金融領域機器閱讀理解模型
2020-06-15 12:04:36黃敏珍
現代計算機 2020年13期
黃敏珍
(廣東工業大學,廣州 510006)
0 引言
在人的日常生活中,幾乎每個人都離不開金融。提到金融很多人會想到股票、基金、證券等,感覺這些離我們生活很遙遠,其實不然,人們常用的銀行、車貸、房貸、養老保險、市場物價等都離不開金融,它其實是市場的映射,與我們生活息息相關。對于機器閱讀理解的數據集有很多,但用在金融領域的數據集不多,常用的機器閱讀理解數據集有SQUAD[1]、SearchQA[2]、MS MARCO[3]、Dureader[4]。SQUAD 是文章段落類型數據集,問題和答案都是人工生成的,答案是文章中的一段,但部分答案未必在文章中出現;SearchQA 的問題和文章爬蟲而得,答案是由程序而得,通常是一到兩個詞;MS MARCO 數據集相比前兩者差異較大,問題和文章是搜索引擎收集的,答案是人工生成得;Dureader 是2017 年由百度團隊發布規模最大的中文機器閱讀理解數據集,其數據來源是百度搜索和百度知道,數據結構是一個問題對應多篇文章,且一個問題只含一個標準答案。而近年來抽取式的機器閱讀理解模型成為主流,其主要代表模型有Seo 等人于2016 年提出的雙向注意力流(Bidirectional Attention Flow,BiDAF)[5],Wang等人于2016 提出的一種結合M-LSTM 和PointerNet的模型Match-LSTM[6],Yu 等人于2018 年提出一種編碼器僅由卷積和self-attention 組成的QANet 模型[7]。
本文在Match-LSTM 基礎上提出一種多重注意力機制的端到端的抽取式機器閱讀理解模型。首先對數據重構,增強問題與文章的關聯,再對融合后的文檔作自注意力機制(self-attention)加深問題與文章的關聯,突出文章中與問題關聯較深的特征,然后聯合多篇文章再作self-attention 突出文章語義特征與文章間的關聯性,我把這種聯合了多篇文章的注意力機制稱為mul-attention。整個模型在相同數據集下與BiDAF、Match-LSTM、QANet 作對比,并分析了本文模型對問題類型的影響。
1 相關工作
1.1 Match-LSTM
Match-LSTM 是一種結合 M-LSTM 和 PointerNet的模型(Machine Comprehension Using Match-LSTM and Answer Pointer,Match-LSTM)。它主要在匹配層采用M-LSTM,計算文章中每個詞關于問題的注意力分布向量,再將注意力分布向量與問題編碼向量作點乘,計算文章中每個詞對問題的關聯,最后用同樣的方法倒序再運行一遍,結合這兩次運算得到文章向量的新表示形式。然后作答層采用PointerNet,即該文在答案預測上提出了兩種模式,第一種是認為答案不是連續的,答案可從文章各處零碎拼接而成,第二種是認為答案是連續的,只需預測答案在文章中的始末位置就可預測出答案,該文實驗證明答案預測始末位置相比從文章各處拼接效率和準確率更高,但這種方法對于長度較長的答案預測效果有待提高。整個Match-LSTM更適合實體類問題的解答。
