最小熵遷移對抗散列方法
2020-04-21 11:18:26卓君寶王樹徽黃慶明
計算機研究與發展 2020年4期
卓君寶 蘇 馳 王樹徽 黃慶明
1(智能信息處理重點實驗室(中國科學院計算技術研究所) 北京 100190) 2(中國科學院大學計算機科學與技術學院 北京 100049) 3(數字視頻編解碼技術國家工程實驗室(北京大學) 北京 100871)
大數據時代的到來,網絡上涌現了大量的高維圖像數據.圖像檢索越來越受到學術界和工業界的關注.隨著深度學習的普及,深度散列方法[1-7]也備受關注,其性能遠遠超過了傳統的無監督方法[8-10]和基于淺層模型的有監督方法[11-13].然而深度學習方法往往需要大量的標注信息,搜集這些標注信息往往耗費巨大人力物力.此外,大多數現有的深度學習方法都基于獨立同分布的假設,即訓練集(源域)和測試集(目標域)的分布一致.然而在現實應用中,源域和目標域往往存在較大的差異.因此利用有標注的數據集(源域)并遷移到相關的無標注目標域[14-19]受到極大的關注和發展.然而在圖像檢索領域,跨域遷移學習的研究處于起步階段,仍待繼續研究.跨域圖像檢索的難點在于目標域無標注且與源域存在較大域間差異,這種差異往往導致在帶標注源域上訓練好的模型應用于目標域時檢索性能大幅度下降.如何學習具有判別力和域不變的散列碼是跨域圖像檢索的重點.
深度適配散列(deep adaptive hashing, DAH)[20]首次將域適配的方法應用于跨域圖像檢索任務中,在學習散列碼的同時,DAH引入最大均值差異(maximum mean discrepancy, MMD)[14-15]來度量域間差異,通過最小化MMD來學習域不變的散列碼.此后遷移對抗散列(transfer adversarial hashing, TAH)[21]提出將跨域識別中經典的域對抗網絡[19]應用到跨域圖像檢索中.TAH通過引入一個域分類器來判別源域和目標域的分布是否一致,采用對抗思想促使所學的源域與目標域散列碼分布趨于一致,進而學習到域不變的散列碼,取得了當前最好檢索性能.
然而現有深度跨域圖像檢索方法仍然存在2個問題:1)在學習散列碼時,標注信息僅僅被用于構建2個樣本是否相似的監督信息去指導網絡的學習,忽略了標注信息的語義信息.這使得所學的散列碼的判別力不足,造成檢索性能的瓶頸.2)現有的分布對齊方法學習域不變特征的能力仍然不足,使得將源域學習得到的散列函數應用于目標域時性能仍然有較大下降.
針對上面2個問題,我們提出語義保持模塊和最小熵損失來改進現有深度跨域圖像檢索方法.首先,我們在散列特征后再引入一個分類子網絡,通過源域的標注信息來訓練該分類子網絡并將語義信息反傳給生成散列特征的子網絡,有效保持了散列碼的判別力.此外,在目標域上,由于沒有語義標注信息,無法像源域那樣引入監督信息.因此我們引入最小化目標域樣本的類別響應分布的熵來促使目標域樣本的類別響應能夠集中在某個類別上.最小熵損失有效增強了散列碼的泛化能力.
基于TAH模型以及我們所提的語義保持和最小熵損失,我們構建了一個新的可端到端訓練的跨域圖像檢索網絡.由于語義保持采用的多類別的交叉熵損失也是一種熵,因此我們稱所提的模型為最小熵遷移對抗散列(min-entropy transfer adversarial hashing, METAH).我們在2個數據集上進行了大量實驗,與領域內現有主要模型進行了詳盡的對比,實驗證明了所提模型取得了更優的性能,證明了所提語義保持模塊和最小熵損失的有效性.
1 相關工作
跟我們工作相關的2個任務分別是跨域識別和基于散列的圖像檢索.我們將從這2個任務進行相關工作的闡述.
1.1 跨域識別
跨域識別又稱為域適配(domain adaptation, DA),跨域識別已經得到很大的發展,這里我們只回顧和我們方法比較相關的深度域適配方法.
