基于Spark Streaming的實時數據處理系統設計與實現
2020-05-18 14:22:20施炤
現代信息科技 2020年20期

摘? 要:一般的大數據平臺在歷史數據處理方面大多都是先通過一些數據導入工具比如Sqoop、DataX等進行數據全量導入,而實時數據處理更加關注的是數據的實時性。針對實時數據處理問題,文章基于Spark Streaming設計實現了一種實時數據處理系統,能夠實現高效的實時數據接入、傳輸、計算校驗和存儲。該系統具有實時數據獲取、實時數據計算、實時數據存儲等特點,為進一步從實時數據中獲取有效信息提供了必要的基礎支撐。
關鍵詞:實時;Flume;Kafka;Spark Streaming;HBase
中圖分類號:TP274 ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)20-0010-03
Design and Implementation of Real-time Data Processing System
Based on Spark Streaming
SHI Zhao
(Nanjing University of Posts and Telecommunications,Nanjing? 210023,China)
Abstract:In terms of historical data processing,general big data platforms mostly import full data through some data import tools such as Sqoop,DataX,etc.,while real-time data processing pays more attention to the real-time nature of the data. Aiming at the real-time data processing problem,this paper designs and implements a real-time data processing system based on Spark Streaming,which can realize efficient real-time data access,transmission,calculation,verification and storage. The system has the characteristics of real-time data acquisition,real-time data calculation,real-time data storage,etc.,which provides the necessary basic support for further obtaining effective information from real-time data.
Keywords:real-time;Flume;Kafka;Spark Streaming;HBase
0? 引? 言
隨著大數據技術的發展,人們越來越重視數據中潛藏著的價值。利用大數據技術,我們可以從數據中挖掘其隱藏的價值,為我們的生產、生活和學習提供有力的指導。社會生產和生活中每時每刻在產生新的實時數據,但我們對這些數據的處理還不充分。如何從這些數據中獲取更多有效的信息支撐應用中的實時響應,是目前的研究熱點,Spark Streaming技術的出現,為我們實現高效實時數據處理提供了技術支撐。本文使用Spark Streaming技術設計了一個實時數據處理系統,該系統是作者在參與上海德拓信息技術股份有限公司南京分公司關于離線數據采集存儲系統的開發與維護的經驗基礎上提出的一種實時數據處理系統。
1? 實時數據處理系統的需求
實時數據的產生多種多樣,如用戶的瀏覽信息、游客的出行記錄信息、顧客的消費信息等,這些信息會被系統記錄在數據庫或日志中。導入這些數據,需要對這些數據庫或者日志監控,數據寫入數據庫或者日志后通過監控獲取這些數據,還需要經過數據的清洗。數據錄入錯誤、數據的數值不正確等多種原因導致的臟數據,若不經過校驗和清洗就直接導入到庫中,會產生極大的成本和時間代價。因此獲取到的數據需要經過數據清洗后存入到數據庫以避免臟數據帶來的影響。
2? 實時數據處理系統分析
一個實時數據處理過程包含了數據的接入、數據的傳輸、數據的計算校驗和數據的存儲,其具體流程如圖1所示。首先需要有數據接入,有了數據之后需要將數據傳輸到相應位置等待數據計算校驗,經過計算校驗之后的數據才能存儲進數據庫。
2.1? 數據接入分析