1.2 self-attention
self-attention 即自注意力機制,是由注意力機制[8]演變而來,模擬人類大腦的關注能力,把特征關鍵點放大增強。self-attention 自身既是觀察者也是被觀察者,被觀察者被看做是固定的序列,觀察者中的每一個元素與被觀察者作點積,再將每個元素求得的值加權求和,得到一個兩者間的注意力分布,這個分布在原始的attention 中看作兩者間的相似度,對于self-attention 就相當于自身特征的增強。在自然語言處理的領域中,self-attention 首先是由 Bahdanau 等人[9]于 2014 年提出用于機器翻譯上,后來發現在自然語言處理的其他領域也有不錯的效果,漸漸地被應用到機器閱讀理解上,許多實驗[10-12]都發現它在機器閱讀理解有增強文章的語義,使其附帶上下文的語義信息的作用。
2 數據
本模型的數據從百度搜索和百度知道而得,包含經濟、股票、匯兌、價格、儲蓄、貸款等多方面的信息統稱為金融領域。一共有1 萬個問題,每個問題對應一個標準答案,5 篇文章,文章一般是篇幅較大得解答,答案選自一個精確簡短的解答,答案未必一字不漏的出現在文章中,但文章中部分片段包含與答案相似的含義,其中把6000 個問題用于訓練,2000 個用于測試,2000 個用于驗證。在訓練集中有2010 個描述類問題,3244 個實體類問題,746 個是非類問題,其中訓練集中有1604 個事實類問題,4396 觀點類問題,具體數據類型分布如圖1。
3 模型
模型主要分成4 個模塊:數據重構模塊、融合后文章self-attention 模塊、多篇文章mul-attention 模塊、作答模塊。其中作答模塊與Match-LSTM 相同。
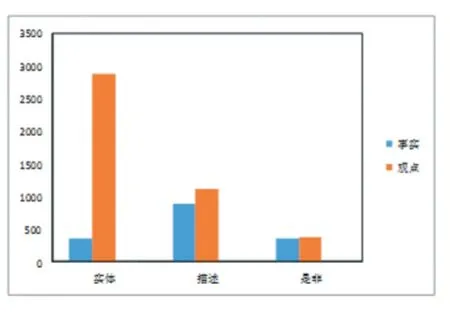
圖1 數據類型分布
3.1 數據重構模塊
由于網上的文章參差不齊,數據量繁多,因此需要在有限的長度內截取有用的信息,本模塊根據文章與問題或者答案的相關性做排序提取有用信息。數據采用jieba 分詞,用Word2Vec[13]從1.3G 的中文維基百科語料訓練獲取文字的詞向量,詞向量的維度m 為150。其中多個問題記為 Q={q1,q2,…,qn},n 為問題個數,多個答案記為A={a1,a2,…,an},問題q1對應的文章記為P1={p1,p2,p3,p4,p5}。文章p1對應的句子記為為p1 的句子總數。在訓練時,根據式(1)算出文章p中的句子s 與答案a 的相關度并根據相關度從大到小的順序對文章重新排列。測試和預測時,根據式(2)算出文章p 中的句子s 與問題q 的相關度并根據相關度從大到小的順序對文章重新排列。以上排序后均只截取文章前max_p 個詞,問題只截取前max_q 個詞,答案只截取前max_a 個詞。重構的數據作為下一層的輸入。
