面向稀疏數(shù)據(jù)集的聚類(lèi)算法
2020-04-22 14:17:08趙玉明舒紅平魏培陽(yáng)
科學(xué)技術(shù)與工程 2020年2期
趙玉明, 舒紅平, 魏培陽(yáng), 劉 魁
(成都信息工程大學(xué)軟件工程學(xué)院;成都信息工程大學(xué)軟件自動(dòng)生成與智能服務(wù)四川省重點(diǎn)實(shí)驗(yàn)室,成都 610225)
作為知識(shí)庫(kù)發(fā)現(xiàn)的一個(gè)步驟,數(shù)據(jù)挖掘可以幫助人們從大型數(shù)據(jù)庫(kù)中提取模式、關(guān)聯(lián)、變化、異常及有意義的結(jié)構(gòu)[1]。其中,聚類(lèi)是數(shù)據(jù)挖掘的重要研究方向,可以將數(shù)據(jù)對(duì)象分成簇或類(lèi),讓同一個(gè)簇中的對(duì)象具有很高的相似性,而不同簇的對(duì)象相異。聚類(lèi)主要源于很多學(xué)科領(lǐng)域,包括:數(shù)學(xué)、計(jì)算機(jī)科學(xué)、統(tǒng)計(jì)學(xué)、生物學(xué)和經(jīng)濟(jì)學(xué)等[2]。在不同的領(lǐng)域中,都有適用于該領(lǐng)域的聚類(lèi)技術(shù),并被用來(lái)衡量數(shù)據(jù)之間的相似性,從而對(duì)該領(lǐng)域的樣本進(jìn)行有效的劃分。
聚類(lèi)算法可以分為劃分聚類(lèi)、層次聚類(lèi)以及密度聚類(lèi)等。它們的共性就是采用歐式距離來(lái)衡量類(lèi)之間的距離,如最近距離單連接(single-link)、最遠(yuǎn)距離全連接(complete-link)、平均距離聚類(lèi)(group-average)和中心距離聚類(lèi)(centroid-similarity)。同時(shí),聚類(lèi)的基本的框架是搜索和合并,所以每次都要掃描整體數(shù)據(jù),進(jìn)行大量的歐式距離計(jì)算。而在此過(guò)程中會(huì)遇到如下的3個(gè)問(wèn)題:
(1)在數(shù)據(jù)分布相對(duì)離散的時(shí)候,數(shù)據(jù)集中存在大量的空值,如果仍用歐氏距離,反復(fù)掃描整個(gè)數(shù)據(jù)集,則會(huì)進(jìn)行大量無(wú)意義的計(jì)算。導(dǎo)致聚類(lèi)的時(shí)間效率受到很大的影響,如果數(shù)據(jù)量很大,會(huì)導(dǎo)致內(nèi)存不足的問(wèn)題。
