基于主成分分析的雷達行為狀態聚類分析方法
2020-05-18 07:38:58畢大平潘繼飛陳秋菊
探測與控制學報 2020年2期
關鍵詞:分類
方 旖,畢大平,潘繼飛,2,陳秋菊,2
(1.國防科技大學電子對抗學院預警對抗系,安徽 合肥 230037;2.電子對抗信息處理實驗室,安徽 合肥 230037)
0 引言
隨著相控陣技術與軟件化技術的發展,雷達作為具有多功能、多任務、多種工作模式的高度智能化系統,逐漸展現出極強的靈活性和自適應能力,給雷達對抗技術帶來了前所未有的挑戰。主要體現在:必須具備及時準確地感知雷達內部狀態動態變化的能力,才能引導對抗裝備敏捷地決策出最優的對抗策略,進而實施認知對抗。盡管雷達信號多變,但信號設計與工作模式、行為意圖及能力緊密關聯,且雷達工作模式類型有限,這一本質特征為雷達認知對抗提供了可行性[1]。
圍繞雷達實現參數級對抗向行為級智能對抗躍升的需求,專家學者積極開展雷達輻射源行為精確辨識研究。最常用的句法模型算法[2-4]依賴于時鐘周期所描述的量化精度,隨著時鐘周期的縮短,量化精度會有所改善,但是同時會使得編碼序列增加,所需工作量增大。TTP變換算法[5-6]基于TOA的脈沖序列PRI分析方法,并在此基礎上利用掃描特性、PDW中的PW,RF等參數對算法進行了改進,對提高提取效率有很好的效果。文獻[7]提出了通過構建CPI(相干處理周期)矩陣,并將矩陣與先前構建的雷達數據庫進行關聯。文獻[8]利用生物信息學方法“多序列比對(MSA)”從信號中重建MFR的搜索計劃,還原搜索任務。文獻[9]采用了分別對脈沖組數據、工作模式分層次建模的方法,對各個層次之間的聯系進行描述。
上述雷達行為識別方法普遍需要大量的雷達先驗信息與完備的數據庫支撐,或受限于動態表征算法的能力,無法實現較為復雜的工作狀態的識別。針對這個問題,本文在小樣本數據條件下,設計了一種基于主成分分析的改進型C-均值聚類算法以完成樣本數據的分類方法,并根據雷達脈沖描述字及其變化規律從邏輯角度反推設計原則,進而與常見工作狀態(模式)匹配。
1 雷達行為狀態分析模型建立
