基于類別相關的領域自適應交通圖像語義分割方法
2020-04-21 07:58:26賈穎霞郎叢妍馮松鶴
計算機研究與發展 2020年4期
賈穎霞 郎叢妍 馮松鶴
(北京交通大學計算機與信息技術學院 北京 100044)
圖像語義分割作為計算機視覺領域的一個重要研究問題,旨在對輸入圖像的每一個像素根據其所屬的類別進行分類,最終整合得到包含語義信息的分割輸出結果,其分割結果的準確度對后續的場景理解、目標追蹤以及圖文轉換等課題起著直接且至關重要的作用.近年來,由于深度學習的發展以及全卷積神經網絡(fully convolutional network, FCN)[1]的出現,語義分割得以快速發展.
然而,現有的語義分割算法[1-4]存在著許多不足,特別是對精準標注過分依賴.由于對數據進行人工標注將會耗費大量的時間和精力,因此實際應用中收集到的圖像大多沒有精準的數據標注.對精準標注的過分依賴導致現有的語義分割方法難以直接應用于非精準甚至無標注數據集中.
為解決這一問題,近年來提出領域自適應方法,用于縮小所含類別相似、數據分布相近的有標注源域數據集和無標注目標域數據集之間的語義鴻溝.擁有一定量的有標注數據,通過訓練神經網絡模型,便可對其進行特征提取與語義分割.利用生成-對抗學習[5]的思想,對這個網絡經過調整、優化,即可將其有效應用在其他跨域的無標注數據集中.而與常見的利用生成對抗網絡(generative adversarial network, GAN)[5]進行圖像分類或圖像增強的方法不同,語義分割方法所需的特征需要同時包含圖像整體的空間布局信息和局部語義類別的上下文信息,實現難度大.
現有的領域自適應語義分割方法大多存在2個問題:
1) 絕大多數算法直接將領域自適應方法應用在原圖上,分別利用來自源域和目標域的原圖進行對抗學習,進而實現語義分割,而實驗結果表明,這一做法存在2個不足:①若直接對原圖進行識別及語義分割、對抗判別等操作,容易出現分割不準或過度分類等問題,如圖1左側展示的場景是陰天1輛轎車停在紐約街頭馬路,圖1右側展示的場景是晴天1輛跑車停在倫敦鄉鎮的柵欄外,2張原圖間場景存在較大差異,而在語義分割方法中,兩者所包含的語義信息及語義類別卻較為相近.②現有的領域自適應方法所采用的對抗判別基準多為直接使用GAN[5]網絡中的鑒別器,判別輸入的2張圖片是否來自同一數據域.而圖像語義信息通過其包含的全部語義類別體現.僅利用整張原圖進行語義判別,容易造成類別錯分等分割結果不理想的問題.
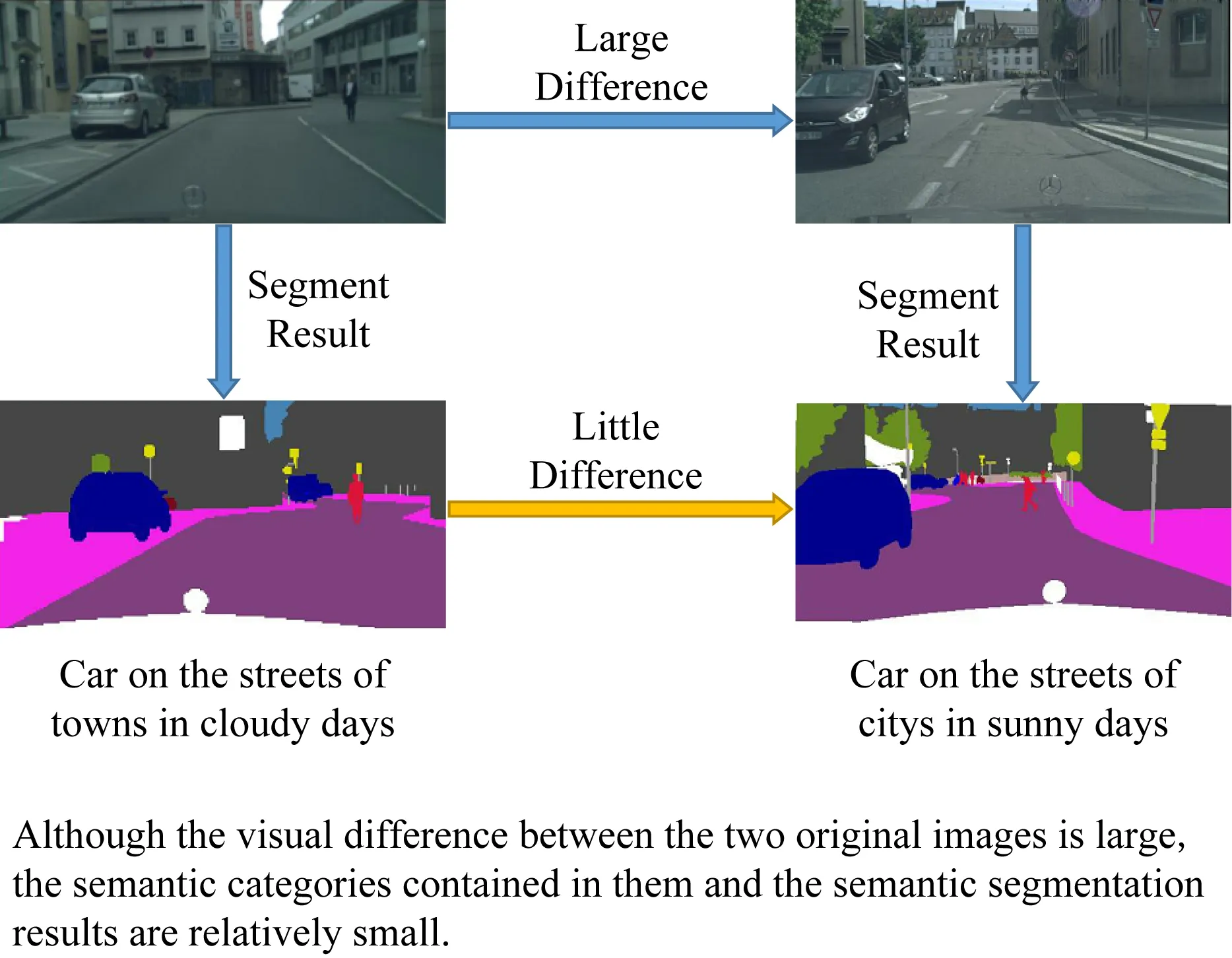
Fig. 1 Comparison of original image and segmentation results圖1 原圖及語義分割結果對比圖
2) 目前許多數據集均存在“長尾分布”效應,即20%的語義類別占據80%的數據量,諸如在交通場景數據集中,車輛、道路等占據了約80%的數據量,而交通信號燈及路標等類別,因其所占數據量較小且易與背景混淆而時常難以被正確分割,為實際應用帶來了諸多不便.
