基于紋理特征的維吾爾文離線手寫簽名鑒別
2020-04-24 03:07:44張淑婧麥合甫熱提吾爾尼沙買買提朱亞俐庫爾班吾布力
計算機工程與設計 2020年3期
張淑婧,麥合甫熱提,吾爾尼沙·買買提,朱亞俐,庫爾班·吾布力+
(1.新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046; 2.新疆大學 教務處,新疆 烏魯木齊 830046)
0 引 言
手寫簽名鑒別通過不同的獲取方式分為兩種:在線手寫簽名鑒別和離線手寫簽名鑒別。離線手寫簽名中只存在簽名的靜態特征,鑒別難度較大。通過不斷的研究,常見語種的離線簽名鑒別已趨近完善,取得良好的實驗結果,而針對維吾爾文簽名的研究仍處于發展階段。
Muhammad Sharif等[1]使用遺傳算法對簽名的特征進行選擇,使用SVM分類器進行分類鑒別,在CEDAR和GPDS拉丁文數據庫上得到最終AER分別為4.17%和5.42%。Elias N.Zois等[2]對網格特征編碼并進行模板匹配,該方法在GPDS數據庫上可得到EER為9.42%。Guerbai等[3]使用單類SVM進行不依賴于書寫者的簽名鑒別實驗,在CEDAR數據庫中結果AER為5.60%。Hafemann等[4]提出使用卷積神經網絡進行簽名鑒別的方法,運用支持向量機進行分類鑒別,在CEDAR數據庫中得到約為4.63%的等錯誤率。在維吾爾文簽名識別和鑒別的研究中,庫爾班·吾布力等[5-8]于2014-2018年通過對簽名圖像提取改進的方向特征、灰度共生矩等特征,采用不同的分類算法進行簽名識別和鑒別。吐爾遜姑麗·阿布都瓦依提[5]開始對維吾爾文離線手寫簽名鑒別進行研究。在文獻[6]中采用密度特征和KNN分類器,得到識別準確率達96%。
本文中采用多尺度塊局部二值模式以及改進的分塊局部相位量化算法對簽名進行特征提取,并使用隨機森林算法對維吾爾文簽名進行分類鑒別,對得到的實驗結果進行分析。
1 離線手寫簽名鑒別
離線手寫簽名鑒別問題的研究,是生物識別研究中的一個研究領域,也是模式識別領域的一個研究方向。作為模式識別中的一個研究方向,與大多數模式識別問題一樣,離線手寫前面分為4個步驟,分別為數據采集、預處理、特征提取、訓練及測試。其流程如圖1所示。
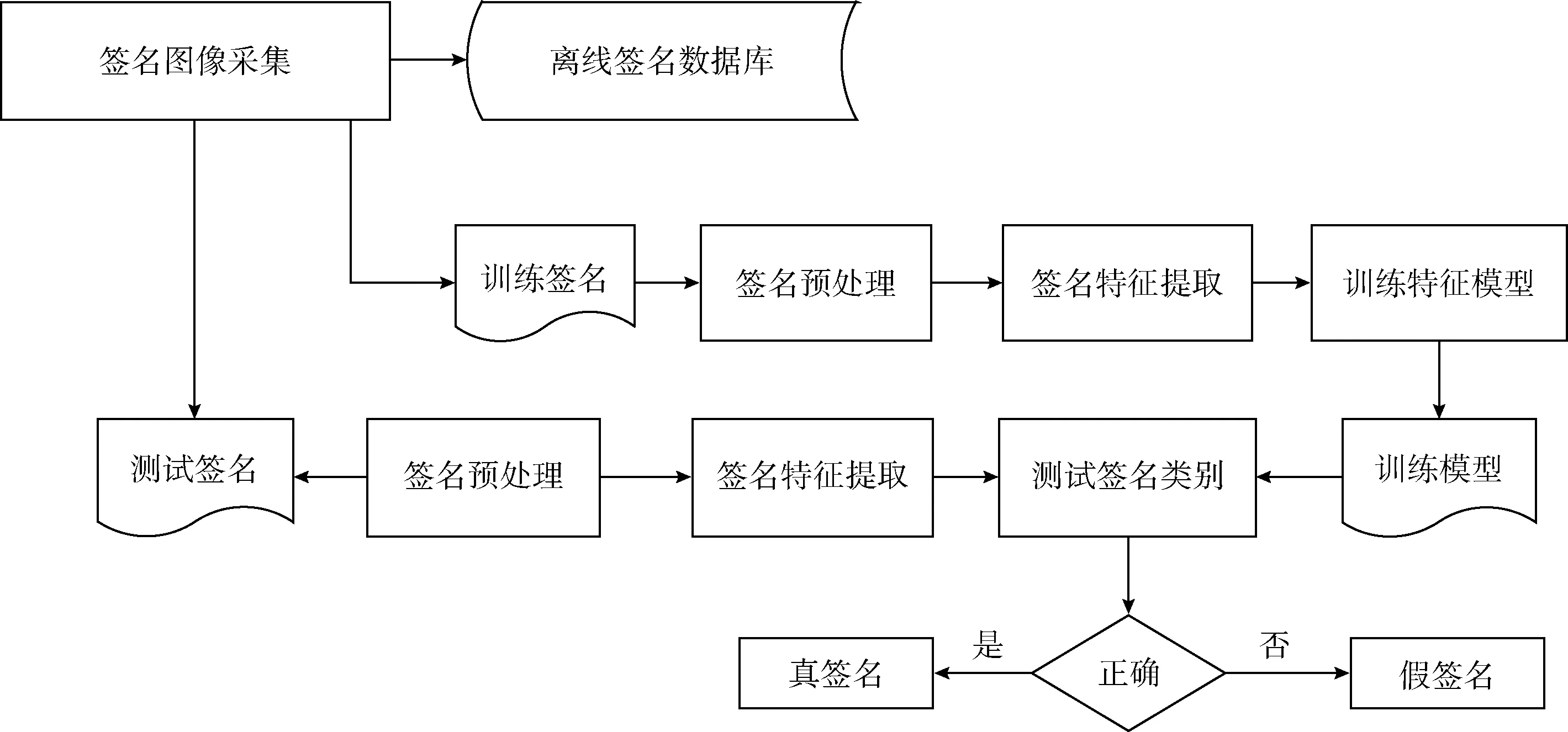
圖1 離線手寫簽名鑒別流程
