基于動態窗口的大數據流式處理技術研究
2020-06-04 12:55:32呂勤
數字技術與應用 2020年3期
呂勤
摘要:目前市場上的大數據流式處理系統普遍存在計算結果不能共享、實時處理性能不高、計算時間窗口固定和不能動態擴容等問題。針對這些問題,本文設計了一種基于新型時間切片原理,具備動態資源調度、系統容錯、動態窗口計算能力的高性能大數據流式處理系統。
關鍵詞:大數據流式處理;時間窗口;實時計算
中圖分類號:TP319 文獻標識碼:A 文章編號:1007-9416(2020)03-0140-03
1 大數據流式處理面臨的挑戰
目前業內主流的大數據流式處理系統面臨諸多挑戰,最突出的包括計算資源和存儲資源的動態調度分配、系統容錯和動態時間窗口調整等。在資源調度方面,許多流式處理系統普遍采用多節點進行分布式數據計算和數據結果的存儲,技術難點在于數據流對多個計算節點的均勻分配以及數據結果的均勻存儲和各個節點資源的均衡使用。此外,在大數據流式處理過程中,數據分發節點、計算節點和存儲節點間存在大量的數據交互,網絡資源消耗極高,往往成為系統性能瓶頸。在系統容錯方面需要在單個節點出現故障時,能保證整體系統的正常運行。當整個系統資源不足以滿足數據的處理時,還要能在保證當前系統的穩定運行情況下動態添加資源,以實現系統處理能力的動態擴展[1]。在計算窗口方面,因為存在計算任務執行過程中只保存數據處理的結果數據、流入的原始數據被丟棄等原因,多數流式處理系統的計算窗口都是靜態的,無法支持在計算任務啟動后臨時調整計算窗口。
2 大數據流式處理系統架構
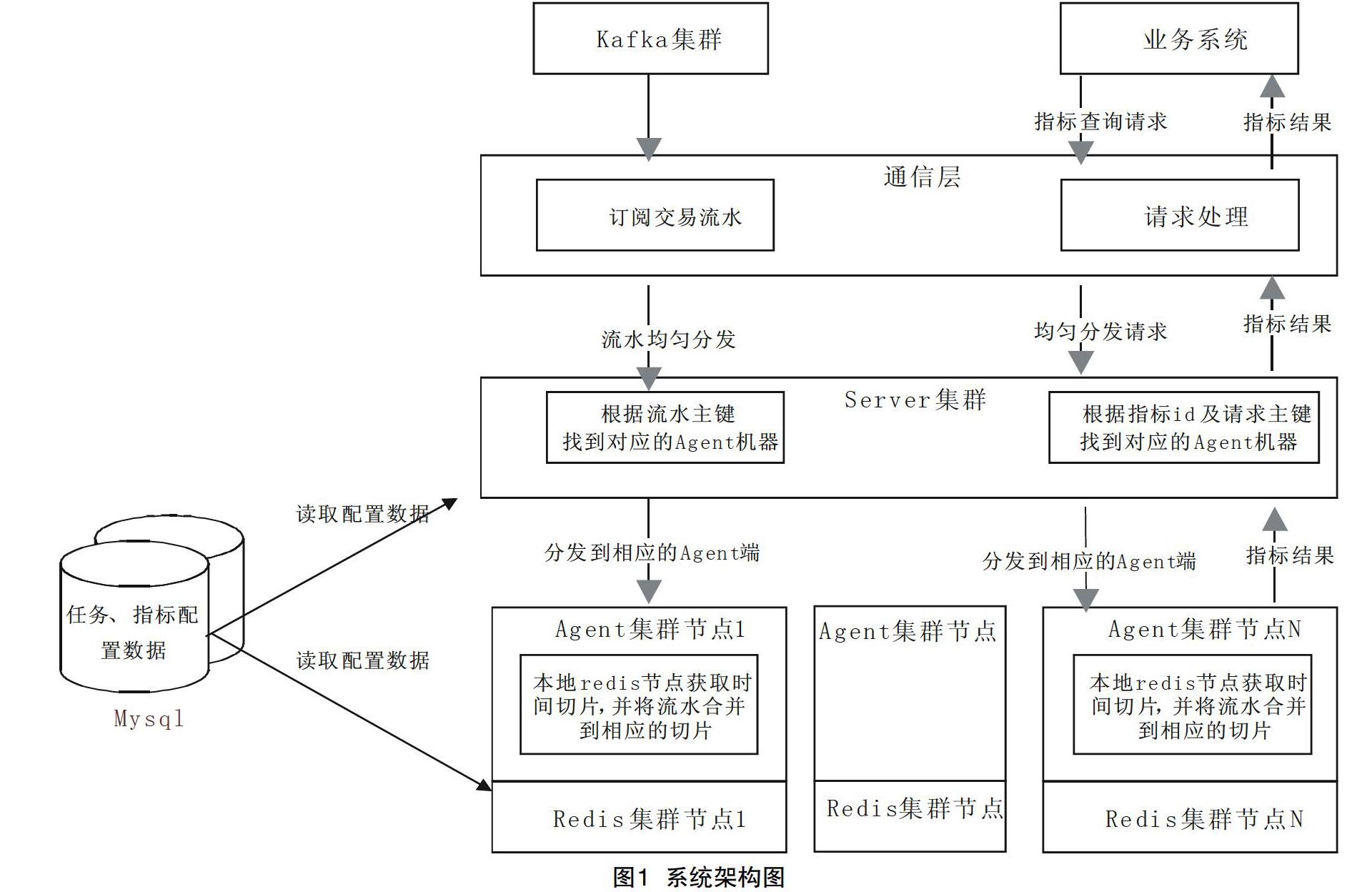
為了滿足業務發展對高性能實時指標計算能力的需要,同時解決目前行業內同類工具普遍存在的問題,采用新型的時間切片原理,在利用Kafka、Netty和Redis等開源組件的技術特性的基礎上,設計了一套高性能的大數據流式處理系統。該系統主要功能包括接受外部系統流水數據、實時指標計算和向外部系統提供指標查詢等功能。系統分為四層架構,分別為通訊層、服務層(Server層)、計算層(Agent層)和計算結果緩存層,每層均為多節點集群,緩存層由Redis集群組成,計算層與緩存層的節點按照1∶1配置,部署在同一物理節點上[2]。系統架構參見圖1。
