基于關鍵詞檢索的非結構化數據審計應用研究
2020-04-21 07:46:44楊兆群蔡潤柱郭嘉玲
中國內部審計 2020年4期
關鍵詞:商業銀行
楊兆群 蔡潤柱 郭嘉玲
[摘要]商業銀行非結構化數據的增多,給審計工作帶來諸多挑戰,面對審計風險的提高,內部審計需要重新審視傳統的審計工作模式與方法技術,了解審計發展的困局與出路,掌握非結構化數據分析的發展現狀,探索一條可行的非結構化數據審計工作模式,從而提高審計質量與效率,降低審計風險,逐步實現審計信息化。
[關鍵詞]商業銀行?? 內部審計?? 非結構化?? 文本數據
互聯網金融、移動支付快速發展的帶動下,
國內銀行業不斷創新業務種類與業務流程,擴展業務空間并逐漸向數字化銀行轉變。同時,在強監管及內部控制的態勢下,各項業務檔案、指標與報告文檔種類繁多,超過80%為非結構化數據,包含大量有價值的信息,而挖掘這些信息又不同于結構化數據的處理,由此給內部審計帶來前所未有的挑戰,急需一種新的方法予以應對。
一、非結構化數據應用現狀
(一)非結構化數據類型
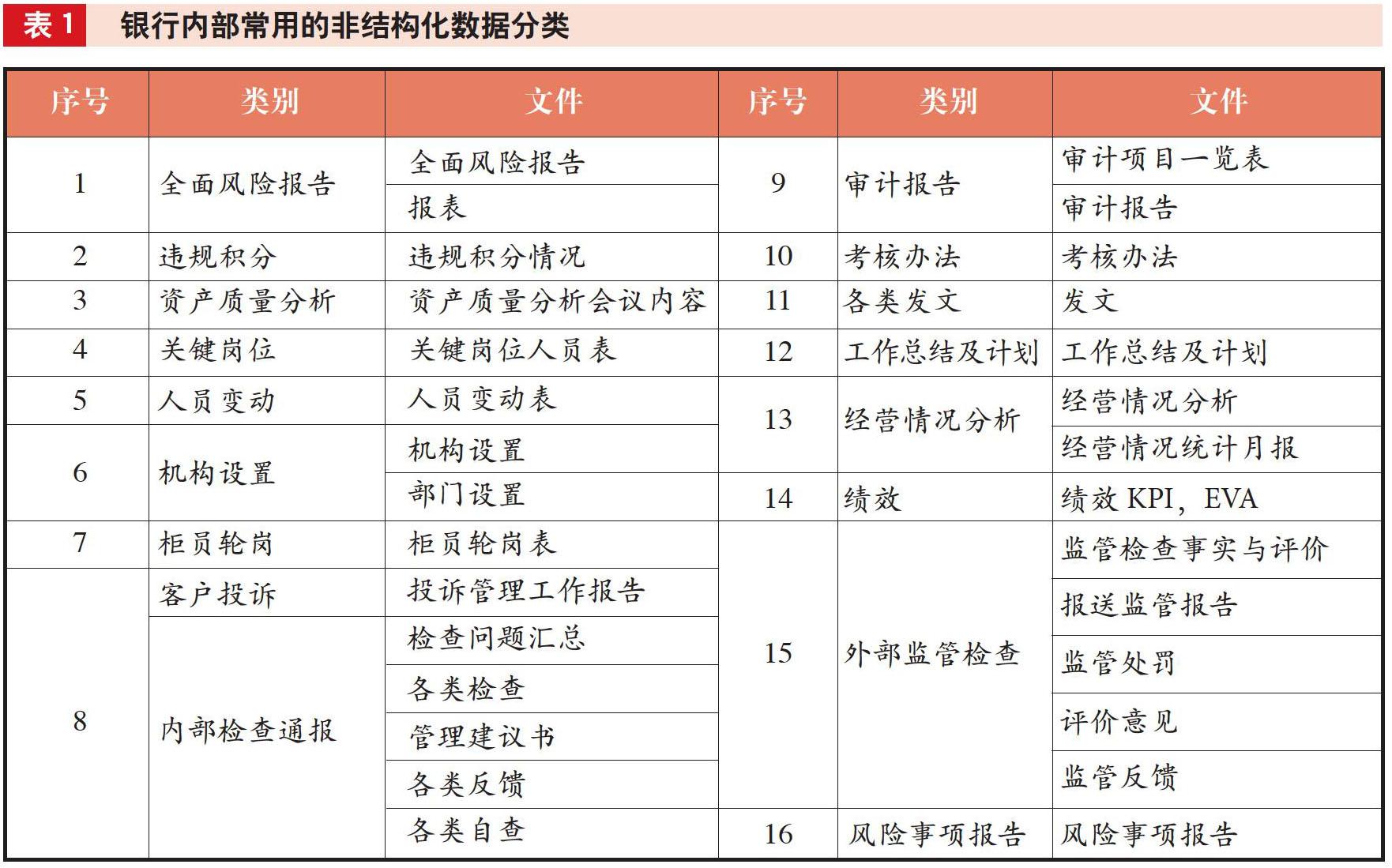
開展銀行內部審計工作時,需要調閱審計對象各類型的非結構化管理文檔,文檔類型有文本、表格、PDF文件、音頻文件等,這些文檔數據主要包括全面風險報告、人員變動、內部檢查報告、考核管理、公文管理等16類,如表1所示。處理如此多的數據,現有審計模式很難不失質效。
(二)非結構化數據特點
隨著業務類型及交易控制手段的更新,銀行內部產生大量、多類型、價值密度低的非結構化數據,這些數據包括行內系統數據、行內文檔數據,同時也包括購買行外的征信、處罰、拍賣等數據。因此,除數據量大、種類繁多、存儲空間大等特點外,非結構化數據還具有數據結構隨機,無法用現有的軟件工具提取、存儲、搜索、共享、分析和處理,數據結構復雜,分析使用難度高,大量數據處理及不同數據之間耦合關聯,在海量數據中不易找尋風險線索,數據價值密度低等特點。
(三)非結構化數據應用方法
一是銀行系統產生的應用日志或系統日志以XML格式保存在數據庫表中,日常應用中多以數據庫語言LIKE或正則表達式函數模糊查詢。二是對于WORD、PDF、EXCEL、TXT、圖片等非結構化電子數據,主要由審計對象提供,數據檢查以手工翻閱、人腦分析判斷各線索之間的關聯為主。三是對于培訓簽到表、機房巡檢表、機房進出登記簿、信貸檔案等非結構化紙質數據,現場審計只能通過人力排查。四是對于報告、發文、審批授權等存放于系統中的非結構化文件數據,主要采用抽樣及觀察方式開展檢查。上述方法低效、低質,無法快速獲得有價值的信息,反而增加了審計工作的風險。
