智適應學習系統中個性化學習推薦研究及應用
2020-05-20 07:15:38謝銳兵
現代計算機 2020年11期
謝銳兵
(浙江廣廈建設職業技術學院,東陽 322100)
0 引言
隨著互聯網技術的快速發展和電腦、智能手機等智能設備的普及,在線學習呈突飛猛進式發展,其范圍涵蓋了各種校內課程教育、校外輔導和成人終身教育以及社會職業教育、技能培訓等。“互聯網+”教育因其數字化、自主化、碎片化、靈活性等的學習優勢非常受大家的歡迎。隨著各種網絡學習資源的開發建設積累和網絡資源開放性、共享性的不斷加大,在線學習系統中的學習資源也日益增加,這在給學習人員帶來豐富充實的學習資源的同時,也給學習人員帶來了選擇的困惱,容易給學習人員帶來“資源迷航”[1]。因材施教歷來是中國教育遵循的原則,個性化學習需求也越來越受人們重視,國家在2010 年制定的《國家中長期教育改革和發展規劃綱要(2010-2020)》中就提出了尊重個性化學習需求的意見[1]。學習資源陳列式展示的在線學習平臺很明顯無法有效實現個性化學習需求。
人工智能的快速發展和應用,給在線學習的發展帶來了契機。人工智能于1956 年被提出以來,已經在各行各業獲得了應用,人工智能在教育領域的應用也越來越受專家學者的重視,“智慧學習”已經成了一個熱門話題。運用互聯網技術和人工智能技術構建支持學習者自適應學習的智適應學習系統,是當前在線學習研究的主要方向之一。自適應學習是指滿足個性化學習需求的學習模式,智適應系統的核心功能是能根據用戶信息、資源信息和學習行為日志進行數據分析和計算,通過數據挖掘、機器學習等技術進行模型量化,再運用相關的推薦算法構建出適合學習者的最優學習路徑,從而有針對性的向用戶推薦學習資源,滿足個性化學習需求。
推薦算法是實現個性化推薦的關鍵技術,目前常用的推薦算法有基于內容的推薦算法、基于協同過濾的推薦算法、基于關聯規則的推薦算法、基于知識的推薦算法、組合推薦算法等,其中基于協同過濾推薦算法是應用最為廣泛的經典算法,也是目前智能化學習系統中主要應用的推薦算法[2]。然而在線學習平臺使用基于協同過濾推薦算法會存在數據稀疏和冷啟動問題,很多專家學者也提出了不同的解決方法。申云鳳提出將人工神經網絡算法和蟻群算法運用到用戶相似度模型構建和協同過濾推薦過程中[3];熊慧君等人提出了二次協同過濾推薦的思路[4];孫華燕等人提出了通過基于因果聚類分析和基于模糊相似關系來對協同過濾推薦算法進行改進[5]。本文研究了基于行為量化的協同過濾推薦和基于特性和內容標簽的推薦的算法組合使用,以此來實現個性化推薦,以及改善數據稀缺和冷啟動問題,并在建筑業工人移動智慧培訓平臺中進行應用。
1 基于用戶行為量化的協同過濾個性化學習推薦
1.1 基于協同過濾推薦算法原理
在推薦系統中,主要需要通過用戶行為數據或對資源的評價來判斷用戶對資源的喜好程度,并以此作為模型,對具有相似喜好的用戶進行資源推薦,這就需要基于協同過濾推薦算法來實現。基于協同過濾推薦在新聞推薦、電影推薦、商品推薦、廣告推薦中等被廣泛使用[5]。基于協同過濾算法的主要流程是首先根據用戶的行為日志或對資源的評價建立用戶模型或資源模型,再根據相似度算法尋找相似用戶或相似資源,形成推薦路徑,最后依據推薦路徑對目標用戶進行基于協同過濾的資源推薦,實現個性化推薦結果。基于協同過濾推薦的相似度計算方法主要有皮爾森相關系數計算方法、余玄相似度計算方法和修正余玄相似度計算方法等[6]。
