基于雙用戶視角與知識圖譜注意力網(wǎng)絡(luò)的推薦模型
2020-06-15 12:04:32張素琪許馨勻佘士耀任珂可
現(xiàn)代計算機(jī) 2020年13期
張素琪,許馨勻,佘士耀,任珂可
(1.天津商業(yè)大學(xué)信息工程學(xué)院,天津300134;2.河北工業(yè)大學(xué)人工智能與數(shù)據(jù)科學(xué)學(xué)院,天津300401)
0 引言
互聯(lián)網(wǎng)為我們帶來了更為便捷和娛樂的生活,但隨著信息量的快速增長,用戶在線瀏覽信息時會出現(xiàn)難以抉擇閱讀項目的情況,這時推薦模型應(yīng)運(yùn)而生。推薦模型可為用戶推薦潛在的興趣項目,帶給用戶更好的體驗,同時可為運(yùn)營商帶來巨大的商業(yè)效益,應(yīng)用甚廣。
傳統(tǒng)的推薦模型主要基于協(xié)同過濾[1]的方法,但該類方法會面臨數(shù)據(jù)稀疏以及冷啟動的問題。為緩解上述問題,研究者們引入了各種附加信息,如社交網(wǎng)絡(luò)[2,3]、知識圖譜(KG)[4,5]、用戶評論[6,7]等。其中,知識圖譜是一種異構(gòu)信息網(wǎng)絡(luò),其節(jié)點(diǎn)表示實(shí)體,邊表示實(shí)體間的關(guān)系。這種結(jié)構(gòu)化知識為提高推薦模型的準(zhǔn)確性和可解釋性提供了一個有價值的解決方案。
基于知識圖譜的推薦方法大致分為三種:基于路徑的方法[8-10]、基于嵌入的方法[11-13]和兩者混合的方法[14-16]。石川等[7]將知識圖譜視為一種加權(quán)的異構(gòu)信息網(wǎng)絡(luò),設(shè)計了多條meta-path 并在PathSim 的基礎(chǔ)上融入邊信息,獲得基于元路徑的用戶相似度。趙歡等人[8]改進(jìn)了傳統(tǒng)的meta-path,引入元圖(meta-graph)的概念。基于路徑的方法將知識圖譜以meta-path 等方式融入推薦中,體現(xiàn)了推薦的可解釋性,但meta-path 的設(shè)計依賴于人工設(shè)定。基于嵌入的方法則需要利用KGE 等算法[17,18]得到知識圖譜表示向量。DKN[11]提取新聞標(biāo)題的背景知識來構(gòu)建知識圖譜,采用TranR[17]方法實(shí)現(xiàn)知識圖譜的嵌入,然后將詞表示向量與知識圖譜的實(shí)體向量作為卷積網(wǎng)絡(luò)的輸入以提取新聞特征。該方法隱式地指引用戶和項目的表示學(xué)習(xí),缺乏推理能力。近來,利用圖神經(jīng)網(wǎng)絡(luò)[19-21]表示知識圖譜的方法得到了學(xué)界的關(guān)注。