安全持久性內存存儲研究綜述
2020-06-08 08:59:42舒繼武
計算機研究與發展 2020年5期
關鍵詞:一致性
楊 帆 李 飛 舒繼武
(清華大學計算機科學與技術系 北京 100084)
持久性內存具有大容量、高性能、低價格的特點,是DRAM潛在的替代品[1-5].持久性內存的出現改變了傳統的內存層級,它可與DRAM同處于內存層次,支持字節粒度的訪問,同時具備外存的非易失性,使得持久性內存存儲成為可能.
持久性內存直接連接到內存總線,會遭受與DRAM相同的惡意攻擊,如內存數據機密性攻擊與完整性攻擊.為了避免內存隱私數據被竊取,基于計數器模式的加密方法(counter mode encryption, CME)被廣泛使用來防范內存數據機密性攻擊[6-8].在CME中,每一個內存塊都與一個獨一無二的計數器相關聯.為了防范內存數據完整性攻擊,通常采用完整性驗證的方法來確保從內存讀取的數據與最近一次寫入的數據相同[7-13];默克爾樹(Merkle tree, MT)被用來確保內存數據的完整性,樹狀結構的消息認證碼(message authenticated code, MAC)構建于整個內存之上,樹根存儲于安全區域內,無法被篡改.
直接將傳統基于DRAM的內存安全保障架構移植到持久性內存之上并不能充分發揮原本內存安全保障架構的性能優勢,甚至還會影響持久性內存系統的可用性,這主要由2個方面導致:
1) 持久性內存的寫特性
由于DRAM具有很高的耐久性,面向傳統DRAM的安全架構未考慮安全保障措施造成過多內存磨損的問題.然而,持久性內存的單元壽命有限,與寫次數有關,對持久性內存加密與完整性驗證會增加寫操作的位翻轉,加劇單元磨損,從而造成壽命降低[14-16].另外,相比于DRAM,持久性內存的寫帶寬更低,而安全元數據(如加密計數器以及完整性驗證樹節點)的寫回會占用數據寫回的帶寬,從而影響應用程序的執行性能.
2) 持久性內存的非易失性
傳統DRAM內存數據在斷電后快速丟失,面向DRAM的安全架構未考慮內存數據的持久性與恢復.持久性內存在斷電后仍能保留數據,斷電后的安全性也需要得到保障;與此同時,持久性內存支持內存數據的快速恢復,重啟之后,對內存數據的機密性與完整性保障需要繼續,即需要保障持久性內存在其整個生命周期內的安全性,而現有內存安全保障架構并不支持這一點.在現有的內存安全架構下,為了提高安全驗證流程性能,頻繁訪問的安全元數據會被緩存到內存控制器內的安全元數據緩存或者最后一級緩存(last level cache, LLC)中[13].斷電會造成緩存中的數據丟失,從而造成數據與安全元數據之間的不一致,主要分為2種:1)持久性內存加密過程中,數據與加密計數器之間出現不一致,異常斷電可能會造成重啟后解密失敗;2)持久性內存完整性驗證過程中,數據與完整性驗證樹之間出現不一致,異常斷電可能會造成重啟后完整性驗證失敗.
嚴格保障數據與安全元數據之間的一致性會帶來高昂的運行時開銷,這是由于:1)數據的寫回會強制相關安全元數據寫回,額外的持久性內存寫操作占據了內存帶寬;2)寫操作需要等待安全流程完成之后才能完成,這增加了寫操作的完成時間,使得CPU寫隊列更易于被填滿,進而影響CPU的執行效率.此外,持久性內存應用會頻繁使用緩存刷寫操作,這些操作將寫操作的延遲置于CPU執行的關鍵路徑之上,從而嚴重影響系統的性能.
系統崩潰恢復時,安全元數據的恢復會嚴重影響系統的可用性.由于持久性內存的容量可達6 TB[1],而安全元數據的內存存儲開銷正比于內存容量,對于大容量的持久性內存而言,恢復安全元數據時間可達數小時,嚴重影響了系統的可用性.
持久性內存在寫特性、非易失性等方面呈現出與傳統DRAM完全不同的特點,直接將現有的內存安全架構部署到持久性內存上并不能完全與持久性內存的特性匹配,也不能充分發揮原本內存安全保障架構的性能優勢,甚至影響系統的可用性.為此,需要結合持久性內存特性,優化加密與完整性驗證流程,同時針對存儲災后一致性問題重新設計硬件邏輯,以實現高效的安全持久性內存存儲.
1 內存安全
在本節中,主要介紹面向DRAM的內存安全架構的相關內容.主要包括威脅模型、內存加密的方法、數據結構及流程,內存完整性驗證的方法、數據結構及流程,內存安全領域的通用優化等.
1.1 威脅模型
在硬件輔助的內存加密與完整性驗證安全系統里,系統資源劃分為安全區與危險區.如圖1所示,安全區稱為可信計算基(trusted computing base, TCB),TCB包括處理器片上資源,主要有CPU寄存器和緩存,可信計算基內的數據無法被竊取與篡改.危險區包括CPU片外所有資源,主要有內存總線以及內存等.
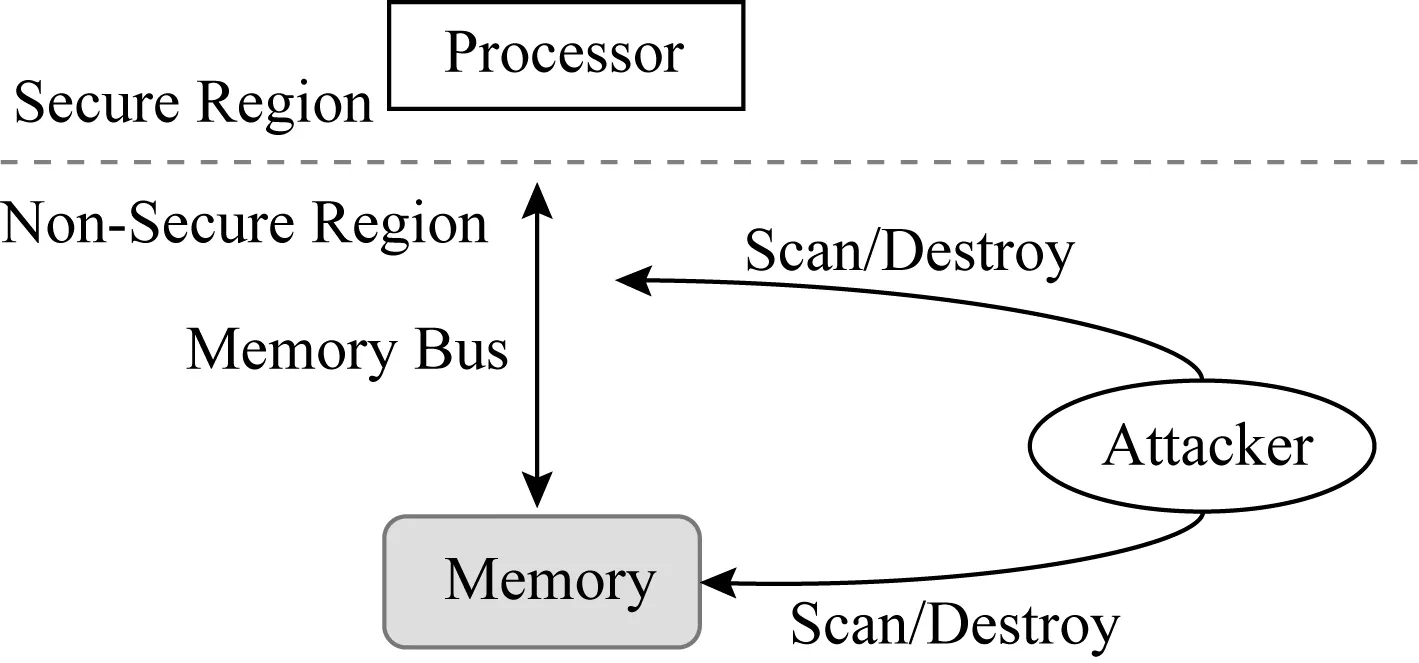
Fig. 1 Threat model[6]圖1 威脅模型[6]
威脅模型里主要包括2種攻擊:1)數據機密性攻擊,指攻擊者可以竊取內存總線及內存里的數據;2)數據完整性攻擊,指攻擊者可以篡改內存總線以及內存中的數據.完整性攻擊分為3類:1)數據欺騙攻擊(data spoofing attack),直接對數據塊進行惡意篡改;2)數據拼接攻擊(data splicing attack),交換2個有效數據塊的內容;3)數據重放攻擊(data replaying attack),將數據塊重放回之前的舊版本.
1.2 內存加密
內存加密的目的是為了確保數據的機密性.任何從LLC替換出去的數據在進入內存總線之前都會被加密.由于內存讀操作處于程序執行的關鍵路徑之上,而解密操作處于內存讀操作的關鍵路徑之上,內存加密會帶來高昂的內存讀操作開銷.CME將解密操作從讀操作的關鍵路徑上剔除,被廣泛應用于內存加密系統中[6-8].圖2展示了數據加密與解密流程,在加密過程中,CME將數據塊與一次性密碼本(one-time pad, OTP)進行異或來產生加密數據.密鑰與初始向量(initialization vector,IV)作為加密模塊的輸入,產生OTP,其中IV由數據塊的地址以及數據塊對應的計數器組成.在解密過程中,當數據塊從內存中讀出時,與加密過程相同的IV會被生成,進而產生相同的OTP,使用與加密過程相同的OTP對數據進行解密.CME的核心在于將內存讀操作與OTP的生成并行化,從而隱藏解密延遲.
