基于Q-learning及其改進算法的信道決策方法
2020-05-18 12:02:34馬海波俞力周新馮熳
現代信息科技 2020年20期
馬海波 俞力 周新 馮熳
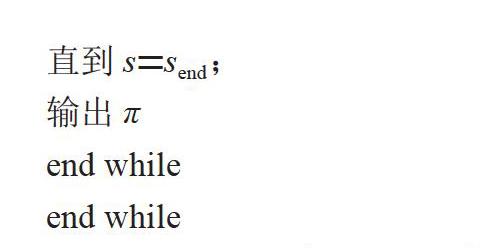


摘? 要:信道決策是智能抗干擾通信系統的重要組成部分。針對信道決策問題,文章提出一種基于Q-learning及其改進算法的決策方法,在干擾類型及信道模型未知的情況下,通過和信道交互完成信道決策;針對固定模式干擾情況下收斂速度慢的問題,進一步提出一種改進的Q-learning算法。實驗結果表明,與傳統頻率自適應系統相比,通過學習干擾系統的信道切換策略直接切換到未被干擾的信道,可有效減少信道反饋時間,提高工作效率。
關鍵詞:信道決策;智能通信;抗干擾通信
中圖分類號:TN925;TN972? ? ? 文獻標識碼:A 文章編號:2096-4706(2020)20-0081-04
Channel Selection Strategy Method Based on Q-learning and Its Improved Algorithm
MA Haibo1,YU Li1,ZHOU Xin2,FENG Man2
(1.Purple Mountain Laboratories,Nanjing? 211111,China;
2.School of Information Science and Engineering,Southeast University,Nanjing? 211096,China)
Abstract:Channel selection strategy (CSS) plays an important role in intelligent anti-jamming communication systems. Aiming at the problem of CSS,this paper proposes a selection strategy method based on Q-learning and its improved algorithm. When the interference type and channel model are unknown,the CSS is completed by interacting with the channel. Aiming at the problem of slow convergence speed under fixed mode interference,an improved Q-learning algorithm is further proposed. The experimental results show that compared with the traditional frequency adaptive system,the channel feedback time can be effectively reduced and the efficiency can be improved by learning the channel switching strategy of the interference system directly switch to the undisturbed channel.
Keywords:channel selection strategy;intelligent communication;anti-jamming communication
0? 引? 言
面向移動通信5G和6G發展需求,開展具有全覆蓋、全頻譜、全應用和強安全特征的6G先期研究,突破天地融合大規模無線傳輸技術,發展融合大數據與人工智能的智能通信技術,在移動通信領域重大基礎理論創新和關鍵核心技術等方面取得突破是紫金山實驗室普適通信方向的主要聚焦點。在這樣的背景下,作者在從事無線移動通信領域系統架構設計、5G通信物理層研究的相關工作過程中認識到,要實現智能、安全通信,信道決策是重要的環節,也是高頻譜利用率和通信質量的關鍵。所謂信道決策,即,通過頻譜感知技術,利用信道反饋信息更新調頻頻點,以達到規避干擾的目的。然而,傳統的信道決策方法在每次發射信號前都要對信道進行檢測和反饋,工作效率低下,不能滿足實時、高效的抗干擾通信要求[1,2]。
隨著人工智能技術的不斷進步,機器學習等智能算法在信道決策領域有了大量的研究與應用。其中,強化學習作為一種自學習系統,能夠解決分布式參數優化的問題[3-5],因此,Tao Liang團隊將強化學習應用于信道決策中,通過引入預分配和基于權重的兩種機制來提高學習效率,得到優于傳統強化學習的信道選擇性能[6];在干擾和信道模型未知的情況下,Liang Xiao等人設計了一種基于Q-learning的功率控制算法,網絡中的次級用戶通過和無線網絡不斷交互,進而利用反饋更新功率參數[7]。Youngjune Gwon等通過采用Q-learning算法學習信道質量,得到最佳介入信道以主動躲避干擾信道[8]。Chen Han等人則是對信道和功率聯合控制,其中干擾機可以調整干擾策略,獲得最大干擾效果,通信方通過在物理層和MAC層選擇傳輸節點和信道,通過跨層Q-learning獲得最優信道及功率的組合[9]。綜上,目前強化學習算法在智能信道決策領域已有了廣泛應用[10-15]。
