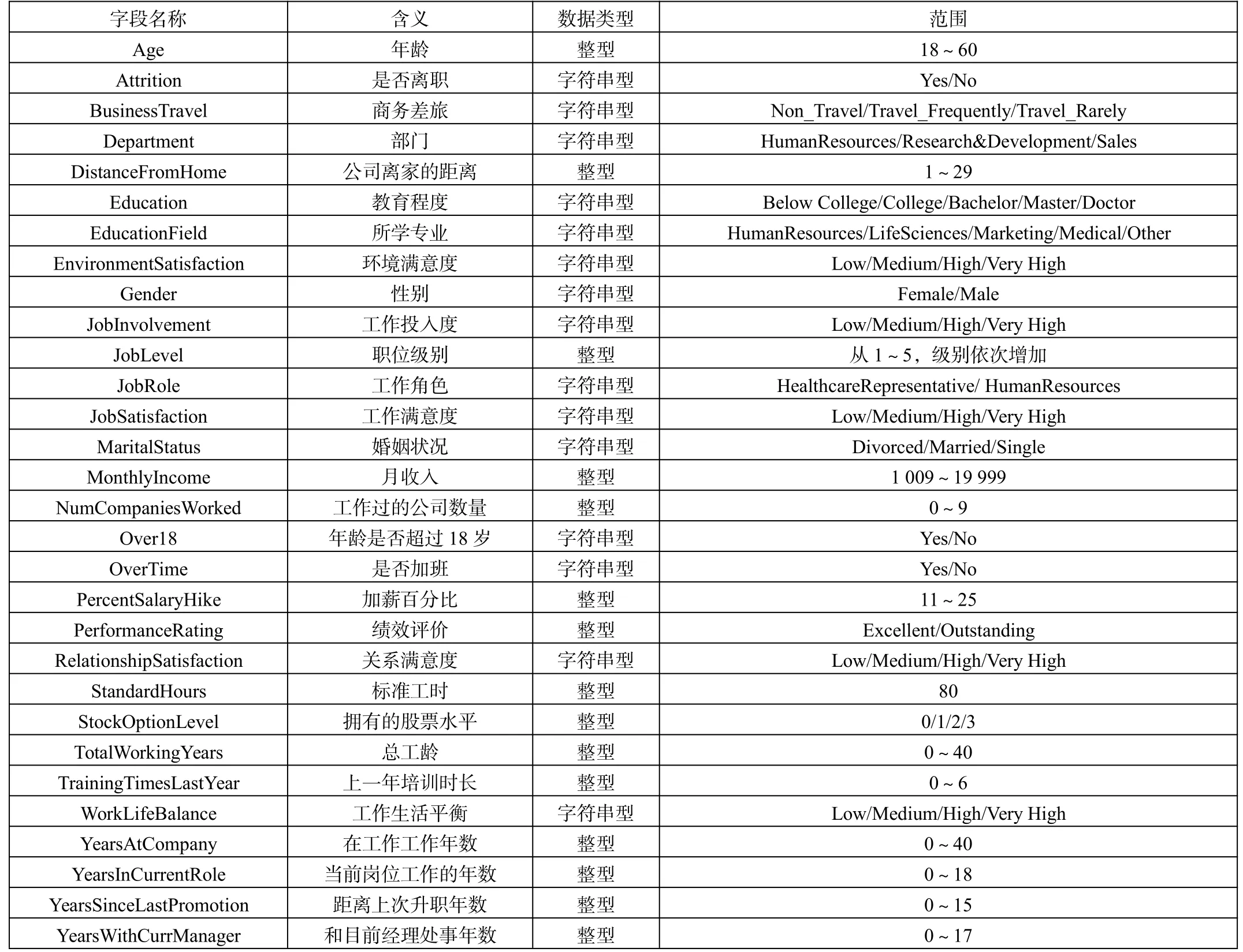
表1 數據集字段描述
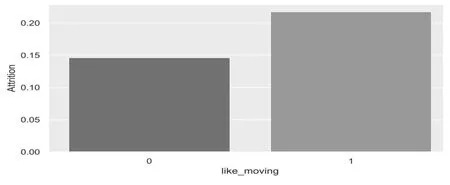
圖1 like_moving 與流失率關系圖
圖2 為新特征Time_in_each_comp_level 與員工流失率關系圖。

圖2 Time_in_each_comp_level 與流失率關系圖
從圖2 柱狀圖高度看出,平均年數小于3 年的員工的離職率是剩余員工的2 倍,具有區分度。
3.2.1.3 Total_satisfication(總體滿意度)&NotSatisfied(是否不滿意)
觀察原數據得出,滿意度分為Environment Satisfaction、Relationship Satisfaction、Job Satisfaction,即環境滿意度、關系滿意度和工作滿意度。而與員工滿意度相關的因素還有WorkLifeBalance 和JobInvolvement。員工參與度過低說明該員工對工作沒有熱情,也是總體滿意度的一方面。有時候某一方面的滿意度低但總體滿意度高并不會導致員工離職,因此計算總體滿意度更為合適。Total_satisfication(總體滿意度)計算公式為:

同時構建新特征Not Satisfied,該特征屬性值為0 和1。若員工的平均滿意度小于2.5,則該員工NotSatisfied 特征取值為1,否則為0。圖3 為新特征NotSatisfied 與員工流失率關系圖。
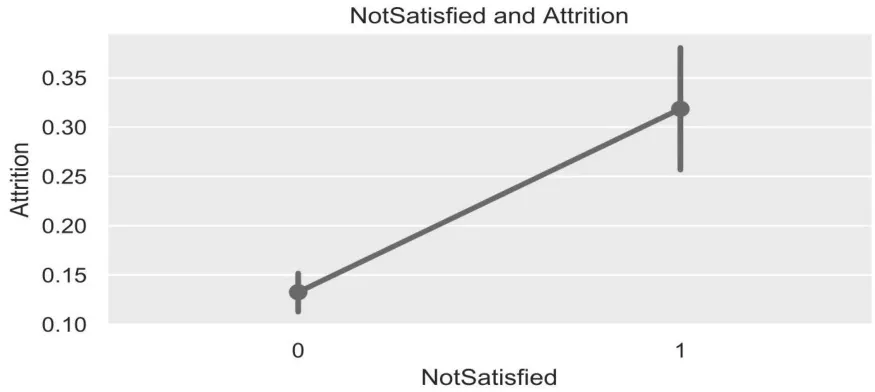
圖3 NotSatisfied 與流失率關系圖
從圖3 看出,總體不滿意的員工的流失率超過0.3,而總體滿意的員工離流失不到0.15,差了2 倍之多。
3.2.1.4 LongDistance&ImBance(是否由工作距離導致的生活工作不平衡)
