改進RetinaFace的自然場景口罩佩戴檢測算法
2020-06-18 05:43:12牛作東李捍東陳進軍
計算機工程與應用 2020年12期
牛作東,覃 濤,李捍東,陳進軍
貴州大學 電氣工程學院,貴陽550025
1 引言
自2019年12月以來,在我國爆發(fā)了新型冠狀病毒肺炎(COVID-19)傳播疫情[1],到目前為止(2020年2月27日),根據(jù)國家衛(wèi)生健康委員會發(fā)布的最新消息,31個省(自治區(qū)、直轄市)和新疆建設兵團由新型冠狀病毒感染的肺炎患者累計報告確診病例78 824例,累計死亡病例2 788例,現(xiàn)有確診病例39 919例。新型冠狀病毒具有極強的傳染性,它可以通過接觸或者空氣中的飛沫、氣溶膠等載體進行傳播,而且在適宜環(huán)境下可以存活5天[2-3]。因此勤洗手、佩戴口罩可以有效降低被病毒傳染的機率。國家衛(wèi)生健康委員會發(fā)布的《新型冠狀病毒感染肺炎預防指南》中強調(diào),個人外出前往公共場所、就醫(yī)和乘坐公共交通工具時,佩戴醫(yī)用外科口罩或N95口罩。因此在疫情期間公共場所佩戴口罩預防病毒傳播是每個人的責任,這不僅需要個人自覺遵守,也需要采取一定的手段監(jiān)督和管理。
雖然目前沒有專門應用于人臉口罩佩戴檢測的算法,但是隨著深度學習在計算機視覺領域的發(fā)展[4-6],基于神經(jīng)網(wǎng)絡的目標檢測算法在行人目標檢測、人臉檢測、遙感圖像目標檢測、醫(yī)學圖像檢測和自然場景文本檢測等領域都有著廣泛的應用[7-10]。
本文通過研究相關的目標檢測算法,發(fā)現(xiàn)用于人臉檢測的深度學習模型可以適用于口罩佩戴的檢測任務。其中文獻[11]從穩(wěn)健的錨點角度看待小人臉檢測(Seeing Small Faces from robust anchor’s perspective,
SSF)問題,對先驗框進行了比例不變性設計,提出了新的預期最大重疊(Expected Max Overlapping,EMO)值解決檢測框重疊問題,并采用新的網(wǎng)絡體系結構來減少先驗框跨度、額外位移和目標隨機性轉移問題,該方法增強了人臉檢測中對小人臉檢測的能力。文獻[12]提出了一種雙鏡頭人臉檢測(Dual Shot Face Detector,DSFD)方法,在該方法中使用了一種功能增強模塊(Feature Enhance Module,F(xiàn)EM)來增強原始特征圖,提出了利用計算出的漸進式錨點損失(Progressive Anchor Loss,PAL)和 改 進 的 錨 點 匹 配(Improved Anchor Matching,IAM)優(yōu)化了回歸網(wǎng)絡的初始化,最終取得了不錯的人臉檢測效果。文獻[13]提出了一種基于單次縮放感知的卷積神經(jīng)網(wǎng)絡的人臉檢測器(Single-shot scale-aware network for real-time Face Detection,SFDet),該方法設計了一個具有多尺度感知的檢測網(wǎng)絡和與之相關聯(lián)的先驗框并在分類損失計算中引入了交并比(Intersection over Union,IoU)感知加權方案從而提高了人臉檢測的效果。