數據采集:本文使用維吾爾文離線簽名數據庫,此數據庫中采集了870個維吾爾族人的簽名。每人書寫21個真簽名,簡單偽造簽名21個,熟練偽造簽名21個,共17 400個簽名樣本。從中選擇18人的真假簽名作為本實驗的簽名樣本進行實驗。同時,使用拉丁文簽名數據庫CEDAR進行簽名鑒別實驗。
預處理:為了更好保留簽名圖像的差異化信息,在對圖像進行特征提取之前需要對其進行處理。本文中首先對圖像進行大小歸一化,將簽名圖像大小歸一為384×96像素。此后,使用加權平均法進行灰度化處理,用OTSU算法對簽名圖像進行二值化處理,并使用雙邊濾波對圖像進行去噪。這樣能夠更好保存圖像的內部信息以及邊緣信息。預處理圖像如圖2所示。

圖2 預處理簽名圖像
特征提取:特征提取是簽名鑒別過程中重要的一環,只有從簽名中提取到能夠表示簽名者身份的特征才能繼續進行鑒別。本文采用由Shengcai Lia等提出的多尺度塊局部二值算子與局部相位量化特征進行串聯融合,形成本文用于實驗的特征向量。
訓練及測試:首先將訓練簽名樣本從特征提出中所提取出的特征向量進行訓練,形成訓練模型,再通過訓練模型進行分類測試,得出測試簽名是否為真簽名。本文中采用隨機森林算法對簽名進行分類鑒別。
2 特征提取
2.1 局部二值模式
局部二值模式(local binary pattern,LBP)[9],是一種主要對圖像紋理特征進行描述的特征算子,其具有灰度不變性及旋轉不變性等特性。通過多年來對該算子的不斷發展與改進,現已被廣泛應用于圖像分類,圖像檢索等領域。
2.1.1 基本LBP算子
LBP算法以鄰域為窗口,提取圖像的局部紋理。選取鄰域大小為3×3的窗口,將窗口內中心點gc的灰度值作為中心閾值,將其周圍8個點g0,…,g7的像素與其比較,若鄰域灰度值大于gc灰度值,則該點記為1,反之記為0。以該鄰域內以左上角點為起點,按順時針方向可得到一個八位二進制數,求取該二進制數的十進制表示方法,即為該點LBP值,求取方法如圖3所示。
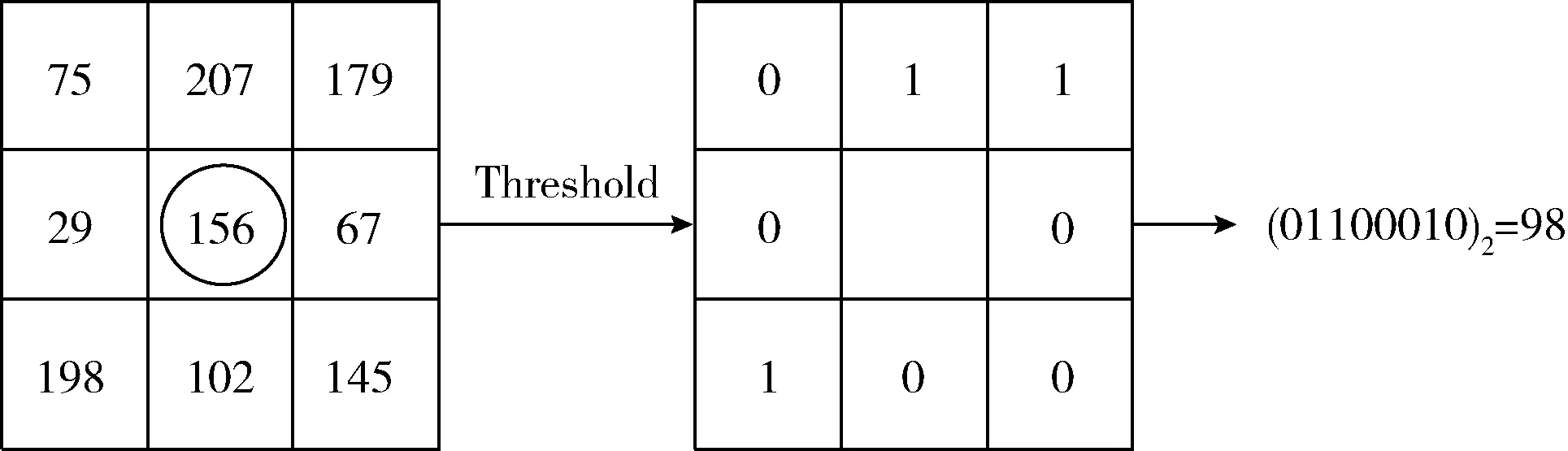
圖3 基本LBP算子生成過程
2.1.2 多尺度塊局部二值模式
多尺度塊局部二值模式(multiscale block local binary pattern,MB-LBP)是由Shengcai Lia等提出的一種LBP的改進算法[10]。該算法將進行灰度值的比較時,沒有采取原始LBP算法中的將像素灰度值進行比較,而是將對圖像子區域內像素的平均灰度值作為子區域灰度值進行比較。如圖4所示。