通過對原數據中DistanceFromHome 列的分析,發現距離的遠近和員工流失率并沒有明顯關系。但根據生活經驗,通過同時考慮DistanceFromHome 特征和WorkLifeBalance特征,來識別出那些因為工作距離導致家庭生活不能平衡的員工。新特征LongDistance&ImBance 的屬性值為0 和1,若員工的 DistanceFromHome 特征大于 11 且員工WorkLifeBalance 特征為low,則該員工LongDistance&ImBance 特征值為1,否則為0。
圖4 為新特征LongDistance&ImBance 與員工流失率關系圖。
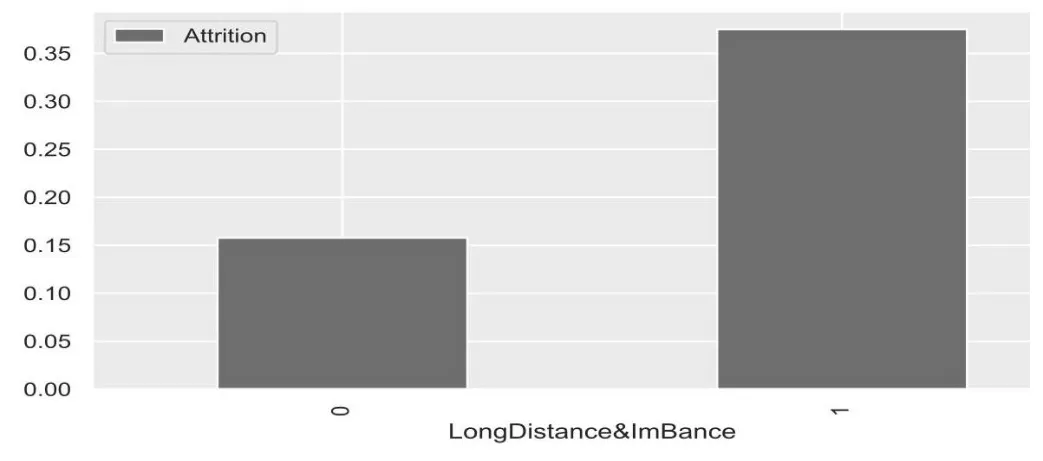
圖4 LongDistance&ImBance 與流失率關系圖
從圖4 看出,由距離遠導致工作生活無法平衡的員工的流失率是剩余員工的2 倍之多。
3.2.1.5 LongDistance_&_joblevel1(是否是工作距離遠且職位級別低的人)
從對原數據的分析來看,單純的職位級別特征和工作距離特征對于員工的流失沒有特定關系。但根據生活經驗,如果一個人的職位很高,那他會舍不得放棄摸爬滾打了幾十年才得來的高職位,哪怕工作路途遙遠。而當一個員工級別很低,他離職的機會成本也比較低。那他為何不找一份距離近的工作?因此,新特征LongDistance_&_joblevel1 的屬性值為0 和1,若員工的DistanceFromHome 特征大于11 且員工joblevel 特征為1,則該員工LongDistance_&_joblevel1 特征值為1,否則為0。
圖5 為新特征LongDistance_&_joblevel1 與員工流失率關系圖。
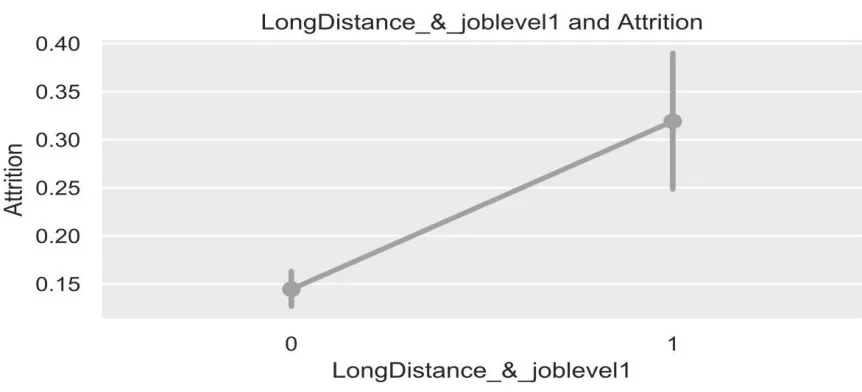
圖5 LongDistance_&_joblevel1 與流失率關系圖
從圖5 看出,職位級別低且工作距離遠的員工的流失率是其余員工的2 倍之多。
3.2.1.6 LongDistance_&_Singl(e是否是工作距離遠且單身的人)
