基于深度學習的電子物流票據(jù)信息分割與識別
2020-06-12 03:50:06沈明軍汪山虎王朝暉楊佳龍陳杉杉
甘肅科技縱橫 2020年5期
關(guān)鍵詞:模型
沈明軍,汪山虎,王朝暉,楊佳龍,陳杉杉
(江蘇大學,江蘇 鎮(zhèn)江 212013)
0 引言
隨著我國電商和物流領(lǐng)域的迅猛發(fā)展,涌現(xiàn)了大量的電子物流票據(jù),對于這些電子票據(jù)信息的識別和利用有著巨大的社會效益和經(jīng)濟效益。實現(xiàn)電子物流票據(jù)的快速識別錄入,迅速獲取物流信息,不僅縮短信息采集時間,更有利于物流和電商企業(yè)及時響應(yīng)市場需求,做出合理資源分配。
在電子物流票據(jù)的識別過程中,具體包含兩大應(yīng)用技術(shù),即字符分割和字符識別。字符分割的完整性很大程度決定了識別的正確性,所以字符分割技術(shù)至關(guān)重要。在字符分割領(lǐng)域,早期有提出基于投影的分割算法[1],利用文本區(qū)域行列之間的間隔,對字符進行切割,此算法對英文和數(shù)字等連通體文本的分割準確率較高,但在含有大量左右偏旁的中文字符集較難準確分割;有學者在投影分割的基礎(chǔ)上提出了統(tǒng)計分割算法[2],該算法通過聚類算法分析出正常字符寬度范圍,再結(jié)合高度、寬度和高寬比三種特征信息進行字符分割,但此算法識別非正常中文字符集所利用的特征信息過于簡單,容易錯誤識別導致分割失敗;有學者提出了基于連通域的字符分割算法[3],但并不適用具有文字密集性特點的電子物流票據(jù),容易導致多行多字被分割。
基于以上的分析,面對電子物流票據(jù)中單字符分割時所利用特征單一的問題,我們在統(tǒng)計分割算法的基礎(chǔ)上,將聚類算法與深度學習相結(jié)合實現(xiàn)基于復雜特征的電子物流票據(jù)分割。利用深度模型學習到的文字特征替代了高度、寬度和高寬比三種簡單特征,例如文字的形態(tài)、結(jié)構(gòu)等隱性特征;為了充分考慮偏旁的左右字符信息,通過左順序優(yōu)先和右預(yù)判相結(jié)合的方法,提高了偏旁的組合準確率,進而有效提高了整體上單字符分割的準確度。在字符分割結(jié)束后,將中文字符送入VGG16深度網(wǎng)絡(luò)模中進行識別[4],識別準確率達到了99.9%。
1 相關(guān)理論
1.1 基于投影的字符分割算法
二值化文字圖像后,對字符像素分別在x,y軸上投影,即對每一行或每一列像素進行累加,形成高低起伏的統(tǒng)計分布圖,根據(jù)峰谷依次進行水平分割、垂直分割,如圖1所示。投影法對行文本的切割準確而高效,而對行文本中每個中文字符的列分割,卻容易失敗,因為有中文字符含有左右偏旁,垂直投影后,很容易把偏旁單獨分割出來。如果在文本中再混合英文、標點和數(shù)字,由于英文、標點和數(shù)字存在與分割出的偏旁同一寬度的情況,對于分割錯誤的偏旁就很難進行正確的組合,所以投影分割算法適用于英文、數(shù)字和標點這種連通體字符的分割,而在中文字符分割上的表現(xiàn)效果不佳。
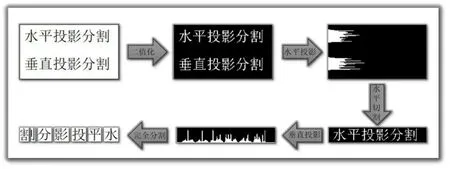