根據以上分析,本文針對現有的領域自適應及語義分割方法中存在的問題,提出2個改進方案:
1) 為改善現有數據集中數據分布不均的情況提出基于改進focal loss[6]的損失函數;同時,引入Pixel Shuffle方法[7]改進上采樣方法,在對源域數據進行語義分割的過程中,有效提高解碼器對原圖空間信息及上下文語義信息的恢復程度.
2) 提出一種新的基于類別相關的領域自適應語義分割方法,通過提出新的領域自適應階段、設計基于語義類別相關的對抗判別標準,并對目標域語義分割網絡進行約束調優來有效解決不同數據集跨域分割問題,使得語義分割效果具有更細粒度的提升,進而減少對全標注樣本的需求;同時顯著提高對于標注情況、圖像風格、數據分布均不相似但包含相同語義類別的2個數據集間的自適應水平,提升語義分割精準度和泛化性能.
1 研究現狀
1.1 語義分割
目前大多數語義分割方法的核心思想來自FCN[1],FCN將卷積神經網絡(convolutional neural network, CNN)[8]中的最后一層替換為卷積層,同時使用跳躍式結構,將高層次特征與低層次特征結合,有效提高分割精準度.而為了更好地融合多尺度語義信息,提高分割結果,近年來,許多方法采用“編碼器-解碼器”[2]結構,其中編碼器負責提取高層抽象語義特征,解碼器通過反卷積[9]或反池化等方法擬合不同層次特征,逐步將分割特征圖的語義信息和大小恢復至與原圖一致.近來,文獻[3]中提出名為Deeplab V3+的方法,引入可任意控制編碼器用以提取特征的分辨率,同時通過空洞卷積方法平衡其精度和耗時.
針對現有監督方法過于依賴精確標注的問題,文獻[10]中提出基于顯著圖信息的弱監督語義分割方法,通過顯著圖求得每個像素屬于前景物體或者背景的概率,并采用多標簽交叉熵損失訓練出一個簡單的深度卷積神經網絡,再根據數據集中圖像級別的標注信息剔除部分噪聲,使得該網絡具備較高語義分割能力.文獻[11]中提出基于對抗性擦除的方法,將圖片輸入至分類網絡,通過訓練得到對于當前圖片而言最具判別力的區域,將這部分的像素值在網絡中設置為0,并將擦除后的圖片輸入分類網絡進行再訓練.網絡會自動尋找其他證據,使得圖像可以被正確分類,重復以上操作,最后通過融合經擦除的區域獲取相應物體的整個區域.文獻[12]中提出基于圖模型和圖匹配的自監督學習語義分割方法,提出一種基于類內連通圖的三元組抽樣方案改進分割精度.以上方法均取得較為優異的結果,但針對完全無標注的圖像,依然難以有效、快速地處理.
針對以上問題,本文引入1.2節中描述的領域自適應方法,通過對有標注數據集的分割方法進行訓練學習與遷移,解決對無標注數據集的跨域分割問題,顯著提升無標注數據集的語義分割精準度.
1.2 領域自適應
領域自適應是遷移學習[13]在計算機視覺領域的應用,用以解決源域和目標域之間的域不變及域遷移問題.根據“適應”內容的不同,目前主要有3類領域自適應方法.1)基于對抗-生成[5]思想,使得目標域有效“適應”源域的分割模型及方法;2)基于風格轉換[13],利用目標域數據對源域數據進行圖像增強,進而實現2個域內數據彼此“適應”的方法;3)采用“師生”模型體系結構的基于知識蒸餾[14]的領域自適應方法.
在基于生成對抗思想的方法中,依據對抗階段采用的判別標準的不同,可將其分為基于數據分布的域適應、基于特征選擇的域適應以及基于子空間學習的域適應方法等.這類方法的主要實現難點在于如何有效減小源域數據集與目標域數據集兩者間的分布差異.文獻[15]中通過最小化最大平均差異方法,實現對源域和目標域之間特征分布的有效對齊.文獻[16]中提出依據相關對齊損失,匹配源域數據集和目標域數據集特征的均值和協方差.
針對現有領域自適應方法中,多采用原圖或高層次抽象特征圖進行跨域訓練,進而造成的語義不一致或類別錯分問題,本文提出一種新的基于類別相關的領域自適應語義分割方法:首先,對原圖進行粗分割;其次,對其分割結果進行類別相關的優化調整.通過提升跨域數據集間的自適應水平,有效實現對無標注數據集的跨域語義分割,提高算法的泛化性能.
2 一種基于類別相關的語義分割方法
2.1 方法綜述
在本節中,如圖2所示,本文提出一種包含3個處理階段的基于類別相關領域的自適應語義分割方法模型.
1) 對基于監督學習的語義分割方法進行改進.為了提高圖像中類別邊緣的分割精度,改進解碼過程中基于特征圖的上采樣(upsampling)方法,提高對輸入圖像中的空間信息及上下文語義信息的恢復程度;同時,針對數據集中數據分布不均的情況,對現有方法的損失函數進行相應改進,使本文方法針對難分割、數據量小的類別,能有效提高其分割準確度.
2) 根據前期調研,現有領域自適應方法的適應階段大多選擇在原圖或經卷積處理后的特征圖上進行,而本文則選擇在經過分割網絡處理得到的粗分割輸出空間上進行學習與訓練,這樣使得本文方法既能在一定程度上有效避免語義不一致問題,又能有效利用圖像中的基礎結構化的域不變特征、上下文語義及空間信息.此外,提出將類別相關的數據分布情況作為領域自適應的對齊標準,并對整體的語義分割網絡進行約束調優,使本文方法的分割效果較先前方法有更細粒度的提升.
3) 根據前2階段學習及訓練得出的網絡,設計損失函數,對算法網絡進行全局約束優化,提高本文算法泛化性,使得標注情況、圖像風格、數據分布均不相似但包含相同語義類別的2個數據集間能夠更好地實現領域自適應.
