改進biLSTM網絡的短文本分類方法
2020-04-24 03:08:00李文慧張英俊潘理虎
計算機工程與設計 2020年3期
李文慧,張英俊,潘理虎
(太原科技大學 計算機科學與技術學院,山西 太原 030024)
0 引 言
短文本自身信息少、特征表示高維稀疏、語義分布不明顯、無序性、噪音嚴重等給信息抽取造成了一定的困擾[1],并且目前的文本分類模型缺乏穩健性、泛化能力差、易受干擾[2]。
繼圖像處理之后深度學習在自然語言處理(NLP)領域掀起了熱潮[3]。深度學習更深層次的表達文本信息,無需先驗知識,在訓練過程中不僅容納海量數據還集特征提取和性能評價于一體,有極大優越性。
深度學習中表現良好的文本分類模型——長短期記憶網絡(long short-term memory,LSTM)[4],LSTM是循環神經網絡(recurrent neural network,RNN)中的一種,適合處理信息傳播過程中間隔和延遲相對較長的信息,提取重要特征,LSTM在RNN的基礎上增加了神經元中控制信息出入有記憶功能的處理器——門(gate)機制,解決長短距離依賴的問題;常見的LSTM文本分類模型有多種,YL Ji等[5]提出將RNN和CNN(卷積神經網絡)相結合的短文本分類模型,解決傳統人工神經網絡(ANN)在短文本語料集上分類效果不佳的問題;F Li等[6]提出基于低成本序列特征的雙向長短期記憶遞歸神經網絡,學習實體及其上下文的表示,并使用它們對關系進行分類,解決關系分類問題;張沖[7]提出基于注意力機制的雙向LSTM模型,利用LSTM長短距離依賴的優勢降低文本向量提取過程中語義消失和特征冗余;謝金寶等[8]提出多元特征融合的文本分類模型,由3個通路(CNN、LSTM、Attention)組成提取不同層級的特征,增強模型的辨別力。
1 相關工作
深度學習模型,包括卷積神經網絡、循環神經網絡,即使性能表現優越,但缺乏對噪音示例正確分類的能力,特別是當噪音被控制在人類無法察覺的范圍內時,對噪聲樣本的辨別力不從心,模型的過擬合嚴重,泛化能力不夠;通常的解決辦法有:
(1)使用不同種類的正則化方法簡化模型,排除模型記憶訓練數據導致泛化能力差的原因;
(2)結合多重神經網絡提高泛化能力;
(3)均化或者加入更多噪聲樣本應付敵對數據;
(4)從數據、算法性能上優化。
對抗訓練[9]由Goodfellow提出,在深度學習模型訓練方面扮演者一個很重要的角色,作為正則化方式之一,不但優化了模型的分類性能(提升準確率),防止過擬合產生敵對樣本,還通過產生錯誤分類反攻模型讓錯誤樣本加入訓練過程中,提升對敵抗樣本的防備能力,使之擁有更好的泛化能力和魯棒性,并且模型的分類準確率的預測值在添加對抗性噪音前后盡可能變化范圍不大。
本文在雙向LSTM的基礎上結合對抗訓練和注意力機制構造一種神經網絡模型(bi-LSTM based on adversarial training and attention,Ad-Attention-biLSTM);首先,利用雙向LSTM更加豐富的表達上下文信息,每個詞被embedding之后經過時間序列學習長遠距離深層次的文本信息并提取特征;其次,利用注意力機制[10]計算詞級別的特征重要程度,為其分配不同的權重,增強具有類別區分能力特征詞的表達,弱化冗余特征對文本分類的影響;然后,通過損失函數在LSTM輸入層詞向量上做很小的擾動,驗證擾動對短文本分類效果的影響;在數據集DBpedia上利用本文提出的方法進行實驗,與短文本分類模型Attention-LSTM、Attention-biLSTM、CNN、CNN-lSTM、Word2vec的相比,從分類準確率、損失率方面進行分析,本文構建的模型在魯棒性、穩健性、抗干擾性等方面表現較好。
2 短文本分類模型
基于對抗訓練和注意力機制的bi-LSTM文本分類模型如圖1所示。
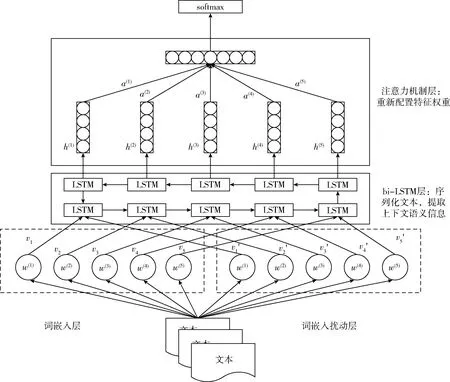
圖1 基于對抗訓練和注意力機制的Bi-LSTM文本分類模型
2.1 輸入層