(2)在數(shù)據(jù)分布相對(duì)離散的時(shí)候,使用歐式距離,無(wú)法很好的衡量出不同簇之間數(shù)據(jù)的依賴性以及分布密度不均衡的特點(diǎn)。同時(shí)缺乏從數(shù)據(jù)的整體分布進(jìn)行聚類(lèi),導(dǎo)致聚類(lèi)的質(zhì)量產(chǎn)生嚴(yán)重的影響。
(3)在數(shù)據(jù)分布相對(duì)離散的時(shí)候,使用歐式距離,計(jì)算不同簇之間的距離。更多考慮共同項(xiàng)之間的距離,忽略非共同項(xiàng)之間可能蘊(yùn)藏的信息。尤其在數(shù)據(jù)分布呈現(xiàn)極度稀疏性的時(shí)候,歐式聚類(lèi)缺乏考慮數(shù)據(jù)上下文之間的關(guān)系,無(wú)法達(dá)到預(yù)計(jì)的聚類(lèi)效果。
在信息論中,KL(Kullback-Leibler)散度用來(lái)衡量用一個(gè)分布來(lái)擬合另一個(gè)分布時(shí)候產(chǎn)生的信息損耗。典型情況下,P表示數(shù)據(jù)的真實(shí)分布,Q表示數(shù)據(jù)的理論分布、模型分布或P的近似分布。當(dāng)兩個(gè)隨機(jī)分布相同時(shí),它們的相對(duì)熵為零,當(dāng)兩個(gè)隨機(jī)分布的差別增大時(shí),它們的相對(duì)熵也會(huì)增大。KL的值越大,說(shuō)明兩個(gè)分布差距越大,KL為零則說(shuō)明分布近似相同[3]。目前,KL散度主要最為圖像、信號(hào)、聲音信號(hào)的處理上,文獻(xiàn)[3,5-6]的作者,已將開(kāi)始將KL散度引入到相似性度量上,并且已經(jīng)取得很好的效果。在文獻(xiàn)[4]中,使用KL散度來(lái)計(jì)算用戶的相似性,進(jìn)而應(yīng)用在協(xié)同過(guò)濾算法中,減少了用戶評(píng)分稀疏性的問(wèn)題,提高了推薦的質(zhì)量和效率。
基于以上分析,在面對(duì)稀疏數(shù)據(jù)集的聚類(lèi)過(guò)程中,提供以下的聚類(lèi)思路:
(1)通過(guò)預(yù)聚類(lèi),根據(jù)整體數(shù)據(jù)集的分布特點(diǎn),將不同簇之間的數(shù)據(jù)進(jìn)行聚類(lèi)[7]。解決沒(méi)有考慮數(shù)據(jù)整體分布的缺點(diǎn)。
(2)構(gòu)建整體數(shù)據(jù)集的概率矩陣,然后計(jì)算KL矩陣,根據(jù)KL矩陣合并數(shù)據(jù)。完成對(duì)數(shù)據(jù)集的第一次聚類(lèi)。在計(jì)算KL矩陣的時(shí)候,借助預(yù)聚類(lèi)中數(shù)據(jù)的分布特性,考慮不同數(shù)據(jù)蘊(yùn)含的信息[8]。解決沒(méi)有考慮非共同項(xiàng)之間距離以及數(shù)據(jù)本身信息的缺點(diǎn)。