深度域混淆網絡(deep domain confusion, DDC)[14]基于AlexNet架構,其在fc7層上使用單核的MMD來度量域間的差異,通過最小化MMD來使域間差異減小從而學到域不變的特征.深度適配網絡(deep adaptation network, DAN)[15]則在多個全連接層上使用多核的MMD來度量域間差異,進一步加強特征遷移能力.深度相關對齊(deep correlation alignment, DCORAL)[17]和深度無監督卷積域適配(deep unsupervised convolutional domain adaptation, DUCDA)[16]則用源域特征協方差和目標域特征協方差之間的差值矩陣范數來度量域間差異,從而減小深度網絡的特征分布距離以學習域不變的特征.群體匹配差異(population matching discrepancy, PMD)[22]則是對源域和目標域間的樣本計算最優匹配,將匹配的樣本對間的距離進行累加來表征域間差異,通過最小化PMD來學習域不變的特征.
生成對抗網絡(generative adversarial network, GAN)[23]的提出讓基于特征的跨域遷移方法又有了新的突破.域對抗網絡[19]、對抗判別域適配(adver-sarial discriminative domain adaptation, ADDA)[24],和條件對抗域適配(conditional adversarial domain adaptation, CADA)[25],都是利用對抗思想將目標域特征空間向源域特征空間靠近,從而讓目標域的特征可以適配源域的特征分類器.
1.2 散列方法
散列方法是經典的研究方向,主要包括無監督散列[8-10]和有監督散列[1-7,11-13].這里只回顧和我們的方法比較相關的有監督深度散列方法.
卷積神經網絡散列(convolutional neural network hashing, CNNH)[4]采用2階段策略:1)先學散列碼;2)學習一個深度網絡將圖像映射到所學的散列碼.深度神經網絡散列(deep neural network hashing, DNNH)[5]改進了CNNH,不采用2階段訓練策略而是同時學習圖像特征和散列函數,這種端到端訓練方式能夠更加充分利用深度網絡的特征學習和函數擬合能力.深度散列網絡(deep hashing network, DHN)[6]進一步優化DNNH,通過引入交叉熵損失和量化損失來保持相似度和約束量化誤差.散列網絡(HashNet)[7]則解決了符號函數的病態梯度問題,直接優化符號函數,HashNet是單域圖像檢索最好的方法.深度語義排序散列(deep semantic ranking hashing, DSRH)[26]則考慮了多標簽圖像間的語義相似度.
2 最小熵遷移對抗散列方法
2.1 模型框架
如圖1所示,我們的模型采用孿生網絡結構,且上下2個子網絡權值共享.子網絡基于AlexNet,該網絡由conv1~conv5共5層卷積層和fc6~fc8共3層全連接層構成.我們用1個輸出為b的全連接層fchashing替換fc8用于學習散列函數f.由于fchashing難以學習到離散的輸出,因此我們對其放寬了限制,即約束fchashing輸出[-1,1]的連續值.為了能將所學的散列函數泛化到目標域,我們在fchashing后經過梯度取反層(圖1中2個沙漏所表示),之后引入1個域分類器ad_net.該域分類器的作用在于促使fchashing學到域不變的散列特征.此外,為了更好地保持散列碼的語義信息,我們在fchashing后增加語義保持模塊,這里我們用1層全連接層fccls來構建語義保持模塊,它將散列碼映射到類別空間.我們稱所提方法為最小熵遷移對抗散列(METAH).
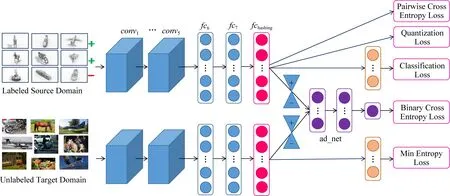
Fig. 1 Framework of the proposed method圖1 所提方法的結構圖
2.2 學習散列函數
我們采用經典的最大后驗估計(maximum a posterior, MAP)來使得所學的散列函數能夠保持成對樣本間的相似度或不相似度.