圖1 文字進行投影分割
1.2 基于統(tǒng)計學習的字符分割算法
基于統(tǒng)計學習的字符分割算法是在投影分割算法的基礎(chǔ)上進行改進的,在基礎(chǔ)投影分割后,收集分割字符的寬度數(shù)據(jù),進行聚類分析,再結(jié)合長度、寬度和長寬比三種特征進行字符分割。
雖然統(tǒng)計分割在實際中的部分應(yīng)用表現(xiàn)突出,甚至可以商用,比如在牌照、商品字符等方面[5],但是只有在結(jié)合具體的場景中才有效果。這主要原因是統(tǒng)計分割對投影分割的完善是有限的,一方面表現(xiàn)在對非整體字符中英文、標點和數(shù)字的識別具有很大的限制,因為在統(tǒng)計分割中采集到字符的數(shù)據(jù)特征只包含長、寬和長寬比三種特征,而非正常字符中的偏旁、數(shù)字、標點和英文在這三種特征上重合的可能性很大;另一方面是對偏旁組合考慮的情況考慮不夠全面,容易導致組合失敗。
1.3 卷積神經(jīng)網(wǎng)絡(luò)
隨著深度學習的崛起,卷積神經(jīng)網(wǎng)絡(luò)(CNN)[6]在計算機視覺領(lǐng)域得到廣泛的應(yīng)用,原因在于卷積對圖片特征的提取力得到了毋庸置疑的肯定。CNN是一類包含卷積計算且具有深度結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò),常用于目標分類、目標檢測等研究領(lǐng)域,其主要由輸入層、卷積層、池化層、全連接層組成。
卷積層可以提取圖片的特征,隨著層數(shù)的加深,提取的特征信息會更加豐富;池化層是取卷積核區(qū)域的最大值或平均值來代替該區(qū)域從而達到增強魯棒性和減少計算量;全連接層連接所有的特征,將輸出值送給分類器(如softmax分類器)實現(xiàn)概率輸出。
2 改進的字符分割、識別算法
本論述的工作是對電子物流票據(jù)字符進行精準分割與識別。為避免異常寬度字符(包括中文偏旁、英文字符、數(shù)字和標點)無法識別,在原始投影算法上結(jié)合異常寬度字符聚類算法,并運用基礎(chǔ)CNN網(wǎng)絡(luò)實現(xiàn)異常寬度字符的分類,再通過組合機制將多個偏旁拼接成整字。最后,將整字依次輸入到VGG16深度模型中識別。
2.1 K-Means聚類算法
K-Means聚類算法是一種迭代求解的聚類分析算法。在輸入數(shù)據(jù)中,隨機設(shè)置k個中心點,計算數(shù)據(jù)集中每一個點到中心點的距離(如歐式距離),根據(jù)距離迭代調(diào)整中心尋找最優(yōu)解[7]。
本論述在投影分割后,通過K-Means算法對分割字符的寬度進行正常和異常聚類分析。設(shè)置中心簇k=2,目的是分出正常寬度字符和異常寬度字符。在正常字符的寬度數(shù)據(jù)集中找出正常字符的寬度范圍,用于以后中文偏旁的組合。正常寬度字符集包括完整的中文漢字,異常寬度字符集里包括中文偏旁、英文字符、數(shù)字和標點。
選用歐式距離作為目標函數(shù),見式(1):

