基于深度神經網絡burst特征分析的網站指紋攻擊方法
2020-04-21 07:57:00馬陳城杜學繪曹利峰
計算機研究與發展 2020年4期
關鍵詞:模型
馬陳城 杜學繪 曹利峰 吳 蓓
1(戰略支援部隊信息工程大學 鄭州 450001) 2(河南省信息安全重點實驗室(戰略支援部隊信息工程大學) 鄭州 450001) 3(61497部隊 北京 100000)
對于黨政軍網絡及大型企業網絡等敏感網絡,網絡監管是維護網絡良好秩序的重要手段.近年來發展迅速的流量加密和匿名網絡技術,一方面保護了網絡的敏感數據和用戶隱私,另一方面也給網絡監管帶來了巨大的困難和挑戰.SSH和VPN等技術通過加密數據包載荷,可繞過基于載荷字段的流量分析和檢測,但通過分析數據包的長度分布等規律,加密流量仍能被有效分析[1-3].但隨后的Tor(the onion router)匿名通信技術進一步隱匿了數據包長度信息,給流量分析帶來了更大的困難.由于匿名通信系統具有節點發現難、服務定位難、用戶監控難、通信關系確認難等特點,利用匿名通信系統隱藏真實身份從事惡意甚至網絡犯罪活動的現象層出不窮[4],如利用暗網進行地下交易[5]及國內不法分子翻越中國墻訪問不健康網站和發表不正當言論等行為.
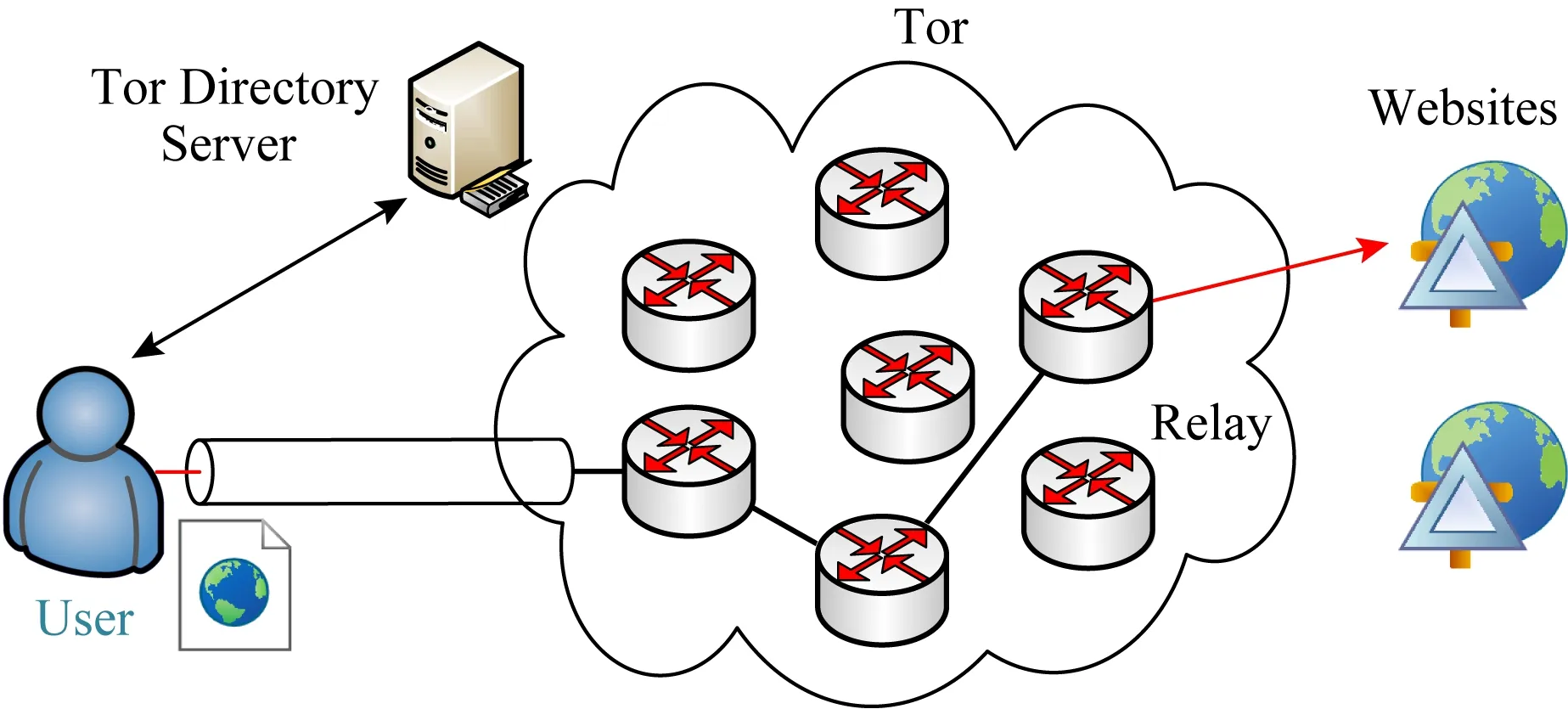
Fig. 1 Schematic diagram of the Tor network圖1 Tor網絡原理示意圖
Tor網絡[6]是匿名網絡的代表之作.目前Tor網絡在全球擁有6 000個志愿者節點,日活躍用戶達到了200萬[7].Tor基于傳輸層安全協議(transport layer security, TLS)加密數據包載荷以及隨機鏈路技術來保護用戶端的數據隱私.其原理如圖1所示,用戶本地的客戶端與Tor目錄服務器進行協商分配鏈路節點,由于構成通信鏈路(circuit)的3個Tor節點relay的隨機性和周期更新性,基于鏈路追溯數據包是困難的.待傳輸數據在客戶端相應地被依次實施3道傳輸層安全協議(TLS)加密,每經過一個Tor節點,最外面一層的加密就被相應地解開,因此即使控制了其中一個Tor節點,也無法讀取用戶的數據包內容.Tor基于一個或多個512 B的數據單元(cell)實現數據傳輸.固定長度的cell傳輸模式使得過去基于數據包長度的分析手段失去了攻擊和分析效果.為了對基于Tor匿名網絡的通信和訪問行為進行有效監管,針對Tor匿名通信系統的攻擊和分析技術研究發展迅速,如流水印技術[8]、流量關聯分析技術[9]等.其中,網站指紋(website finger-printing, WF)攻擊技術發展尤為迅速[10-11].相比其他匿名通信攻擊技術,WF攻擊技術具有易部署、低成本的特點.面向加密或匿名傳輸的WF攻擊技術基于內網用戶訪問網站產生的流量數據對模型進行訓練,模型對新產生的網頁流進行分類,分析該網頁流是否正在利用加密通道或匿名通信網絡秘密訪問敏感網站,如非法網站或可能導致內網失泄密的網站,及以暗網為代表的隱藏網站等[12],實現對利用匿名網絡訪問非法網站行為的攻擊與分析.
WF攻擊與分析本質上是一個分類問題[11],機器學習在網絡空間安全中的廣泛應用[13-14]促進了WF技術的快速發展,近幾年神經網絡方法更是隱隱成為研究WF技術的主要利器[15].基于神經網絡的WF攻擊技術通過數據驅動構建模型,使模型自動學習網站指紋特征.相比傳統方法[16-17],神經網絡方法能夠學習到人工經驗難以定義的網站指紋特性,實現更好的攻擊效果[11].
但目前主流的基于神經網絡的WF攻擊與分析方法仍存在不足之處.WF攻擊技術研究通常基于封閉世界場景(close-world, CW)和開放世界場景(open-world, OW)2個假設進行分析.CW場景假設用戶僅訪問網絡管理員定義的被監控的敏感網站,WF模型需要識別出用戶當前訪問被監控網站的具體站點域名,是一個n分類問題(n為被監控網站的數量);而OW場景假設用戶訪問任意網站,WF模型需要識別用戶是否正在訪問被監控網站集的站點,即識別網頁流是否屬于被監控網站集,是一個二分類問題.在CW和OW場景下,當前基于神經網絡的WF研究都僅直接利用經典的神經網絡架構,如VGG16[18],ResNet[19]等,沒有根據WF攻擊技術的特點對神經網絡模型結構進行設計和改進,存在網絡過于復雜和分析模塊冗余導致特征提取和分析不徹底、模型運行緩慢等問題[20],因此神經網絡在WF攻擊技術上的適應性還有待提高,模型性能還有很大的提升空間.另外,神經網絡方法在OW場景下通常僅基于閾值判別法分析神經網絡輸出的指紋向量以實現二分類決策[21].由于神經網絡方法輸出的指紋向量的高度準確性,閾值法雖然簡單但也表現出了較好的分類性能[22].但是閾值法沒有分析被監控網站集和非監控網站集的指紋向量在各維度的相關性,也沒有學習被監控網站集和非監控網站集的二類別特性.在被監控集網站為天然自成一類的情況下(如被監控集的站點均為Tor隱藏網站),閾值法的分類性能表現出較大的不足.
針對上述研究存在的問題,本文通過對Tor匿名網絡流量序列的特征表現進行研究后,設計了基于深度分析burst特征的網站指紋攻擊模型(deep burst-analysis based website fingerprinting attack, DBF).強加密性和隱匿性的Tor網絡流量只有少數特征可分析出有用信息,突發流量特征(burst)是其中的一個重要的上層特征,它反映了訪問網站時數據交互過程中的一段持續性的數據傳輸行為.為對Tor匿名網絡流量的burst特征進行有效發現與分析,本文分別針對CW與OW場景進行了相關研究.在CW場景中,設計了基于burst特征提取模塊和burst特征抽象學習及深度分析模塊的DBF-CW(DBF in Close-World)模型.首先,burst特征提取模塊通過由多個卷積層平行拼接而成的淺層卷積神經網絡(convolution neural network, CNN)對不同長度的burst特征進行提取;然后,burst特征抽象學習及深度分析模塊對VGG16架構的基本區塊(由2層卷積層及一層池化層組成)和含殘差連接的密集神經網絡(dense neural network, DNN)進行融合,對burst特征進行深度的抽象學習,由此提取并輸出網頁流的指紋向量,并通過對指紋向量做反向最大值函數計算實現對被監控網頁流的網站標記識別;在OW場景中,基于DBF-CW輸出的指紋向量結果,進一步設計了基于隨機森林算法的二分類模型DBF-OW(DBF in Open-World),通過對指紋向量進行向量維度相關性分析,模型可以學習二分類特性,實現了比閾值法更好的分類效果.
