一種基于自適應非極大值抑制的文本檢測算法
2020-06-04 12:55:32陳澤瀛
數字技術與應用 2020年3期
陳澤瀛

摘要:場景文本檢測是場景文本識別系統的重要步驟,也是一個具有挑戰性的問題。與一般對象檢測不同,場景文本檢測的主要挑戰在于自然圖像中文本的任意方向,較小的尺寸以及顯著不同的寬高比。本文提出了一種名為SANTD( Self-adaptive NMS Text Detection)可端到端訓練的文本檢測模型,該檢測模型可以在單個網絡中精確、高效地檢測任意方向的場景文本。同時,本文還對非極大值抑制做了修改,使其可自適應地檢測文本框附近的密度值。在評估實驗中,SANTD在準確率和召回率上都表現出了一定的優勢。在數據集ICDAR 2015上,SANTD以11.6fps得到84.3%的值。
關鍵詞:文本檢測;自適應;非極大值抑制;卷積神經網絡
中圖分類號:TP391 文獻標識碼:A 文章編號:1007-9416(2020)03-0117-04
0 引言
場景文本是自然場景中最常見的視覺對象之一,經常出現在道路標志、車牌、廣告牌、產品包裝上。盡管自然場景下的文本檢測與傳統的OCR相似,但由于文本的多樣性、背景的復雜性以及無法控制的光照條件等因素,使得場景文本閱讀更具挑戰性,如文獻[1]所述。近年來,場景文本檢測已經得到了廣泛的研究[1-3],并且隨著目標檢測、語義分割的迅速發展,近來取得了明顯的進步。這些場景文本檢測器主要可以分為兩類。一類是基于目標檢測(如SSD[4]、YOLO[5]、DenseBox[6])直接預測候選邊界框的文本檢測算法如TextBoxes[7],FCRN[8]和EAST[9]。第二類是基于語義分割,例如文獻[10]和文獻[11],它們生成分割圖并通過后期處理生成最終的文本邊界框。
本文基于目標檢測算法SSD通過端到端可訓練的單個神經網絡直接預測具有四邊形的單詞邊界框來檢測文本,并在網絡中構建自適應非極大值抑制算法,稱之為SANTD。
本文用四邊形代替傳統目標檢測中的矩形框來表示文本區域,同時為了識別較長的文本區域,加入“長條形”卷積核來預測文本區域邊界框。SANTD通過聯合預測文本是否存在和錨點框坐標偏移,直接在多層輸出文本邊界框,然后輸出所有錨點框經過可學習非極大值抑制后的錨點框。在網絡中,單個前向網絡可以檢測圖像上的多尺度文本框。該檢測器在速度上具有很大優勢。
1 相關工作
1.1 文本檢測
場景文本閱讀系統通常由文本檢測和文本識別兩部分組成。前一個組件主要以單詞邊框的形式在圖像中定位文本。后者將文字圖像裁剪成機器可解釋的字符序列。在本文中,我們涵蓋了這兩個方面,但更多的是關注檢測。一般來說,大多數文本檢測器可以根據原始檢測目標和目標包圍盒的形狀,按照兩種分類策略大致分為幾類。
1.1.1 基于回歸的文本檢測