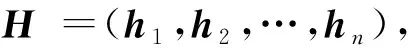
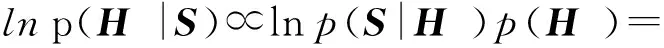
(1)
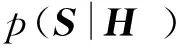
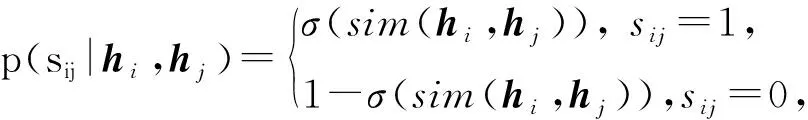
(2)
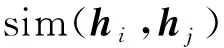
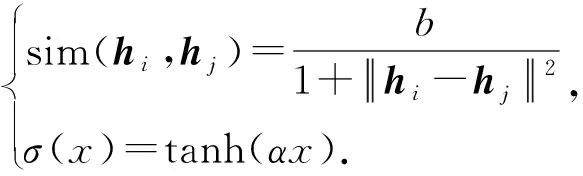
(3)
將式(2)和式(3)代入最大后驗估計式(1)可以得到以下損失:
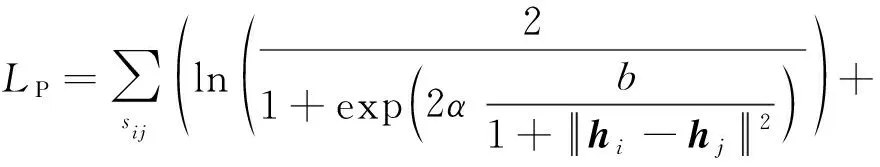
(4)
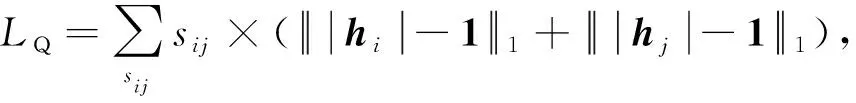
(5)
其中,1=(1,1,…,1)是全為1的b維向量,|·|是絕對值函數,即將輸入向量的每個元素取絕對值.
2.3 對抗分布對齊
在跨域圖像檢索中,由于源域和目標域存在較大分布差異,且目標域沒有標注信息,將源域訓練好的模型應用于目標域時會造成性能大幅下降.因此我們需要在學習散列碼的同時縮小域間差異,使得所學習的散列碼是域不變的.
域對抗網絡[19]是一個典型的域分布對齊方法,發展至今,域對抗方法具有良好的理論保證且在跨域識別達到較優的性能.本文也采用域對抗思想來減小域間差異.域對抗思想是引入一個域分類器,其作用是區分樣本特征來自源域還是目標域.由于我們訓練時知道樣本來自于源域或目標域,域分類器可以通過這種標注來訓練,即最小化二分類交叉熵損失.而另一方面,我們希望所學到的特征是域分類器區分不開的,即最大化二分類交叉熵損失.從分布擬合的角度來看,域分類器用于區分2個域的分布,而特征生成器則拉近2個域的分布,進而減小域間差異.
記GF為散列特征生成器即conv1~conv5,fc6~fc7,fchashing所組成的子網絡,其可訓練參數為θF.域分類器GD的可訓練參數記為θD.則域對抗網絡的損失為
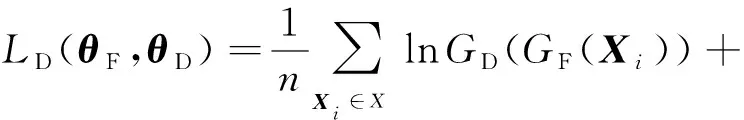
(6)
式(6)是二分類的交叉熵損失.對抗學習則是尋求損失函數LD(θF,θD)的鞍點:
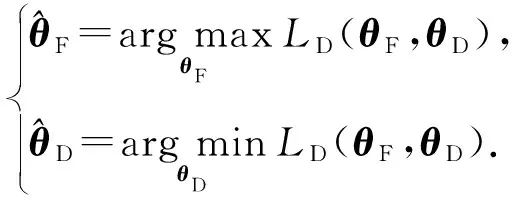
(7)
求解式(7)需要分開優化,且這種方式訓練比較困難.因此我們也采用梯度取反層[19]來實現對抗學習,具體方法是引入梯度取反層(圖1沙漏所示),操作為
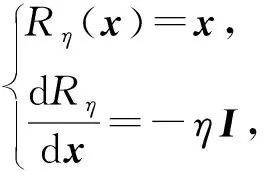
(8)
其中,I是單位陣.梯度取反層正向計算時其輸出保持不變,而反向傳播時將原梯度取反并乘以η.
因此,域對抗網絡的損失為
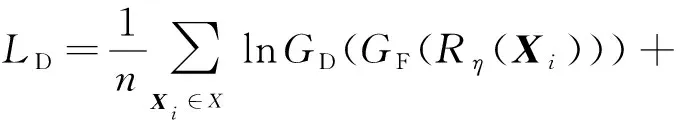
(9)
2.4 語義信息保持
(10)
其中,〈·,·〉是內積.引入該分類損失大大增強了散列特征的判別力,增強了模型的泛化能力.
