滲透緩存命中率誘導的緩存區域動態分配機制研究
2020-06-19 08:45:58李靈枝胡九川葉笑春范東睿嚴龍
軟件導刊 2020年4期
李靈枝 胡九川 葉笑春 范東睿 嚴龍

摘要:為解決計算機體系結構性能瓶頸——存儲墻問題,在依賴硬件技術和體系結構創新的同時,還需優化程序算法。傳統算法主要以時間和空間復雜度作為衡量指標,未考慮計算機存儲結構設置。延遲避免和延遲容忍機制是解決“存儲墻”問題的新途徑。借助一種新型緩存結構——滲透緩存可緩解該問題。利用延遲容忍機制,通過研究滲透緩存模型在處理器片上數據調配方式,提出一種依據歷史訪存命中率變化情況動態調控滲透緩存容量機制(以下簡稱動態滲透機制)。通過改進數據在滲透緩存上的調配策略,使緩存容量動態適應程序的數據特征,經過調整得出命中率更高的緩存結構配置方案。闡述了動態滲透機制原理與仿真實驗模型架構。仿真實驗結果表明,在SPLASH-2的部分測試集下,與傳統緩存命中率相比較,平均提高了7.629%;以動態滲透機制得出的緩存容量配置方案命中率比傳統緩存平均提高31.003%。即在緩存結構改進的動態滲透機制下,訪存命中率得到提高,從而緩解了“存儲墻”問題。
關鍵詞:滲透緩存;存儲墻;動態緩存分區;緩存容量
DOI: 10. 11907/rjdk,192752
開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301
文獻標識碼:A
文章編號:1672-7800(2020)004-0001-08
Research on Dynamic Allocation Mechanism of Cache Area Induced
by Percolation Cache Hit Ratio
LI Lingz-hil. HU Jiu-chuanl . YE Xiao-chunz . FAN Dong-ruj2 , YAN Lon2
(1.SchooL of Computer and Information Technology , Beijing Jiaotong University , Beijing 100044 , Ch.ina ;
2.State Kev Laboratory of Computer A rchitectu re,Institute of Computing Tecnolog了 ,
Clzine..se Academy of .Science.s , Beijing 100 190 . Clzina )Abstract: In order to tackle the performance bottleneck of computer architecture development-memory wall.while rely ing on the in-novation and development of hardware technology and architecture, it is necessary to optimize the program algorithm. Traditional algo-rithms mainly use time and space complexity as a measure. and do not consider the setting of computer storage structure. Delay avoid-ance and delay tolerance mechanisms are new ways to solve the memory wall problem. With the help of a new precolation cache struc-ture and delay tolerance mechanism. this paper proposes a mechanism to dy namically adjust the precolation cache capacity accordingto the change of historical hit rate by studying the allocation method of the precolation cache