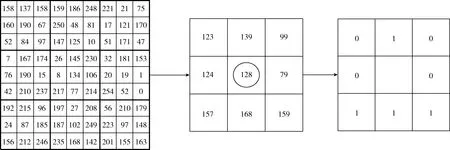
圖4 MB-LBP算子生成過程
圖4為一個9×9的MB-LBP算子生成過程。9×9的圖像塊劃分為9個大小為3×3的小塊,求取每個3×3小塊的灰度平均值,得到3×3的灰度矩陣,其余提取MB-LBP算子與原始LBP算子過程一樣。當采用3×3的MB-LBP算子時,則相當于一個基本3×3LBP算子。求取小區域平均灰度值時,可以采取求和區域表或積分圖像的方法。本文采取積分圖像的方法,以方便快捷的計算灰度平均值標量。因此,MB-LBP算子的提取速度同樣較快,僅稍慢于基本3×3算子提取速度。不同分塊規模時MB-LBP濾波圖像如圖5所示。

圖5 MB-LBP濾波后簽名圖像
由圖5可以看出,不同規模MB-LBP濾波的圖像有較大區別。隨意在進行實驗時,應選擇合適的規模。本文中選取9×9的MB-LBP算子進行實驗。提取MB-LBP算子的進行訓練鑒別時,還需要提取其直方圖,形成MB-LBP直方圖特征。
2.2 局部相位量化
局部相位量化(local phase quantization,LPQ)是由Ojansivu等[11]提出的一種局部描述符,在圖像的頻域空間處理空間模糊紋理特征,其具有良好的模糊不變性和灰度不變性。LPQ算法的提出者指出,該算法僅使用圖像的相位信息作為圖像特征,具有較強的魯棒性,該算法目前別廣泛應用于人臉識別領域中。在數字圖像處理領域中,空間模糊圖像I(x) 是通過對圖像強度f(x) 和點擴展函數h(x) 進行卷積得到的,公式如下
I(x)=f(x)×h(x)
(1)
在圖像頻域內,上式可用式(2)
J(u)=F(u)×H(u)
(2)
該式為式(2)在頻域內的乘積形式。其中,J(u)、F(u) 和H(u) 分別為I(x)、f(x) 和h(x) 的離散傅里葉變換。由于局部相位量化算法僅討論圖像相位,則考慮到J(u)、F(u) 和H(u) 的相位信息,則可有公式
∠J(u)=∠F(u)×∠H(u)
(3)
當點擴展函數h(x) 中心對稱時,其傅里葉變換H(u) 一直為實數。當H(u) 不小于0時,相位信息∠H(u) 為0;當H(u) 小于0時, ∠H(u) 值為π。
在LPQ算法中,通過計算短時離散傅里葉變換,計算圖像中M×M大小的領域Nx內每個像素位置的圖像f(x), 公式如下所示