(3)在完成第一次聚類(lèi)后,再次重復(fù)以上的步驟,直到最后的距離矩陣[9]無(wú)法指導(dǎo)聚類(lèi)為止。而在此過(guò)程中,數(shù)據(jù)只需要在預(yù)聚類(lèi)過(guò)程中讀入內(nèi)存,完成對(duì)數(shù)據(jù)的預(yù)聚類(lèi)。后期的工作是處理概率矩陣和距離矩陣。解決了反復(fù)掃描數(shù)據(jù),進(jìn)行大量計(jì)算的問(wèn)題。
1 KL散度的引入及數(shù)據(jù)特征分析
在介紹相對(duì)熵之前,首先了解什么是信息熵[10]。
一個(gè)隨機(jī)變量X的可能取值為X={x1,x2,…,xn},對(duì)應(yīng)的概率為P(X=xi)(i=1,2,3,…,n),則隨機(jī)變量X的熵定義為:
(1)
信息熵主要是反應(yīng)信息的不確定性,在機(jī)器學(xué)習(xí)中,它的一個(gè)很重要的作用是可以為做決策提供一定的判斷依據(jù)。
在概率學(xué)和統(tǒng)計(jì)學(xué)上,經(jīng)常會(huì)使用一種更簡(jiǎn)單的、近似的分布來(lái)替代觀察數(shù)據(jù)或太復(fù)雜的分布。KL散度能度量使用一個(gè)分布來(lái)近似代替另一個(gè)分布時(shí)所損失的信息。
相對(duì)熵又稱互熵、交叉熵、鑒別信息、Kullback熵[11]、Kullback-Leible散度(即KL散度)等。設(shè)P(x)和Q(x)是X取值的兩個(gè)概率概率分布,則P對(duì)Q的相對(duì)熵為:
(2)
相對(duì)熵突出的特點(diǎn)是非對(duì)稱性[12],也就是D(P||Q)和D(Q||P)是不相等的,但是表示的都是P和Q之間的距離,在本文算法設(shè)計(jì)中采取兩者的平均值(DSKL)作為兩個(gè)簇或者類(lèi)之間的距離,即
(3)
在聚類(lèi)過(guò)程中,假設(shè)要聚類(lèi)的數(shù)據(jù)為:X={X1,X2,…,Xn-1,Xn}。X是n個(gè)Rx(x=1,2…,m-1,m)空間的數(shù)據(jù)。其基本的分布見(jiàn)表1。

表1 數(shù)據(jù)分布表
在以上的數(shù)據(jù)分布中,每一個(gè)Xi所對(duì)應(yīng)的m都不完全相同,并且數(shù)據(jù)的稀疏性很大。設(shè)N是數(shù)據(jù)集的個(gè)數(shù),M是每個(gè)數(shù)據(jù)的最大空間維度,V表示非零數(shù)據(jù)的個(gè)數(shù),K表示此數(shù)據(jù)集的稀疏度。則