基于以上描述,本文旨在基于強化學習算法進行干擾信道選擇策略,從而實現對干擾的有效回避。然而,在實際的干擾與抗干擾問題中,通信信道的切換都需要一定時間的觀察才能夠確定對方下一時刻的通信信道,這就錯過了最佳的時機。因此,本文在Q-learning算法的基礎上,提出一種改進算法,以實現實時、高效的抗干擾通信。
1? 信道決策模型
考慮一個典型的抗干擾通信系統,其中包括發射機、干擾機、接收機以及無線信道,系統信道按時隙劃分,在通信過程中不考慮干擾類型并且頻譜感知結果正確。假設系統的傳輸頻段被均勻劃分為M個帶寬相等的信道,即,信道的集合可以記為{0,1,2,3,…,M-1}。由于發射機和干擾機的發射功率有限,每次切換信道時默認只選擇其中一個信道進行通信或干擾。用戶通過頻譜感知技術獲得信道的狀態,進而利用強化學習算法學習干擾方的信道切換模式,通過避開干擾信道,最終實現抗干擾效果。
假設用戶和干擾方每隔時間T更換一次信道,用戶和干擾的時隙結構如圖1所示,用戶在τ1時間內進行信道決策并發射信號,τ2時間內用戶通過頻譜感知獲取干擾信號的信道信息,τ3時間內根據所獲取的干擾信道信息進行Q表更新。
若當前時刻用戶的通信信道為Ci,由用戶通過頻譜感知得到的干擾信道為Cj,則當前的狀態s可記為
(1)
若干擾未成功,則獎勵為1;否則,獎勵為-1。
2? 基于Q-learning的信道決策算法
在強化學習中,Q-learning是一種離線算法,該算法中存在兩個控制策略,一個策略用于選擇新的動作,另一個策略用于更新價值函數。簡單來說,Q-learning會觀察狀態s下獲得最大獎勵的動作,但不一定會執行該動作,仿真參數如表1所示,Q-learning用于信道決策的流程算法如下:
對于環境中所涉及的狀態s∈S以及可能采取的動作a∈A,令Q(s,a)=0,π(s,a)=,其中s=
while
通信方感知信道的狀態s=s0;
while
從[0,1]中產生一個隨機數rand,若rand<ε,則通信方從動作空間內隨機產生一個頻點a,否則令a=π(s),ε為探索率;
當通信方執行結束這個動作后,通過頻譜感知技術得到信道反饋,給出即時獎勵? ,此時信道狀態變為s*;
令a*=π(s*),表示在狀態s*時策略π給出的動作;
更新值函數,令
Q(s,a)=(1-α)Q(s,a)+α(+γQ(s*,a*));
更新當前策略,令
π(s)=;
更新信道信息,令s=s*;
直到s=send;
輸出π
end while
end while
2.1? 固定模式干擾
干擾方會按固定的順序選擇下一時刻的干擾信道,其信道切換策略表達式為:
Cj=(Cj+2)mod 10? ? ? ? ? ? ? ? ? ? ? ? ? (2)
固定模式干擾下系統的仿真結果如圖2和圖3所示。
由仿真結果可以看出,基于Q-learning的信道決策算法可以通過和環境的交互實現干擾規避。并且,干擾方具備頻譜感知能力,其信道切換是以未成功干擾為前提,因此需要較長的時間才可以完成所有狀態值的更新,由圖3所示的收斂結果也可以看出,大約訓練220次達到規避干擾的效果。
2.2? 隨機模式干擾
即干擾方每個時隙都生成一個隨機數rand∈[0,1],再根據rand值選擇下一個信道。式(3)給出了隨機模式干擾下的信道更新策略,圖4為該模式下學習前后的時頻圖。圖5給出了收斂結果,可以看出,學習大約200次左右可以完全規避干擾。
3? 改進的Q-learning算法
上述算法雖然均可取得滿意的信道決策效果,但收斂速度較慢,在實際中很難應用。針對該問題,本節針對固定模式干擾,提出一種改進的Q-learning算法。假設系統中干擾方僅選擇一個信道發射干擾信號,在判斷是否干擾成功時,不僅可以對當前的信道進行判斷,也可對其他信道進行判斷,即根據信道反饋的結果給出的獎勵不僅僅是當前信道的獎勵,而是所有信道的獎勵rt,t={0,1,2,3,…,M-1},然后利用獎勵值對Q函數進行更新,有效提高了系統的運行速度。所提出的改進Q-learning算法流程具體算法如下:
對于環境中所涉及的狀態s∈S以及可能采取的動作a∈A,令Q(s,a)=0,π(s,a)=,其中s=
while
通信方感知信道的狀態s=s0;
while
從[0,1]中產生一個隨機數rand,若rand<ε,則通信方從動作空間內隨機產生一個頻點a,否則令a=π(s);
當通信方執行結束這個動作后,通過頻譜感知技術得到干擾頻點Cj,此時信道狀態變為s*;
令a*=π(s*),表示在狀態s*時策略π給出的動作;