model on the processor chip. By improvingthe dispatch strategy of' data on the precolation cache storage structure, the capacity of the cache can dvnamically adapt to the charac-teristics of' the program and adjust the cache structure configuration scheme with a higher hit rate.Key Words : percolation cache; memory wall; dynamic cache partition; cache capacity
收稿日期:2019-12-16
基金項目:國家自然科學基金項目(61732018)
作者簡介:李靈枝(1995-),女,北京交通大學計算機與信息技術學院碩士研究生,CCF會員,研究方向為計算機體系結構、軟件工程;
胡九川(1965-),男,博士,CCF會員,北京交通大學計算機與信息技術學院副教授,研究方向為計算機體系結構、范疇論;葉笑春(1981-),男,博士,中國科學院計算技術研究所計算機體系結構國家重點實驗室副研究員,研究方向為眾核處理器設計;范東睿(1979-),男,博士,CCF會員,中國科學院計算技術研究所計算機體系結構國家重點實驗室研究員,研究方向為高通量眾核處理器體系結構;嚴龍(1988-),男,碩士,中國科學院計算技術研究所計算機體系結構國家重點實驗室工程師,研究方向為計算機體系結構。
本文通訊作者:李靈枝。
O 引言
訪存延遲是造成存儲墻問題的重要原因之一,也是高性能、高通量計算性能提高的主要瓶頸之一[1-2]。通過預取技術可以隱藏長時間訪存延遲,降低代價高昂的流水線停滯概率,以緩解存儲墻問題。為保證預取的有效性和準確性,需要在預取策略中權衡不同影響因素,如在恒定步幅預取中合理設置預取步幅,在全局歷史緩沖預取中合理設定要觀測的歷史數據范圍。顯然,要節省處理器資源,提高預取器的準確度,無疑會增加預取算法的復雜度和技術難度。無論采用何種預取方法,擴大預取范圍都會導致數據準確度降低,不準確的預取更會污染緩存,導致處理器性能下降。
為了更好地權衡預取精度與預取范圍的關系,本文將預取思想融合到滲透技術中,改變過去由缺失數據觸發預取的傳統模式,實現將數據源源不斷的涌向處理器核周圍的動態滲透機制。滲透技術是預取技術的深化,指在處理器訪問某個數據之前即預測到處理器需要該數據并將其預先取到片上緩存中,從而避免較高的訪存延遲。動態滲透機制通過在應用程序的訪存過程中設置固定檢查點,定期檢測應用程序的訪存命中率,據此動態調配滲透緩存容量,以達到提高訪存命中率目的。
靜態滲透研究[3-4]提出以泉吸和泉涌緩存作為數據載體的新型層次存儲結構模型,結合該模型提出相應的靜態滲透數據調配方式。由于固定統一的緩存數據調配方式不能靈活動態地對不同訪存模式各程序區分處理,使得滲透緩存對處理器發來的訪存請求只能機械地作出回應,導致滲透緩存存儲結構優勢未充分利用。為解決上述問題,本文提出有針對性地對不同訪存模式程序進行滲透處理算法,依據歷史訪存命中率數據動態調控滲透緩存容量,充分利用數據滲透緩存結構優勢,快速分析訪存蹤跡,挖掘出該程序總體訪存數據特征,識別當前程序的訪存模式,經過多輪動態反饋機制,最后找到最適合當前程序訪存特征的緩存存儲結構配置方案,并通過實驗仿真檢驗算法結果。
仿真實驗結果表明,在SPLASH-2的部分測試集LU、WORDCOUNT、CHOLESKY和RANDOM下,動態調控緩存命中率比傳統方式分別提高6.3482%、3.3021%、0.5124%、20.3538%.在動態滲透算法得出的緩存配置方案下,緩存命中率分別提高84.6522%、4.9791%、9.8053%、24.5741%,表明動態滲透算法能夠避免訪存延遲,提高處理器性能。
1 相關工作
為避免訪存延遲影響計算機性能,人們不斷改進緩存技術、軟硬件預取、多線程和亂序執行思想以及工業集成技術。順序預取[5]、步幅預取[6]、馬爾可夫預取[7]以及全局歷史緩沖預取[8]等技術不斷在改進中發展,雖然預取已經取得了很好效果,但被動的、不適用于多級層次緩存結構的緩存處理方式,以及不能良好平衡預取精度和預取范圍的預取技術,需要結合滲透思想作進一步改進,從而更好地緩解存儲墻問題,提高處理器性能。