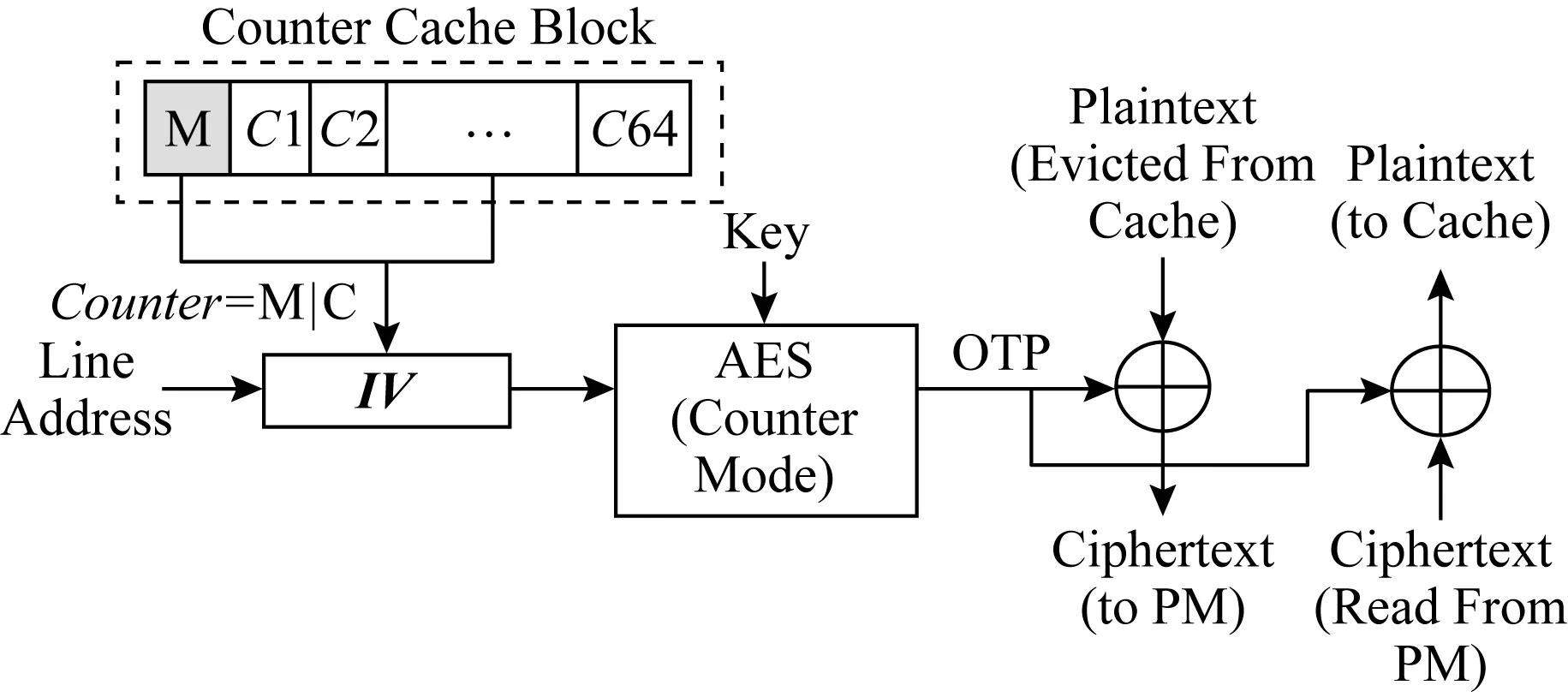
Fig. 2 Counter mode encryption[8]圖2 計數器模式加密[8]
緩存與內存之間的數據傳輸通常是以64 B的粒度進行,因此CME將64 B的內存塊與一個計數器相關聯.目前在學術界廣泛使用的一種計數器組織模式是將計數器分為主計數器與從計數器[7-8],從計數器通常是7 b,與一個64 B的特定內存塊相關聯.主計數器通常是64 b,由4 KB內存頁內的所有64 B內存塊共享.只有當從計數器溢出時,主計數器才會加1,主計數器覆蓋的所有內存塊將被取到安全區進行重新加密.
計數器模式加密的安全性基于一個前提,即每個OTP都不會被重用,這需要保證IV的唯一性,主要包括2方面:1)空間上的唯一性,將不同地址的內存塊映射到不同的計數器;2)時間上的唯一性,對同一內存塊的每次內存寫操作,都將該內存塊對應的從計數器做加1操作.圖2展示了計數器塊的構成,對于一個64 B的計數器塊(counter cache block),它包含64 b的主計數器(M)以及64個7 b的從計數器(C1到C64).
1.3 內存完整性驗證
內存完整性驗證確保從內存中讀取的值與最近寫入內存的值相同.對于內存寫回,計算寫回數據的MAC值并一同寫入內存,在內存數據讀取的過程中驗證其對應的MAC值即可檢測數據欺騙攻擊與數據拼接攻擊.然而基于內存數據構建單層的MAC并不能檢測重放攻擊,攻擊者可以將數據及其對應的MAC值重放回舊的一致版本.默克爾樹被廣泛使用來檢測重放攻擊[8-10],默克爾樹維護以樹狀結構組織的分層MAC,將數據和計數器作為其葉節點,父MAC節點保護多個子MAC節點.圖3展示了一個四叉默克爾樹的結構,任意一個樹內部節點都包含了4個孩子節點的MAC.當內存讀操作發生時,沿默克爾樹自底至上讀取并檢查數據塊的MAC值直至樹根,來驗證所獲取的內存塊的完整性;當發生內存寫操作時,更新樹相應分支節點的MAC值;樹根包含整個內存的信息,存儲在TCB中的寄存器上,無法被攻擊者破壞或重放;上述組織方式,保證了內存數據的完整性.
默克爾樹片上存儲開銷較低,它僅需將根保留在處理器芯片內.但是,默克爾樹構建于整個內存數據之上,其大小正比于內存容量,因此樹節點可能會導致高昂的內存存儲開銷.目前最先進的內存完整性驗證架構是BMT(Bonsai Merkle tree)架構[8],它是基于CME模式構建.如圖4所示,它首先使用單層數據消息身份驗證代碼(data Hash message auth-enticated code, Data HMAC)來檢測欺騙和拼接攻擊,每個Data HMAC是通過將加密的數據塊、計數器及數據塊地址作為輸入生成的散列值.其次,BMT架構基于加密計數器構建默克爾樹來檢測重放攻擊,使用散列函數(如基于SHA-1的HMAC)計算出孩子節點的HMAC值,并將其存入父親節點,HMAC密鑰和BMT樹根存儲在TCB的寄存器里,以防止攻擊者將BMT自頂向下重放.與基于整個內存數據構建MT不同的是,在BMT中,加密的數據塊不直接受到默克爾樹的保護,而計算Data HMAC的輸入則包含受默克爾樹保護的加密計數器,因此能夠檢測到重放攻擊.BMT只基于加密計數器構建默克爾樹,從而減少了樹節點的內存存儲開銷,降低了樹的高度,同時縮短了默克爾樹的驗證時間.

Fig. 3 The structure of Merkle tree[9]圖3 默克爾樹[9]
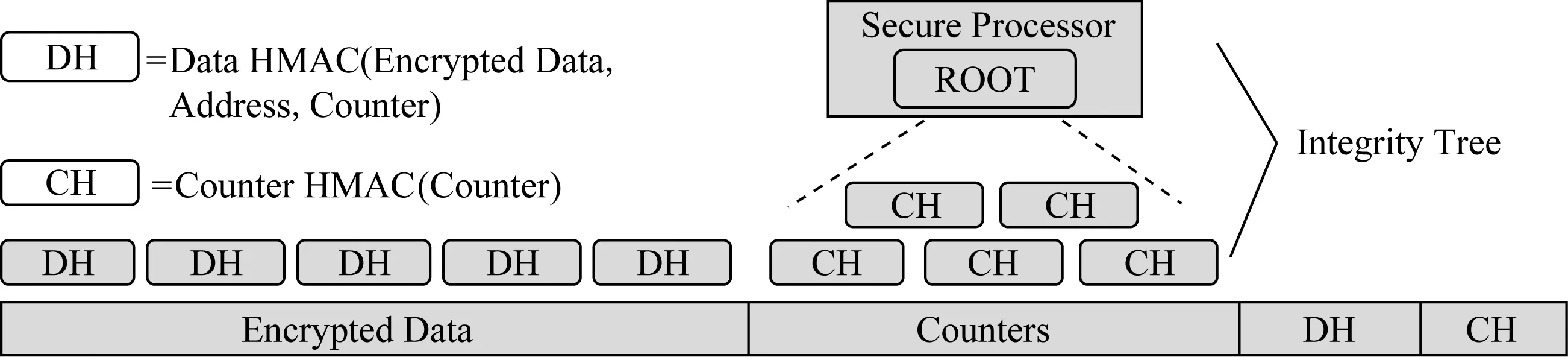
Fig. 4 Overall architecture of BMT[8] 圖4 BMT的總體架構[8]
1.4 緩存安全元數據
緩存安全元數據可以提高CME和BMT的運行性能[8-9,11-13].以內存讀取和解密為例,如果相應的加密計數器已經被緩存,則可以將OTP的生成和內存訪問并行執行,從而隱藏了生成OTP的延遲.對于同一數據頁(4 KB)中不同數據塊(64 B),所有對應的加密計數器均被緩存到同一高速緩存行(64 B)中[8,13],而數據頁中連續數據塊的訪問會命中到相同的計數器緩存行.因此,對于大多數工作負載而言,加密計數器能夠表現出較高的緩存命中率.
默克爾樹中經常訪問和驗證的樹節點被緩存在芯片上[8-9,11-13].一旦在片上高速緩存中找到所需的樹節點,即可完成數據塊的完整性驗證.由于緩存的樹節點已經通過驗證,并且可以確保其在TCB上的安全性,因此可以像樹根一樣信任它.較高層中的樹節點覆蓋更大范圍的內存數據,并具有較高的局部性,樹根保護整個內存.
1.5 安全元數據存儲開銷
安全元數據存儲開銷正比于受保護的內存容量大小.重新設計安全元數據的組織結構[11-12],不僅有利于減少安全元數據的存儲開銷,而且能夠提升安全元數據的緩存命中率,從而加速內存加密與完整性驗證流程.