(1)通信層負責與外部系統的交互。通訊層采用kafka作為數據流入起點。Kafka是一種高吞吐量的分布式發布訂閱消息系統,十分適合作為流式處理系統的數據“生產者”和“消費者”。通訊層通過訂閱kafka中的topic,接受外部系統的流水數據并發送到后端服務層。同時通訊層還負責接受外部系統的指標查詢服務請求,并將從服務層獲取的查詢結果反饋給外部系統。
(2)服務層主要功能包括計算指令分發、計算任務監控和指標結果二次加工等。在接收到通訊層發來的流水數據后,服務層先通過對流入數據關鍵值的判斷,確定需要執行的計算任務(計算任務是最小的計算單位),再通過對計算任務參數的組合計算,確定具體的計算節點。服務層將流水數據和需要執行的計算任務列表進行封裝,通過Netty分發到指定的計算節點。
服務層通過收集計算節點的執行狀態實現對計算任務監控。當所有的計算任務都執行成功后,服務層認為當前流入數據已被系統正常處理。如果有計算任務執行失敗,數據分發節點會分析失敗原因并決定是否轉派其他計算節點再次執行。
服務層在響應指標查詢服務請求,獲取緩存節點上的中間結果后,根據預置的處理公式進行二次或多次加工,最終完成服務。
(3)計算層主要功能包括計算任務執行、異常處理、數據序列化以及時間切片等。計算節點識別服務層分發的數據,并使用對應的算子和原有緩存節點中的計算結果合并計算,合并計算的結果再次保存到緩存節點中,并向服務層返回任務執行成功狀態。若計算任務出現異常,則向服務層返回計算任務執行失敗狀態,結果數據不保存。
(4)緩存層主要功能為存儲計算結果,由Redis集群構成。Redis集群內置的自動分區、復制、LRU逐出、事務等特性為系統緩存層的高可用和高性能提供了保證。
3 系統技術特色與實現原理
該系統具備動態資源調度、系統容錯和動態調整指標計算時間窗口等能力,處理性能高效,運行穩定。該系統實現以上能力,主要實現了以下幾項關鍵的技術。
3.1 動態資源調度
資源調度的核心技術是本地數據本地計算的MPP架構和均勻存儲均勻計算。
(1)本地數據本地計算的MPP架構設計:通過將計算節點和存儲節點1∶1的部署在同一物理節點的部署方式,實現數據的讀取、計算和結果回寫均能在同一物理節點上執行,形成MPP架構,大幅減少網絡開銷[3]。