通過對原數據中MaritalStatus 列的分析,發現在所有離職的員工中,單身的員工占了最大比例。因此,再根據生活經驗,單身的人不用承擔養家糊口的壓力,他們的試錯成本比較低。若他的工作單位距離較遠,那他有充分理由去嘗試一家離家近的公司,因此這類人的流失率比較高。新特征LongDistance_&_Single 的屬性值為0 和1,若員工的DistanceFromHome 特征大于11 且員工MaritalStatus 特征為Single,則該員工LongDistance_&_Single 特征值為1,否則為0。
圖6 為新特征LongDistance_&_Single 與員工流失率關系圖。
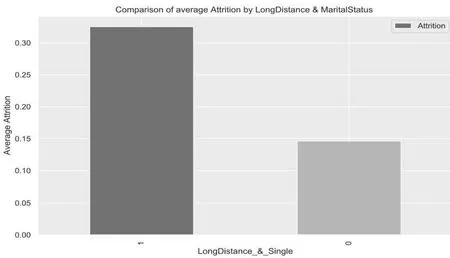
圖6 LongDistance_&_Single 與流失率關系圖
從圖6 看出,單身且工作距離遠的的員工的流失率是其余員工的2 倍之多。
3.2.1.7 Young_&_Badpay(是否年輕且收入低)
根據經驗,剛入職場的年輕人往往敢于嘗試,且對收入的期望值很高。但由于剛剛開始工作,薪水無法一下子滿足他們的期待,于是年輕員工就流失了,去尋求更令他們滿意的發展。新特征Young_&_Badpay 的屬性值為0 和1,若員工的Age 特征小于24 且員工MonthlyIncome 特征小于3 500,則該員工Young_&_Badpay 特征值為1,否則為0。
圖7 為新特征Young_&_Badpay 與員工流失率關系圖。
從圖7 看出,年輕且收入低的員工的流失率大約在0.35,而其余員工流失率在0.1 左右,差距顯著。
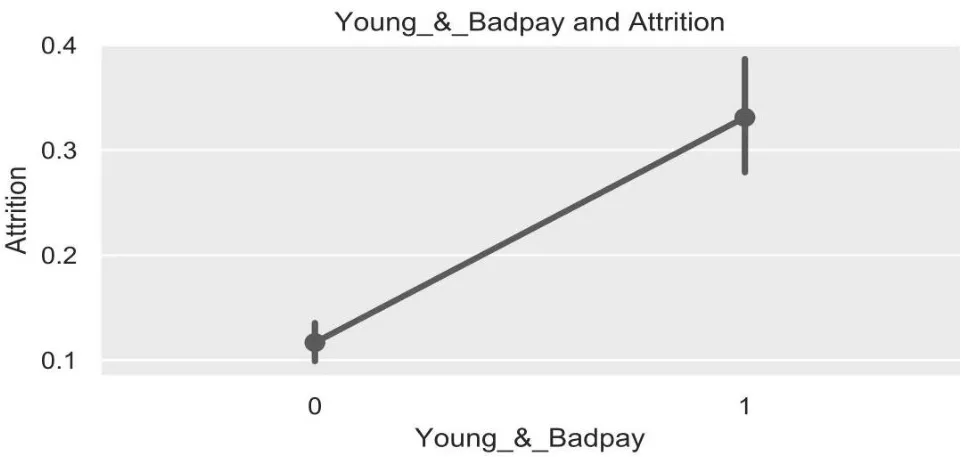
圖7 Young_&_Badpay 與流失率關系圖
3.2.1.8 MonthlyIncome_level(工資水平)
原始數據MonthlyIncome 列的數值眾多,因此想到對MonthlyIncome 列離散化,構成新特征MonthlyIncome_level。新特征MonthlyIncome_level 的屬性值為0、1 和2,若員工的MonthlyIncome 小于3 725(3 725 為第一四分位數),則該員工MonthlyIncome_level 特征值為0;若員工的MonthlyIncome 小于11 250(11 250 為第三四分位數),則該員工MonthlyIncome_level 特征值為1;其余為2。