現有的神經網絡深度學習模型不穩定,看似不可察覺的輸入錯誤可能導致模型受到影響,現實情境中如果發生錯誤分類代價將不可估量,比如郵件過濾系統,錯誤地對攻擊性郵件進行分類;我們希望通過一些方法來計算得到對抗樣本,對數據集進行小而故意的最壞情況的擾動形成新的輸入,使其參與到訓練過程中來提升模型的性能,進而提升模型對抵抗樣本的防御能力,受擾動的輸入導致模型輸出一個高置信度的錯誤答案,這表明對抗性示例暴露了深度學習模型的盲點,在高維空間中,深度學習模型缺乏抵抗對抗擾動的能力容易導致錯誤分類,淺層的softmax回歸模型也容易受到對抗性例子的影響,通過設計更強大的優化方法來成功地訓練出深層的模型,可以減少敵對樣本對模型的影響。
對抗訓練是一種正則化的方法用于提高分類模型的魯棒性。Ian J. Goodfellow等[11]認為神經網絡易受對抗性擾動的主要原因是它們的線性特性,在MNIST圖像數據集增加擾動進行對抗訓練,減少了數據集上最大輸出網絡的測試錯誤;Takeru Miyato等[9]把對抗訓練應用于半監督化的文本分類中,并引入虛擬訓練,實驗結果表明詞嵌入質量提高,而且模型不太容易過擬合;張一珂等[12]把對抗訓練應用于增強語言模型的數據,通過設計輔助的卷積神經網絡(CNN)識別生成數據的真假,該方法克服了傳統的缺陷,降低了錯誤判別特征的錯誤率。
文本中詞匯的表示方式一般為離散形式的,包括詞獨熱和向量表示,每個文本中T個詞匯的序列表示為{w(t)|t=1,…,T}, 其對應的類別為y,定義詞向量(word embeddings)矩陣V∈R(K+1)×D, 其中K是詞匯表中的詞匯數;輸入層分為兩部分:普通的詞向量嵌入層和經過擾動后的詞向量嵌入層,擾動后的輸入層如圖2所示,普通輸入層中vk是第i單詞的嵌入,為了將離散詞匯輸入轉變為連續的向量,擾動輸入層用正則化嵌入vk′來替換嵌入vk,定義為
(1)
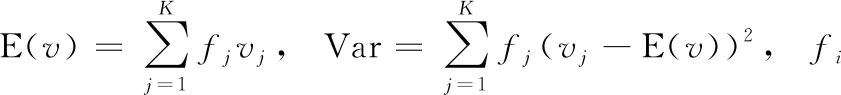
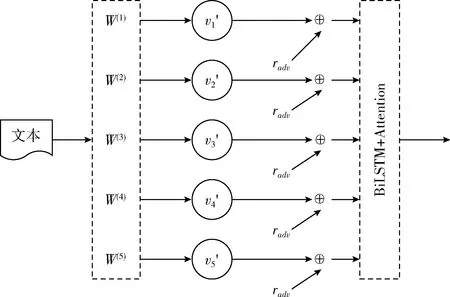
圖2 輸入層擾動模型
在模型輸入擾動層詞嵌入部分vk′做調節,把擾動radv添加到詞嵌入,然后將擾動后的輸入重新喂給模型(biLSTM-Attention),其中radv是通過L2正則化約束和神經網絡中的反向傳播梯度下降函數求得