(4)
通常認(rèn)為K<5%的時(shí)候,可以將這類(lèi)數(shù)據(jù)集歸納為稀疏性數(shù)據(jù)。
2 基于KL散度的聚類(lèi)算法(KL-cluster)
2.1 數(shù)據(jù)預(yù)聚類(lèi)
首先,掃描整體數(shù)據(jù),對(duì)稀疏數(shù)據(jù)集上的數(shù)據(jù)進(jìn)行整體的預(yù)聚類(lèi)。預(yù)聚類(lèi)是完成對(duì)整體數(shù)據(jù)所屬類(lèi)別的確定,可以在整體上分析數(shù)據(jù)[13]。在確定好具體的類(lèi)別數(shù)目后,就可以對(duì)每個(gè)簇中的數(shù)據(jù)所屬類(lèi)別進(jìn)行處理。從而為形成概率矩陣提供依據(jù)。所以預(yù)聚類(lèi)的結(jié)果直接影響到以后的聚類(lèi)效果。
在進(jìn)行預(yù)聚類(lèi)的時(shí)候,最為關(guān)鍵的就是聚類(lèi)數(shù)目的確定。在文獻(xiàn)[1]中,提供了一種基于層次思想的計(jì)算方法,即COPS。摒棄了傳統(tǒng)的針對(duì)數(shù)據(jù)集的反復(fù)聚類(lèi),而是先掃描整體數(shù)據(jù)集,獲得聚類(lèi)特征值,然后自底向上地生成不同層次的數(shù)據(jù)集劃分,增量地構(gòu)建一條關(guān)于不同層次劃分的聚類(lèi)質(zhì)量曲線Q(C),曲線極值點(diǎn)所對(duì)應(yīng)的劃分用于估計(jì)最佳的聚類(lèi)數(shù)目。為此,在數(shù)據(jù)的預(yù)聚類(lèi)階段采用了此種方法,對(duì)數(shù)據(jù)的整體分布進(jìn)行分析。通過(guò)預(yù)聚類(lèi)形成的Q(C)曲線,可以直觀的看到每個(gè)數(shù)據(jù)分布的依賴性、噪音影響以及邊界模糊等情況。為確定每個(gè)數(shù)據(jù)集的聚類(lèi)數(shù)目提供良好的依據(jù),同時(shí)為概率矩陣和KL矩陣的構(gòu)建提供精確的標(biāo)準(zhǔn)。完整的設(shè)計(jì)過(guò)程可以參考文獻(xiàn)[1]。
2.2 基于KL散度的聚類(lèi)過(guò)程