在過去兩年中,基于回歸的文本檢測已成為場景文本檢測的主流。基于普通目標檢測器,提出了幾種文本檢測方法,并取得了實質性進展。源自SSD[4]的TextBoxes[7]使用“長”默認框和“長”卷積核來應對極端的寬高比。同樣,在文獻[12]中,Ma等人利用Faster-RCNN[13]的體系結構,并在RPN中添加旋轉錨點以檢測面向任意方向的場景文本。SegLink[14]基于SSD網絡預測文本分割區域和區域間鏈接,并將這些分割區域鏈接到文本框,以便在自然場景中處理長方向的文本。基于DenseBox[6],EAST[9]直接使文本框回歸。
本文基于目標檢測算法DSSD[15],與上述直接回歸文本框或直接分割的方法不同,我們定位文本框角點的位置,然后通過對檢測到的角進行采樣、分組和引入可學習非極大值抑制來生成文本框。
1.1.2 基于分割的文本檢測
基于分割的文本檢測是文本檢測的另一個方向。受FCN[16]的啟發,提出了一些使用分割圖來檢測場景文本的方法。在文獻[10]中,Zhang等人第一次嘗試由FCN從分割圖提取文本塊。然后,他們使用MSER[17]檢測這些文本塊中的字符,并通過一些先驗規則將字符分組為單詞或文本行。在文獻[11]中,Yao等人使用FCN來預測輸入圖像的三種類型的地圖(文本區域,字符和鏈接方向)。然后進行一些后處理以獲得帶有分割圖的文本邊界框。
1.1.3 基于角點的目標檢測
基于角點的目標檢測是目標檢測算法的一種新方式。在DeNet[18]中,Tychsen-Smith等人在Faster-RCNN風格的兩階段模型中,提出了一個角檢測層和一個稀疏樣本層來代替RPN。在文獻[19]中,Wang等提出PLN(點連接網絡),它使用完全卷積網絡對邊界框的角點、中心點及其連接線進行回歸,然后使用角點、中心點及其連接線形成對象的邊界框。
1.1.4 端到端文本檢測器
端到端方法同時訓練檢測和識別模塊,以便通過利用識別結果來提高檢測精度。 FOTS[20]和EAA[21]將流行的檢測和識別方法進行疊加,并以端到端的方式對其進行訓練。Mask TextSpotter[22]利用他們的統一模型將識別任務視為語義分割問題。顯然,使用識別模塊進行訓練可以幫助文本檢測器對類似文本的背景識別更加魯棒。
1.2 非極大值抑制
非極大值抑制(NMS,Non-Maximum Suppression)是計算機視覺中廣泛使用的后處理算法。它是許多檢測方法的重要組成部分,例如邊緣檢測[23],特征點檢測和目標檢測[13,24,25]。NMS廣泛應用于目標檢測算法中,對于重疊度較高的一部分同類候選框來說,去掉那些置信度較低的框,只保留置信度最大的那一個進行后面的流程,其中重疊度通過NMS閾值衡量。
Soft-NMS[26]和Learning-NMS[27]被提出用來改善NMS的結果。Soft-NMS不會丟棄得分低于閾值的所有周圍提議,而是通過增加鄰居與得分較高的邊界框的重疊程度來降低鄰居的檢測得分。文獻[27]試圖學習僅使用盒子及其分數作為輸入的深層神經網絡來執行NMS功能,但是該網絡經過專門設計并且非常復雜。文獻[28]提出了一個對象關系模塊來學習NMS作為端到端通用對象檢測器的功能。文獻[29]用學習到的本地化置信度代替了在NMS過程中使用的提議分類分數,以指導NMS保存更準確的本地化邊界框。與它們不同的是,本文建議將每個真實目標周圍的密度作為自己的抑制閾值來學習,這與文字計數任務中的文字密度估計有一些相似之處。