2.5 最小熵
在目標域中,一個理想的散列碼在經過fccls后得到的分類響應應該集中于某一類上.由于目標域沒有標注,我們無法知道目標域樣本應該屬于哪一類,因此我們通過最小熵來促使目標域樣本分類響應集中于某一類上.熵的計算為
(11)
源域由于有標注信息,其樣本的分類響應往往集中在所標注的類別上;而目標域由于存在域間差異,其在分類響應上往往不夠集中.最小熵能夠在語義層減小源域和目標域的域間差異,進而影響特征層,使得特征層的域間差異也相應減小,即增強了散列碼的域不變能力具有更強的泛化能力.
2.6 總損失
綜合2.2~2.5節,我們采用最終目標損失來訓練所提的最小熵遷移對抗散列方法:
L=λPLP+λQLQ+λDLD+λCLC+λELE,
(12)
其中,λ*是一些控制各個損失間平衡的超參數.
3 實驗與結果
我們在2個常用數據集上進行了大量實驗,并與領域內現有主要模型進行了詳盡的對比.實驗證明了所提模型取得了更優的性能.
3.1 實驗設置與對比算法
NUS-WIDE是一個跨模態檢索常用的數據集,其包含269 648個文本-圖像對.該數據集標注了81個語義概念用于測試檢索算法的性能.為了公平比較,我們沿用文獻[5-8]的設定,只在出現頻率最高的21個語義概念所涵蓋的195 834張圖像上做實驗.查詢集包含2 100張圖像,訓練集包含10 000張圖像,剩下的作為被檢索的數據庫.
VisDA-2017是一個跨域識別常用的數據集,其包含2個域,源域由CAD模型渲染生成的12類圖像構成,記為Syn,目標域是在COCO上選取的相應類別的子集,記為Real.由于該數據集域間差異比較大,我們構建2種設定:1)查詢集和數據庫都采用Real域而帶標注訓練集為Syn域,記為Syn→Real;2)查詢集和數據庫都采用Syn域而帶標注訓練集為Real域,記為Real→Syn.
我們在漢明距離小于2(Hamming radius 2)的檢索結果上計算平均精度均值(mean average precision, MAP)作為評測性能.對比算法包括局部敏感散列(locality sensitive hashing, LSH)[8]、譜散列(spectral hashing, SH)[9]、迭代量化(iterative quantization, ITQ)[10]等傳統無監督方法;核散列(kernel supervised hashing, KSH)[12]、監督離散散列(supervised discrete hashing, SDH)[13]等有監督淺層模型;CNNH[4], DNNH[5],DHN[6],HashNet[7]等單域有監督深度模型以及傳遞散列網絡(transi-tive hashing network, THN)[27],TAH[21]等跨模態或者跨域的有監督深度檢索方法.為了更好地驗證和分析我們所提的語義信息保持模塊和最小熵的有效性,我們構造了2個變體METAH-e和METAH.其中METAH-e中λE=0,即不加最小熵損失.
為了公平比較,我們的算法也是基于在ImageNet上與訓練好的AlexNet上.我們采用Caffe框架來微調conv1~conv5等卷積層和fc6~fc7等全連接層.此外,我們多加1層全連接層fchashing層,并在fchashing層后接2個分支:1)2層全連接層構成的子網絡ad_net用于對抗學習;2)1個分類全連接層fccls構成的語義保持模塊.fchashing,ad_net,fccls等新加全連接層的學習率設置為conv1~conv5,fc6~fc7學習率的10倍.整個優化過程采用沖量為0.9的小批量隨機梯度下降法(stochastic gradient descent, SGD).1次迭代對每個域隨機抽取64張圖像用于估計梯度.權重衰減設為0.0005.在3.3節中的梯度取反層中的參數η的更新為:η=2/(1+exp(10i)),其中i是當前迭代的次數.式(12)中的超參數設置如表1所示:
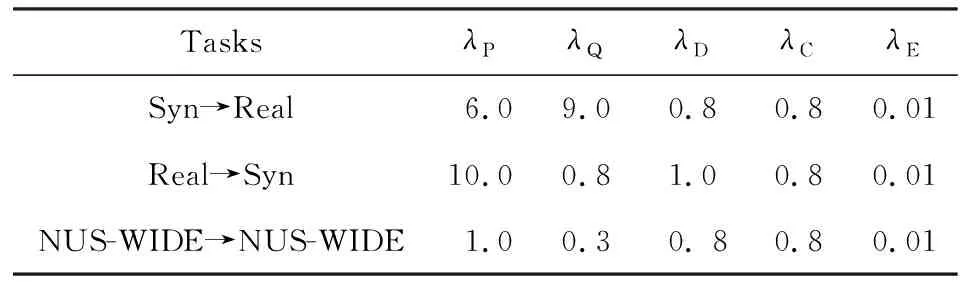
Table 1 Values for Hyper-Parameters表1 超參數設置
3.2 定量實驗結果
NUS-WIDE上的平均精度均值如表2所示.我們可以看出:即使在訓練集和測試集域間差異幾乎不存在的情況下,我們的方法也能取得最優的結果.在散列碼的長度分別為48 b和64 b的設定中,我們的方法比TAH[21]的平均精度均值分別提高了0.086和0.087.在32 b設定中,我們的方法提升很小,原因在于32 b維度太小,模型能力較弱,不能同時學習散列碼和保持語義信息.而在48 b和64 b的設定中,語義信息保持(METAH-e)所帶來的性能提升則非常顯著.由于域間差異幾乎不存在,METAH相比于METAH-e性能提升很小甚至起負遷移的作用.