VAULT[11]通過在每個緩存行大小的樹條目中容納更多計數器來減少完整性驗證樹的深度,從而減少完整性驗證樹的存儲開銷.Morphable Counters[12]探索了加密計數器的訪問模式,增加了每個緩存行大小的節點中容納的計數器數目,根據加密計數器的使用模式動態更改計數器組織方式,降低由于計數器溢出導致的重新加密開銷.
2 持久性內存安全
本節主要介紹由于持久性內存與DRAM不同的寫特性,將傳統內存安全架構構建于持久性內存在內存加密、完整性驗證等方面所面臨的挑戰以及相關的研究工作.
2.1 持久性內存加密與完整性驗證
如何高效處理寫操作是設計持久性內存系統的關鍵挑戰之一.與持久性內存讀相比,持久性內存寫操作不僅延遲更高,且能耗更大,存在耐久性的局限[2-3].內存寫操作往往只有少量的位會被修改[15],持久性內存系統會利用這種特性來優化每次寫操作中寫到持久性內存的位數量.例如持久性內存系統采用一種稱為數據比較寫(data com-parison write, DCW)的技術[4],僅將高速緩存行中的修改位寫入持久性內存介質中.如果超過一半的位被修改,則通過翻轉數據位,進一步減少對持久性內存介質的位寫操作,這種方式被稱為FNW[5](flip-n-write).FNW將每次寫操作的比特翻轉位數限制為緩存行位數的一半.通過這些優化,每次寫入存儲器的平均位數減少到僅10%~15%.鑒于持久性內存低于DRAM的寫性能和有限的耐久性,這些減少比特翻轉的方法對于實現持久性內存高性能和高耐久性至關重要.
由于持久性內存耐久性及其寫操作的特性,針對持久性內存進行加密與完整性驗證會帶來一些新的挑戰,主要分為2個方面:
1) 持久性內存加密帶來的挑戰
理想的加密算法都遵循雪崩效應[14],即使輸入數據中只有1 b的改變也會導致加密數據中一半位被改變.盡管雪崩特性對于提供安全性至關重要,但它導致每次寫入持久性內存中的位數大致為緩存行位數的50%.如圖5所示,其中寫操作僅修改1 b,當進行加密操作時,2個加密值之間的位差異可能是緩存行位數的一半.因此,加密將導致寫入持久性內存的位數過多,從而使諸如DCW和FNW之類的優化失效,比特翻轉的增多也會進一步造成更高的能耗.同時,基于持久性內存的應用會有頻繁的刷寫緩存行操作,這類操作會加速從加密計數器的溢出,當從計數器溢出時,需要重新將總量為4 KB的數據讀進安全區,重新解密后加密再寫回內存,造成運行時停滯.因此,需要針對持久性內存的寫特性設計實現低寫開銷的加密模式.
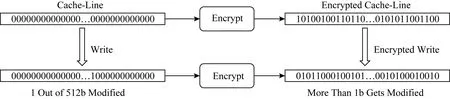
Fig. 5 Encryption incurs an increase in the number of bit flips for write operations圖5 加密造成寫操作的位翻轉增多[15]
2) 持久性內存完整性驗證帶來的挑戰
完整性驗證樹會增加額外的內存寫操作,主要包含數據散列消息認證碼和計數器散列消息認證碼.其次,數據細微位變化可能造成其生成的散列消息認證碼的大量位修改,從而增加散列值的比特翻轉.最后,持久性內存容量過大,將導致完整性驗證樹層級過高,加速內存帶寬消耗,而持久性內存帶寬遠低于內存,從而出現帶寬資源瓶頸.因此,需要針對持久性內存的寫特性設計實現高性能、低寫開銷的完整性驗證模式.
2.2 相關工作
主要介紹3類相關工作:1)減少持久性內存加密場景下的寫開銷;2)減少持久性內存完整性驗證過程的寫操作、能耗、內存訪問等開銷;3)降低加密流程中計數器的溢出頻率.
1) 減少加密場景下的寫開銷
DEUCE[15]是佐治亞理工學院于2015年提出的針對持久性內存的加密模式.對于一個緩存行內的大部分字(word)而言,寫操作并不會修改它們,對此未修改部分不需要重新加密,只需要對修改部分的word重加密即可.基于這個想法,DEUCE提出細粒度的加密模式,針對緩存行里修改的word,DEUCE使用更新的加密計數器對其重新加密.解密階段,對修改的word使用更新的加密計數器進行解密,對于未修改的word使用原本的加密計數器進行解密.
DEUCE加密模式采用了雙計數器的加密方式.首先以word為粒度,對每一個緩存行內的word記錄一個修改標志位;其次定義2個虛擬加密計數器LCTR(leading counter)和TCTR(trailing counter),其中LCTR值始終保持最新,通過屏蔽LCTR的幾個最低有效比特(least significant bits, LSBs)來獲取TCTR的值.若屏蔽2個LSB,則每4次寫操作將更新TCTR使之與LCTR相同,這段期間稱為期間間隔(epoch interval).在一段期間間隔內,TCTR值保持不變,LCTR值則正常更新.
對于寫操作,在一個期間間隔內至少修改了一次的word,使用LCTR進行加密,未修改的word則使用TCTR進行加密.因此,對于未修改的word而言,其加密后的數據仍然保持不變.當TCTR與LCTR值相同時,重置緩存行中的所有修改標志位,并對整個緩存行重新加密.
對于讀操作,如圖6所示,DEUCE會維護2個OTP,分別由LCTR與TCTR生成,修改標志位(modified bit)決定解密word采用哪一個OTP,只有在期間間隔內至少修改一次的word才會使用OTP-LCTR進行解密,否則使用OTP-TCTR進行解密.
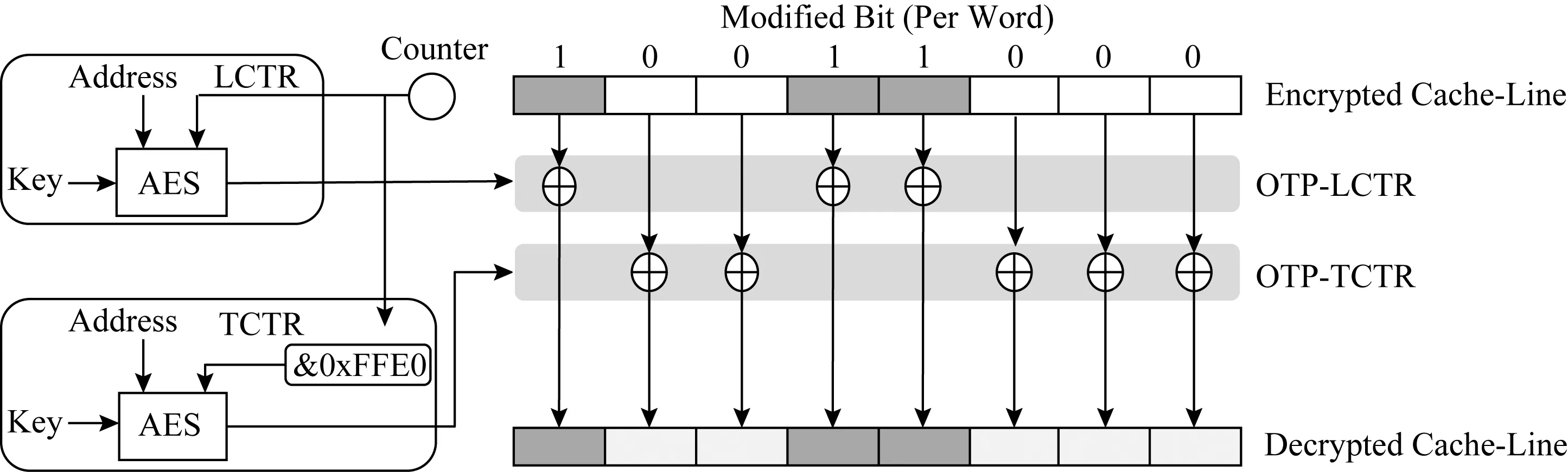
Fig. 6 Decryption of DEUCE[15]圖6 DEUCE解密操作[15]
SECRET[16]是匹茲堡大學于2016年提出的針對持久性內存的細粒度、低功耗的加密模式.與DEUCE思想類似,SECRET只對修改的word進行重新加密,此外,針對word的全0寫,SECRET保持其最近的加密狀態,避免對全0寫操作的重加密開銷,進一步減少了寫操作比特翻轉數量.
SECRET加密模式提出word粒度的加密模式,通過為每一個緩存行提供一個全局加密計數器,同時為緩存行中每一個word提供一個本地計數器(local counter, LC).當LC溢出時,將該緩存行對應的所有LC置0,同時將對應的全局加密計數器加1,對此緩存行重新加密.SECRET加密模式為每一個word提供1 b的zero-flag,用來記錄word的狀態,當word為全0寫時,將對應的zero-flag置1,同時在寫回過程中,將word以其先前的加密狀態保留在持久性內存中.如圖7所示,Word1與Word3被修改,因此其對應的LC自增1,Word2未被修改,因此其對應的密文保持不變.對于Word3而言,由于其為全0寫,因此將對應的zero-flag置零,保持其密文不變.