2 SANTD
2.1 網絡結構
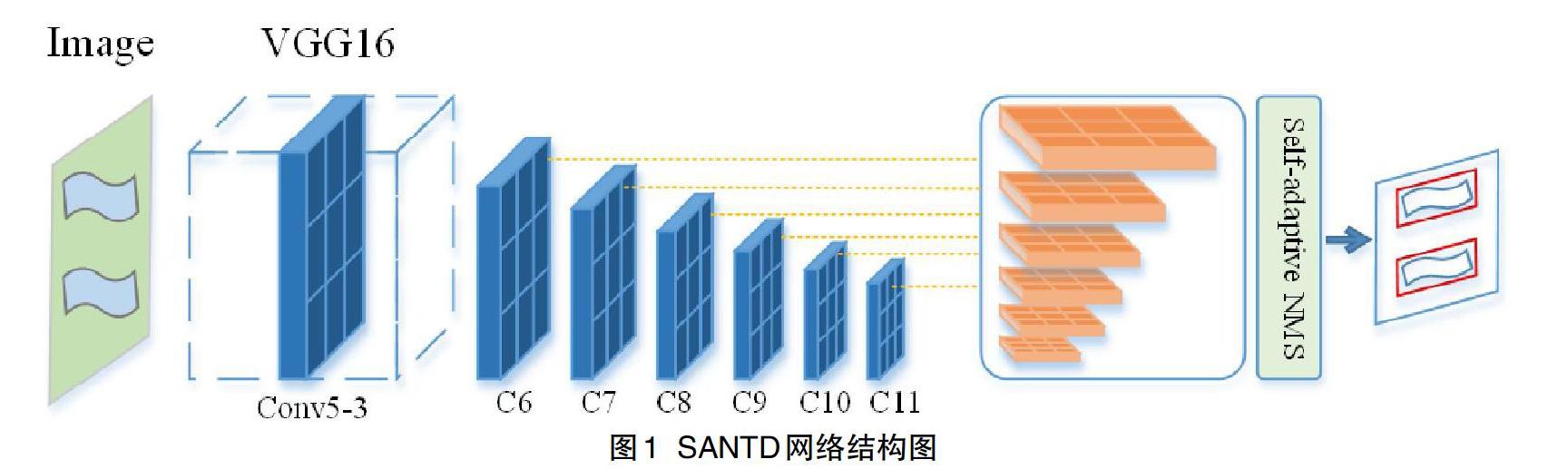
本文使用基于VGG16的全卷積網絡結構作為主干網絡,使用類似于U-Net的構建方式聚合低卷積層特征,網絡結構如圖1所示。
SANTD繼承了當前較為流行的VGG-16網絡結構[30],保留了從Conv1_1到Conv5_3的卷積層,并將VGG-16的最后兩個全連接層轉換為兩個卷積層(C6和C7)進行下采樣[4]。在C7之后通過最大池化分成不同分辨率的另外四個卷積層,分為四個階段(C8至C11)。然后,在C11之后加入多個上采樣卷積層用來聚合不同感受野下的檢測結果。最后,通過自適應非極大值抑制提取出文本框。綜上所述,SANTD是完全卷積的結構,僅由卷積和池化層組成,所以SANTD可以在訓練和測試階段適應任意大小的圖像。
2.2 自適應非極大值抑制
Greedy-NMS和Soft-NMS的設計都遵循著一個假設:當一個檢測框與當前最大得分檢測框重疊程度較高時,這個檢測框是假陽性的可能性更大。這個假設用于目標識別時沒有問題,因為在正常情況下目標很少會發生遮擋。但是,這種假設在擁擠的場景中則會有一定的偏差;在密集文字場景中,人類實例彼此高度重疊的檢測框。為了適應密集文字場景檢測,NMS應考慮:(1)遠離的檢測框,其誤報的可能性較小,因此應予以保留;(2)對于高度重疊的相鄰檢測框,抑制策略不僅取決于與的重疊,而且還要判定此時是否位于擁擠區域。如果位于擁擠的區域,則其高度重疊的相鄰檢測框很可能是真實的,因此應給予較輕的懲罰或予以保留。但是對于稀疏區域的實例,懲罰應更高些。
本文將檢測框的擁擠度定義為其他檢測框與檢測框重疊部分的最大值,如公式所示:
(1)
另外,本文將非極大值抑制的閾值進行調整,用與的較大值作為當前循環下的閾值如公式所示:
(2)
(3)
其中,表示檢測框的自適應非極大值抑制閾值,表示檢測框的擁擠度,表示檢測框得分或經過前序非極大值抑制后的當前得分。當鄰近檢測框與檢測框重疊區域小于時,閾值與傳統NMS一致為超參數;當大于等于時,自適應NMS閾值將轉變成,即當前。
自適應非極大值抑制算法如圖2所示,從算法復雜度而言幾乎與greedy NMS和soft NMS保持一致。自適應非極大值抑制的唯一額外消耗是一個包含個元素的列表,其中存儲了每個檢測框的擁擠度,對于今天的硬件配置而言,可以忽略不計。因此,自適應非極大值抑制算法對檢測器的運行效率影響不大。
3 評估實驗
為了驗證該方法的有效性,我們在ICDAR2013和ICDAR2015公共數據集上進行了實驗,并與其他方法進行了比較。
3.1 實驗細節
SANTD在SynthText[8]上進行了預訓練,然后在其他數據集(COCO-Text除外)上進行了微調。我們使用Adam優化模型,將學習率固定為。在訓練前階段,我們在SynthText上訓練模型一個時間。在微調階段,迭代次數由數據集的大小決定。