該方法對網(wǎng)絡(luò)中的各個實(shí)體進(jìn)行向量表示,再通過注意力機(jī)制等方法自動挖掘用戶興趣路徑,因此可看為基于路徑和嵌入的方法的混合。RippleNet[14]以已交互的項目為中心構(gòu)建知識圖譜,興趣在知識圖譜上逐層向外擴(kuò)散且逐層衰減。KGCN[15]利用了圖注意力網(wǎng)絡(luò)(GAT)自動捕獲高階結(jié)構(gòu)和語義信息。該方法使得推薦具有較好的可解釋性,并且不依賴人工設(shè)計的特征。目前,該類方法仍處于發(fā)展階段,如何將知識圖譜融入推薦模型中以更好地實(shí)現(xiàn)用戶和項目的表示還有待解決。
本文提出了基于雙用戶視角與知識圖譜注意力網(wǎng)絡(luò)(Dual-User Perspective and Knowledge Graph Atten?tion Network,DKGAT)的推薦模型。為了更好地挖掘用戶特征,DKGAT 從雙視角分析用戶行為,并分別進(jìn)行用戶表示。首先,用戶興趣為用戶本身特性的傳達(dá),是靜態(tài)且不輕易受外界影響的,因此從該角度分析用戶行為是靜態(tài)用戶視角。其次,用戶若對某個項目感興趣則會產(chǎn)生交互行為,即用戶交互的歷史項目體現(xiàn)了個人興趣,是興趣的外在展現(xiàn),因此可稱之為動態(tài)用戶視角。在項目特征的表示方面,為準(zhǔn)確的捕獲特定用戶興趣,需要在知識圖譜中同時捕獲低階與高階項目屬性,并自動挖掘用戶興趣路徑。為此,DKGAT 基于用戶的本質(zhì)喜好即靜態(tài)用戶表示,利用注意力機(jī)制在知識圖譜中關(guān)注用戶感興趣的項目屬性,并通過鄰域聚合的方法得到項目表示。最后,通過注意力機(jī)制計算用戶的歷史交互項目和待推薦項目之間的相似性,即可獲取基于待推薦項目的動態(tài)用戶表示。兩種用戶表示不僅可反應(yīng)用戶的本質(zhì)特性,還可挖掘出用戶與待推薦項目相關(guān)的興趣。
1 建立模型
1.1 任務(wù)定義
推薦模型中存在M 個用戶和N 個項目,分別記為U={u1,u2,…,uM}和V={v1,v2,…,vN}。依據(jù)用戶對項目的隱式反饋定義用戶-項目交互矩陣Y∈RM×N,其中yuv=1 表示用戶u 瀏覽過項目v,否則yuv= 0。知識圖譜G可用三元組(h,r,t)表示,其中h∈E、r∈R、t∈E分別表示頭、關(guān)系、尾,E和R分別為知識圖譜中的實(shí)體集合和關(guān)系集合。例如,三元組(A Song of Ice and Fire, book.author, George Martin)表示“A Song of Ice and Fire”的作者是George Martin。在推薦模型中,可以將項目v∈V看為一個實(shí)體,如在上面的例子中,“A Song of Ice and Fire”既可以看為實(shí)體也可以看為項目。