文獻[14]提出了一種單階段野外人臉定位算法,命名為RetinaFace,該方法采用軟量級的骨干網(wǎng)絡,可以在單個CPU上實時運行并完成多尺度的人臉檢測、人臉對齊、像素級人臉分析和人臉密集關鍵點三維分析任務。在WIDER FACE[15]人臉數(shù)據(jù)集上的人臉檢測平均精度(Average Precision,AP)對比結果如表1所示,WIDER FACE是一個人臉檢測基準(Benchmark)數(shù)據(jù)集,也是世界數(shù)據(jù)規(guī)模最大的權威人臉檢測平臺,它根據(jù)圖片中人臉檢測難度分為了容易(Easy)、中等(Medium)和困難(Hard)三個等級。
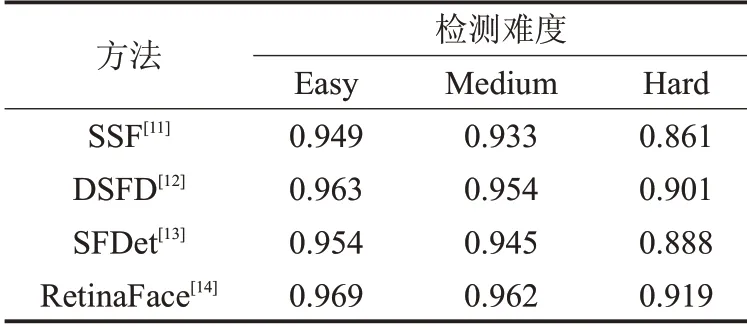
表1 人臉檢測mAP值對比 %
從表1的對比結果中可以看出RetinaFace在人臉檢測方面具有一定的優(yōu)勢,因此本文通過改進RetinaFace提出了一種自然場景下人臉口罩佩戴檢測方法,主要工作有以下幾點:
(1)改進了RetinaFace算法的網(wǎng)絡結構,在人臉檢測的基礎上通過改進分類損失函數(shù)增加了人臉口罩配戴檢測任務,并且去掉了人臉關鍵點三維分析等無關的檢測任務,提高算法的訓練速度。
(2)在RetinaFace的特征金字塔網(wǎng)絡中引入了注意力機制,并進行了優(yōu)化,增加了自注意力機制(Self-Attention),使特征提取網(wǎng)絡提取有效的目標信息并抑制無用信息,增強特征圖的表達能力和上下文描述能力。
(3)制作了新的數(shù)據(jù)集,并對數(shù)據(jù)做了大量的手工標注用于模型網(wǎng)絡的訓練和測試。
2 RetinaFace算法原理
RetinaFace是一種魯棒的單級人臉檢測算法,該算法利用多任務聯(lián)合額外監(jiān)督學習和自監(jiān)督學習的優(yōu)點,可以對不同尺度的人臉進行像素級定位。該算法的網(wǎng)絡結構如圖1所示,它融合了特征金字塔網(wǎng)絡、上下文網(wǎng)絡和任務聯(lián)合等優(yōu)秀的建模的思想。
2.1 RetinaFace特征提取網(wǎng)絡
在RetinaFace算法的特征提取網(wǎng)絡中采用了從P2到P6特征金字塔的五個等級,其中P2到P5是由相應的殘差連接網(wǎng)絡(Residual Network)[16]的輸出特征圖(C2至C6)分別自上而下和橫向連接計算得到的。P6是通過C5采用Stride=2的3×3的卷積核進行卷積采樣得到的。C1到C5使用了ResNet-512在ImageNet-11數(shù)據(jù)集上經(jīng)過預訓練的殘差層[17],對于P6層使用了“Xavieer”方法[18]進行了隨機初始化。
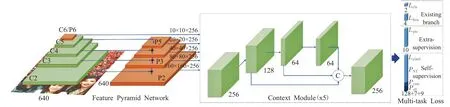
圖1 RetinaFace網(wǎng)絡結構
RetinaFace算法使用了五個獨立的上下文模塊,分別對應P2到P6五個特征金字塔級別,用來增加感受野的作用域和增強魯棒的上下文語義分割能力。另外使用了可變形卷積網(wǎng)絡(Deformable Convolutional Network,DCN)[19]代替了上下文模塊中的3×3卷積層,進一步加強了非剛性的上下文建模能力。
2.2 RetinaFace多任務損失函數(shù)
對于一個訓練的錨點(Anchor)框i,多任務聯(lián)合損失函數(shù)定義為:

其中,Lcls是分類損失函數(shù),pi是錨點框中包含預測目標的概率,∈(0,1)分別表示是負錨點框和正錨點框。Lbox是目標檢測框回歸損失函數(shù),其中ti={tx,ty,tw,th}i表示與正錨點框相關的預測框的坐標信息,同理=表示與負錨點框相關的預測框的坐標信息。是面部標志回歸損失函數(shù),其中l(wèi)i=和分別表示正錨點框中預測的五個人臉標志點和標注的五個人臉標志點。Lpixel表示的是面部密集點回歸損失函數(shù)。λ1、λ2和λ3表示的是損失平衡權值參數(shù),在RetinaFace算法中分別設置為0.25、0.1和0.01,意味著在有監(jiān)督的學習中再加關注檢測框和面部標志點的信息。
2.3 RetinaFace錨點框
RetinaFace算法中在P2到P6不同的特征金字塔級別中使用不同的錨點框,如表2所示。其中在P2層中通過平鋪尺度小的錨點框來捕捉小的面部特征,因此會花費更多的計算,并且承擔更大的誤報風險。對于輸入圖像大小為640×640,縮放步長設置為21/3,將長寬比設置為1∶1,錨點框在特征金字塔的各個級別上覆蓋的尺度可以從16×16到406×406,總計產(chǎn)生102 300個錨點框,并且其中的75%來自特征金字塔P2層。
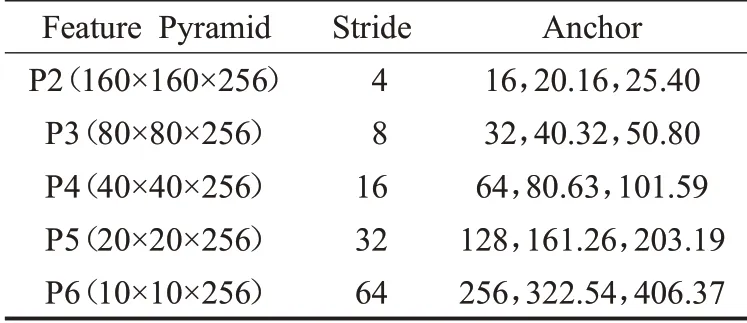
表2 錨點框尺寸
3 改進RetinaFace算法用于口罩佩戴檢測
為了實現(xiàn)對人臉口罩佩戴進行檢測,本文在RetinaFace算法的基礎上進行了改進,改進后的網(wǎng)絡結構如圖2所示,整個框架分為特征金字塔網(wǎng)絡、上下文網(wǎng)絡和多任務聯(lián)合損失三個部分。其中在特征金字塔中的主干網(wǎng)絡為ResNet-512,用于特征提取并引入了注意力機制模塊,增強特征圖的表達能力。在多任務聯(lián)合損失中舍去了無關的面部密集點回歸損失,提高算法模型的訓練速度和效率。
3.1 特征提取網(wǎng)絡
本文使用預訓練好的Resnet-512作為特征金字塔網(wǎng)絡的主干網(wǎng)絡,用于特征提取,除了第一層使用7×7的卷積外,其余4層均由殘差連接單元組成,對于Res_N層表示包含n個殘差連接單元。使用殘差連接可以有效地解決深層網(wǎng)絡訓練的時候會出現(xiàn)梯度消失或梯度爆炸的問題,殘差連接單元的內(nèi)部結構如圖3所示。

