基于Weka的軟件缺陷預測研究與應用
2020-05-19 05:11:37郭江峰曲豫賓
河南科技 2020年8期
關鍵詞:機器學習
郭江峰 曲豫賓
摘 要:在軟件開發過程中,軟件缺陷預測能預先識別存在的潛在缺陷模塊,大幅減少測試所需的人力、物力,優化測試資源分配,提高測試效率和軟件產品質量。軟件缺陷預測技術不僅具有重要的研究意義,更具有重要的應用價值。基于Weka數據挖掘平臺,本研究使用NASA缺陷數據集進行了軟件缺陷預測,在合理選擇機器學習算法、科學設置參數的情況下,取得了良好的軟件缺陷預測結果。
關鍵詞:軟件缺陷預測;度量元;機器學習;Weka
中圖分類號:TP311.52文獻標識碼:A文章編號:1003-5168(2020)08-0014-05
Research and Application of Software Defect Prediction Based on Weka
GUO Jiangfeng1,2 QU Yubin1
(1.Jiangsu College of Engineering and Technology,Nantong Jiangsu 226007;
2.Kizilsu Vocational Technical College,Atushi Xinjiang 845350)
Abstract: In the process of software development, software defect prediction can identify the potential defect modules in advance, greatly reduce the human and material resources needed for testing, optimize the distribution of testing resources, and improve the testing efficiency and software product quality. Software defect prediction technology not only has important research significance, but