雷達對抗偵察接收機通過偵察天線波束覆蓋或頻段掃描的方式接收指定雷達目標的脈沖信號,生成脈沖描述字,包括到達時間、脈沖寬度、脈沖幅度、脈沖載頻、到達角、重頻、波束方位等參數。雷達信號形式與其行為意圖息息相關,也與工作模式存在對應關系。在不同雷達工作模式下,脈沖描述字參數表現為不同的特性[10-12]。例如,重頻(PRF)通常情況下分為高重頻(HPRF)、中重頻(MPRF)、低重頻(LPRF)。當重頻足夠低時,可以盡可能測量出足夠大的不模糊速度和距離。在中重頻狀態下,雷達在旁瓣雜波區內對目標的檢測性能優于高PRF,通常對目標的距離和速度都是模糊的,但可以通過不斷變換PRI的形式來解決問題。中重頻波形主要用于全方位的速度距離搜索,但它的遠距離性能會相對較差。在高重頻狀態下工作的雷達主要用于速度搜索模式和邊搜索邊測距模式,在PRF足夠高的情況下可以對所有感興趣的目標速度都能不模糊測量,但它的缺陷是難以檢測到旁瓣雜波區的目標。雷達對不同類別的目標采用不同的跟蹤數據率,對處于跟蹤過渡過程中的目標,用較短的采樣間隔時間;對已穩定跟蹤的目標,根據它的重要性及威脅等級分成若干種跟蹤狀態,即威脅等級高的采樣間隔時間較小,等級低的采樣間隔時間較大。
圍繞雷達行為辨識問題,建立圖1所示模型。
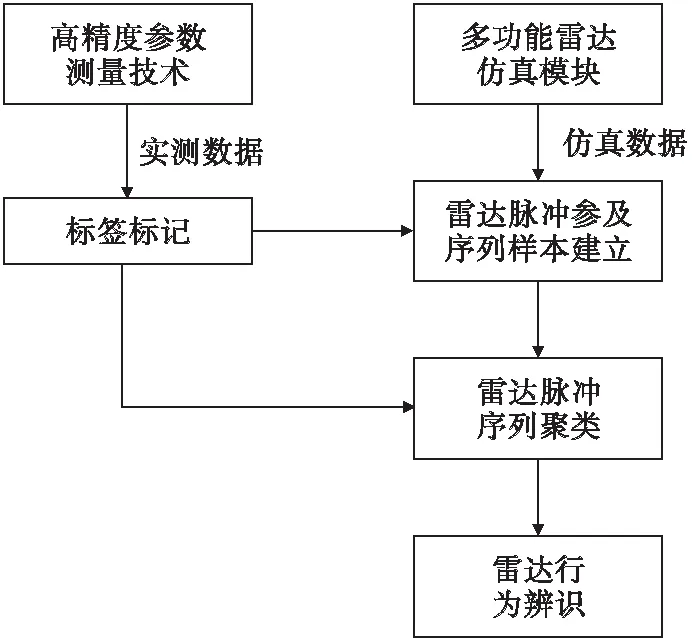
圖1 雷達行為辨識模型Fig.1 Radar behavior recognition model
本文所提方法基于在系統準確區分不同輻射源信號的前提下運用。直接測量與仿真的信號數據冗長且干擾因素大,難以完成聚類分析。對所有原始數據進行處理,處理完成的雷達脈沖參數建立樣本序列,并對序列聚類。最后對每一類進行識別,確定雷達行為狀態。
2 基于主成分分析的樣本優化
2.1 數據預處理
雷達信號特征參數的選擇取決于該參數是否能夠從本質上反映工作模式的行為意圖。例如,對某型機載側視雷達來說,分別工作在遠區搜索、近區搜索及跟蹤三種模式下時,脈寬、重頻及脈壓比都有較為明顯的區別。遠區搜索時,脈寬較另外兩種模式寬,是由于對遠區目標搜索時需要消耗較多的能量,而此時的重頻較低,脈壓比較大;近區搜索時,脈寬相較遠區搜索窄,相對跟蹤模式下的脈寬較寬;跟蹤模式下,重頻較高,便于精確瞄準目標。可以看出在不同工作模式下脈寬、重頻和脈壓比有明顯不同。而當在跟蹤模式下跟蹤不同目標時,波束方位指向就具有明確的指向模式意圖。因此,根據描述字對信號特征進行分析從而對工作模式進行識別,是一種行之有效的方法。