圖3 殘差單元結構
在殘差連接單元中,對于輸入特征向量x,輸出特征向量y,通過殘差連接建立的計算公式為:

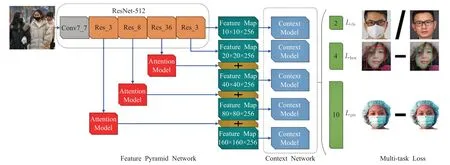
圖2 本文算法的網(wǎng)絡結構
其中,σ表示線性修正單元(Rectified Linear Unit,ReLU)激活函數(shù),Wi表示權重參數(shù),f(x,{Wi})表示需要學習的殘差映射,對于圖中三層的殘差連接單元,其計算方式如公式(3)所示。相加操作通過快捷連接和逐元素進行相加,相加之后再次采用ReLU激活函數(shù)進行非線性化。
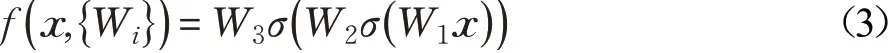
3.2 改進的自注意力機制
本文在特征金字塔網(wǎng)絡中引入了注意力機制模塊,其內(nèi)部結構如圖4所示,主要包括金字塔注意力機制(Pyramid Attention Mechanism,PAM)和自注意力機制(Self-Attention,SA)。金字塔注意力機制可以增強特征圖的表達能力,自注意力可以更好地利用特征的上文關系,提高注意力特征圖的描述能力。

圖4 自注意力網(wǎng)絡結構
在金字塔注意力機制中包括聚合操作、分布操作和描述操作。設輸入的特征圖包含C個通道,其中的單個通道特征可表示為xi∈RH×W×1,i=1,2,…,C,其中聚合操作利用空間池化fk生成一個k級的空間特征圖描述,具體計算方式為:

空間特征圖描述隨著k的增長會更加詳細,為了進一步滿足在多任務上的不同需要求,引入敏感性m來度量描述的詳細程度,對于敏感性m可以用來描述金字塔池化后的特征向量的集合:

則包含多級特征上下文的空間注意力特征圖描述為:

空間特征分布的表達式為:
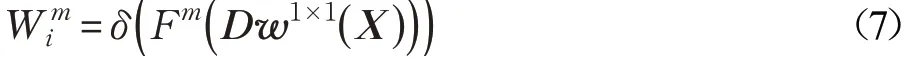
其中,X∈RH×W×C表示輸入特征圖,Dw1×1表示內(nèi)核為1×1的深度卷積。Fm表示與聚合操作具有相同敏感性的空間池化特征的集合。δ表示用于歸一化的Softmax函數(shù)。最后每個空間特征的描述可以表示為:


其中,δ表示Sigmod函數(shù),Xd是由公式(8)獲得的所有通道描述的集合。W1∈RC×C/r,W0∈RC/r×C,σ表示ReLU函數(shù)。r定義為平衡因子,在所有實驗中將其設置為16,以平衡準確性和復雜性之間的關系。最后的輸出特征圖可表示為:

其中?表示逐通道乘法。
3.3 多任務聯(lián)合損失
本文參考了RetinaFace算法損失函數(shù)的設計,為了提高算法的訓練速度和檢測效率,只保留了相關的分類損失、檢測框回歸損失和面部標志回歸損失,并進行了優(yōu)化。去掉了面部密集點回歸損失。總的損失函數(shù)表示為:
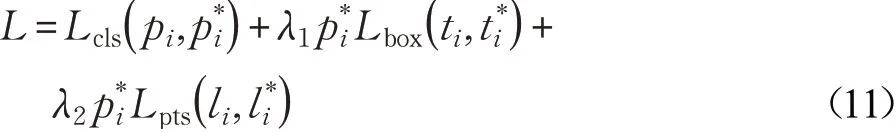
各變量定義如公式(1),其中分類損失Lcls( pi,)是由交叉熵損失函數(shù)做的二分類(完整人臉和佩戴口罩人臉),檢測框回歸損失Lbox( ti,)使用了Smooth-L1損失函數(shù),面部標志回歸損失Lpts( li,)同樣使用了Smooth-L1損失函數(shù)對五個檢測的人臉標志點做了歸一化處理。另外,本文將損失平衡權值參數(shù)λ1和λ2分別設置為0.3和0.1。
4 實驗分析
4.1 實驗數(shù)據(jù)集
由于目前沒有公開的自然場景人臉口罩佩戴數(shù)據(jù)集,本文參考WIDER FACE數(shù)據(jù)集和RetinaFace算法對數(shù)據(jù)集的處理方法,制作了人臉口罩佩戴數(shù)據(jù)集。首先從WIDER FACE人臉數(shù)據(jù)集和MAFA(Masked Faces)[21]遮擋人臉數(shù)據(jù)集中分別隨機抽取1 400張人臉圖片和1 600張人臉佩戴口罩圖片,共包含16 344張人臉目標和3 127張口罩佩戴目標。然后對數(shù)據(jù)集進行統(tǒng)一的標注,標注的信息主要有目標框的中心坐標、長度、寬度、類別和五個人臉標注點,示例如圖5所示,對應的標注數(shù)據(jù)如表3所示。其中80%圖片用于模型訓練,剩余20%的圖片用于測試。
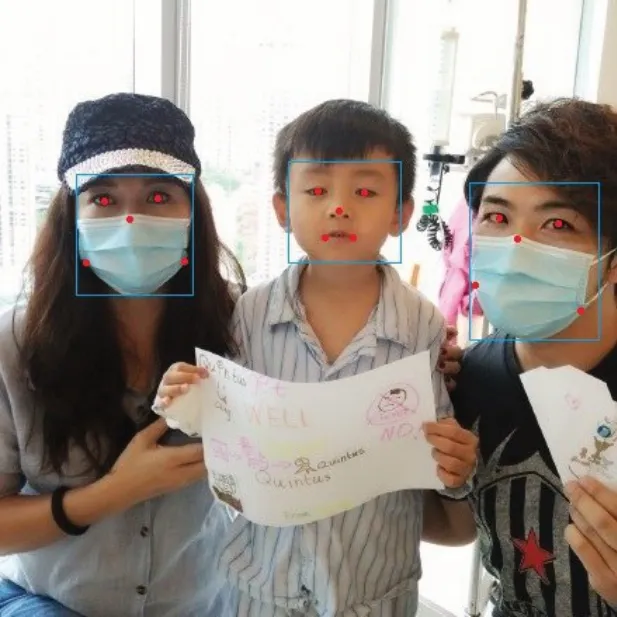
圖5 數(shù)據(jù)集標注示例圖片
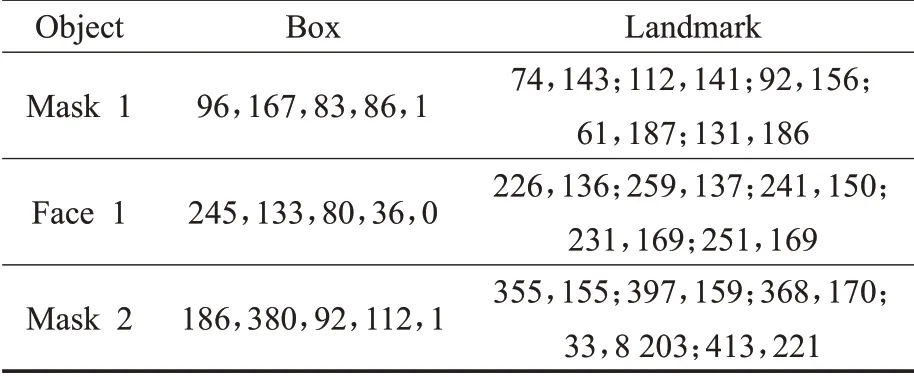
表3 示例圖片標注數(shù)據(jù)
4.2 網(wǎng)絡模型訓練
本文算法在Ubuntu 18.04操作系統(tǒng)中編程實現(xiàn),編程語言采用的是Python 3.6,深度學習框架為MXNet 1.0,另外使用GPU加速工具CUDA 8.0。硬件配置主要包括CPU為Intel?CoreTMi7-8700K@3.7 GHz,GPU為NVDIA GTX 1080Ti@11 GB,RAM為32 GB。
訓練方式采用隨機梯度下降(Stochastic Gradient Descent,SGD)優(yōu)化模型對網(wǎng)絡進訓練,動量為0.9,權重衰減為0.000 5,批量為8×4。學習率從10-3開始,當網(wǎng)絡更新5個輪次(epoch)后上升到10-2,然后在第34和第46個輪次除以10,整個訓練過程一共進行60個輪次結束。
另外,在相同的實驗環(huán)境下,使用相同的訓練方式,本文訓練了一個原始的RetinaFace網(wǎng)絡模型,用于對比分析。
4.3 實驗結果分析
本文將數(shù)據(jù)集中20%的圖片用于實驗測試分析,共600張圖片,其中包含標注的3 196個人臉目標和684個佩戴口罩目標。評估指標使用目標檢測領域常用的ROC曲線(Receiver Operating Characteristic curve)、平均精度AP(Average Precision)、平均精度均值mAP(Mean Average Precision)和每秒幀率FPS(Frame Per Second)來客觀評價本文算法對于人臉和口罩佩戴檢測的效果。其中AP的值反映單一目標的檢測效果,其計算方式為:

其中,p(r)表示真正率(True Positive Rate)和召回率的映射關系,真正率p和召回率r的計算方式為:

其中TP(True Positive,真正數(shù))表示正樣本被預測為正樣本的個數(shù),F(xiàn)P(False Positive,假正數(shù))表示負樣本被預測為了正樣本的個數(shù),F(xiàn)N(False Negative,假負數(shù))表示正樣本被預測為負樣本的個數(shù)。本文根據(jù)真正率和假正數(shù)的關系繪制ROC曲線用來表示對目標檢測的性能,如圖6所示,其中橫軸表示假正數(shù),縱軸表示真正率。總體上看本文算法和RetinaFace算法對人臉的檢測效果明顯優(yōu)于口罩佩戴檢測,原因是在數(shù)據(jù)集中人臉目標多于口罩佩戴目標,在模型訓練過程中可以學到更多的人臉特征信息。當假正數(shù)到達600時,在人臉目標檢測上本文算法和RetinaFace的檢出率分別為0.938和0.928,在口罩佩戴目標檢測上本文算法和RetinaFace的檢出率分別為0.853和0.798,可以看出本文算法的檢測性能相比RetinaFace算法均有所提高。
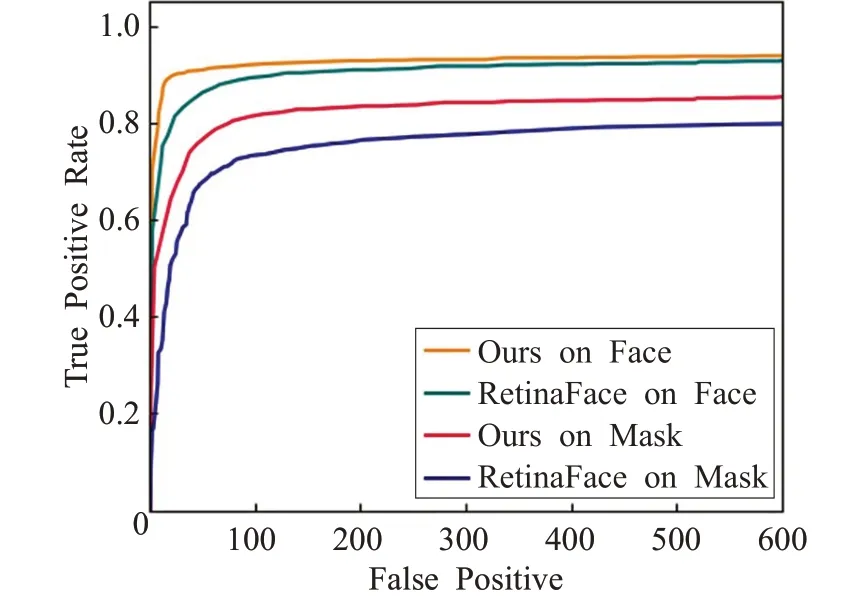
圖6 ROC曲線比對數(shù)據(jù)
mAP表示所有類別平均精度的均值,反映了總體上的目標檢測效果,其計算方式為:

其中,n表示類別的個數(shù),i表示某個類別。
每秒幀率(FPS)表示每秒處理的圖片數(shù)量,用來衡量算法的檢測效率。本文將IoU設置為0.5時的實驗結果如表4所示。可以看出,由于本文在訓練好的RetinaFace網(wǎng)絡基礎上進行初始化訓練,因此在人臉類別的檢測上AP值分別高達90.6%和87.3%,在人臉口罩佩戴檢測上的取值分別為84.7%和76.5%。總體而言,本文改進的網(wǎng)絡模型與RetinaFace相比mAP值提高了5.8個百分點。在檢測效率上,本文算法使用注意力機制增加了計算量,檢測效率略低于RetinaFace算法。

表4 實驗對比數(shù)據(jù)
從ROC曲線和平均精度均值兩個指標上看,本文算法改進后在人臉檢測和口罩佩戴檢測方面RetinaFace均有一定程度的提高,具體檢測示例效果如圖7所示,第一行圖片中的正常目標,本文算法和RetinaFace均取得了不錯的檢測效果,正確檢測出了圖片中的目標信息。對于第二行圖片中當包含小尺寸目標時本文算法的檢測效果相比RetinaFace提升較大,正確檢測出了4個小的人臉目標。對于第三行圖片中部分受到遮擋的目標,本文算法相比RetinaFace具有一定的檢測能力,分別檢測出了一個受遮擋的人臉目標和口罩佩戴目標。對于拍攝環(huán)境較差的第四行圖片,本文算法的檢測能力優(yōu)于RetinaFace,可以檢測出圖片中清晰度低的目標。在消融實驗中進一步具體分析了本文提出的改進方法對模型檢測能力的影響。