在聚類(lèi)過(guò)程中,首先根據(jù)預(yù)聚類(lèi)形成的類(lèi)別數(shù)目,將每個(gè)簇中的數(shù)據(jù)進(jìn)行分類(lèi),然后統(tǒng)計(jì)每個(gè)簇中的數(shù)據(jù)在預(yù)聚類(lèi)形成的類(lèi)別上的頻率,形成整體數(shù)據(jù)集上的概率矩陣[13](probabilistic matrix,PM)。然后根據(jù)概率矩陣計(jì)算任意兩個(gè)簇之間的距離矩陣,KL距離矩陣[14](distance matrix,DM),根據(jù)距離矩陣,將距離矩陣中的最小的兩個(gè)簇合并,再次在新形成的數(shù)據(jù)集上構(gòu)造概率矩陣和距離矩陣。重復(fù)以上的步驟。通過(guò)以上的遞歸調(diào)用,最后構(gòu)造出來(lái)的距離矩陣無(wú)法指導(dǎo)數(shù)據(jù)合并,此時(shí)完成聚類(lèi)。
2.2.1 概率矩陣的形成過(guò)程
通過(guò)預(yù)聚類(lèi)過(guò)程,離散數(shù)據(jù)集上的數(shù)據(jù)分為k(k=1,2…,k-1,k)類(lèi)。然后循環(huán)統(tǒng)計(jì)各簇中的數(shù)據(jù)在k類(lèi)數(shù)據(jù)上分頻率分布,這樣就會(huì)形成一個(gè)n×k的概率矩陣。通過(guò)這樣的方法就可以將稀疏數(shù)據(jù)根概率分布,集中在k類(lèi)上,可以完成對(duì)稀疏性數(shù)據(jù)第一步收斂,減少稀疏性的弊端。形成的概率矩陣如式(5)所示:
(5)
2.2.2 距離矩陣的形成過(guò)程
根據(jù)以上的概率矩陣,分別計(jì)算矩陣中任意一行和其他一行之間的KL距離,形成整體數(shù)據(jù)集上的KL矩陣。在KL散度介紹中也談到了KL具有非對(duì)稱性,這里采用任意兩行相互計(jì)算距離的平均值作為實(shí)際的KL值[14]。剩下的部分都用0來(lái)填充,最后形成如式(6)所示的上三角概率矩陣[15]:
(6)
式(7)中:DM12的計(jì)算方式如式(7)所示:
(7)
通過(guò)形成的KL矩陣,將距離矩陣中小于一定精度的值所代表的兩行數(shù)據(jù)合并[16]。通過(guò)以上過(guò)程完成對(duì)數(shù)據(jù)集的一次合并,形成新的數(shù)據(jù)集。對(duì)合并后形成的數(shù)據(jù)集,按照上面的過(guò)程形成新的概率矩陣和距離矩陣,再次完成數(shù)據(jù)的合并。通過(guò)不斷地重復(fù),直到KL矩陣無(wú)法達(dá)到合并數(shù)據(jù)的精度后,完成所有數(shù)據(jù)集的聚類(lèi)[17]。具體的算法流程如下如圖1所示。
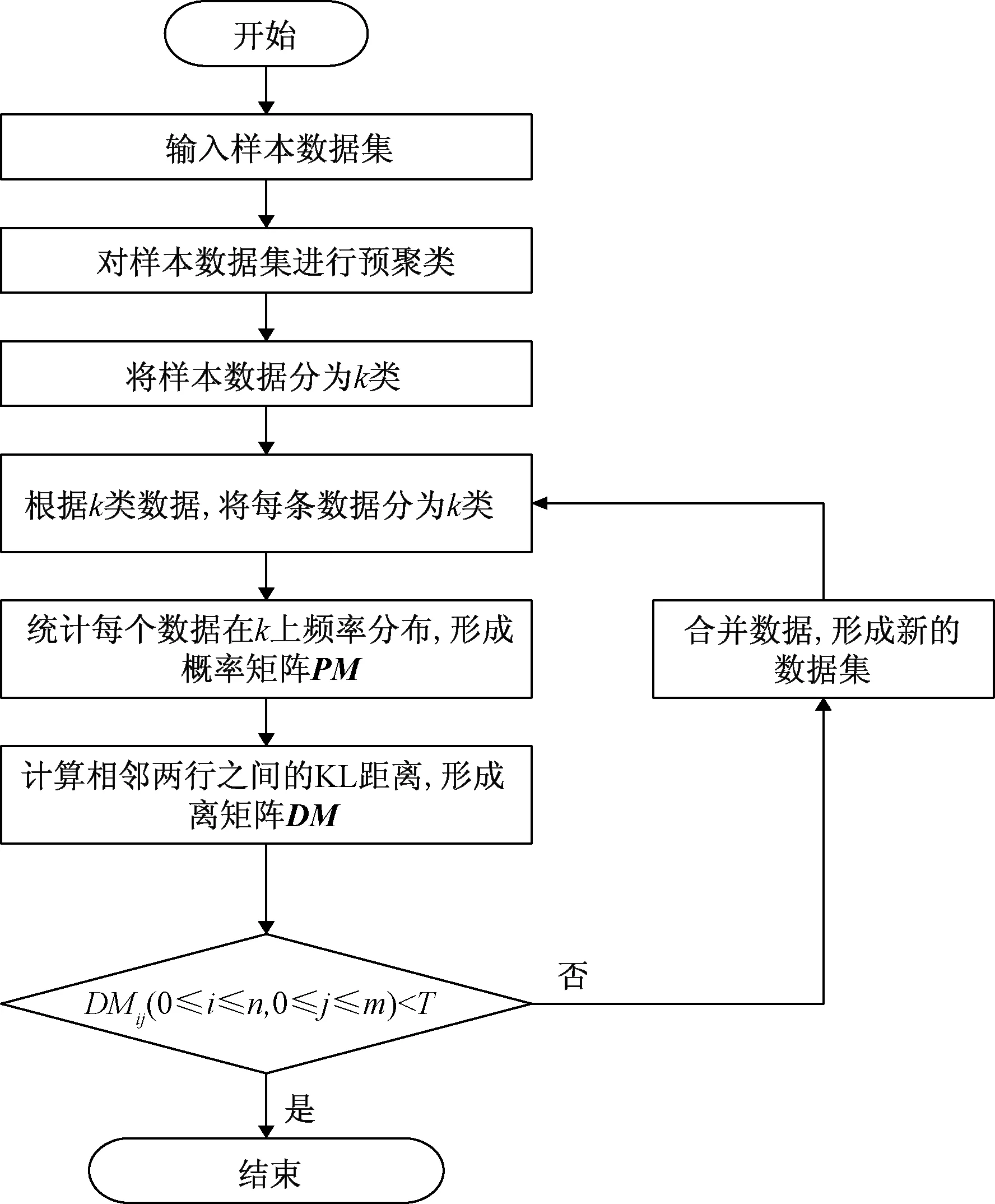
圖1 KL聚類(lèi)算法流程圖
KL_cluster算法:

表2 KL聚類(lèi)算法
3 實(shí)驗(yàn)與分析
3.1 數(shù)據(jù)選擇