圖8 為新特征MonthlyIncome_level 與員工流失率關系圖。
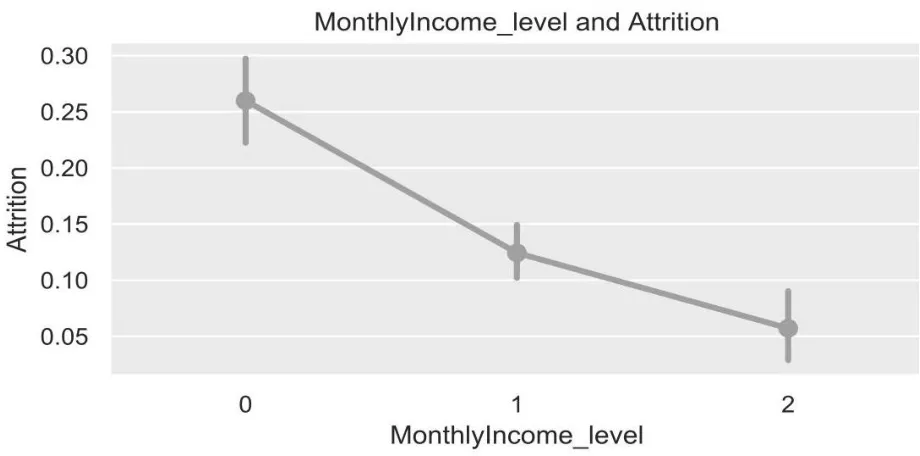
圖8 MonthlyIncome_level 與流失率關系圖
從圖8 看出,處在低收入檔的員工的流失率是其余員工的2 倍之多。
3.2.1.9 Income_Distance(收入的距離代價)
新特征Income_Distance 所代表的含義是,掙得一元錢所需要付出的上班距離代價,因為距離的遠近可以看作另一種成本(包括交通成本、時間成本等)。
Income_Distance 的計算公式是(MonthlyIncome)/(DistanceFromHome),之后再對得到的值離散化。根據經驗,(MonthlyIncome)/(DistanceFromHome)值越大,員工流失率越低。新特征Income_Distance_level 的屬性值為0、1、2 和3,若員工的Income_Distance 小于420(420 為0.3分位數),則該員工Income_Distance_level 特征值為0;若員工的Income_Distance 小于1 200(1 200 為二分位數),則該員 工Income_Distance_level特征值為1 ;若員工的Income_Distance 小于2 700(2 700 為0.8 分位數),則該員工Income_Distance_level 特征值為2;其余為3。
3.2.1.10 Income_YearsComp(收入的時間代價)
同理,新特征Income_YearsComp 所代表的含義是,掙得一元錢所需要付出的工齡代價,因為時間成本也是重要的考量因素。Income_YearsComp 的計算公式是(MonthlyIncome)/(YearsAtCompany)。根據經驗,(MonthlyIncome)/(YearsAtCompany)值越大,員工流失率越低。
