基于改進增強型神經(jīng)網(wǎng)絡(luò)的短期電力負荷預(yù)測?
2020-05-15 05:19:56袁小凱許愛東張乾坤張福錚
計算機與數(shù)字工程 2020年2期
關(guān)鍵詞:模型
袁小凱 李 果 許愛東 張乾坤 張福錚
(南方電網(wǎng)科學(xué)研究院 廣州 510080)
1 引言
考慮到歷史電力負荷數(shù)據(jù)、天氣、時間等信息影響,電力負荷預(yù)測用于預(yù)測未來的電力負荷,對于獨立的系統(tǒng)操作而言,有許多電力負荷預(yù)測應(yīng)用向調(diào)度員提供信息和市場操作,比如發(fā)電調(diào)度、系統(tǒng)儲備生成,因此準確的電力負荷預(yù)測模型是規(guī)劃管理和運行的必要條件[1~3]。電力負荷預(yù)測在幫助電力企業(yè)購買和發(fā)電、負荷開關(guān)、電壓控制、基礎(chǔ)設(shè)施建設(shè)等方面做出重要決策具有重要作用,同時對能源供應(yīng)商、金融機構(gòu)和其他參與發(fā)電、輸電、配電和市場營銷的參與者也非常重要。通常根據(jù)預(yù)測的持續(xù)時間,將負荷預(yù)測分為長期預(yù)測和短期預(yù)測。長期負荷預(yù)測的時間跨度為幾個月至數(shù)年,而對未來一周進行的預(yù)測通常稱為短期負荷預(yù)測。隨著預(yù)測精度的提高,運行成本的降低和電力系統(tǒng)運行的可靠性也隨著提高。本文主要研究短期電力負荷預(yù)測,因為它與電力系統(tǒng)的經(jīng)濟和安全運行密切相關(guān)。由于電力系統(tǒng)運行的經(jīng)濟性和可靠性受電力負荷的影響較大,成本節(jié)約主要依賴于負荷預(yù)測的準確性。主要調(diào)度中心的負荷調(diào)度員負責(zé)通過購買、銷售和調(diào)度電力來維持和控制電力的流動。調(diào)度員需要預(yù)先對負荷模式進行預(yù)估,以便分配足夠的發(fā)電量來滿足客戶的需求。過高估計未來的負荷可能導(dǎo)致不必要的發(fā)電機組啟動,從而導(dǎo)致儲備和運營成本的增加。低估未來負荷將導(dǎo)致為系統(tǒng)提供操作儲備和穩(wěn)定性的失敗,這將導(dǎo)致電力系統(tǒng)網(wǎng)絡(luò)的崩潰。
負荷預(yù)測的方法主要包括傳統(tǒng)和人工智能兩種,前者包括時間序列、多變量回歸和狀態(tài)估計方法,后者包括模糊邏輯[4]、支持向量機[5~6]、人工神經(jīng)網(wǎng)絡(luò)(ANN)[7~8]和預(yù)處理訓(xùn)練數(shù)據(jù)的方法,然后利用預(yù)處理后的數(shù)據(jù)使用多個ANN進行負荷預(yù)測。傳統(tǒng)的方法具有簡單性的優(yōu)點,而人工智能的方法具有較高的預(yù)測精度,因為它們可以精確地模擬所觀測到的負載與所觀測到的負載與所依賴變量間的高度非線性關(guān)系。
