空氣質量監測大數據區間的統計問題淺談
2020-05-25 02:28:07徐學龍
科學與信息化 2020年5期
關鍵詞:大數據
徐學龍

摘 要 在新的歷史時期為了能夠降低客戶端和服務端之間遠程過程調用通信,提升已存儲空氣質量監測數據表格區間統計效率,文章提出一種基于協調處理器的大數據區間統計方法,旨在通過特定的協議來將區間統計參數從客戶端傳遞到服務端,在信息經過流通和分析之后得到最終的區間統計結果。經過試驗研究證明,使用終端協處理器進行空氣質量監測能夠提升空氣質量統計效率。
關鍵詞 空氣質量;監測;大數據;區間統計;HBase
城市環境空氣質量管理遭遇的瓶頸問題是面源管控難,加上城市污染來源復雜、種類多、污染溯源和靶向治理難和環境空氣監測點源自動化監測設備少的影響,無法對空氣質量進行清晰有效的預測和預警,使得環境空氣監測信息化水平不高,無法滿足大氣污染治理的總體需求。HBase0.92 版本支持下的終端協調處理器能夠在服務器的終端完成計數、求和、求最大數值等統計工作,在統計分析之后能夠將結果數據重新返回到客戶端,減少客戶端到服務端的RPC調用,從而提升數據信息的統計查詢效率。
1 空氣質量監測大數據區間存儲模式的設計
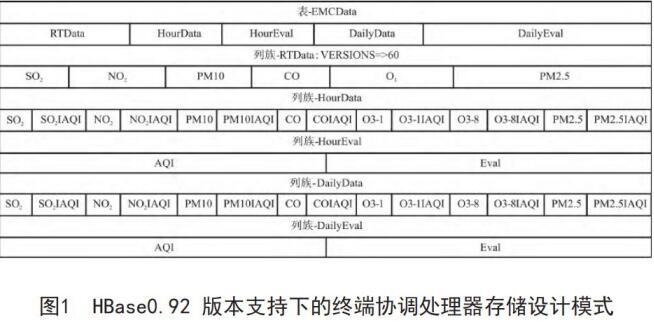
HBase0.92 版本支持下的終端協調處理器存儲設計模式如圖1所示,經過實踐操作證明這種存儲模式能夠有效對空氣質量監測數據進行存儲,從而滿足當地空氣質量監測和分析需要[1]。
2 空氣質量監測大數據區間統計協調處理器
空氣質量監測大數據區間統計協調處理器一般可以劃分為終端模式和觀察模式兩種。終端處理器能夠將數據檢索統計過程在服務器的終端完成,在這個過程中減少客戶端到服務端遠程操作過程數據調用所產生的一系列費用,從而在最大限度上提升數據信息的統計效率和統計有效性。
空氣質量監測大數據區間統計協調處理器的數據區間統計步驟如下所示:①實現對EMCStat.pro-to文件內容的定義,按照protobuf協議定義區間統計協處理器的請求數據信息格式和RPC服務格式。第二,定義協處理器類EMCStat End Point,應用get EMCStat 方法實現對區間統計數據信息的協調處理。第三,在EMCData 表中額外加載EMCStat Endpoint 協議處理器。第四,客戶端綜合調用EMCStat Endpoint 協處理器,對分布在不同Region上的數據信息進行區間統計分析,并將統計數據信息及時輸出結果數據。
2.1 Protobuf協議統計分析
HBase0.92 版本支持下的終端協調處理器應用專門的協議來定義客戶端和服務端的通信數據信息,并根據 EMCStat Request 協議的基本模式和要求向協議處理器傳遞經過處理的參數信息,具體包含區間統計數據信息、站點編碼數據信息、不同操作時間段的數據信息等,在統計完這些數據信息之后將其編訂成一個完整的數據信息集合列表。在按照協議規定獲得指定的參數數據之后執行區間統計程序,按照 EMCStat Request 協議格式將統計結果重新返回到客戶端[2]。
2.2 區間統計協議處理器的是吸納
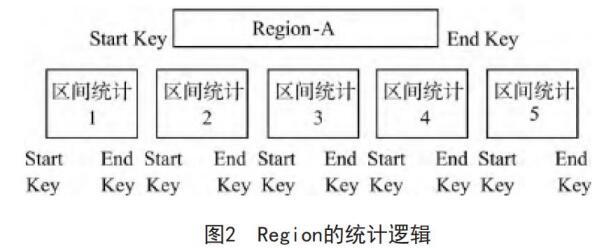
EMCStat Request 協議為區間性的邏輯協議模式。區間范圍內的統計協議處理器能夠對每一個Region進行統計,并根據實際情況判斷Region是否參與到最終的統計分析中。在區間統計的Start Key 和End Key 大小相差太多的時候可以直接跳過Region區域。整個Region的統計邏輯如圖2所示。
2.3 客戶端的調用