3.2.1.11 Stability(穩固性)
根據經驗,有些員工在公司的年數已經很長了,但是總是在崗位之中換來換去,因為該員工在大部分崗位都無法按要求完成工作,但公司卻不能把他辭退,只能讓他不停嘗試新崗位,直到找到一個合適的崗位。而有些人在短時間內就找到了自己擅長的崗位,并長期做了下去。顯然,后者的流失率會更低。因此,新特征 Stability 的公式為YearsInCurrentRole/YearsAtCompany。
3.2.1.12 Fidelity(忠誠性)
新特征 Fidelity 公式為 NumCompaniesWorked/TotalWorkingYears。該值越小,代表該員工越忠誠,流失的概率也越小。
3.2.1.13 Has_stock(是否持股)
根據經驗,有些公司為了激勵員工,會贈送股權,這是一種將員工利益與公司利益捆綁的手段。原數據中StockOptionLevel 代表持股等級,但筆者認為是否持股才是決定員工流失的關鍵因素,不論持股的數量是多少。因此,構建新特征Has_stock,該新特征的屬性值為0 和1,0 代表員工沒有股權,1 代表員工有股權。
圖9 為新特征Has_stock 與員工流失率關系圖。
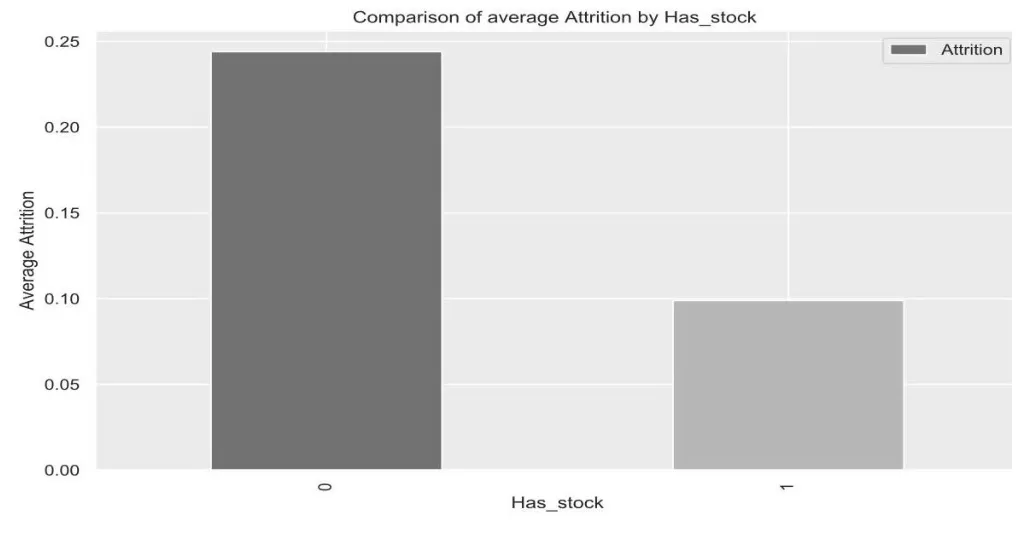
圖9 Has_stock 與流失率關系圖
從圖9 看出,未持有股份的員工的流失率是持有股份員工的2 倍之多。
3.2.1.14 cluster_result(聚類結果)
最后根據 KMeans 聚類結果增加了新特征cluster_result[5]。KMeans 中k取值(即聚類數)的設定是通過循環的方式得到。當k=2 時,聚類模型的輪廓系數最高。因此,將該聚類標簽作為新特征。
3.2.2 特征相關性分析及篩選