(2)
(3)
2.2 Bi-LSTM層
在文本分類任務中,每個特征詞存在序列關系且其表達受上下文不同距離特征詞的影響。雙向長短時記憶時間遞歸神經網絡(Bi-LSTM)每個序列向前和向后分別是兩個LSTM層,彌補了LSTM缺乏下文語義信息的不足,每個LSTM層均對應著一個輸出層,雙向結構提供給輸出層輸入序列中每個時刻完整的過去和未來的上下文信息,門機制決定信息的傳輸,能夠學習到對當前信息重要依賴的信息,遺忘門決定丟棄哪些對分類不重要的信息,輸入門確定哪些信息需要更新,輸出門決定輸出哪些信息;其中遺忘門信息更新如式(4)所示,激活函數δ使用sigmoid
ft=δ(Wf·X+bf)
(4)
輸入門信息更新如式(5)所示
it=δ(Wi·X+bi)
(5)
輸出門信息更新如式(6)所示
ot=δ(Wo·X+bo)
(6)
單元狀態信息更新如式(7)所示
ct=ft⊙ct-1+it⊙tanh(Wc·X+bc)
(7)
t時刻隱層狀態信息更新如式(8)所示
h(t)=ot⊙tanh(ct)
(8)
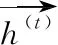
2.3 注意力機制層
在短文本分類過程中,傳統的方法直接把Bi-LSTM層每個時刻對應的更新輸出向量求和取平均值,這樣就默認為每個特征詞匯對于區分文本類別有相同的貢獻程度,然而短文本特征向量表示高維稀疏,存在大量噪音和冗余特征,直接求和取平均值容易導致分類精度不高,所以我們更期望冗余或者不重要的特征詞權重占比更小,而擁有強的類別區分能力的特征詞權重占比更大;近年來注意力機制(Attention)被應用在自然語言處理中,類似于人腦注意力分配機制,通過視覺快速掃視眼前所見景象,聚焦需要重點關注的目標景象,然后對這一目標景象攝入大量的時間及注意力,以得到更多和目標景象相關的細節信息,進而抵觸其它無用信息,人類注意力機制在很大程度上提高了視覺范圍內信息加工的準確性和效率;在自然于然處理文本分類中借鑒注意力機制,對目前任務貢獻量不同的區域劃分不同的比例權重,目的是從大量的信息中篩選出對分類更至關重要的信息,每個時刻的輸出向量可以理解為這個時刻的輸入詞在上下文的語境中對當前任務的一個貢獻,如圖3所示是注意力機制編碼模型,注意力機制分配權重的形式如式(9)、式(10)所示