本文的主要貢獻有3個方面:
1) 在封閉世界場景中設計了一個基于CNN和DNN的WF攻擊模型DBF-CW,通過對淺層卷積網絡、VGG16基本區塊和含殘差連接的密集神經網絡進行連接與結合,形成多層深度神經網絡結構,對Tor流量序列的burst特征進行提取和深度分析,提高了burst特征發現的成功率和準確率,模型對Tor流量的分析和分類性能得到很大的提高;
2) 在開放世界場景中設計了一個基于隨機森林算法的WF模型DBF-OW,改進了基于閾值法的決策思路,通過分析DBF-CW輸出的指紋向量間各維度相關性與被監控網站集和非監控集二類別的映射規律,實現了更有效的二分類決策;
3) 使用了多個數據集對方法進行評估,從實踐的角度驗證了本文所提出的DBF模型在緩解概念漂移、繞過網站指紋攻擊防御機制、識別Tor網絡隱藏網站、小樣本訓練模型和運行速度等方面優異的性能表現.
1 相關工作
1.1 針對匿名通信的攻擊與分析技術對比
從對流量的干擾程度及流量的采集點2個維度進行分析[23],匿名通信攻擊技術主要可分為被動端到端流量分析[9]、主動端到端流量分析[8,24-25]、被動單端流量分析[1,12,26]和主動單端流量分析[27-29],它們的區別如表1所示.端到端分析在實際網絡環境中難以實施完備的攻擊,因為需要在被監控站點近端進行系統部署,而站點數量往往是非常龐大的.主動單端攻擊通過向用戶端注入惡意代碼,通過分析用戶機器物理特征(如內存)與訪問不同網站時的映射關系來實現攻擊,操作性要求較高.相比之下,以網站指紋攻擊為代表的被動單端流量分析的實現成本最低,通過監聽并分析用戶近端流量即可建模,是當前實現全面的敏感站點檢測的最可行方法.

Table 1 Comparison of Four Anonymous Network Communication Attack Technologies
1.2 網站指紋攻擊技術發展現狀
網站指紋(WF)攻擊是一個本地的、被動地獲取用戶進出流量、不主動干預流量狀態的一種流量竊聽攻擊.如圖2所示,WF攻擊的發起者可以是用戶與Tor入口節點之間鏈路上的本地管理員(local administrator)、服務提供商(Internet server provider, ISP)、自治系統(auto-nomous system, AS)或者控制了Tor入口節點的攻擊者.網絡管理員首先定義需要監控的敏感網站集,通過前期獲取用戶端近端流量樣本和網站標記形成訓練數據,完成訓練的模型部署在用戶端近端的鏈路上.基于被動監聽用戶的進出流量判斷用戶當前是否正在訪問被監控網站,以達到網絡監管的目的.
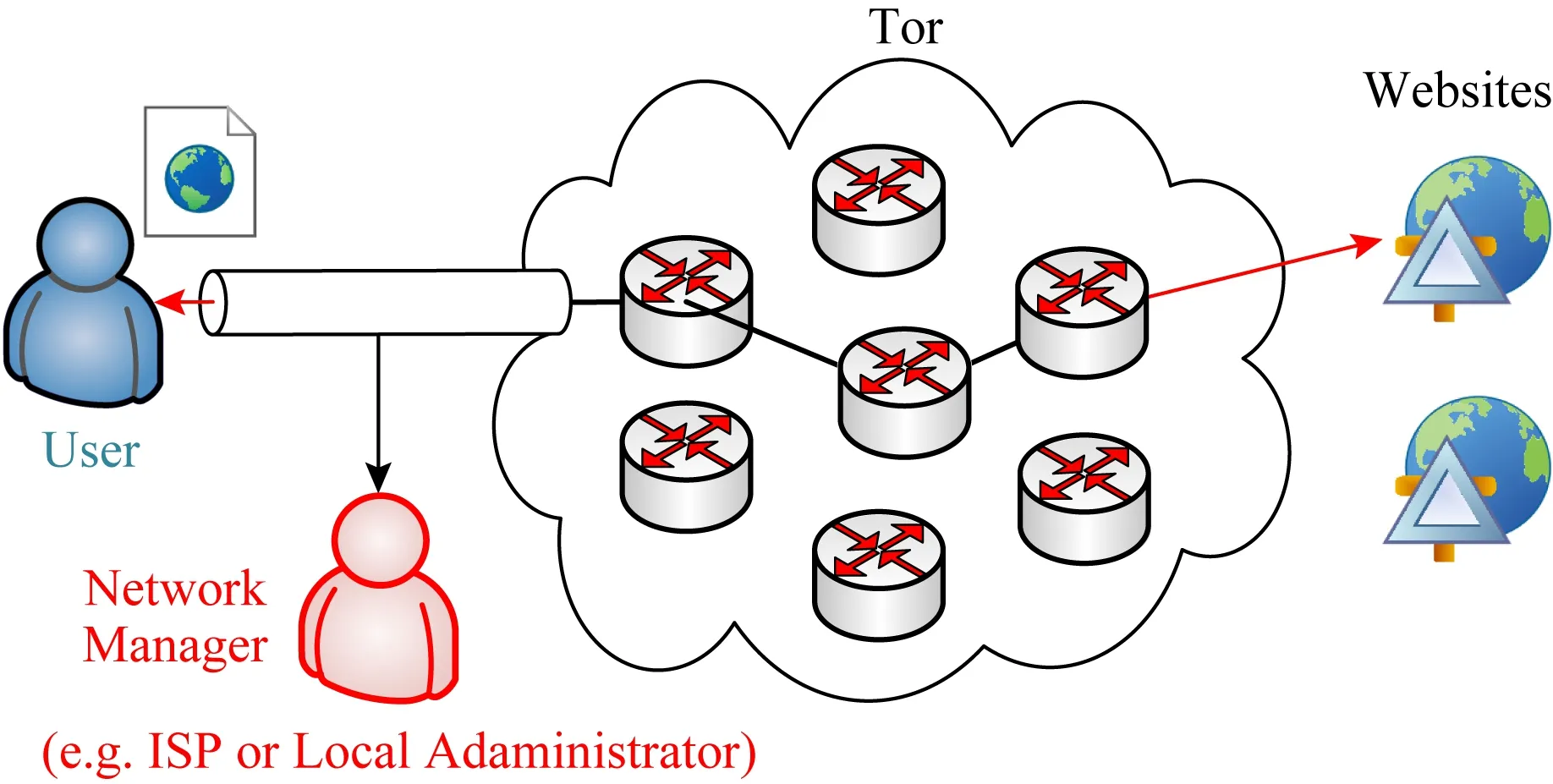
Fig. 2 Schematic diagram of WF attack圖2 WF攻擊原理示意圖
WF攻擊通常基于3種模型假設:
1) 用戶訪問行為單一.假設用戶在同一時間只瀏覽一個網頁,攻擊者可以簡單獲取到網頁流的開始和結束.
2) 無噪聲流量.假設網頁流無背景流量,不需要處理噪聲流量.
3) 特殊網頁可代表網站.假設用戶訪問某個具體網站時必將訪問某個特殊網頁(如網站首頁),因此網站指紋分析可轉化為網頁指紋分析.
WF攻擊技術由于初期所基于的安全假設過于理想化而沒有被廣泛認可[30],近年來有許多研究圍繞放松其基于的安全假設展開[31].Gu等人[1]在2015年在用戶同時訪問2個網站的復雜情況下成功實施了WF攻擊;Wang等人[32]在2016年提出了模型更新算法以應對數據概念漂移問題,提出了多網頁流分割算法以應對用戶同時瀏覽多個網頁的情況,還提出了處理流量噪聲的手段等;Cui等人[33]在2019年提出了2個針對連續和重合網頁流的分割算法;針對網站指紋攻擊可轉換為網頁指紋攻擊的理想假設,Cai等人[34]在2012年基于隱Markov鏈對網站鏈接的點擊關系進行分析,基于多網頁訓練形成網站指紋;Zhuo等人[35]在2017年提出了一種面向分析網站鏈接的隱Markov鏈模型.
上述對模型基礎性安全假設進行分析和放松的研究工作,為在理想條件下建模的WF攻擊技術提供了數據清洗等基礎性的支撐工作,大大提高了WF模型應用到真實網絡中的可行性.這些基礎性的工作同樣適用于本文模型,因此本文不涉及對安全假設的研究,旨在在理想條件下,提高WF模型在2個場景下對Tor匿名通信的攻擊和分析能力,從提升分類性能的角度提高WF攻擊技術應用到實際的可行性.
依據數據封裝協議的不同,WF攻擊主要分為3類[36].在早期網站還使用HTTP1.0進行數據傳輸時,攻擊者通過分析資源(如圖片、文字等)長度可實現WF攻擊[37-38].而后HTTP1.1,VPN和SSH通過加密和混淆的方式使攻擊者無法獲取網站資源長度特征,基于數據包長度的分析可構建網站的指紋信息[26,39].Tor匿名網絡通過填充和固定傳輸單元的大小進一步隱匿了長度特征,針對Tor網絡的網站指紋攻擊在當前仍是一個難點.
作為WF模型的信息源,流量特征的提取是決定模型性能的關鍵一環.Tor流量可以在數據包、TLS和cell層次上進行提取,實驗證明在cell層次上提取特征最有利于對Tor流量的分析[40].由于只有方向特征和數量特征可利用,對cell的分析通常基于cell方向序列的形式.方向序列中的burst特征被WF研究廣泛使用[16,36],是實現WF攻擊的一個重要的上層特征.
當前主流的面向Tor網絡的WF模型主要分為基于人工設計指紋的一般機器學習方法和指紋(半)自動學習的神經網絡方法.如表2所示,序列號1~7為一般機器學習方法,其基于流量特征直接形成或者通過形態變換形成網站指紋;而序列號8~14為神經網絡方法,它通過深度挖掘流量特征的方式自動學習形成網站指紋.表2還對各研究所采用的基礎模型算法、所利用的流量基礎特征的層次、類型和表現形式進行了總結和描述.