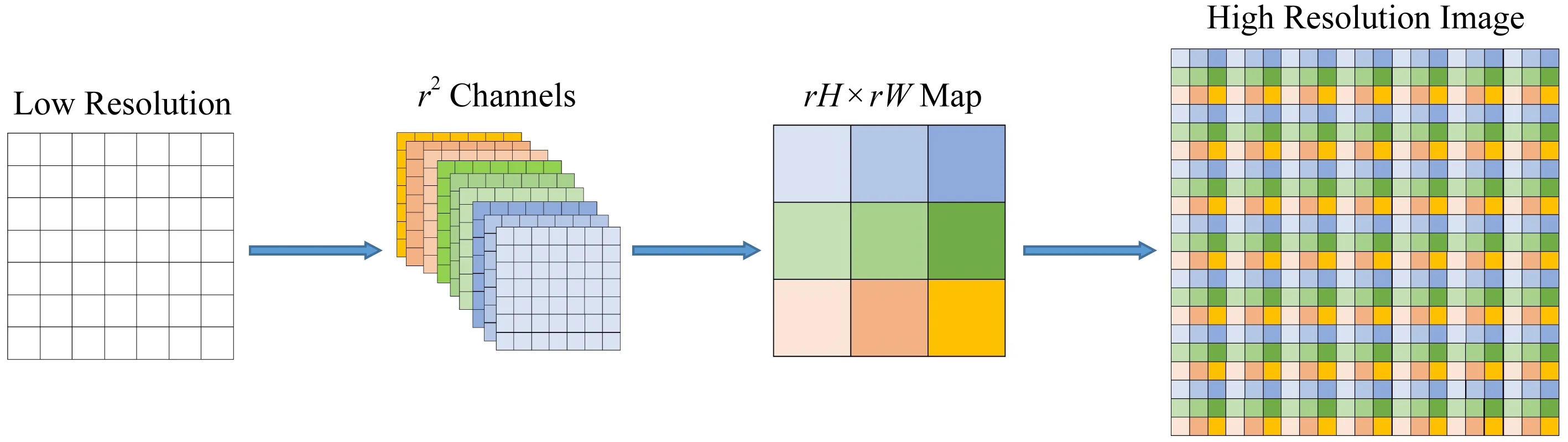
Fig. 3 The graph of super-resolution reconstruction method圖3 超分辨率重建方法示意圖
2.2 方法設計
2.2.1 基于監督學習的方法改進
本文首先對現有基于監督學習的語義分割網絡進行改進.
本文針對源域數據集采用的基礎網絡模型為DeepLab[3],其使用“編碼器-解碼器”結構,在解碼過程中使用雙線性插值方法,利用周圍4個像素點信息對待測樣點進行插值計算,繼而將特征圖逐步復原至輸入圖像的大小.
而雙線性插值方法不僅計算量較大,且僅考慮待測樣點周圍4個直接相鄰點灰度值的影響,未考慮其他各相鄰點間灰度值變化率的影響,從而導致縮放后圖像的高頻分量損失,相應類別的分割邊緣模糊;同時,因在相鄰點之間反復計算,存在一定程度的重疊(overlap)現象.
因此,在擴大特征圖大小且恢復圖像語義信息的上采樣過程中,本文采用如圖3所示的超分辨率重建[7]方法.首先通過卷積計算得到r2個通道的特征圖,然后通過周期篩選方法得到更高分辨率的圖像.其中,r為上采樣因子(upscaling factor),即相應圖像的擴大倍率.
將帶有精準標注的源域數據輸入至經過優化的語義分割網絡中,得到語義分割結果,并將此結果與源域數據中的真實分割區域(ground truth)進行比對,求得當前方法的分割準確率.
同時,針對數據集中語義類別分布存在的如圖4所示的“長尾效應”,即20%的語義類別占據數據集中80%的數據量,而其他很多對分割精準度具有重要影響的語義類別因所占數據比例較小而難以被正確分割,本文提出如式(1)所示的基于改進focal loss[6]的優化方法,作為基于監督學習語義分割方法的損失函數,旨在將更多的注意力傾注在數據量小但對分割結果影響較大的數據類別上,使得相應類別及圖像整體的分割準確率能夠得到有效提升.
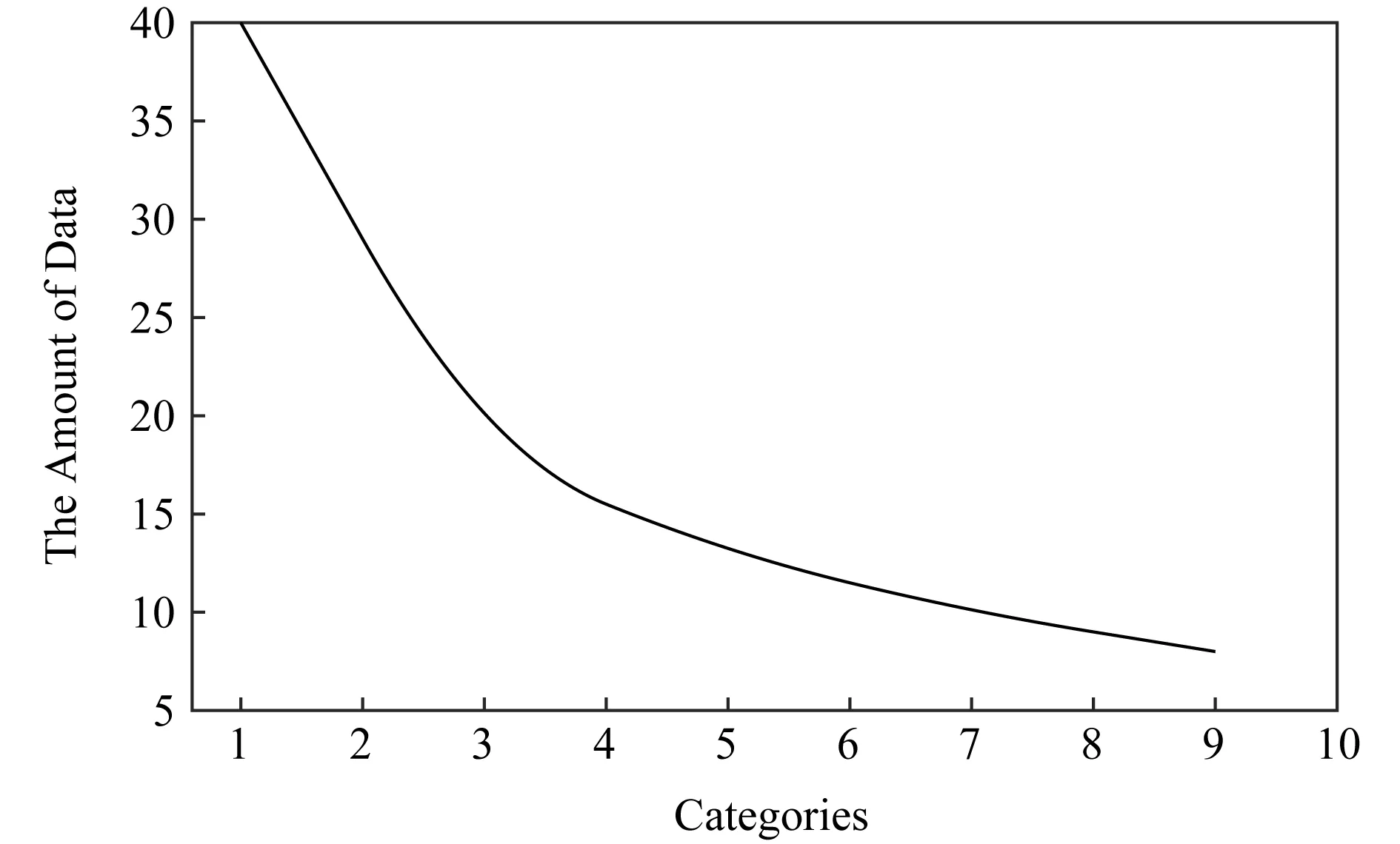
Fig. 4 The graph of long tail distribution圖4 長尾分布示意圖
(1)
其中,PS表示源域中某個類別被正確預測的概率,與參數α,γ一起用于優化分割結果.依據此函數及其計算結果,對當前的監督學習方法進行迭代優化.
2.2.2 基于類別對齊的領域自適應方法
根據文獻閱讀及實驗復現,現有的領域自適應語義分割方法選擇的自適應階段通常為目標域數據原圖或經卷積計算處理后的特征圖.對語義分割方法而言,原圖中所含冗余因子較多,如光照情況、色彩情況等.直接對原圖進行領域自適應及分割,容易導致語義不一致問題.同時,經卷積提取的特征圖中所含的圖像上下文及空間信息又較為匱乏,因而容易導致邊緣模糊或類別錯分問題.