其中,xn表示數(shù)據(jù)對象,μk表示中心點,rnk在數(shù)據(jù)點n分配到類別k的時候為1,沒有分配到類別k的時候為0。
迭代優(yōu)化過程中,先固定 μk,更新rnk,將每個數(shù)據(jù)對象放到與其最近的聚類中心的類別中;然后固定rnk,更新 μk,根據(jù)J對 μk的偏導等于零求得中心 μk的更新公式,見式(2):

這樣交替更新,直至目標函數(shù)收斂,分離出正常與異常字符。
2.2 CNN異常寬度字符分類
采用CNN網(wǎng)絡(luò)模型對異常寬度字符集里的字符進行識別,此深度模型主要由2層卷積層,2層池化層和2層全連接層組成,具體結(jié)構(gòu)如圖2所示。
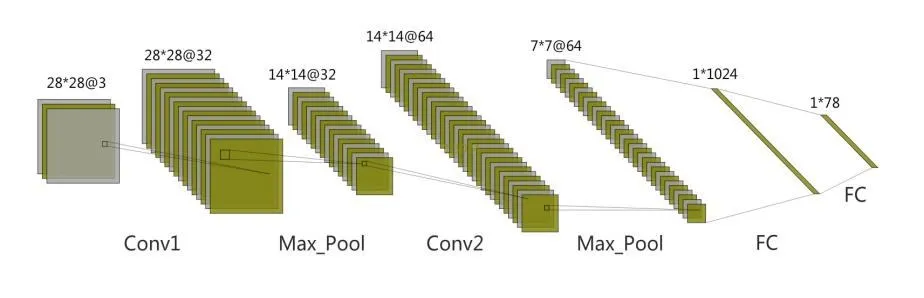
圖2 異常寬度字符分類CNN
輸入數(shù)據(jù)為原始訓練圖像(圖像大小:28×28×3),因為數(shù)字、常用標點、英文共有有78種類別,所有模型輸出的神經(jīng)元個數(shù)為78。模型的測試集效果達99.9995%,訓練集為100%。
2.3 偏旁組合機制
根據(jù)卷積神經(jīng)網(wǎng)絡(luò)識別出來的偏旁進行重新組合,采用左順序優(yōu)先的策略,即從每一行文本的最左側(cè)開始檢測,檢測到第一個偏旁,開始分析其左右字符,具體情況見表1所列。

表1 偏旁組合情況
面對第一和第二種情況,我們從檢測到的偏旁和右鄰近的偏旁進行組合,對組合后的寬度進行計算,如果滿足在正常字符的寬度范圍之內(nèi)就進行組合,如果低于正常字符的最小寬度值,則會繼續(xù)組合右邊的偏旁。
面對第三種情況,我們將所檢測到的偏旁和左右整字的寬度分別相加,如果只有一個組合寬度在正常字符范圍之內(nèi),就將偏旁和整字進行組合;如果兩個組合寬度都在正常字符寬度范圍之內(nèi),我們選擇寬度靠近K-Means聚類算法算出的聚簇中心的組合。如果兩個組合都超出正常字符范圍,則對偏旁寬度進行縮減之后再次進行組合分析。
面對第三種情況,我們對所檢測偏旁不做任何操作。
2.4 VGG16字符識別模型
在單字符分割后,采用VGG16網(wǎng)絡(luò)模型實現(xiàn)字符識別。模型訓練的數(shù)據(jù)集借助強大的圖形庫自動生成,含有3755個常用中文字符,并對每一個字符進行了六種增強,分別為:文字扭曲、背景噪聲、文字位置、筆畫粘連、筆畫斷裂和文字傾斜。
VGG16深度模型具有結(jié)構(gòu)簡單,提取特征能力強的優(yōu)勢。雖然之后出現(xiàn)了更加優(yōu)秀的網(wǎng)絡(luò),如ResNet[8]和 DenseNet[9]等,但考慮到 VGG16 模型分類能力已經(jīng)足夠滿足我們的分類需求,而其他更優(yōu)秀網(wǎng)絡(luò)一般具有訓練難度大和線上部署時的預(yù)測速度慢等問題,所以我們最終還是采用了VGG16網(wǎng)絡(luò)作為文字圖片的識別網(wǎng)絡(luò)。網(wǎng)絡(luò)主要結(jié)構(gòu)如圖3所示。
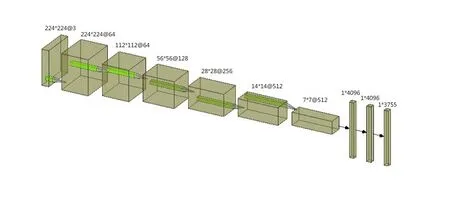
圖3 VGG16識別網(wǎng)絡(luò)結(jié)構(gòu)圖