在本文中,通過集成學(xué)習(xí)算法提高了預(yù)測精度。在集成學(xué)習(xí)算法中,結(jié)合一組預(yù)測模型來提高預(yù)測精度。理論和實驗研究表明,當(dāng)群體中的ANN是準確的,并且每個網(wǎng)絡(luò)的誤差與該組的其他誤差呈負相關(guān)時,可以通過投票或平均ANN的輸出得到一個改進的精確泛化。在集成學(xué)習(xí)中,常用的兩種算法是套袋法和增強法[9]。這兩種算法都將單個預(yù)測模型的輸出集合起來,以提高總體預(yù)測的準確性。已有成果表明,套袋法和增強法技術(shù)均比使用單個預(yù)測模型更準確。與使用單一的ANN相比,應(yīng)用套袋法的ANN可以通過減少負荷預(yù)測誤差的方差來提高負荷預(yù)測[10]。由于許多研究成果表明它可以產(chǎn)生較低的分類錯誤率,并且對過度擬合具有魯棒性。本文提出了一種改進的短期電力負荷預(yù)測技術(shù),基于迭代生成大量的ANN模型的增強型ANN(BooNN)算法,在每次迭代中,結(jié)果模型減少了預(yù)期輸出之間的誤差,并且在之前的迭代中得到了經(jīng)過訓(xùn)練的模型所獲得的誤差[11]。同時使用一個前向階段的加法模型,通過在前一次迭代中減去目標輸出的加權(quán)估計值來更新每次迭代的目標輸出。實驗結(jié)果表明,該技術(shù)可以減少預(yù)測誤差和預(yù)測精度的變化,與使用單一的ANN、套袋法ANN和其他技術(shù)相比,采用BooNN方法可減少計算時間,提高收斂速度。
2 人工神經(jīng)網(wǎng)絡(luò)
由于電力負荷負載的情況依賴于多種因素,如天氣、時間、經(jīng)濟、電價、隨機擾動和地理條件,所以提出了許多負荷預(yù)測技術(shù),并應(yīng)用于準確預(yù)測負荷模式。負載的情況多受到幾個因素的影響,同時負載模式與影響因素之間的關(guān)系是非線性的。基于人工智能的算法在處理非線性關(guān)系時具有很大的優(yōu)勢,如模糊邏輯、支持向量機和神經(jīng)網(wǎng)絡(luò),進行了大量的基于人工智能算法的應(yīng)用負荷預(yù)測問題研究,因為可以執(zhí)行比傳統(tǒng)的短期負荷預(yù)測方法,如支持向量機和ANN,包括類似的小波神經(jīng)網(wǎng)絡(luò)和混合ANN模型等。在這些算法中,由于其易于實現(xiàn)和良好的性能,ANN模型已經(jīng)廣泛應(yīng)用。