給定用戶-項目交互矩陣Y、各個項目的知識圖譜G,推薦任務(wù)旨在預(yù)測用戶u 是否對項目v 有興趣。最終期望得到預(yù)測函數(shù)y?uv=F(u,v|Θ,Y,G),其中y?uv表示用戶u 對項目v 的交互概率,Θ 則表示模型參數(shù)。
1.2 模型概述
模型以用戶u 和項目v 為輸入,通過知識圖譜獲取用戶和項目表示,最終輸出u 與v 的交互概率。
圖1 為模型結(jié)構(gòu)。項目表示反應(yīng)項目特征,首先需要構(gòu)建以項目為中心的知識圖譜,再利用知識圖譜注意力網(wǎng)絡(luò)(KGAT)對知識圖譜進(jìn)行表示,即可得到項目表示向量v。用戶表示則由兩部分組成,分別來自于靜態(tài)用戶視角和動態(tài)用戶視角。用戶的靜態(tài)視角反應(yīng)用戶自身的固有喜好,是用戶本質(zhì)的表達(dá);動態(tài)視角則從用戶交互的歷史項目中挖掘的喜好信息。靜態(tài)用戶表示us用在KGAT 中,挖掘用戶關(guān)注的重要項目特征,以獲取基于特定用戶的項目表示。動態(tài)用戶表示ud則反應(yīng)了用戶的交互歷史,若待推薦項目與已交互項目之間有較高的相似度,則推薦的概率也會較高。為獲取動態(tài)用戶表示ud,可分別對每個已交互項目構(gòu)建知識圖譜,通過KGAT 獲取每個項目的表示向量,然后利用注意力機(jī)制獲取各已交互項目與待推薦項目的相似性權(quán)重,基于此權(quán)重對已交互項目加權(quán)求和,即可獲得ud。這樣的動態(tài)用戶向量不僅反映了用戶的交互歷史,也反映了用戶的歷史興趣與待推薦項目的相似度。將ud和us做聚合,以獲得最終的用戶表示u。最后通過內(nèi)積等方法計算用戶表示和項目表示的相關(guān)性,即可獲取推薦評分。
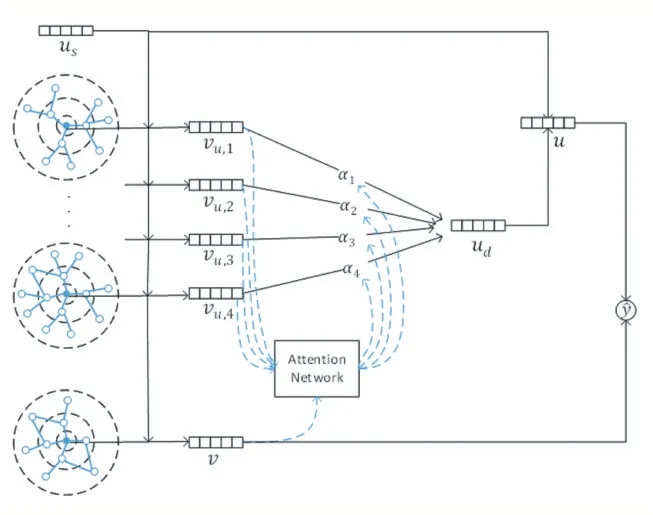
圖1 DKGAT模型結(jié)構(gòu)
圖中以用戶有四個交互項目為例,左側(cè)省略號表示省略的交互項目的知識圖譜。
1.3 知識圖譜注意力網(wǎng)絡(luò)
知識圖譜注意力網(wǎng)絡(luò)(KGAT)為應(yīng)用在知識圖譜上的圖注意力網(wǎng)絡(luò),可用來捕獲知識圖譜中的拓?fù)浣Y(jié)構(gòu)信息以及實(shí)體信息。圖2 為KGAT 模型。每一個項目都可構(gòu)成一個知識圖譜G,然后通過KGAT 模型,獲取圖譜特征并表示為向量。該模型是多層結(jié)構(gòu),低層時可獲取低階實(shí)體特征,高層時又可挖掘高階實(shí)體信息。下面主要介紹一層KGAT 模型,最后再對多層結(jié)構(gòu)做推廣。