此外,現有方法選擇的自適應判別基準通常直接采用GAN[5]的思想,即直接將整張圖像輸入至領域自適應網絡的判別器中,判斷2個輸入圖像是否來自同一數據域.然而,此判別基準可能過度關注全局信息的對齊而忽略原本相近的語義類別,導致原本正確分割的語義類別被調節至錯誤分割.
根據理論分析及驗證性實驗結果,本方法首先將源域數據和目標域數據直接輸入至2.2.1節的網絡中進行分割.對于源域數據,得到基于監督學習的精準分割結果;對于目標域數據,得到其粗分割結果.
因此,將2.2.1節中設計及優化后的分割網絡視為生成器,并固定其網絡結構及相應參數設置,將源域數據中的語義類別及其分割情況作為起始基準.結合目標域數據的分割結果,根據式(2)(3),在判別環節分別計算源域和目標域的分割結果中具體語義類別及其數據分布情況,并傳入本文設計的判別網絡中,根據類別相關對齊原理,進行類別層面的對齊調優,使得源域數據與目標域數據所含的語義類別類內相似性不斷提升,類間獨立性不斷擴大.
(2)
(3)
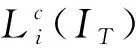
同時,針對以上基于類別相關的領域自適應方法,首先統計2個域的總體數據分布情況,然后根據生成-對抗學習思想設計損失函數,并利用其計算結果,對本文方法的對齊過程及判別器設計進行相應優化:
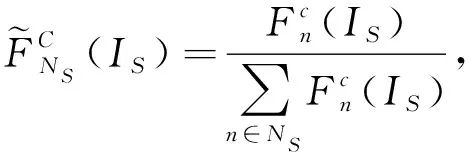
(4)
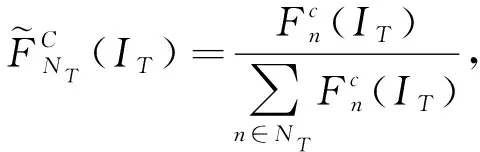
(5)
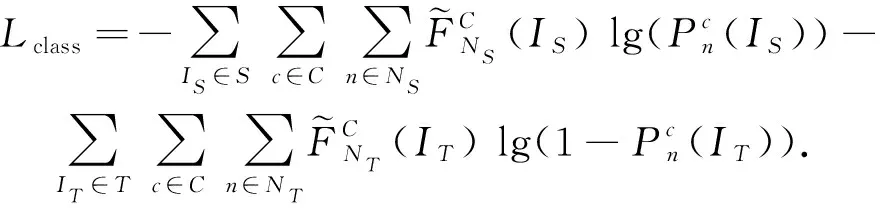
(6)
2.2.3 約束調優
以2.2.1節和2.2.2節中優化設計的模型為基礎,對本文提出的算法網絡進行整體約束優化,同時,經由此階段處理,可對2.2.2節中部分類別不一致及類別在2個域間分布不均的情況進行優化調整.
將分割結果輸入到領域自適應階段的判別器中進行判別,根據判別結果,對分割網絡進行迭代優化,直至判別器無法鑒別其接收的分割結果圖來自源域還是目標域,即類別對齊已完全實現時,則認為當前基于類別相關的算法網絡結構已經達到較為理想的結果,實現了對領域自適應語義分割方法的有效提高.
在此過程中,提出式(7)所示的損失函數,將本文方法模型視為一個基于GAN[5]的結構,依據此函數計算本算法的整體損失值,對算法網絡進行優化與改進.
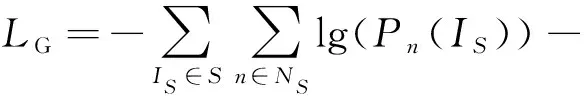
(7)
其中,IS,IT分別表示源域數據和目標域數據正確分割的情況.