本文采取的分析方法是利用C-均值算法對特征參數聚類分析。C-均值聚類算法基于距離原則將原始數據根據到聚類中心的距離來分類,而原始數據本身量級差別很大,在對其采用歐式距離計算時會產生極大的誤差,因此要對原始數據進行預處理,使C-均值聚類算法可以更好地運算以達到分類的目的。
數據歸一化有多種辦法:
1)線性函數歸一化(Min-Max scaling):線性函數將原始數據線性化的方法轉換到[0,1]的范圍計算,公式如下:
(1)
2)0均值標準化:將原始數據集歸一化為均值為0,方差為1的數據集,計算公式如下:
(2)
以上兩種方法雖然可以把數據歸一化,但是歸一化之后的數據量級依然相差很大,無法滿足適合C-均值聚類算法的要求。本文提出一種新的數據預處理的方法,即先將原始數據歸一化,以相同比例同時縮小,然后將得到的數據取對數,這樣出來的結果在量級上相差很小,方便之后進行聚類分析。但是,重頻參數在初始歸一化之后量級也僅相差10倍,就不再采取對數化處理。數據預處理的公式如下:
Xk′=log(max(Xk)/Xki),i=1,2,…,N
(3)
式(3)中,Xk為對數處理后的樣本數據,max(Xk)為樣本數據中的最大值。
2.2 基于主成分分析的樣本篩選
主成分分析(Principal Component Analysis,PCA)是最常用的降維方法之一,通過線性投影,將高維的數據投射到低維的空間中,并期望在所投空間中維度上包含的信息量最大,進而使用較少的維度,也可以保留較多的原數據中的信息。本文通過主成分分析對雷達脈沖參數進一步篩選,可以減少樣本數據集的大小,在有限的時間和資源下,提高分類算法的效率,以便建立更精準的雷達行為狀態識別模型。
主成分分析可以由以下幾個步驟完成對雷達脈沖序列特征參數的篩選:
1) 對所有特征進行中心化:去均值。對原始樣本中的每個特征參數求均值,并將每一個特征減去求得的均值。
2) 求協方差矩陣。雷達脈沖序列按時間排列,每一行為一個樣本,每一列為一個維度,計算公式為:
(4)
3) 求協方差矩陣的特征值和相對應的特征向量。將計算所得的特征值從大到小排列,選取最大的3個,并提出其對應的特征向量u(1),u(2),u(3),…,u(k)。