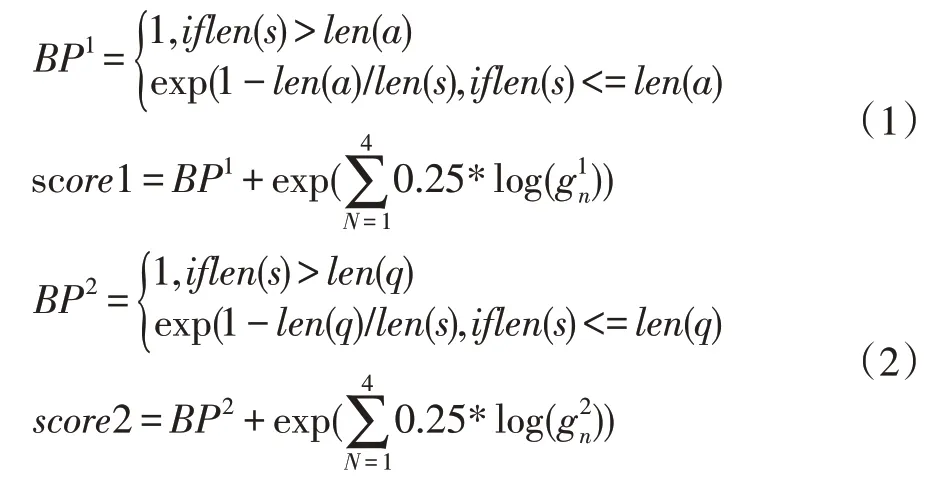
3.2 融合后文章self-attention模塊
匹配模塊分為兩個部分:Match-LSTM 匹配融合和self-attention。
(1)Match-LSTM 匹配融合
這一部分實質是讓文章攜帶問題信息,把問題看作前提,文章為假設。首先用單向LSTM 編碼問題和文章,如式(3):

再計算文章上問題的注意力分布,并softmax 歸一化,式(4):
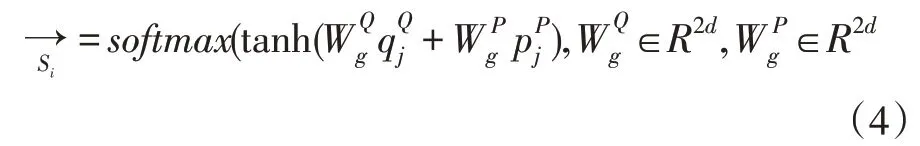

(2)self-attention
在融合的前提作self-attention 加深問題與文章的關聯,突出文章中與問題關聯較深的特征,融合后的文章看作兩個序列,一個看作一個固定的key-value 序列,另一個看作有移動序列,移動序列中的每一個詞都會遍歷一次key-value。由上一部分得到融合后文章,首先將固定序列每一個key 與移動序列每個元素作點積,計算融合后文章本身的注意力分布,然后用Soft?max 歸一化,如式(6),最后加權、拼接,如式(7),得 PS=
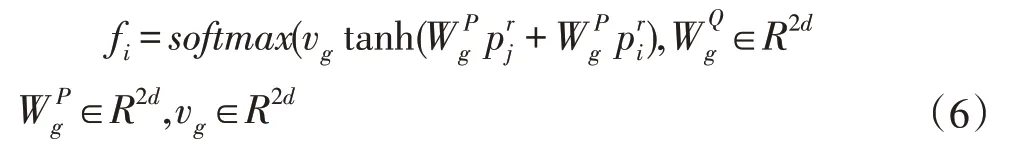
其中d 為隱藏層維數。
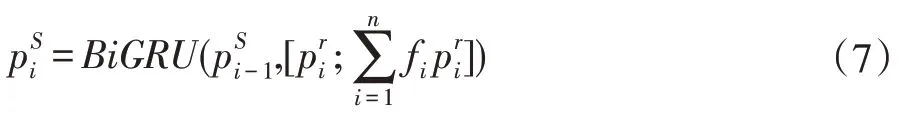
3.3 mul-attention模塊
這一模塊把同一個問題對應的所有文章拼接在一起看作一個整體,對這個整體作self-attention,由4.2模塊得第i 個問題self-attention 后的文章為內含5 篇文章,即則一個問題對應的文章這個整體表示為其根據式(8-9)作自注意力機制。
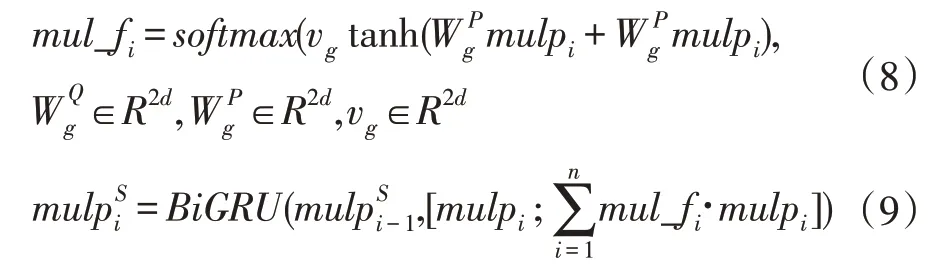
4 實驗
4.1 實驗設置
本實驗從百度搜索和百度知道獲取的金融類型數據,一共1 萬條數據,6000 條用于訓練,2000 條用于測試,2000 條用于驗證,一條數據包含一個問題、一個標準答案、5 篇文章,詞向量維度為150。文章截取的最大長度max_p 為400,問題截取的最大長度max_q 為60,batch 的大小為16,答案截取的最大長度max_a 為200,隱藏層的維度d 為64,實驗的迭代次數epoch 為10 次,模型構建采用 TensorFlow1.2.0,Python3.5,采用Adam 優化模型參數,學習率為0.0001。實驗運行硬件條件為E5-2660 10 核、16G 內存。訓練時間為7 小時17 分鐘。