3 實驗結果與分析
3.1 數據集
本文提出一種基于類別相關的領域自適應語義分割方法,并在道路交通數據集GTA5[17],SYNTHIA[18],Cityscapes[19]上進行實驗.
同時,為了證明本文方法的魯棒性,在MSCOCO[20]和VOC 2012[21]數據集上進行驗證性實驗,并統計交通場景相應數據類別的實驗結果.
GTA5[17]是基于游戲Grand Theft Auto V提取的包含有25 966張分辨率為1 914×1 052的超高清且自動帶有標注數據的賽車游戲場景圖像數據集,其場景均為對美國洛杉磯和南加州真實交通環境場景的復現,所包含的類別與Cityscapes數據集完全兼容.
SYNTHIA[18]是由計算機合成的、城市道路駕駛環境的像素級標注的數據集,包含21 494張分辨率為1 914×1 052的超高清且自動帶有標注數據的交通場景圖像,其所含類別與Cityscapes完全兼容.
Cityscapes[19]是由梅賽德斯-奔馳提供的無人駕駛環境下的圖像分割數據集,用于評估視覺算法在城區場景語義理解方面的性能.Cityscapes包含德國50個城市不同場景、不同背景、不同季節的街景,其中包含5 000張精細標注的道路交通場景圖像、20 000張粗略標注的圖像、30類標注物體以及1 525張只包含原圖、沒有標簽的測試集圖像.
MSCOCO[20]是微軟發布的,包括91個類別、328 000張圖片和2 500 000條標注信息的數據集,而其對于圖像的標注信息不僅有類別、位置信息,還有對圖像的語義文本描述.
VOC 2012[21]是包含11 530張圖片的開源數據集,其中每張圖片都有標注,標注的物體包括人、動物(如貓、狗、鳥)、交通工具(如車、船和飛機等)、家具(如椅子、桌子、沙發等)在內的20個類別.
3.2 實驗環境、網絡設計及評價指標
本文模型所使用的深度學習框架為Pytorch 1.0.0版本,相關實驗在基于Ubuntu 16.04操作系統的2塊NVIDIA TITAN XP獨立顯卡上運行.
本文實驗采用的網絡結構如圖2所示,對于本文提出的方法,在計算式(1)所示的損失值時,設定α=0.2,γ=2效果最為理想.在訓練過程中,我們將初始語義分割階段視為生成部分,在對輸入圖像進行語義分割時,分別使用VGG-16[22]和ResNet-101[23]這2種網絡模型作為基礎架構,源域與目標域共享參數,使用Leaky-ReLU[24]作為激活函數,并使用超分辨率重建[7]作為上采樣方法,使用隨機梯度下降法(stochastic gradient descent, SGD)[25]作為生成部分的優化方法,令初始學習率rg=2.5×10-4,動量參數βg=0.9;對于判別部分中的判別網絡,使用4層通道數分別為 {64,128,256,1}的卷積層,使用Leaky-ReLU[24]為激活函數,令初始學習率rd=1.0× 10-6, 令1階矩估計、2階矩估計的指數衰減率分別為β1=0.9,β2=0.99;在計算本文方法的整體損失值時,分別將基于監督學習的損失值、基于類別相關的判別損失值及基于GAN[5]模型結構的損失值對應權重設置為λ1,λ2,λ3,對應權重值分別為0.2,1.0,0.5.
本文采用的主要評價指標為如式(8)(9)所示的針對每個類別的像素分割精準度(pixel accurancy, PA)和針對圖像整體的平均交并比(mean inter-section over union,mIoU).
像素分割精度表示的是該類別標記正確的像素數目占總像素數目的比例:
(8)
其中,pii表示被正確分類的像素數目,pij表示實際類別為i而被預測為類別j的像素點的數目.
平均交并比表示的是預測分割區域(predicted segmentation)和真實分割區域間交集與并集的比值:
(9)
其中,k+1表示數據集中全部類別數目.
3.3 實驗結果
根據圖2所示的網絡結構,在3.1節中的數據集上進行實驗,得到統計結果.
3.3.1 以GTA5數據集為源域的對比實驗
設定GTA5[17]為源域數據集,設定Cityscapes[19]為無標注目標域數據集.選擇VGG-16網絡作為本算法的基礎神經網絡結構,將本方法與現有的其他領域自適應語義分割方法[26-33]進行表1、表2所示的對比分析.
表1所示,本文方法與近期一些實現方法相比,分割精準度及平均交并比均有所提升.特別是交通標志或交通燈等占有數據量較小,易與背景類混淆,因而難以被正確地分割語義類別,利用本文提出的類別相關方法,其分割精準度得到有效提升.先前方法中,路燈類的平均分割精準度為19.4%,最高精準度[31]為30.3%,本文方法可以將其提高至33.4%;路標類在先前方法中的平均分割精準度為9.6%,最高精準度[28]為18.3%,而本文提出的方法將其提高至19.7%;同時,本文方法將車行道類別的分割精準度提高至87.3%,將植物草木類的分割精準度提高至83.2%.近年來,使用ResNet[23]的算法均取得較為理想的效果,本文采用其作為基礎的神經網絡模型,繼續在GTA5[17]與Cityscapes[19]數據集上訓練本文提出的領域自適應語義分割方法,并與直接在目標域上使用ResNet結構的語義分割方法和使用VGG-16[22]作為基礎模型的本文方法進行對比實驗.
表2展示出3個方法在2個數據集上的實驗結果,其中,RES表示單獨使用ResNet對數據集進行特征提取與分割的結果,Ours-V表示使用VGG-16作為本文骨架網絡得到的實驗結果,Ours-R表示使用ResNet作為本文骨架網絡得到的實驗結果.相比其他2個方法,使用基于ResNet-101[23]結構的本文方法,在具體語義類別及整體圖像的分割精準度上均有提升.例如,將交通標志類的平均分割精準度從20%提升至23.4%,將路燈類的平均分割精準度從32%提升至35.4%,繼而將圖像整體的分割平均交并比提升至43.7%.