滲透技術最初在文獻[9]中以線程滲透一詞提出,旨在充分利用處理器上的硬件線程資源達到線程間相互容忍延遲的目的。由于需要軟件環境支持,線程滲透目前暫未實現;文獻[10]提出滲透延遲容忍模型,將存儲空間劃分為低延遲的核內存儲空間和高延遲的核外存儲空間,并允許并行訪問。該文獻只對特定問題進行了研究,對于求解其它非規則問題則暫未給出證明;文獻[11]提出N-層滲透執行模型,旨在線程執行時就把下一線程所需數據準備好,并把前一線程所訪問過的數據滲透存儲到下一級緩存中;文獻[12]分解了訪存操作,從線程仿真層面動態決定計算操作和訪存操作的時序關系,明確數據在存儲層次中的移動方向。由于滲透操作需程序員人為顯式指定,使技術實現較為困難;文獻[3]、文獻[4]從緩存結構層面深入分析滲透數據在存儲層次中的移動軌跡,提出改進的滲透緩存結構和相應數據調配方式。由于對不同程序采用統一、靜態的緩存調配方式,忽略了探究不同程序數據特點,仿真實驗雖取得了良好效果,但對數據局部性研究空間還很大。
預取技術與滲透技術的研究重心大多集中在數據到達處理器前的階段,即未被處理器訪問過的數據。文獻[13]、文獻[14]指出,在研究緩存數據整體特征時,被處理器訪問過的數據同樣具有重要價值;文獻[13]提出定向反饋預取機制,結合特定歷史數據信息動態調整預取數據的存放位置。借助預取請求的準確性、及時性和由預取引起的緩存污染估計預取器的有效性;為了改善多核系統中共享緩存的分區策略,文獻[15]、文獻[16]提出由初始化、回滾和重分區3階段實現的緩存分區算法,實驗證明該策略可以提高多核系統的吞吐量,改善系統公平性。本文綜合前人研究,提出單核處理器片上對三級滲透緩存進行動態分區的動態滲透算法,將調配數據方式從被動預取轉變為主動預取,明確定義了焦點數據和滲透數據。在緩存數據到達和離開處理器的整個過程中充分利用數據的及時局部性減小訪存延遲,以找到緩存結構配置的更優方案。
2研究內容
2.1動態滲透緩存結構
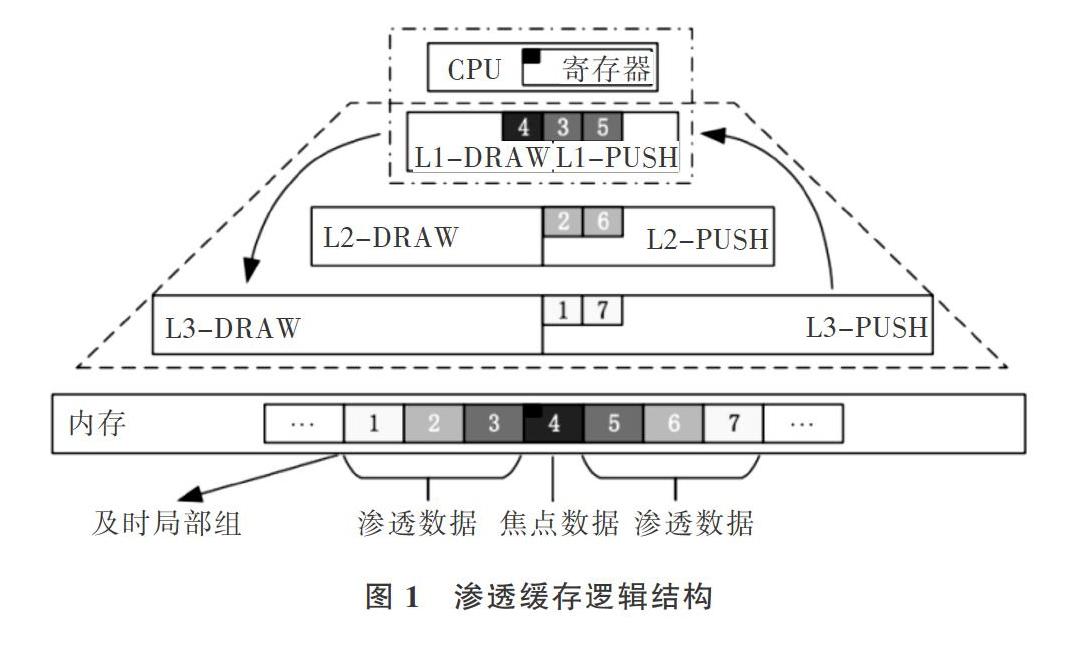
本文依據數據的及時局部性特征定義一個及時局部組,如圖1所示,下面從時間和空間兩方面解釋緩存數據的及時局部性。在局部時間內,剛被處理器訪問過的數據再次被處理器訪問的概率較大;在局部空間內,剛被處理器訪問過的數據前后緊鄰的數據塊在局部時間范圍內被訪問的概率也較大。不同距離間隔和時間間隔都會造成應用程序在及時局部性上的差異波動。穩定的數據及時局部性是縮小訪存延遲,提高處理器性能的基本保證。圖
李靈枝,胡九川,葉笑春,等:滲透緩存命中率誘導的緩存區域動態分配機制研究1中,焦點數據為處理器主動要訪存的數據(紅色小方塊);焦點數據所在塊為焦點數據塊(緩存塊4);與焦點數據塊緊鄰的緩存塊1、2、3、5、6、7為滲透數據塊,顯然滲透數據塊對于焦點數據塊來說具有更好的及時局部性。
為有效保證處理器訪問某數據時,該數據恰好剛剛到達處理器周圍的片上存儲空間中,既不過早也不過晚,本文采用兼具時間局部性和空間局部性的三級滲透緩存代替傳統緩存。滲透緩存結構和傳統緩存結構區別如圖1所示,每級緩存都由兩個性質不同的泉吸緩存( SpringDraw Cache)和泉涌緩存(Spring Push Cache)構成。SDC存儲焦點數據塊,即被訪問過的數據,主要負責維護數據的時間局部性關系。SPC存儲滲透數據塊,即未被訪問過的、焦點數據周邊的數據,主要負責維護數據的空間局部性關系。各級滲透緩存分別賦予不同的、針對處理器內核訪存行為特點的數據緩存功能。當焦點數據塊被遷移到處理器中使用時,一個及時局部組中的滲透數據塊,會根據與焦點數據的不同距離主動遷移到各級SPC緩存中。當處理器用完焦點數據時,焦點數據塊會根據遷出處理器時間的長短,依次以優先級由高到低地按一級、二級、三級泉吸緩存順序遷移到SDC中。
宏觀上數據的流通方向如圖1中紅色箭頭所示,滲透數據從內存遷到SPC,焦點數據從處理器遷到SDC。滲透緩存的緩存單元由有效位valid、標記tag和數據data三部分構成,多個緩存單元構成一個滲透緩存,如圖2所示。在程序執行過程中,滲透數據會隨著焦點數據的移動而動態改變,那些主動滲透遷移到片上的各級緩存數據匯聚在一起,隨著焦點數據的流動,源源不斷地流向處理器核周圍,形成一種處理器被數據包圍起來的態勢,以提高處理器訪存的命中率。