二、非結構化數據應用面臨的問題
現行審計的基本模式為“非現場+現場”,首先通過非現場結構化的數據分析確定工作方向和范圍,然后通過現場檢查確認問題屬性,在文檔與音頻等資料數量少的情形下這樣做是可行的,但在銀行業信息技術加快應用、風控體系管理日益完善、非結構化數據已成主流數據的形勢下,已有的非現場技術僅能對部分結構化數據建模分析,而對大量有價值的數據則無法有效利用,致使審計風險不斷加大。
第一,審計方法與工具不足。由于非結構化數據具有量大、類型多、結構不固定等特點,傳統的數據建模、抽樣統計、數據透視等方法已不再適用,現行廣泛使用的數據處理工具SYSBASE、ORACLE、SQL等很難兼容非結構化數據。而隨著傳統銀行向數字化銀行轉型,非結構化數據的日益增多也使內部審計現有的方法、工具無法應對。
第二,無法實現連續審計。結構化數據可以通過數據建模、腳本監控的方式實現日常風險的監督,較好地保證數據的有效性與風險發現的及時性,實現持續審計監督的職能。但非結構化數據,審計人員只能定期或在特定項目中通過人工翻閱,且數據大多是歷史性的,時效性差,即便發現風險也存在滯后性,無法實現連續審計。
第三,審計資料利用率低。審計工作從結構化數據中發現問題的幾率在逐漸減少,大部分有價值的數據潛藏在各種非結構化數據中,而審計項目周期基本在30-90日,因通過人工翻閱大量的非結構化數據無法保證完全覆蓋,故一般只按比例抽取一定的數據進行檢查,資料利用率低,發現問題缺乏代表性,更難揭露整體風險。
三、非結構化數據分析對于審計工作的意義
銀行內部非結構化數據的增多,使審計面臨的風險隨之增加,充分開展非結構化數據分析對于審計工作發揮職能、提質增效意義重大。
(一)化繁為簡
審計工作需要檢查各種類型的非結構化文本數據,不同類型文檔采用的檢查手段大相徑庭,檢查流程千差萬別,對審計人員的能力及經驗有較高要求,比如,檢查信貸客戶,既要翻閱堆積如山的紙質信貸檔案,又要登錄系統查詢授信審批流程日志,審計過程繁瑣而又機械,關注的風險點又大不相同。通過引入非結構化數據分析技術,將多種形式的文本數據規范為一種,利用關鍵詞算法技術快速提取可疑風險點,達到化繁為簡的目的。