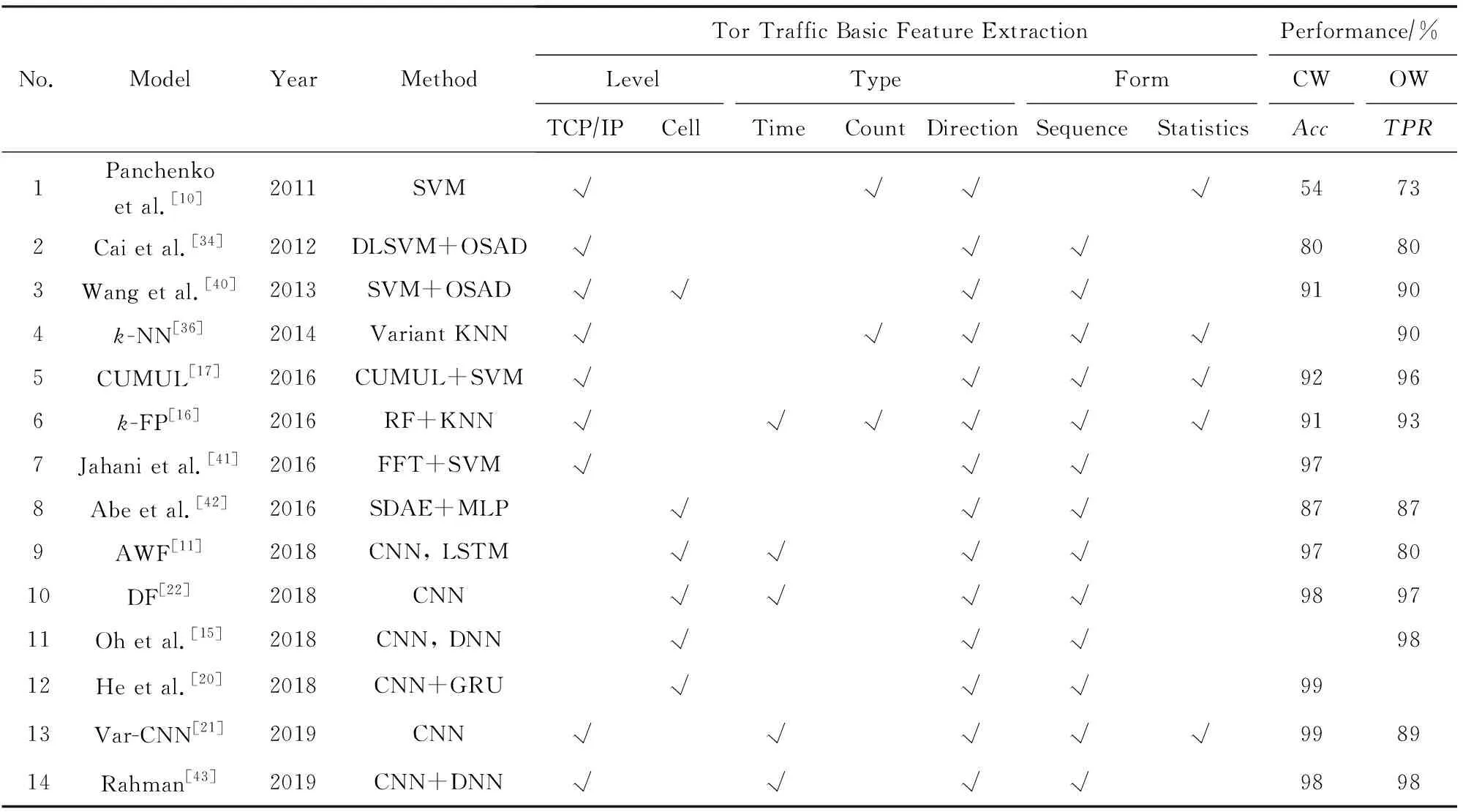
Table 2 Comparison of Website Fingerprint Attack Methods for Tor
Notes:Accmeans accuracy;TPRmeans true positive rate; “√” means the item is selected.
對于一般機器學習方法,由于模型分析能力有限,指紋向量通常基于人工設計的規則進行提取,模型算法只進行指紋向量的距離對比、相似性計算等,因此模型所分析的特征一般需要包含豐富的表層信息,如通過增加特征維度、擴大特征的涵蓋范圍(如通過統計計算的方式)等,特征提取一般較為復雜.Wang等人[36]在2014年通過對傳統KNN算法進行加權改進,并基于改進后的k-NN算法分析高維特征集實施WF攻擊,在封閉世界環境下取得了91%的準確率.Panchenko等人[17]在2016年對網頁流實例使用累加和(cumulative representation, CUMUL)的方式表達序列特征,并使用基于RBF(radial basis function)核函數的改進SVM進行分類,得到較好的效果.Hayes等人[16]在2016年使用隨機森林(random forest, RF)模型分析網頁流的包計數、包間隔等共150維統計特征,并基于各葉子節點的標識形成網頁指紋,通過傳統KNN算法和漢明距離(Hamming distance)實現分類.然而,一般機器學習方法基于人工設計的指紋是不穩健的,匿名網絡通過改進協議即可破壞這些指紋的提取[11].
對于指紋(半)自動學習的神經網絡方法,由于模型具備強大的分析能力,指紋向量通常由模型自行分析得到,因此模型所分析的特征一般為不加處理的原始流量特征(如網頁流的包方向序列、時間序列等),較少通過統計的方式對原始數據進行加工.Abe等人[42]在2016年提出了一種基于自編碼神經網絡和多層感知機分析Tor cell方向序列的WF方法,在開放世界場景中的準確度要高于此前的一般機器學習方法.Rimmer等人[11]在2018年提出了利用深度學習的思想分析Tor cell方向序列并自動提取流量特征,以實現網站指紋建模.他們采用了SDAE(stacked denoising autoencoder),CNN和LSTM(long short term memory)這3種神經網絡進行模型構建.實驗結果表明,基于神經網絡的網站指紋攻擊方法在性能上比當前人工提取指紋的傳統方法要好.Sirinam等人[22]在2018年基于CNN的VGG框架[18]分析Tor網頁流cell序列特征,在封閉世界情景下達到98%的準確率,并成功攻破了WTD-PAD防御機制[44].Oh等人[15]基于CNN分析cell序列和人工提取的burst長度特征實施WF攻擊,在封閉世界情景得到了較高的準確率.He等人[20]利用殘差網絡思想分析cell序列特征和包時間戳特征,基于CNN的ResNets架構[19]和GRU網絡實施WF攻擊,在封閉世界場景下得到了99%的準確率.Bhat等人[21]在2019年同樣基于ResNets架構訓練WF模型,并且還引入了時間類特征,通過集成的方法綜合分析了方向和時間類特征,也取得了99%的分類準確率.Rahman等人[43]在2019年通過實驗證明了在一般機器學習算法中無法被有效使用的時間特征,在神經網絡中能被有效挖掘出有用的信息.以上方法從特征設計和提取的角度對WF攻擊技術進行改進,或利用已有的神經網絡架構直接應用到WF攻擊上,但都沒有根據Tor流量和WF攻擊技術的特點對神經網絡結構進行改進,網絡結構存在指紋分析不徹底或結構冗余的問題,前者導致分類準確率較低,后者導致模型運行速度緩慢.
burst特征是方向(direction)特征的序列形式表現,是流量中的一種上層特征表現,在人工設計指紋的一般機器學習方法被廣泛使用[16,36],但通過人工提取的burst特征只有長度信息,而位置抽象信息及潛藏的深度規律難以被人工設計的規則所提取和分析.同時,當前的神經網絡方法[11,20,22]大多僅利用深度學習泛性地挖掘原始流量特征的規律,而沒有從流量本身潛藏的特性分析出發設計模型,因此目前還沒有針對burst特征進行分析的神經網絡方法.對于數據加密、鏈路隨機、傳輸時延不穩定、隱匿了數據傳輸單元長度特征的Tor流量,burst特征無疑是一個非常重要的上層特征表現,而本文是該領域首個針對Tor流量burst特征進行分析的神經網絡方法.
由于WF攻擊的蓬勃發展,相應的防御手段也應運而生[45],但大多數防御技術的實用性較差[46-47],或僅針對某一個具體的WF攻擊模型進行防御,應用范圍不廣[48].BuFLO家族(BuFLO[49],CS-BuFLO[50],Tamaraw[51])對WF進行了有效的阻截,但是消耗過多的網絡帶寬和增加較多的傳輸延遲.近年來基于神經網絡方法提出了對抗樣本模型,基于誤導攻擊者將該網頁流誤導分類至另一個網站的思想實施防御[52-53],但是該方法的假設前提過強,實際可操作性較低.目前相對可用的WF防御機制是WTF-PAD[54]和Walkie-Talkie(W-T)[55],但本文在實驗部分會驗證模型可以有效攻破這2個防御機制.
2 基于burst深度分析的網站指紋攻擊模型
基于當前神經網絡方法與面向Tor匿名網絡的WF攻擊技術結合不足的問題,根據burst特征在基于Tor網絡的網站訪問流量中具有強顯性的特點,設計了基于深度分析burst特征的網站指紋攻擊模型(DBF).本節首先對模型的重要元素進行定義,然后給出模型的整體框架,最后對DBF模型的2個重要部分DBF-CW和DBF-OW進行闡述和分析.
2.1 模型基本元素的定義
在對本文提出的DBF模型進行分析前,需要對網站指紋(WF)攻擊技術的重要元素進行介紹,符號定義如表3所示,其中4個重要的定義如下:
定義1.網站集(website set).網站集分為被監控網站集和非監控網站集.被監控網站集是由網絡管理員定義的禁止用戶訪問的網站集,以MW表示;而非監控集則為真實網絡中除監控集以外的所有網站,以UW表示.
WF模型的任務是分析內網中是否存在用戶正在利用匿名網絡訪問被監控網站,甚至進一步分析用戶訪問的是哪一個被監控網站,2個目的分別對應于WF模型驗證及測試階段的開放世界場景(OW)和封閉世界場景(CW).如表3所示,MW的大小為Ns,UW的大小在真實網絡中為無限大,而在模型實驗階段是有限的,實驗會采集一個盡可能大的數據集以模擬真實環境,至少保證UW的大小遠大于MW的大小.