在處理器訪問焦點數據時,滲透數據塊會被搬運到泉涌緩存中來,按照它們與焦點數據塊在內存中的距離劃分重要程度,數據塊越重要就放置在泉涌緩存的越高層級。隨著訪問繼續,泉涌緩存中的數據塊重要程度發生變化,更重要的數據塊會搬運到更高的層級。因此,即使處理器訪問泉涌緩存中的數據塊在該數據塊還未到達最高層級的泉涌緩存中,也可能已經在低層級的泉涌緩存中,這樣就避免了過長的訪存延遲。
2.2動態滲透調配原理
不同配置的緩存結構會導致緩存命中率出現明顯差異。由于不同程序具有不同訪存軌跡特征,所以不同容量配置的滲透緩存其命中率也會有所波動,如果將固定統一的滲透緩存結構用于迥然不同的訪存程序中,很可能導致滲透緩存的性能優勢不能更好利用,因此本文提出適用于非特定應用程序的、可動態改變滲透緩存容量的調配策略,以進一步挖掘滲透緩存的性能優勢。
為了充分兼顧數據的時間與空間及時局部性,設置處理器訪問滲透緩存的順序為第一級緩存到第二級緩存再到第三級緩存,在每級緩存內部先訪問SDC再訪問SPC。滲透操作在處理器發出訪存請求時展開,滲透數據的同時隱藏了處理器訪問已滲透到緩存中數據的加載延遲,從而達到延遲容忍的效果。舉例說明一輪滲透操作如下:每當處理器發出讀寫請求便觸發一輪動態滲透操作,在一輪動態滲透過程中一個及時局部組中的數據塊全部主動遷移到指定緩存中,其中焦點數據被遷移到處理器中直接使用,焦點數據塊遷移到第一級SDC中,以當前焦點數據塊為中心的一個及時局部組中的滲透數據塊3和5遷移到第一級SPC中,滲透數據塊2和6遷移到第二級SPC,滲透數據塊l和7遷移到第三級SPC,過程如圖1所示。
本文提出的動態滲透機制主要分為兩個環節,第一環節先通過分析不同程序獨有的數據特征,經過多輪動態調整后,得出最符合當前程序的緩存結構配置方案,仿真實驗結果表明在此過程中,動態緩存的命中率比傳統緩存高。前義中提出的多輪調整最多需要四輪,初始條件下SDC和SPC在第一、二、三級SDC和SPC上都是平均分配緩存容量大小;在程序運行到第一個監測點時,執行第一輪動態滲透,通過兩兩三組SDC和SPC的命中率大小比較可能得出兩種調整方向;在選擇了當前最優的調度方案后,繼續滲透操作;在到達第二個監測點時開始執行第二輪調整,此時比較以第一輪調整后的緩存容量分配方案下SDC和SPC的命中率分布情況,同樣有兩種調整方向,選擇最優的分配方案,繼續后續滲透操作;在到達第三個監測點時開始執行第三輪調整,此時動態調整的方向需要分情況討論,如果在同級緩存內第一、二輪調整是同時有利于SDC( SPC)的,此時需要選擇有利于SPC(SDC)的方向進
行調整,目的是為了通過第四個監測點時,驗證得出是否前者是最終滲透方案;如果在第三輪動態滲透時發現第一、二輪動態滲透是互逆的滲透操作,則直接比較第一、二輪動態調整后,同級SDC和SPC中各白的命中率表現,選擇命中率較高的作為最終滲透方案,并且不再需要第四輪動態滲透了
動態滲透機制的第二環節主要為了驗證第一環節得出的方案是否是更有效的,因此以第一環節得到的緩存配置方案作為初始條件再一次去仿真驗證,實驗結果表明滲透緩存在此基礎上的命中率能被進一步提高。
2.3歷史命中率誘導的滲透緩存容量動態調控算法
本文中定義(l)為滲透緩存中泉吸、泉涌的命中率表示:
其中上標j為滲透的輪數;下標Cl為第i級泉吸或泉涌緩存,d為SDC,p為SPC,i為滲透緩存級數,如d2表示第二級泉吸緩存;白變量x為滲透數據的時鐘周期為緩存ci的命中次數;為訪問緩存Cl的次數;為緩存ci的容量大小;表示動態調控因子;signa/:表示動態滲透調整信號,可取0,l兩種情況
用式(2)表示第i輪動態調控過程中滲透緩存的總命中率。
設置t為四個動態調控的時間點如圖3所示,在T0時刻到t1。時刻為第一輪滲透,第二、三、四輪滲透依次類推。t0時刻開始動態滲透,初始化操作,將各級滲透緩存平均分配給泉吸泉涌緩存;之后開始對滲透緩存進行第一、二、
三、四輪動態調控并得出結果。
算法Y:依據歷史訪存命中率變化動態調控滲透緩存容量算法。
輸入:
輸…:
tl時刻進行第一輪動態淵控
t2時刻進行第二輪動態調控