原始數據的特征有31 個,除去3 個無用特征之后,又經過挖掘加入的新特征有15 個。表2 是部分特征與標簽列Attrition 的相關性排序(羅列前十位和后五位)。從中看出,新增加的特征 Young_&_Badpay、Fidelity、MonthlyIncome_level、Has_stock、Total_satisfication、NotSatisfied、Time_in_each_comp_level等都與標簽列Attrition 密切相關,因此新特征的挖掘是有效的。
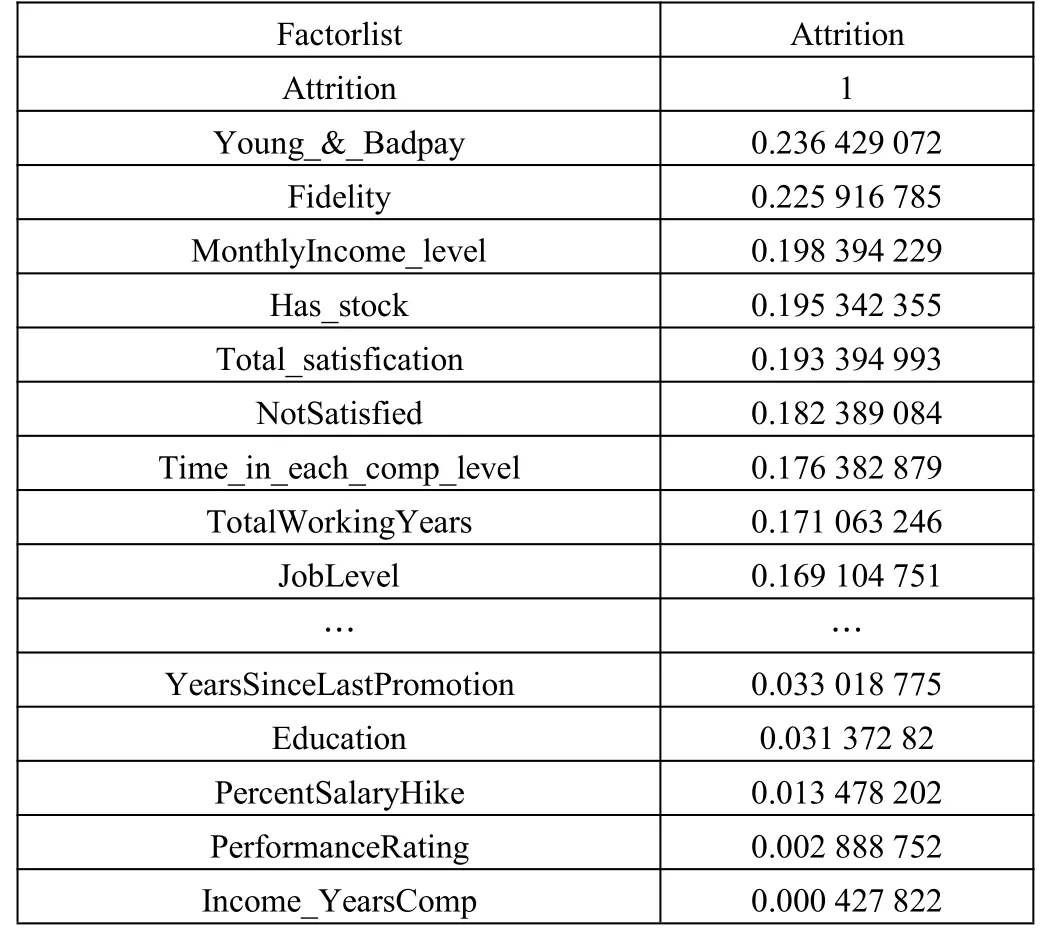
表2 部分特征與標簽列Attrition 的相關性排序(前十位和后五位)
根據表2 刪除一些排名倒數,對標簽列貢獻度小的特征,刪除標準是該特征與標簽列Attrition 的相關性小于0.05(即 Income_YearsComp、PerformanceRating、PercentSalaryHike、Education、YearsSinceLastPromotion、NumCompaniesWorked、RelationshipSatisfaction)。
3.3 獨熱編碼處理
基于此,本文對經上述處理后的數據采用get_dummies方法對離散型數據進行獨熱編碼,如Gender、JobRole 等。采用one-hot 編碼后,一方面可以使樣本之間能夠直接進行距離的計算,另一方面能夠擴充樣本特征的數目。
3.4 歸一化處理
為消除數據中各指標之間的量綱和取值范圍差異的影響,采用歸一化對Age、MonthlyIncome、Stability、Fidelity、DistanceFromHome 等特征進行線性變換,將數值映射到[0,1]區間。
3.5 樣本傾斜處理
樣本不平衡是指數據集中各個類別分布不平衡,某一類別的樣本個數遠少于其他類別。絕大多數機器學習方法對不平衡的數據集都沒有很好的預測效果。在本文的數據集中,流失樣本237 個,占總樣本的16.1%,未流失的樣本為1 233個,占總樣本的83.9%。流失的個數遠小于未流失的個數,因此在建立模型之前,需要對數據進行樣本不平衡處理。