數據擴充我們使用與SSD相同的數據擴充方式。我們以SSD方式從輸入圖像中隨機采樣補丁,然后將采樣補丁的大小調整為512×512。
我們的方法在PyTorch[31]中實現。所有實驗都是在常規工作站上進行的(CPU:IntelXeonCPU E5-2650 v3 @ 2.30GHz; GPU:NVIDIA Tesla V100; RAM:64GB)。我們在4個GPU上并行訓練具有32個批處理大小的模型,并在1個批處理大小的GPU上評估模型。
3.2 評估協議
用于文本檢測和文本識別的經典評估協議都依賴于三個參數,它們分別是準確率(),召回率()和值()。
(4)
其中,和分別是命中框,錯誤框和錯過的框的數量。對于文字檢測時,如果預測框與真實框之間的大于給定閾值(通常設置為0.5),則將檢測到的框視為命中框。文本端到端識別中的命中框不僅需要相同的限制,還需要正確的識別結果。由于需要在精度和召回率之間進行權衡,因此是性能評估中最常用評估值。
3.3 實驗結果
3.3.1 檢測水平方向文字
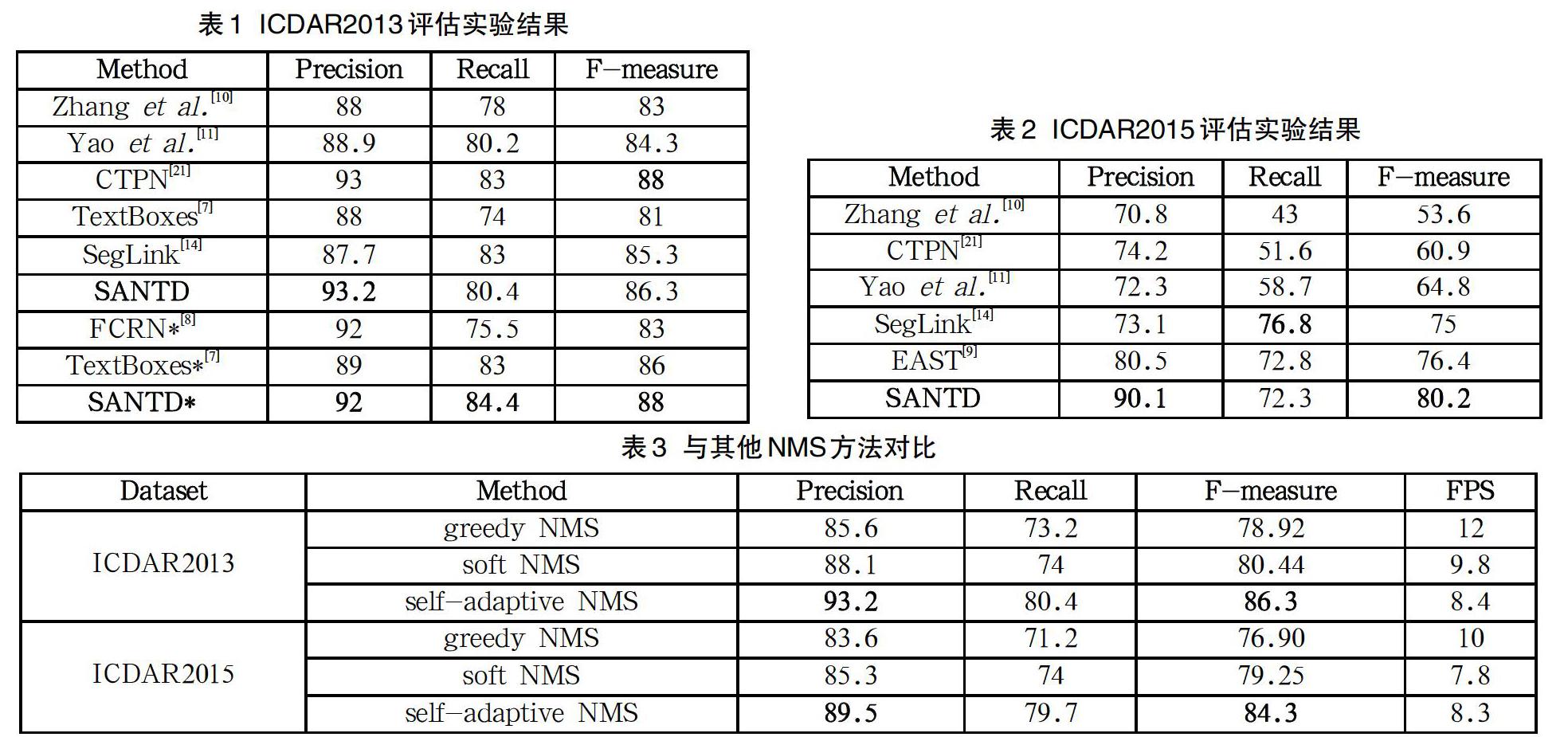
我們評估了模型在ICDAR2013數據集上水平文本的檢測能力。在測試中,輸入圖像的大小調整為512×512。我們還使用多尺度輸入來評估模型,表1中帶*的部分是在多尺度下的評估結果,多尺度包括(512×512;768×768;768×1280;1280×1280)。
結果如表1所示,與大多數評估方式保持一致,使用“Deteval”方式進行評估。本文提出的算法在評估中取得了不錯的結果。單次測試時,我們的方法達到了86.3%的值,略低于最高結果。在多尺度評估中,我們的方法達到了88%的值,與其他方法相比具備一定的競爭力。
3.3.2 檢測任意方向文字
我們在ICDAR2015數據集上評估我們的模型,以測試其在任意方向文本檢測方面的能力。我們在ICDAR2015和ICDAR2013的數據集上再微調。為了更好地檢測垂直文本,在最近的15個epoch中,以0.2的概率將圖像隨機正向或逆向旋轉90度。
本文將SANTD與其他方法進行了比較,并在表2中列出了評估實驗結果。從表2中可以看出SANTD優于其他方法。在單次測試中,SANTD達到了80.2%的值,超過了所有其他文獻[9-11,14,21]中的算法。
3.3.3 與其他NMS對比
為了驗證自適應非極大值抑制的有效性,本文使用同樣的網絡結果,只在最后一步非極大值抑制做相應變化,分別在ICDAR2013和ICDAR2015兩個數據集上進行評估實驗,實驗結果如表3所示。
由表3可見,自適應非極大值抑制不管是在數據集ICDAR 2013上還是ICDAR2015都表現出了不錯的成績,同時在FPS上也并沒有太多差別。
4 結語
本文提出一種自適應非極大值抑制的,并且可以檢測任意方向文本的檢測算法SANTD。該算法快速、高效且可端到端訓練。在未來的工作中,我們希望以端到端的方式加入文字識別模型,同時訓練文本檢測和文本識別模型,由此或許可以讓檢測和識別都能表現得更加準確、高魯棒性和更強的可推廣性,使其轉化為一個更好的場景文本發現系統,從而可以更廣泛地應用到生產生活中去。