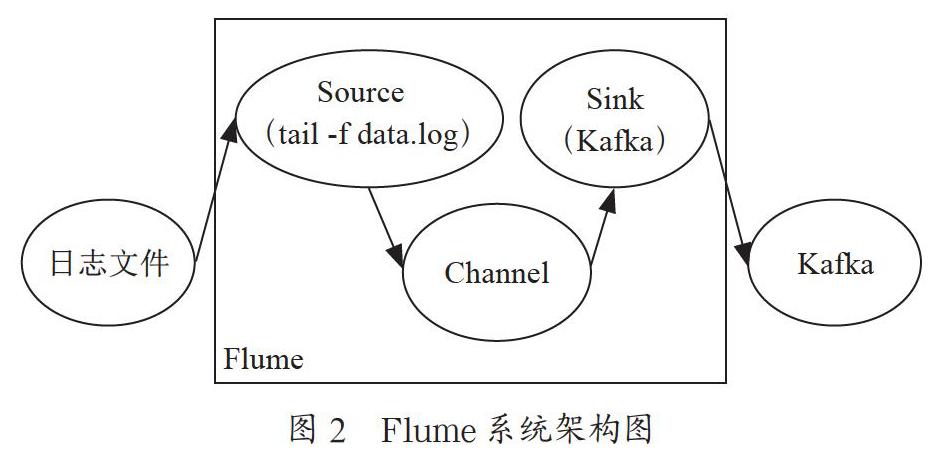
根據所需獲取的數據的來源不同,可分為兩種。若是獲取數據庫中的實時增加的數據,可以開啟數據庫的binlog日志[1],然后配置canal中deployer的instances.properties配置文件和adapter中的application.yml以及hbase.yml配置文件,實現源庫和目標庫之間數據同步,原理就是數據庫之間的主從復制。若是獲取的數據為日志文件中的新增數據,我們可以使用Flume這樣一個高可用的海量日志采集聚合傳輸的工具[2]。Flume用來監測日志文件的變化,一旦日志文件的內容發生變化,Flume便可以獲取新增的數據內容。Flume由Source,Channel和Sink組成,Source負責完成數據的收集,Channel對Source提供的數據進行緩存,Sink取出Channel中的數據,存入到相應的文件系統(HDFS)、數據庫或者Kafka中,其系統架構圖如圖2所示。
2.2? 數據傳輸分析
數據的接入速率與數據的處理速率不同,這就需要在數據接入和數據處理之間加上一個緩沖區。這個緩沖區必須是高性能的,而且可用于實時事件響應的場景,Kafka正滿足這些需求。Kafka是Apache下的一個開源流處理平臺,可以處理用戶在日常生活中的所有動作流數據,同時Kafka可以以集群模式運行,緩解節點或者服務器之間的壓力。因此我們可以將由Flume監測日志文件而獲取的數據發送給Kafka的topic,存儲在Kafka的緩沖區中,等待Kafka消費者將這些采集到的數據“消費”。
2.3? 數據計算校驗分析
一般的數據計算方法是通過MapReduce完成,但Map-Reduce僅僅支持map和reduce操作,操作單一,map的中間結果寫入磁盤,reduce的結果寫入HDFS,大數據量的MapReduce操作所花費的時間會很高,因此MapReduce不適合用于實時計算的場景。spark是內存計算,避免了多次計算的中間結果寫到HDFS的I/O開銷,且spark提供的RDD操作很多[3]。因此Spark Streaming[4]用在數據計算校驗部分正合適。
2.4? 數據存儲分析
實時數據導入系統中將經過Spark Streaming流式處理[5]后的數據存儲到HBase中[6]。HBase具有海量存儲,高并發,極易擴展,成本較低等特點,而且HBase可以同時存儲多版本數據(HBase使用不同Timestamp來標識相同Rowkey行對應的不同版本數據)。HBase查詢數據的響應速度很快,這是因為HBase的特殊尋址方式(請求ZooKeeper獲取元數據,訪問元數據獲取RegionServer地址,訪問RegionServer獲取所需數據),尋址訪問的同時會把元數據的相關信息緩存下來。這樣的訪問方式成就了HBase的快速響應的特點。HBase表中Rowkey的設計至關重要。HBase中有很多region,每個region都有startRowKey和stopRowKey,若Rowkey設計不合理,會導致某個region被頻繁訪問,造成熱點現象,引起節點性能下降。因此HBase的Rowkey設計需要注意Rowkey的長度一般不超過16個字節;需要保證Rowkey的唯一性(HBase表中的數據是以KeyValue的形式存在的,若插入相同Rowkey的值則原先的數據會被覆蓋);Rowkey設計要充分利用其有序性;設計的Rowkey應該均勻分布在各個HBase節點上。
3? 實時數據處理系統的設計與實現
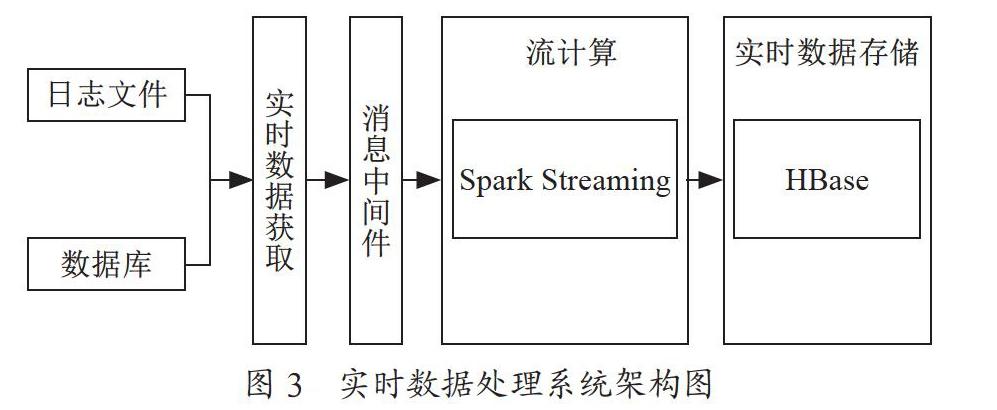
通過上一節的分析,本文實現了一種實時數據處理系統,通過Flume實時數據獲取模塊獲取日志文件和數據庫中的實時新增數據,再將數據暫存到Kafka消息中間件,由Spark Streaming調用Kafka中的數據做實時處理,處理后的結構存儲到HBase中。其結構圖如圖3所示。
3.1? 數據接入設計
數據接入以Flume為例,Flume是由Source、Channel和Sink組成,需要將這三部分配置好并串聯起來。設置Source端的監測命令為tail -F/root/flume.log,監測flume.log文件內容的變化,若tail-F/root/flume.log命令監測到日志文件內容變動,Flume會獲取這些內容。
3.2? 數據傳輸設計
設置flume sink端的類型為Kafka,配置Kafka的boot-strapserver地址并設置Kafka的topic。除此之外還需要設置序列化方式為kafka.serializer.StringEncoder。通過Kafka的bootstrapserver和對應的topic,才能將Source端收集到的數據準確無誤的傳輸到Kafka指定的topic。配置好Source和Sink后,需要再配置一個Channel將Source端收集到的數據傳輸到Kafka中。
