Hadoop和Spark在Web系統(tǒng)推薦功能中的應(yīng)用
2020-06-08 01:55:13童瑩楊貞卓
現(xiàn)代信息科技 2020年19期
童瑩 楊貞卓

摘? 要:隨著Web系統(tǒng)的數(shù)據(jù)量不斷增大,利用傳統(tǒng)數(shù)據(jù)庫(kù)等技術(shù)難以滿足系統(tǒng)數(shù)據(jù)分析及用戶個(gè)性化需求的要求,而大數(shù)據(jù)技術(shù)可以有效達(dá)成上述目標(biāo)。文章基于Hadoop和Spark兩個(gè)大數(shù)據(jù)框架,介紹了其基本功能,結(jié)合兩個(gè)框架的工作原理及部署、應(yīng)用方式,將其應(yīng)用到一個(gè)Web系統(tǒng)的影視推薦功能中,最后提出了系統(tǒng)推薦功能后期的完善思路。
關(guān)鍵詞:Hadoop;Spark;Python;推薦功能
Abstract:With the increasing amount of data in the Web system,it is difficult to meet the requirements of system data analysis and user personalized needs by using traditional database technology,while big data technology can effectively achieve the above goals. Based on Hadoop and Spark two big data frameworks,this paper introduces their basic functions. Combined with the working principle,deployment and application mode of the two frameworks,it applies them to the movie recommendation function of a Web system. Finally,it puts forward the improvement ideas of the system recommendation function in the later stage.
Keywords:Hadoop;Spark;Python;recommendation function
0? 引? 言
如今Web系統(tǒng)開發(fā)的一個(gè)重要趨勢(shì)就是加入大數(shù)據(jù)技術(shù)來(lái)進(jìn)行數(shù)據(jù)處理。傳統(tǒng)的無(wú)個(gè)性化推薦的購(gòu)物網(wǎng)站、電影網(wǎng)站等Web系統(tǒng),很難對(duì)用戶進(jìn)行精準(zhǔn)營(yíng)銷。隨著大數(shù)據(jù)應(yīng)用技術(shù)的不斷發(fā)展,其已被應(yīng)用到個(gè)性化推薦及數(shù)據(jù)分析功能中。不止購(gòu)物網(wǎng)站,多個(gè)行業(yè)都用到了數(shù)據(jù)處理功能,如:阿里的“猜你喜歡”,又或是外賣平臺(tái)的派單功能中,根據(jù)最近的用戶進(jìn)行派單操作,均是利用大數(shù)據(jù)技術(shù)實(shí)現(xiàn)了精準(zhǔn)的推薦及任務(wù)分派。本設(shè)計(jì)源于武漢商學(xué)院信息工程學(xué)院軟件工程實(shí)訓(xùn),通過(guò)將傳統(tǒng)的Web系統(tǒng)和大數(shù)據(jù)技術(shù)結(jié)合的方式,完成了Web系統(tǒng)中推薦功能模塊。