4) 將原始特征投影到選取的特征向量上,得到降維后的新3維特征。計算與之對應的主成分表達式的系數,并把系數與原始數據相乘得到分配權值之后的樣本數據X′(N)={X1′,…,Xn′}。
原樣本數據包含所有脈沖參數,例如脈沖寬度、重復周期、波束方位、脈壓比、脈沖幅度、帶寬等,有些特征參數對分類影響很大,有些特征參數對分類幾乎不會產生作用,通過主成分分析,可以提取貢獻率最大的三類參數構成數據集,減少數據冗余,提高分類效率。
2.2 基于均值漂移優化C-均值聚類算法
C-均值聚類算法屬于動態聚類算法,即在迭代過程中,樣本不會因為之前的判定而固定類別。此算法采用歐氏距離計算方法計算各個樣本到聚類中心的距離,將樣本歸于距離最短的聚類中心所在的那一類里,并計算聚類之后的每個數值對象的平均值來獲取新的聚類中心,根據前后兩次的聚類中心是否變化來判定聚類是否完成,聚類中心是否選取正確[13-15]。此算法使用的聚類準則函數是誤差平方和準則,即:
(4)
式(4)中,Nj為第j類樣本數,mj為第j類wj,為使結果更優化,應該使Jc最小化。基本計算步驟如下:
1)已知樣本X(N)={X1,…,Xn},令T表示迭代運算次數,隨機挑選N個樣本作為初始的聚類中心,主要看樣本需求分為幾類。
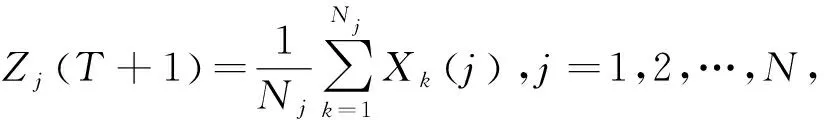
4)若Zj(T+1)≠Zj(T),j=1,2,…,N,則T=T+1,返回2),否則算法結束。
從計算方法中可以看出此種聚類方法受初始樣本和隨機選取的初始聚類中心影響很大,聚類結果往往與預期分類有所差別,因此在聚類之前基于均值漂移對樣本數據進行優化,使得初始的中心值逼近最佳位置。
均值漂移是一種基于密度梯度上升的非參數方法[16],其核心是通過計算隨機選取的中心點在一定范圍內到每一點的距離平均值,將計算平均值所得到的偏移值作為中心點,重復計算,反復迭代,使中心點逐步逼近最優位置。由于每個參數對偏移值的貢獻率不同,因此在均值漂移中引入核函數進行計算:
(5)
式(5)中,xi為雷達脈沖序列特征參數,h為區域半徑,s(xi)為各類特征所占權重。
改進后的C-均值算法流程圖如圖2所示。
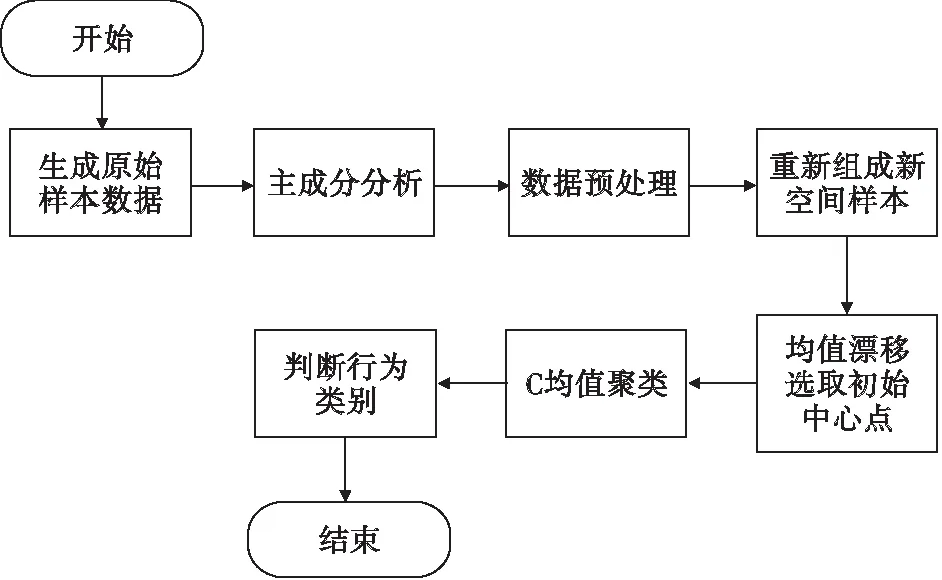