ANN是一個由人工神經(jīng)元組成的學(xué)習(xí)系統(tǒng),其試圖模擬人腦的功能。通常ANN體系結(jié)構(gòu)包括輸入層、隱含層和輸出層三層。第一層的輸入由不同的因素或特征組成,對想要的預(yù)測輸出有顯著影響。隱含層利用這些特性來計算中間值,最后一層的輸出由預(yù)測值組成。
ANN的每個隱含層都由N個神經(jīng)元組成。每一層的輸入乘以權(quán)重Wl,然后添加到偏差bl中。權(quán)重矩陣將輸出從(l -1)層擴展到第lth層。例如在t時刻的具有F個特征的輸入如下:
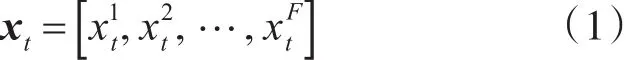

式中,W1是一個權(quán)重矩陣,b1是一個偏置向量,ρ1是一個激活函數(shù)。同時每一層的輸出都是下一層的輸入,因此,最終的輸出有效地包含了每一層的權(quán)重輸入和增加的偏差。最后一層L的最終輸出是:
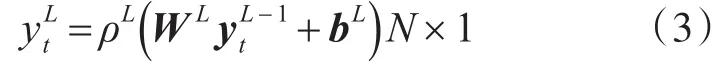
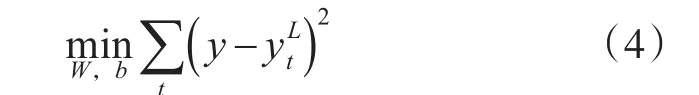
3 基于增強法的短期電力負荷預(yù)測
在短期電力負荷預(yù)測中,需要研究不同的獨立參數(shù)對電力負荷的影響。通過給出在離散時間t=1,2,…,T內(nèi)的 X過去值,可得到對應(yīng)的觀測值y,兩者間可以用模型 f表示如下:

對應(yīng)該模型函數(shù) f?需要符合如下條件:
1)估計值有較小的偏差,即前一次觀測的負載y和負載 y?間的偏差應(yīng)該較小。
2)預(yù)測值有較低的方差。在所有模型的平均預(yù)測中,不同模型的預(yù)測之間不應(yīng)該有很大的差異。
3)該函數(shù)應(yīng)避免過度擬合,即模型應(yīng)該能夠忽略觀測中的隨機誤差。
模型通過已知的獨立特征和依賴荷載觀測得到,以及給出的預(yù)測的獨立參數(shù),可以用來預(yù)測下面的負荷。需要注意的是X和y可以看作是訓(xùn)練數(shù)據(jù),因為通過它們可以建立描述兩者之間關(guān)系的函數(shù),并用該函數(shù)來預(yù)測未來時間對應(yīng)的數(shù)據(jù)。
由于 f是一個高度非線性函數(shù),類似ANN和SVM智能算法多用于快速逼近該函數(shù)。為了進一步提高負荷預(yù)測精度,本文采用了基于ANN的集成學(xué)習(xí)方法。使用一組ANN模型,通過對不同的數(shù)據(jù)集進行訓(xùn)練,得到每個ANN模型。將這組集合的模型融合在一起,得到最終的估計預(yù)測。