其中,us∈Rd和ri,j∈Rd分別為用戶的靜態(tài)表示和關(guān)系表示,d 為向量維度。事實(shí)上,表示關(guān)系r對用戶喜好的影響程度。例如某些用戶會喜歡同類型的項目,因此當(dāng)關(guān)系r 為項目類型時需要給予較高的關(guān)注。
為了獲取項目v 的近鄰特征,可計算與項目v 直接連接的節(jié)點(diǎn)又稱鄰域的線性組合:

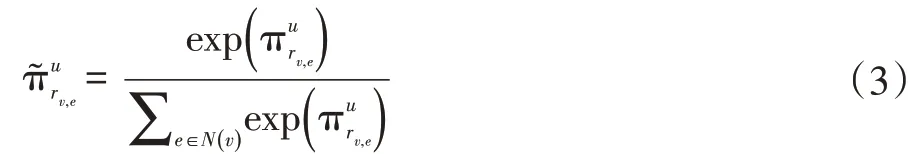
其中,e0∈Rd為初始的實(shí)體表示。當(dāng)計算項目鄰域的表示時,歸一化的用戶-關(guān)系評分可作為用戶喜好權(quán)重,以基于用戶喜好權(quán)重對項目的鄰域加權(quán)求和。
在真實(shí)的知識圖譜中,對不同的實(shí)體e,其鄰域N(e)的數(shù)量可能存在顯著差異。為了保持每個批處理的計算模式固定且有效,需要為每個實(shí)體抽取一個固定數(shù)量的鄰域集作為樣本。抽取后實(shí)體v 的鄰域表示可記為其中為約束數(shù)量。
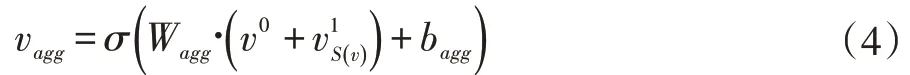
其中,Wagg∈Rd×2d和bagg∈Rd為權(quán)重和偏置;σ為非線性函數(shù)。
通過一層的KGCN,實(shí)體的表示則僅依賴于自身及其鄰域,可稱vagg為項目v 的1 階表示,又記為v1。若將KGCN 從一層擴(kuò)展到多層,則間接相連的實(shí)體也會影響到項目的最終表示。為更深入以及合理地探索用戶的潛在興趣,挖掘?qū)嶓w的高階特征是很有必要的。將每個實(shí)體的初始表示即0 階表示與其鄰域?qū)嶓w的0 階表示聚合,則可獲得1 階實(shí)體表示,然后可以重復(fù)上述過程,即進(jìn)一步聚合1 階表示,以獲得2 階表示。一般來說,一個實(shí)體的L 階表示是它自己與其L跳范圍內(nèi)的實(shí)體的聚合。可將該項目的L 階表示vL看為最終的項目表示v。
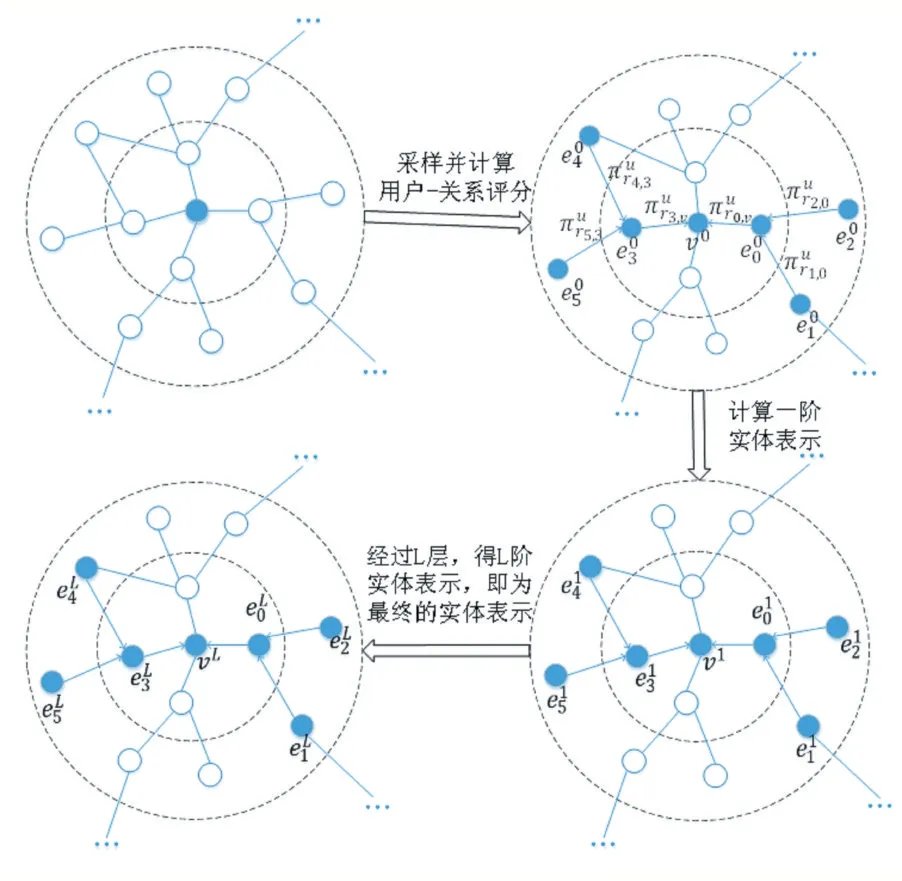
圖2 KGAT模型
首幅圖為以項目為中心構(gòu)建的知識圖譜,省略號表示剩余的圖譜結(jié)構(gòu)。對首幅圖中實(shí)體實(shí)現(xiàn)個數(shù)為2的采樣,并計算用戶-關(guān)系評分即可獲得第二幅圖,圖中表示用戶-關(guān)系評分,表示初始的實(shí)體表示。通過公式(2),即可獲得第三幅圖中的實(shí)體一階表示將上述操作重復(fù)L 層,即可獲得實(shí)體的L 階表示,也為最終的實(shí)體表示。
1.4 動態(tài)用戶表示
考慮到若用戶的交互歷史中,存在較多與待推薦項目相似的項目,則可認(rèn)為該用戶對待推薦項目感興趣的可能性大。為此,在模型中引入注意力機(jī)制,以更多的關(guān)注相似項目。