(二)提升價值
傳統審計工作中僅利用結構化數據及少部分非結構化數據,描述的風險不夠全面系統,數據價值未能有效展示。運用非結構化技術后,一是可以充分挖掘數據,提取有價值的數據,彌補單純結構化數據分析的不足;二是充分整合數據,尤其是數據之間的關聯性,形成對審計對象的整體畫像,降低因數據量不足而引起的理解偏差,實現數據價值的提升。
(三)提速增效
在非結構化數據量加速增加的時代,審計人員僅靠手工翻閱及肉眼排查,必然會導致審計周期被拖長,審計范圍被限制,最終影響審計效率與效益。非結構化數據分析技術的運用,可快速識別和分析資料文檔,形成審計場景的風險因子,從而加快審計工作開展,提升審計工作質量。
(四)降低風險
審計風險作為審計工作的系統性風險,不能通過風險組合或者替代等手段將其杜絕。隨著非結構化數據的增多,審計工作難以有效地把握審計對象的整體風險情況,深度與廣度受到數據復雜度及數據量的影響,導致風險累積效應增大。而借助非結構化數據分析手段,全面分析和利用數據,形成整體的風險圖譜,可有效減少審計過程的風險累積。通過最大程度地分析數據,可發現具有普遍性、全局性的風險因素,實現審計風險有效可控。
四、非結構化數據分析應用原理與場景
(一)非結構化數據分析應用原理
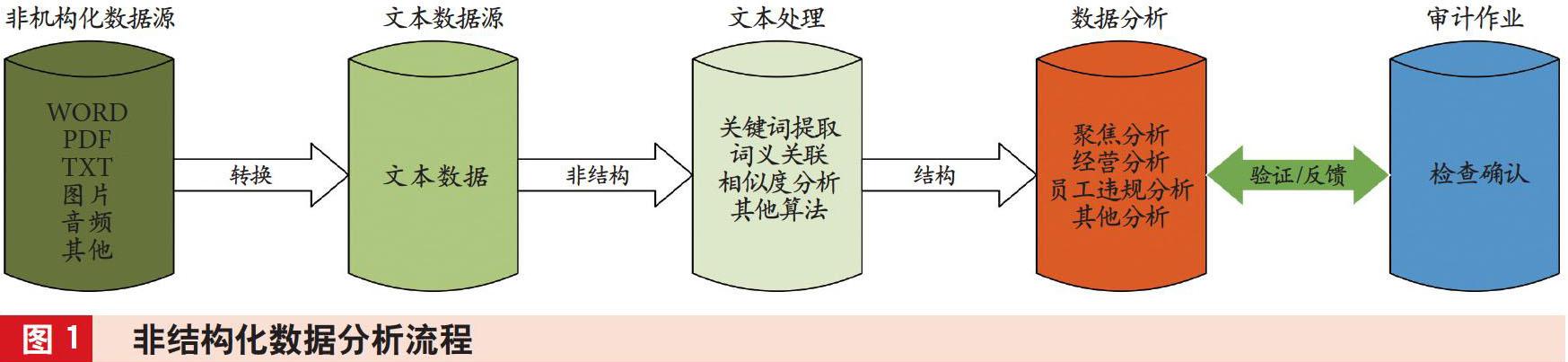
非結構化數據分析的原理是通過將非結構化數據轉換為文本數據,然后對文本數據進行加工處理,逐步轉為半結構化或結構化數據,如圖1所示。
1. 非結構化數據轉換。為便于統一分析,簡化分析方法,首先將非結構化數據轉換為文本數據,其中OFFICE文檔與TXT文件轉換為文本數據較為容易,自身就是可編輯的文本;PDF文件可借助文本編輯工具如OFFICE、WPS等轉換為WORD或TXT文件;圖片文件轉換主要使用OCR技術識別圖片數據,但轉換的準確率會受圖片質量的影響,目前OCR技術識別圖片數據仍需要人工校驗,并逐步優化識別腳本;音頻文件轉換為文本數據,需要借助外部工具,如訊飛、百度語音等應用工具,轉換準確率較高。
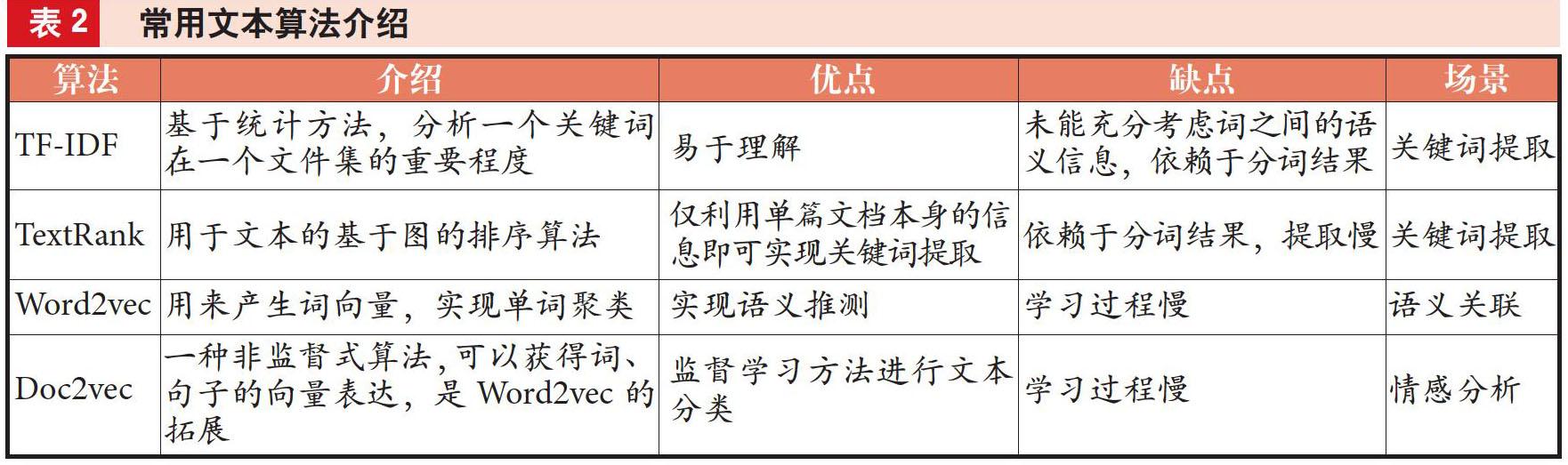