圖2 改進后的C-均值算法流程圖Fig.2 Improved C-means algorithm flow chart
改進后的C-均值算法完善了原算法對初始樣本數據過于敏感的問題,在不影響每組樣本數據分布的前提下,對預處理過的樣本再一次通過權值分配降低分類偶然性,提高聚類分析的準確性,可以更好地對雷達信號參數特性進行分析。
聚類穩定后,提取中心點參數值,根據聚類中心參數與模式間的對應關系判定模式類別,利用了脈沖參數與工作模式之間基于雷達設計準則的邏輯關系進行判斷。在缺少大數據驅動的條件下,此方法具有一定的實現價值。
3 仿真實驗與分析
本文選擇某型機載側視雷達在兩種情況下的信號參數,分別進行對工作模式的分類。雷達脈沖描述字序列由某型雷達對抗偵察設備偵收分選所得。為檢驗本文提出算法在不同行為狀態的適用性,分別在兩種不同行為狀態的數據樣本下進行實驗。仿真過程中根據雷達設計原則及先驗知識庫,對雷達每種行為狀態隨機生成初始樣本,每個樣本為8維的數組:第一組選擇在合理精度范圍內的1 000組數據,其中遠區搜索模式下300組數據,近區搜索模式下400組數據,跟蹤模式下300組數據;第二組選擇在合理精度范圍內的300組數據,其中搜索模式下224組數據,跟蹤1號目標37組數據,跟蹤2號目標39組數據。采用準確度(Accuracy)和靈敏度(Sensitivity)兩種性能評估指標對實驗結果進行分析。準確度的定義為:

(7)
是所有正確分類的數據點占總數據點的百分比。但是,由于MPAR脈沖序列組并不是均勻分布的,僅用準確度來評價是不夠完善的。例如脈沖數據包含10%的跟蹤模式和90%的搜索模式,如果檢測出所有活動都是搜索模式,那么分類準確度為90%,但此時并沒有識別出跟蹤模式。因此引入靈敏度概念對分類結果進行評價。靈敏度公式為:

(8)
3.1 實驗一
為檢驗改進后算法的有效性,對樣本數據分別進行原始聚類算法實驗、通過歸一化處理后的聚類算法實驗和基于主成分分析與均值漂移后的聚類算法實驗。得到圖3所示結果。
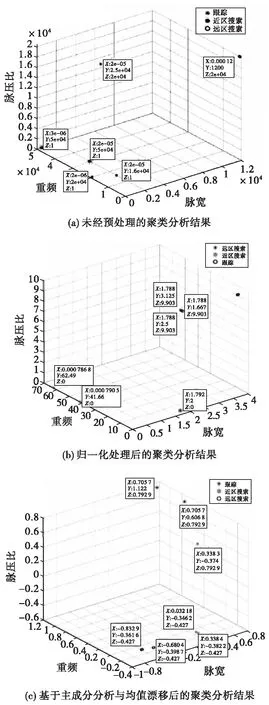
圖3 三類聚類算法實驗對比Fig.3 Experimental comparison of three kinds of clustering algorithms