t3時刻進行第三輪動態淵控,為l時,在t4時刻進行第四輪動態淵控
結合前文提出的動態滲透機制,概述動態滲透算法調控過程如下:
t1時刻:計算各級滲透緩存中,的值,大的增加倍容量,小的減小倍容量,調整結束后發送給各
李靈枝,胡九川,葉笑春,等:滲透緩存命中率誘導的緩存區域動態分配機制研究個緩存模塊調整信號,等待第二輪動態調控;
時刻:計算和,若高,則反向調整同級間SDC和SPC的大小,調整后發送給各個緩存模塊調整信號,否則不調整,等待第三輪動態調控;
t3時刻:若第二輪反向調整,比較,選擇值最大時緩存大小分配比例;若第二輪沒反向調整,且 大于 ,則反向調整并等待第四輪動態調控,否則選擇第三輪緩存大小分配比例;
t4時刻:由于只有在第二、三輪滲透參數一致的情況下,才會有第四輪比較,所以此時,直接比較 ,選擇值最大時的緩存大小分配比例,即為動態滲透得出的最佳分配比例。
3仿真實驗
3.1仿真平臺模塊設計
本文的關注焦點在于滲透緩存,所以仿真實驗設計主要實現處理器、滲透緩存、內存以及動態滲透主要和緩存密切相關的模塊,滲透緩存動態調控原理和功能邏輯結構如圖4所示,各個模塊功能依次如下:
處理器模塊負責讀取測試集中的訪存地址,解析焦點數據和滲透數據地址;再將滲透請求信號和地址信號發送給滲透緩存模塊;等待動態滲透模塊發來的一輪滲透完成信號和動態滲透信號,一旦收到一輪滲透完成信號,則處理器模塊開始獲取下一條訪存地址。一旦收到動態滲透信號,則動態調整后續滲透操作中的滲透參數。如此循環直至訪存蹤跡文件讀完。
滲透緩存模塊收到來自處理器或上級緩存發來的滲透請求信號和地址信號后,判斷是否在當前緩存命中。若未命中則該請求繼續發送給下級緩存或內存;若命中,則將即將被覆蓋的數據遷移到下一級緩存中。每完成一個滲透數據塊遷移操作,緩存模塊便給動態滲透模塊發送一個單次滲透完成信號。
內存模塊處理來白緩存的滲透請求信號、來自泉吸緩存的替換請求信號。將在緩存中缺失的滲透數據塊復制給相應的緩存。
動態滲透模塊收集來自滲透緩存模塊的一次滲透完成信號,一旦這些信號達到一輪滲透操作應該遷移的數據塊個數,就給處理器模塊發送一個一輪滲透完成信號。一旦時鐘周期到達設定好的時間點,就依次開始四輪動態調控操作,一輪動態滲透完成時發送對應信號給處理器和滲透緩存模塊,使得在后續的訪存操作滲透緩存容量得到動態改變。
3.2滲透緩存參數設置
本文通過仿真平臺實現了傳統緩存模型和動態滲透緩存模型。傳統緩存是目前通用處理器芯片中采用的三級緩存模式,動態滲透緩存模型為上文介紹的三級泉吸泉涌緩存,兩種緩存的訪存順序分別如圖5、6所示。處理器訪問傳統緩存時依次訪問第一級、第二級、第三級緩存,若在第一級緩存發生命中,則直接對數據進行讀寫操作;否則,將數據所在的數據塊從下級緩存或內存中取到第一級緩存中再進行讀寫操作。
處理器訪問滲透緩存時,先根據圖5中指定的訪問順序依次訪問滲透緩存,如果處理器訪問的數據在泉涌緩存命中,則該數據被遷移到第一級泉吸緩存,同時把及時局部組中沒有遷移到泉涌緩存中的數據滲透進來;如果處理器訪問的數據在泉吸緩存命中,則該數據不發生遷移,也不發生數據滲透;如果要訪問的數據沒有在滲透緩存中命中,則訪問內存,同時出發一輪全新的滲透操作,即將處理器訪問的數據發送給第一層泉吸緩存,將及時局部組中其余的滲透數據發送給各級泉涌緩存。當滲透數據到達時,若泉吸緩存已滿,則滲透過來的新數據需覆蓋原來的數據,同時被覆蓋的數據被遷移到下級泉吸緩存或內存中。
滲透緩存只要處理器發出讀寫訪存請求,都將觸發一輪滲透數據的遷移過程,而傳統緩存只遷移當前數據塊到緩存中。顯然,處理器訪問傳統緩存始終只對所訪問的數據所在的那一個數據塊進行操作,而處理器訪問滲透緩存則需要對及時局部組中所有的數據塊進行操作。
仿真實驗中傳統緩存和滲透緩存參數配置如表1所示,滲透緩存和傳統緩存的總容量大小相等,動態滲透算法通過改變緩存的組數實現對緩存容量的動態分配。
3.3實驗結果
由于滲透緩存的結構以及數據搬運數量、調配方法跟傳統緩存在較大區別,若采用傳統緩存的周期時間計算方法作為動態滲透緩存的性能評估指標,其準確性和有效性有待商榷。因此本文采用文獻[17]中對多級緩存的耗時估算方法作為動態滲透緩存的性能評估指標,該估算方法中的關鍵參數為緩存命中率,一般而言,命中率越高緩存性能越高,因此滲透緩存命中率可作為現階段評估緩存性能的主要指標。考慮到緩存是處理器的重要耗能單元,在本文提出的機制中,每次訪存操作都有可能會觸發相關滲透操作,即將會有更多的數據換入和換出操作,可能會導致能耗開銷增加,所以本文通過在單位時間內處理相同數據所消耗的時間來衡量滲透緩存所帶來的額外功耗。
