基于BiasSVD 和聚類用戶最近鄰的協同過濾算法研究
2020-06-15 12:04:38李佳張牧
現代計算機 2020年13期
李佳,張牧
(成都體育學院,成都 610041)
0 引言
隨著網絡科技的發達,信息泛濫的時代已經到來,一般的搜索引擎不能為用戶提供準確的搜索結果,而個性化推薦系統能夠主動學習與分析用戶的行為,自主對信息過濾,為用戶提供適合自己需求的推薦。個性化推薦系統的算法有多種,其中協同過濾算法是最成熟的[1],面對如今的大數據時代,協同過濾算法存在可擴展性問題。Sarwar 等人[2]將SVD 技術運用到協同過濾算法,得到低秩矩陣,降低矩陣復雜度。Rashid 等人[3]采用聚類技術為每個聚類生成代理用戶,與目標用戶相似度最高的代理用戶進行最近鄰的推薦,大大減小對最近鄰的搜索范圍。Karypis 等人[4]指出通過增加服務器數量,提高算法吞吐量。李改等人[5]在SVD 模型中進行正則化約束來訓練數據,用最小二乘法來訓練分解模型。
為了解決協同過濾算法的可擴展問題,本文提出基于BiasSVD 和聚類用戶最近鄰的協同過濾算法,首先選用的是BiasSVD 降維技術,該方法在原有的LFM模型上加入偏置項,使得BiasSVD 模型更加貼近現實和精細,該方法對擴展性的問題改善程度較為顯著,但是仍然會造成信息丟失以及存在一定的偏差,所以最終得到的目標用戶預測評分將通過聚類用戶最近鄰預測評分和真實評分的平均偏差值來調整,從而提高協同過濾算法的推薦質量。
1 相關工作
協同過濾算法為用戶產生推薦大概分為三個步驟,通過自主收集學習用戶行為信息,建立用戶項目評分矩陣Rm×n,接著計算用戶或者項目之間的相似度產生最近鄰集合,最后根據最近鄰產生預測評分或者商品推薦。
本文評分矩陣有m行n列,m代表用戶個數,n代表項目個數。其中,u、v表示用戶,i、j表示項目,rui為用戶u對項目i的評分。
1.1 BiasSVD
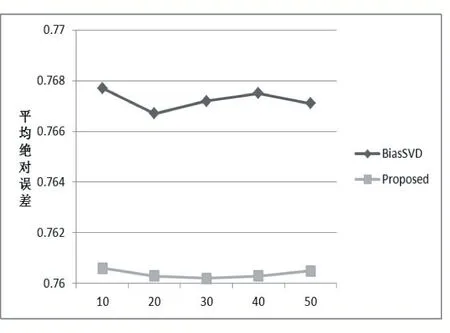
BiasSVD 又叫偏差矩陣分解[6],它是通過降維的方法把高維的項目評分矩陣Rm×n分解為兩個低維矩陣相乘,即Rm×n=Pm×fQf×n,其中f bui為用戶u對項目i的偏好評分,μ為數據訓練集中所有評分記錄的平均值,bu[u]表示用戶u評分偏差,bi[i]表示項目i的偏好。 例如預測用戶Grace 對《計算機導論》這本書的偏好評分,其中總體平均值為3 分。《計算機導論》的質量比大部分書籍都好,對它的評分比其他書籍平均分高于0.6 分。而且用戶Grace 評分是比較嚴謹的,偏向于給書籍打低0.2 分,所以用戶Grace 對《計算機導論》的偏好評分bui=3+0.6-0.2=3.4。從上述分析,利用偏差矩陣分解的評分預測公式如下: pui為用戶u對項目i的預測評分,p和q表示經過降維后的用戶特征矩陣以及項目特征矩陣。 基于BiasSVD 預測出來的評分加上偏置項,不僅降低數據復雜度,而且使得預測評分更接近真實評分,但是依然存在一定偏差,需要通過最近鄰用戶真實評分和預測評分的平均差值來調整目標用戶的預測評分。 聚類的方法有很多種,本文采用的是K-means 聚類方法。基于K-means 聚類協同過濾算法首先確定k個聚類中心,然后計算用戶與每個聚類中心之間的相似度,比較這些相似度的大小,用戶就和相似度最高的聚類中心是一個類別的,以此反復計算,直到所有用戶都已經聚類,最后為目標用戶尋找最近鄰,第一步是計算目標用戶和聚類中心的相似度,找到目標用戶所屬類別,第二步就是在該類別的集合中找到目標用戶的最近鄰,由此可以看出,最近鄰的搜索空間已經大大地減小。 在該聚類的集合中計算用戶之間的相似度,本文選取的用戶相似度公式是在皮爾遜系數基礎上作了一點改進。皮爾遜系數公式: 公式(3)中計算目標用戶u與用戶v相似度,ruv表示用戶u與v共同評分的項目集合。rui和rvi分別表示用戶u和v對項目i的評分,分別表示用戶u和v評分平均值。 公式⑷是改進的相似度公式,N(u)?N(v)表示用戶u和v共同評分個數,N(u)?N(v)表示用戶u和v評分項目數的并集。這在一定程度上懲罰共同評分項目數少的用戶相似度,提高相似度計算的準確性。 通過公式(4)計算目標用戶u和其他用戶v的相似度sim(u,v),相似度大小取值范圍為[-1,1],然后降序排列,選取前N 個作為目標用戶u的最近鄰集合。 