(2)均勻存儲均勻計算:系統采用Redis的hash算法以及Server、Agent與Redis的協同實現了均勻存儲均勻計算。具體來講,均勻存儲的實現是利用Redis Cluster4.0的新技術特性,把所有數據劃分為16384個不同的虛擬槽,根據機器的性能可以把不同的槽位分配給不同的Redis節點。通過對流水數據的關鍵值和計算任務的ID進行hash計算找到數據對應的槽位。Server端存儲一張槽位與機器的對應關系表,在根據槽位找到對應的具體機器的同時,也確定了對應的Redis存儲節點。在這種機制下某個Redis節點只會存儲對應部分的數據,并且保證數據均勻分散在不同的Redis節點上。均勻計算也遵循了同樣的原理。服務層通過同樣的流水數據的關鍵值和計算任務的ID進行hash計算找到計算任務對應的槽位和對應的Agent節點。計算任務和數據存儲的分布遵循同樣的hash算法,也保證了計算節點上的計算任務和存儲節點上的數據的一致性。
3.2 系統容錯
在傳統的Keepalived+Nginx的容錯技術以外,該系統還通過健康狀態監控機制實現系統容錯。Server節點和Agent節點都有各自的健康狀態監聽模塊來記錄本節點的健康狀態。此外Agent節點定期向Server層發送心跳匯報節點健康狀態信息,Server層根據Agent節點的健康狀態動態調整數據的分發和計算任務的分配,保證分發時避開不健康的計算節點。
在計算節點出現故障時,通過兩段處理的方式保證計算任務的正常進行。第一段處理,服務層在分發計算內容前,先判斷計算節點的健康狀態,如果該計算節點狀態為非健康,則隨機選擇一個健康的計算節點進行分發。由于新選擇的計算節點對應的緩存節點中未存儲對應的數據,該計算節點通過Redis Cluster的保障機制從其他緩存節點找到對應的中間數據,保證計算服務的持續進行。第二段處理,計算節點在出現故障時會嘗試自動重啟。如果重啟失敗,則繼續維持第一段處理,如果重啟成功,則Agent會向Server重新上報健康狀態,恢復正常工作。
3.3 動態窗口
所謂動態時間窗口,即在不需要重新發布計算任務的前提下,可以實時調整指標查詢窗口的大小,且能立即獲得對應的結果。目前大多數基于窗口的流式計算解決方案都不能很好地支持動態窗口。其根本原因在于這些解決方案的計算任務都是基于源數據的,由于源數據的數據量大,導致無法在長時間保存源數據的同時又支持快速計算指標結果。在本處理系統中,動態窗口的實現基于系統獨有的時間切片的設計原理。