圖7 口罩佩戴檢測效果對比示例
4.4 消融實驗
消融實驗是深度學習領域常用的實驗方法,用來分析不同的網(wǎng)絡分支對整個模型的影響[22]。為了進一步分析本文通過引入自注意力機制對模型進行口罩佩戴檢測的影響,進行了消融實驗,首先將本文算法裁剪成四組分別進行訓練,然后對測試集中的檢測目標進行分類,目標像素小于32×32的為小目標(Small),目標標注點小于等于3的為缺損目標(Defect),其余的為正常目標(Normal),最后測試不同實驗組在不同目標類別上的mAP,實驗結果如表5所示,第二組網(wǎng)絡中增加了金字塔注意力機制,在三種類別上的mAP值相比第一組網(wǎng)絡分別提升了4.5、2.8和8.4個百分點,提升最高的是小目標類別,這是由于在金字塔注意力機制中使用了聚合操作、分布操作和描述操作,在通道中有效保留了小目標的特征信息,增強了特征圖的表達能力,提高了小目標的檢測效果。
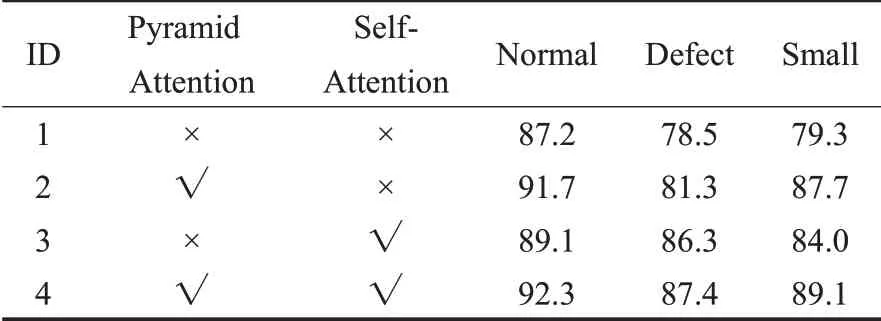
表5 消融實驗中mAP值對比數(shù)據(jù) %
第三組網(wǎng)絡中引入了自注意力機制,在三種類別上的mAP值相比第一組分別提升了1.9、7.8和4.7個百分點,提升最高的是缺損目標,這是由于通過自注意力機制使得特征圖在空間上增強特征上下文之間的聯(lián)系,使用少量的特征點也能更好地描述特征圖的信息。相比第二組網(wǎng)絡,在三種類別上的mAP值分別提升了-2.6、5.0和-3.7個百分點,可以看出單獨使用自注意力機制在正常目標和小目標檢測上弱于單獨使用金字塔注意力機制,這是由于自注意力機制無法抑制特征圖通道上無用信息的干擾,使網(wǎng)絡學習得到了無關的信息描述,從而影響了網(wǎng)絡的檢測效果。
第四組網(wǎng)絡使用了金字塔注意力機制和自注意力機制在三種類別的目標上均取得了最優(yōu)的檢測結果,說明本文改進的注意力機制結構的合理性和有效性。
4.5 自然場景口罩佩戴檢測實驗
為了驗證本文算法在自然場景下口罩佩戴檢測的效果,在視頻中進行了測試實驗,實驗結果如圖8所示,該視頻是從互聯(lián)網(wǎng)中爬取,視頻尺寸為450×360,幀速率為25.0幀/s,可以看出,在整體上本文算法可以有效地對視頻中人臉口罩佩戴進行檢測,但也有漏檢的情況出現(xiàn),其中圖8(b)出現(xiàn)了一個錯檢測目標。另外,在視頻內(nèi)容進行畫面切換的幀中,出現(xiàn)了檢測失真的情況,如圖8(d)所示,原因是本文算法在處理視頻中口罩佩戴檢測時效率不足,這也是在未來的工作中需要改進的地方。

圖8 視頻中口罩佩戴檢測效果
5 結論
本文通過改進RetinaFace算法,提出了一種自然場景下人臉口罩佩的檢測方法,該方法通過在特征金字塔網(wǎng)絡中引入注意力機制,分別使用了金字塔注意力機制增強特征圖在通道上的表達能力,并抑制無用信息,使用自注意力機制在特征圖的空間上增強了上下文聯(lián)系和特征描述能力,最終提高了對多尺度目標的檢測效果。實驗通過在本文建立的3 000張圖片的數(shù)據(jù)集上進行訓練的結果表示,本方法可以有效檢測自然場景下佩戴口罩的人臉和沒有佩戴口罩的人臉,平均精度均值達到87.7%,每秒幀率為18.3幀/s,另外在自然場景視頻檢測中也取得了不錯的效果,證明了本文算法框架的合理性。在未來的研究中,將進一步對網(wǎng)絡結構進行優(yōu)化,使用更多的數(shù)據(jù)集對網(wǎng)絡模型進行訓練,提高人臉口罩佩戴的檢測能力和檢測效率。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