ut=tanh(Wwh(t)+bw)
(9)
(10)
s=∑ta(t)ut
(11)
其中,h(t)是注意力機制層經過Bi-LSTM層語義編碼得到的輸入,ut、Ww、bw是注意力機制層的參數,a(t)是h(t)對應特征詞對區分文本類別貢獻程度的評分權重,s是輸出向量的加權值。
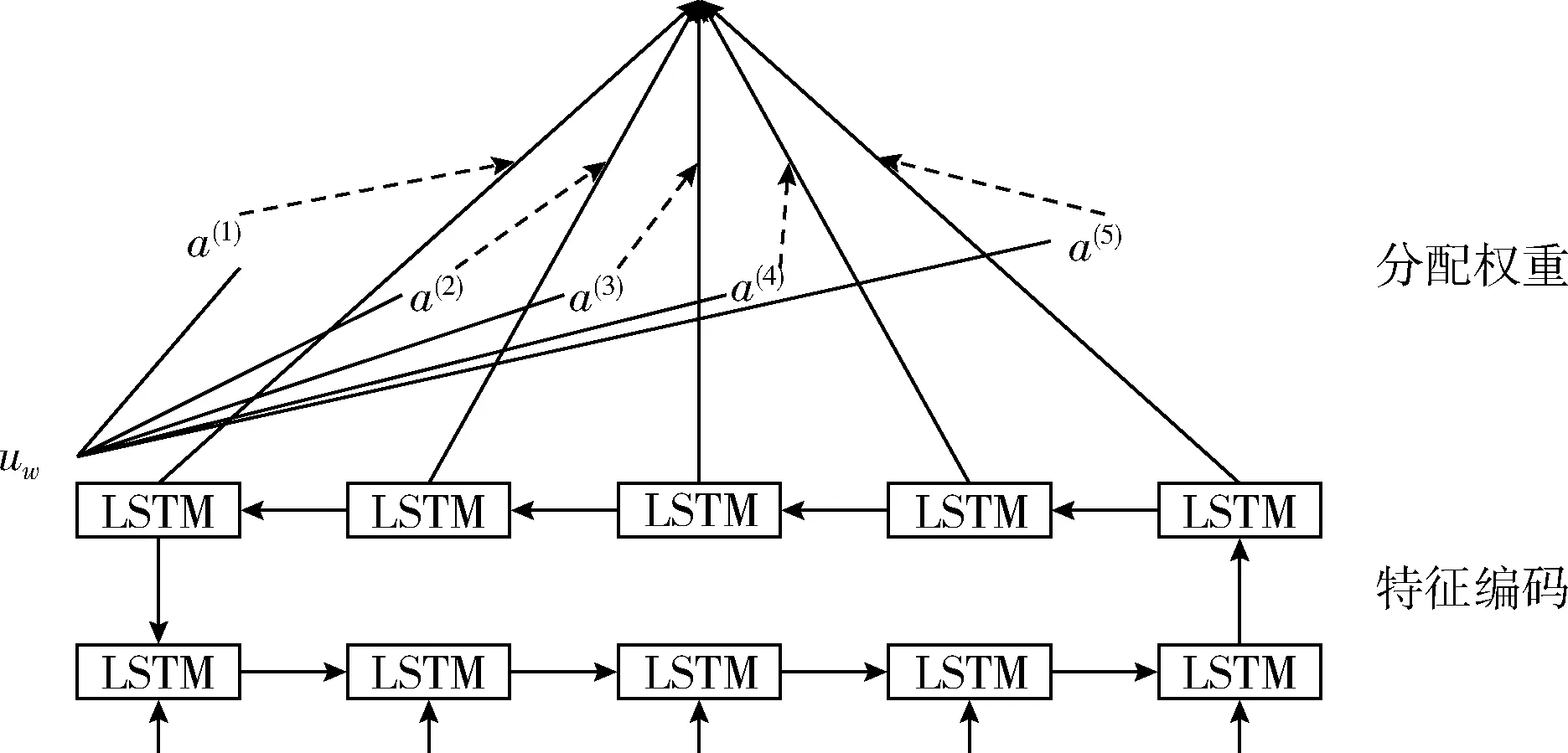
圖3 基于注意力機制編碼模型
2.4 模型優化層
將輸入層的兩部分分別喂給模型進行訓練,經由biLSTM層和注意力機制層后,通過softmax層計算模型的交叉熵損失函數loss如式(12)~式(14)所示
(12)
(13)
(14)
其中,loss1是輸入層沒有擾動時模型的損失函數,lossadv是嵌入層擾動后模型的損失函數,把loss1和lossadv取平均值計算總loss,然后經過函數對loss進行優化,使其達到最小。
3 實驗設置
3.1 實驗數據設置與處理
本文文本分類使用的語料來自于維基百科的DBpedia數據集,有56萬數據訓練集,7萬測試集,共15個類別,設置文本長度不超過100個單詞,每個文本由結構化的3部分組成包括文本類別、標題、內容,由于是英文語料無需分詞處理,對其去停用詞處理。
3.2 實驗環境設置
實驗環境為python 3.5、64位,使用tensorflow框架,CPU處理器。
3.3 實驗參數設置
通過預先訓練好的biLSTM語言模型初始化詞向量嵌入矩陣和模型權重,正向和反向的LSTM均具有512個隱藏單元,兩個單向的LSTM共享詞嵌入,其它超參數和單向LSTM相同,在數據集上單詞嵌入維度256,帶有1024個候選樣本的softmax損失函數進行訓練,優化函數使用AdamOptimizer,批量大小為256,初始學習率為0.001,每步訓練的學習率為0.9999指數衰減因子,訓練了 