基于協同過濾推薦主要有基于用戶的協同過濾推薦和基于資源的協同過濾推薦。基于用戶的協同過濾推薦是根據不同用戶對相同資源具有相似的評價從而建立相似用戶模型,認為其需求喜好相近,繼而將相似用戶A 曾經選擇過而相似用戶B 還沒有選擇的資源推薦給相似用戶B,從而實現個性化推薦。基于資源的協同過濾推薦則是通過資源模型來計算資源的相似度,并將相關資源推薦給選擇了與其高相似度的其他資源的用戶。一般推薦系統中,會將兩種推薦結合使用,以提高推薦的有效性和準確度。
1.2 基于用戶行為量化的協同過濾推薦流程
協同過濾推薦需要根據用戶對資源喜好度來計算用戶或資源的相似度,一般推薦系統中最直接最簡單的方法就是利用用戶對資源的評分作為計算相似度重要參數,例如影視推薦系統中對影視作品的評分。在智適應學習系統中,由于學習資源豐富,資源個數眾多,特別是基于移動學習資源碎片化后,學習用戶一次學習往往需要瀏覽多條資源,再加上學習的枯燥性和壓力性,要求學習用戶對每條瀏覽過的學習資源進行再評分非常不現實,所以無法通過直接評分的方式來計算學習用戶對學習資源的喜好。但學習用戶在對資源進行學習后,會留下學習行為日志,例如資源的點擊量、資源的瀏覽時長、資源的收藏情況、資源的下載情況等等,這些學習行為日志在很大程度上能代表學習用戶對學習資源的喜好情況。因此系統可以先對用戶學習行為進行加權量化計算用戶喜好度值[6],再計算相似度進行資源推薦。
(1)計算用戶喜好度量化值
收集并獲取智適應學習系統中學習用戶的行為記錄,確定用于量化計算的行為特征因子x,獲得行為特征向量X={x1,x2,x3,…,xn},對每個行為特征賦值量化,取值 Ci,Ci∈ [0,10],同時對每個行為特征加權 Qi,并且:

由此,可計算出某個行為特征因子xi的喜好量化權值W(xi):

系統根據用戶所有特征因子的喜好量化權值求和計算出用戶A 對資源j 的喜好值WA,j,并以此計算用戶喜好度值。
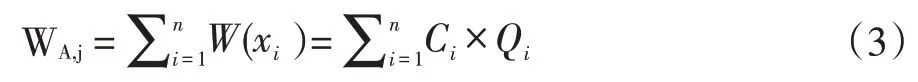
WA,j∈ [0,10],值越高,說明用戶 A 對資源 j 的喜好度越高。
(2)計算學習用戶相似度
利用公式(3)可以計算出學習用戶對學習資源的喜好度量化值,假設用戶A 對資源i 的喜好度值為WA,i,用戶A 對所有資源的喜好度平均值為,用戶 B 對資源i 的喜好度值為WB,i,用戶B 對所有資源的喜好度平均值為利用修正的余玄相似度計算方法[7],可以計算出用戶A 和用戶B 的相似度:
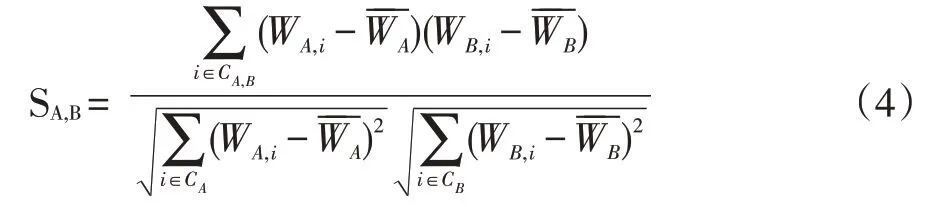
其中CA,B指用戶A 和B 有共同學習行為的資源集合,CA為用戶A 所有具有學習行為的資源集合,CB為用戶B 所有具有學習行為的資源集合。SA,B值越高,說明其相似度越高,系統以此構建學習用戶相似度模型。
(3)計算資源推薦度
要給學習用戶A 推薦資源,先通過學習用戶相似度模型計算出與A 有學習高相似度的其他用戶群體K,記為U(A,K),對K 群體已經有學習行為而學習用戶A 還沒有學習行為的學習資源i 相對于學習用戶A的推薦度可以用公式計算:
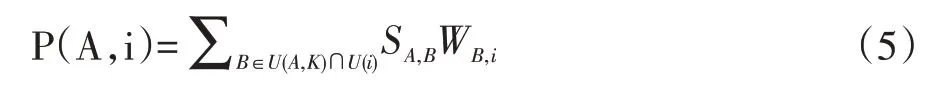
SA,B為學習用戶 A 和 B 的相似度,WB,i為用戶 B 對學習資源i 的喜好度值,U(i)為對學習資源i 有學習行為的學習用戶群體。系統根據推薦度值建立學習資源推薦列表,最終推薦給學習用戶A,實現個性化推薦。
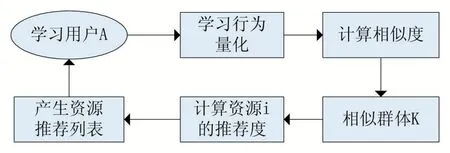
圖1 基于用戶行為量化的協同過濾推薦流程
1.3 智適應學習系統中基于協同過濾推薦應用存在的不足
在智適應學習系統中,有效應用基于協同過濾推薦的前提是要有足夠多的學習用戶學習行為記錄,用以量化并計算相似學習用戶群體。然而在現實中,大多數智適應學習系統中有效的活動學習用戶占比較少的部分,其產生的學習行為記錄稀少,而且隨著學習系統功能的更加完善、覆蓋面的更加廣泛,活動學習用戶中有交集的學習行為記錄更少,這大大降低了基于協同過濾推薦的效率和準確度,這便是基于協同過濾推薦中存在的數據稀缺問題[8]。同時,在針對新注冊用戶時,由于其初始使用而沒有任何學習行為記錄,基于協同過濾推薦更是無法計算其相似學習用戶,同樣,當系統中新添加了學習資源時,由于這些新的學習資源還沒有任何學習用戶使用過,也就沒有針對這些學習資源的學習行為記錄,基于協同推薦也無法將這些資源有效地推薦給有需要的學習用戶,這便是基于協同過濾推薦存在的冷啟動問題[8]。基于協同過濾推薦的數據稀缺和冷啟動缺陷會給智適應學習系統中的個性化資源推薦帶來不利影響。為了有效解決數據稀缺和冷啟動的缺陷問題,可以在基于協同過濾推薦的同時組合使用基于特性和內容的標簽推薦來實現全面個性化學習推薦。
2 基于特性和內容標簽推薦的個性化學習推薦
基于特性和內容的標簽推薦來實現個性化學習推薦,可以有效解決智適應學習系統中當新注冊學習用戶登錄或學習行為日志偏少用戶登錄時,因學習日志缺少,系統無法根據其過往行為來分析和判斷其學習偏好而無法進行基于協同過濾推薦的問題。智適應學習系統在學習資源建設時,需對每個資源設置主要標簽,例如課程名、知識點、授課教師、關鍵字等,以此來建立資源的特性和內容特征,同時在注冊新學習用戶時,為每位學習用戶建立初始學習偏好標簽,如專業、課程等,以此來建立學習用戶初始學習偏好模型。通過對學習偏好模型和資源的特性和內容特征進行相似度計算,實現個性化資源的推薦。
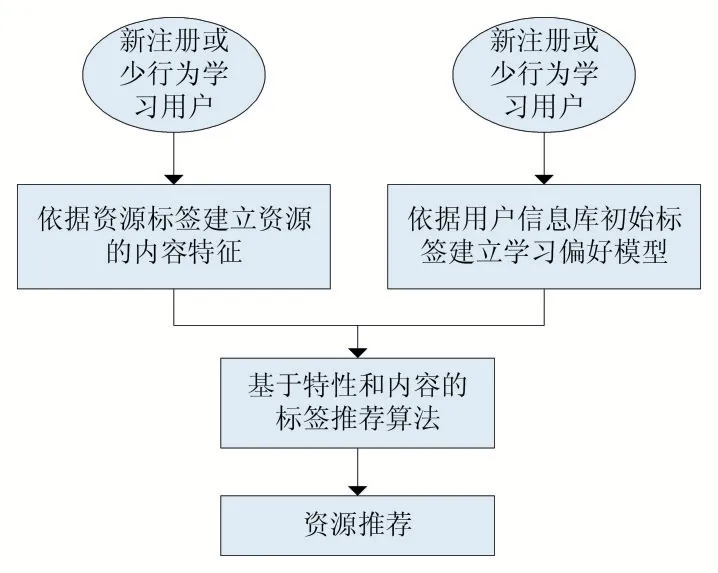
圖2 基于特性和內容標簽推薦的個性化學習推薦流程
學習用戶的初始學習偏好標簽和學習資源標簽均包含兩個方面,一是特性標簽,代表資源的分類,例如課程名、授課教師、專業對象等,一是內容標簽,代表具體的內容特征,例如內容關鍵字等。特性標簽的推薦約束優先于內容標簽的推薦約束。系統進行標簽推薦時,首先匹配特性標簽,當學習偏好中的特性標簽和資源的特性標簽直接匹配上時,系統將其標記為優先推薦大類,然后在此基礎上,再進行內容標簽的相似度計算,得出更精確的推薦路徑。
取數據庫中用戶初始學習偏好內容標簽,建立特征向量 S={t1,t2,t3,…,tn},其中 S 表示學習用戶,tn表示第n 個標簽特征。系統為每個標簽特征賦權重,權重向量M={wt1,wt2,wt3,…,wtn},wtn表示標簽 tn的權重。學習用戶的初始學習偏好特征向量T(s)可以通過求所有標簽權重的平均值獲得[9]。