一般處理數據不平衡的方法有上采樣、下采樣。由于本文的數據集相對較小,因此采用上采樣的方法處理數據不平衡。表3 為針對同一處理后的數據,在決策樹模型下,通過不同采樣方式得到的準確率、精確率、召回率和F1 值。可以看出,隨機上采樣法對本文數據集處理效果最優。
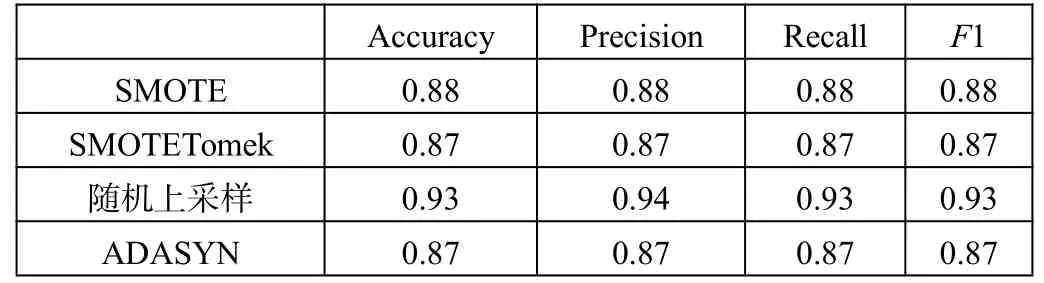
表3 不同采樣方式的比較
4 分類算法的比較及分析
在開始訓練模型之前,把數據集劃分為訓練集和測試集,用來檢驗模型的泛化能力。本文選取80%的數據作為訓練集,20%的數據作為測試集。基于決策樹、支持向量機、隨機森林和LightGBM 算法,分別在訓練集進行模型訓練,后在測試集上進行結果預測。
4.1 模型結果對比及分析
表4 是將平衡之后的樣本代入機器學習模型中訓練的結果。其中用到的模型有決策樹、支持向量機、隨機森林和LightGBM。
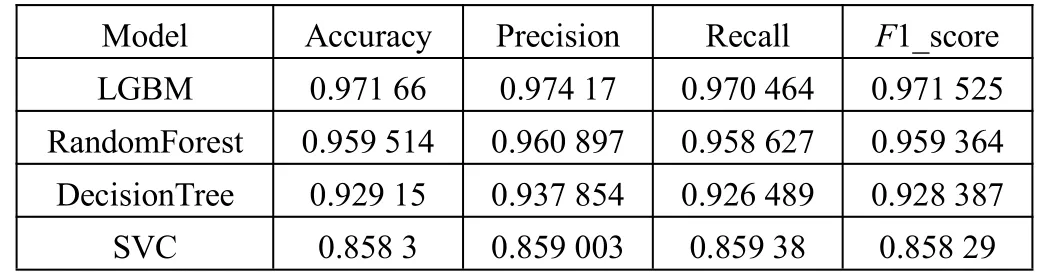
表4 模型結果對比分析
整體而言,雖然集成模型以花費更多時間為代價,但其預測性能較單模型而言更優[6]。就集成模型比較來看,LGBM總體預測效果最好,在測試集上達到97%的準確率。除此以外,還嘗試基于集成學習的stacking 方式構建以LGBM 和SVC 為基學習器,邏輯回歸為二層學習器的LSL(LGBM-SVC-Logistic)模型。從訓練結果看,LSL(LGBM-SVC-Logistic)模型在準確率、精確率、召回率和F1 值上的表現僅與單個LGBM 模型相持平。因此考慮到集成學習stacking 的時間成本,且未帶來更優的模型表現,遂放棄stacking 集成算法。
4.2 特征重要性
對LGBM 模型預測結果進一步分析,將輸入模型的特征進行重要性排序,得到與員工流失傾向相關的主要因素。最具影響力的流失因素重要性排序如圖10 所示,影響流失的主要因素為月收入、收入的距離代價、在每個公司工作年數、年齡、總體滿意度等。在這最重要的10 個因素中,本文所構建的新特征排在第二、三、五、七、八位,以此可以推斷新構建的特征是有效的。