Table 3 Concepts and Symbol Definitions of WF Model
定義2.網頁流實例(instance).是用戶對單個網站訪問一次所產生的流量,是WF模型訓練和分析的數據基本單元,Ii表示實例集I中的第i個實例,Fi表示實例Ii用于模型輸入的特征向量.
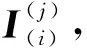
定義3.網站標記(website label).是網站類別的標識,是WF模型的分類標記.其中封閉世界場景標記(CW)集中的每一個標記分別對應于被監控網站集中的一個網站,為Ns類標記;開放世界場景標記(OW)集為二類標記,即被監控網站類標記和非監控網站類標記.實例Ii的2種標記分別記為l(CW)(Ii)和l(OW)(Ii),以l(Ii)泛指Ii的2種標記.
定義4.指紋向量(fingerprinting vector).即神經網絡的結果向量(result vector),由神經網絡方法自動學習特征形成并輸出,用于識別網站標記.實例Ii的指紋向量記為Ri,Ri[k]為向量第k維的值.
2.2 DBF模型框架
封閉世界場景假設(CW)和開放世界場景假設(OW)是WF攻擊技術研究中2個重要的場景驗證.DBF模型由DBF-CW和DBF-OW這2個子模型構成,如圖3所示.DBF-CW基于深度神經網絡對被監控網站的網頁流burst特征進行深度分析和學習,輸出網頁流的指紋向量,若網頁流屬于被監控網站集,則利用指紋向量可直接得到該被監控流的網站域名CW標記.CW標記為多分類標記,每一類為一個具體的網站域名.以往的研究通常僅訓練一個WF模型同時用于2個場景,在OW場景中對模型輸出的指紋向量基于閾值判斷的方式實現二分類決策.DBF-OW同樣是基于DBF-CW輸出的指紋向量進行再分析,但放棄了閾值法的使用,而是利用隨機森林(RF)算法對被監控網站流和非監控流進行二分類特性學習以構建模型,在OW場景下實現二分類獲取流的OW標記,即識別該網頁流是否屬于被監控網站集,OW是二類標記,即被監控網站標記和非監控網站標記.
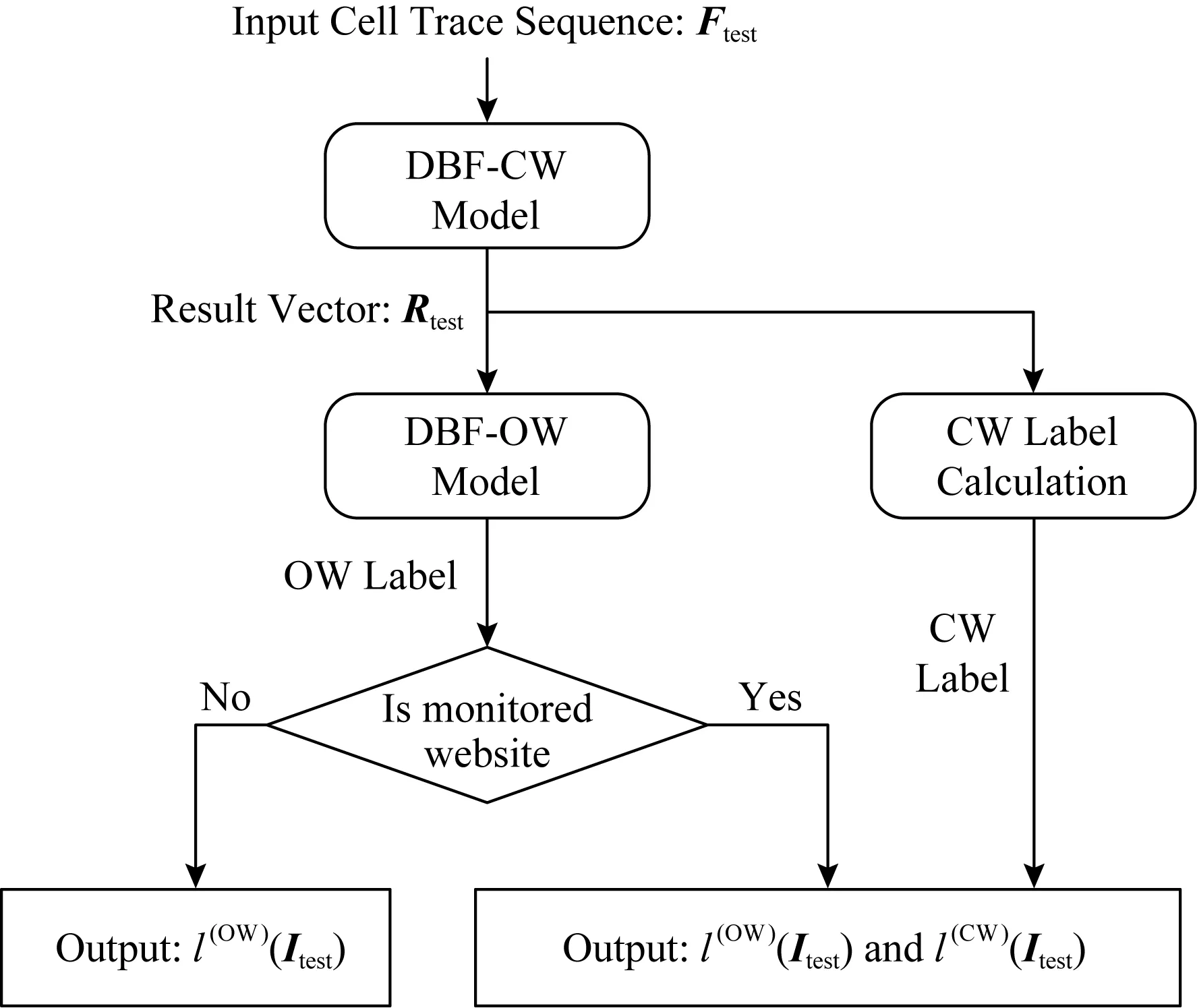
Fig. 3 The framework of DBF圖3 DBF模型框架
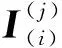
(1)
(2)
在模型驗證和測試階段,對于CW場景,DBF-CW與常規基于神經網絡的WF模型相同,輸入待測試的被監控網頁流實例Itest的特征向量Ftest,提取指紋向量Rtest,Rtest←DBF_CW(Ftest),進一步得到被監控網站CW標記l(CW)(Itest)=arg max(Rtest),即實例標記l(CW)(Itest)為Rtest中向量值最大對應的維度位序.對于OW場景,區別于一般神經網絡方法人工設定一個閾值Th,只有當Rtest[arg max(Rtest)]>Th時,實例Itest才被判定為被監控網頁流,否則為非監控網頁流的思路,DBF在DBF-CW提取出指紋向量的基礎上,DBF的子模型DBF-OW基于隨機森林算法分析指紋向量Rtest各維度值的關聯性和潛在規律得到實例Itest的OW標記,即l(OW)(Itest)←DBF_OW(Rtest).
在WF模型應用到實際中時,模型首先基于OW場景分析網頁流是否屬于被監控網站集,若是則進一步基于CW場景分析網頁流所屬的具體網站域名.具體而言,模型首先基于DBF-CW計算獲取指紋向量,并基于DBF-OW對指紋向量的分析得到網頁流的OW標記,若流的OW標記為被監控網站,則進一步基于指紋向量分析流的CW標記,即識別流的具體網站域名,如圖3所示.
2.3 封閉世界場景模型DBF-CW
2.3.1 burst特征
2.3.2 burst特征深度分析的神經網絡原理
一維卷積神經網絡對序列具有較好的分析效果,而且相比循環網絡,運行速度更快.卷積網絡基于卷積層和池化層的疊加,使得卷積窗口能覆蓋到越來越多的局部序列信息,并提取到越來越深度抽象的序列特性,其卷積原理如圖4所示.卷積網絡的卷積核可用于提取網頁流序列的burst特征,并通過更深層的卷積和池化運算得到序列中burst位置的抽象相關特性.Tor流量的burst特征有長有短,利用卷積核大小不同的卷積層對不同長度的burst特征進行提取,進而利用深層網絡對不同長度burst的位置分布進行分析,能較有效地分析Tor流量的burst特征,解構Tor流量特性.深度神經網絡對高維向量具有較好的分析效果,基于卷積網絡輸出的高維向量,DNN可以實現對向量各維度間復雜的相關性分析,如圖5所示.