本文選用的測試基準用例為斯坦福大學開發的“面向共享存儲的并行應用程序( Stanfo-d Parallel Applications forShared Memorv)”第二版(SPLASH-2),測試集中的訪存蹤跡是由C語言和pthread編寫的多線程程序生成。本文為了體現時間和空間局部性,選用了SPLASH-2測試集中Choleskv、連續LU為核心測試用例。其中Choleskv將一個稀疏矩陣表示分解為一個下三角矩陣及其轉置;連續LU將一個密集矩陣分解為一個上三角矩陣和一個下三角矩陣的乘積,并允許相鄰的數據被劃分到同一個塊中,分解時使用分塊訪問技術來挖掘每個獨立子塊中的時間局部性。此外,本文還選用普通的Wordcount程序的訪存蹤跡和隨機生成的訪存蹤跡作為測試集進行仿真實驗,驗證動態調控算法的普適性。
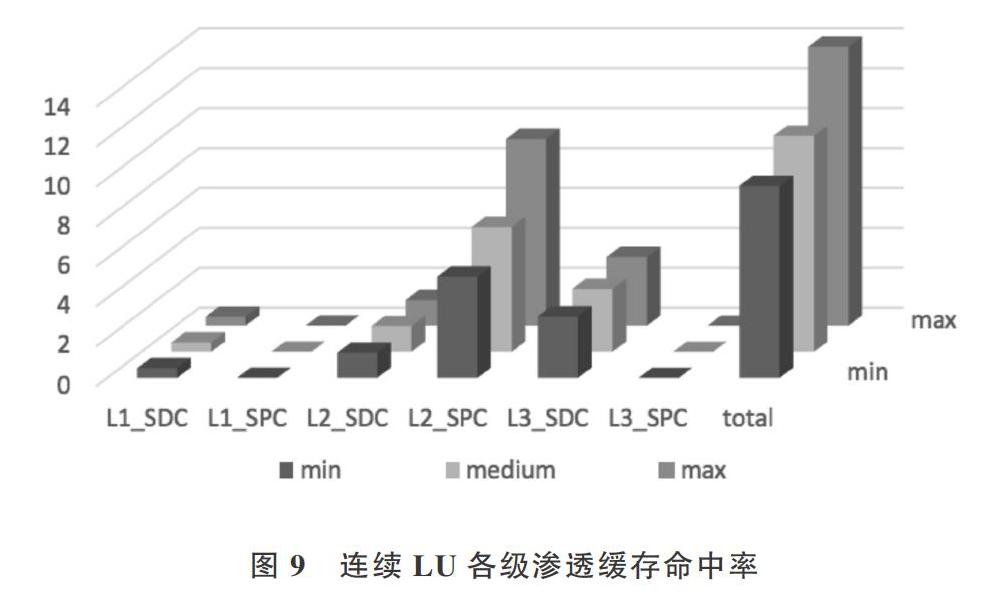
各個測試集中三級滲透泉吸、泉涌緩存的仿真結果命中率表現分別如下圖7、8、9、10所示,文獻[14][18]中指出過多的依賴歷史數據會導致算法的效率降低,即良好的算法需要在普適性、簡單性和累積參照數據之間取得平衡。因此本文設計仿真實驗時,設置了不同大小的歷史數據作為累積信息,用¨表示,其中min表示在一輪動態滲透的過程中參考的歷史數據大小為總測試集的2.5%,mid與max分別為5%和10%。
實驗結果表明在隨機訪存蹤跡、Choleskv和Wordcount測試集下,泉吸緩存的命中率相對較高,即被訪問過的數據更趨向于再次被訪問,數據的時間局部性較好。而在連續LU測試集的情況下,第二級泉涌緩存和第三級泉吸緩
動態滲透算法在不同測試集下的時間消耗如下圖11所示。傳統表示傳統的三級緩存;動態一1結果是在動態調控滲透過程中得出的結果,即動態滲透算法的第一環節;動態一2結果是以動態滲透算法得出最佳滲透緩存容量配置為初始條件時得到的結果,即動態滲透算法的第二環節;靜態表示靜態滲透得到的結果。存的命中率相對更高,即與焦點數據塊隔一個數據塊的數據和被訪問過的數據更可能被訪問,即及時局部性整體較好。
李靈枝,胡九川,葉笑春,等:滲透緩存命中率誘導的緩存區域動態分配機制研究
上圖中,相較于傳統的三級緩存而言,新型的以SDC、SPC構成的三級滲透緩存雖然在命中率上有所提高,但是在耗時上也有明顯增加。可以看出,動態滲透相較于靜態滲透而言,功耗依然是較小的;在LU測試集下動態滲透的兩個階段所消耗的時間有明顯波動,在動態一1的滲透階段SDC和SPC容量的動態調整過程中,緩存數據的換入換出破壞了LU連續測試集(將一個密集矩陣分解為一個上三角矩陣和一個下三角矩陣的乘積,即矩陣被分解為一個一維的數組,允許相鄰的數據被劃分到同一個塊中,即時間局部性較好)原本良好的時間局部特性,造成讀取完同樣的測試數據時,所耗時間較大。
動態滲透算法在各個測試集下仿真實驗結果如表2和所示圖11所示。根據實驗結果可以得出,在隨機訪存蹤跡測試集下,越小滲透緩存命中率越高;在連續LU測試集下, 越大滲透緩存命中率越高,不同 的命中率相差明顯;在Wordcount測試集下,滲透緩存命中率在 取5%時表現最好,過小和過大的 都會導致滲透緩存命中率都會下降。
圖12表明,動態滲透算法能夠充分挖掘數據的及時局部性,針對不同程序的不同訪存模式給出針對性的、命中率更高的滲透緩存容量分配方案。圖13展示了動態滲透算法在各測試集下帶來的性能變化。
相對于傳統緩存而言,在執行動態滲透的過程中滲透緩存命中率在全部測試集上都有所提高,相較傳統緩存,滲透緩存命中率分別提高6.3482%、3.3021%、0.5124%、20.3538%:在動態滲透算法得出的緩存配置方案設置下,緩存命中率分別提高84.65 2%、4.979 1%、9.805 3%、24.5741%,實驗結果表明動態滲透算法能夠進一步避免訪存延遲和提高處理器性能;動態滲透結果比靜態最優配置時的命中率平均提高2.07%;在測試集Cholesky的情況下,動態滲透算法得出的緩存容量分配方案相對于傳統緩存都有所提高,但是相對于靜態滲透,命中率反而降低了0.0033%,原因是在動態改變滲透緩存容量由大變小時,遷移數據會導致訪存延遲急劇增加,因此只能犧牲容量被調小的緩存中已有的數據;當緩存容量由小變大時,新增緩存是未遷移數據的空白空間,隨著處理器后續的訪存需求,數據被遷移進來。在此過程中,若訪問被犧牲掉的數據會造成命中率在極小范圍內有所下降。