3.3? 數據計算校驗設計
數據存儲到了Kafka的topic中,需要創建一個消費者消費采集到的數據。這里的消費者是通過Spark Streaming實現的,通過Spark Streaming對采集到的數據進行計算校驗。首先需要將Spark Streaming與Kafka連接,才能讀取到topic中的數據。因此需要配置bootstrapserver、key.deserializer、value.deserializer,設置topic、groupid,kafkaoffset的維護等級,關閉自動提交。
經過上一步取到topic中的數據后,就需要對數據進行計算校驗了。先將數據以空格切分得到一個字符串數組,若數組長度或者數組中的數據值不符合需求則不存儲這條數據。以WordCount為例,讀取topic中的數據后首先需要將這一條數據以空格分隔存儲在數組中,然后遍歷這個數組并將其轉換成一個元組,最后將相同key值的元組聚合得到單詞出現的次數。其中獲取到的數據經flatmapRDD、mapToPairRDD和reduceByKeyRDD計算獲得最終結果。
3.4? 數據存儲設計
將Spark Streaming處理計算后的數據存入HBase,需要先在HBase數據庫中創建好對應的表,建表語句如下:create ‘wordcount,sz,指定表名為WordCount,列族為sz。這里以WordCount為例,統計每個單詞出現的次數,因此Rowkey就是每個RDD中tuple的key值,也就是這些出現過的單詞。表建好后,需要將經過RDD處理計算好的數據插入到HBase表中。
首先輪訓RDD中所有的元組,然后創建HBase配置對象,指定ZooKeeper的端口號和ZooKeeper的節點,指定HBase的HMaster節點,創建連接對象并指定表名從而與HBase連接并把每個元組的key和value插入HBase表中。其中key為HBase表的Rowkey,value為對應列族sz,對應列num的cell中的值。
當第一批數據處理完后第二批數據處理時,有可能會有相同的key的數據,由于HBase可以存儲多版本數據,這樣的相同key的數據插入進數據庫時,會被HBase當作新版本的數據存儲下來,并不能實現累加,這顯然與WordCount計數的需求不同。因此需要刪除表中原有的這一條數據,插入新值與原值的和。因此需要獲取表中的所有Rowkey,每當要插入數據時,先檢測是否會有相同的Rowkey出現,若表中不存在相同的Rowkey則直接插入該條數據;若表中存在相同的Rowkey,則需要記錄原有的值并刪除這條數據,插入原值和現有值的和從而達到計數的目的。
3.5? 系統運行介紹
整個系統是檢測日志文件的,所以先要向日志文件里寫入數據,如圖4所示。
運行Spark Streaming代碼,讀取監測到的數據并做計算處理,程序輸出如圖5所示。
查看HBase中的數據,檢驗計算后的數據是否成功存入,HBase中的數據如圖6所示。
4? 結? 論
隨著大數據技術的不斷發展,企業越來越意識到實時數據中的價值。因此本文設計了一種基于Spark Streaming的實時數據處理系統,能夠實現實時數據的接入、傳輸、計算校驗和存儲。在互聯網時代,大數據技術已經日益成熟,許多企業已經開始著眼于數據的隱藏價值,并開始著手建立基于大數據的分布式數據采集和數據應用平臺,該實時數據處理系統可以使企業快人一步處理實時數據。但此系統也有些不足,實時數據處理系統只是將實時數據采集并存儲起來,并沒有對數據進行應用,后續可用機器學習技術對數據的價值進行深層次的挖掘。
參考文獻:
[1] 蘇子權.基于MySQL Binlog的數據增量同步系統的設計與實現 [D].南京:南京大學,2018.
[2] 袁昌權,胡益群,許光,等.基于Hadoop的高可用數據采集與存儲方案 [J].電子技術與軟件工程,2019(18):169-170.
[3] 吳信東,嵇圣硙.MapReduce與Spark用于大數據分析之比較 [J].軟件學報,2018,29(6):1770-1791.
[4] 柯杰.基于Spark Streaming日志實時監測系統的設計與實現 [D].南京:東南大學,2017.
[5] 李欣.基于Spark/HBase的交通流數據存儲及索引模型探討 [J].地理與地理信息科學,2019,35(4):1-8.
作者簡介:施炤(1995.07—),男,漢族,江蘇鎮江人,碩士研究生,研究方向:大數據技術。