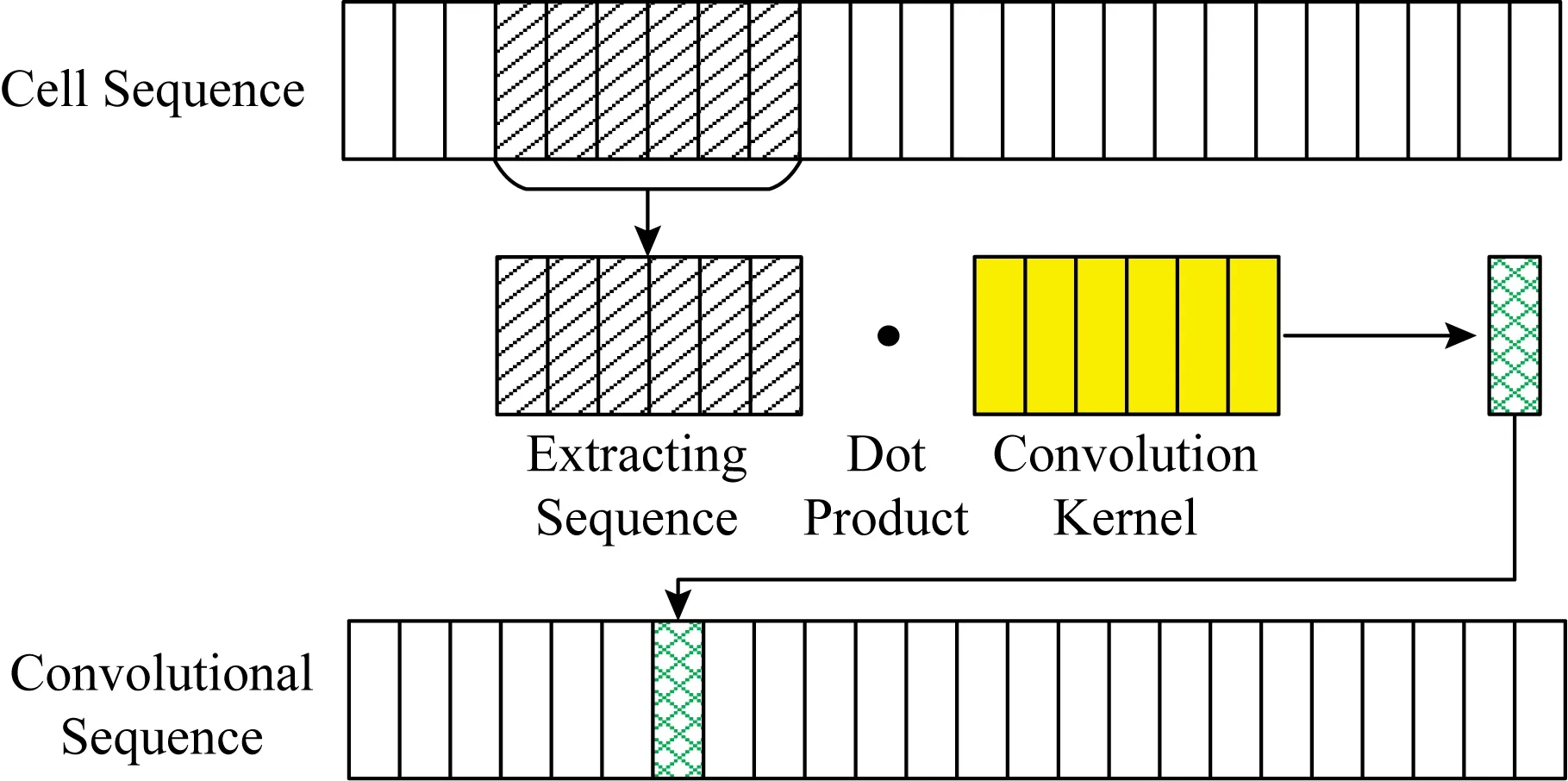
Fig. 4 Schematic diagram of one-dimensional convolution operation圖4 一維卷積運算示意圖
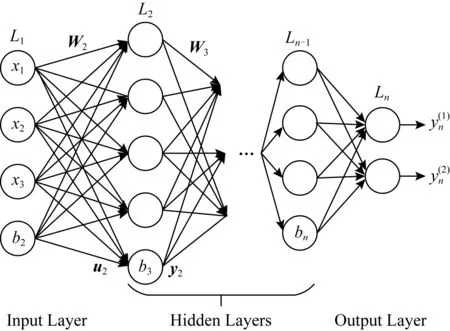
Fig. 5 Schematic diagram of dense neural network圖5 密集神經網絡示意圖
2.3.3 DBF-CW的神經網絡結構設計
DBF-CW由burst提取模塊、burst抽象學習模塊和burst深度分析模塊三大模塊構成,主要由卷積層(convolution layer, Conv)、最大池化層(max pooling layer)、密集層(dense layer)、批標準化處理(batch normalization)和Dropout處理這5個基本層件組成,如圖6所示.批標準化處理有助于神經網絡參數的快速訓練;Dropout處理則有利于提高模型的泛化性,丟失率越高,模型越不容易過擬合,但丟失率過高會大大降低模型的性能.

Fig. 6 The neural network structure of DBF-CW圖6 DBF-CW神經網絡結構
模塊1為burst特征提取模塊,主要作用和功能是利用不同大小的卷積核對短、中、長burst進行提取,并對burst在序列中的位置進行簡單的定位和淺層分析.定義短、中、長burst長度依次為8,24和72,后者依次為前者的3倍長度.基于該定義,模型對不同長度的burst分別采用了4個與其長度對應大小(即8,24和72)的卷積核進行提取,然后將得到的3個卷積張量在通道維度軸上進行拼接(concatenate),形成通道軸為12維的卷積張量.拼接后的張量進入有32個大小為1的卷積核的卷積層中進行學習,大小為1的卷積核的主要作用是學習卷積張量在通道維度軸上的通道向量各維度之間的規律和相關性,分析定位burst在序列上可能出現的單點位置.最后采用一層最大池化層加快卷積網絡對局部特征的學習效率.DBF-CW使用的池化層均為最大池化層,且池化窗口大小與短burst長度一致,步進長度為短burst長度的一半.
模塊2為burst抽象學習模塊,主要作用是對第1模塊輸出的淺層卷積張量實施更加抽象和深度的學習,從局部特征的學習逐漸過渡到全局概念的學習,以挖掘不同類網頁流序列burst特征的深層抽象特性和概念.該模塊由經典CNN架構VGG16的2個基本區塊構成,該基本區塊由2層卷積層和一層最大池化層組成,在充分利用卷積運算對特征規律學習的同時,保證了網絡的學習效率.第1個VGG16基本區塊的卷積核數為64,是模塊1卷積層的2倍;第2個VGG16基本區塊的卷積核數為128,是上一個基本區塊的2倍.隨著卷積網絡層的深入,卷積核數的增加有助于學習到不同類網頁流burst特征的深層概念.burst抽象學習模塊的卷積窗口大小均與定義的短burst長度一致,步進長度均為1.
模塊3為burst深度分析模塊,主要作用是將上一模塊輸出的具有burst特性深度和全局概念意義的卷積張量鋪平形成向量,并基于密集神經網絡對該向量的各維度相關性和特征規律進行分析,以進一步挖掘上一模塊所提取出的各個全局特征的關系.模塊3由4個密集基本區塊構成,密集基本區塊由一層全連接層、一層批標準化層和一層Dropout層組成,全連接層的神經元數均為512.同時,burst深度分析模塊還基于殘差連接的思想,將第1和第3、第2和第4基本區塊的輸出進行殘差相加,以緩解特征向量信息隨著網絡層的增加而丟失和遺忘的問題.
模型采用RMSProp算法訓練網絡,批處理大小batch為128,采用交叉熵計算分類損失,模型評估指標為準確率(accuracy,Acc).
2.4 開放世界場景模型DBF-OW
DBF-OW模型基于隨機森林(RF)算法,對DBF-CW輸出的指紋向量Ri進行分析.隨機森林是基于結構和參數簡單的決策樹等弱分類器的集成模型,對中低維的特征向量具有良好的分析效果.如圖7所示,DBF-CW結果向量在進入RF模型訓練前,DBF-OW先計算向量Ri各維度值的3個統計特征.結果向量各維度值的統計分布是反映向量屬性的重要特征,對模型的分類決策具有影響力.3個統計特征如式(3)~(5)所示,DBF-OW通過計算Ri的最大維度值、熵和標準差,得到Ri各維度值的分布情況,并將這3個統計特征添加到Ri中,形成Ns+3維的特征向量.新的特征向量與其對應的二分類標記輸入到RF模型中進行規律學習,最終得到一個可識別未知網頁流實例的二分類標記的開放世界模型.
(3)
(4)
(5)
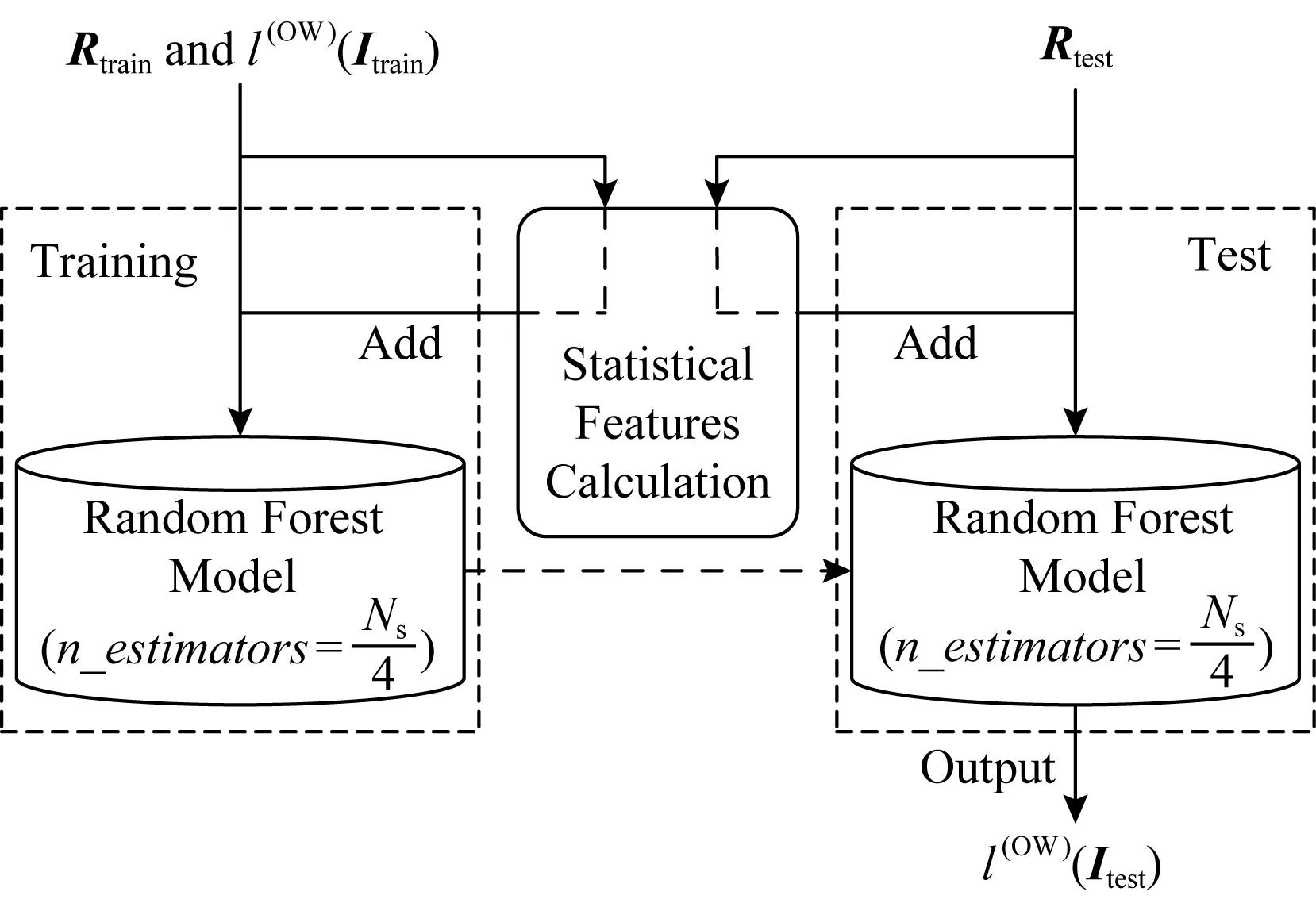
Fig.7 The structure of DBF-OW圖7 DBF-OW模型結構
DBF-OW所基于的隨機森林由若干決策樹構成,每個決策樹的訓練、結構和參數相互獨立、各不相同.每個決策樹在分析訓練數據時,以指紋向量某一維度的屬性值作為基準對數據進行劃分,計算分類前和分類后的信息熵差值,以此得到以不同維度軸作為劃分基準的各數據劃分方法的信息增益,以信息增益最大的分類方法作為該“樹支”的分類邏輯.訓練數據被劃分成多個部分后,決策樹對各部分數據分別繼續分析,形成新的分支邏輯,以此類推,最終形成一個有若干分支的決策樹.信息熵、信息增益及劃分基準選擇的計算如式(6)~(8)所示:
(6)
(7)
(8)
其中,Ent(D)表示原始數據集D的信息熵,|y|是數據的類別數,p(xi)表示第i類數據占整個數據集的比例;G(D,a)表示以指紋向量第a維度作為劃分基準時的信息增益,J表示此時的分支數,Dj表示被劃分到第j個分支的數據;a*表示被選擇的基準維度,即信息增益最大的指紋向量維度.