為了驗(yàn)證本算法的有效性,并且本算法主要針對(duì)的是離散性數(shù)據(jù)集。一方面,引用公開(kāi)數(shù)據(jù)集MovieLens中最新的數(shù)據(jù),ML-Lastest-Small和Yahoo Music作為數(shù)據(jù)集。另一方面,在The MovieDB中下載數(shù)據(jù),然后將數(shù)據(jù)清洗、整理,得到179位觀眾對(duì)國(guó)內(nèi)外將近180部電影評(píng)分的數(shù)據(jù)集,這里簡(jiǎn)稱為MVD。來(lái)驗(yàn)證算法的有效性。數(shù)據(jù)基本情況見(jiàn)表3。
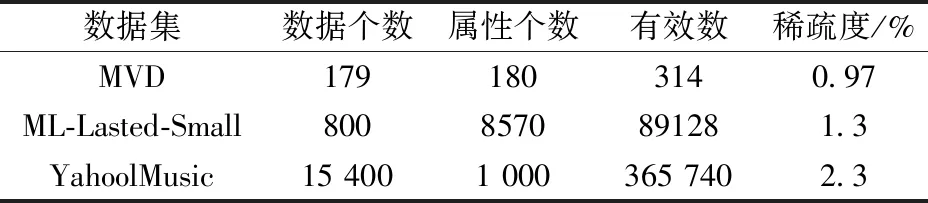
表3 數(shù)據(jù)基本信息
3.2 過(guò)程分析
3.2.1 算法評(píng)價(jià)指標(biāo)
在算法準(zhǔn)確率上,使用本文算法和常用的K-Means算法以及K-Prototypes算法進(jìn)行對(duì)比,同時(shí)也使用誤差平方和指標(biāo)(SSE)進(jìn)行評(píng)判。具體的誤差平方和計(jì)算公式如式(8)所示:
(8)
式(8)中:x表示數(shù)據(jù)集中數(shù)據(jù);μ表示類(lèi)的中心點(diǎn)。通過(guò)此方法可以評(píng)估出聚類(lèi)中心的準(zhǔn)確度。
3.2.2 預(yù)聚類(lèi)分析
首先對(duì)每個(gè)數(shù)據(jù)集上的數(shù)據(jù)集進(jìn)行預(yù)聚類(lèi)。根據(jù)文獻(xiàn)[1]的方法。得到的實(shí)驗(yàn)結(jié)果如圖3和圖4所示。
通過(guò)預(yù)聚類(lèi),可以發(fā)現(xiàn),聚類(lèi)數(shù)目從最優(yōu)變化到變到兩邊次優(yōu)的時(shí)候,聚類(lèi)質(zhì)量發(fā)生大幅度下降。在圖2和圖3中,可以明顯看到有兩個(gè)基本重合的簇,數(shù)據(jù)存在一定的關(guān)聯(lián)性。而通過(guò)這種方法可以很好的監(jiān)測(cè)出數(shù)據(jù)依賴關(guān)系,同時(shí)為預(yù)聚類(lèi)提供正確的結(jié)果。圖4中,在達(dá)到最佳的聚類(lèi)數(shù)10之前,曲線的變化很小,說(shuō)明數(shù)據(jù)由于密度分布不均勻、邊界模糊的情況,尤其是在聚類(lèi)數(shù)目達(dá)到8的時(shí)候,Q(C)曲線出現(xiàn)了一定的上升趨勢(shì)。

圖2 MDB的預(yù)聚類(lèi)結(jié)果
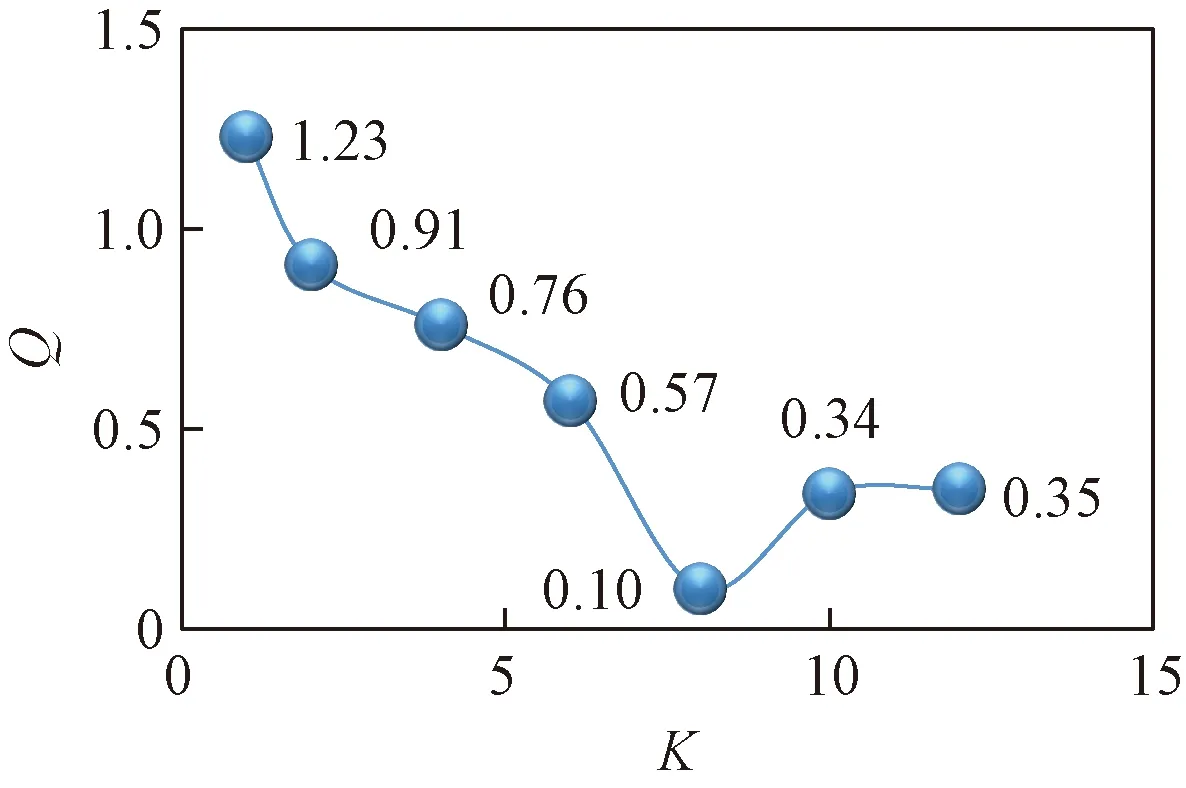