2. 文本數據處理。非結構化數據轉換為文本數據時處于半結構化狀態,需用已有的NLP、SNA算法進行處理。常用的文本處理算法包括TF-IDF、TextRank、Word2vec及Doc2vec等,每種算法都有相應的應用場景與特點,如表2所示。
3. 數據分析。從文本數據中提取的關鍵詞、關鍵句、詞向量等數據,可根據應用場景的不同采取不同的數據分析方法,常用的分析方法有SNA分析、聚焦分析、經營分析、員工違規分析等。數據分析不能一蹴而就、一勞永逸,還需對其結果的準確率及適應性進行檢查,逐步完善算法學習。銀行內部常用的非結構化數據提取關鍵詞詞庫如表3所示。
4. 審計作業。數據分析的結果要與審計作業相結合,服務于審計工作。同時,審計工作要提供數據分析場景及反饋數據分析的驗證結果,促進數據分析模型的迭代優化。審計作業在整個非結構化分析過程中同樣重要,驗證的全面性與適應性決定了數據分析模型的質量。
(二)非結構化數據分析在銀行審計中的應用場景
1. 授信報告情感分析。信貸業務的全流程包括貸前、貸中、貸后三個階段,審計工作需要對每個階段的客戶調查報告進行人工翻閱和判斷,這個過程要耗費大量的人力成本與時間成本并存在一定的操作風險。運用情感分析文本挖掘技術,可以將文本數據向量化,利用模型學習來分析文本內容,從而減少審計項目成本投入,實現對授信客戶風險的準確判斷。
2. 報告相似度分析。在銀行工作中,有很多報告或報表需要定期編寫,如信貸客戶調查報告、系統上線后評價報告等,通過報告相似度分析,可以判斷員工的履職情況,有效降低內控合規風險。另外,報告相似度分析也可以應用到客戶提交材料的分析,如財務報告、資產負債表等,分析客戶提交材料的真實性,及時發現業務風險。
3. 客戶畫像。全面了解客戶是一項困難的工作,特別是在單純依賴結構化數據的情況下,客戶信息的不完整影響對客戶整體風險的判斷,易造成風險事件。利用非結構化數據,大多時候會包含一些外部數據,如判決信息、商業信息、習慣信息等,提取這些客戶關鍵信息,通過對客戶貼信息標簽,將客戶的特征信息提取再匯總,形成對客戶的整體畫像,更加全面了解客戶,從而為客戶打造更好的服務。
五、非結構化數據分析應用案例
根據非結構化數據分析原理及場景,利用Python(V3.7)分析工具,針對情感分析及相似度分析應用案例展開說明。
(一)授信報告情感分析應用