also has important application value. Based on Weka data mining platform, the software defect prediction was carried out by using NASA defect data set in this study, and good software defect prediction results were obtained under the condition of selecting machine learning algorithm reasonably and setting parameters scientifically.
Keywords: software defect prediction;metrics;machine learning;Weka
隨著科學技術和社會經濟的快速發展,計算機技術在各個行業得到了廣泛應用,計算機軟件(系統)與人們的工作、生活也越來越緊密,軟件質量和系統可靠性對生產和管理活動的效率和安全性的影響也越來越大[1]。但是,隨著人們對軟件需求的不斷增長,軟件規模變大,復雜程度增加,軟件的開發與維護難度越來越大。隱含缺陷的軟件在運行過程中可能會產生軟件失效或系統崩潰,嚴重的軟件缺陷會給企業帶來巨額的經濟損失,甚至可能引發人員傷亡[1-2]。
用戶需求不明確、軟件開發過程不規范、軟件開發人員經驗與能力不足等原因,均會導致軟件缺陷的產生。為保證軟件質量,軟件測試人員會通過一定的軟件測試方法對軟件缺陷進行排查,然后通知開發人員對軟件缺陷進行處理。然而,受軟件項目的開發進度和成本控制等實際因素的影響,軟件測試工程師無法對所有軟件模塊進行完全覆蓋測試。
1 軟件缺陷預測的定義與研究意義
隨著人們對計算機軟件的依賴程度越來越大,如何有效提高軟件質量成為軟件工程領域研究的重點和難點。傳統的軟件質量保障手段(如靜態代碼審查或動態軟件測試)效率低下,需要大量的人力、物力,而且需要額外對代碼進行插樁等修改操作[3]。軟件缺陷預測技術逐漸成為軟件工程領域的研究熱點之一[4-12]。