大數(shù)據(jù)的特點(diǎn)就是能夠在短時(shí)間內(nèi)捕捉、管理和處理海量數(shù)據(jù),在Web系統(tǒng)中添加個(gè)性化推薦功能,可使其更精準(zhǔn)的滿足用戶個(gè)性化的信息推薦需求,勢(shì)必成為未來(lái)Web應(yīng)用系統(tǒng)不可或缺的功能。實(shí)現(xiàn)大數(shù)據(jù)推薦功能的框架有很多,Hadoop和Spark作為大數(shù)據(jù)技術(shù)的主流框架,很適合與Web系統(tǒng)結(jié)合,用以完成其中數(shù)據(jù)推薦等功能,所以利用Hadoop和Spark實(shí)現(xiàn)Web系統(tǒng)推薦功能,具有很強(qiáng)的應(yīng)用價(jià)值。
1? 大數(shù)據(jù)框架的基本介紹
大數(shù)據(jù)框架也稱處理框架,是大數(shù)據(jù)系統(tǒng)中一個(gè)最基本的組件。處理框架負(fù)責(zé)對(duì)系統(tǒng)中的數(shù)據(jù)進(jìn)行計(jì)算。Hadoop可以看作是MapReduce處理引擎的處理框架,引擎和框架通常可以相互替換或同時(shí)使用,例如:Spark可以結(jié)合Hadoop,并取代MapReduce。組件之間的互操作性體現(xiàn)了大數(shù)據(jù)系統(tǒng)的靈活性,了解和應(yīng)用大數(shù)據(jù)處理框架,對(duì)深入應(yīng)用大數(shù)據(jù)至關(guān)重要。
1.1? Hadoop的基本組件介紹
Hadoop作為一個(gè)分布式系統(tǒng),能讓開發(fā)人員在不了解底層架構(gòu)的情況下,輕松完成應(yīng)用。它實(shí)現(xiàn)的分布式文件系統(tǒng)核心組件是HDFS和MapReduce。HDFS是Hadoop的儲(chǔ)存系統(tǒng),能夠?qū)崿F(xiàn)創(chuàng)建文件、刪除文件、移動(dòng)文件等功能,操作的數(shù)據(jù)主要是要處理的原始數(shù)據(jù)以及計(jì)算過(guò)程中的中間數(shù)據(jù),它能實(shí)現(xiàn)高吞吐量的數(shù)據(jù)讀寫。MapReduce系統(tǒng)是一個(gè)分布式計(jì)算框架,可利用分散的計(jì)算機(jī)集群對(duì)海量的數(shù)據(jù)進(jìn)行分解處理。當(dāng)然,除了上面這些優(yōu)勢(shì),Hadoop也存在著一些缺點(diǎn),例如:Hadoop無(wú)法對(duì)大量小文件進(jìn)行高效存儲(chǔ),MapReduce計(jì)算框架缺少迭代支持,另一方面會(huì)有較高的延遲,但作為大數(shù)據(jù)開源框架的代表,Hadoop仍是目前業(yè)界廣泛認(rèn)可,且使用非常廣泛的一個(gè)大數(shù)據(jù)開源框架。
1.2? Spark的基本組件介紹