在銀行信貸業務申請過程中,銀行需要對申請人開展一系列審核,主要是評價申請人的各種經營情況、還款意愿的真實性。通常情況下,銀行對貸款申請人的工作背景、經濟實力等因素展開分析,但是僅憑這些要素不足以判斷借款人的真實風險。在很多情況下,壞賬的發生是因為借款人的主觀因素所引起,這些因素包括申請貸款的動機、還款的能力、財務狀況等,因此需要將情感因素納入到貸款的風險評估當中。通過在貸款審批意見過程中加入情感分析模塊,分析銀行授信整個流程中貸款的審批意見情感因子,能夠有效解決上述問題。審批意見的情感分析應用是對授信流程中所有文檔的情感分析,通過授信流程中所有的文檔表現出來的語義和情感傾向,判斷是否存在風險隱患。授信審批意見表現出來的情感傾向隨著風險的變化有微妙的變化,不同授信環節的人由于與項目利益相關性不同,情感上存在差異,如客戶經理與審查員的風險關注點不同,貸款審查委員之間對于項目的認知也具有明顯傾向性,風險經理與業務客戶經理的風險把握不盡相同。因此,必須將授信流程中的重要文檔(授信分析報告、審查意見、貸審會記錄、風險核查報告、監控報告、貸后檢查報告等)都作為處理對象,一方面可以得出不同環節的文本情感得分差異,另一方面可以綜合評分判斷風險。如圖2所示。
基于貸款審批意見的文本情感分析,主要目標是通過對貸款流程報告中的所有審批意見進行情感分析,查找負面傾向明顯的客戶,如表4所示。
通過風險模型的方式可以鎖定部分風險客戶。另外,外部黑名單數據通過和行內客戶關聯也可以鎖定部分黑名單客戶,通過情感分析也可以得出疑似可能發生風險的客戶。從這三個維度,就可以對行內的客戶進行抽樣,從而更精準地找出疑似風險客戶。
(二)調查報告相似度分析
場景一:分支機構會定期提交月報或者季報,通過文本相似度分析對提交的報告進行檢查,目的是核查相關人員是否認真編寫報告。相似度的計算結果在0-1之間,如果相似度達到一定閾值,則可判斷兩份報告的相似度較高。
場景二:部分銀行客戶與資金中介進行合作,貸款前的調查報告由資金中介完成,因而導致同一個中介下很多客戶的貸前調查報告非常相似。
場景三:銀行在發放貸款后,會定期進行貸后調查并出具貸后調查報告。分析各個季度或者月度貸后調查報告相似的情況。在中文信息處理中,文本相似度的計算廣泛應用于信息檢索、機器翻譯、自動問答系統、文本挖掘等領域。文本相似度計算目前的主流方法是采用語義結合詞頻的方式。在進行文本分析的過程中,詞語首先要轉換為詞向量,向量空間模型將字詞轉為連續值的向量表達,并且意思相近的詞將被映射到向量空間中相近的位置。轉換后的詞匯都是空間中的點,如圖3 所示。