卷積層用來理解圖片的重要的空間信息,比如空間上鄰近的像素為相似的值、RGB的各個通道之間的關(guān)聯(lián)性、相距較遠的像素之間的關(guān)聯(lián)等。池化層主要是用來增強對微小位置變化的魯棒性和保留主要特征的同時減少參數(shù)和計算量,防止過擬合,提高模型泛化能力。
全連接層起到將學到的“分布式特征表示”映射到樣本標記空間的作用。同時在三個全連接層中增加了兩次dropout層,來防止過擬合。3個全連接層在整個卷積神經(jīng)網(wǎng)絡(luò)中起到的是對文字圖片進行分類的作用。
在全連接層最后一層有3755個神經(jīng)元,是因為我們要對3755個常用中文字符進行的分類。而英文、標點和數(shù)字的識別在分割時就已經(jīng)被識別出來,所以不參加這里的分類。
3 實驗與分析
3.1 實驗運行平臺
本實驗采用運行平臺CPU為Intel Core i7-8700k,顯卡為GeForce GTX1080,系統(tǒng)為64位Ubuntu 16.04,在Tensorflow+GUDA9.2下進行實驗。
3.2 單字符分割實驗
3.2.1 數(shù)據(jù)集
本論述聚類算法和深度識別模型分析的數(shù)據(jù)集來自電子物流票據(jù)中分割出來的文本圖片,我們在對文本圖像二值化后進行了投影分割,分割效果如圖4所示。

圖4 投影分割流程圖
分割結(jié)束后由垂直投影計算得到分割字符的寬度數(shù)據(jù)集,而深度識別模型的數(shù)據(jù)集我們自制的數(shù)據(jù)集,將電子物流票據(jù)中的各類英文、數(shù)字和標點和偏旁用投影法分割出來,共有78種。將78種圖片二值化,字符為白,背景為黑,對圖像進行各種類型的膨脹,多樣化數(shù)據(jù)。圖片的size設(shè)置為(3,28,28),三通道上的值同為二值化后的圖像值,即將二值化的圖像復制三份,之后再對圖片進行縮放、旋轉(zhuǎn)(仿射變換),然后增加隨機噪聲。將數(shù)據(jù)保存為npy格式,共10 000組,每個數(shù)字滿足“粗細、旋轉(zhuǎn)角度、縮放比例、噪聲分布”的多樣化。
3.2.2 參數(shù)設(shè)計及實驗結(jié)果
對分割字符寬度數(shù)據(jù)集進行聚類分析,在K-Means算法中,我們設(shè)聚簇中心k=2,將分割出的字符集分為兩類,一為整字寬度集,二為非整字寬度集,具體效果如圖5所示。
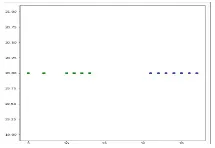
圖5 聚類分析結(jié)果圖
由上圖顯示,在我們所做的數(shù)據(jù)中,整字寬度集和非整字寬度集的分類比較明顯,他們聚簇中心點分別為24.3和8.6,計算方差為162.676,所以對整字和非整字的區(qū)分比較容易,對整字集的寬度也很容易從聚類圖中得到。