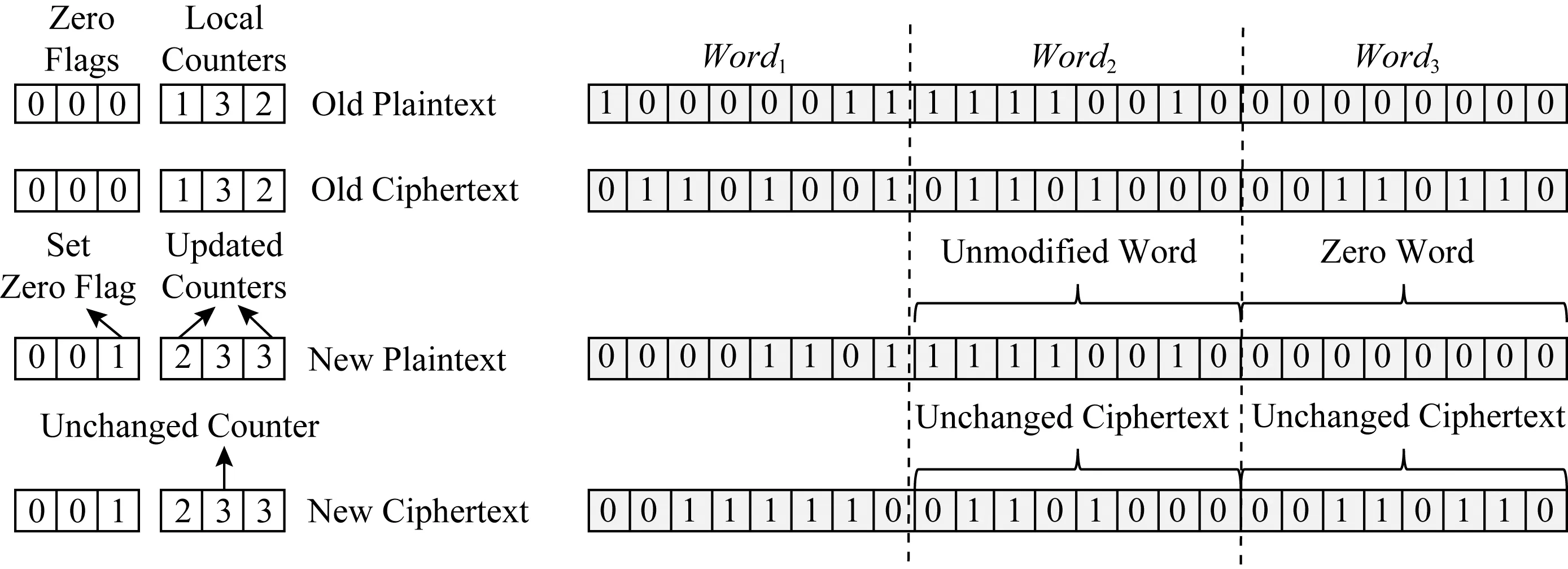
Fig. 7 Encryption of SECRET[16]圖7 SECRET加密操作[16]
SECRET加密模式還進一步研究了由于加密造成的能耗開銷.對于持久性內存單元而言,不同模式的翻轉造成的能耗不同(比如單元從01到10的能耗與00到01的能耗不同[17]).針對每一個加密寫操作,SECRET加密模式將其與3種掩碼進行異或,計算3種異或之后寫操作的能耗,并選擇能耗最低的作為最終數據寫入持久性內存,從而降低寫操作的能耗.
上述工作提出的技術為位級別的持久性內存寫減少技術,旨在減少內存加密中,寫操作造成的位翻轉數目.下述工作將內存加密應用于特定場景,如data shredding,或與其他存儲技術相結合,如data deduplication,旨在減少持久性內存寫次數.
Silent Shredder[18]是惠普實驗室于2016年提出的持久性內存寫減少技術.為了避免進程之間的數據泄漏,在將進程的內存頁分配給另一個進程之前將其清零(data shredding).Silent shredder技術利用計數器模式加密中使用的初始向量IV,在進行數據清除時修改對應內存頁面的IV,從而避免了對持久性內存頁面的寫操作.
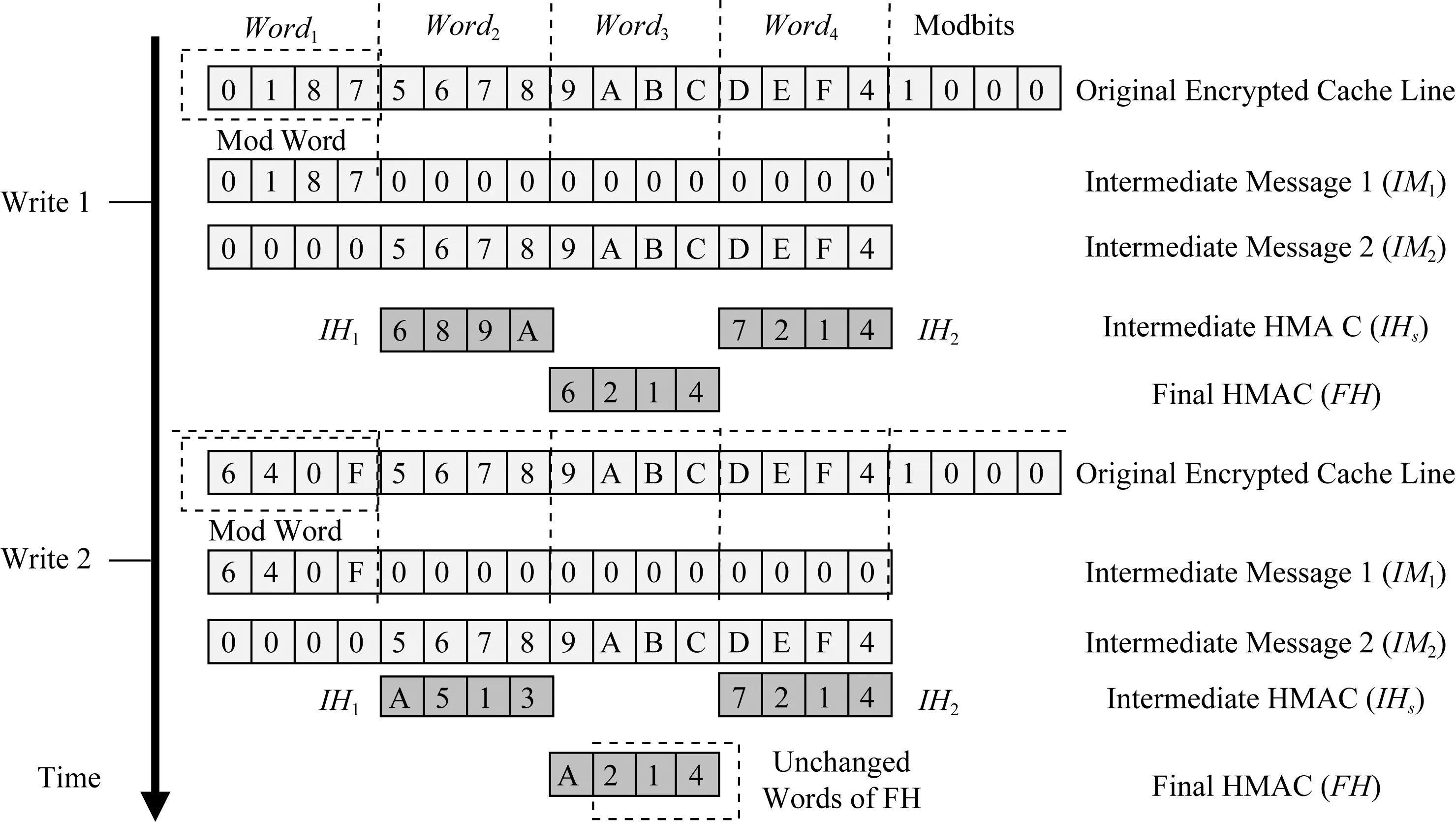
Fig. 8 The MAC computation of ASSURE[20]圖8 ASSURE中MAC值的計算操作[20]
DeWrite[19]是華中科技大學于2018年提出的針對持久性內存加密的寫減少技術.DeWrite將加密和高效的重復數據刪除(data deduplication)集成到持久性內存系統中,對重復數據刪除元數據和加密元數據進行協同設計,減少了加密計數器的空間開銷;此外,將加密與重復數據刪除操作并行執行,進一步提升性能.
2) 減少完整性驗證過程的開銷
ASSURE[20]是匹茲堡大學于2017年提出的針對持久性內存的低寫開銷的完整性驗證模式.與細粒度的持久性內存加密模式思想類似,ASSURE完整性驗證模式采用基于細粒度的加密,采取word粒度的完整性驗證,只對修改的部分做散列,未修改部分填充0,并將得到的結果合并.這種方法減少由于散列擴散(少量數據位修改造成其對應散列值的大量位變化)造成的額外寫操作比特翻轉.
ASSURE完整性驗證模式將原始的加密緩存行拆分為2個中間消息(intermediate message, IM).IM具有與緩存行相同的長度和分區邊界.第1個(第2個)IM,IM1(IM2)由修改(未修改)的word構成,未修改(修改)的word清0.然后將IM1(IM2)作為輸入提供給散列函數,生成中間HMACIH1(IH2).與IM相似,IH也按word粒度進行分區.最終的HMAC(final HMAC, FH)由IH1和IH2對應的word構成.如圖8所示,對于2次寫操作,只有Word1被修改,首先設置修改標志位,未修改部分置0,生成IM1,類似地將修改部分置0,生成IM2,分別將IM1和IM2作為散列函數輸入,得到各自的IH后,整合得到FH.由于2次寫操作只修改了Word1,因此2次寫操作對應的FH只修改了Word1對應的區域,從而減少了散列函數造成的比特翻轉.
ASSURE完整性驗證模式還進一步研究如何減少完整性驗證的內存訪問開銷,提出了雙根默克爾樹,基于數據的冷熱程度構造完整性驗證樹,通過統計各個MT組的訪問數量,決定下一個CPU執行期間的冷熱分組,從而將MT分成更少樹層級的熱組與更多樹層級的冷組.由于基于熱數據構建的完整性驗證樹的層級遠小于基于整個持久性內存構建的完整性驗證樹,從而降低熱數據的完整性驗證開銷.