通過KGAT 模型,可得項目的表示向量。通過注意力機(jī)制,計算各個已交互項目與待推薦項目之間的相似性權(quán)重,按此權(quán)重對各個交互歷史表示進(jìn)行加權(quán)求和,即可獲得用戶的動態(tài)喜好表示。具體為,以待推薦項目表示v∈Rd為基準(zhǔn),為用戶u 交互歷史中的各個項目向量分配權(quán)重并加權(quán)平均,獲取一個相對于基準(zhǔn)的用戶動態(tài)喜好表示:

其中αi為注意力系數(shù),其計算方法為:
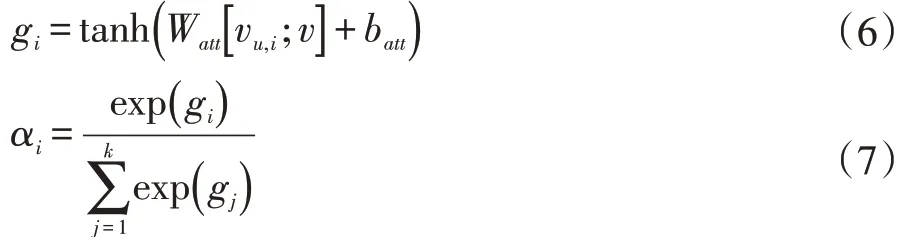
其中,Watt∈R1×2d,batt∈R1×1為注意力機(jī)制的權(quán)重和偏置。
1.5 輸出層與模型訓(xùn)練
將用戶的靜態(tài)喜好表示us∈Rd與動態(tài)喜好表示ud∈Rd進(jìn)行拼接,再通過一個線性變換,即可完整地全面地獲得用戶喜好,記為u∈Rd:

其中,Wu∈Rd×2d和bu∈Rd為權(quán)重和偏置。
最后,將用戶表示u和項目表示v通過向量的內(nèi)積獲得用戶u 選擇交互項目v 的概率:

2 實(shí)驗
將提出的KGAT 模型應(yīng)用到三個不同領(lǐng)域的數(shù)據(jù)集上,并通過實(shí)驗結(jié)果分析,驗證模型的有效性。
2.1 數(shù)據(jù)集
本文分別選用來自于電影領(lǐng)域、圖書領(lǐng)域以及音樂領(lǐng)域的三個基準(zhǔn)數(shù)據(jù)集進(jìn)行實(shí)驗,且三者的數(shù)據(jù)量相差較大。MovieLens①https://grouplens.org/datasets/movielens/的數(shù)據(jù)來自于MovieLens 網(wǎng)站,評分范圍為1 到5;Book②http://www2.informatik.uni-freiburg.de/~cziegler/BX/的數(shù)據(jù)來自Book-Crossings 社區(qū),評分范圍為0 到10;Music③https://searchengineland.com/library/bing/bing-satori的數(shù)據(jù)來自于Last.FM 在線音樂系統(tǒng)。數(shù)據(jù)集的具體統(tǒng)計結(jié)果見表1。
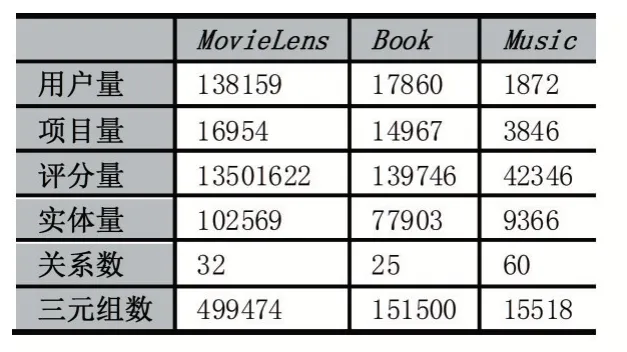
表1 數(shù)據(jù)集統(tǒng)計
實(shí)驗中將每一個數(shù)據(jù)集隨機(jī)劃分為訓(xùn)練集、驗證集和測試集,三者的比例為6:2:2。本實(shí)驗為點(diǎn)擊率預(yù)測,即判斷用戶是否會對待推薦項目感興趣,實(shí)驗采用AUC 和準(zhǔn)確率(ACC)作為評價指標(biāo)。