Spark是一個(gè)開源集群運(yùn)算框架,由Scala語(yǔ)言進(jìn)行實(shí)現(xiàn),它是一種面向?qū)ο蟆⒑瘮?shù)式編程語(yǔ)言,能夠像操作本地集合對(duì)象一樣輕松地操作分布式數(shù)據(jù)集。Spark本身具有幾個(gè)特點(diǎn),首先相對(duì)于同為計(jì)算模型MapReduce來(lái)說(shuō),Spark更快,不管數(shù)據(jù)是從磁盤中讀取還是從內(nèi)存中讀取。其次Spark易用性更好,除了Scala之外,它還支持Java,Python等語(yǔ)言編寫,和Hadoop一樣,Spark的通用性也強(qiáng),它的生態(tài)圈也十分廣泛,包括了Spark SQL,MLlib等組件。Spark具有很強(qiáng)的適應(yīng)性,能夠讀取HDFS,HBase等為持久層讀寫原生數(shù)據(jù),作為資源管理器去調(diào)度Job來(lái)完成Spark應(yīng)用的計(jì)算,但因其缺少文件管理系統(tǒng),所以一般在實(shí)際開發(fā)中,常與Hadoop結(jié)合起來(lái)一起使用。
Spark的MLlib機(jī)器學(xué)習(xí)庫(kù)是它非常重要的一個(gè)組成部分。MLlib機(jī)器學(xué)習(xí)庫(kù)由一些通用學(xué)習(xí)算法和工具組成,包括分類、回歸、聚類、協(xié)同過(guò)濾、降維等。相對(duì)于Hadoop中MapReduce實(shí)現(xiàn)的機(jī)器學(xué)習(xí)算法,Spark基于內(nèi)存的計(jì)算模型良好的改善了MapReduce計(jì)算框架迭代中反復(fù)讀取磁盤的問(wèn)題。在Web系統(tǒng)的推薦功能中,開發(fā)人員可以直接調(diào)用Spark MLlib庫(kù)中的協(xié)同過(guò)濾算法來(lái)對(duì)數(shù)據(jù)進(jìn)行處理。
2? Hadoop和Spark的應(yīng)用方式
Hadoop具有高可靠性,高擴(kuò)展性,高效性,高容錯(cuò)性的優(yōu)點(diǎn),Spark有更高的性能,能夠與Hadoop生態(tài)兼容,并且還有易用的機(jī)器學(xué)習(xí)庫(kù)。類似的大數(shù)據(jù)框架還有storm、Flink等,但前者對(duì)于真正的大流量應(yīng)用還不太穩(wěn)定,后者產(chǎn)生時(shí)間較晚,應(yīng)用起來(lái)有一定風(fēng)險(xiǎn)。
Hadoop和Spark大數(shù)據(jù)框架搭建在虛擬機(jī)環(huán)境上,可以通過(guò)Java,Python等完成應(yīng)用開發(fā),也可使用包括專為Spark服務(wù)的Scala來(lái)進(jìn)行開發(fā)。鑒于信息工程學(xué)院開設(shè)了Phyton課程,在我們此次Web系統(tǒng)的推薦功能中,采用Python來(lái)調(diào)用Hadoop和Spark服務(wù)。
Python是一個(gè)輕量化腳本語(yǔ)言,使用方便。Hadoop和Spark都支持Python,所以此系統(tǒng)中通過(guò)Python來(lái)連接使用Hadoop和Spark。使用Hadoop和Spark服務(wù),首先需要連接上Hadoop和Spark的主機(jī)。開發(fā)人員可以通過(guò)使用用來(lái)操作Hadoop和Spark的PyHDFS和PySpark來(lái)完成。具體操作為:
(1)用pyhdfs.HdfsClient鏈接Hadoop主機(jī),設(shè)置主機(jī)HOST信息及用戶名信息,具體代碼為:fs = pyhdfs.HdfsClient(hosts='Hadoop0,50070', user_name='hdfs')