通過計算向量空間詞語的相似度,可以最終計算兩個句子的相似度, 如表5所示。
總之,隨著信息技術的發展,大數據應用已成為數據分析常態,非結構化數據分析作為大數據應用的一部分,在商業銀行內部審計工作中的重要性顯著提高。內部審計在處理非結構化數據時還不能像處理結構化數據那樣游刃有余,面對審計項目的增多,審計資料的多樣化與復雜化,單靠人力無法實現審計工作質的飛躍與量的提升,勢必要開展非結構化數據的分析與應用,提升數據分析模型的質量,做好技術分析與審計實施的結合,逐步提升審計工作持續性與全面性,加快內部審計工作信息化建設。
(作者單位:東莞銀行股份有限公司,郵政編碼:523000,電子郵箱:yazhaqu@163.com)
主要參考文獻
陳偉,勾東升,徐發亮.基于文本數據分析的大數據審計方法研究[J].中國注冊會計師, 2018(11):80-84
呂勁松,王志成,王秦輝,徐權.大數據環境下商業銀行審計非結構化數據研究[J].管理理論與方法, 2017(205):141-144
徐宗本,張講社.基于認知的非結構化信息處理:現狀與趨勢[J].中國基礎科學, 2007(6):4-8
趙輝,范志城,許永池,陳波,徐秀星.基于關鍵字檢索的方法在非結構化審計數據分析中的運用[J].中國內部審計, 2010(10):58-61
猜你喜歡
大眾投資指南(2020年10期)2020-07-24 08:03:40
中國外匯(2019年10期)2019-08-27 01:58:00
中國外匯(2019年8期)2019-07-13 06:01:26
智富時代(2019年4期)2019-06-01 07:35:00
經濟技術協作信息(2018年20期)2019-01-19 02:56:32
消費導刊(2017年20期)2018-01-03 06:27:21
湖南城市學院學報(自然科學版)(2016年4期)2016-02-27 14:02:56
山西大同大學學報(社會科學版)(2016年6期)2016-01-23 02:06:18
當代經濟(2015年4期)2015-04-16 05:57:02
現代企業(2015年6期)2015-02-28 18:52:13