參考文獻
[1] Bissacco A,Cummins M,Netzer Y,et al.PhotoOCR:Reading Text in Uncontrolled Conditions[C]//2013 IEEE International Conference on Computer Vision(ICCV).IEEE,2013:785-792.
[2] Epshtein B,Ofek E,Wexler Y.Detecting Text in Natural Scenes with Stroke Width Transform[C]//Computer Vision and Pattern Recognition (CVPR),2010 IEEE Conference on.IEEE,2010:2963-2970.
[3] Yao C,Bai X,Liu W,et al.Detecting Texts of Arbitrary Orientations in Natural Images[C]//IEEE Conference on Computer Vision & Pattern Recognition.IEEE,2012:1083-1090.
[4] Liu W,Anguelov D,Erhan D,et al.SSD:Single Shot MultiBox Detector[C]//European Conference on Computer Vision.Springer International Publishing,2016:21-37.
[5] Redmon J,Divvala S,Girshick R,et al.You Only Look Once:Unified,Real-Time Object Detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016.
[6] Huang L,Yang Y,Deng Y,et al.DenseBox:Unifying Landmark Localization with End to End Object Detection[J].Computer Science,2015,37(9):682-689.
[7] Liao M,Shi B,Bai X,et al.TextBoxes:A Fast Text Detector with a Single Deep Neural Network[J].AAAI,2017:4161-4167.
[8] Gupta A,Vedaldi A,Zisserman A.Synthetic Data for Text Localisation in Natural Images[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016:2315-2324.
