基于姿態引導對齊網絡的局部行人再識別
2020-05-18 11:08:02趙杰煜
計算機工程 2020年5期
鄭 燁,趙杰煜,王 翀,張 毅
(寧波大學 信息科學與工程學院,浙江 寧波 315000)
0 概述
目標行人從一個相機視域離開,然后在另一個不重疊的相機視域中再次被識別,這一過程在計算機視覺領域稱為行人再識別(Re-ID),其是實現多攝像頭跟蹤的前提條件,在現實生活中得到廣泛應用。目前,對于行人再識別的研究主要集中于整體圖像的研究,但在現實場景中,由于遮擋等原因拍攝到的圖像不都是完整的圖像,也可能存在只有部分身體的局部圖像,因此需對局部行人再識別作進一步研究。
深度卷積神經網絡(Deep Convolutional Neural Network,DCNN)模型通常會將圖像縮放到固定大小作為輸入,而尺寸相同的局部圖像與整體圖像會存在嚴重的不匹配問題并對特征匹配產生影響。相比而言,預對齊的局部行人圖像更適合與整體圖像進行匹配。本文提出姿態引導對齊網絡(Pose-Guided Alignment Network,PGAN)模型,將人體先驗知識引入到對齊網絡中,使用空間變換生成與標準姿勢對齊的行人圖像,并在訓練階段利用姿勢信息學習空間變換器的對齊參數。
1 相關工作
1.1 行人再識別
表征學習被應用于行人識別中以學習人的外貌特征。文獻[1-2]使用卷積神經網絡(Convolutional Neural Network,CNN)學習全局特征。文獻[3-4]將圖像分為多個部分提取可區分的局部特征,通過圖像水平分割可有效提取變化較少的局部特征。圖片切塊是一種常見的局部特征提取方式,但其缺點在于對圖像對齊的要求較高,如果兩幅圖像沒有上下對齊,那么很可能出現頭和上身不對齊的現象,反而使得模型判斷錯誤。行人身體的不匹配問題將嚴重影響不同圖像之間的特征匹配。為應對圖像不對齊問題,研究人員將空間變換網絡(Spatial Transformation Network,STN)引入到再識別模型中對行人圖片進行空間變換對齊行人,還有研究人員將人體解析[5]、姿態估計方法等作為先驗知識引入到Re-ID模型中對行人圖像進行對齊。
1.1.1 基于空間變換的行人再識別
STN[6]是一個空間變換模塊,可以引入神經網絡以提供空間變換功能,包括平移、縮放、旋轉等。STN是一個小型網絡,可以進行標準的反向傳播和端到端訓練,而不會顯著增加訓練過程的復雜性。STN由定位網、網格生成器和采樣器組成,定位網獲取輸入的特征圖并輸出變換參數,網格生成器計算每個輸出像素的原始圖像中的位置坐標,采樣器生成采樣的輸出圖像。
文獻[7]提出一種多尺度上下文感知網絡(MSCAN),通過將STN與定位損失相結合來提取可變的身體部位,從而減少背景影響并在一定程度上將行人圖像對齊,但是定位損失的中心先驗約束是基于圖像主體完整且圖像對齊的前提而提出。文獻[8]提出行人對齊網絡(PAN),使用STN在Re-ID深度卷積網絡前對齊行人圖像,但是PAN僅使用Re-ID損失對其進行訓練,圖像對齊效果較差。
1.1.2 基于姿態估計的行人再識別
Spindle Net[9]和GLAD[10]使用姿勢估計算法預測人體關鍵點,然后學習每個部件的特征并組合部件級的特征以形成最終描述符,以解決姿勢變化問題。姿態驅動深度卷積模型(PDC)[11]通過姿態信息裁剪身體區域,然后獲得經過旋轉和調整大小的身體部位用于姿勢變換網絡對身體部位進行歸一化。文獻[12]利用姿態不變特征(PIE)作為行人描述符,利用姿勢估計定位關鍵點,將身體各部件通過仿射變化映射生成Pose Boex結構。文獻[13]提出一個姿勢敏感的行人Re-ID模型,將關節信息和粗略方位信息引入到卷積神經網絡中學習判別特征,實驗結果表明,檢測到的關節位置和拍攝視角有助于學習特征。然而這些方法都將姿勢估計直接嵌入到模型中,增加了計算成本和模型復雜度。