在分類問題上增強法得到了廣泛應(yīng)用,但還沒有應(yīng)用到許多回歸問題[12~13]。利用 ANN提高負荷預(yù)測的目的是減少預(yù)測誤差的偏差和方差,并且對過度擬合具有很強的魯棒性。在推進過程中,通過模型迭代生成目標。首先,在迭代中,通過使用獨立特性和依賴目標輸出組成的原始訓(xùn)練數(shù)據(jù),在第ith迭代時生成初始的模型h?i。在下一個迭代次數(shù)i+1中,由第一個模型的預(yù)測錯誤代替輸出目標生成第二個模型。

式中,hi是通過第i個模型得到的目標輸出與實際輸出之間的誤差,αi是每個模型的權(quán)值。該過程一直持續(xù)到生成一定數(shù)量的M個模型,可以將所有這些模型形成一個集合F,該集合可以由一組估計 f?的預(yù)測因子表示如下:
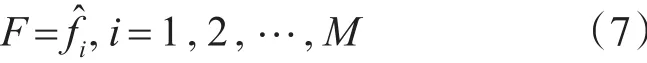
隨后,將上述提出的預(yù)測器進行線性組合,可以描述如下:

式中,αi是第ith預(yù)測器的權(quán)值,該權(quán)值與每個函數(shù)的輸出相乘并相加得到對應(yīng)的最終輸出。對于負荷預(yù)測問題,需要研究由獨立變量Xtr和負載ytr組成的訓(xùn)練數(shù)據(jù)集。利用增強法的步驟如下:
1)首先,定義以下參數(shù):模型迭代的總數(shù)為常數(shù)值M,在i=1,2,…,M 時,αi=α0,α0是0和1之間常數(shù),
2)每個模型都是迭代生成。在第一次迭代i=1時,利用一下公式計算模型
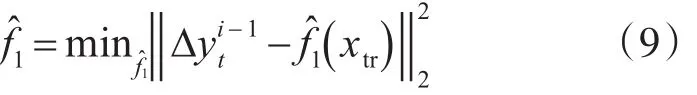
3)從i=2到i=M ,殘差 ?y1
t更新如下:
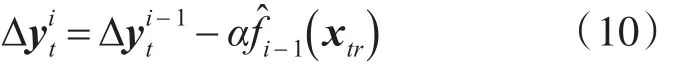
利用更新后的殘差計算一個新的ANN模型,如下:
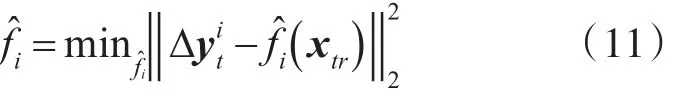
在每次迭代中使用更新的估計值的權(quán)值,可避免只使用一部分參數(shù)帶來的過度擬合。
4)在所有迭代的末尾,在每次迭代中將獲得的所有ANN模型定義為集合。
5)結(jié)合給定的獨立數(shù)據(jù)X,預(yù)測負荷以加權(quán)總求和的形式計算得到集合中所有模型的輸出結(jié)果如下:

4 仿真結(jié)果
為了更好地比較提出算法的優(yōu)越性,結(jié)合具體數(shù)據(jù)分別將BooNN算法與ANN、BNN、ARMA模型、HybANN和BRT算法進行比校[14~16]。
4.1 數(shù)據(jù)集