軟件缺陷預測,一般是指通過分析軟件源代碼或開發過程,設計出與軟件缺陷存在相關性的度量元,然后對軟件歷史倉庫進行挖掘分析來創建缺陷預測數據集。基于缺陷預測數據集,使用特定的建模方法(如機器學習)構建缺陷預測模型,基于預測模型對軟件后續版本中的潛在缺陷模塊進行預測分析[13]。
軟件缺陷預測能大幅度減少測試所需的人力、物力,并且無須額外對代碼進行插樁等修改操作。軟件部署前、模塊開發結束后可以及時開展缺陷預測,預先識別出潛在缺陷模塊,便于項目主管優化測試資源分配,提高測試效率和軟件產品質量。因此,研究軟件缺陷預測技術,構建軟件缺陷預測模型,提前預測識別軟件中的缺陷,不僅具有重要的研究意義,更具有重要的應用價值。
2 軟件缺陷預測方法
根據軟件缺陷預測方法的不同,可將其分為靜態預測和動態預測[6]。靜態預測主要將軟件代碼量化為靜態特征,對這些特征和歷史缺陷信息進行統計分析,挖掘歷史缺陷的分布規律并構建預測模型,然后基于預測模型對新的程序模塊進行預測。動態預測則是對軟件缺陷發生的時間進行分析,挖掘軟件缺陷與其發生時間之間的關聯。目前,隨著機器學習算法的廣泛應用,靜態軟件缺陷預測不斷取得良好的預測結果,受到了研究者的更多關注[14-15]。
2.1 軟件缺陷預測過程
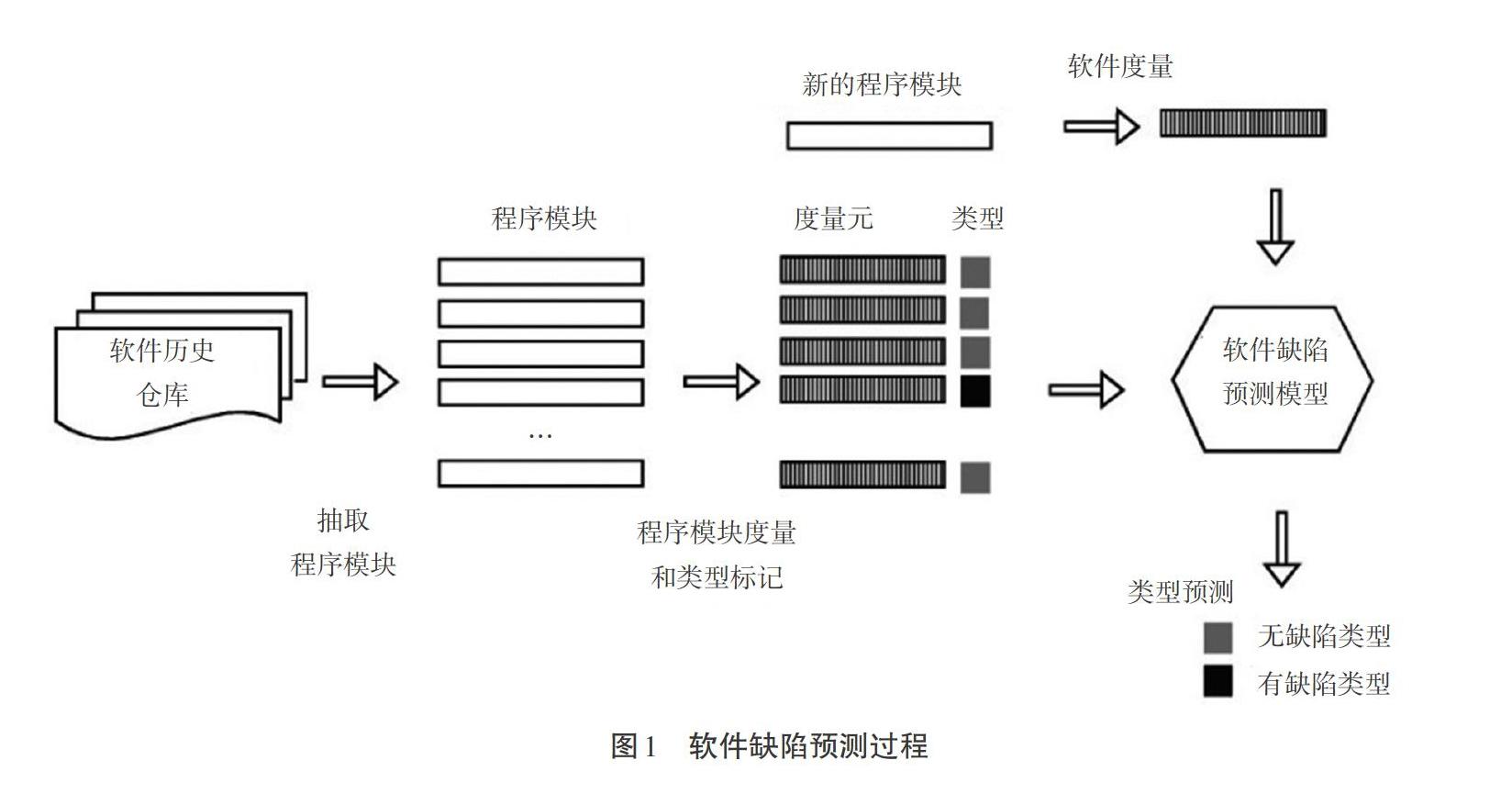
軟件缺陷預測過程可分為四個階段,如圖1所示[16]。
2.1.1 程序模塊抽取。對軟件歷史倉庫進行挖掘分析,從中抽取出程序模塊。程序模塊的粒度可設置為文件、包、類、函數等。抽取出模塊后,將這些程序模塊分別標記為有缺陷模塊或無缺陷模塊。
2.1.2 設計度量元。基于軟件靜態代碼或軟件開發過程,設計相應的度量元,通過這些度量元對程序模塊進行軟件度量,并構建出缺陷預測數據集。
2.1.3 構建缺陷預測模型。對缺陷預測數據集進行必要的數據預處理之后,借助特定的建模方法(如機器學習方法)構建出軟件缺陷預測模型。
2.1.4 缺陷預測。使用構建好的軟件缺陷預測模型對新程序模塊進行預測分類,將程序模塊預測為有缺陷傾向性模塊或無缺陷傾向性模塊。預測目標也可以是程序模塊含有的缺陷數或缺陷密度。
2.2 度量元設計