通過三個實驗結果散點圖可以看出三種方法均可以完成對雷達行為狀態的聚類。表1為在不同算法下多次進行聚類分析的準確率。表2為在不同算法下雷達不同行為狀態的聚類靈敏度。
實驗結果表明,改進后的聚類算法較之前提升了分類的準確率,總分類基本可以穩定在85%左右,能夠適用于無法即刻獲取大量樣本數據進行數據驅動的算法識別的情況下,并達到一個較好的效果。對于第一組的雷達行為狀況分析,遠區搜索相較于近區搜索和跟蹤狀態,分類效果更好,準確率更高。產生這種現象的原因是遠區搜索的重頻低,脈寬寬,搜索時間長,而近區搜索和跟蹤的重頻高,其中跟蹤要求的數據率高,因此需要高重頻來保重跟蹤行為的完成。
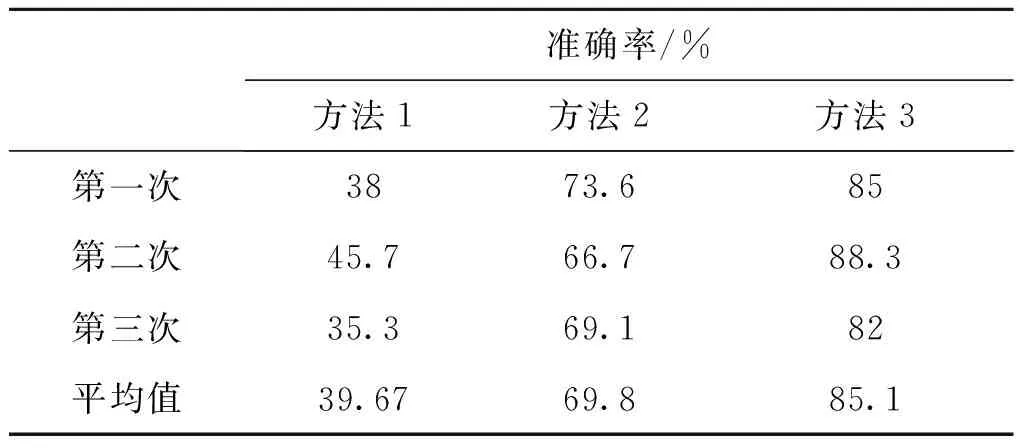
表1 聚類識別準確率
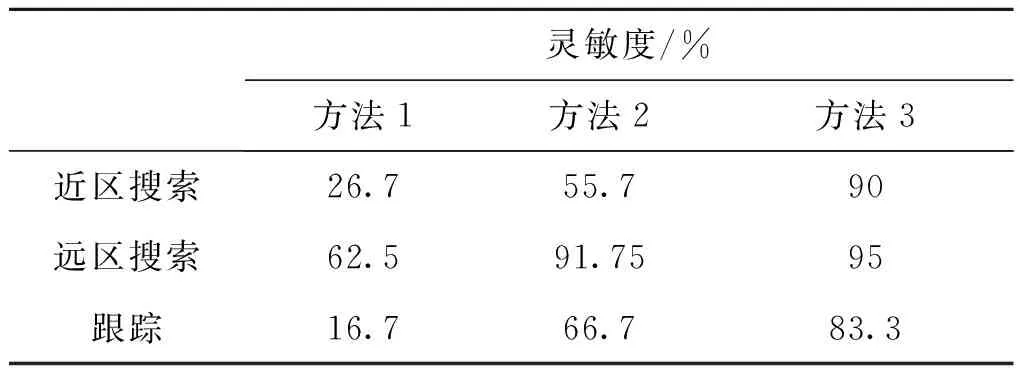
表2 各類雷達行為聚類識別靈敏度
信號參數在未經預處理的情況下使用原始C-均值聚類分析方法分類,結果容易出現類別不清、分類錯誤的情況。反復驗證之后發現,未經處理的數據在隨機選取聚類中心時,不同的聚類中心反復迭代之后的結果差別極大。數值本身的多大的量級差也使得計算歐式距離時,各點到聚類中心的距離差別不大,導致分類錯誤。算法的改進使得聚類初始中心點的選取對分類準確率的影響減弱。同時經過主成分分析,篩選得到的重頻、脈寬和脈壓比經過歸一化和權值的轉換,可以提升算法分類的性能,具有較好的效果。實驗中,改進算法在各個行為下都以較大優勢領先對比的識別算法。
3.2 實驗二
為檢驗主成分分析對算法優化產生了積極作用,對樣本數據分別在兩組不同雷達行為狀態的情況下進行實驗,對比分類的準確率。得到如圖4所示。
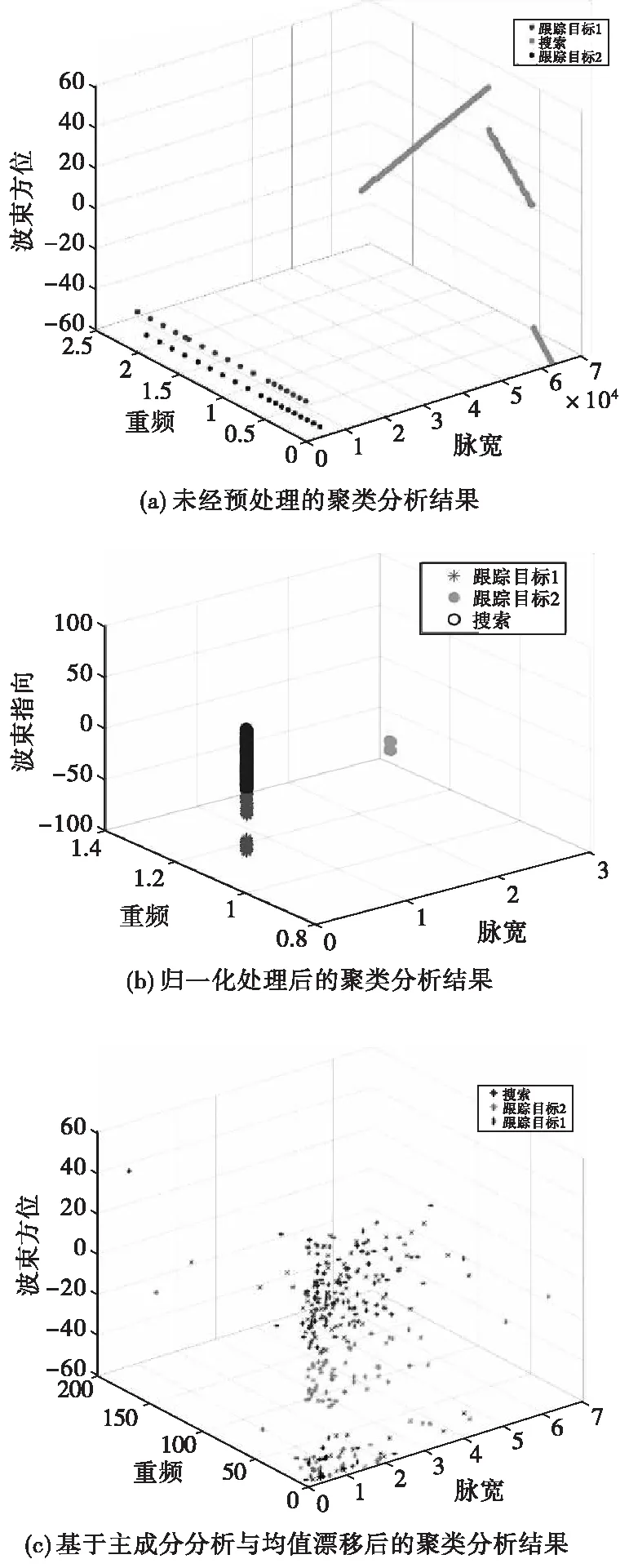
圖4 三類聚類算法實驗對比Fig.4 Experimental comparison of three kinds of clustering algorithms
實驗結果表明,經過經過改進的樣本數據更有利于聚類識別。第一組數據的搜索距離不同,使得兩類搜索方式的脈寬和重復頻率影響聚類的權值比重較大。第二組數據的跟蹤目標不同,導致兩類跟蹤方式的波束方位對聚類結果影響較大。因此第一組數據篩選出的特征參數是重頻、脈寬和脈壓比;第二組數據篩選出的是重頻、脈寬和波束方位。貢獻率較大的幾類參數能夠緩解原始算法類中心的偏移影響問題。