為了實現(xiàn)各算法比較的真實性,統(tǒng)一選取來自廣州地區(qū)的歷史小時溫度和負荷模式,用作比較負荷預(yù)測的性能。用在訓(xùn)練和預(yù)測負載模式不同的獨立參數(shù)包括干球溫度、露點溫度、一天的小時、一星期的天數(shù)、顯示哪些天是假期或周末的標志、前一天的平均負荷,24h內(nèi)負荷的差別,以及前一周相同天和小時的負載。作為短期負荷預(yù)測的這些參數(shù),同樣在負載模式上表現(xiàn)出相關(guān)的特點。對應(yīng)的訓(xùn)練數(shù)據(jù)集包含由這些變量組成的數(shù)據(jù)向量,以及在這些數(shù)據(jù)所給出的時間內(nèi)所測量的電力負荷對應(yīng)的目標輸出。將2014-2017年的樣本用于訓(xùn)練,同時為了提高計算預(yù)測模型的準確性,將2018-2019年的樣本也應(yīng)用在短期負荷預(yù)測中。
4.2 在BooNN中選擇ANN模型
通過不同的實驗,得到了最佳性能的神經(jīng)網(wǎng)絡(luò)模型參數(shù)。第一個實驗分別采用以下訓(xùn)練算法:Levenberg-Marquardt反向傳播(LMB)、貝葉斯正則化反向傳播(BRB)、彈性反向傳播(RB)、梯度下降法和自適應(yīng)學(xué)習(xí)速率反向傳播(GDMAB)。隱含層和輸出層的激活函數(shù)分別選為Sigmoid型和線性函數(shù),因為這樣的配置通過訓(xùn)練近似任何有限數(shù)目不連續(xù)的函數(shù)。輸入層中神經(jīng)元的數(shù)量選為8,該數(shù)目等于輸入訓(xùn)練和測試數(shù)據(jù)中變量的數(shù)量。輸出層中有一個神經(jīng)元,因為最終的預(yù)測輸出是一個標量。實驗中只有一個隱含層,初始值從0到1不等。基于LMB和BRB的ANN表現(xiàn)出較好的性能,幾乎與初始值無關(guān),其次是RB和GDMAB算法。LMB用作接下來的ANN模型的訓(xùn)練算法。
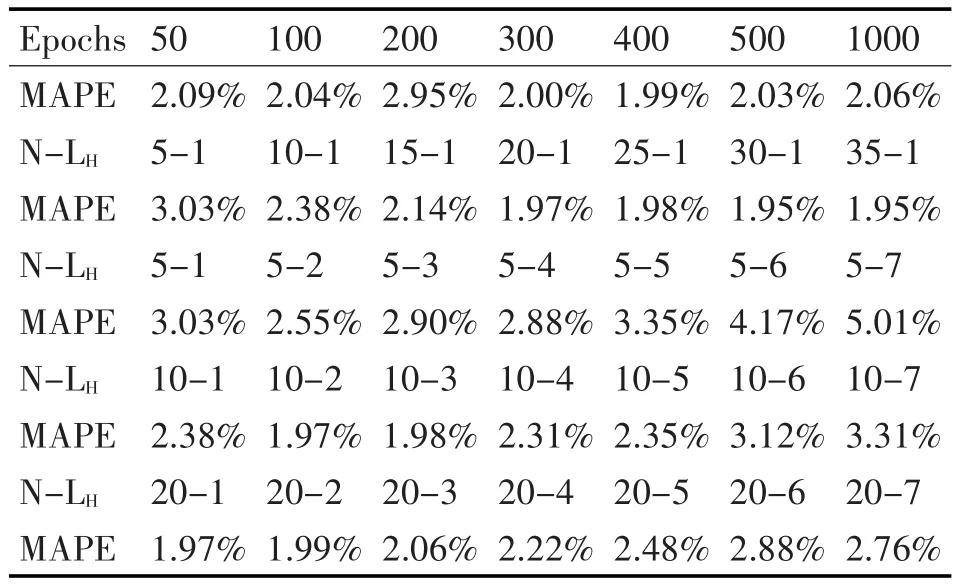
表1 不同時間、節(jié)點數(shù)和隱含層時的MAPE值
下一個實驗比較了ANN的性能,它具有不同的時間、節(jié)點數(shù)和隱含層數(shù),如表1所示。在表中,N-LH表示在LH隱含層中神經(jīng)元的數(shù)量。對于時間節(jié)點大于500,節(jié)點數(shù)大于20和隱含層數(shù)大于1的情形,在性能上沒有顯著提高。在200個時間節(jié)點內(nèi),MAPE會產(chǎn)生一個突變,其原因在于隨著時間的減少,ANN可能沒有經(jīng)過適當(dāng)?shù)挠?xùn)練導(dǎo)致輸出結(jié)果不穩(wěn)定。