在各決策樹訓練完畢后,決策樹的所有葉結點由該結點訓練數據的大多數類作為該結點的類別.決策樹在對新的數據點指紋向量進行分析時,新向量依照決策樹的邏輯分支分配到某個葉結點,該葉結點對應的類別即決策樹對該向量的類別預測.在所有決策樹都對新數據點的指紋向量進行類別預測后,隨機森林對各決策樹的預測結果進行集成和綜合分析,以投票的方式決定數據點的類別,如式(9)所示:
(9)
其中,ct(x)表示第t個決策樹對x的預測結果;T是隨機森林模型中決策樹的個數;Y是標簽集;派函數∏()表示當括號內條件為真時函數值為1,否則為0.因此式(9)的含義是對于標簽集Y中的每一個元素標記y,將隨機森林模型T中的每一棵樹t的預測結果ct(x)與y進行比較,當結果為真時對y的預測值加1,最后通過反向最大值函數輸出具有最大預測值的y值,即為隨機森林模型對數據x的標記預測結果.隨機森林以決策樹為基礎,通過各決策樹對指紋向量的學習,分析向量各維度的相關性和潛在規律,獲取指紋向量的屬性邏輯規則,對應于決策樹的每一條路徑.
隨機森林作為一個集成模型,子分類器的個數是一個重要的參數.由于結果向量的維度會隨著被監控網站集的大小而變化,DBF-OW設定子分類器數為Ns/4,即被監控網站集大小的四分之一.RF子分類器數隨著被監控網站集的大小而變化,有利于RF模型對數據進行充分的擬合,避免欠擬合的情況發生.
3 實驗與結果
3.1 實驗設置
實驗主要分為2個部分,分別在封閉世界場景和開放世界場景下對模型性能進行評估.采用了微星(MSI)GT63作為實驗機器,包含了6個Intel?CoreTMi7-8750H@2.2 GHz的CPU和一個NVDIA GeForce GTX 1070的GPU,機器內存為32 GB.實驗中的算法代碼均基于Keras實現,DF[22]和AWF[11]作為實驗的對比模型.由于實驗所使用的數據集只有包方向序列特征,k-FP[16],k-NN[36]和CUMUL[17]等需要分析時間特征的算法無法在該實驗條件下執行,這些模型的實驗對比結果來源于與數據集或模型相關的論文.
3.2 評估指標
封閉世界場景是一個多分類任務,在該場景下模型的分類性能主要體現在對不同網頁流的分類能力上,因此采用準確率(Acc)對模型性能進行評估:
(10)
其中,TPi表示第i類網頁流被正確分類的實例數,N表示參與評估的實例總數.
開放世界場景是一個二分類任務,在該場景下模型的分類性能不僅體現在能正確識別出受監控網頁,還體現在盡可能少地將非監控網頁誤識別成監控網頁.實驗采用了真陽性率(true positive rate,TPR)、假陽性率(false positive rate,FPR)和多類真陽性率(multi-TPR,MTPR)對模型性能進行評估:
(11)
(12)
(13)
其中,TP表示被監控網頁流被正確分類的實例數,TN表示非監控網頁流被正確分類的實例數,FN表示受監控網頁流被錯誤分類為非監控網頁流的實例數,FP表示非監控網頁流被錯誤分類為受監控網頁流的實例數.在真實網絡中非監控網頁流要遠多于被監控網頁流,準確率和精度(precision)指標不能準確衡量模型性能,因此實驗不采用這2個指標.
3.3 實驗數據集
針對不同的實驗目的,實驗采用了多個基于Tor網絡訪問網站的數據集,數據集的每一條數據表示一個網頁流實例的數據包方向序列,即(1,-1,-1,…,-1)的數據形式,序列長度均為5 000維,不足5 000維的部分以0補足.如表4所示,前綴為CW的數據集表示封閉世界數據集,前綴為OW的數據集表示封閉世界數據集;N(MW)表示被監控網站集的大小;N(Ii)表示各被監控網站的網頁流實例數;N(UW)表示非監控網站集的大小,每個非監控網站的實例數均為1;數據括號中的第1個數表示訓練-驗證集(train-val)的大小,第2個數表示測試集(test)的大小,訓練-驗證集和測試集的劃分與源論文保持一致.所有數據的測試集僅用于模型最后的結果對比;在參數驗證的實驗中,驗證集的大小始終保持為訓練-驗證集的10%.
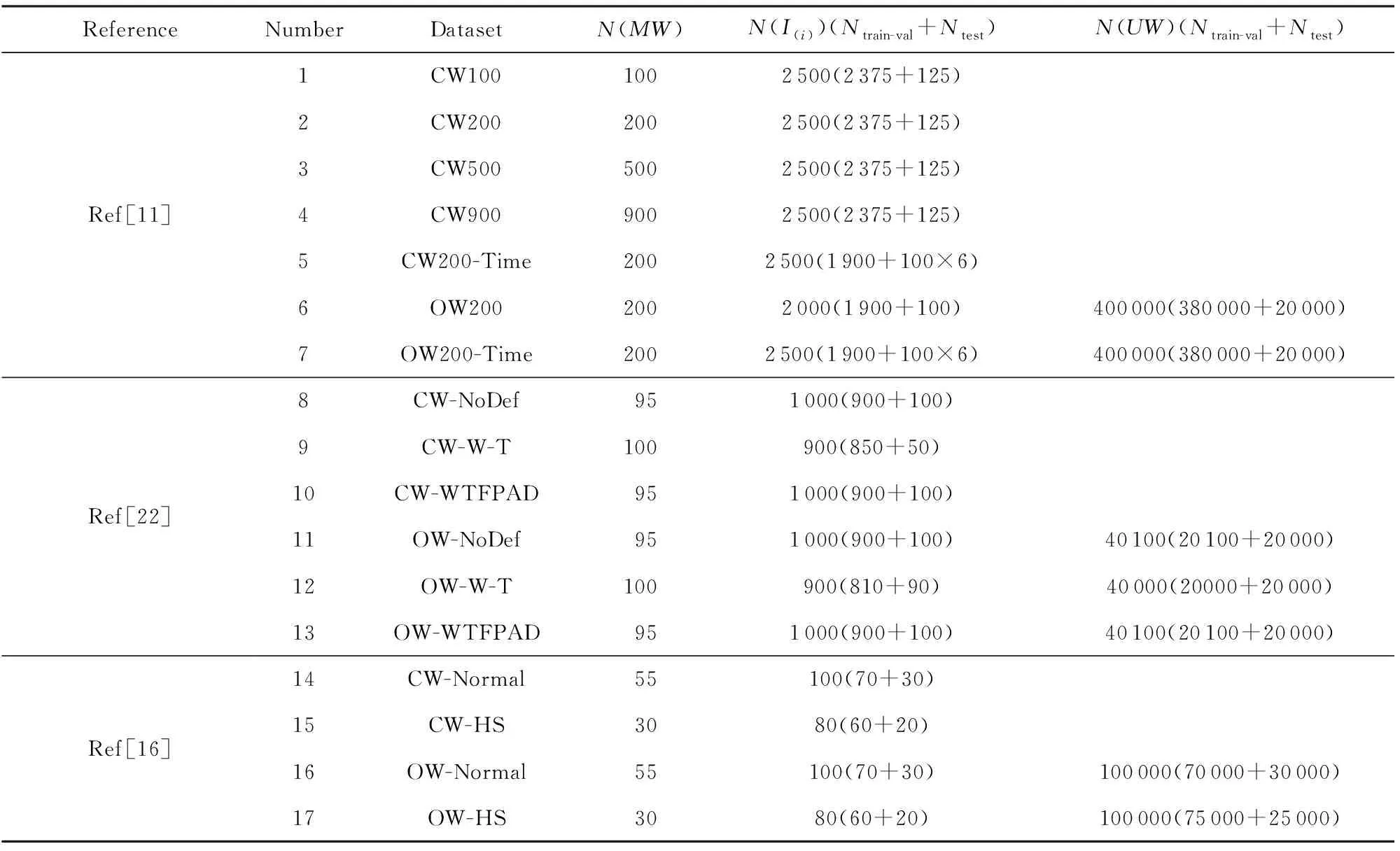
Table 4 Datasets Used in the Experiments
不同數據集的用處不盡相同.CW100-CW900數據集的被監控網站集大小不同,可用于驗證被監控網站集MW的大小對模型性能的影響.CW200-Time和OW200-Time數據集采集了與訓練數據間隔3 d、10 d、2周、4周、6周的被監控網站實例,可用于測試模型的抗概念漂移性能.Sirinam數據集[22]用于驗證模型對W-T和WTFPAD這2個相對成熟的WF防御機制的突破能力,CW-NoDef,CW-W-T,CW-WTFPAD分別是在無WF防御、有W-T防御和有WTFPAD防御機制下采集的封閉世界數據集,OW-NoDef,OW-W-T,OW-WTFPAD同理.Haye數據集[1]可用于驗證模型對Tor隱藏網站的檢測能力,CW-Normal和CW-HS是用戶通過Tor網絡分別訪問普通網站和Tor隱藏網站所采集到的數據集,OW-Normal和OW-HS同理.