3) 降低加密計數器的溢出頻率
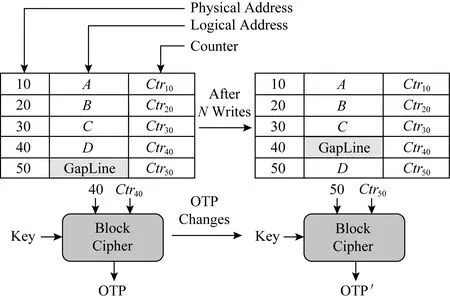
Fig. 9 The impact of wear-leveling on counter mode encryption in ACME[21]圖9 ACME中磨損均衡對計數器模式加密的影響[21]
ACME[21]是匹茲堡大學于2018年提出的持久性內存加密模式,利用持久性內存磨損均衡算法來降低加密計數器的溢出頻率.ACME加密模式采用了region-based start-gap磨損均衡算法.如圖9所示,首先將加密計數器與其對應的物理地址一一綁定,當對某一個邏輯地址的更新達到指定次數時,觸發磨損均衡算法,從而將該邏輯地址映射到其他物理地址上,如圖9所示,邏輯地址D對應的物理地址從40重新映射至50.觸發磨損均衡后,邏輯地址對應的加密計數器也將發生改變,此方法將部分加密計數器的頻繁更新均攤到整個區域內的計數器上,減少了加密計數器的溢出頻率.
3 安全持久性內存一致性
第2節主要介紹了構建安全持久性內存時,減少寫操作開銷的一系列工作,這些工作未考慮持久性內存的非易失性.本節主要介紹由于持久性內存的非易失性,將傳統內存安全架構構建于持久性內存之上所面臨的挑戰,主要包括:安全持久性內存災后一致性的起因、持久性內存加密中的災后一致性問題及相關工作、持久性內存完整性驗證中的災后一致性問題及其相關工作、安全持久性內存災后恢復方法.
3.1 安全持久性內存災后一致性起因
傳統DRAM具有易失性,斷電后內存數據會丟失.持久性內存具有非易失性,斷電后數據仍然保留,因此攻擊者能夠直接獲取斷電后內存里的數據.除此之外,要想在系統重啟之后能夠持續正確地進行安全保障,就需要保證安全元數據與數據之間的一致性,包括2個方面:1)數據與加密元數據之間的一致性,若不一致會導致解密失敗;2)數據與完整性驗證元數據之間的一致性,若數據與其散列消息認證碼不一致,則數據完整性驗證不通過.因此,要保障持久性內存在其生命周期內的安全性,必須保障安全持久性內存的災后一致性.
3.2 持久性內存加密中的災后一致性
圖10展示了系統故障可能導致的數據和加密計數器不一致的情況.對持久性內存的每次寫訪問均包含2個單獨的寫請求,一個寫請求作用于加密數據,另一個寫作用于加密計數器.如果在數據寫到達持久性內存之后且在計數器寫入之前發生系統故障,則在系統重啟時將觀察到滯后的加密計數器值,從而導致原始數據丟失,如圖10(a)所示.如果加密計數器到達持久性內存后發生故障,但數據尚未持久化,也會發生類似的不一致情況,如圖10(b)所示.
要保障持久性內存加密的災后一致性,主要面臨了2個挑戰:1)如何保障數據與其對應加密計數器的原子寫回;2)如何減少由于保障原子性帶來的開銷,主要包括2個方面:1)寫放大,數據的寫回會造成額外的加密計數器寫回;2)性能開銷,原子性保障會增加寫操作的延遲,而寫操作延遲增加會導致CPU寫隊列阻塞頻率上升,進而影響CPU執行時間.此外,基于持久性內存的應用會使用緩存刷寫指令(如clwb,mfence等),該指令將寫操作置于CPU執行關鍵路徑之上,如圖11所示,在非加密情況下,寫回操作到內存控制器即可完成,而在加密情況下,寫回操作必須等待加密災后一致性保障完成之后才能返回,這增長了寫操作的關鍵路徑,從而影響了系統性能[23].
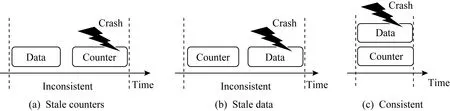
Fig. 10 Crash consistency in encrypted persistent memory[22]圖10 持久性內存加密中的災后一致性[22]
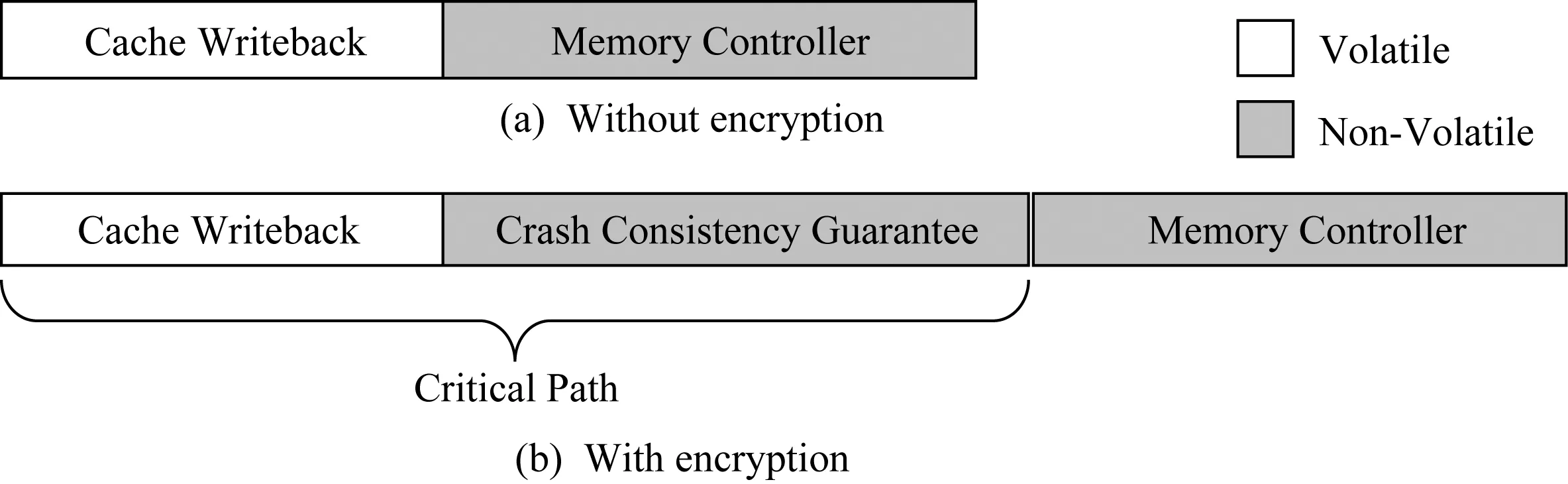
Fig. 11 Write latency with and without encryption 圖11 加密與非加密情況下的寫延遲
SCA[22](selective counter-atomicity)是弗吉尼亞大學在2018年提出的針對持久性內存加密的一致性保障機制.SCA機制在內存控制器中增加額外的寫隊列來存儲加密計數器,數據發往內存控制器中的數據寫隊列,計數器被發往計數器寫隊列.Intel提供的硬件異步DRAM自刷新(asynchronous DRAM refresh, ADR)機制可確保在電源故障的情況下,使用備用電源將緩存在內存控制器寫隊列中的所有寫請求寫回到持久性內存.通過擴展ADR機制,使其支持數據寫隊列和計數器寫隊列,并確保在電源故障時,只有在寫隊列中同時包含數據和相關計數器的條目才能寫回持久性內存.為了跟蹤數據及其計數器,SCA機制向每個數據寫隊列和計數器寫隊列條目添加了一個額外的就緒位.僅當相應的寫隊列已接受數據和計數器寫時,才設置2個寫隊列中的就緒位.為避免系統故障影響設置2個寫隊列的就緒位的原子性,該操作還受到ADR機制的保護.
SCA機制提出的原子寫入包括3個步驟:1)內存控制器將加密的數據發送到數據寫隊列,同時,加密引擎將關聯的計數器緩存行發送到計數器寫隊列.2)當數據寫到達數據寫隊列時,內存控制器檢查計數器寫隊列是否具有關聯的計數器條目.如果是,則將2個條目中的就緒位都設置為1.否則,就緒位保持為0.當計數器到達計數器寫隊列時,內存控制器執行相同的步驟.3)2個寫隊列僅放行設置了就緒位的條目,所有未就緒的條目將保持阻塞狀態,直到其就緒位被置位.在系統故障期間,2個寫隊列僅將就緒條目寫入持久性內存中.
圖12展示了counter-atomicity寫一個物理地址0X100的流程.步驟①處理器對地址0X100發出counter-atomicity的寫請求,持久性內存協調器(步驟②)以及加密引擎(步驟③)會收到這個請求.步驟④若0X100地址對應的計數器(地址0X200)緩存命中,則加密引擎更新相應計數器,生成OTP,同時將最新的計數器發送至計數器寫隊列.步驟⑤持久性內存協調器將數據與OTP異或,將生成的密文發送至數據寫隊列.步驟⑥數據寫隊列接收到數據后檢查相應的計數器寫隊列,由于在計數器寫隊列中未找到對應的計數器條目,因此其就緒位置0.步驟⑦計數器寫隊列接收到計數器條目,同時檢查數據寫隊列中是否有相應的數據條目.步驟⑧由于此時數據和相應計數器都處于對應的寫隊列中,內存控制器將條目設置為就緒,寫操作完成.