資源的內容標簽中相同的標簽在不同的資源中具有的權重應有不同,例如關鍵字“算法”在編程類學習資源中的權重與在管理類學習資源中的權重就明顯不同,故系統不能對每個關鍵字標簽的權重進行初始化賦值。詞頻-逆向文件頻率(TF-IDF)是用來計算學習資源內容標簽的特征向量權重的比較好的方法[10]。
詞頻TF(ti,cj)表示學習資源cj中標簽ti出現的頻次mij與所有各學習資源中ti出現的最大頻次Max(mi)的比值,取值范圍為[0,1],算式如下:

逆向文件頻率IDF(ti)通過取學習資源總數K 與出現標簽ti的學習資源數量k(ti)比值的對數來表示,算式如下:

學習資源cj中標簽ti的TF-IDF 權重w(ti,cj)表示為:
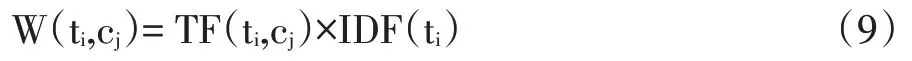
學習資源cj的標簽權重值W(cj)可以表示為特征向量:
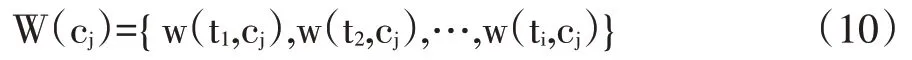
采用余玄相似度計算學習用戶初始學習偏好特征向量T(s)和學習資源特征向量W(cj)進行相似度,相似度越高,說明推薦度越高,以此來取最佳的推薦路徑,進行資源推薦。余玄相似度計算公式為:
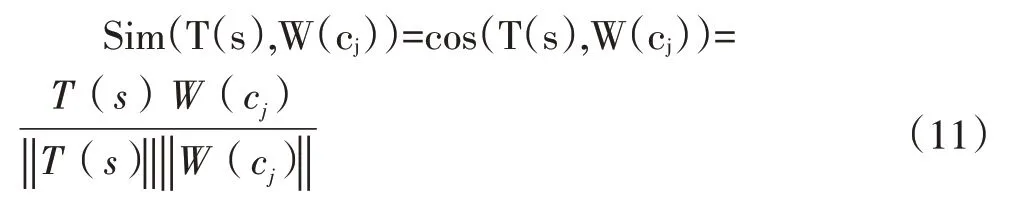
基于特性和內容的標簽推薦算法能有效的解決數據稀缺和冷啟動帶來的資源推薦困難問題,能夠對新注冊用戶以及少學習行為學習用戶的智適應學習進行比較準確的個性化資源推薦,享受智慧學習帶來的便捷和效率。相比傳統的基于內容推薦算法,基于特性和內容的標簽推薦算法因標簽的提前設定從而大大降低了數據挖掘和分析計算的壓力,大大提高了算法的運算效率,降低了平臺的運行能耗,同時特性標簽的應用,有利于學習資源的精確分類,對單純需要特性標簽推薦的學習用戶可以實現直接的分類推薦,特別對音視頻、動畫、虛擬實驗類等非純文本學習資源的推薦有效,對基于內容標簽推薦的學習用戶,也能較大范圍地提高資源推薦的準確性。
3 個性化學習推薦案例應用
建筑業工人移動智慧培訓平臺是一套針對建筑行業從業工人職業教育和技能培訓的智適應系統,系統面向建筑業工人,主要提供現場管理、安全生產、崗位技能、特種作業、技能鑒定等初、中、高級的理論知識培訓和技能操作模擬實驗培訓。培訓平臺主要有智慧學習、練習測試、系統管理三大塊功能,分別提供移動遠程個性化學習、在線遠程練習及模擬測試、學習資源和用戶管理以及系統管理等操作。建筑業工人由于普遍存在知識水平低、學習判斷和選擇能力弱等問題,在傳統的在線自主學習過程中存在較大的困難,無法達到較好的學習效果,因此個性化學習推薦尤為重要。我們分別在建筑業工人移動智慧培訓平臺的智慧學習和練習測試模塊應用了基于協同推薦加基于特性和內容的標簽推薦的組合推薦方法。