3.4 封閉世界場景實驗
封閉世界場景的實驗目的,是檢驗WF攻擊模型是否能正確分類被監控網頁流實例所對應的被監控網站集標記,檢驗的是模型的多分類性能.實驗主要分為參數驗證和性能測試2部分.參數驗證階段主要探討訓練輪次epoch、神經網絡的輸入序列長度、訓練實例數對模型性能的影響;性能測試階段主要分析被監控網站集MW的大小對性能的影響、模型的抗概念漂移能力、繞過WF攻擊防御機制的能力以及檢測Tor隱藏網站的能力.DBF-CW與DF的默認參數是epoch為30,輸入序列長度為5 000.AWF的默認參數是epoch為30,輸入序列長度為3 000.
3.4.1 epoch對模型準確率的影響
實驗在CW100和CW-NoDef數據集上對訓練不同epoch下的模型準確率進行驗證,訓練集為訓練-驗證集的90%,驗證集為10%.如圖8和圖9所示,圖8為DBF-CW模型分別在CW100和CW-NoDef數據集上運行60個epoch的結果,圖9為DBF-CW,DF和AWF模型在CW100數據集運行30個epoch的結果.盡管CW100和CW-NoDef數據集的大小不同,但當epoch為15~20時,DBF-CW在2個數據集上均達到了擬合的狀態,驗證了DBF-CW訓練的穩定性.同時,相比AWF模型,DBF-CW和DF訓練速度更快且更穩健,僅經過前5輪的訓練,整體準確率已經穩定在97%以上.
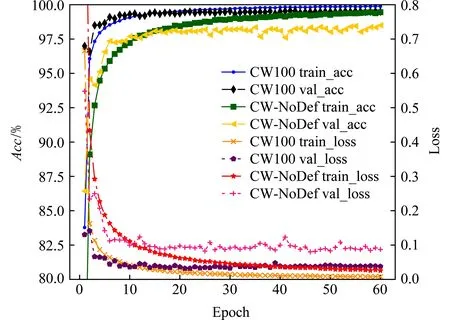
Fig. 8 Performance of DBF-CW under different epochs圖8 DBF-CW訓練不同epoch時的性能
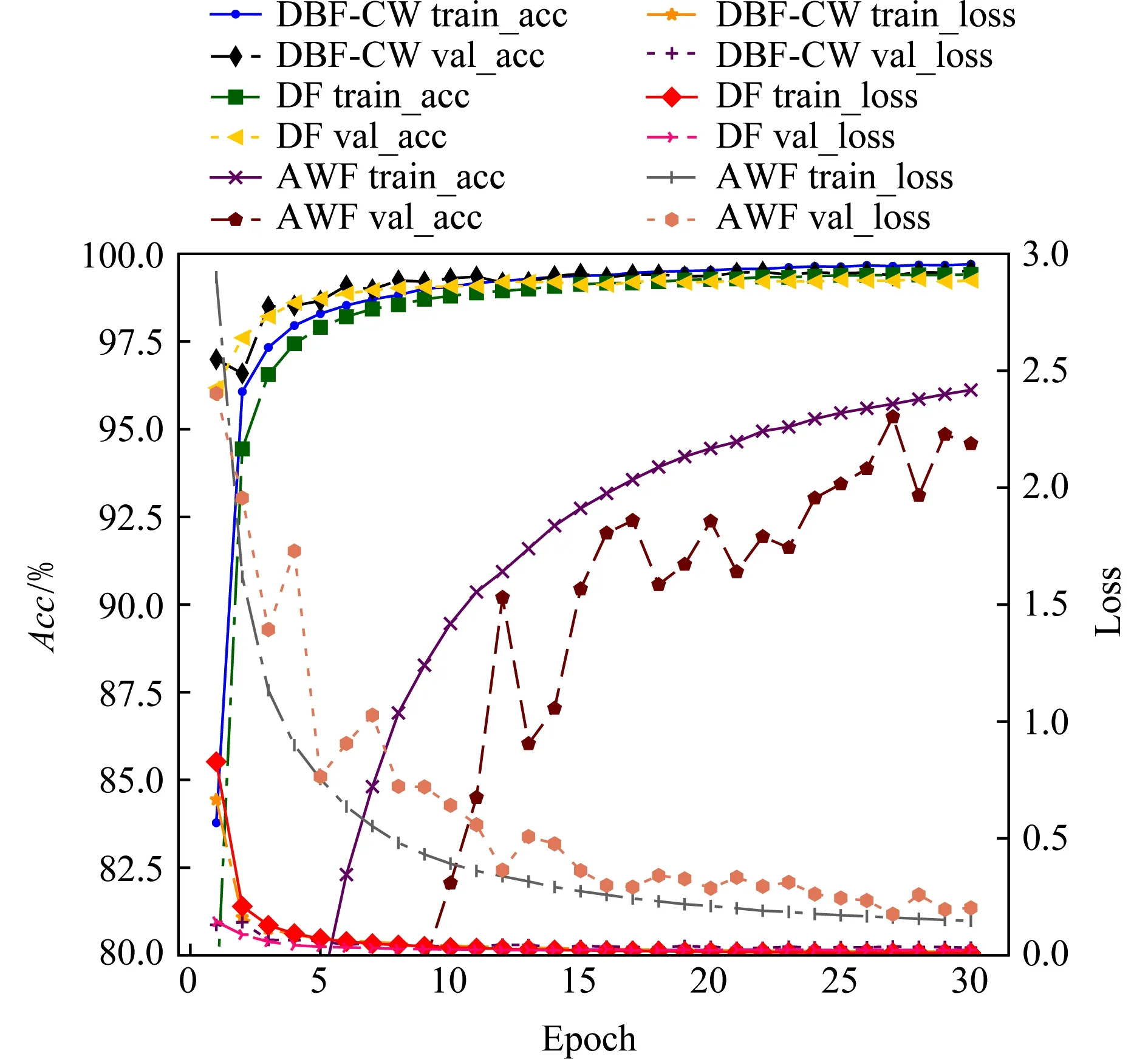
Fig. 9 Performance under different epochs on the CW100 dataset圖9 各算法在CW100數據集上訓練不同epoch的性能
3.4.2 網頁流序列長度對模型準確率的影響
實驗在CW100和CW-NoDef數據集上驗證模型在輸入的網頁流序列長度不同時的準確率變化,訓練集為訓練-驗證集的90%,驗證集為10%.如圖10所示,DBF-CW和DF模型的準確率均隨著輸入序列長度的增大而增大,且在輸入長度為1 000時,模型的驗證準確率在98%以上.相比AWF模型,DBF-CW和DF模型對輸入長度不敏感,準確率變化幅度較小,表明模型對輸入的長度依賴性不強,有較好的健壯性.
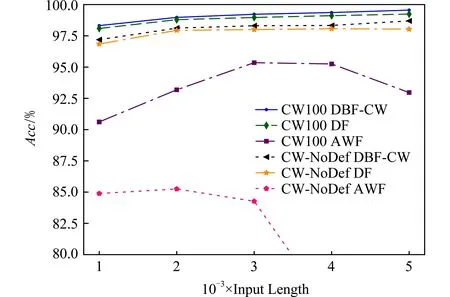
Fig. 10 Accuracy of the algorithms with different input lengths圖10 各算法在輸入序列長度不同時的準確率
3.4.3 訓練實例數對模型準確率的影響
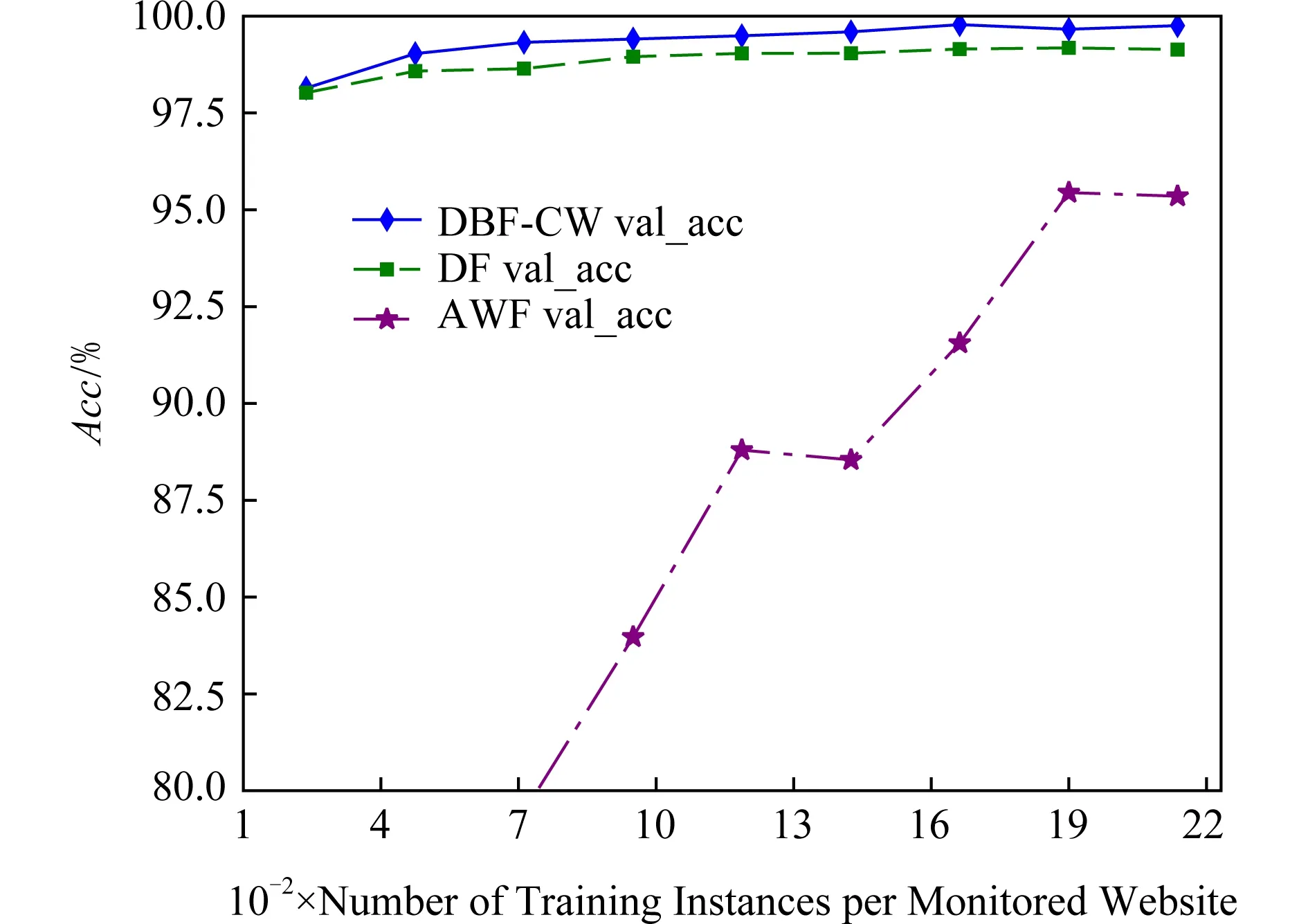
Fig. 11 Accuracy of the algorithms with different training instances on the CW100 dataset圖11 各算法在CW100數據集上訓練不同實例數的準確率
實驗在CW100和CW-NoDef數據集上對模型的訓練實例數與模型準確率之間的關系進行驗證,驗證集大小為訓練-驗證集的10%,訓練集大小依次為10%~90%,間隔10%,取9個點.實驗結果如圖11和圖12所示,隨著每類被監控網站的訓練實例數增加,3個算法模型的分類準確率均隨之增大,但DBF-CW相比AWF的變化幅度小得多.在小樣本訓練的情況下,DBF-CW和DF算法仍能保持96%以上的分類準確率,表明算法對樣本的規律學習和泛化性能比較好,在小樣本訓練的情況下同樣可以成功實施WF攻擊.