度量元的設計是軟件缺陷預測研究中的核心問題[17]。典型的度量元包括代碼行數、McCabe環路復雜度和Halstead科學度量等。將McCabe環路復雜度作為度量元主要考慮程序的控制流復雜度,其假設條件是如果程序模塊的控制流復雜度越高,含有缺陷的可能性也越高[18]。將Halstead科學度量作為度量元主要考慮程序內操作符和操作數的數量,其假設條件是如果程序模塊中的操作符和操作數越多,導致代碼的閱讀難度越大,含有缺陷的可能性越高[19]。
除了基于軟件代碼設計度量元之外,部分研究者基于軟件開發過程進行度量元的設計[20-21]。基于軟件開發過程主要考慮軟件項目管理、開發人員經驗、代碼修改特征等方面。基于哪一種方式設計度量元更能有效構建缺陷預測模型,研究人員對此進行了比較研究。Graves[22]、Moser[21]等人研究認為,基于開發過程設計出的度量元更為有效。而Menzies[23]等人研究認為,基于靜態代碼的度量元可以構建出高質量的缺陷預測模型。可以看出,兩者并無明顯的優劣之分,合理地設計度量元,都能取得良好的預測效果。
2.3 缺陷預測模型構建與應用
在構建缺陷預測模型之前,根據數據集的質量,可能需要先進行缺陷預測數據集的預處理。這是因為數據集可能存在噪聲、維數災難和類不平衡等問題,預處理可以提高數據集的質量[24]。
數據集經過預處理后,借助一定的算法來構建缺陷預測模型。作為人工智能和數據科學核心的機器學習,在軟件缺陷預測領域得到了廣泛應用,通常被選用為構建軟件缺陷預測模型的算法。常用于軟件缺陷預測的機器學習方法可分為分類方法和回歸方法。分類方法主要包括分類回歸樹、樸素貝葉斯、K-最近鄰、支持向量機、集成學習和聚類分析等;回歸方法主要包括線性回歸、多項式回歸、逐步回歸和彈性回歸等。
使用構建的軟件缺陷預測模型,就可以對新數據(測試集)進行測試并得出預測結果,預測目標可以是模塊內是否含有缺陷、含有的缺陷數量或缺陷密度等。
3 基于Weka的軟件缺陷預測應用
Weka是由新西蘭懷卡托大學開發的數據挖掘工具,內含了大量的機器學習算法,可以實現數據的預處理、分類、回歸、聚類、關聯規則以及可視化等功能。
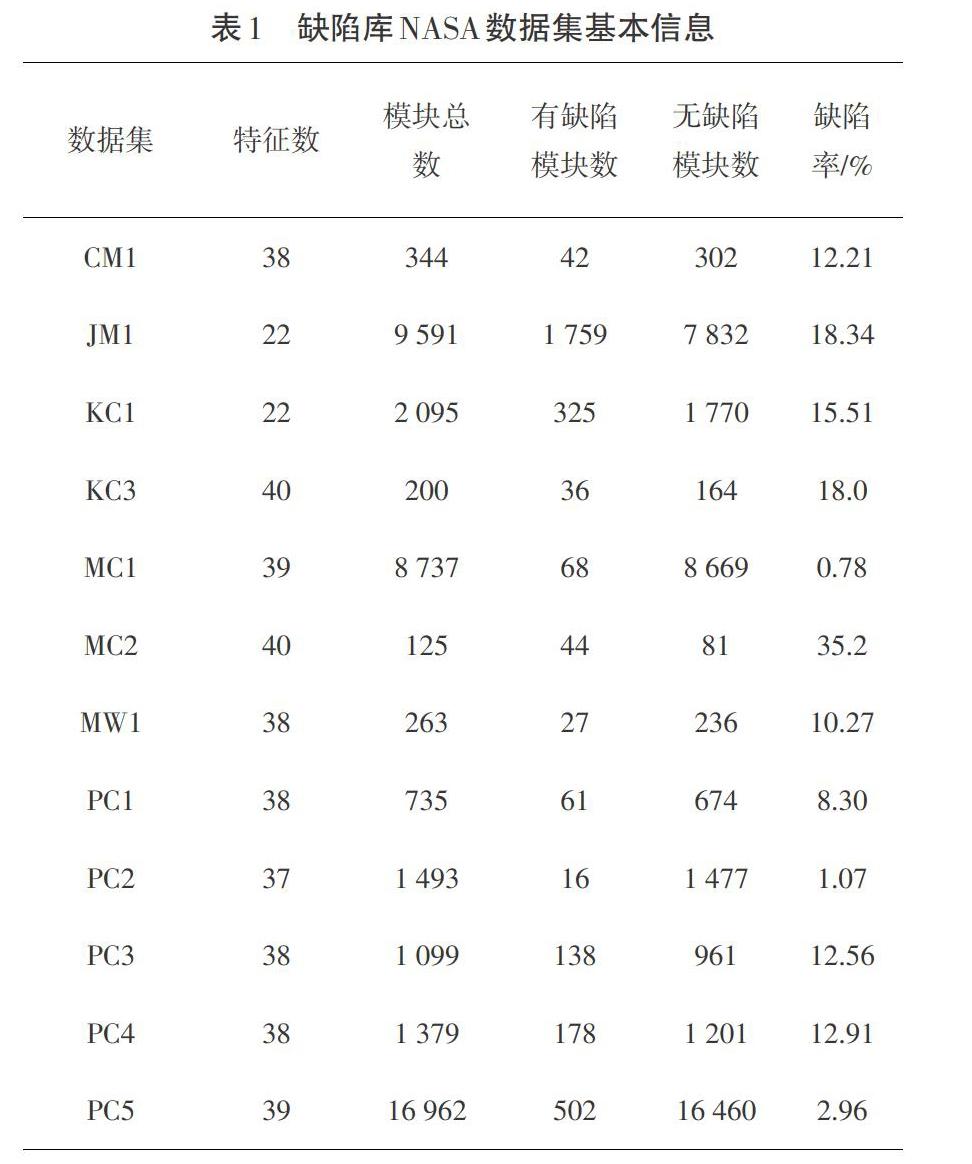
本文試驗數據采用美國國家航空航天局(NASA)缺陷數據集。里面包括12個項目的缺陷數據集,其中每個數據集都對軟件系統中的功能模塊進行了標記,分別標記為有缺陷模塊和無缺陷模塊。數據集的缺陷率為0.78%~35.2%,數據集的模塊總數范圍為125~16 962,數據集基本信息如表1所示。