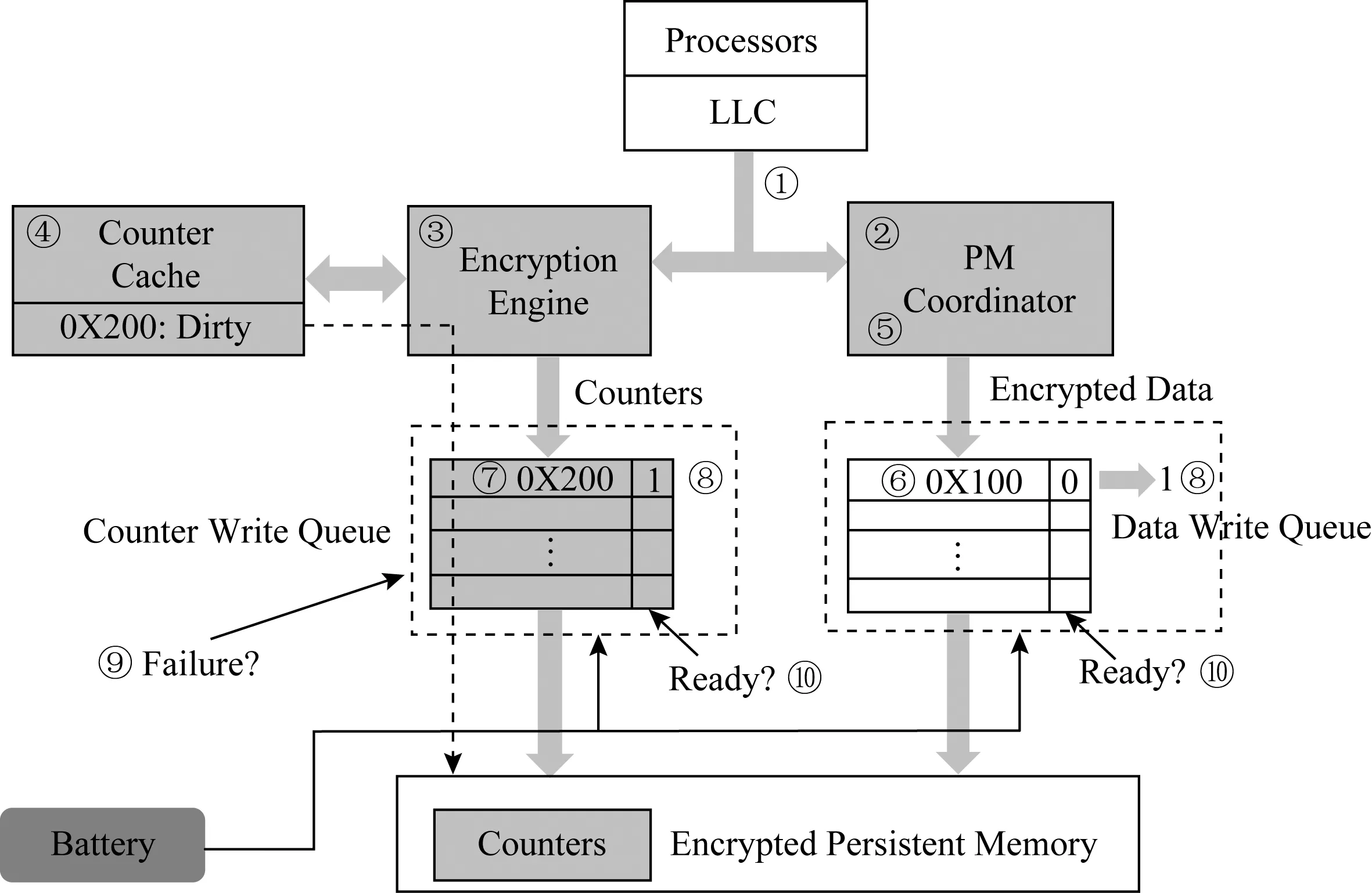
Fig. 12 Counter-atomicity write process in SCA[22]圖12 SCA中counter-atomicity寫操作流程[22]
在系統崩潰時,步驟⑨觸發ADR機制,計數器與數據寫隊列開始寫回滯留在隊列中的條目.步驟⑩寫隊列檢查就緒位,并只寫回就緒位置1的條目,確保數據與相應計數器在內存中的一致性.
SCA機制還充分利用事務語義,結合事務語義降低counter-atomicity導致的開銷.基于持久性內存的應用程序通常采用事務接口來保障數據的災后一致性.例如使用撤消日志記錄或者重做日志記錄,日志記錄保證了即使在更新期間出現故障,也可以恢復數據的一致狀態[24-26].所有這些機制都通過維護2個版本的數據來確保災后一致性.例如,日志記錄機制在日志中維護一個版本,在原始數據結構中維護另一個版本,并確保在任意時間點僅修改其中一個版本.在修改其中一個版本時,如果發生任何崩潰,則利用另一個未修改版本恢復一致狀態.由于已經修改的數據版本在恢復中不起作用,因此不需要針對這個版本嚴格保障數據與其加密計數器之間的一致性.以基于重做日志的事務為例,執行分為3個階段:1)準備階段,創建日志項,對數據進行備份;2)修改階段,對數據進行就地修改,由于備份中已經存在數據一致性的版本,因此對數據的修改并不會影響數據的可恢復性;3)提交階段,數據修改完成后,使在準備階段創建的備份日志條目無效,并將新的修改狀態標記為當前一致狀態.
表1展示了事務執行不同階段是否需要嚴格保障數據與其對應加密計數器的一致性.在準備階段,通過修改日志來創建數據的備份,因此日志不能用于一致恢復,而原始數據未經修改,處于一致性的狀態.在準備階段,修改日志并不會影響數據的可恢復性,因此不需要嚴格執行counter-atomicity.同樣,在修改階段,日志中的備份副本是一致的,可以用于將數據恢復至一致的版本.因此,在修改階段,對數據的寫操作不會影響數據的可恢復性,也不需要嚴格執行counter-atomicity.另一方面,在提交階段的寫入會使備份日志條目無效.提交階段將一致狀態從日志切換到已修改的數據,由于此階段的寫操作會標記在事務恢復過程中應該使用日志還是數據,因此會影響崩潰后數據的一致性狀態,所以此階段的寫操作必須嚴格執行counter-atomicity,否則在恢復過程中可能使用錯誤的版本.需要注意的是,在從一個階段轉換到另一個階段之前,需要保證數據與其計數器之間的一致性,將相關的計數器從緩存刷寫回持久性內存.SCA機制通過結合事務特性,在不影響災后一致性的前提下,僅對一部分寫操作強制執行counter-atomicity,提高了事務系統的性能.
Table 1 The Consistency States Affecting Counter-atomicity in Different Stages of a Transaction with Undo-logging[22]

表1 重做日志事務中不同階段的一致性狀態對counter-atomicity的影響[22]
Osiris[27]是中佛羅里達大學在2018年提出的針對持久性內存加密的一致性保障機制.它使用糾錯碼(error correction code, ECC)來檢測滯后的加密計數器,在系統恢復期間將加密計數器恢復至與數據一致的版本,從而放松系統運行時數據與加密計數器的原子性保障.當將ECC應用于明文并且將得到的ECC位與數據一起加密時,ECC位可以為加密計數器提供完整性檢查,若計數器值與數據不匹配,則解密后明文數據會與其ECC位不匹配.
具體而言,在計數器模式的加解密中,使用方法解密數據:{X,Z}=Ekey(VX)?Y,其中Y是密文,VX是X對應的IV,Ekey(VX)對VX利用key進行加密,Z則是由FECC(X)計算得來.在常規系統中,若FECC(X)!=Z,可認為X或Z發生錯誤;在計數器模式的加解密中,還可能是解密過程使用了滯后的計數器.
在運行過程中,Osiris架構部署了止損機制,當一個計數器緩存行更新N次時,將其寫回持久性內存.因此在恢復過程中,可嘗試使用所有可能的N種IV解密數據,與數據匹配的IV將在[VX+1,VX+N]范圍中,其中VX是存儲在持久性內存中的滯后IV.在VX成功解密該塊時停止,即所得的ECC值與預期的ECC匹配(FECC(X)=Z),恢復出一致的計數器數據.
SuperMem[28]是華中科技大學在2019年提出的針對持久性內存加密的一致性保障機制,采用了write-through的加密計數器緩存,每次更新計數器的同時,將計數器寫回內存控制器的寫隊列中,還修改了緩存刷新指令,增加額外的寄存器,以保障數據寫與計數器寫之間的原子性.如圖13所示,在CPU發出刷新指令Flu(A)時,內存控制器首先從緩存中讀取地址A對應的計數器(Read(Ac)),然后增加計數器值(Ac++),使用更新后的計數器來加密地址A對應的數據(Enc(A)),同時將相關的計數器存儲到寄存器中(Sto(Ac));加密完數據之后,將密文添加到寄存器中(Sto(A)),最后將密文與對應計數器添加到寫隊列中(App(Ac+A));由于ADR機制的支持,寫隊列中的條目最終會寫回持久性內存,因此始終保障了持久性內存中數據及其對應的計數器之間的一致性.

Fig. 13 The sequence that the memory controller deals with a cache line flush in SuperMem[28]圖13 SuperMem里緩存刷新指令的流程[28]
由于每次數據寫操作會導致額外的計數器寫,SuperMem機制提出計數器寫合并優化.在基于計數器的加密模式中,相鄰64個64 B的內存塊數據對應同一個64 B的計數器緩存行.基于此,當從計數器緩存中逐出的計數器緩存行到達內存控制器寫隊列時,檢查寫隊列中的寫條目是否具有與新到達緩存行相同的物理地址.如果是,則將這些緩存行合并為一次寫操作,減少計數器寫次數.進一步地,SuperMem機制還探索了計數器在bank級別的并行性,通過將數據及其計數器分散到不同的內存bank中,加速數據與計數器的寫入,從而提升系統性能.
cc-NVM[29]是清華大學在2019年提出的面向安全持久性內存的一致性保障架構.針對加密計數器的一致性保障問題,cc-NVM架構在運行時并不對每次寫操作都嚴格保障數據與其對應加密計數器的原子性,相反地,cc-NVM架構采用write-back的安全元數據緩存寫回策略,充分利用了安全元數據緩存.
cc-NVM架構利用BMT中現有的數據散列消息認證碼來檢測數據與其加密計數器之間的一致性,在異常崩潰后,通過數據散列消息認證碼使斷電造成的不一致的數據與加密計數器恢復一致,從而減少了運行時加密計數器寫開銷與保障持久性內存加密一致性的性能開銷.