而對于企業決策者來說,可以根據這些重要的影響因素制訂相關的政策,如:①制訂合理的薪酬制度,提高員工相應的收入,激發員工的工作積極性,以保證為企業發展貢獻力量[7];②對于一些距離企業遠的員工,給與他們更多交通費上的支持,或者允許路途遙遠的員工遠程上班;③對于那些在每個公司都停留時間不長的員工,給予他們更多的關心和人格需求的關注,讓他們在IBM公司感到足夠的安全感,并愿意長期在IBM 公司工作。
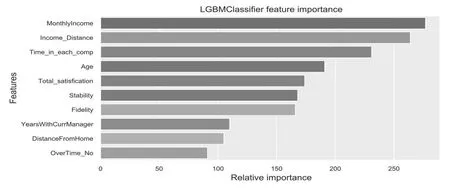
圖10 特征重要性排序圖
5 結論
員工的流失對于企業來說,不論是財務還是非財務方面,都會產生較大負面影響。因此如何降低員工流失率、保留住高效員工已經成為了人力資源部門面臨的最棘手的問題。因此,本文根據IBM Watson Analytics 分析平臺上分享的員工流失數據進行實證分析,著重于數據預處理中的特征挖掘來對員工的流失情況進行預測。實驗結果顯示,新特征的挖掘對于模型的精度提升有較大幫助,模型的預測準確率為0.97。同時,本文識別出了影響員工流失的重要因素,其中包含薪酬、職位穩定性、員工忠誠性等,企業可以根據以上關鍵因素采取有效措施避免企業人才流失。同時,本文還存在一定的不足,在未來的研究中,可以通過調整不同的參數組合,獲取精確度更高的模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工會博覽(2023年3期)2023-04-06 15:52:34
小康(2021年7期)2021-03-15 05:29:03
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
活力(2019年19期)2020-01-06 07:34:38
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
雜文月刊(2019年15期)2019-09-26 00:53:54
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