上述現象符合我們的預期,因為最小熵的作用在于減小域間差異,對于域間差異幾乎不存在的設定中,強行減小域間差異反而會帶來反作用.
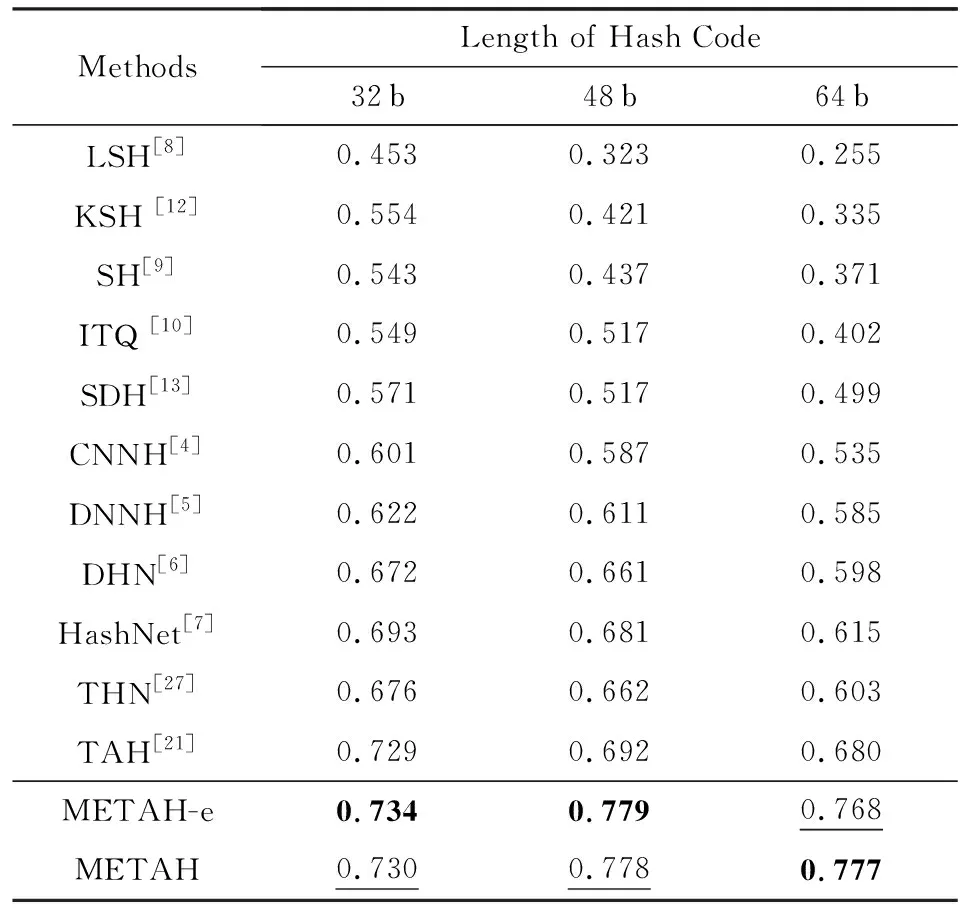
Table 2 MAP Results Within Hamming Radius 2 on NUS-WIDE
Notes: METAH-e is a variant of METAH withλE=0; bold values indicate the best performance; underlined values indicate the second best performance.