在時間節(jié)點大于300或更大時,MAPE幾乎保持不變。隨著節(jié)點數(shù)目的增加,MAPE減少,而隨著節(jié)點數(shù)量的增加,減少的百分比也減少了。此外,對于固定數(shù)目的節(jié)點,當(dāng)層數(shù)大于2時,MAPE也增加。當(dāng)節(jié)點數(shù)是20,隱含層從1到2增加時,MAPE的下降百分比非常低,同時20個節(jié)點、1隱含層的性能與10個節(jié)點、2個隱含層的性能相似。基于上述實驗結(jié)果,在BooNN中使用的ANN模型,其選取參數(shù)為500個時間節(jié)點,一個隱含層中20個節(jié)點。
4.3 不同的樣品迭代次數(shù)比較
不同迭代次數(shù)和訓(xùn)練樣本大小對負荷預(yù)測精度的影響如表2所示。訓(xùn)練樣本的大小從15000到35000,步長為500。迭代次數(shù)從5到25變化,步長為5。通過計算每個訓(xùn)練樣本的大小/迭代次數(shù)得到的平均絕對百分比誤差(MAPE)如下:
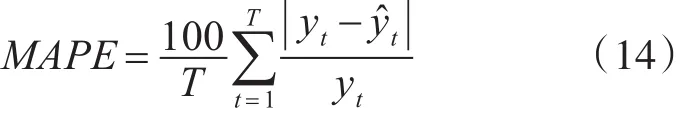
式中,yt是荷載的實際值,y?t是荷載的預(yù)測值,t是荷載樣本的總數(shù)量。可得到如下的結(jié)論:
1)對于每個迭代次數(shù),隨著訓(xùn)練樣本數(shù)量的增加,MAPE減少。
2)從2000后開始的每個樣本,25次迭代的MAPE比5次迭代的要小。
3)從迭代5次到迭代25次,MAPE漸漸減少,并在最小值附近波動。
4)當(dāng)訓(xùn)練樣本不足時,15000個樣本的特性和迭代次數(shù)表現(xiàn)出不穩(wěn)定。在這種情況下,隨著迭代次數(shù)增加MAPE也增加,在一定數(shù)量的迭代后,容易導(dǎo)致過度擬合。
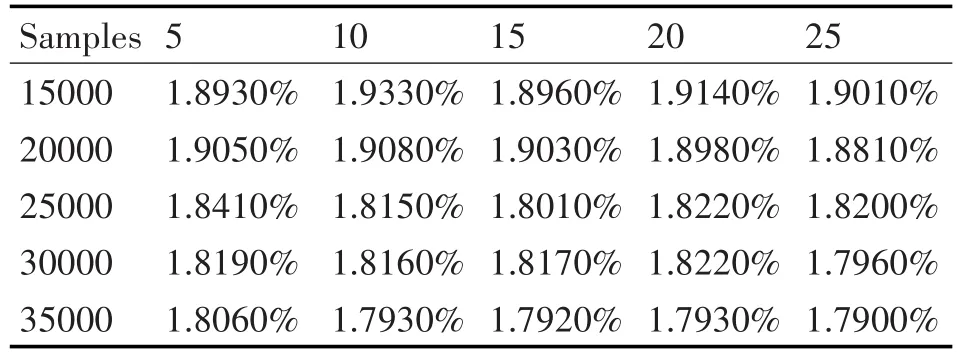
表2 不同采樣數(shù)目和迭代次數(shù)時的MAPE值
圖1進一步表明25000和35000個樣本存在的特性。隨著迭代次數(shù)增加,MAPE的波動會減少,特別是迭代次數(shù)大于20。35000個樣本的MAPE比25000個樣本的MAPE要小。雖然在最后這個差異更小,但是在每個迭代中新的訓(xùn)練模型有助于減少MAPE的值。
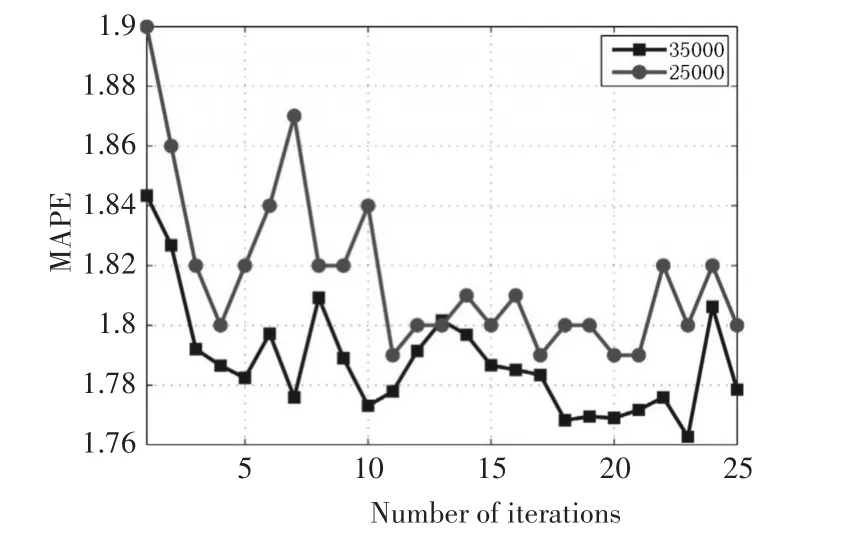
圖1 迭代次數(shù)與MAPE值的關(guān)系
4.4 計算時間與權(quán)重對MAPE的影響