在智慧學習模塊中,系統主要通過學習行為日志中的學習資源的點擊次數、瀏覽時長、收藏情況和點贊情況來作為培訓用戶培訓偏好度量化計算的主要因子。各因子分別量化為0~10 之間的數值,其中點擊次數、瀏覽時長根據具體數量折算,而收藏情況和點贊情況設成是非條件,有收藏和點贊則獲10 分,沒有則獲0分,同時對每個因子加權分別為 0.3、0.3、0.2、0.2,最后計算出培訓用戶的喜好度值,并以此作為計算相似度的依據,通過基于協同的過濾推薦來實現個性化資源推薦。系統同時對培訓資源設置特性和內容標簽,特性標簽主要包括類別、專業方向、科目、所屬知識點、培訓教師、適用對象等,內容標簽主要為學習內容中的具體關鍵字,例如安全法規、BIM、CAD、市政施工等,培訓用戶在注冊時,要求根據其主要的培訓方向和需求選擇相應的特性和內容標簽,存入信息庫,系統根據培訓用戶和培訓資源對應的特性和內容標簽,通過基于特性和內容的標簽推薦實現個性化推薦。
練習測試模塊主要涉及試題的抽取及組卷,在線練習測線系統一般通過隨機、基于遺傳或蟻群算法等完成組卷,單純依賴系統中提前設置好的規則,缺乏個性化特征。建筑業工人移動智慧培訓平臺的練習測試模塊中通過在遺傳算法中組合使用個性化推薦算法進行組卷,將通過基于推薦算法計算出的推薦值作為遺傳算法中的約束條件之一,從而實現個性化的組卷。系統將試題的練習次數、出錯率、重要性權重、對應知識點的學習用戶學習偏好度值等作為試題推薦度值計算的重要因子,計算出其推薦度值,再配合時長約束、難易度約束、題型約束、分值約束等條件,運用遺傳算法進行初始化、選擇、交叉和變異,生成符合組卷策略并滿足個性化需求的試卷。
通過對建筑業工人移動智慧培訓平臺的使用調查發現,其中89 名系統新注冊用戶初始使用學習資源推薦準確度高達95.2%,且注冊時特性和內容標簽設置越全面其推薦準確度越高;306 名經常活動學習用戶個性化學習資源推薦準確度為89.7%;練習測試環節通過個性化推薦遺傳算法組卷和常規遺傳算法組卷對比實驗,59.8%的學習用戶表示針對性有所提高,27.1%的學習用戶表示無法判斷,其余表示沒區別。從數據中可以看到,基于協同推薦加基于特性和內容的標簽推薦的組合推薦在智適應學習平臺的個性化學習資源推薦中效果明顯。
4 結語
智適應學習系統中學習資源高效、準確的個性化推薦,是其“智慧學習”的重要表現,個性化學習資源推薦能滿足學習用戶多元化的學習需求,提高學習效率和學習質量。個性化學習資源的推薦是當前在線學習平臺研究的主要方向之一,推薦算法是實現個性化推薦的關鍵。單純采用基于協同的過濾推薦存在數據稀缺和冷啟動的缺陷,本文研究在基于學習用戶學習行為記錄量化的協同過濾推薦的同時組合使用基于特性和內容的標簽推薦方法,以提高個性化推薦的質量。通過在建筑業工人移動智慧培訓平臺中的智慧學習模塊和練習測試模塊中的應用分析,證明文中研究的方法確實有效。本文對推薦算法本身的改進研究不足,下一步將繼續研究改進推薦算法和智能算法聯合提高推薦效率的問題。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
辦公室業務(2020年18期)2020-09-29 12:15:58
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
勞動保護(2019年7期)2019-08-27 00:41:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
臺聲(2016年2期)2016-09-16 01:06:53
體育師友(2011年5期)2011-03-20 15:29:53
英語學習(2008年9期)2008-12-31 00:00:00