3.1 數據集加載與預處理
在“Preprocess”選項卡中,單擊“Open file”命令按鈕,選擇指定的數據集。Weka默認的數據格式為“*.arff”。
加載完數據集后,如果數據集中問題數據較多,則不能直接進行數據挖掘模型的訓練和學習,必須進行數據預處理。數據預處理一般可分為數據清理、數據集成、數據變換、數據歸約4個方面。這些預處理都可以使用Weka提供的過濾器(Filter)來實現,Filter又可分為非監督學習和監督學習兩種過濾器。
3.2 指定分類器
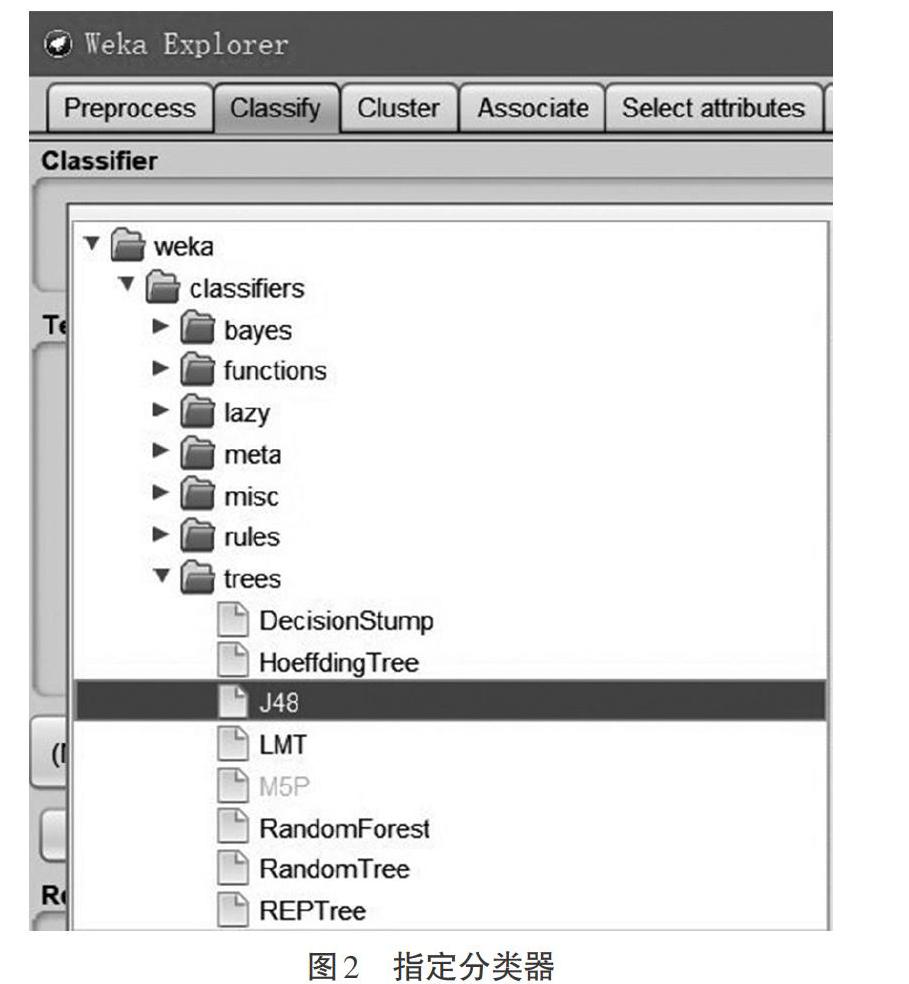
選擇“Classify”選項卡,點擊“Choose”按鈕,展開“Classifiers”后可以看到bayes、functions、lazy、meta、misc、rules、trees,共7種類型,每種類型又包括多種具體的分類或回歸算法,如圖2所示。鼠標左鍵點擊“Choose”按鈕右側的文本框,出現“GenericObjectEditor”對話框,可以在對話框中為各算法指定具體參數,不同的參數值對算法性能具有重要影響。
本次試驗選擇軟件缺陷預測研究中經常采用的決策樹法分類器,在圖2中展開“trees”列表,選擇其中的“J48”。
3.3 構建軟件缺陷預測模型
為評估軟件缺陷預測模型的性能,需要通過“Test Option”來指定測試模式。Weka共提供了4種測試模式,分別為“Using training set”“Supplied test set”“Cross-validation”和“Percentage split”。
本次試驗采用交叉驗證模式(Cross-validation)。將“Folds”參數指定為“10”,即進行10折交叉驗證。在該參數設置下,將數據集隨機劃分為10份,輪流將其中的9份作為訓練數據,剩余1份作為測試數據[16]。循環10次,取這10次運行結果的平均值作為模型的預測性能。
點擊“Start”按鈕,使用訓練數據對算法進行訓練并生成相應的預測模型。