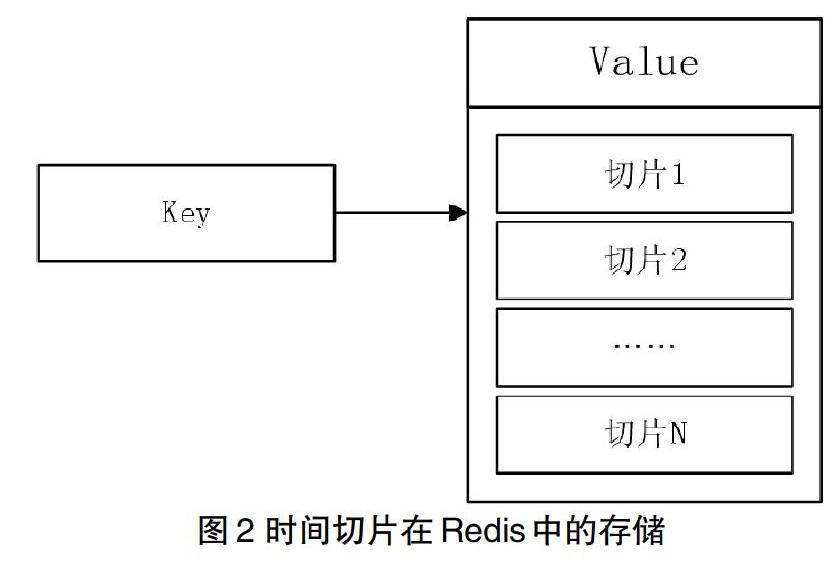
時間切片設計原理:時間切片是將時序數據按照一定的時間間隔聚合后的新的時序數據。一個時間切片是數據信息保存的最小單位,也是保存數據的主要形式。在本系統中,時間切片中不存儲源數據,而是存儲該切片時間段內所有流水數據按照指標配置進行聚合計算后得到的結果數據,這種設計大幅壓縮了數據存儲量,可以存儲較長時間的數據。本系統通過Redis技術實現流水數據的時間切片處理。當流水數據進入到某個具體的數據計算任務后,首先提取流水數據的發生時間,然后根據流水數據的關鍵值和計算任務ID拼裝成Redis的key,根據key取出對應的value,并讀取value中最新切片的時間。如果流水數據的發生時間比該切片時間早,則不需要創建新的切片,找到當前的流水數據對應的時間切片,并根據任務里配置的聚合函數計算結果并更新該時間切片的value,更新回Redis中。如果流水數據的發生時間晚于目前的處理時間,則需要創建新的切片,并根據任務里配置的聚合函數計算出當前流水數據的結果后存入Redis中。時間切片在Redis中的存儲參見圖2。
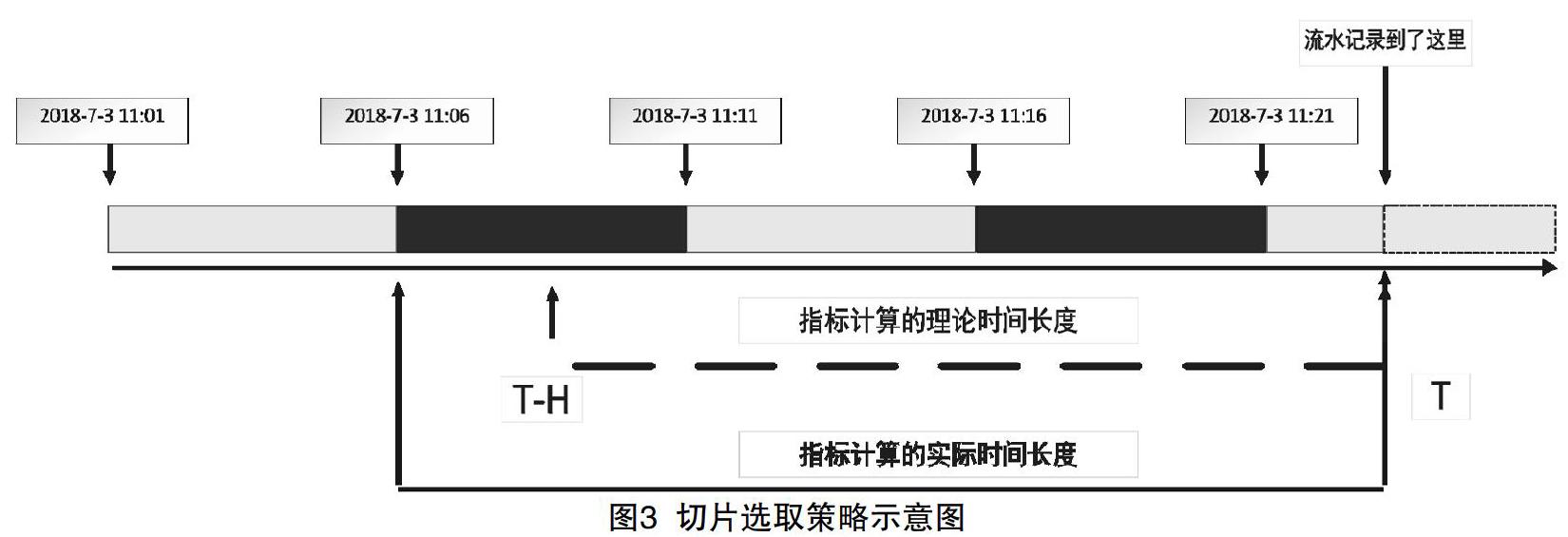
在指標查詢任務中,時間切片的選取采用落入即包含的策略。切片選取策略參見圖3。以5分鐘切片為例,從起始切片開始,每隔5分鐘開啟一個新的切片,T為當前時刻,H為指標計算所需的持續時間,從T-H到T就是指標計算的時間長度。如果T-H正好處于時間切片首尾,就將X個時間切片納入計算,如果T-H在某個時間切片的中間位置,則采用時間覆蓋原則,將該時間切片全部納入計算。在圖3中,虛線段是指標計算的理論時間長度,實線段是指標計算的實際時間長度。采用這種策略,雖然在精度上有細微損失,但大幅提高了計算效率。當需要動態調整指標查詢的時間窗口時,無需對源數據重新計算,只需要通過必要的二次計算即可實時獲取新的結果,實現動態窗口設置的實時生效。
4 結論