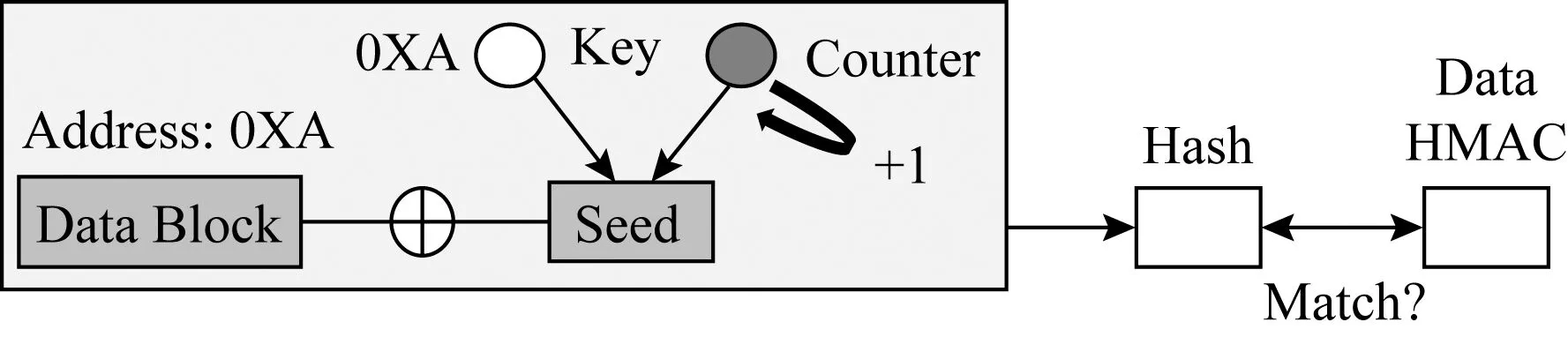
Fig. 14 The process of counter recovery in cc-NVM[29]圖14 cc-NVM架構中恢復計數器的流程[29]
數據散列消息認證碼的計算為Data HMAC=Hash(address,data,counter),在恢復過程中,首先計算崩潰后的數據與其加密計數器的散列值,將散列值與內存中存在的散列值比較,若相同,則數據與計數器一致;若不同,則計數器增1后繼續比較,流程如圖14所示:
3.3 持久性內存完整性驗證中的災后一致性
相比于持久性內存加密而言,持久性內存完整性驗證樹的一致性保障更為復雜.為了保障異常斷電重啟后,完整性驗證能夠正確執行,運行時完整性驗證樹的更新需要更新至樹根,主要流程為:數據寫回會修改其對應的加密計數器(BMT葉子節點),加密計數器的修改會導致重新計算其散列值并存入父親節點,依次計算散列值直至更新至根節點,其中根節點使用持久性寄存器存儲于TCB區域.因此,每一次數據內存寫都包含一個數據寫及一系列直至根節點的安全元數據寫操作.
圖15展示了系統故障可能導致的數據和完整性驗證樹的不一致.若分支上的所有樹節點未能同時抵達持久性內存,任意一個樹節點出現滯后,都會造成樹本身的不一致,即崩潰重啟后無法正確進行完整性驗證,如圖15(a)所示.另外,由于樹根節點處于安全區域,而樹內部節點和葉子節點處于非安全區.TCB區的根與持久性內存中的樹節點未能原子更新也會造成不一致現象,如圖15(b)所示.

Fig. 16 Write latency with and without integrity authentication 圖16 完整性驗證與沒有完整性驗證情況下的寫延遲
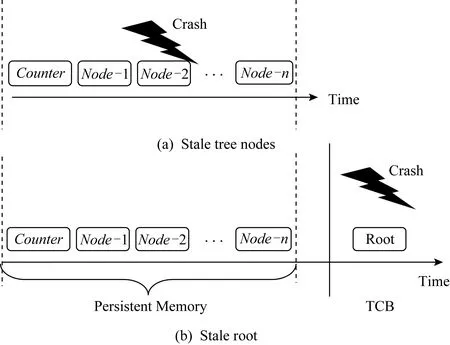
Fig. 15 Crash consistency in authenticated persistent memory圖15 持久性內存完整性驗證中的災后一致性
保障持久性內存完整性驗證的災后一致性,主要面臨2個挑戰:
1) 如何保障數據及其對應的一系列樹節點的原子寫回.由于樹根存儲于安全區,而其他樹節點存儲于非安全區,因此該一致性保障主要包括2個方面:①數據與樹相應分支上的所有非根節點之間的一致性;②樹根與其他樹節點跨區域之間的一致性.
2) 如何減少由于保障原子性帶來的開銷,主要包括2個方面:①寫放大,數據的寫回會造成額外的一系列樹節點的寫回;②性能開銷,原子性保障會增加寫操作的延遲,由于樹節點的更新是自底向上依次進行的,其造成的寫延遲正比于樹層級,而寫操作延遲增加會使得CPU寫隊列阻塞頻率增加,進而影響CPU執行時間.不僅如此,基于持久性內存的應用會使用緩存刷寫指令(如clwb,mfence等),該指令將寫操作置于CPU執行關鍵路徑之上,寫操作延遲的增加進一步降低了系統性能.如圖16(a)所示,在沒有完整性驗證情況下,寫回操作到內存控制器即可完成.然而,在完整性驗證情況下,圖16(b)所示,寫回操作必須等待一致性保障完成之后,即樹根更新之后才能返回,這極大增長了寫操作的關鍵路徑,影響系統性能[23].
嚴格更新策略被廣泛應用于持久性內存完整性驗證的災后一致性保障中[27,30-32].對于嚴格更新策略,任意數據寫回內存,都會從完整性驗證樹的葉子節點更新至樹根.通過利用持久性寄存器,保障數據、葉子節點和樹根的原子性更新,而不考慮樹的內部節點.如圖17所示,首先將數據(步驟①)、葉子節點(步驟②)以及樹根(步驟④)的更新值全部保留在持久性寄存器中,然后將寄存器中的值依次拷貝到內存控制器的寫隊列(步驟⑥⑦).引入DONE_BIT作為原子性更新流程中的分界線,僅在數據、計數器以及樹根的更新寫入持久性寄存器后設置DONE_BIT(步驟⑤),并在所有持久性寄存器值復制到內存控制器的寫隊列,以及更新完TCB中的樹根之后清除DONE_BIT(步驟⑨).這種方案在本質上類似于重做日志記錄,通過使用片上持久性寄存器來存儲數據的一致性的版本.
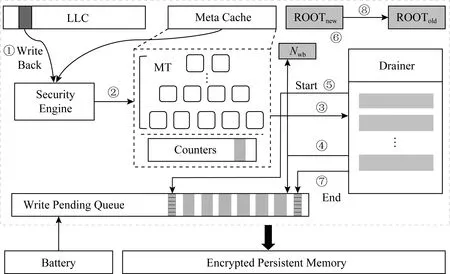
Fig. 18 Overall architecture of cc-NVM[29] 圖18 cc-NVM架構的總體結構[29]
在崩潰后恢復時,利用葉子節點恢復樹根,然后將其與安全區內存儲的持久性樹根做比較,若相同則恢復成功.這種完整性驗證的一致性保障主要存在2個缺陷:1)每次內存寫操作,必須等待完整性驗證樹更新至樹根節點,而父節點必須等待其子節點的散列值計算完成才能繼續向上計算,因此會造成極高的寫延遲;2)由于一致性保障未考慮內部節點,一旦恢復失敗,由于無法定位出錯數據塊,任意數據塊的損壞都會造成整個持久性內存數據丟棄,引起單點故障問題.中佛羅里達大學2019年在Triad-NVM[31]中提出增加持久性寄存器來存儲樹分支上的所有樹節點來避免單點故障問題(改變圖17的步驟③⑧),然而這種方式仍會引起極高的寫放大,并且未解決寫延遲高的問題.
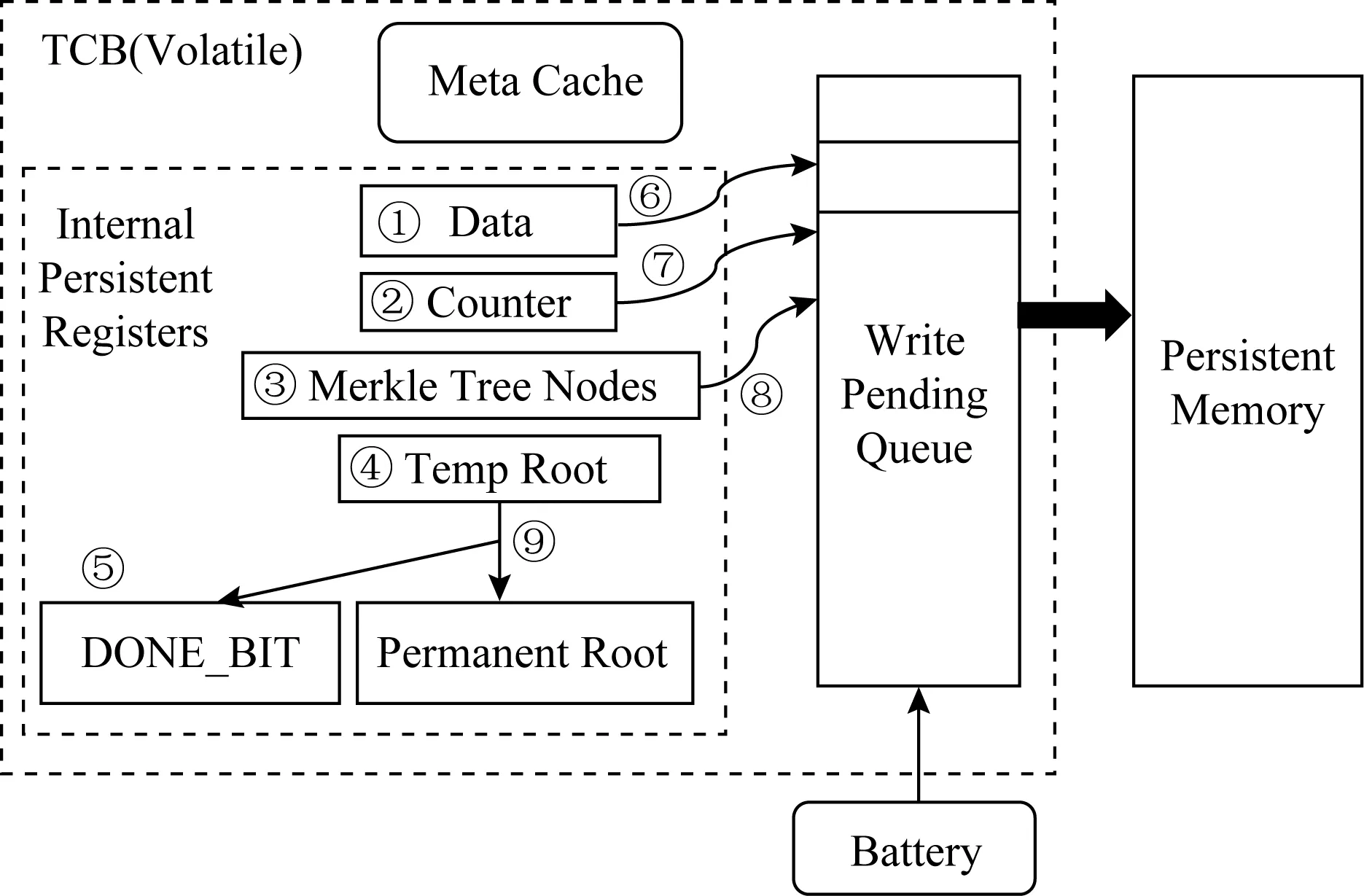
Fig. 17 Process of consistency guarantee based on strict updating strategy in BMT[32]圖17 BMT中基于嚴格更新策略的一致性保障流程[32]
清華大學在2019年提出的cc -NVM架構[29]利用內存控制器中的持久性區域(寫隊列)進行原子性保障,并采用懶惰更新的完整性驗證樹更新策略,降低運行時的完整性驗證一致性保障開銷.