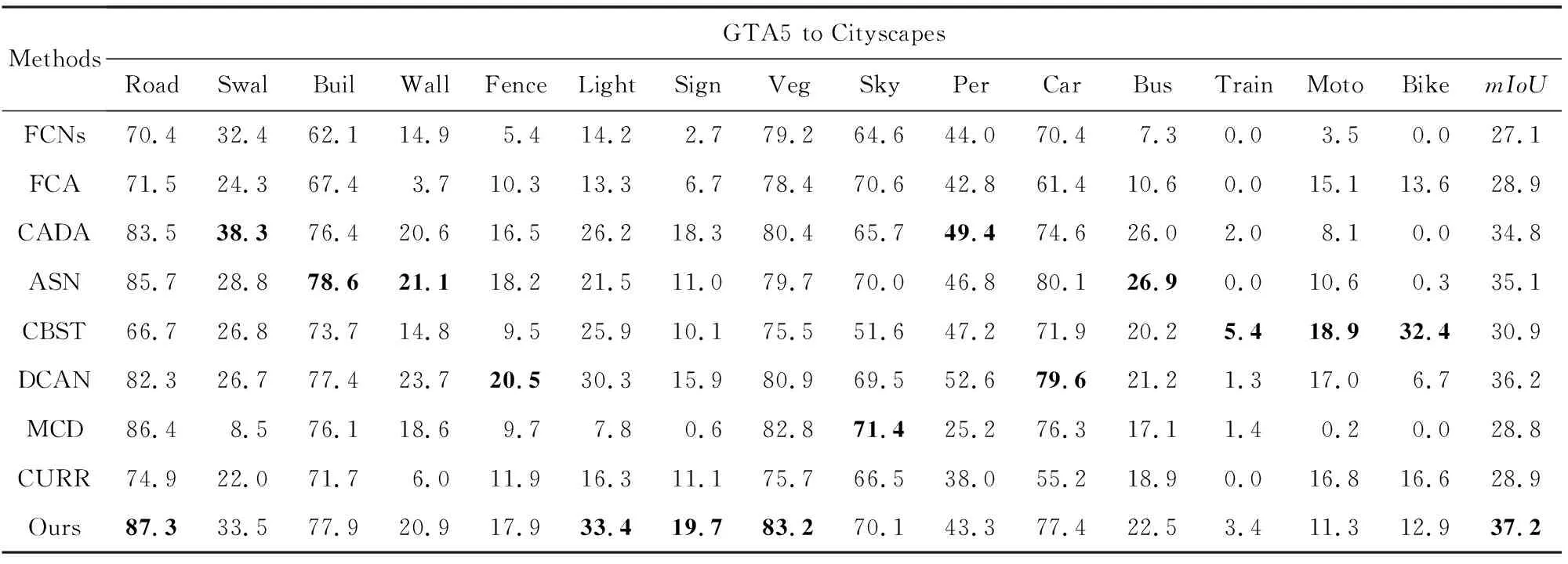
Table 1 Comparison of Results with GTA5 as Source and Cityscapes as Target Domain表1 GTA5為源域、Cityscapes為目標域的實驗結果對比
Notes: The best results are in bold; Swal stands for Sidewalk, Buil stands for Building, Veg stands for Vegetation, Per stands for Person, and Moto stands for Motorbike.

Table 2 Comparison of Experimental Results with Baseline on ResNet and VGG-16表2 分別以ResNet和VGG-16為Baseline的實驗對比結果
Notes: Swal stands for Sidewalk, Buil stands for Building, Veg stands for Vegetation, Per stands for Person, and Moto stands for Motorbike.
圖5展示了本文提出的方法在以GTA5[17]為源域、Cityscapes[19]為目標域的分割結果.其中圖5(b)所示為直接對無標注數據集進行分割的結果,其中如車行道、汽車等語義類別已被識別,但與之相比,圖5(c)中展示的結果對于圖像中每個類別的分割邊緣,其中路標、信號燈以及人行道等語義類別的分割精準度均有顯著提升,且分割結果與圖5(d)所示的數據集給出的真實分割區域較為接近.
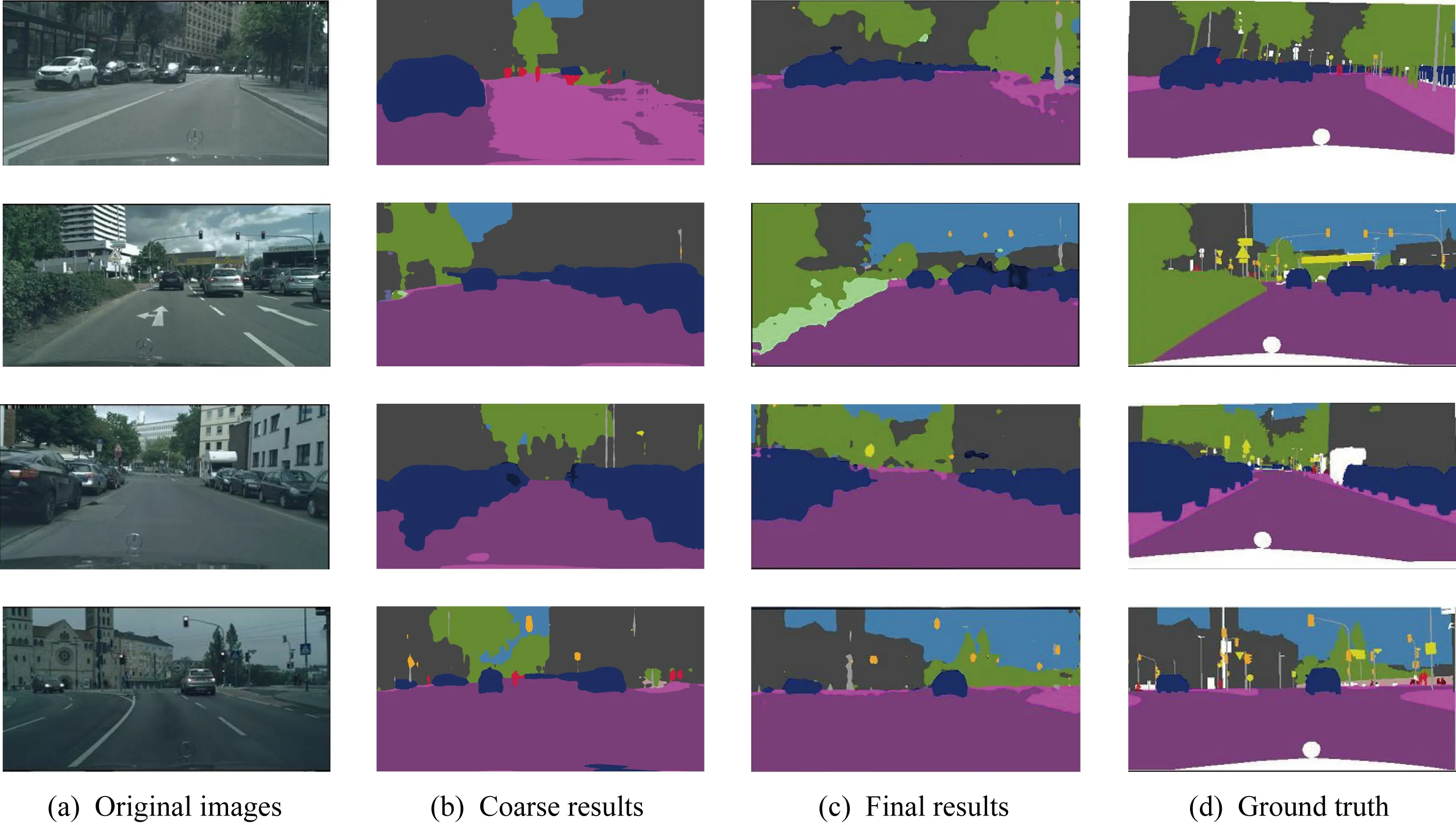
Fig. 5 An example of semantic segmentation results with GTA5 as source domain and Cityscapes as target domain圖5 以GTA5為源域、Cityscapes為目標域分割示例
3.3.2 以SYNTHIA數據集為源域的對比實驗
基于先前的模型及參數設置,以虛擬合成數據集SYNTHIA[18]為源域、以Cityscapes[19]數據集為目標域進行實驗.