1.2 局部行人再識別
在局部行人再識別中,由于存在只有局部身體可被觀測到的局部圖像,局部圖像與整體圖像的匹配是局部行人再識別的一大難題。滑動窗口匹配(Sliding Window Matching,SWM)[14]利用與局部圖像大小相同的滑動窗口來搜索每個整體圖像上最相似的區域,然而局部匹配的計算代價太大。文獻[15]提出一種深度空間特征重構(Deep Spatial Feature Reconstruction,DSR)方案,使用全卷積網絡(Full Convolutional Network,FCN)生成具有一定大小的空間特征圖,以匹配不同大小的行人圖像。與SWM方案相比,DSR方案大幅減少了計算量。文獻[16]提出可視性局部模型(Visibility Partial Model,VPM),通過監督學習感知區域的可見性,提取區域級特征并比較兩個圖像的共享區域。
2 基于PGAN的局部行人再識別
為解決遮擋和尺度變化問題,本文設計一個姿態引導對齊網絡來對齊局部行人,然后學習有效的特征進行行人再識別,整體框架(如圖1所示)包括以下模塊:
1)姿態引導的空間變換(Pose-Guided Spatial Transformation,PST)模塊,其進行訓練并將整體/部分行人圖像轉換為對齊的行人圖像。該對齊方法是基于完整或部分人體姿態,將人體骨骼作為先驗知識,利用姿態估計方法提取每個行人圖像的姿態信息。需要注意的是:該過程無需對每個圖像進行姿態估計,而是使用一個空間變換器來學習標準姿態和給定標準姿態之間的轉換參數。在無需顯示姿態信息的情況下,該方法是一種非常有效的推理方法。
2)特征提取模塊(ResNet)[17],其作為特征提取器的主干模塊,提取行人圖像的全局特征。
基于PGAN模型,局部圖像可以實現與整體圖像的匹配。

圖1 姿態引導對齊網絡框架
2.1 姿態引導的空間變換
PST模塊是PGAN中的關鍵部分,利用姿態信息引導局部行人圖像進行空間變換。具體為訓練一個空間變換生成一個與目標姿態接近的對齊行人圖像,根據人體骨骼關鍵點確定損失函數。
行人再識別通常使用二維圖像作為輸入,本文采用仿射變換來變換整體/部分行人圖像進行對齊。在PST模塊中,所有圖像被轉換成更接近標準姿態的圖像。當原始行人圖像與對應的轉換圖像分別表示為I、Ia,I、Ia中的像素可以進一步表示為p、pa,那么p、pa之間的仿射變換為:
pa=Rp+b
(1)
其中,R是一個與縮放、旋轉相關的2×2參數矩陣,b是一個與平移相關的1×2參數向量。
由定位網絡、網格生成器和采樣器組成的空間轉換網絡[6]在PST模塊中被用來進行仿射變換得到仿射變換后的圖像Ia。輸入為原始行人圖像I,輸出為θ,包含用于對齊的仿射變換參數。
(2)
其中,floc(I)表示定位網絡。定位網絡結構如表1所示,包括兩個卷積層、兩個池化層和兩個全連接(FC)層,最后一個FC層生成仿射轉換參數θ,用于創建網格生成器中的采樣網格。

表1 定位網絡結構
然后采樣器從原始行人圖像I中提取一組采樣點,并產生采樣輸出Ia。從仿射圖像到原始圖像的逐點變換過程如下:
(3)
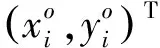
最終得到仿射變換后的圖像Ia:
Ia=fSTN(I)
(4)
其中,fSTN為空間轉換網絡。
如果所有行人都有相同的姿勢和尺度,則再識別難度會大幅下降。為獲得更好的再識別性能,不同I的變換圖像Ia中的行人應具有相似的姿態和尺度,但在原始的STN中,變換參數是由網絡在沒有任何指導的情況下進行學習得到,換言之,其不能確保轉換后的圖像Ia具有所需屬性,例如姿態和比例。本文將關鍵點形式表示的標準姿態作為對齊目標,引導網絡學習本文所需的變換,關鍵點是人體骨骼關節,如圖2所示,其中包括成對對稱的16個關節和單個關節,共17個關節。關鍵點的定義如下:
Kp={k0,k1,…,ki,…,kN}=