cc-NVM架構采用延遲蔓延的BMT更新策略,通過引入記錄一段時期寫回次數的持久性寄存器Nwb,使得每次更新只更新至緩存的樹節點,而不更新至樹根,極大減小了寫操作延遲.如圖18所示,正常數據寫回流程為步驟①~④.為了保障完整性驗證樹的一致性更新,cc-NVM架構引入基于Epoch的安全元數據更新方式,通過利用內存控制器內的持久性區域保障一個Epoch內所有臟安全元數據的原子性轉換,在轉換開始時內存控制器寫隊列阻塞所有安全元數據(步驟⑤),在原子性轉換過程中將更新從葉子節點蔓延至樹根ROOTnew(步驟⑥),當所有臟元數據抵達寫隊列后,寫隊列放行安全元數據寫操作(步驟⑦).由于ADR機制的保障,寫隊列中的條目在步驟⑦之后一定能夠寫入持久性內存,因此保障了系列樹節點的原子性更新.同時,cc-NVM架構采用雙根的方式保障2個區域(可信計算基與持久性內存)數據的一致性,在原子性轉換的最后,將ROOTnew賦值給ROOTold(步驟⑧),從而始終保證至少有一個樹根與持久性內存中的完整性驗證樹一致.由于cc-NVM架構考慮了樹內部節點的一致性,因此避免了出現單點故障,但破壞原子轉換期間修改的數據,仍會造成部分內存數據的丟失.
3.4 安全持久性內存災后恢復
第3.2節和第3.3節工作主要是安全持久性內存的運行時優化,本節主要介紹安全持久性內存的恢復機制.持久性內存安全存儲系統的恢復過程主要分2個步驟[27,32]:1)掃描整個內存數據,恢復加密計數器至最新值;2)掃描整個加密計數器,恢復完整性驗證樹結構.由于持久性內存容量可達到TB級[1],且安全元數據量極大,1TB的持久性數據對應了16 GB的加密計數器,以及基于16 GB計數器構建的完整性驗證樹,恢復安全元數據(加密計數器,完整性驗證樹)時長可達數小時[32],從而導致掃描內存數據、加/解密與散列計算開銷極高.
Triad-NVM機制[31]通過嚴格持久化默克爾樹的低N層來減少恢復時長同時減少寫開銷,其目標是在恢復時間和性能之間進行權衡.
Anubis[32]是中佛羅里達大學于2019年提出的針對安全持久性內存存儲系統的快速恢復機制.Anubis機制通過在持久性內存中記錄臟安全元數據的地址以實現災后快速恢復.針對BMT提出相應的快速恢復機制AGIT(Anubis for general integrity tree),在運行時,對任何數據寫,需要同時將其對應安全元數據的地址寫回持久性內存中.針對Intel SGX(Intel software guard extensions)integrity tree,提出ASIT(Anubis for SGX integrity tree),對任何數據寫,需要將其對應安全元數據的地址以及臟元數據寫回持久性內存中.在恢復過程只恢復記錄的地址對應的數據即可,避免了全盤掃描,從而減少了恢復時長.但是,額外的記錄會造成寫放大,并且對于記錄的地址,需要額外實現安全保護措施,增加了運行時開銷.
4 總結與展望
本文從持久性內存特性出發,分別針對持久性內存的寫特性與非易失性,展開介紹了基于持久性內存構建安全內存存儲系統面臨的挑戰.針對寫特性,由于持久性內存具有有限的耐久性,相關工作[15-16,18-20]主要目的在于減少由于安全措施導致的額外比特翻轉,以及減少持久性內存的寫次數,并未考慮非易失性.
針對非易失性,基于持久性內存構建安全存儲系統需要保障其在生命周期內的安全性,因此需要考慮數據與安全元數據之間的災后一致性.本文分別從內存加密與內存完整性驗證2方面詳細闡述了一致性保障帶來的挑戰,同時介紹了相關工作,表2對比了不同安全持久性內存存儲系統架構.第1類工作SCA[22]和SuperMem架構[28]主要解決了內存加密的一致性保障,并未考慮完整性驗證的一致性保障.第2類工作解決了完整性驗證的一致性保障,其中Osiris[27],Triad-NVM[31],AGIT架構[32]采取了嚴格更新策略,而cc-NVM架構[29]采取了懶惰更新的策略,其性能開銷最低;第3類工作Triad-NVM[31]和Anubis架構[32]減少了安全持久性內存恢復時長,提高了系統的可用性.然而,上述工作并未完全解決單點故障問題,如何解決恢復后的完整性驗證導致的單點故障問題需要進一步探索.
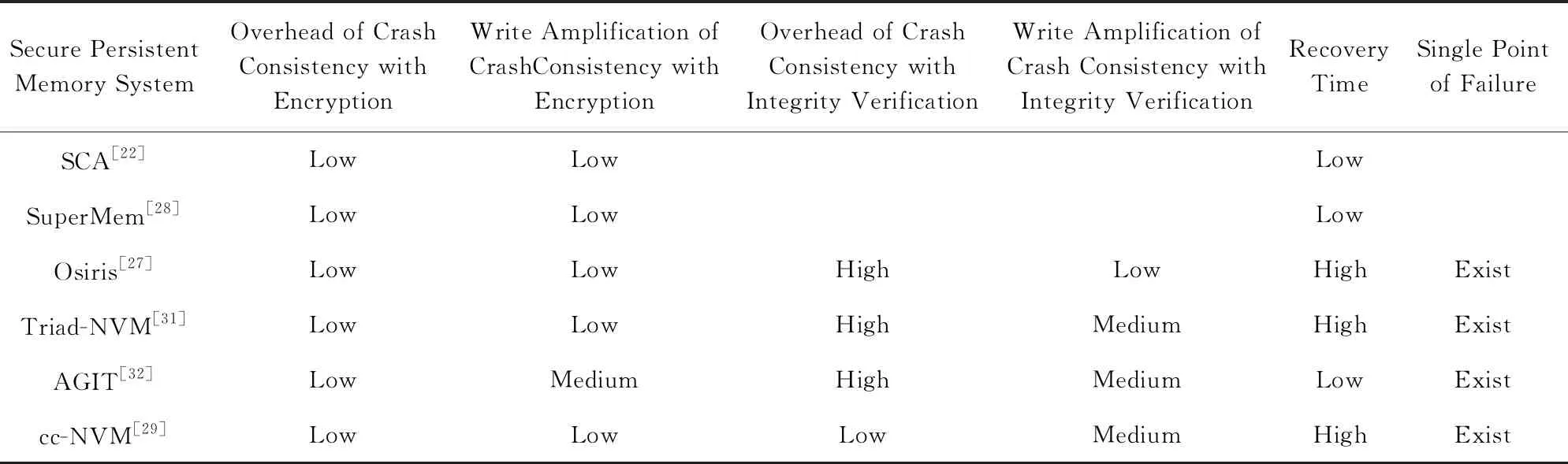
Table 2 Comparison Between Different Secure Persistent Memory Storage Systems表2 不同安全持久性內存存儲系統對比
此外,現有大部分安全持久性內存研究主要針對BMT風格的安全架構,當完整性驗證樹結構轉變為Intel SGX風格時,將會給安全持久性內存研究帶來新的機遇與挑戰.Anubis架構[32]針對Intel SGX完整性樹設計了恢復策略ASIT,然而此策略引入了較高的性能開銷.Intel SGX風格的完整性驗證樹具有可并行更新的特性,如何針對此特性設計高效的完整性驗證樹持久化方法以及恢復策略需要進一步探索.
猜你喜歡
遼寧教育(2022年19期)2022-11-18 07:20:42
公民與法治(2022年5期)2022-07-29 00:47:28
汽車實用技術(2022年9期)2022-05-20 05:51:26
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
裝備制造技術(2020年11期)2021-01-26 00:39:12
中國公共安全(2017年11期)2017-02-06 05:28:08
電測與儀表(2016年7期)2016-04-12 00:22:18
燕山大學學報(2015年4期)2015-12-25 02:19:49