F(u,x)=∑f(x-y)e-2πjuT
(4)
式中:u為頻率。圖像的行列的卷積計算可以分開進行,在本算法中,以對圖像先行后列的方式做一維卷積計算。計算局部傅里葉系數時,采用的4個頻率點如下所示
u1=[a,0]T,u2=[0,a]T,u3=[a,a]T,u4=[a,-a]T,
(5)
其中,a是足夠小的數,且使H(u)>0。 則有
Fx=[F(u1,x),F(u2,x),F(u3,x),F(u4,x)]
(6)
為使LPQ算子方便表示和計算,需將它們進行進一步的量化。通過對Fx中每一分量的實部和虛部的符號對傅里葉系數的相位信息進行標記,公式如下
(7)
向量K(x)=[Re{F(x)},Im{F(x)}] 的第j個部分由kj表示。此時qj通過二進制編碼的方法,被量化為LPQ特征值,計算方法如下所示
(8)
LPQ算法提取特征過程如圖6所示。
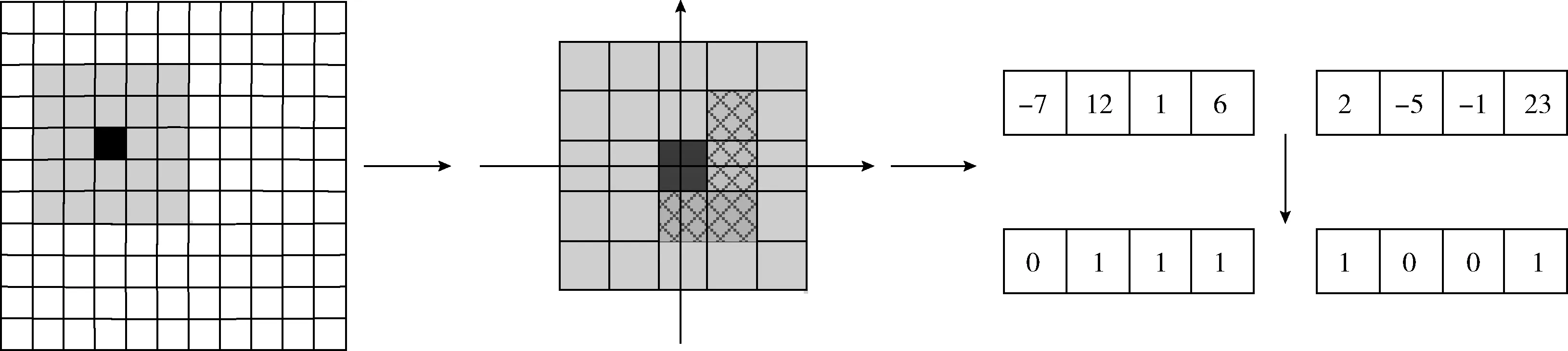
圖6 LPQ提取特征過程
3 隨機森林
隨機森林(random forest,RF)算法由2001年被提出,該算法是一種基于決策樹的機器學習算法[12]。其利用對多個樹進行訓練并預測的分類算法,通過生成多個決策樹和投票的方法對多特征數據進行分類,具有較高的計算效率和準確率。現階段,隨機森林別廣泛應用于生態、經濟、圖像識別中。
該算法的基本單元為決策樹,采用Bagging集成思想,隨機選取不同的訓練特征子集構建不同的決策樹,根據所有構建出的決策樹的分類結果通過投票的方法確定最終分類。隨機森林具有樣本集的隨機性和特征的隨機性這兩個主要特性。所以,隨機森林算法具有良好的泛化能力,快速處理上千維的特征數據,且不會產生過擬合現象。
隨機森林算法作為一種基于決策樹的分類算法,主要包括以下幾個步驟:
步驟1 從原始樣本集D中采用Bootstrap 重抽樣的方法有放回地形成k個樣本子集Dk;
步驟2 設原始樣本中包含a個屬性,從每一個樣本中選擇屬性a中的m個特征值,建立決策樹;
步驟3 重復上述過程,建立n個決策樹,并在每個節點位置將小于維度格式的維度向量作為該節點的分類標準;
步驟4 對獲得的分類結果進行誤差測試,采用多數投票確定最優分類結果。
圖7為隨機森林算法的生成過程。

圖7 隨機森林分類流程
4 實 驗
4.1 數據庫與實驗環境