本文提出的基于BiasSVD 和聚類用戶最近鄰的協同過濾算法的中心思想是通過公式(2)得到預測評分pui,然后采用公式(4)計算相似度獲取目標用戶u最近鄰集合user(u),最后結合最近鄰真實評分rvi與預測評分pvi之間差的平均差值evi來調整目標用戶的最終預測評分即公式如下: 其中 N 是集合 user(u)的元素個數,eui相當于是一個偏移量。當eui的值大于零時,表示實際上真實評分比預測評分高很多,所以增加偏移量eui到原來基準評分pui上;當eui值為零時,表示預測出來的評分已經很精確接近真實評分,不需要再調整;當eui值小于零時,真實評分比預測出的評分低很多,相應的在基準分pui上減去偏移量evi。所以最終預測評分公式如下: 為了得到最合適的用戶、項目特征矩陣p、q和用戶、項目偏好向量bu、bi,利用隨機梯度算法來優化,首先定義誤差公式由于防止過擬化加上規范化因子最終誤差公式如下: 公式(8)利用隨機梯度下降法得到的更新規則為: 算法2 基于BiasSVD 和用戶最近鄰的協同過濾算法 輸入:項目評分矩陣Rm×n,目標用戶u,項目i,用戶項目特征數f,迭代次數step,以及梯度下降步長γ,懲罰因子λ 輸出:用戶u對項目i的預測評分 步驟: (1)計算總體平均值μ (2)初始化bu、bi為全 0 (3)初始化p、q矩陣 (4)過隨機梯度下降法的迭代得到優化好的p、q矩陣和bu,bi向量 (5)對所有用戶進行K-means 聚類 (6)通過公式(5)計算evi的值 (7)找到目標用戶聚類的集合,基于該集合利用公式計算p'ui預測評分 為了驗證改進算法的準確性,首先應該選擇合適的數據集,本文采用的數據集是由美國Minnesota 大學的GroupLens 研究小組從MovieLens 網站提取而來[7]。該數據集有943 個用戶,1682 部電影,總共有100000條記錄,每個用戶至少要為20 部電影評分,分值范圍是1-5,分數高低表示用戶對電影的喜好程度。數據集分為訓練集和測試集,按80%和20%的比例來分。 評分預測的預測準確度一般用均方根誤差(RMSE)和平均絕對誤差(MAE)計算[8]。本文采用MAE 作為本實驗的評價標準,它是通過計算用戶實際項目的評分與相對應的預測評分之間的絕對偏差和的平均值表示預測準確度,其值越低,預測準確性則越高。公式如下: pi、qi分別表示用戶對項目i的預測評分和實際評分,N表示項目的個數。 平均推薦時間(MRT)反映了產生推薦項目的時間,其計算公式如下: Tis為用戶發出請求的時間,Tic用戶得到的推薦結果。 在本文實驗中,隨機梯度下降法的梯度下降率為0.99,迭代次數step=100,參數值γ=0.02,λ=0.3。 實驗1:不同特征向量維度下不同近鄰數的比較結果 圖1 特征矩陣維度f 與近鄰數量k 的關系 由圖1 觀察知道隨著特征矩陣維度f的增加,不同近鄰MAE 值的也在減小,并且隨著最近鄰數k的增加,預測精度也在逐漸提高。 實驗2:不同近鄰數k比較結果 從實驗1 得到特征矩陣維度f的取值影響著MAE 值的大小,本實驗中在f=30 基礎上,觀察不同最近鄰數的MAE 值大小,并且與基于用戶的協同過濾算法(UCF 算法)作比較。 圖2 改進算法與UCF算法MAE值比較結果 由圖2 可知在f=30 基礎上,隨著最近鄰數k的增加其MAE 值也在減小,預測準確度在提高。但是當k的值過大,導致算法復雜度增加,并且準確度也會降低。改進的算法MAE 值均小于基于用戶協同過濾算法MAE 值,說明改進算法提高了預測準確度與推薦質量。 實驗3:基于BiasSVD 與改進算法的比較結果 從實驗2 可知當最近鄰數取值適當時,改進算法的預測準確度比較高。本實驗在k=35 的基礎上,比較本文改進算法(Proposed)與基于BiasSVD 協同過濾算法的準確度。 圖3 改進算法與BiasSVD算法的MAE值比較 由圖3 觀察得到改進的算法的MAE 值比基于Bi?asSVD 協同過濾算法MAE 值都要小,說明改進的算法在一定程度上提高推薦算法的預測準確度,從而提高推薦系統的推薦質量。 實驗4:不同算法平均推薦時間比較 圖4 改進算法與UCF算法的平均推薦時間比較 由圖4 可知,本文改進算法的平均推薦時間都要少于基于用戶的協同過濾算法,所以改進算法大大縮減了推薦時間,在一定程度上提高了算法的擴展性。 本文針對協同過濾算法可擴展性問題,在偏置矩陣模型基礎上結合聚類用戶最近鄰實際評分與預測評分之間的平均偏差來調整目標用戶的預測評分,從而不僅減低數據的復雜度,并且提高了評分預測的準確性,以及可擴展性。