VisDA-2017上Syn→Real的平均精度均值如表3所示.在散列碼的長度分別為32 b,48 b,64 b的設定中,我們的方法比TAH的平均精度均值分別提高了0.048,0.101,0.101.可以看出由于32 b維度較小,METAH的平均精度均值提升相比于48 b和64 b較小.由于該任務中源域和目標域存在較大差異,因而我們所提的最小熵作用更加明顯.因此在32 b,48 b,64 b的設定中,METAH相比于METAH-e的平均精度均值分別提升了0.023,0.024,0.038.值得注意的是我們對不同長度的散列碼都采用同樣的超參數,而TAH各個設定的超參數都是通過交叉驗證獲得的,所以METAH具有更大的潛能.
VisDA-2017上Real→Syn的平均精度均值如表4所示.相比于最好的對比算法TAH[8],我們的方法METAH在散列碼的長度分別為32 b,48 b,64 b的設定中平均精度均值分別提高了0.001,0.008,0.071.相比于Syn→Real,在Real→Syn上METAH的提升較小,原因可能是我們使用了和Syn→Real同樣的超參數設置,即λC=0.8,λE=0.01,然而對于跨域圖像檢索的設定,目標域是無標注的,因此通過交叉驗證針對不同長度散列碼去搜索最優的參數是不可取的,所以我們這里針對所有不同長度散列碼都只用一套相同的超參數.此外,在散列碼的長度分別為32 b,48 b,64 b的設定中,METAH相比于METAH-e的平均精度均值分別提升了0.008,0.010,0.003.證明了所提的最小熵在減小域間差異上的有效性.
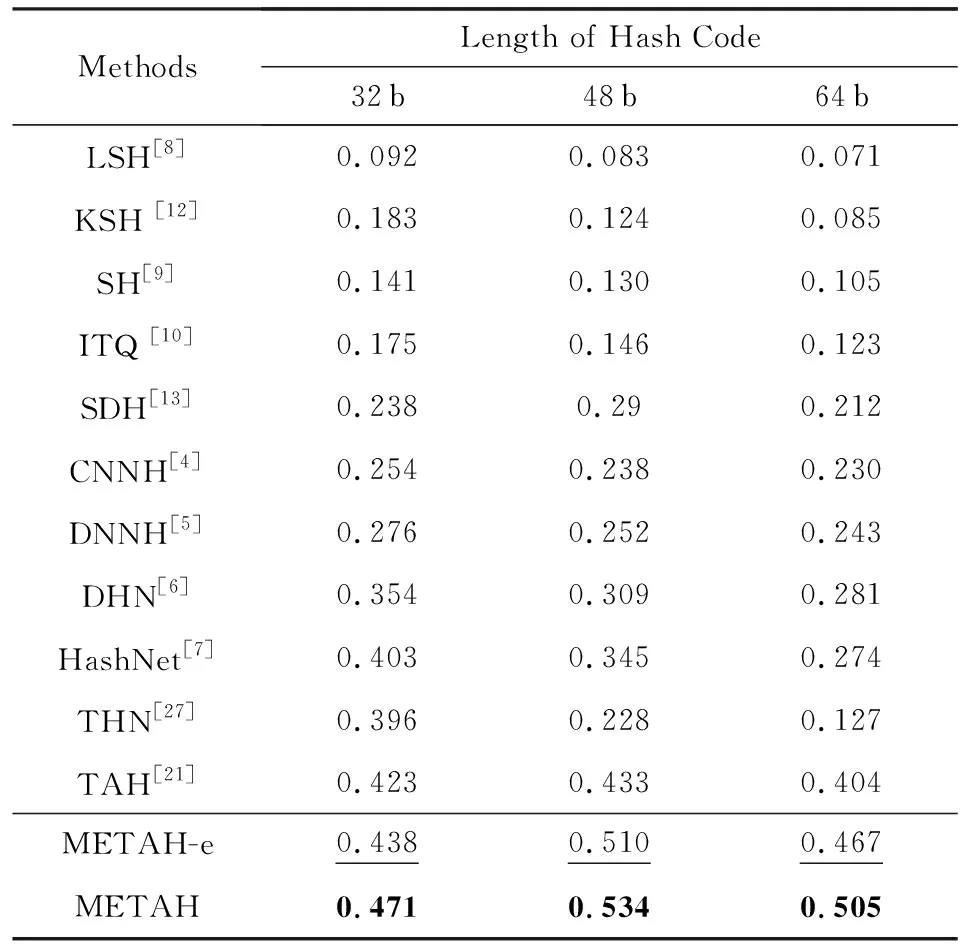
Table 3 MAP Results Within Hamming Radius 2 on Syn→Real
Notes: METAH-e is a variant of METAH withλE=0; bold values indicate the best performance; underlined values indicate the second best performance.