本次試驗生成決策樹模型,如圖3所示。在右側的“Classifier output”中,顯示用文本表示的決策樹、準確率及誤差分析等結果。同時,左下角的“Results list”出現了一個列表項,顯示生成時間和算法名稱。在分類結果中,顯示出混淆矩陣,如圖4所示。
通過混淆矩陣可以看出,缺陷數據集中178個“Defective”屬性被標記為有缺陷的模塊,其中104個被正確預測為有缺陷、有74個被錯誤預測為無缺陷。數據集中1 201個“Defective”屬性被標記為無缺陷的模塊,其中,78個被錯誤預測為有缺陷,有1 123個被正確預測為無缺陷。矩陣左上到右下對角線上的數字越大,說明預測的準確度越好。在結果列表中,鼠標右擊選中結果項,在出現的快捷菜單中選擇“Visualize tree”,可以圖形化顯示生成的決策樹。
3.4 預測軟件缺陷
軟件缺陷預測模型生成之后,就可以對待預測的數據集進行預測。值得注意的是,待預測數據集和訓練用數據集的屬性設置要保持一致。
在“Test Opion”中選擇“Supplied test set”,點擊“Set”按鈕,在出現的“Test Instances”對話框中指定要應用模型的數據集。右鍵點擊“Result list”中剛產生的列表項,選擇“Re-evaluate model on current test set”。預測模型將對測試數據集進行預測,結果顯示在右側區域,如圖5所示。可以看出,在選用合適的機器學習算法的基礎上,預測正確率達到了96.12%,效果良好。
4 結論
軟件缺陷預測能預先識別出軟件中的潛在缺陷模塊,大幅度減少測試所需的人力、物力,優化測試資源分配,提高測試效率和軟件產品質量。度量元的設計是軟件缺陷預測研究中的核心問題,設計與軟件缺陷存在強相關性的度量元可以顯著提高預測模型質量。靜態軟件缺陷預測可基于軟件代碼或者軟件開發過程設計度量元。人們可以借助Weka數據挖掘工具,合理選擇機器學習算法,設置相關參數,構建出實用的軟件缺陷預測模型,進而對軟件缺陷實施預測。由于不同軟件項目具有不同的開發流程和編程語言等特性,如何在數據集間存在較大差異的情況下提升軟件缺陷預測方案的有效性、開展跨項目的軟件缺陷預測,值得進一步的研究。
參考文獻:
[1]于巧.基于機器學習的軟件缺陷預測方法研究[D].北京:中國礦業大學,2017.