本文提出的基于窗口計算的大數據流式處理系統已經實際投入應用。整個系統采用三臺服務器搭建Kafka集群、兩臺服務器搭建服務層、四臺服務器搭建數據計算集群和存儲集群。在壓力測試中,在并發數為100且單條數據大小不超過5M的情況下,集群的指標查詢性能達到7萬TPS,成功率100%。以實際生產數據測試,在60秒內發起2.3億次指標查詢請求,系統的平均響應時間為16ms,TPS為24600左右,且此時的各節點硬件資源使用均未達到極限。通過橫向動態擴展和網絡優化,該流式處理系統的計算能力還能線性提高[4]。
參考文獻
[1] 孫大為,張廣艷,鄭緯民.大數據流式計算:關鍵技術及系統實例[J].軟件學報,2014,25(04):839-862.
[2] 王奇.基于發布訂閱的分布式復雜事件處理系統的研究與實現[D].北京:北京郵電大學,2018.
[3] 蘇錦.基于Netty的高性能RPC服務器的研究與實現[D].南京:南京郵電大學,2018.
[4] 崔曉旻.基于Netty的高可服務消息中間件的研究與實現[D].成都:電子科技大學,2014.
Abstract:At present, there are many problems in big data streaming processing systems in the market, such as the calculation results can not be shared, the real-time processing performance is not high, the calculation time window is fixed, and the calculation capacity cannot be expanded dynamically. To solve these problems, this paper designs a high-performance streaming data processing system based on the new time slicing principle, which has the ability of dynamic resource scheduling, system fault tolerance and dynamic window computing.
Key words:big data stream processing; time window; real time computing