由于傳統緩存模型中主要考慮數據向處理器核聚集的過程,未考慮數據往外流動的過程,而本文提出的動態滲透機制不僅通過泉涌和泉吸兩個方向的滲透操作,保證數據流人和流出的有序控制,同時泉吸機制能夠更好地滿足數據的時間重用性,對于時間重用步長較短的數據可以高效地再次訪問到,避免了數據的頻繁換出,減少了內存抖動。
4 結語
本文在靜態滲透基礎上提出的依據歷史訪存命中率的變化動態調控滲透緩存容量的算法,其性能較之傳統緩存和靜態滲透緩存有較大提升。由于程序訪問的局部性原理,及時局部組中的數據塊下次被訪問的可能性較高,并且不同程序的數據特征在SDC和SPC上有不同的性能表現,因此合理、動態的配置各級滲透緩存容量的大小有利于創造更優良的數據及時局部性,以提高處理器性能。
通過仿真實驗得出結論:動態滲透機制深入地挖掘了數據的時間和空間局部性,由于SDC和SPC的大小比例配置要視程序的局部性情況而定,不同的配置會使滲透緩存的性能表現各不相同。動態滲透機制通過對不同訪存模式的應用,經過動態多輪調整和檢驗得出較為適合當前程序的滲透緩存容量配置方案。
在仿真實驗中,本文為了直觀的和靜態滲透作出對比,采用了評估傳統緩存的緩存周期時間模型(CVcle TimeModel)計算方法和單位時間耗時量作為評價動態滲透緩存性能的標準,在其他功耗方面的研究還需推出一種更合理、全面的評價指標,因此為了更加全面有效地評估動態滲透機制對處理器的性能貢獻,迫切需要研究出一種適合滲透緩存的周期時間計算方法。本文從三級SDC和SPC容量的角度研究了動態調控滲透緩存容量的機制,后續研究T作中,我們將進一步討論對前文提出的及時局部組數據的概念,是否可以通過對一輪滲透中的數據塊的個數進行動態調控,進一步完善對滲透緩存動態調控機制的研究。
參考文獻:
[1]胡九川,范東睿,李丹萍,等.一種支持數據滲透遷移的片上緩存模型研究[J].北京交通大學學報,2017,41(5):1-9
[2]李丹萍.單核處理器片上滲透數據調配方法研究[D].北京:北京交通大學 . 2016.
[3]HASHEMI M. KHUBAIB N. EBRAHIMI E, et al. Accelerating De-pendent Cache Misses with an Enhanced Memorv Controller[C] . Acm/ieee International Sympnsium on Computer Architecture. IEEE , 2016.
[4]GALR J, CHALDHURI M. RAMACHANDRAhr P, et al. Near-Opti-mal Ac.cess Partitinning for Memory Hierarchies with Multiple Hetero-geneous Bandwidth Sourc.es [C]. IEEE International Symposium onHigh Performance Computer Architecture. IEEE. 2017, 4-8 (2)13-24.
[5]SMITH A J. Seqential program prefetching in memory hierarchies FJl.
Computer, 1978, 11( 12) :7-21.
[6]FU J W C, PATEL J H. JANSSENS B L. Stride directed prefetchingin scalar processors [C]. International Symposium on Microarchitec-ture. ACM . 1992
[7]JOSEPH D, GRUNV'ALD D. Prefetching using markov predictors [Cl. International Symposium on Cnmputer Architecture. ACM,