表3所示,圖像整體的分割平均交并比被提升至43.6%,圖中汽車、車行道、人行道等語義類別的分割精準度也得到顯著提升.其中,車行道類的平均分割精準度在先前方法中的均值為66%,最高值[31]為79.9%,而本文方法可將其提升至84.4%;汽車類的分割精準度在先前方法中的均值為60.4%,最高值[29]為71.1%,本文方法可將其提升至73.6%.對于信號燈、路標以及公共汽車這3個語義類別,現有方法的分割精準度均值為4.9%,8.2%,12.4%,而本文方法可將其提升至12.6%,14.3%,21.4%.
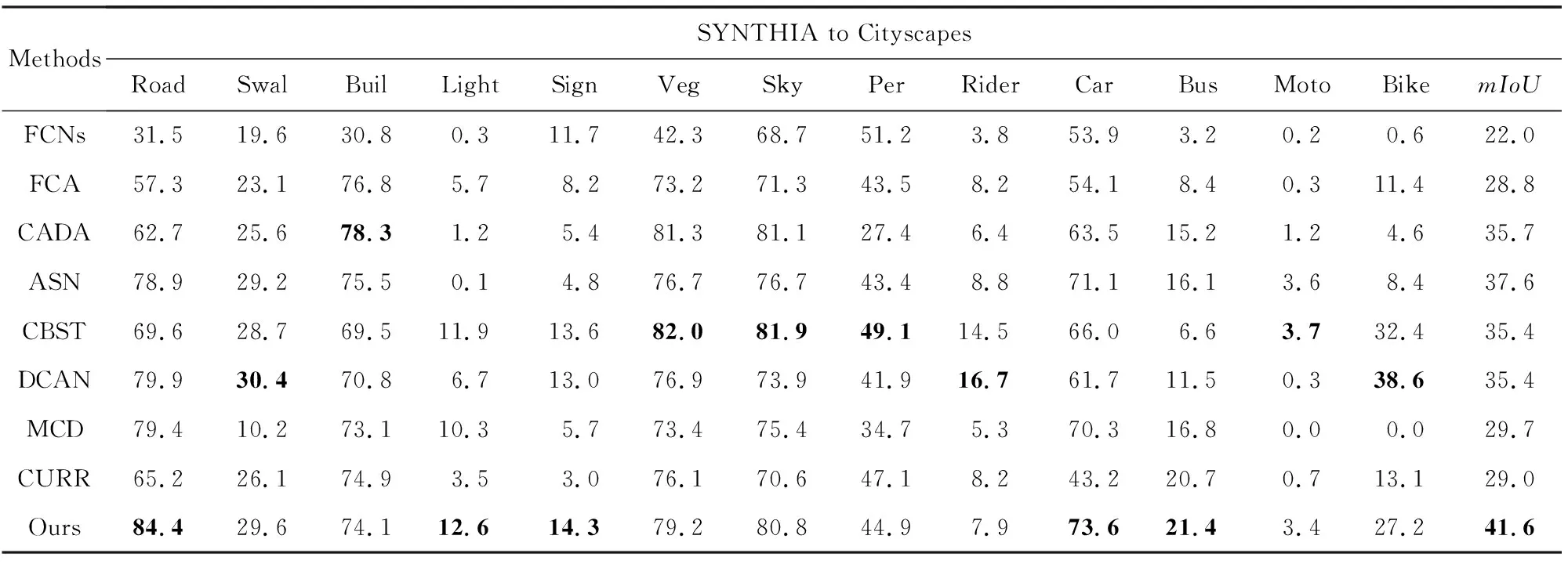
Table 3 Comparison of Experimental Results with SYNTHIA as Source Domain and Cityscapes as Target Domain表3 以SYNTHIA數據集為源域、Cityscapes數據集為目標域的方法實驗結果對比
Notes: The best results are in bold; Swal stands for Sidewalk, Buil stands for Building, Veg stands for Vegetation, Per stands for Person, and Moto stands for Motorbike.
此外,基于不同源域數據集上的實驗結果也表明了本文所提方法的正確性、有效性和泛化性.
圖6展示了本文提出方法在以SYNTHIA[18]為源域、Cityscape[19]為目標域的分割結果.圖6(b)所示為未經自適應優化的結果,觀察可見,圖像中汽車、道路等常見語義類別已經可以被提取,但由于源域SYNTHIA是計算機合成的數據集,與目標域Cityscapes的真實交通圖像場景略有不同,因而目標域的分割結果中存在分割邊緣模糊和類別錯分等現象.圖6(c)所示為本文方法的實驗結果,經過本文的方法處理,車輛、道路、交通信號燈以及行人等類別的分割結果與圖6(d)中所示的真實分割標注已經非常接近,而路障、建筑以及人行道等類別也被有效識別及分割.