在改變權(quán)重時,MAPE的變化如圖2所示。權(quán)重的變化從0.25到1.5,步長為0.25。為了便于比較,本文利用BNN進行了50次迭代得到MAPE,并給出了最佳的ANN。由于這兩種方法的MAPE不受權(quán)重影響,對應(yīng)為一個恒定的值。對樣本數(shù)量為35000,迭代次數(shù)為25,可以看出在α<1時BooNN的MAPE值小于ANN和BNN的值,這意味著權(quán)重α應(yīng)該保持小于1。因此,在α<1時BooNN與使用單一ANN和BNN相比提高了性能。
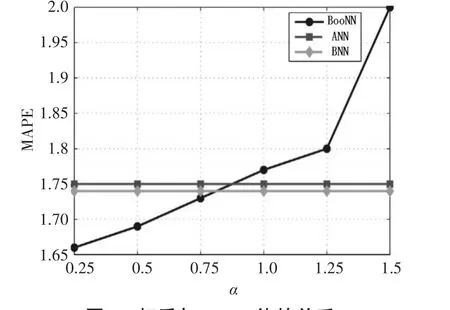
圖2 權(quán)重與MAPE值的關(guān)系
在改變權(quán)重時,計算時間的變化如圖3所示。權(quán)重的變化從0.25到1.5,步長為0.25。在權(quán)重從0.25到1時,BooNN的計算時間逐漸變小。從權(quán)重為1后,BooNN的計算時間逐漸增加。此外,從ANN和BNN的MAPE為常數(shù)值可以看出,雖然BooNN的計算時間大于單個ANN的計算時間,但比使用BNN少3到8倍。
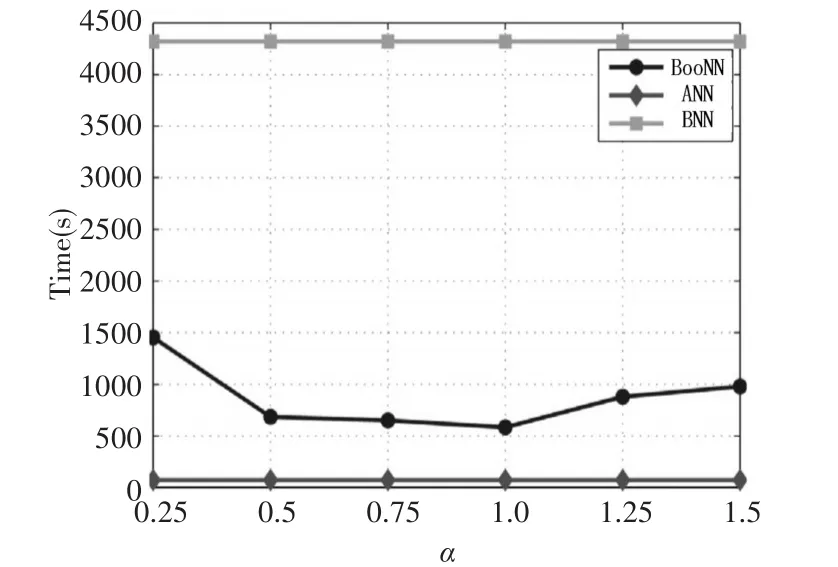
圖3 權(quán)重與計算時間的關(guān)系
4.5 單個ANN和套袋法ANN的比較
在權(quán)重α=0.5時,分別比較了ANN、BNN和BooNN算法的MAPE值,以及權(quán)重α=1時BooNN算法的MAPE值,如圖4所示。可以知道:
1)BooNN的MAPE值與BNN的MAPE值近似或者小,相比于單個ANN的MAPE要小的多。
2)相比于BNN,BooNN的最大MAPE值較多,相比于ANN,則較少。雖然在權(quán)重α=0.5時,幾乎沒有樣本的MAPE較大。
3)在權(quán)重 α=1時BooNN的MAPE值比權(quán)重α=0.5時分布的更廣。在權(quán)重α=0.5時BooNN相比BNN擁有較低的平均值和相似變化,以及相對單個ANN有較低的變化,可以看出BooNN可以減小MAPE的變化。雖然對α=1而言變化更大,但是相比于ANN該分布已經(jīng)大于一個更低的值。
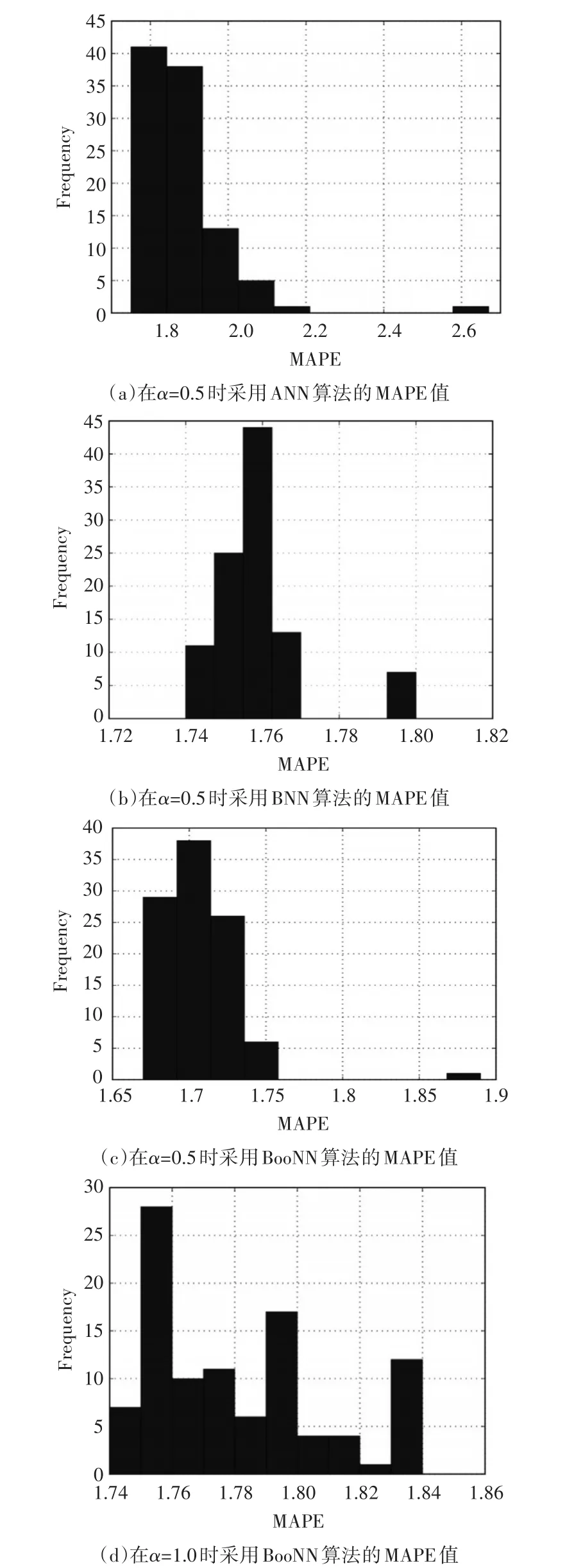
圖4 采用不同算法時MAPE的取值情況
4.6 與現(xiàn)有技術(shù)比較
將本文提出的算法與現(xiàn)有技術(shù)進行了進一步的比較,包括BNN,以及一種基于類似改進的小波神經(jīng)網(wǎng)絡(luò)(WNN)和BRT的自適應(yīng)模型。為此,選擇了2014年和2016年的廣州訓(xùn)練和測試數(shù)據(jù)集。相比較上述算法,使用BooNN計算的月復(fù)月的MAPE和平均的MAPE均相對較小。