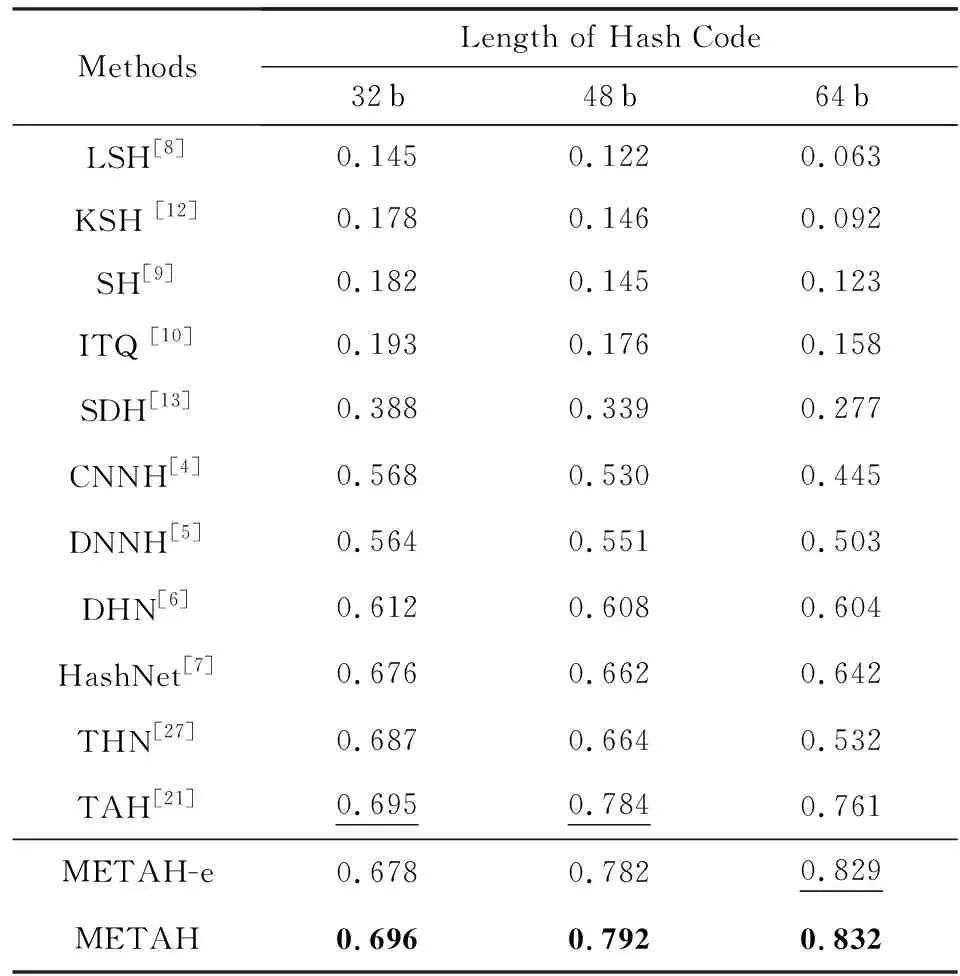
Table 4 MAP Results Within Hamming Radius 2 on Real→Syn
Notes: METAH-e is a variant of METAH withλE=0; bold values indicate the best performance; underlined values indicate the second best performance.
3.3 定性實驗結果
我們在VisDA-2017數據集上進行了可視化實驗.在Syn→Real任務中,我們在Real域隨機選取了1個查詢,并在Real域構成的數據庫中進行檢索,我們列出前10的檢索結果,與TAH,METAH-e的對比結果如圖2所示.虛線框指錯誤檢索結果,實線框指正確檢索結果.可以看出METAH-e和METAH的查詢結果相比于TAH錯誤結果更少,證明了所提方法的有效性.在Real→Syn上的檢索結果如圖3所示,我們可以觀察到相似的現象,即METAH-e和METAH的查詢結果相比于TAH錯誤結果更少.