4.2 實驗結果
本次實驗評價指標為Rouge-L 和BLEU-4,首先以 BiDAF、Match-LSTM、QANet 為對比模型,對比在相同數據集下模型的性能,如表1 所示,Match-LSTM 與BiDAF 性能相近,QANet 與其他模型差距較大,本實驗模型相比其他模型Rouge-L 至少提升2.72,BLEU-4至少提升了7.08。
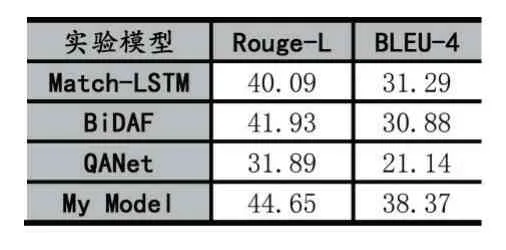
表1 不同模型驗證結果
接著以Match-LSTM 為基線,增量式對比數據重構、融合后文章self-attention、mul-attention 對整個模型的影響,實驗結果如表2 所示。由表所示數據重構后整體性能漲幅明顯Rouge-L 提升了4.2,BLEU-4 提升了5.52。融合后文章self-attention 與mul-attention對模型的提升接近,前者Rouge-L 和BLEU-4 分別提升了 0.26、0.94,后者 Rouge-L 和 BLEU-4 分別提升了0.1、0.62。
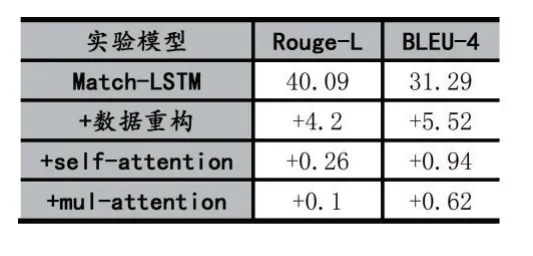
表2 增量式驗證結果
最后從問題類型的角度觀察模型,統計在本文數據集中實體類型、描述類型、是非類型問題在本文模型的效果,然后以Match-LSTM 為基線,針對問題類型增量式對比數據重構、融合后文章self-attention、mul-at?tention 對整個模型的影響,實驗結果如表3 所示。其中數據重構對每一類問題都有一定程度實驗效果的提升,self-attention 對是非類問題類型提升效果更高,mul-attention 對實體類問題類型實驗效果提升更高。綜合而言整個模型對實體類和描述類問題類型實驗效果的提升接近,對是非類問題類型的提升相對較小。
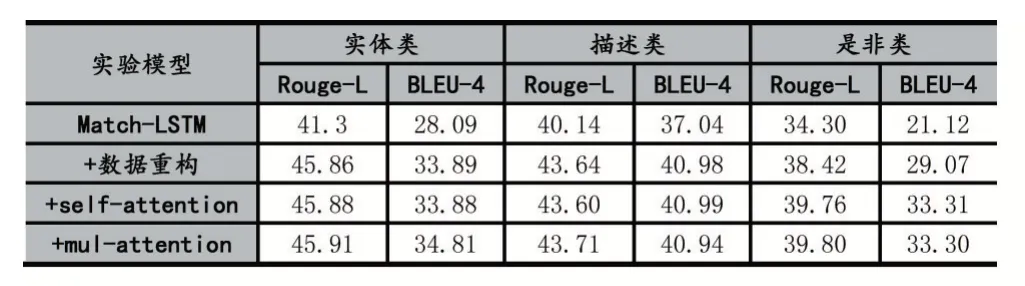
表3 不同問題類型下增量式驗證結果
5 結語
本文在Match-LSTM 基礎上提出一種多重注意力機制的端到端的抽取式機器閱讀理解模型。首先提出了一種數據重構的方法,使得重構后的文章對問題更具有關聯性,大幅度的提高模型的訓練效果,然后對融合后的文檔作自注意力機制(self-attention)加深問題與文章的關聯,突出文章中與問題關聯較深的特征,最后聯合多篇文章再作self-attention 突出文章語義特征與文章間的關聯性。最終驗證結果達到Rouge-L 和BLEU-4 分別為44.65、38.37。其次本文還針對問題類型對本模型作出數據分析,實驗表明模型對每一個問題類型實驗效果都有提升,實體類和描述類問題的提升相對較高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