(2)再通過(guò)pySpark連接到Spark主機(jī),利用Spark Context容器,在參數(shù)中設(shè)定應(yīng)用的名字和要連接到的集群的URL:sc = SparkContext(appName="endless similar matrix",master="Spark://Hadoop0:7077")
通過(guò)這兩步操作,開發(fā)人員就可以很輕易地連接上主機(jī),當(dāng)然前提是需要保證上述使用的主機(jī)名及端口是正確的。
除了連接服務(wù),開發(fā)時(shí),要使用HDFS存儲(chǔ)系統(tǒng)需要的數(shù)據(jù),在本系統(tǒng)中,可以選擇通過(guò)upload來(lái)進(jìn)行上傳操作,實(shí)現(xiàn)該操作的代碼為:upload_to_hdfs(file)
在準(zhǔn)備好系統(tǒng)所需要的存儲(chǔ)文件以后,就可以調(diào)用Spark來(lái)對(duì)數(shù)據(jù)進(jìn)行處理,讀取文件的路徑,本系統(tǒng)中代碼如下所示:text = sc.textFile("hdfs://Hadoop0:9000/user/data.csv")
以上就是連接Hadoop和Spark集群所進(jìn)行的操作,如果需要進(jìn)一步對(duì)文件進(jìn)行處理優(yōu)化,就需要編寫腳本來(lái)設(shè)置處理方法,也可以直接調(diào)用Spark MLlib庫(kù)中的已有算法,通過(guò)設(shè)置好需要的一些迭代參數(shù),進(jìn)行模型訓(xùn)練即可。當(dāng)然如果需要將服務(wù)暴露出去供系統(tǒng)開發(fā)人員后端調(diào)用,則可以先將端口號(hào)修改為0.0.0.0,然后通過(guò)設(shè)置的路由,訪問(wèn)相對(duì)應(yīng)的函數(shù)即可,實(shí)現(xiàn)代碼為:app.run(host="0.0.0.0")
3? Hadoop和Spark在推薦系統(tǒng)中的應(yīng)用
Web系統(tǒng)推薦功能要解決的就是數(shù)據(jù)量大的問(wèn)題,同時(shí)還要快和準(zhǔn),如果用單機(jī)處理,即使內(nèi)存夠跑完整個(gè)流程也要耗費(fèi)大量時(shí)間,迭代就更加難以完成,所以實(shí)際開發(fā)中,Web系統(tǒng)常常要用到分布式系統(tǒng)。對(duì)于分布式計(jì)算框架,Hadoop和Spark是目前合適并且優(yōu)秀的分布式模型。目前它們的應(yīng)用場(chǎng)景有很多,包括提供個(gè)性化服務(wù),優(yōu)化業(yè)務(wù)流程等,當(dāng)然最常見的就是個(gè)性化推薦的服務(wù)。下文具體介紹Hadoop和Spark在Web系統(tǒng)推薦功能中的開發(fā)方法。
首先,Hadoop和Spark都是免費(fèi)開源框架,開發(fā)人員可在Apache官網(wǎng)下載Hadoop和Spark的安裝包;然后安裝一個(gè)虛擬機(jī)環(huán)境,安裝配置諸如:ubantu等系統(tǒng);接著通過(guò)Xshell等終端模擬軟件連接上虛擬機(jī),此時(shí)就可將下載的安裝包上傳到虛擬機(jī)當(dāng)中;上傳完成后,通過(guò)zxvf指令將安裝包解壓至指定位置。完成上述部署后,還需要對(duì)幾個(gè)配置文件進(jìn)行修改,修改之前,因?yàn)镠adoop需要Java環(huán)境,所以開發(fā)人員還需要先行下載Java JDK,并且在etc/profile中配置路徑。這些完成之后,就要對(duì)Hadoop和Spark配置文件進(jìn)行修改,主要開發(fā)步為:
(1)在Hadoop中,首先修改Hadoop-env.sh文件,將jdk路徑導(dǎo)入進(jìn)去,修改core-site.xml文件,指定namenode的通信地址以及Hadoop運(yùn)行時(shí)產(chǎn)生的文件路徑,接著修改hdfs-site.xml,設(shè)置HDFS副本數(shù)量,然后修改mapred-site.xml。應(yīng)注意的是,由于在配置文件目錄下沒(méi)有此文件,需要修改名稱,具體方式為:mvmapred-site.xml.template mapred-site.xml
通知MapReduce使用yarn,修改yarn-site.xml,然后修改reduce獲取數(shù)據(jù)的方式。這些修改完成之后需要將Hadoop添加到環(huán)境變量中去,然后執(zhí)行。
配置文件修改完成后,需要先格式化Hadoop,然后在sbin目錄下執(zhí)行start-all.sh腳本即可啟動(dòng)Hadoop服務(wù),通過(guò)jps可以看到各個(gè)節(jié)點(diǎn)的端口,具體如圖1所示。
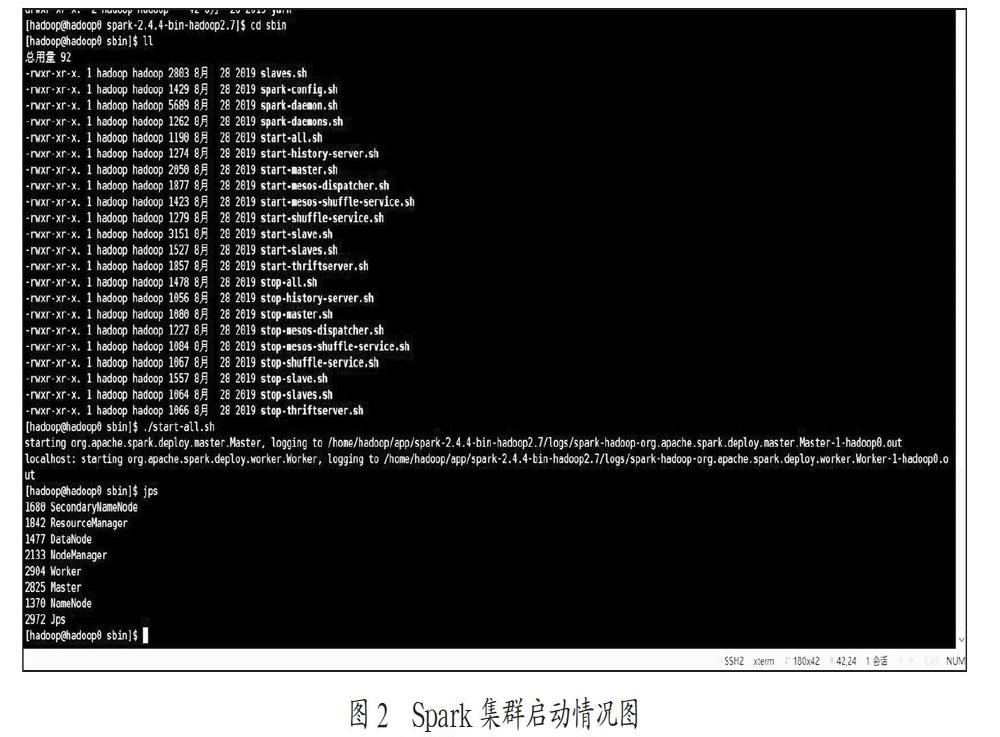
(2)Hadoop啟動(dòng)完成后就可以啟動(dòng)系統(tǒng)的Spark服務(wù),同Hadoop一樣也需要先修改其配置文件,并且需要先將Python配置到默認(rèn)環(huán)境中,雖然Spark大部分是以Scala作為開發(fā)語(yǔ)言的,但在此處,采用Pyhton來(lái)進(jìn)行操作。將環(huán)境配置完成之后,同樣是在sbin目錄下運(yùn)行start-all.sh腳本來(lái)啟動(dòng)Spark集群,通過(guò)jps查看是否成功,如圖2所示。
(3)集群都啟動(dòng)成功后,開發(fā)人員就需要準(zhǔn)備推薦功能所需要的推薦服務(wù),結(jié)合本W(wǎng)eb系統(tǒng)中影視推薦功能,此服務(wù)可結(jié)合用戶的喜好,有針對(duì)性的為其推薦相類似的影視資源。此功能要利用協(xié)同過(guò)濾算法,因?yàn)镾park自帶的MLlib庫(kù)中有ALS(協(xié)同過(guò)濾)可以直接調(diào)用,所以只需要設(shè)置好迭代的參數(shù)即可,當(dāng)然首先還是要先對(duì)數(shù)據(jù)集進(jìn)行處理,具體代碼為:movieRatings = text.map(lambda x: x.split(",")[:3])model = ALS.train(movieRatings, 10, 10, 0.01)
通過(guò)這兩步操作就可以完成一個(gè)模型的訓(xùn)練。
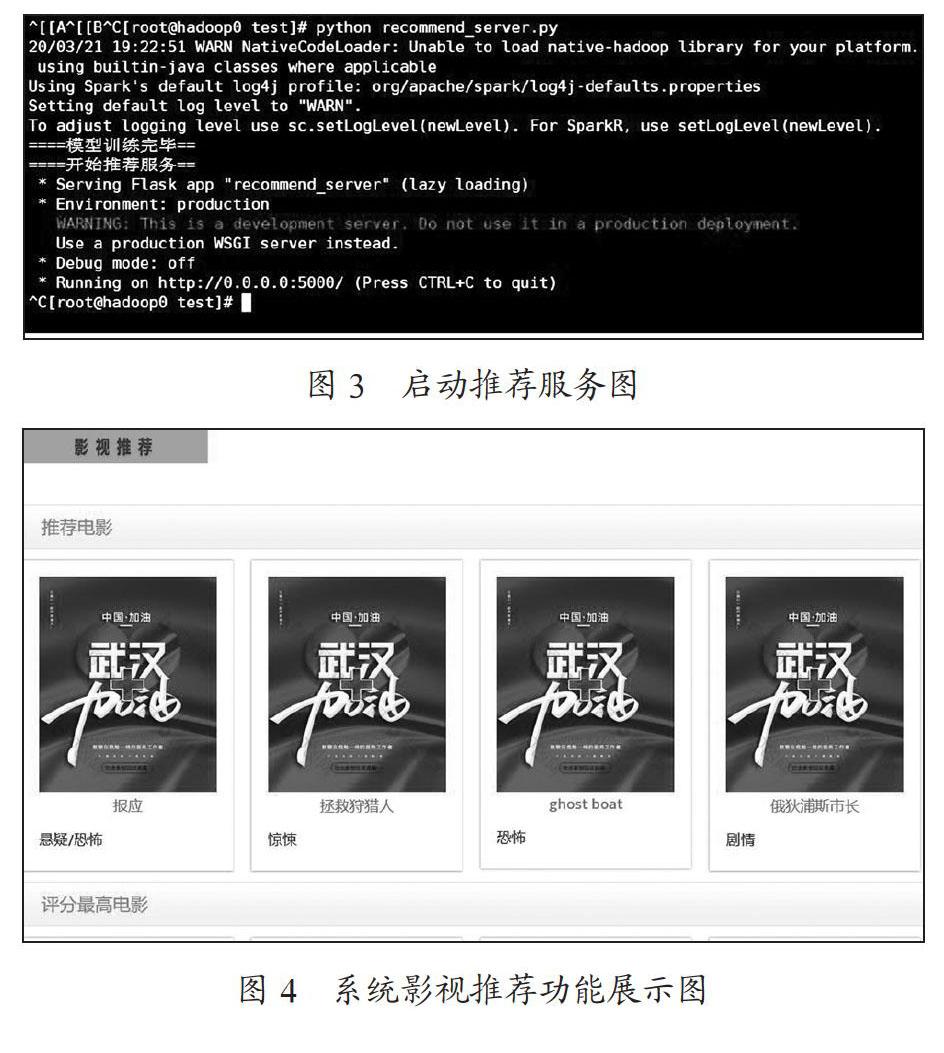
(4)服務(wù)腳本編寫好之后,需要上傳到虛擬機(jī)環(huán)境當(dāng)中運(yùn)行,在運(yùn)行服務(wù)腳本之前,開發(fā)人員需要通過(guò)pip指令在虛擬機(jī)中安裝好PySpark,PyHDFS等各個(gè)插件,然后可以直接通過(guò)Python腳本的方式來(lái)直接啟動(dòng)服務(wù),如圖3所示。
