基于形狀特征和SVM多分類的銅仁地區茶葉病害識別研究
2020-04-23 09:39:32黃太遠李旺邱亞西余小波
種子科技 2020年6期
黃太遠 李旺 邱亞西 余小波

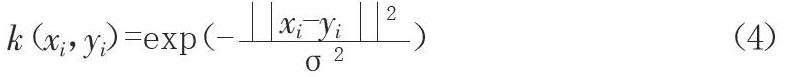

摘? ?要:針對茶葉常見葉部病斑圖像的形狀特點,將機器學習應用于茶葉病害識別當中。以茶葉3種常見病害作為研究對象,運用支持向量機方法進行分類識別研究,對有病害的茶葉圖像進行處理和特征提取,利用徑向基核函數進行分類來提高茶葉病害識別率。運用分類識別方法對茶葉病害進行研究,使茶葉在發病初期就能得到更好的預防以及后期能保證茶葉的質量和產量,提高當地茶葉的銷量,促進經濟發展。
關鍵詞:形狀特征;SVM多分類;茶葉病害;識別
文章編號: 1005-2690(2020)06-0007-02? ? ? ?中圖分類號: TP391.41;S435.711? ? ? ?文獻標志碼: B
目前,銅仁市在栽茶和茶葉的病害處理方面還很薄弱,小部分做得較好一些的只有私人茶園,且采摘量只占全年總產量的40%左右[1],大多數茶葉在樹上老化或被蟲子、病菌感染發生了病變,茶葉的利用率低。而茶葉作為銅仁茶農的主要經濟來源,以茶葉病害為研究對象,對茶葉葉部病斑進行圖像預處理,然后提取其病斑部分的形狀特征,對提取的特征數據利用支持向量機分類方法訓練得出分類模型,對茶葉的常見病害進行分類識別,以提高識別率,可促進計算機智能識別在農業中的應用。
1? ?支持向量
支持向量機[2-4](Support Vector Machine,SVM)是一種將數據進行分類后的算法,而SVM通常用于二元分類學習,對于多元的主要是將其分為多個二元來解決數據分類。
數據的分類主要有線性可分、非線性可分兩類。為了能讓兩類正確分離且它們距離最大的分類平面成為最佳超平面,其方程為:
式中,ω表示分離超平面的法向量,b表示截距,位于分離超平面之上的樣本為正樣本,之下的為負樣本。
本文利用徑向基核函數[5-7](Radial Basis Function Kernel)將提取出來的數據進行分類識別,RBF函數具有很強的靈活性,與其他的核函數相比參數較少。因此,大多數情況下,通過計算機計算時會比其他核函數的效率更高、運算速度更快、性能更好。下面就是徑向基RBF核函數形式:
2? ?茶葉病害圖像特征提取
茶葉病害圖像包含了豐富的特征信息,如圖1所示。例如,形狀特征和紋理特征[8-10],按照形狀分類的現有技術,本文利用茶葉病害部位的輪廓、凸凸和最小包圍盒得到形狀描述[11-12],利用這些形狀的相關數據計算出面積、矩形度、周長凹凸比、面積凹凸比、茶葉病害部位的伸長度和茶葉病害部位的圓度6種相對形態參數來提取所需的數據。
本文先提取茶葉病害部位的外部輪廓,通過采用輪廓跟蹤法對茶葉病害圖像進行輪廓提取,具體算法步驟如下。
(1)對圖像預處理后的茶葉病害二值化圖像采用自頂向下、從左到右的順序進行掃描,得到第一個像素點為1的點,此時將其作為起始點。
(2)通過步驟(1)得到起始點后,反方向查找此時該像素點在其8個方向上的領域點,若查找到該像素值為1的點且領域上包含0像素點,若該像素點在之前沒有被查找過,則將這個像素點作為當前點,并記下對應的鏈碼值。
(3)重復步驟(2),直到回到起始點。
(4)根據步驟(2)和(3)所記錄的鏈碼值,得到茶葉病害部位的形狀輪廓。
根據以上步驟提取茶葉病斑的數據見表1和表2。
3? ?試驗過程及結果分析
試驗環境是MATLAB2017b,利用SVM進行分類。在試驗過程中用到libsvm工具包進行測試和分類,先建立分類模型,然后利用得到的這個模型進行分類。本次試驗總共選取了102個特征數據樣本,然后隨機抽取部分特征數據作為訓練數據,再用剩下的特征數據作為測試數據。分析過程如下。試驗結果如圖2所示。
利用訓練數據建立模型:
Model=svmtrain(trains_label,Trains_matrix,cmd)
其中svmtrain是模型訓練函數,trains_label為訓練樣本類別,Trains_matrix為歸一化后的訓練樣本的特征值,cmd為返回的模型值。
利用建立好的模型放在訓練數據上的分類效果:
[predicts_label_1,accuracys_1,acc]=svmpredict(trains_label,Trains_matrix,Model)