[9] Zhou X,Yao C,Wen H,et al.EAST:An Efficient and Accurate Scene Text Detector[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2017:2642-2651.
[10] Zhang Z,Zhang C,Shen W,et al.Multi-Oriented Text Detection with Fully Convolutional Networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016:4159-4167.
[11] Yao C,Bai X,Nong S.Scene Text Detection via Holistic,Multi-Channel Prediction[J].arXiv e-prints,2016:1606.09002.
[12] Ma J,Shao W,Ye H,et al.Arbitrary-Oriented Scene Text Detection via Rotation Proposals[J].ieee transactions on multimedia,2017(99):1.
[13] Ren S,He K,Girshick R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[14] Shi B,Bai X,Belongie S.Detecting Oriented Text in Natural Images by Linking Segments[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2017:3482-3490.
[15] Fu C Y,Liu W,Ranga A,et al.DSSD:Deconvolutional Single Shot Detector[J].arXiv e-prints,2017:1701.06659.
[16] Long J,Shelhamer E,Darrell T.Fully Convolutional Networks for Semantic Segmentation[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,39(4):640-651.
[17] Neumann L,Matas J.A Method for Text Localization and Recognition in Real-World Images[C]//Computer Vision-accv -asian Conference on Computer Vision.DBLP,2010:770-783.
[18] Tychsen-Smith L,Petersson L.DeNet:Scalable Real-time Object Detection with Directed Sparse Sampling[J].ICCV,2017:428-436.
[19] Wang X,Chen K,Huang Z,et al.Point Linking Network for Object Detection[J].arXiv e-prints,2017:1706.03646.
[20] Liu X,Liang D,Yan S,et al.FOTS:Fast Oriented Text Spotting with a Unified Network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE/CVF,2018:5676-5685.
[21] Epshtein B,Ofek E,Wexler Y.Detecting Text in Natural Scenes with Stroke Width Transform[C]//Computer Vision and Pattern Recognition (CVPR),2010 IEEE Conference on.IEEE,2010:2963-2970.
[22] Lyu P,Liao M,Yao C,et al.Mask TextSpotter:An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2018(10):1.
[23] Rosenfeld A,Thurston M.Edge and Curve Detection for Visual Scene Analysis[J].IEEE Transactions on Computers,1971,C-20(5):562-569.
[24] Lin T Y,Goyal P,Girshick R,et al.Focal Loss for Dense Object Detection[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,42(2):318-327.
[25] Lin T Y,Dollár,Piotr,Girshick R,et al.Feature Pyramid Networks for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2016:936-944.
[26] Bodla N,Singh B,Chellappa R,et al.Soft-NMS--Improving Object Detection With One Line of Code[C]//2017 IEEE International Conference on Computer Vision (ICCV).2017:5562-5570.
[27] Hosang J,Benenson R,Schiele B.A Convnet for Non-maximum Suppression[C]//German Conference on Pattern Recognition. Springer International Publishing,2016:192-204.
[28] Hu H,Gu J,Zhang Z,et al.Relation Networks for Object Detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE/CVF,2018:3588-3597.
[29] Jiang B,Luo R,Mao J,et al.Acquisition of Localization Confidence for Accurate Object Detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE/CVF, 2018:3588-3597.
[30] Simonyan K,Zisserman A.Very Deep Convolutional Networks for Large-Scale Image Recognition[J].Computer Science,2014:730-734.
[31] Pytorch[K].http://pytorch.org/.
Abstract:Scene text detection is an important step in a scene text recognition system, and it is also a challenging problem. Unlike general object detection, the main challenge of scene text detection is the arbitrary orientation of text in natural images, smaller sizes, and significantly different aspect ratios. In this paper, we propose an end-to-end training text detection model called SANTD (Self-adaptive NMS Text Detection), which can accurately and efficiently detect scene text in any direction in a single network. At the same time, this paper also modified the non-maximum suppression so that it can adaptively detect the density value near the box. In the evaluation experiment, SANTD showed certain advantages in both precision and recall. On the dataset ICDAR 2015, SANTD gets a value of 84.3% f-measure at 11.6fps.
Key words:text detection; self-adaptive; NMS; Convolutional Neural Network