100 000 步,除了詞嵌入外,所有參數都采用范數為1.0的梯度裁剪,為了正則化語言模型,在嵌入層的詞嵌入部分中應用了參數為0.5的信息丟失率,在目標y的softmax層和biLSTM+Attention的最終輸出之間,添加了一個隱藏層,維度是128,隱藏層的激活函數使用ReLU。
3.4 實驗結果分析
把本文提出的方法(Ad-Attention-biLSTM)和注意力機制的長短時記憶網絡(Attention-LSTM)、注意力機制的雙向長短時記憶網絡(Attention-biLSTM)在DBpedia數據集上進行實驗,兩個對比實驗的超參數與本文模型參數相同。每次訓練測試集取1%,訓練集分別取總訓練集的1%、2%、3%、4%、5%、6%、7%、8%、9%、10%,不同百分比下訓練集數據量見表1。

表1 訓練集數據量比例
(1)不同數據量對模型分類準確性的影響
訓練集數據量分別是5600、28 000、56 000下模型(Ad-Attention-biLSTM、Attention-biLSTM、Attention-LSTM)的分類準確率變化如圖4~圖6所示。
從圖4~圖6中可以看出,當訓練集數據從1%-10%變化的過程中,本文提出的方法準確率較高,且都在80%-96%之間,波動范圍不大,當epoch大于5時,準確率均在90%以上,模型表現較好;而模型(Attention-biLSTM)的準確率變化范圍在10%-95%之間,變化幅度較大,只有在epoch等于10時,模型的分類性能才較好,僅次于(Ad-Attention-biLSTM);模型(Attention-LSTM)的表現較差,準確率波動范圍較大在5%-90%之間,訓練集數據量為5600時準確率隨epoch變化不明顯且很低在5%以下,只有達到一定數據量56 