至此,一個(gè)推薦服務(wù)已經(jīng)基本搭建并且運(yùn)行起來(lái)了,如果后端需要訪問(wèn)這個(gè)服務(wù),可以用flask框架設(shè)置的路由直接進(jìn)行訪問(wèn)。具體效果如圖4所示。
4? 結(jié)? 論
此基于Hadoop和Spark的Web系統(tǒng)推薦功能可以依據(jù)用戶喜好,實(shí)現(xiàn)個(gè)性化推薦,這讓W(xué)eb系統(tǒng)變得更加個(gè)性化,有針對(duì)性,使用效果更加出色。本W(wǎng)eb系統(tǒng)的推薦功能后期可以進(jìn)一步做升級(jí),如果要處理更大的數(shù)據(jù)量的推薦,可以采用諸如:Spring Cloud等框架集合來(lái)構(gòu)架分布式、微服務(wù)架構(gòu)的Web系統(tǒng)。在此基礎(chǔ)上,結(jié)合Hadoop和Spark,推薦功能的優(yōu)化性會(huì)得到明顯提高。
軟件工程實(shí)訓(xùn)項(xiàng)目通常以某項(xiàng)技術(shù)平臺(tái)為支撐,但僅使用Web開發(fā)技術(shù)完成的Web項(xiàng)目,難以適應(yīng)實(shí)際開發(fā)的需要。Web系統(tǒng)中的推薦功能,個(gè)性化服務(wù)等一定會(huì)應(yīng)用得越來(lái)越廣泛,了解和應(yīng)用大數(shù)據(jù)技術(shù)對(duì)Web開發(fā)人員會(huì)變得更加重要,特別是在涉及大量數(shù)據(jù)處理的系統(tǒng)開發(fā)工作中,其將成為一個(gè)基本應(yīng)具備的開發(fā)技能,此系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn),對(duì)軟件工程專業(yè)、大數(shù)據(jù)專業(yè)的學(xué)生實(shí)訓(xùn)都能起到極大的鍛煉作用。
參考文獻(xiàn):
[1] 李曉穎,趙安娜,周曉靜,等.基于大數(shù)據(jù)分析與挖掘平臺(tái)的個(gè)性化商品推薦研究及應(yīng)用 [J].電子測(cè)試,2019(12):65-66+81.
[2] 李榮.大數(shù)據(jù)技術(shù)必須了解這些 [J].計(jì)算機(jī)與網(wǎng)絡(luò),2019,45(13):36-37.
[3] 孫皓.基于Hadoop平臺(tái)和Spark框架的推薦系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn) [D].福建:華僑大學(xué),2018.
[4] 徐林.基于Spark MLlib協(xié)同過(guò)濾算法的美食推薦系統(tǒng)研究 [J].吉林大學(xué)學(xué)報(bào)(信息科學(xué)版),2019,37(2):181-185.
[5] 吳榮,段宏濤.基于Hadoop平臺(tái)的Spark快數(shù)據(jù)推薦算法解析——以其在圖書推薦系統(tǒng)中的應(yīng)用為例 [J].數(shù)字技術(shù)與應(yīng)用,2020,38(6):115-117.
作者簡(jiǎn)介:童瑩(1981—),女,漢族,湖北武漢人,碩士研究生,講師,研究方向:網(wǎng)絡(luò)數(shù)據(jù)庫(kù)。