1997 : 252-263.
[8]NESBIT K J, SMITH J E. Data cache prefetching using a glohal histo-ry bufferl J]. Micro IEEE , 2005 , 25( 1) : 90-97.
[9]GAO G R, THEOBALD K B. STERLING T L. et al. Programmingmodels and system software for future high-end computing systems:work-in-progress [Cl. International Parallel & Distributed Process-ing Symposium. IEEE . 2003.
[10]TAN G. SLN N, GAO G R. Improving performance of dynamic pro-gramming via parallelism and lr)cality on multicnre architectures [J] .IEEE Transactions on Parallel & Distributed Systems , 2008. 20(2) : 261-274.
[11]袁楠眾核處理器中訪存延遲容忍和避免技 術的研究[D] .北京 : 中國科學院 i-l算技術研究所 . 2010.
[12]GARCIA E, OROZCO D. KHAN R, et al. A dynamic schema tn in-crease performance in many-core architectures through percolationoperations [C] . International Conference on High Performance Com-puting. IEEE Computer Society, 2013.
[13]SRINATH S, MUTLL 0, KIM H, et al. Feedhack directed prefetch-ing: improving the performance and bandwidth-efficiency of hard-ware prefetchers [C]. IEEE International Symposium on High Perfor-mance Computer Architecture. IEEE Computer Society, 2007.
[14]JAIN A. LIN C. Rethinking helady's algorithm to acc.ommodateprefetching[Cl. ISCA Fair cache sharing and paititioning in a chipmultiprocessor arc:hitecture . 2004.
[15]KIM S, CH D. SOLIHIN Y. Fair cache sharing and partitioning in achip multiprocessor architecture [C]. Partitioning in multiprocessorarchitecture .2004
[16]王磊 ,劉道福 , 陳云霽 ,等.片上多核處共享資源分配與調度策略研究綜述[J] .計算機研究與發展 , 2013,50(10): 2212-2227.
[17]HENNESSY J L. PATTERSON D A. Computer architecture : a quan-titative approach[M]. Fifth Edition. San Francisco: MorganKaufmann. 2012.
[18]BELADY L A. A study of replacement algorithms for a virtual-stor-age computer[J].Imb Syst J, 1966.5(2) : 78-101.