為實(shí)現(xiàn)點(diǎn)擊率預(yù)測,需將數(shù)據(jù)集中的顯示評分轉(zhuǎn)換為隱式評分,即用戶對該項目感興趣則隱式評分為1,用戶對該項目不感興趣則為0。在上述三個數(shù)據(jù)集中,可通過為用戶評分設(shè)定閾值的方法將其轉(zhuǎn)換為隱式評分。具體為,在MovieLens 中對大于等于4 的用戶評分設(shè)定其隱式評分為1,其他為0;由于其他兩個數(shù)據(jù)集的數(shù)據(jù)較為稀疏,因此不為其設(shè)定閾值,只要存在用戶評分就隱式評分為1,否則為0。最后,本文使用了文獻(xiàn)[15]構(gòu)建的知識圖譜。
2.2 實(shí)驗設(shè)置
實(shí)驗中參數(shù)的設(shè)置可見表2。其中H 表示知識圖譜中鄰居節(jié)點(diǎn)的采樣個數(shù),d 表示向量維度,L 代表知識圖譜的迭代層數(shù),K 為交互項目采樣個數(shù),λ為正則化權(quán)重,lr 為學(xué)習(xí)率,batch 為批處理大小。
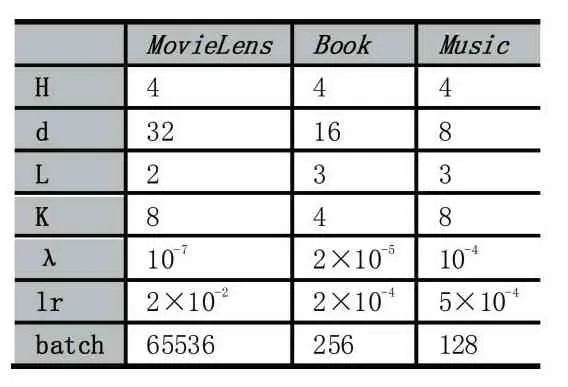
表2 實(shí)驗參數(shù)設(shè)置
2.3 對比實(shí)驗
將本文提出的推薦模型與下面的六種方法在相同的三組數(shù)據(jù)集上進(jìn)行實(shí)驗結(jié)果比較:
(1)PER[10]將知識圖譜視為異構(gòu)信息網(wǎng)絡(luò),基于元路徑表示用戶興趣路徑,然后在全局和個性化級別定義推薦模型。
(2)CKE[12]利用 TransE[18]表示知識圖譜,并將該類信息與文本以及圖像信息融入到模型中以共同學(xué)習(xí)用戶和項目表示。
(3)LibFM[22]將基于特征的因子分解機(jī)的方法應(yīng)用在點(diǎn)擊率預(yù)測任務(wù)上。
(4)Wide&Deep[23]是將傳統(tǒng)的線性模型和深度模型相結(jié)合的通用深度推薦模型。
(5)RippleNet[14]采用了一種類似于內(nèi)存網(wǎng)絡(luò)的方法,該模型在知識圖譜中傳播用戶的喜好以供推薦。
(6)KGCN[15]通過圖卷積網(wǎng)絡(luò)挖掘項目在知識圖譜上的重要屬性以有效地捕獲項目間的相關(guān)性。
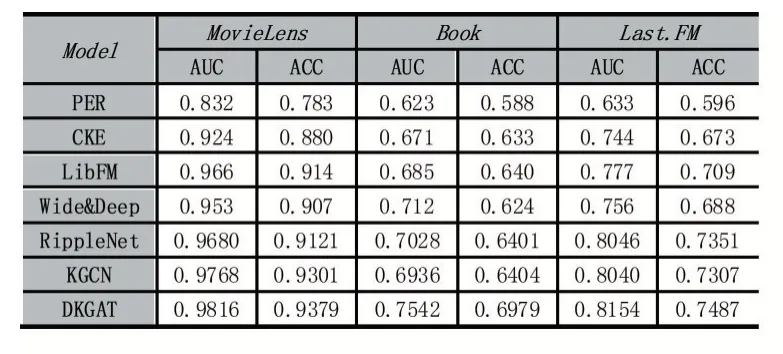
表3 實(shí)驗結(jié)果
2.4 實(shí)驗結(jié)果