for t=0:m-1
if Ct=Cj
rt=-1
else rt=1
s′=
更新值函數,令
Q(s,a)=(1-α)Q(s,a)+α(rt+γQ(s′,a*));
end if
end for
更新當前策略,令
π(s)=;
更新信道信息,令s=s*;
直到s=send;
輸出π;
end while
end while
圖6給出了Q-learning與改進Q-learning算法的收斂曲線對比,可以看出,改進后的Q-learning算法大約僅迭代50次即可收斂,比Q-learning算法的收斂速度提高了4倍左右。
4? 結? 論
本文重點研究了智能抗干擾通信系統中的信道決策算法,通過將強化學習引入到信道決策中,采用Q-learning算法與無線信道進行交互,獲取信道信息以完成信道決策。針對固定模式干擾和隨機模式干擾這兩種情況進行仿真驗證,結果有力驗證了Q-learning算法在信道決策中的有效性。為解決Q-learning算法收斂速度較慢的問題,針對固定模式干擾,本文進一步提出一種改進的Q-learning算法,仿真結果表明,所提出的改進算法可大大提高收斂速度,并具有良好的有效性和可靠性,能夠保證高質量通信系統的實現。
參考文獻:
[1] 趙星宇,丁世飛.深度強化學習研究綜述 [J].計算機科學,2018,45(7):1-6.
[2] 薛蒙蒙.抗干擾通信中的認知引擎關鍵技術研究 [D].天津:天津大學,2016.
[3] 郭憲,方勇純.深入淺出強化學習:原理入門 [M].北京:電子工業出版社,2018.
[4] 趙彪,李鷗,欒紅志.Q學習算法在機會頻譜接入信道選擇中的應用 [J].信號處理,2014,30(3):298-305.
[5] 衡玉龍.認知無線電網絡頻譜共享性能分析與信道選擇策略研究 [D].重慶:重慶大學,2013.
[6] JIANG T,GRACE D,MITCHELL P D. Efficient exploration in reinforcement learning-based cognitive radio spectrum sharing [J]. IET Communications,2011,5(10):1309-1317.
[7] XIAO L,LI Y,LIU J L,et al. Power control with reinforcement learning in cooperative cognitive radio networks against jamming [J]. The Journal of Supercomputing,2015,71(9):3237-3257.
[8] GWON Y J,DASTANGOO S,FOSSA C,et al. Competing Mobile Network Game:Embracing antijamming and jamming strategies with reinforcement learning[C]// 2013 IEEE Conference on Communications and Network Security (CNS). IEEE,2014.
[9] HAN C,NIU Y T. Cross-Layer Anti-Jamming Scheme:A Hierarchical Learning Approach [J]. IEEE Access,2018(6):34874-34883.
[10] 楊鴻杰,張君毅.基于強化學習的智能干擾算法研究 [J].電子測量技術,2018,41(20):49-54.
[11] 劉召.基于強化學習的衛星通信資源分配算法研究 [D].西安:西安電子科技大學,2019.
[12] 劉猛.基于深度學習的抗干擾決策技術研究 [D].北京:中國電子科技集團公司電子科學研究院,2019.
[13] 朱芮,馬永濤,南亞飛,等.融合改進強化學習的認知無線電抗干擾決策算法 [J].計算機科學與探索,2019,13(4):693-701.
[14] XIAO L,JIANG D H,WAN X Y,et al. Anti-Jamming Underwater Transmission With Mobility and Learning [J]. IEEE Communications Letters,2018,22(3):542-545.
[15] JIA L L,YAO F Q,SUN Y M,et al. Bayesian Stackelberg Game for Antijamming Transmission With Incomplete Information [J]. IEEE Communications Letters,2016,20(10):1991-1994.
作者簡介:馬海波(1976—),男,漢族,黑龍江大慶人,高級項目經理,工程師,碩士,研究方向:5G通信系統架構。