Fig. 2 Examples of top 10 retrieval images and P@10 in Syn→Real圖2 在Syn→Real上前10檢索結果和P@10值
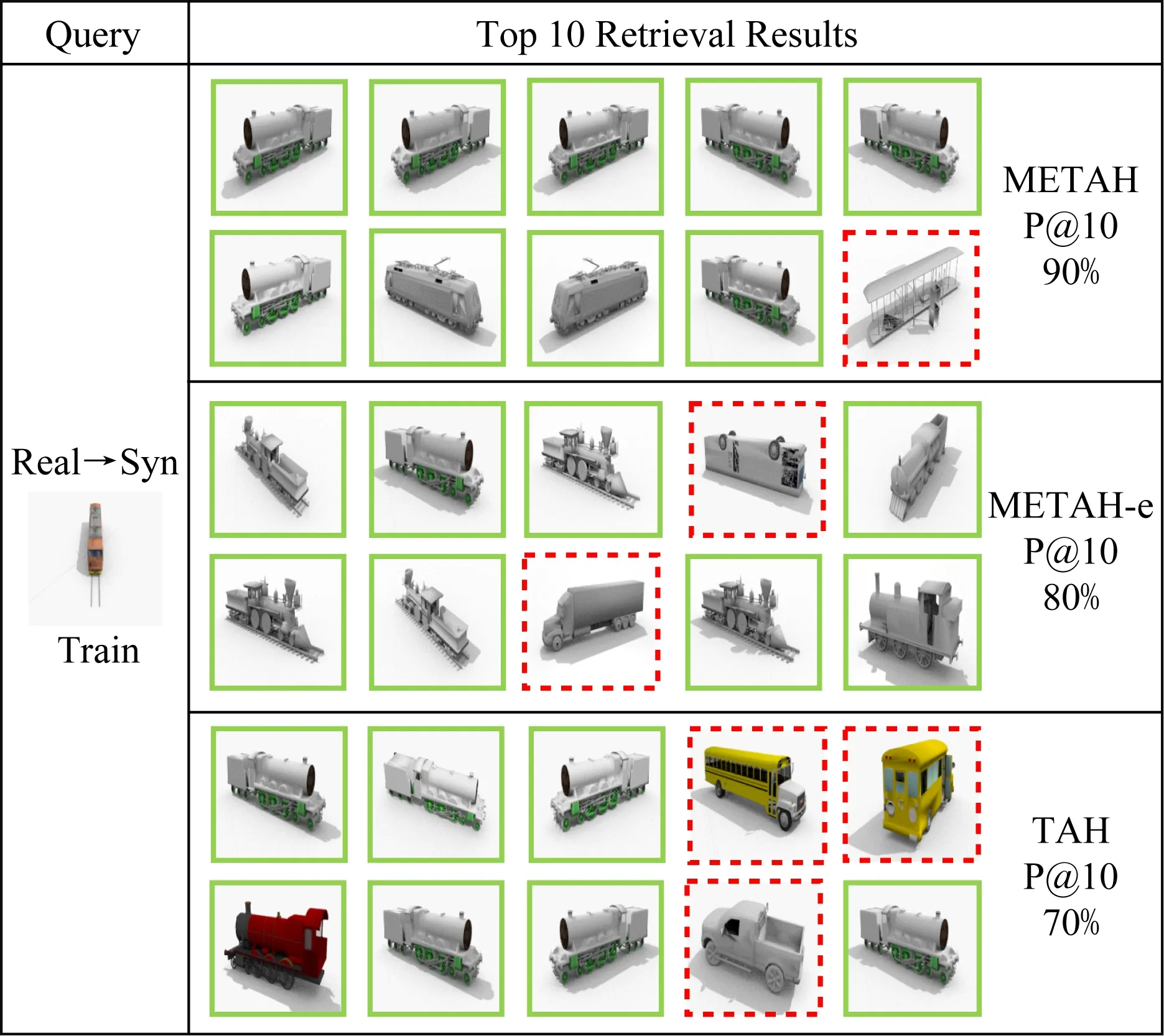
Fig. 3 Examples of top 10 retrieval images and P@10 in Real→Syn圖3 在Real→Syn上前10檢索結果和P@10值
4 總 結
在本文中,我們針對現有深度跨域圖像檢索方法所學散列碼判別力和域不變能力不足這2個問題,提出了語義保持模塊和最小熵損失來改進現有的模型.語義保持模塊能夠使所學到的散列碼包含更多的語義信息.最小熵能使目標域樣本與源域樣本在語義空間上分布更加對齊,使得散列碼更具域不變性.大量的實驗表明我們的模型相比于領域內主要模型取得了更優的性能,驗證了所提改進技術的有效性.
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
鄭州大學學報(醫學版)(2015年2期)2015-02-27 14:50:46
大連民族大學學報(2015年2期)2015-02-27 08:28:11