之后使用深度網(wǎng)絡(luò)模型對非整字集進行識別,我們使用了由兩層卷積和兩次全連接層構(gòu)成的網(wǎng)絡(luò)進行了訓練。網(wǎng)絡(luò)的初始權(quán)值設(shè)計為標準差為0.1的正態(tài)分布,損失函數(shù)選擇了softmax_cross_entropy,優(yōu)化器選擇了Adam,學習率設(shè)為0.001,表2展示了從200次迭代到450次迭代的測試集精度和訓練集精度,在450次迭代以后準確率分別達到了99.95%和100%。
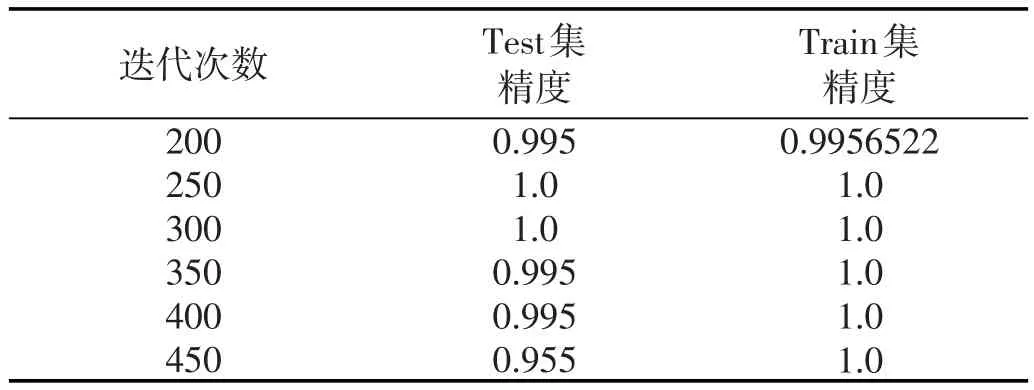
表2 CNN訓練、測試準確度分析
在將非整字集識別完后,就是對非整字集的偏旁進行組合,部分組合效果如圖6所示。

圖6 偏旁組合效果圖
3.3 深度模型識別實驗
3.3.1 數(shù)據(jù)集
電子物流票據(jù)的文字屬于印刷體,我們可以借助強大的圖形庫自動生成數(shù)據(jù)集。本論述的中文數(shù)據(jù)集含有3 755個常用中文字符,對每一個字符進行了六種增強,分別為:文字扭曲、背景噪聲、文字位置、筆畫粘連、筆畫斷裂和文字傾斜。具體效果如圖7所示。

圖7 中文字符數(shù)據(jù)集
3.3.2 參數(shù)設(shè)計及實驗結(jié)果
在制作完數(shù)據(jù)集以后,我們將數(shù)據(jù)送進了VGG16網(wǎng)絡(luò),網(wǎng)絡(luò)的損失函數(shù)選擇交叉熵損失函數(shù),優(yōu)化器選擇了Adam,學習率設(shè)為0.1,最大迭代步數(shù)為16 000,每100步進行一次驗證,每500步存儲一次模型。
在訓練過程中訓練集和測試集的Accuracy變化如圖8所示。
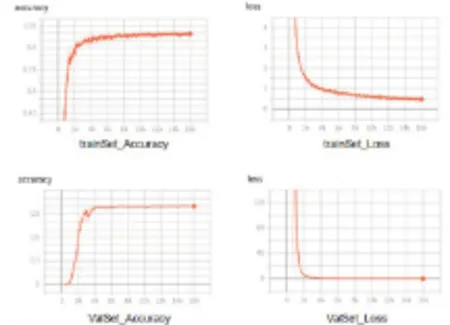
圖8 VGG16準確率與損失值變化情況
實際字符識別效果如圖9所示。
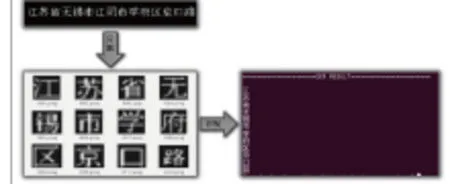
圖9 字符識別效果圖
數(shù)據(jù)定位結(jié)構(gòu)化識別結(jié)果如圖10所示。

圖10 結(jié)構(gòu)化識別結(jié)果
4 結(jié)束語
本論述提出了一種將傳統(tǒng)機器學習算法中的KMeans聚類算法和深度學習分類算法相結(jié)合的方法,解決了傳統(tǒng)方法對含有中文字符的電子物流票據(jù)圖像難分割的問題。首先,我們使用了聚類算法分析出正常字符的寬度大小,進而使用深度網(wǎng)絡(luò)識別出英文字符、數(shù)字、標點和偏旁,再通過左順序優(yōu)先、右預(yù)判和正常字符寬度范圍等信息對偏旁進行了較為準確的組合,有效提高了整體字符分割的準確率。在這之后,我們將分割好的圖片送進VGG16網(wǎng)絡(luò)模型進行了識別,訓練集和驗證集的accuracy都達到了99.9%,且在實際測試中,針對左右偏旁結(jié)合的中文字符識別的效果較好。
本論述只針對電子物流票據(jù)這一特定場景進行深入研究,字符識別在其他復雜場景中的應(yīng)用同樣值得更進一步的探索。如果將本論述的直接分割策略和已經(jīng)商用的置信度反饋機制相結(jié)合,可能會適用于更多場景的字符識別。[10]
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