圖5顯示了各種算法12個月的MAPE值。除了11月和12月,使用BooNN算法的每月MAPE值均小于SIWNN算法,尤其是在6、7和8這三個月。與BNN和BRT相比,除了7月份,比BNN稍高,BooNN算法的MAPE值總是最少的。使用BooNN算法得到的平均MAPE為1.43%,而BNN、SIWNN和BRT分別為1.5%、1.71%和2.44%。在提高預(yù)測精度方面,與現(xiàn)有其他技術(shù)相比,可以看出BooNN算法的優(yōu)越性能。
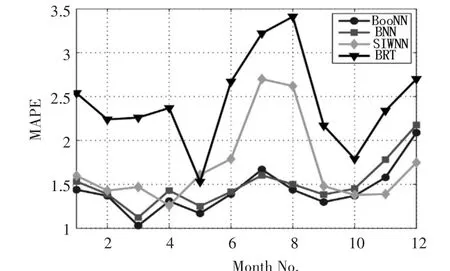
圖5 BooNN和SIWNN,BNN,BRT算法的MAPE值比較
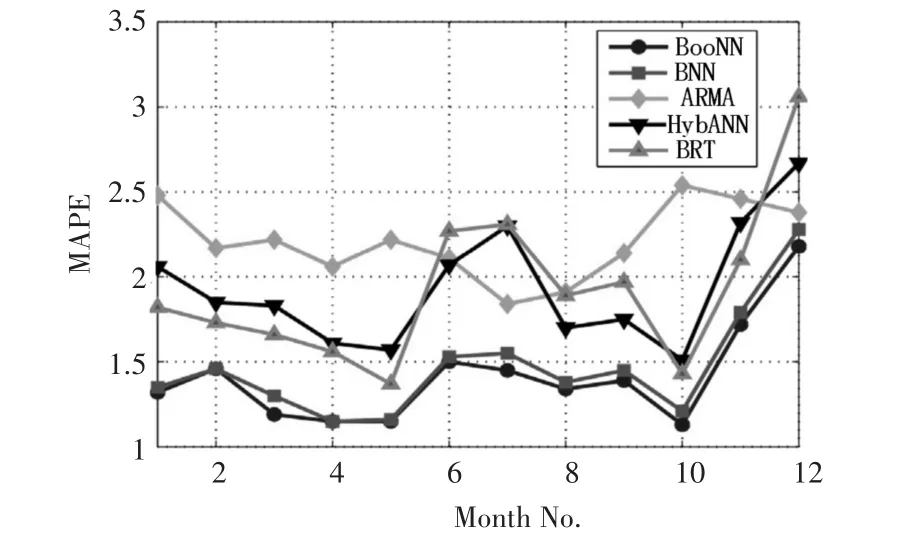
圖6 BooNN和ARMA,HybANN,BNN and BRT算法的MAPE值比較
下面,通過計算2018年的MAPE,將BooNN算法的性能與傳統(tǒng)的ARMA、HybANN、BNN和BRT進行比較。從圖6可以看出,相比上述算法,BooNN的MAPE均較小。雖然與BNN相比,兩種算法的MAPE值相差不大,但是結(jié)合如圖3可以知道,BooNN的計算時間比BNN少的多。因此,考慮到BNN的預(yù)測精度,BooNN在計算節(jié)省方面也有很大的提高。除ARMA外,其他技術(shù)與BooNN相比需要更少的時間,但是與BooNN相比,它們的性能要差很多。使用BooNN算法得到的平均MAPE為1.42%,而 ARMA、HybANN、BNN和 BRT分別為2.21%、1.94%、1.47%和1.93%,再次表明BooNN的預(yù)測精度較高。
5 結(jié)語
本文提出了一種改進的增強型神經(jīng)網(wǎng)絡(luò)(BooNN)的短期電力負荷預(yù)測算法,該算法包括一系列訓(xùn)練用的人工神經(jīng)網(wǎng)絡(luò)(ANN)。在每一次迭代中,利用訓(xùn)練的ANN模型,實現(xiàn)從前一次迭代的預(yù)測模型得到的估計值和實際值的之間誤差最小。實驗表明,當(dāng)計算輸出的模型數(shù)大于或等于20時,可以得到較低的預(yù)測誤差。與單個ANN、套袋法ANN、改進的小波神經(jīng)網(wǎng)絡(luò)、ARMA、混合不受監(jiān)督的ANN等算法相比,BooNN在降低誤差方面表現(xiàn)較好,與BNN相比,節(jié)省了計算時間。使用直方圖的統(tǒng)計分析進一步表明,使用BooNN得到的誤差較低,與使用單一ANN和BNN相比,波動更小。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