1.2 聚類用戶最近鄰
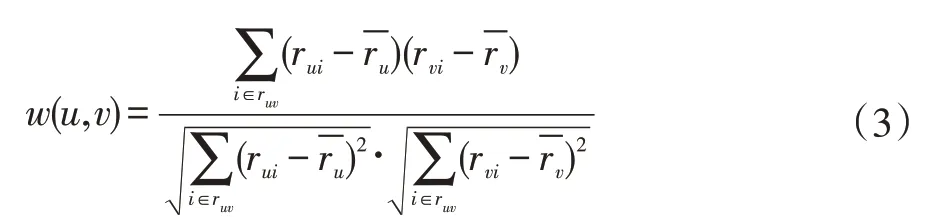

2 基于BiasSVD和聚類用戶最近鄰的協同過濾算法

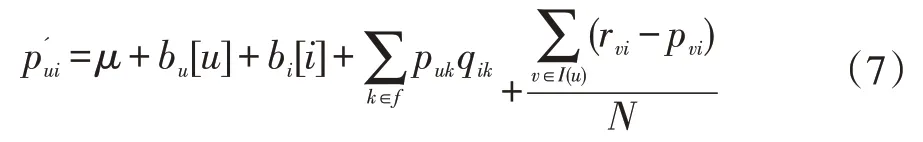

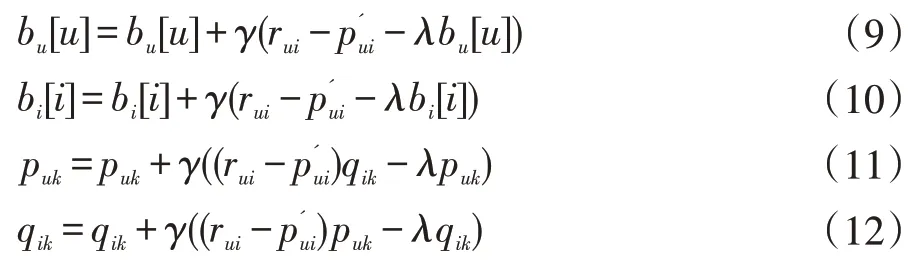
3 實驗結果及分析
3.1 實驗數據集
3.2 評價標準


3.3 實驗結果及分析



4 結語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