{(x0,y0),(x1,y1),…,(xi,yi),…,(xN,yN)}
Kvis={v0,v1,…,vi,…,vN}
(5)
其中,Kp、Kvis分別表示關鍵點和關鍵點可見性,(xi,yi)表示第i個關鍵點的坐標,vi表示其對應的可視分數,N表示總的關鍵點個數。
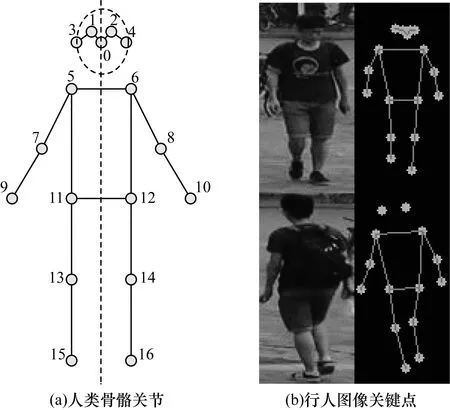
圖2 行人圖像骨骼關節關鍵點
為評價仿射變換后的圖像Ia與標準圖像的姿態相似性,首先通過RMPE姿態估計算法[18]提取Ia中人物的關鍵點P,將這些關鍵點P與標準姿態的目標關鍵點T進行匹配,得到兩個姿態之間的相似性。然后將該相似性作為損失項來指導PGAN中轉換參數的學習過程。需要注意的是:仿射變換在學習階段可能會極大改變圖像中人物的形狀。因此,RMPE姿態估計算法可能無法檢測到Ia中的關鍵點。此外,在模型中嵌入姿態估計會大幅增加計算復雜度,因為每個訓練元中的每幅圖像都需要一個姿態估計,并且該過程不能在GPU上并行執行。
由此可知,Ia的姿態信息不是直接通過姿態估計得到。實際上,變換后的圖像Ia無需估計姿態關鍵點,可以利用輸入圖像I中原始關鍵點的坐標K和STN得到的變換參數θ計算得到,并且原始關鍵點只需在數據準備階段使用一次RMPE姿態估計算法。將原始圖像I及其姿態信息K作為PST模塊的輸入,通過方向定位和關鍵點計算獲得Ia中關鍵點的轉換位置P。
(6)
(7)
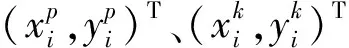
為使輸入圖像與標準姿態對齊,關鍵點匹配損失定義為兩組關鍵點之間的L2損失之和,使Ia中每個轉換后的關鍵點與標準姿態的關鍵點之間盡可能接近。對稱的對齊損失函數LAli為:
(8)
其中,P和T分別表示Ia上關鍵點和目標關鍵點,kn和tn分別表示P和T的第n個關鍵點,vn表示第n個目標關鍵點的可見性分數,N表示關鍵點的數量。
如果輸入圖像是低分辨率或從側面、背面拍攝的圖像,多數姿態估計算法很難區分人體的左右部分。在這種情況下,將所有仿射變換后的關鍵點與標準姿態匹配可能會造成巨大損失,再加上對STN的不當指引,會進一步導致意外的空間變換。為解決上述問題,本文根據人體對稱性放寬約束,只選擇對稱關鍵點的中心和距離來計算損失,而忽略其他屬性。改進的對稱對齊損失函數LAli計算如下:
LAli=MSE(Pm,Tm)+MSE(Pd,Td)
(9)
其中,Pm、Tm分別表示對應仿射圖像的關鍵點P和標準姿態目標關鍵點T中對稱關鍵點的中心坐標(x,y),Pd、Td分別表示P和T中對稱關鍵點的距離,kpi、kpj和kTi、kTj分別表示P和T中對稱的關鍵點對。
PST模塊不僅可以單獨用于對齊(如圖3、圖4所示),還可以嵌入到CNN模型中進行端到端訓練。

圖3 Market-1501訓練集對齊示例

圖4 Market-1501測試集上的對齊結果可視化
Fig.4 Visualization of alignment results on the Market-1501 testing set
2.2 特征提取
ResNet是目前使用較廣泛的CNN特征提取網絡,本文采用ResNet-50作為主干網絡,在PST模塊中提取仿射變換后圖像Ia的全局特征。
F=fFE(Ia)
(10)
其中,fFE(I)是一個特征提取器。
通常用于行人再識別的softmax損失LID和三元組損失LTri都被用來訓練本文模型,同時利用由全連接層和softmax函數組成的分類器來預測輸入行人的身份。
PID=softmax(WTF+b)
LID=cross-entropy(PID,y)
(11)
其中,PID是M個類的預測值分布,M是身份個數,y是每個樣本的身份信息,Fia、Fip、Fin分別是anchor圖像、positive圖像和negative圖像特征,β是三元組損失的邊緣,在實驗中取值為0.3。