Fig. 6 An example of semantic segmentation results with SYNTHIA as source domain and Cityscapes as target domain圖6 以SYNTHIA為源域、Cityscapes為目標域分割示例
3.3.3 以MSCOCO數據集為源域的對比實驗
為了驗證本文方法的有效性和泛化性,設定MSCOCO[20]數據集中帶有精準語義標注的圖像數據為源域數據集,VOC 2012[21]數據集中針對分割任務的圖片為目標域數據集,與文獻[26-29]中的方法進行對比與驗證實驗.
表4所示,對于圖像整體,以及圖像中汽車、摩托車和行人等常見的交通語義類別,本文方法依然擁有較高的分割精準度.其中,汽車類在先前方法中的分割精準度均值約為53.8%,本文方法可將其提升至62.6%;摩托車類在先前方法中的分割精準度均值為42%,本文方法將其提升為43.4%;而先前方法中圖像分割的平均交并比值最高[29]為45.9%,本文提出的方法可達48.6%.
3.4 消融實驗
在3.3節中,經過3組與先前方法的對比實驗,已驗證本文方法的有效性和泛化性;為了進一步驗證本文方法中每個步驟的可行性,本節對本文方法中具體的優化階段進行消融實驗,驗證每個處理階段的正確性和必要性.
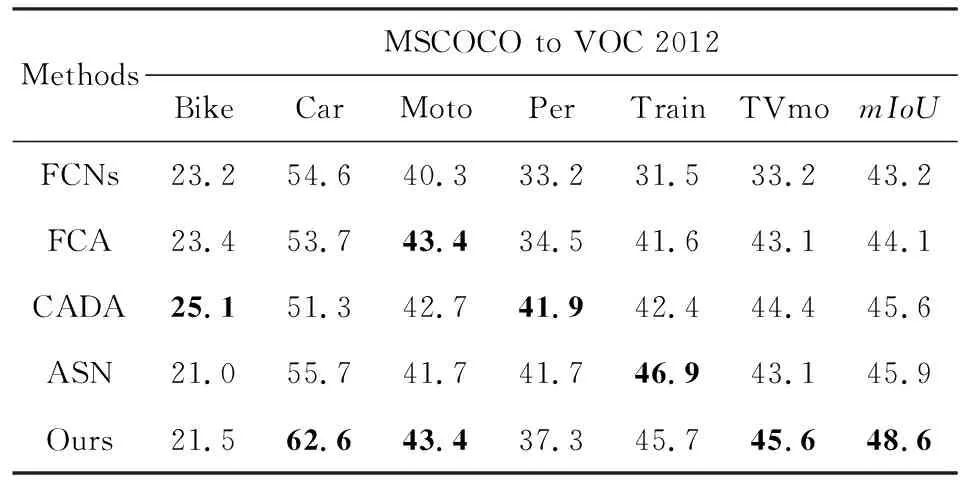
Table 4 Comparison of Results with MSCOCO as Source Domain and VOC 2012 as Target Domain
Notes: The best results are in bold; Moto stands for Motorbike, Per stands for Person, and TVmo stands for TV-monitor.
3.4.1 針對源域數據的消融實驗結果
如表5所示,Ours-BC表示直接使用骨架網絡的本文基礎方法在源域數據集上得到的實驗結果;Ours-PS表示單獨改進本文上采樣方法得到的實驗結果;Ours-FL表示單獨改進本文監督學習方法的損失函數得到的實驗結果;Ours表示融合2個優化方法在源域數據集上得到的實驗結果.針對2.2.1節中提出的基于監督學習的源域數據分割優化方法,經本文消融實驗對比,在使用不同的基礎網絡的前提下,超分辨率重建和改進focal loss損失均可提升原分割結果約2%,本文方法中將其結合使用,可在源域數據集GTA5中提高整體分割精準度約4%.同時,在基礎網絡中,使用ResNet的分割結果優于使用VGG-16得到的分割結果約2%.

Table 5 Ablation Study Results of Optimization Method with GTA5 as Source Domain
Notes: “√” indicates that the method described in the corresponding column is used for the experiment described in the current row.
3.4.2 針對目標域數據的消融實驗結果
針對本文2.2節中提出的優化源域分割方法和使用類別相關信息進行數據對齊,在采用2種基礎網絡的前提下,消融實驗對比結果如表6所示.在表6中,Ours-BC表示直接使用骨架網絡的本文基礎方法在目標域數據集上得到的實驗結果;Ours-S表示單獨對源域訓練部分進行優化在目標域上得到的實驗結果;Ours-C表示單獨利用類別相關信息,在改進目標域跨域方法時在目標域上得到的實驗結果;Ours表示使用本文完整方法得到的實驗結果.在進行領域自適應的過程中經過優化源域分割方法,可提升目標域數據集Cityscapes的分割精準度約3%,使用類別信息可提升分割精準度約3%,本文在2.2.1節和2.2.2節中綜合考慮并實現2階段的優化方法,將目標域的整體分割精準度提升約6%.
綜上,將本文提出的方法,在3個不同類型的源域數據集、2個不同類型的目標域數據集上進行驗證實驗.結果表明:分割的精準度在不同的語義類別上均有著較高的提升,證明了本文方法的有效性,同時,也證明了基于類別相關的領域自適應語義分割方法擁有較強的泛化性,可以有效應用于不同類型的數據集和圖像場景中.

Table 6 Results of Ablation Study with GTA5 as Source Domain and Cityscapes as Target Domain
Notes: “√” indicates that the method described in the corresponding column is used for the experiment described in the current row.
此外,經過對源域數據集和目標域數據集的消融實驗驗證,本文方法中針對分割過程中每個階段提出的優化方法均可有效提升實驗結果,并且,經過本文方法的整體約束優化,分割結果達到更高的精準度.
4 總結與展望
本文提出了一種基于類別相關的領域自適應語義分割方法,用以解決數據集中類別分布不均及無標注數據集的語義分割問題.實驗結果表明:本文方法通過優化上采樣方法、關注小樣本數據類別、調整領域自適應階段、尋找結構化信息以及在判別階段中采用基于類別相關的方法,可以有效提升源域數據集和目標域數據集中圖像的語義分割精準度,并且可以將領域自適應的方法有效應用到更大的范圍中.然而,本文提出的方法在針對行人等具有運動性且容易出現遮擋等問題的類別、分割精準度及邊緣清晰度等結果仍有一定提升空間,未來考慮引入行人重識別中的一些特征、屬性提取方法,以及根據已有數據集得到先驗約束對分割結果再次約束優化等方法,對本文提出的方法進行更深層次的優化.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