本文中數據庫采用由本地收集的維吾爾文簽名數據庫和國際公開的拉丁文手寫簽名數據庫CEDAR。維吾爾文簽名數據庫中,包含30人維吾爾文手寫簽名圖像,其中每人包括20個真簽名,20個簡單偽造簽名,20個熟練偽造簽名,合計1800個簽名圖像。CEDAR數據庫中,包含55人拉丁文簽名,每人包括24個真實簽名圖像和24個偽造簽名圖像,共2640個簽名圖像。在進行離線手寫簽名鑒別時,從兩個數據庫中每人的真簽名和偽造簽名中分別選取12個簽名圖像進行訓練,總共每人選取24個簽名用于訓練,其余簽名圖像用于測試。則對于維吾爾文手寫簽名鑒別實驗而言,總共720個圖像用于訓練,1080個圖像用于測試;對于CEDAR拉丁文數據庫而言,共1320個圖像用于訓練,1320個圖像用于測試。本文中,對兩種不同數據庫隨機選取簽名圖像進行10組實驗,求取實驗結果平均值作為該組實驗的結果。
本文中所有實驗均在64位Windows7的環境下進行,其CPU為i5 4460,3.20 Hz,內存為4 GB,具體程序通過使用Visual Studio 2012與Matlab2016b混合編程調試。
4.2 參數設置與評價標準
本文在使用隨機森林算法中,單棵樹最大深度為10,節點分裂最小樣本數為2,決策樹最大棵數為3000棵樹,其中樹中每個節點隨機選取特征15個,從而尋求最佳分裂。
在進行離線維吾爾文手寫簽名鑒別時,使用錯誤拒絕率(false rejection rate,FRR)與錯誤接受率(false accep-tance rate,FAR)對簽名鑒別的結果進行評價。FRR代表在鑒別過程中將真簽名誤認為偽造簽名的錯誤率,而FAR代表將偽造簽名誤認為真簽名時的錯誤率。為了更好的對簽名鑒別結果的綜合能力進行評價,引入總正確率(ove-rall right rate,ORR)進行評價。FRR、FAR、ORR這3種評價標準計算公式如下所示
(9)
(10)
(11)
4.3 基于MB-LBP的簽名鑒別實驗
本文在提取MB-LBP直方圖特征時,采用分塊的方式,這樣的處理可以更好提取不同部位簽名特點,并進行比較。防止因為不同簽名提取的MB-LBP濾波圖像相似而帶來的誤差。本文主要通過從圖像寬度進行等分的方式對MB-LBP圖像進行分塊,將每一個小圖像塊的MB-LBP直方圖進行串聯融合,形成256×k維的特征向量。該分塊特征記為MB-LBPk,其中,k即為等分后圖像區域塊數。本文實驗中,k取1,2,3,4,6,8等6個值(均可對圖像寬度384進行整除)。實驗結果見表1。