[2]沈鵬.基于機器學習的軟件缺陷預測方法研究[D].重慶:西南大學,2019.
[3]陳翔,顧慶,劉望舒,等.靜態軟件缺陷預測方法研究[J].軟件學報,2016(1):1-25.
[4]Kanmani S,Uthariaraj V R,Sankaranarayanan V,et al.Object-oriented software fault prediction using neural networks[J].Information and Software Technology,2007(5):483-492.
[5]Elish K O,Elish M O.Predicting defect-prone software modules using support vector machines[J].Journal of Systems and Software,2008(5):649-660.
[6]王青,伍書劍,李明樹.軟件缺陷預測技術[J].軟件學報,2008(7):1565-1580.
[7]羅云鋒,賁可榮.軟件故障靜態預測方法綜述[J].計算機科學與探索,2009(5):449-459.
[8]Arisholm E,Briand L C,Johannessen E B.A systematic and comprehensive investigation of methods to build and evaluate fault prediction models[J].Journal of Systems and Software,2010(1):2-17.
[9]Catal C.Software fault prediction:A literature review and current trends[J].Expert Systems withApplications,2011(4):4626-4636.
[10]Hall T,Beecham S,Bowes D,et al.A systematic literature review on fault prediction performance in software engineering[J].IEEE Transactions on Software Engineering,2012(6):1276-1304.
[11]Laradji I H,Alshayeb M,Ghouti L.Software defect prediction using ensemble learning on selected features[J].Information and Software Technology,2015(58):388-402.
[12]Zhang F,Zheng Q,Zou Y,et al.Cross-project defect prediction using a connectivity-based unsupervised classifier[C]//Proceedings of the 38th International Conference on Software Engineering.2016.
[13]陳翔,王莉萍,顧慶,等.跨項目軟件缺陷預測方法研究綜述[J].計算機學報,2018(1):254-274.
[14]Menzies T,Greenwald J,Frank A.Data mining static code attributes to learn defect predictors[J].IEEE Transactions on Software Engineering,2007(1):2-13.
[15]Li L,Leung H.Mining static code metrics for a robust prediction of software defect-proneness[C]//Proceedings of the International Symposium on Empirical Software Engineering and Measurement.LosAlamitos,CA:IEEE Computer Society.2011.
[16]陳翔,賀成,王宇,等.HFS:一種面向軟件缺陷預測的混合特征選擇方法[J].計算機應用研究,2016(6):1758-1761.
[17]Radjenovic D,Hericko M,Torkar R,et al.Software fault prediction metrics:A systematic literature review[J].Information and Software Technology,2013(8):1397-1418.
[18]McCabe T J.A complexity measure[J].IEEE Transactions on Software Engineering,1976(4):308-320.
[19]Halstead M H.Elements of Software Science (Operating and Programming Systems Series)[M].New York:Elsevier Science Inc.,1978.
[20]N Nagappan,T Ball.Use of Relative Code Churn Measures to Predict System Defect Density[C]//In Proceedings of the International Conference on Software Engineering.2005.
[21]R Moser,W Pedrycz,G Succi.A Comparative Analysis of the Efficiency of Change Metrics and Static Code Attributes for Defect Prediction[C]//In Proceedings of the International Conference on Software Engineering.2008.
[22]T Graves,A Karr,J Marron,et al.Predicting Fault Incidence using Software Change History[J].IEEE Transactions on Software Engineering,2000(7):653-661.
[23]T Menzies,J Greenwald,A Frank.Data Mining Static Code Attributes to Learn Defect Predictors[J].IEEE Transactions on Software Engineering,2007(1):2-13.
[24]M Shepperd,Q Song,Z Sun,et al.Data Quality:Some Comments on the NASA Software Defect Datasets[J].IEEE Transactions on Software Engineering,2013(9):1208-1215.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