圖3 MovieValue的預(yù)聚類(lèi)結(jié)果
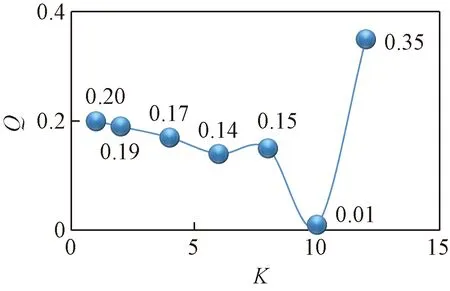
圖4 MovieValue的預(yù)聚類(lèi)結(jié)果
通過(guò)以上分析,預(yù)聚類(lèi)過(guò)程中充分考慮了數(shù)據(jù)分布的特點(diǎn),為整體的數(shù)據(jù)集類(lèi)別劃分提供非常精準(zhǔn)的依據(jù)。
3.2.3 實(shí)驗(yàn)結(jié)果對(duì)比分析
通過(guò)實(shí)驗(yàn),將本文提出的基于KL距離的聚類(lèi)算法、K-Means以及K-Prototypes進(jìn)行對(duì)比,其結(jié)果見(jiàn)表4。
本文算法與K-Means以及K-Prototypes運(yùn)行時(shí)間的對(duì)比見(jiàn)表5。

表4 SSE對(duì)比分析
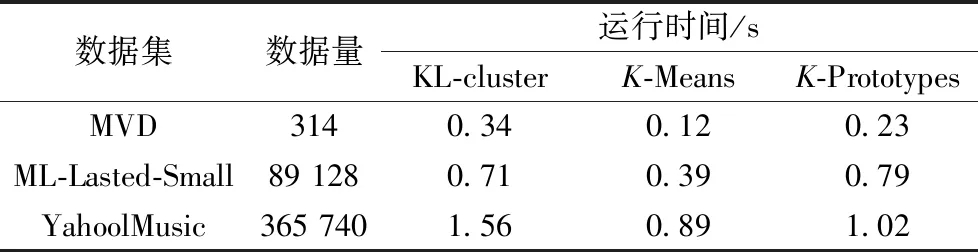
表5 運(yùn)行時(shí)間對(duì)比
從以上的實(shí)驗(yàn)結(jié)果可以看出,KL-cluster算法相比于傳統(tǒng)的K-Means和K-Prototypes,聚類(lèi)的準(zhǔn)確度上有了明顯的提高。而運(yùn)行時(shí)間在某種程度上增加,時(shí)間差距在0.08~0.67 s。原因是在預(yù)聚類(lèi)中占用了一段時(shí)間,雖然犧牲了一定的時(shí)間效率,但是針對(duì)稀疏性的數(shù)據(jù)集上的聚類(lèi)質(zhì)量得到大幅度的提高。
4 結(jié)語(yǔ)
聚類(lèi)算法是機(jī)器學(xué)習(xí)[18]中經(jīng)常使用的一類(lèi)算法,傳統(tǒng)的K-Means算法并不能很好的處理數(shù)據(jù)稀疏性問(wèn)題,在聚類(lèi)的質(zhì)量上產(chǎn)生嚴(yán)重的誤差。為了解決此問(wèn)題,提出了一種基于KL散度[19]的聚類(lèi)算法。算法首先通過(guò)預(yù)聚類(lèi)綜合考慮了數(shù)據(jù)的分布情況,然后對(duì)將整體的數(shù)據(jù)進(jìn)行聚類(lèi),劃分類(lèi)別。然后根據(jù)的數(shù)據(jù)分布情況構(gòu)建概率矩陣,計(jì)算KL矩陣。最后通過(guò)KL矩陣知道數(shù)據(jù)聚類(lèi)。通過(guò)這樣的迭代過(guò)程完成聚類(lèi)[20]。通過(guò)這種方式可以減少序言中提到的三個(gè)問(wèn)題,提升對(duì)稀疏數(shù)據(jù)集中聚類(lèi)質(zhì)量和效率[21]。