表1 基于MB-LBPk的維吾爾文簽名鑒別實驗結果
表1中數據為使用MB-LBP算法提取特征,在維吾爾文簽名圖像數據庫進行實驗的結果。在不分塊的情況下,通過分類鑒別得到FRR為4.87%,FAR為7.71%的結果。當切分塊數為4時,可以得到本組實驗中的最好結果,其FRR為3.54%,FAR為5.54%,ORR為95.46%,分別比未分塊時的鑒別結果提高了1.33%、2.71%和1.75%。使用MB-LBP算法提取的特征在CEDAR數據庫中的實驗結果見表2。
表2中對CEDAR數據庫進行實驗的結果與表1中相似的是,當圖像不進行分塊特征提取時,其鑒別結果低于分塊后的鑒別結果。當k=1時,ORR為95.67%。對圖像提取分塊MB-LBPk時,在k=2的情況下,FRR、FAR、ORR分別為3.88%、3.65%、96.23%。
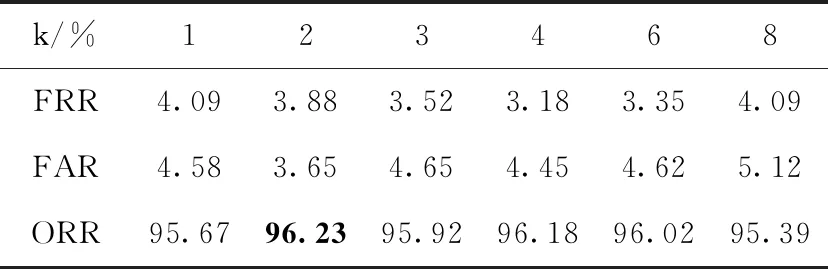
表2 基于MB-LBPk的CEDAR數據庫簽名鑒別實驗結果
表1與表2中結果對比,CEDAR數據庫中總正確率低于維吾爾文簽名鑒別總正確率,且得到最佳結果的分塊特征MB-LBPk的k值也不相同。造成這種情況發生的主要原因是,不同語言的文字書寫結構不同,因此造成鑒別結果的差異。從表1和表2中,可以看出采用對圖像分塊后提取特征的方法可以有效提高簽名的鑒別率。
4.4 基于LPQ的簽名鑒別實驗
與基于MB-LBP的簽名鑒別類似,基于局部相位量化的簽名鑒別實驗中也加入了分塊的思想,該分塊后的LPQ算法記為LPQk。分塊的塊數k=1,2,3,4,6,8, 與MB-LBPk相同。該算法實驗結果見表3。

表3 基于LPQk的維吾爾文簽名鑒別實驗結果
表3中為通過LPQk算法提取維吾爾文簽名特征后的鑒別實驗結果。由表中結果可得知,分塊塊數k=4時,有最佳結果。此時,FRR為3.38%,FAR為5.29%,ORR為95.67%。未分塊k=1時,實驗結果FRR為5.08%,FAR為6.35%,ORR為94.29%。可以得知,當k=4時的實驗結果FRR、FAR和ORR分別比未分塊時提高1.70%、1.06%、1.38%。表4為使用LPQk特征對CEDAR數據庫進行實驗的鑒別結果。

表4 基于LPQk的CEDAR數據庫簽名鑒別實驗結果