對于整個網絡的訓練,本文將結合LAli、LID和LTri作為最終的損失函數,如式(12)所示。通過嵌入PST模塊使得PGAN可以學習對齊特征進行匹配。
L=λLAli+LID+LTri
(12)
其中,超參數λ在實驗中取值為0.1。
3 實驗結果與分析
3.1 數據集與測試協議
本文模型首先在Market-1501數據集上進行訓練,然后在Partial-REID和Partial-iLIDS數據集上進行測試。在數據增強階段,隨機裁剪生成局部圖像用于訓練。
1)Market-1501[19]包含6臺攝像機從不同視角拍攝的1 501個身份的行人圖像32 368張。在訓練集中,包含12 936張751個身份的圖像。
2)Partial-REID[14]是一個局部行人圖像數據集,包含60個身份的600張行人圖像,每個身份有5張全身圖像和5張局部圖像。這些圖像是在某大學校園從不同視角、背景進行拍攝,并存在不同類型的遮擋情況,每個人的所有局部圖像組成Query集,而整體行人圖像用作Gallery集。
3)Partial-iLIDS[20]是一個基于iLIDS的局部圖像數據集。Partial-iLIDS共包含238張由多個非重疊攝像機捕獲的119個身份的圖像。對于被遮擋的行人,通過剪切每個身份圖像的非遮擋區域生成局部圖像,構建Query集,每個身份的非遮擋圖像被選擇用來構成Gallery集。
本文使用累積匹配曲線(Cumulative Match Characteristic,CMC)的Rank-1、Rank-3準確率作為評估指標來衡量模型性能。
3.2 PGAN實現
PGAN實現過程具體如下:
1)局部圖像產生:由于局部行人再識別數據集只提供測試集,因此需要對某些整體數據集進行訓練。為學習部分圖像的對齊,根據給定范圍隨機裁剪圖像生成整體圖像的局部圖像,同時對輸入關鍵點做同樣處理,使其與輸入圖像一致。為平衡訓練集中整體圖像和局部圖像的數量,設置整體圖像的裁剪概率為0.5。
2)數據增強:圖像大小調整為256像素×128像素,并將原始像素值歸一化至[0,1],然后分別減去0.485、0.456、0.406,再除以0.229、0.224、0.225,對RGB通道進行歸一化處理。在訓練階段,在水平方向隨機翻轉每個圖像,填充10個零值像素,再將其隨機裁剪成一個256像素×128像素的圖像進行數據增強。
3)網絡設定:選擇Re-ID中常用的ResNet-50作為骨干網絡。參考文獻[21]設置,使用ImageNet上預訓練的參數初始化ResNet-50,并將最后一個卷積層的stride修改為1,將全連接層的連接數修改為M,M表示訓練數據集中的身份數。在全連接層前使用BN bottleneck,PST中STN的參數θ初始化為[1,0,0,0,1,0]。采用Adam法對模型進行優化,共有120個訓練epoch。初始學習率設定為3.5×10-4,使用Warmup方法改變學習速率,在前10個epoch時將學習速率從3.5×10-5線性增加至3.5×10-4,然后分別在第40個epoch和第70個epoch時將學習率除以10。
4)訓練:本文模型分為兩個訓練階段。在第一個階段使用式(9)中的對齊損失LAli在Market-1501數據集上預訓練PST模型;在第二階段利用預訓練的PST權值和ResNet-50的ImageNet上的預訓練參數初始化整個PGAN模型。
3.3 PST結果可視化
為驗證PST對局部圖像的對齊性,在Partial-REID和Partial-iLIDS數據集上進行實驗。PST可以學習對齊的空間變換,其在Partial-REID數據集上的結果如圖5所示,結果表明PST不僅能對整體圖像進行對齊,而且能對局部圖像進行準確對齊,驗證了PST模塊的有效性。

圖5 Partial-REID數據集上的PST結果可視化
3.4 在Partial-REID和Partial-iLIDS上的測試結果