000時隨著epoch改變分類性能才有所提升;這是因為模型(Attention-LSTM)雖然實現了文本序列化,并融入注意力機制用不同的權重大小區分文本特征,但由于單向的LSTM只有下文語義信息,缺乏上文語義信息,當訓練數據量較少時,文本向量特征表示高維稀疏,模型學習能力差,為了提升模型學習能力,把單向LSTM轉變為雙向LSTM即模型(Attention-biLSTM)時,準確率有了一定程度上得到改善,不僅學習到了不同距離的上下文語義依賴關系,模型的穩定性得到加強,但是以上兩個模型在訓練數據集較小的情況下文本特征冗余對分類性能仍有一定的影響,可能會導致分類錯誤,當在訓練過程中對輸入層詞嵌入部分加入擾動進行對抗訓練后,模型趨于穩定,在3個數據集下的準確率均較高;在不同訓練集數據量下模型預測的分類準確率見表2,本文提出的方法分類準確率在不同訓練集下均在90%以上,優于其它兩種基本方法及模型CNN、CNN-LSTM、Word2vec。
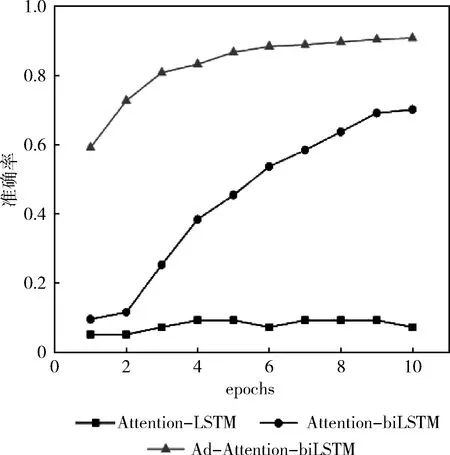
圖4 數據量為5600
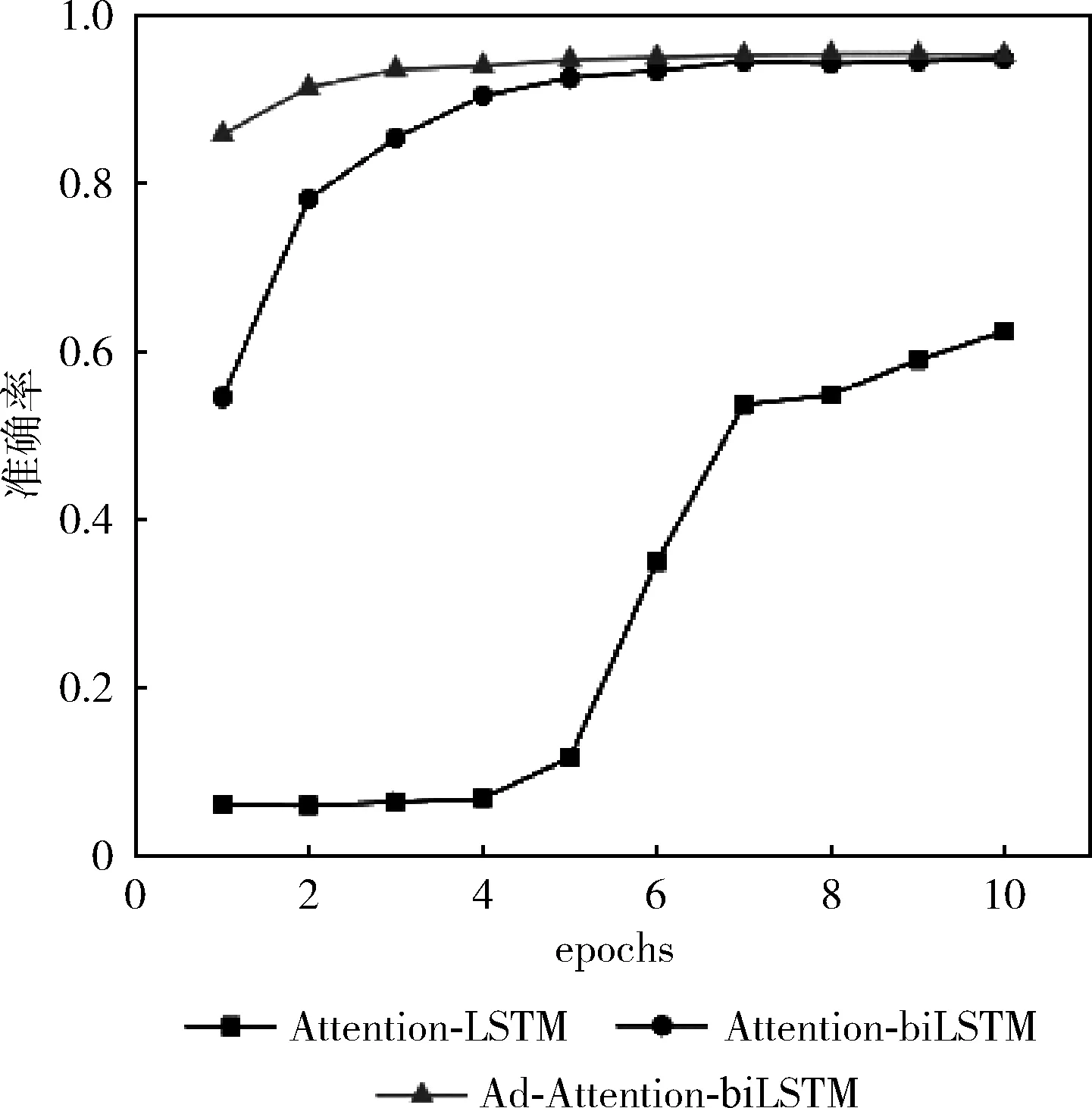
圖5 數據量為28 000
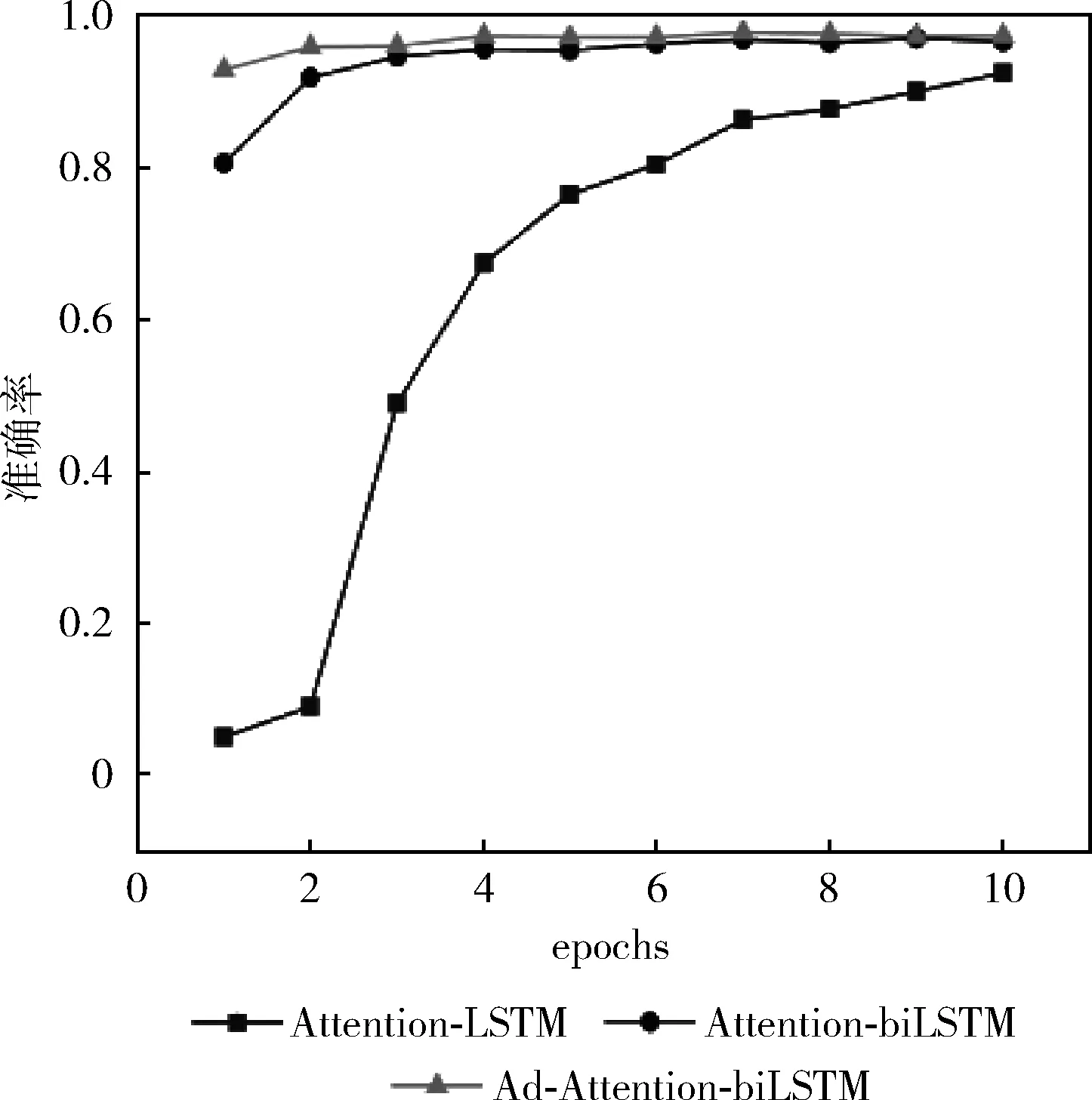
圖6 數據量為56 000
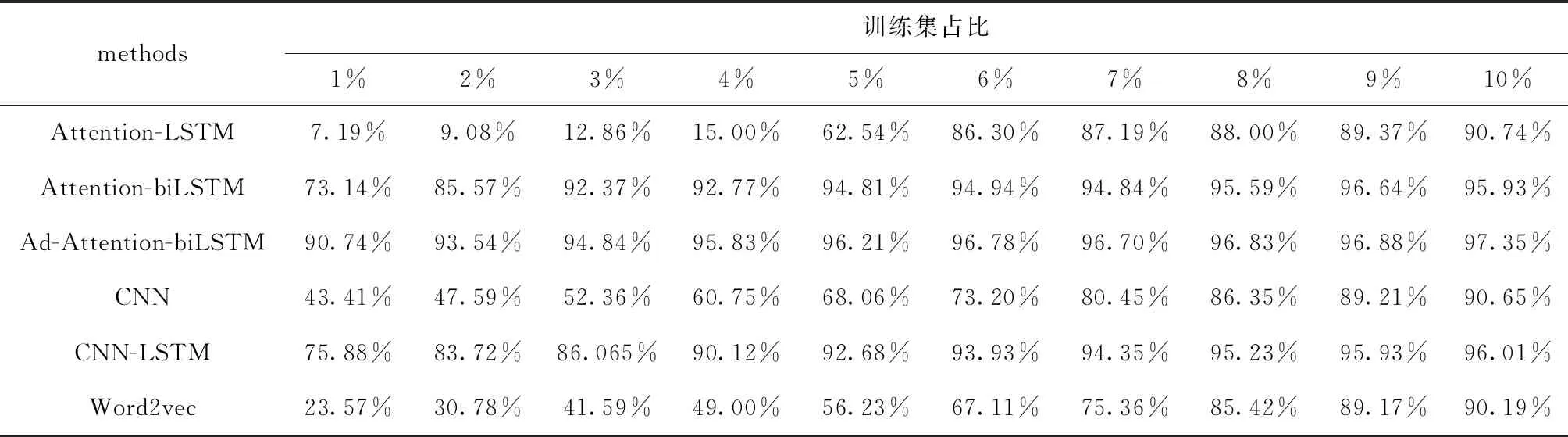
表2 分類預測準確率隨訓練集數據量的變化
(2)不同訓練集數據量對模型收斂性的分析
本文通過計算擾動radv,添加到連續的詞向量上得到新的詞嵌入,模型接收新的詞嵌入,得到擾動后的損失函數值lossadv,通過和原來的loss相加求平均值并優化,訓練集數據量分別是5600、28 000、56 000時和模型(Attention-biLSTM、Attention-LSTM)的損失函數值變化對比如圖7~圖9 所示,當訓練集數據量是5600時,Attention-LSTM的loss值變化較小隨著epoch的變化最終穩定在0.20左右,Attention-biLSTM的loss值雖然一直處于下降趨勢,epoch等于10時為0.15,但仍然很大,而本文提出的模型loss很小一直處于下降趨勢;當訓練集數據量是 28 000 