使用LPQk算法提取CEDAR數據庫中簽名特征鑒別后的結果見表4。在k=1的情況下,得到的總正確率ORR為96.04%。當k=4時,該方法在CEDAR拉丁文數據庫上實驗可以得到最佳結果,FRR為3.05%,FAR為3.85%,總正確率為96.55%。而在k=8,鑒別結果最差為95.98%,比實驗所得到的最高總正確率低0.57%。
表3與表4中的數據相比,最差實驗結果均不出現在未切分前的鑒別實驗中。造成該結果的原因可能是由于維吾爾文、拉丁文的姓名間相似度較高,若不能將簽名圖像的特異部分進行分塊,造成特征向量相似,則簽名鑒別結果較差。所以,在使用LPQk算法進行簽名鑒別實驗時,分塊數k會極大影響簽名鑒別的總正確率。
4.5 基于MB-LBP與LPQ融合的簽名鑒別實驗
在對提取MB-LBP和LPQ兩種特征的簽名分別進行實驗后,由表1~表4中數據可以看出,兩種方法在維吾爾文簽名數據庫和CEDAR簽名數據庫中均獲得良好實驗結果。由此可以看出,兩種特征提取算法皆可以提取出有效的紋理特征。在兩種特征分別提取特征進行實驗的基礎上,對MB-LBPk和LPQk進行并聯融合,形成256×k×2維的高維特征向量(融合時,兩種算法k值取相同值)。采用隨機森林算法對高維特征向量進行訓練分類。實驗結果見表5、表6。

表5 基于MB-LBPk和LPQk的維吾爾文 簽名鑒別實驗結果
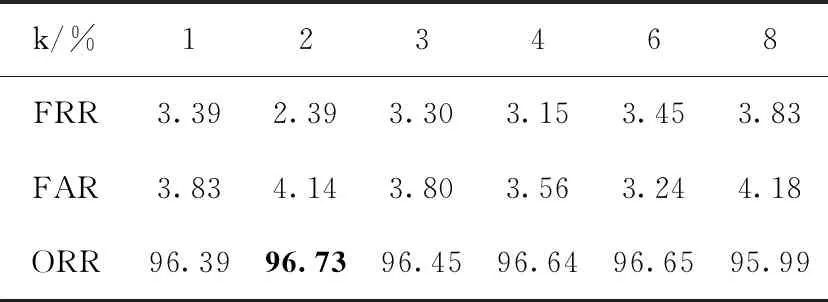
表6 基于MB-LBPk和LPQk的CEDAR數據庫 簽名鑒別實驗結果
表5中數據即為MB-LBPk和LPQk融合特征提取算法在維吾爾文簽名數據庫中進行實驗的結果。當k=4時,簽名鑒別結果最好,總正確率為96.36%。比單獨使用MB-LBPk和LPQk算法提取特征時的總正確率提升0.89%和0.68%。對未分塊時融合后特征向量進行鑒別時總正確率為94.75%,比k=4時ORR低1.60%。
表6為融合特征在CEDAR數據庫中的拉丁文手寫簽名上進行實驗的結果。與維吾爾文簽名鑒別實驗結果不同的是該組實驗的最優結果是在k=2時。此時,CEDAR數據庫離線手寫簽名鑒別的FRR為2.39%,FAR為4.14%,ORR為96.73%。比融合前MB-LBPk和LPQk特征的簽名鑒別總正確率分別提高0.50%和0.18%。較好提升了CEDAR中拉丁文簽名鑒別結果。當k=1未分塊時的ORR為96.39%,比融合后的最佳結果低0.34%。