實(shí)驗的具體結(jié)果顯示在表3 中,可以看到,本文的實(shí)驗結(jié)果普遍優(yōu)于基準(zhǔn)實(shí)驗。相較于最好的對比實(shí)驗結(jié)果,DKGAT 的AUC 性能在三個數(shù)據(jù)集上分別有0.5%、6%、1%的提升,ACC 指標(biāo)在三個數(shù)據(jù)集上分別有0.8%、5.7%、1.8%的提升。
RER 的實(shí)驗結(jié)果不理想,是因為該方法需要在meat-path 的基礎(chǔ)上尋找用戶和項目的關(guān)系,但meatpath 的設(shè)計依賴于專家知識,很難找到最佳方案。CKE 的實(shí)驗結(jié)果較差,一方面是因為實(shí)驗沒有利用圖像和文本信息,另一方面說明利用TransE 等方法預(yù)訓(xùn)練得實(shí)體表示的方法不能很好地利用知識圖譜的信息。LibFM 和Wide&Deep 較上面的兩個實(shí)驗而言結(jié)果較好,說明相較與上述兩類結(jié)合知識圖譜的方法,該類方法可更有效的利用知識信息。
相較于上述四種方法,RippleNet 和KGCN 表現(xiàn)除了較為強(qiáng)悍的性能。RippleNet 利用用戶的交互歷史構(gòu)建可表示用戶的知識圖譜,然后計算圖譜中的實(shí)體與待推薦項目之間的相關(guān)性,并在知識圖譜中逐層的向外擴(kuò)展,挖掘圖中的重要特征。相較于DKGAT,兩者都利用了用戶的交互歷史以獲取用戶表示,但是RippleNet 沒有考慮待推薦項目的圖譜信息,導(dǎo)致特征缺失。而DKGAT 實(shí)驗結(jié)果較好,說明對待推薦項目構(gòu)建知識圖譜,可更為精確的挖掘項目特征,實(shí)現(xiàn)項目表示。KGCN 則考慮到構(gòu)建項目知識圖譜,利用圖神經(jīng)網(wǎng)絡(luò)的方法表示項目。但是KGCN 沒有有效的利用用戶的交互歷史信息,只是將用戶向量用在GCN 中挖掘項目中的重要特征。DKGAT 相較于KGCN 可有效利用用戶的歷史信息,計算已交互項目與待預(yù)測項目之間的相似度,因此可基于待預(yù)測項目實(shí)現(xiàn)動態(tài)的用戶表示。實(shí)驗結(jié)果則證明了相較于KGCN,DKGAT 可有效利用用戶信息。
2.5 參數(shù)的敏感性
為了探究實(shí)驗參數(shù)的結(jié)果的影響,在DKGAT 上分別進(jìn)行了如下三組實(shí)驗。
(1)迭代層數(shù)的影響
知識圖譜以中心節(jié)點(diǎn)為基準(zhǔn)向外擴(kuò)展,因此可探索迭代層數(shù)對實(shí)驗性能的影響。實(shí)驗結(jié)果如圖4所示。
可觀察到,當(dāng)模型迭代3 層時可獲得最佳性能。實(shí)驗結(jié)果表明,當(dāng)擴(kuò)展層數(shù)較小時性能較差,說明層數(shù)較少時利用的特征不夠,不能有效地挖掘長距離的用戶興趣路徑。同時擴(kuò)展層數(shù)較高并不能提高性能,這是因為模型參數(shù)增加使得模型不容易泛化,并且隨著知識圖譜的擴(kuò)張,更多無關(guān)項目特征被考慮進(jìn)來,對興趣的挖掘有阻礙作用。