客戶端區間統計業務邏輯按照 EMCStat Request的消息格式來定義處理器統計過程中所需要的各類參數信息,之后以Batch Call 方式調用 EMCData 表格區間統計協議處理器的信息。考慮到Batch Call 僅僅能夠對對應的Region區間數據信息進行統計分析,為此在統計數據信息的時候還需要對每一個Region區間范圍內的數據統計結果進行綜合匯總輸出處理[3]。
3 空氣質量監測大數據區間的統計實驗分析
空氣質量監測大數據區間實驗統計環境和設備安裝和文獻中所規定的內容一致,模擬數據信息會被錄入到每一個監測項目程序中,之后按照每小時40到60實時數值的順序寫入到 EMCData 表格中。在對數據信息進行綜合統計分析之后自動計算和評價數值。在數據信息錄入的過程中在Region數量分別為奇數1/3/5/7/9/11的時候,對存儲二氧化氮濃度數據列的RTData可以按照每立方米0~41μg、43.05~82.00μg、84.05~123.00μg、125.05~164.00μg、166.05~205.00μg進行計算[4]。
計算時的具體參數設定如下所示:地區碼 4201,站點編碼為空,代表的是統計區域范圍內所有站點的數據信息。統計時間覆蓋所有的Region,在計算的時候為了能夠減少客戶端Scan統計過程RPC調用情況可以為Scan操作設置一個具體的掃描存儲數值,表示RPC調用可以從服務端進行數據讀取的行為,從而有效減少客戶端RPC調用行數。但是在具體設定操作時需要注意的是掃描存儲數值不能夠設定得較高,目的是不過度消耗客戶端的內存。掃描緩存數值的設定需要在能夠減少RPC請求和客戶端內存消耗之間達到一種平衡,結合實際操作將掃描緩存設定的數值控制在256左右。空氣質量監測大數據區間的統計實驗結果如表1所示,時間對比情況如圖3所示[5]。
4 結束語
綜上所述,在服務器端使用Endpoint協處理器對空氣質量監測大數據區間進行統計能夠更為精準的分析出城市空氣質量,并在一定程度上減少數據統計所需要消耗的時間。HBase的數據表在Hadoop集群的每個數據節點上的Region相同這個時候協調處理器工作效率將會達到最為理想的狀態。但是在數據的不斷增加下,Region在每個數據節點上的數量不再相同,基于Endpoint協處理器的空氣質量監測大數據區間將會面臨數據信息阻滯的問題,這個時候怎樣協調和平衡數據信息成為新時期空氣質量監測大數據區間工作所需要著重思考和解決的問題。
參考文獻
[1] 劉黎志,何經緯.空氣質量監測大數據區間的統計問題%Big Data Interval Statistics for Air Quality Monitoring[J].武漢工程大學學報,2019,41(2):179-183.
[2] 李源.淺述城市環境空氣質量監測的工作%Urban Air Quality Monitoring Work[J].能源與節能,2011,(5):41-43.
[3] 劉閩,王帥,林宏,等.沈陽市冬季環境空氣質量統計預報模型建立及應用%The Study on Establishment and Application of Winter Environment Air Quality Forecasting Model of Shenyang[J]. 中國環境監測,2014,(4):10-15.
[4] 鄧聰,楊善黨,王健,等.高原省份城市空氣質量狀況統計分析及PM2.5污染水平時空分布[J]. 環境科學導刊,2017,(5):40-43.
[5] 劉從容,劉振山,胡海旭.環境空氣質量統計預報模式的研究——沈陽市環境空氣質量各季節預報模式[J].環境保護科學,2006,(4):7-8,13.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