result_1=[trains_label,predicts_label_1]
其中svmpredict是對測試集進行預測,accuracy_1是分類的預測準確度,通過有監督的測試集值和預測值求百分比。
圖2a是在102個特征數據中選取40個進行分類訓練及創建模型,再將62個特征數據作為測試樣本進行茶葉病害分類識別,得出的結果為87.10%。圖2b是在原本的基礎上選取50個進行分類訓練及創建模型,再將52個特征數據作為測試樣本進行茶葉病害分類識別,得出的結果為90.38%。圖2c是在圖2b的基礎上增加了10個特征數據(即選取60個進行分類訓練及創建模型),再將42個特征數據作為測試樣本進行茶葉病害分類識別,得出的結果為90.48%。圖2d同圖2c一樣,選取70個特征數據進行分類訓練及創建模型,再將32個特征數據作為測試樣本進行茶葉病害分類識別,最后得出的結果為93.75%。
綜上所述,樣本數量一定的時候所選取的訓練樣本越多,識別率就越高。當訓練數據和測試的比例達到一定值時,識別率將會在某一范圍波動,就像本試驗的數據結果,當訓練樣本達到一定的時候,識別精度就會在90.43%上波動。所以通過SVM分類器識別,具有識別率高、范圍廣等特點,可以有效地解決人工在監控茶葉的過程中保證了茶葉的質量和控制疾病的感染。
4? ?結語
由于茶農對茶葉病害識別存在:主要依靠經驗(主觀、局限、模糊),憑感覺對茶葉病害進行診斷,往往在茶葉的感染程度較嚴重時肉眼才能識別,很難做到“對癥下藥”和及時防治,而且可能造成農藥超標,影響茶葉的質量。現提供一種基于人工智能(圖像處理和SVM分類)對茶葉常見病害進行識別方法研究,以提高識別率。選取適合于茶葉病害的分類識別方法,促進計算機智能識別技術在農業中的應用。
參考文獻:
[ 1 ] 徐代剛.銅仁市茶產業發展分析[J].中國茶葉,2018,40(1):29-33.
[ 2 ] 劉衍琦,詹福宇,蔣獻文,等.MATLAB計算機視覺與深度學習實戰[M].北京:電子工業出版社,2017.
[ 3 ] 卓金武.MATLAB在數學建模中的應用[M].北京:北京航空航天大學出版社,2014.
[ 4 ] Duan Li,Ruizheng Shi,Ni Yao,et al.Real-Time Patient-Specific ECG Arrhythmia Detection by Quantum Genetic Algorithm of Least Squares Twin SVM[J/OL].Journal of?Beijing Institute of Technology:1-10[2019-12-22].
[ 5 ] M. Dirbaz,T. Allahviranloo. Fuzzy multiquadric radial basis functions for solving fuzzy partial differential equations[J].Computational and Applied Mathematics,2019,38(4).
[ 6 ] 魏鋒濤,盧鳳儀.融合核函數在改進徑向基代理模型中的應用[J].計算機工程與應用,2019,55(7):58-65.
[ 7 ] 陳瑤.基于徑向基網絡和支持向量機算法的板形缺陷識別的研究[D].天津:河北工業大學,2015.
[ 8 ] Jiao Yin,Jinli Cao,Siuly Siuly,et al.An Integrated MCI?Detection Framework Based on Spectral-temporal Analysis[J].International Journal of Automation and Computing,2019,16(6):786-799.
[ 9 ] 歐利松.基于SVM的人臉識別系統設計與改進[J].網絡安全技術與應用,2019(12):58-60.
[ 10 ] 周凱紅,喬新新,李福敏.基于支持向量機的彩色圖像分割研究[J].現代電子技術,2019,42(18):103-106,111.
[ 11 ] 郭志強,胡永武,劉鵬,等.基于特征融合的室外天氣圖像分類[J/OL].計算機應用:1-10[2019-12-22].
[ 12 ] 王艷玲,張宏立,劉慶飛,等.基于遷移學習的番茄葉片病害圖像分類[J].中國農業大學學報,2019,24(6):124-130.