由表1~表6中數據可知,MB-LBP和LPQ的特征提取方法,能夠有效提取簽名圖像的特征信息,并通過隨機森林分類器可以得到良好的簽名鑒別結果。分塊后的MB-LBP和LPQ對圖像信息更加敏感,可以使維吾爾文簽名和拉丁文簽名的鑒別結果得到一定的提升。最后通過特征融合的方法,把MB-LBPk和LPQk串聯融合形成高維特征向量,在兩個不同文種簽名圖像庫中進行鑒別實驗,得到的總正確率分別為96.35%和96.73%。
4.6 實驗對比
為了更好探究本文所提出的離線手寫簽名鑒別方法,將本文中所得到的實驗結果與已有的實驗結果進行對比。維吾爾文簽名數據庫結果對比和CEDAR數據庫結果對比見表7、表8。
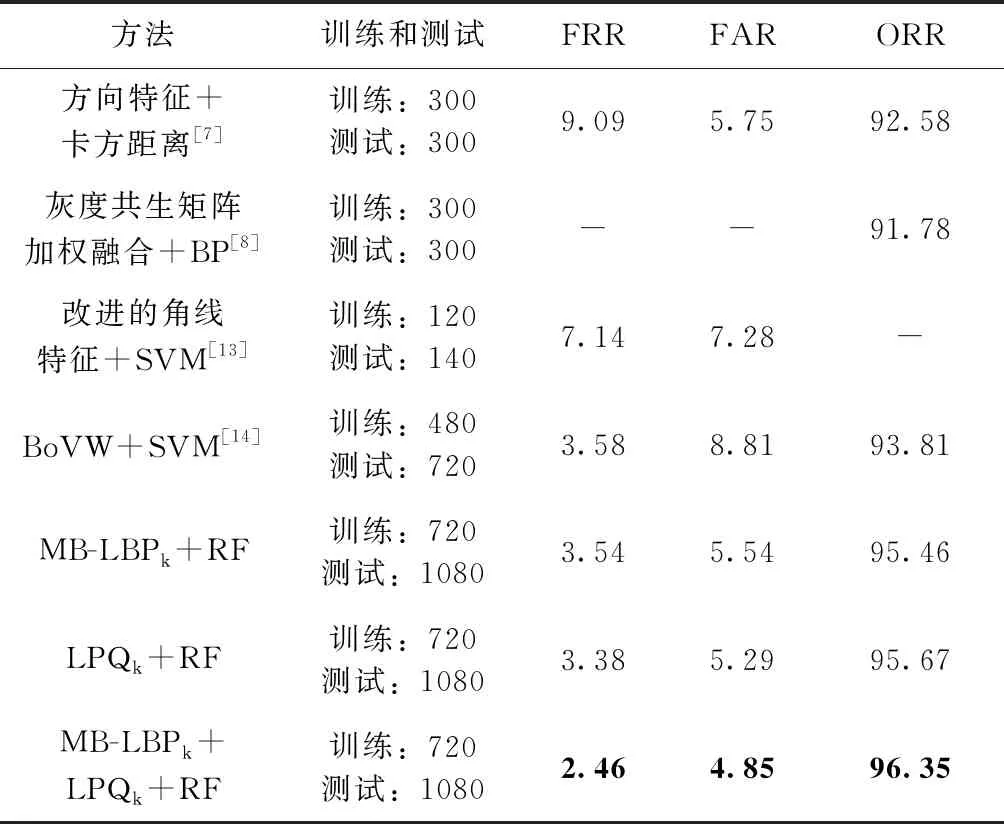
表7 維吾爾文手寫簽名鑒別結果對比/%
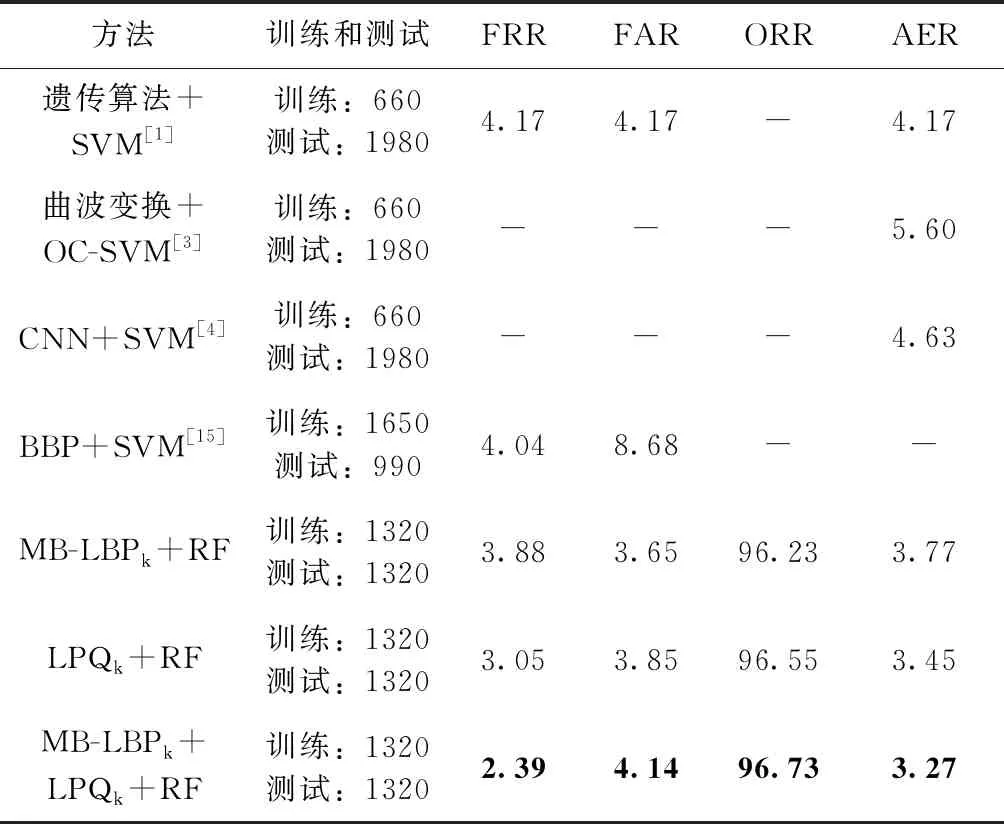
表8 CEDAR數據庫手寫簽名鑒別結果對比/%
通過與已有的實驗結果進行對比,由表7可以看出,本文方法在對維吾爾文離線手寫簽名進行鑒別時,在擴大了實驗數據量的情況下,結果仍高于已有實驗結果。本文方法比2018年提出的視覺詞袋模型特征(BoVW)和SVM分類器進行鑒別的結果FRR、FAR、ORR分別提高了1.12%、3.96%、2.54%[14]。可以看出,該方法比文獻[14]中方法的FAR有大幅度提升,所以其總正確率也同樣提升。從表8中的數據看出,本文方法在CEDAR拉丁文數據庫中也有良好的實驗結果,其結果高于文獻結果1%以上。說明本文提出方法在對于維吾爾文離線手寫簽名鑒別和拉丁文CEDAR數據簽名鑒別中是有效的。
5 結束語
本文中提出了基于MB-LBP和LPQ融合的維吾爾文離線手寫簽名鑒別,并且該方法中使用隨機森林進行分類鑒別。該方法在包含30人簽名(20真簽名/每人,20簡單偽造簽名/每人,20熟練偽造簽名/每人)的維吾爾文手寫簽名數據庫和包含55人(24真簽名/每人,24偽造簽名/每人)CEDAR拉丁文簽名數據庫中進行實驗,得到的總正確率分別為96.35%和96.73%,均高于已有實驗結果。因此,MB-LBP和LPQ可以有效提取簽名圖像特征,且隨機森林算法能夠高效的處理高維特征向量進行分類鑒別。在今后的研究工作中,將本文中兩種算法繼續進行網格化分塊實驗,并使用多種分類器進行鑒別實驗對比。嘗試使用深度學習算法對簽名圖像進行訓練測試,提高簽名的總正確率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