時,Attention-LSTM的loss值沒有太大變化,Attention-biLSTM的loss值變化明顯,epoch等于10時為0.03,但是仍然高于本文提出的方法;當訓練集數據量是56 000時,模型(Attention-biLSTM、Attention-LSTM)的loss下滑趨勢明顯且趨于穩定,最終Attention-LSTM的loss值在0.04左右,Attention-LSTM的loss值在0.02左右,而本文優化后的loss值最終越來越小趨于0;這是由于詞嵌入部分加入對抗訓練即正則化的方式,提高了詞向量的質量,避免過擬合,添加擾動后會導致原來特征類別區分度改變,導致分類錯誤,計算的lossadv很大,但是lossadv的部分是不參與梯度計算的,模型參數W和b的改變對lossadv沒有影響,模型會通過改變詞向量權重來降低loss優化模型,提升魯棒性。
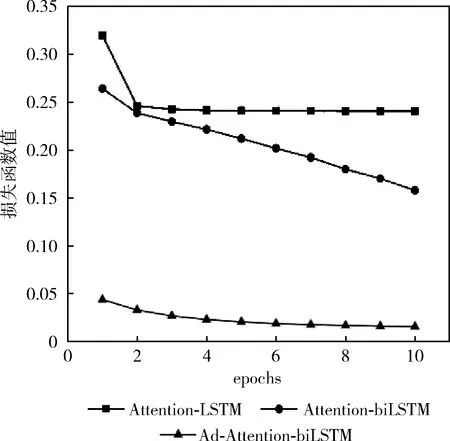
圖7 數據量為5600
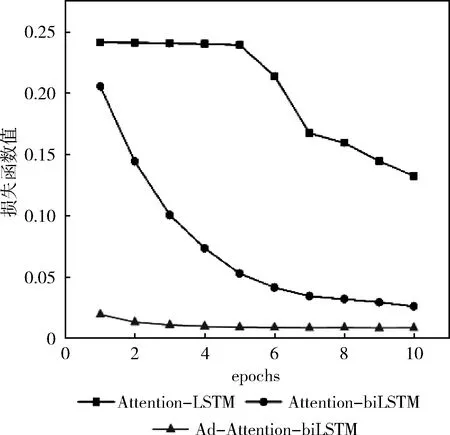
圖8 數據量為28 000
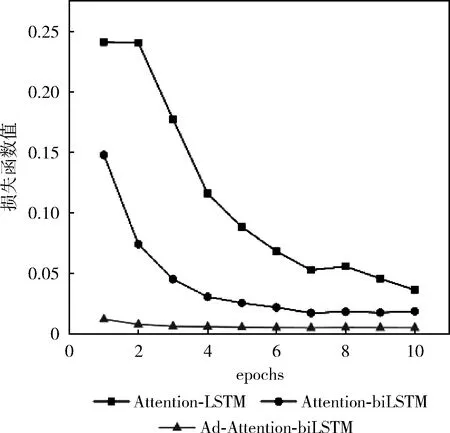
圖9 數據量為56 000
4 結束語
本文提出了一種多層次的文本分類模型(Ad-Attention-biLSTM),在實驗中,我們發現對抗性訓練在文本分類任務的序列模型中不僅具有良好的正則化性能,還提高了詞嵌入的質量,經過擾動后的樣本參與到訓練過程中,提升模型對擾動的防御能力,具有更好的泛化能力,在少量數據集上成功高效地訓練了網絡模型,有學者在訓練過程中將隨機噪聲添加到輸入層和隱藏層,為了防止過擬合,而本文提出的方法優于隨機擾動的方法,但是仍然有不足之處。
本文只是在單一數據集DBpedia上驗證了方法的有效性,后續研究考慮在不同的數據集上做實驗;由于加入了詞嵌入擾動層,準確率和損失值loss得到優化的同時,訓練時間略高于其它方法。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