本文在Partial-REID和Partial-iLIDS數據集上進行Rank-1、Rank-3準確率實驗,結果如表2所示。
表2 Partial-REID、Partial-iLIDS數據集上的Rank-1和Rank-3準確率
Table 2 Accuracy of Rank-1 and Rank-3 on Partial-REID and Partial-iLIDS datasets %
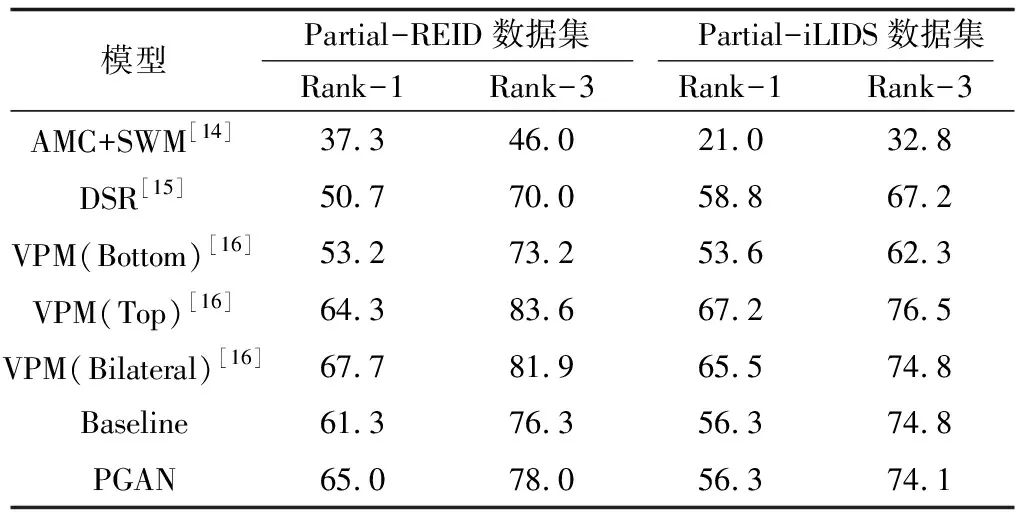
模型Partial-REID數據集 Partial-iLIDS數據集Rank-1Rank-3Rank-1Rank-3AMC+SWM[14]37.346.021.032.8DSR[15]50.770.058.867.2VPM(Bottom)[16]53.273.253.662.3VPM(Top)[16]64.383.667.276.5VPM(Bilateral)[16]67.781.965.574.8Baseline61.376.356.374.8PGAN65.078.056.374.1
為驗證PST對局部Re-ID的識別效果,本文將PGAN與未使用PST的Baseline模型進行比較。對于局部Re-ID數據集,Baseline在Partial-REID、Partial-iLIDS數據集上分別得到61.3%、56.3%的Rank-1準確率,PGAN在Partial-REID數據集上的Rank-1準確率相比Baseline提高了3.7個百分點。PGAN相對于Baseline的優勢在于:PST進行身體水平的對齊,以處理顯著的不對齊問題,但其在Partial-iLIDS數據集上沒有明顯的性能提升,可能的原因為Partial-iLIDS數據集中的局部圖像保留了大部分身體,其不對齊程度在CNN的處理范圍內。
PGAN在兩個局部數據集Partial-REID和Partial-iLIDS上與其他模型進行比較。在Partial-REID數據集上,PGAN的性能相比AMC+SWM和DSR有較大的優勢,但與VPM相當。在Partial-iLIDS數據集上,PGAN的性能超越了AMC+SWM。由于PGAN模型嵌入了一個簡單的PST模塊進行局部圖像與整體圖像的對齊,從而提高局部圖像的識別性能。
3.5 檢索結果可視化
對于卷積神經網絡,即使圖像中只有行人的局部身體部位但包含一些明顯特征的圖像,如黃色衣服或者偏移程度較小的圖像,其也可以學習高層特征實現圖像區分,然而對于沒有明顯特征、顯著不對齊的局部圖像很難與整體圖像進行匹配。圖像行人局部圖像的檢索結果如圖6所示。在圖6(a)中,Baseline無法找到匹配圖像,即匹配圖像排在第5位后,而PGAN匹配圖像排在第1位。在圖6(b)中,對于同一輸入圖像,Baseline匹配圖像排在第4位,而PGAN的匹配圖像排在第1位。實驗結果表明,局部圖像對齊對局部行人再識別具有較大作用。

圖6 檢索結果可視化
4 結束語
本文提出一種用于局部行人再識別的姿態引導對齊網絡(PGAN)。在PGAN中,PST模塊通過姿態信息引導,可對部分行人圖像進行有效對齊,只需在數據準備階段通過姿態估計獲取訓練數據姿態信息,然后基于PST計算得到模型所需姿態信息,使得訓練過程更加高效。實驗結果表明,PGAN在局部行人再識別上取得了較好的識別效果,且在訓練階段和推論階段均未產生額外的計算成本與姿態信息。后續將對結合注意力機制的局部行人再識別模型進行研究,通過抑制背景等干擾信息提高局部行人再識別的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
河南畜牧獸醫(2016年24期)2016-11-29 01:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