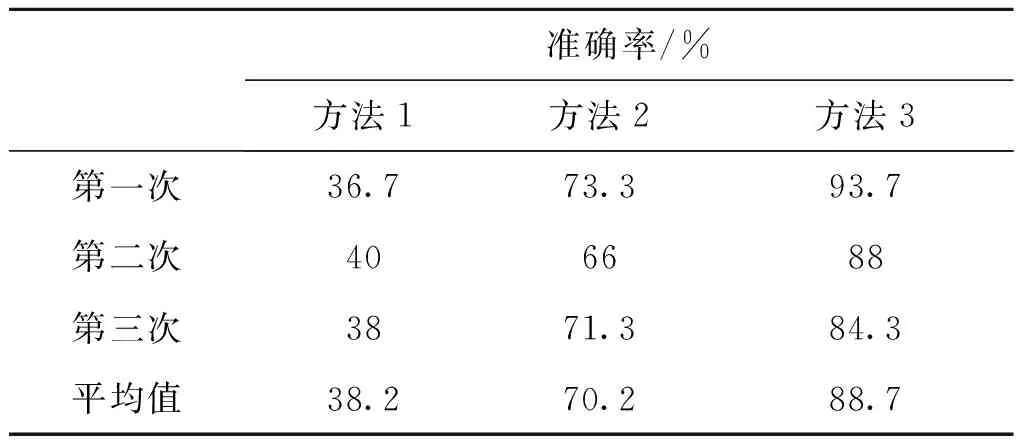
表3 聚類識別準確率
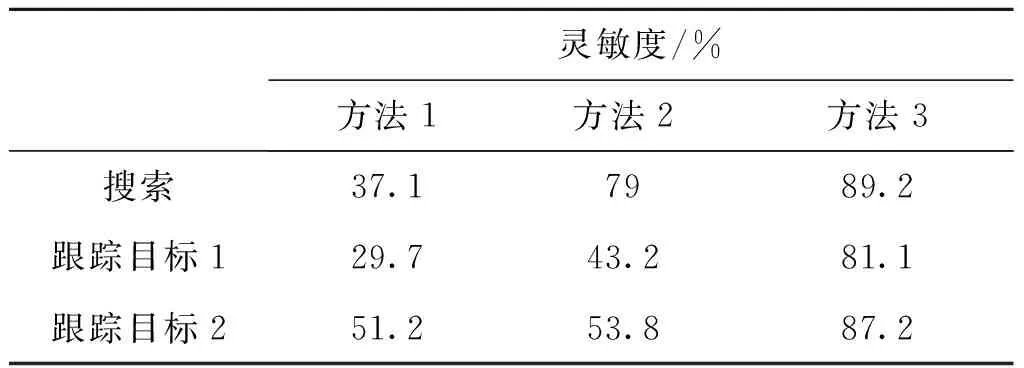
表4 各類雷達行為聚類識別靈敏度
將改進后的聚類算法與文獻[7]中的CPI矩陣算法相比,CPI矩陣算法按照經驗設定16個或32個脈沖序列為一組時,已經產生了一定的誤差。本文算法基于雷達信號參數與工作模式間的本質聯系選取特征參數,無需大量訓練樣本,即可獲得相對較高的識別正確率。即使在偵收到少量脈沖信號的情況下也可進行識別,適用于在實際戰場中突發未知雷達及信號的采取分析,判斷當前雷達行為狀態。
4 結論
本文提出了基于主成分分析的雷達行為狀態聚類分析算法。該方法克服了現實狀況下缺少大量數據樣本和先驗知識的驅動,無法建立神經網絡等有監督識別模型的困難,在適量的樣本數據條件下進行雷達行為聚類分析。該方法在使用過程中結合對數處理歸一化及主成分分析和均值漂移等辦法,降低了數據量級相差過大,聚類中心不穩定等問題的出現頻率,可以較好地在訓練樣本匱乏的條件下,對雷達脈沖特征進行分析。實驗表明,從雷達行為與雷達外部特征表現入手,尋找兩者之間的映射關系,獲取更多規律,挖掘更多信息,避免先驗信息對行為識別的限制,對之后的雷達行為識別具有一定意義。顯然,當雷達行為相近,雷達脈沖參數排布相似時,對聚類算法會產生一定影響,需要通過不斷的研究總結,建立完善合理的雷達行為特征庫,通過不斷地訓練,補充未知雷達行為對應的脈沖序列樣式,解決這一問題。
雷達脈沖序列完成聚類后,根據標簽或雷達設計準則,能夠對每一類的行為狀態進行判定。在后續的研究過程中,可以對大樣本和小樣本分別建立數據庫,大樣本數據能夠利用神經網絡、向量機等訓練模型,小樣本數據可以實時快速分析雷達行為狀態并作出應對干擾措施。為了實現雷達的行為辨識,需要不斷進行深入研究。能夠結合兩類識別方法,克服缺陷,達到一定可靠的識別正確率是之后學習研究的主要目標。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