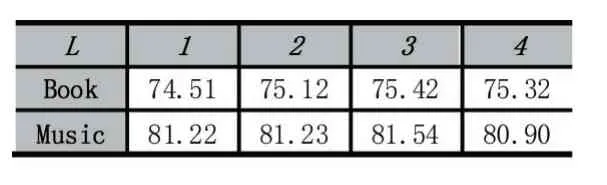
表4 不同迭代層數(shù)時DKGAT 的AUC 值
(2)鄰居節(jié)點(diǎn)采樣個數(shù)的影響
KGAT 通過鄰居節(jié)點(diǎn)的聚合實(shí)現(xiàn)了知識圖譜的向量表示,鄰居節(jié)點(diǎn)的采樣數(shù)則反映了同一迭代層中選取的特征量。因此,可改變?nèi)硬蓸拥泥従庸?jié)點(diǎn)數(shù)量H 的大小來探究其對實(shí)驗結(jié)果的影響。
從表5 中可以看出,當(dāng)H=4 時性能最好。這是因為太小的H 沒有容納足夠的鄰域信息,不能充分地體現(xiàn)項目特征。而太大的H 則會引入更多的無關(guān)特征。
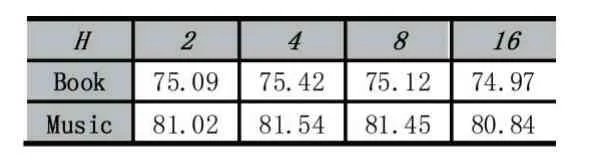
表5 不同鄰居節(jié)點(diǎn)采樣個數(shù)時DKGAT 的AUC 值
(3)交互項目采樣個數(shù)的影響
在計算動態(tài)用戶向量中需對用戶的交互歷史進(jìn)行采樣,這是因為用戶交互的歷史項目較多,全部利用則會造成計算量過大等問題。
從表6 中可以看出,當(dāng)K 較小時性能較差。用戶的交互項目是用戶喜好的外在反應(yīng),若這部分信息利用不充分,則不能很好的挖掘用戶喜好,這也反映了從動態(tài)視角看待用戶的必要性。實(shí)驗結(jié)果同時表明,隨著K 的增加,性能會有所下降,這可能是因為發(fā)生了過擬合。
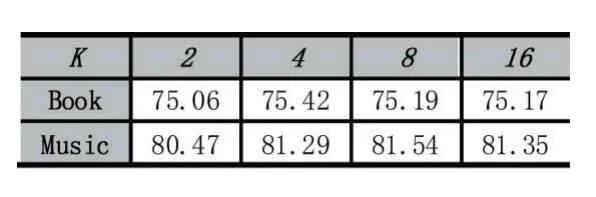
表6 不同交互項目采樣個數(shù)時DKGAT 的AUC 值
3 結(jié)語
本文提出了基于雙用戶視角與知識圖譜注意力網(wǎng)絡(luò)的推薦模型。為挖掘用戶特征,該模型從雙視角分析用戶行為。首先,用戶興趣為用戶本身特性的傳達(dá),此為靜態(tài)用戶視角。其次,用戶交互的歷史項目是興趣的外在展現(xiàn),此為動態(tài)用戶視角。為挖掘項目特征,在知識圖譜中利用注意力機(jī)制捕獲低階與高階項目屬性,并自動挖掘用戶興趣路徑,最終通過鄰域聚合的方法得到項目表示。考慮到現(xiàn)實(shí)中存在很多與知識圖譜相似的結(jié)構(gòu)化信息,如社交網(wǎng)絡(luò),因此在未來的工作中可嘗試將注意力網(wǎng)絡(luò)等應(yīng)用于其他的結(jié)構(gòu)化信息中。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