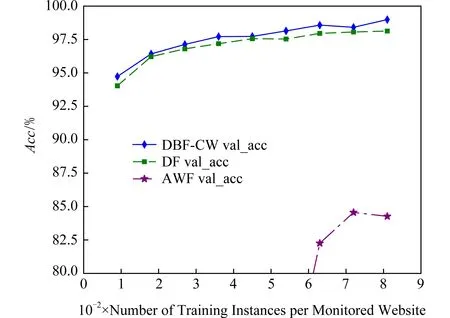
Fig. 12 Accuracy of the algorithms with different training instances on the CW-NoDef dataset圖12 各算法在CW-NoDef集上訓練不同實例數的準確率
3.4.4 被監控網站集大小對模型準確率的影響
實驗在CW100-CW900四個數據集上驗證被監控網站集的大小對模型準確率的影響,這4個數據集的網站集大小分別為100,200,500和900.如圖13和表5所示,隨著被監控網站集的增大,DBF-CW和DF的準確率有略微下降,而AWF模型準確率下降較快.DBF-CW的分類準確率始終保持在最高位,且均在98%以上.實驗表明DBF-CW是健壯的,對WF技術適應性較好,受被監控集網站大小的變化影響較小.
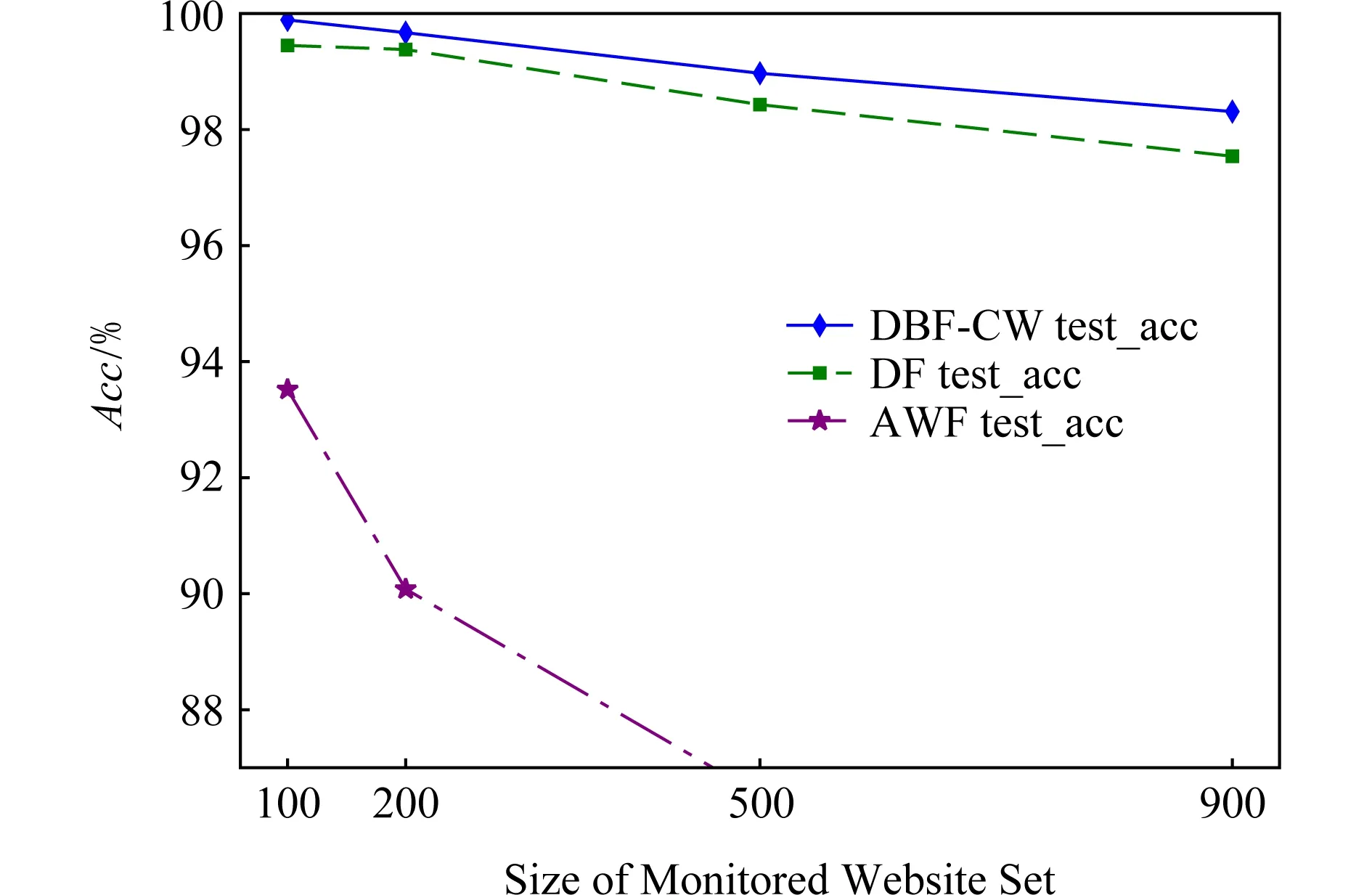
Fig. 13 Test accuracy of the algorithms on CW100-900 dataset 圖13 各算法在CW100-900數據集上的測試準確率對比
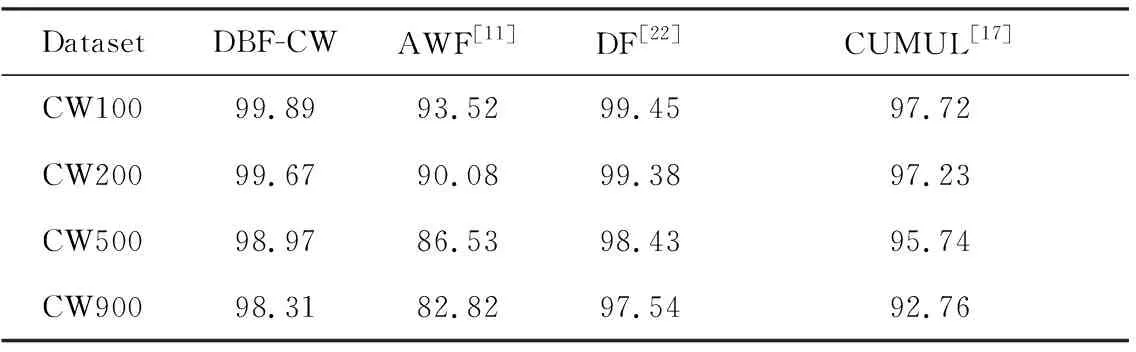
Table 5 Test Accuracy of the Algorithms on CW100-900 Dataset
3.4.5 模型的抗概念漂移能力驗證
實驗采用CW200-Time數據集驗證模型緩解概念漂移(concept drift)的能力.概念漂移是指在實際網絡環境中,數據模式會隨時間的推移而出現變化,模型訓練使用的數據與測試數據的間隔越長,模型通過“舊”數據訓練得到的概念與測試數據實際的概念模式的偏差就會越大,導致模型分類性能下降.
圖14和表6是DBF-CW與對比算法在CW-Time數據集上的準確率對比,CW-Time數據集包含1個訓練集和6個測試集,各測試集的采集時間與訓練集分別相隔了0 d,3 d,10 d、2周、4周和6周.從圖14可以看到,DBF-CW,DF和AWF模型的分類準確率隨著時間間隔增大而均有所下降,但DBF-CW的下降速度是最慢的,驗證了DBF-CW能較有效地緩解概念漂移問題.概念漂移是實際應用中模型隨著時間推移而性能下降的一個無法避免的問題,但如果模型能有效減緩性能下降的速度,就有更充分的時間準備新的訓練數據以訓練出新的模型,以真正解決實際應用場景中的概念漂移問題.
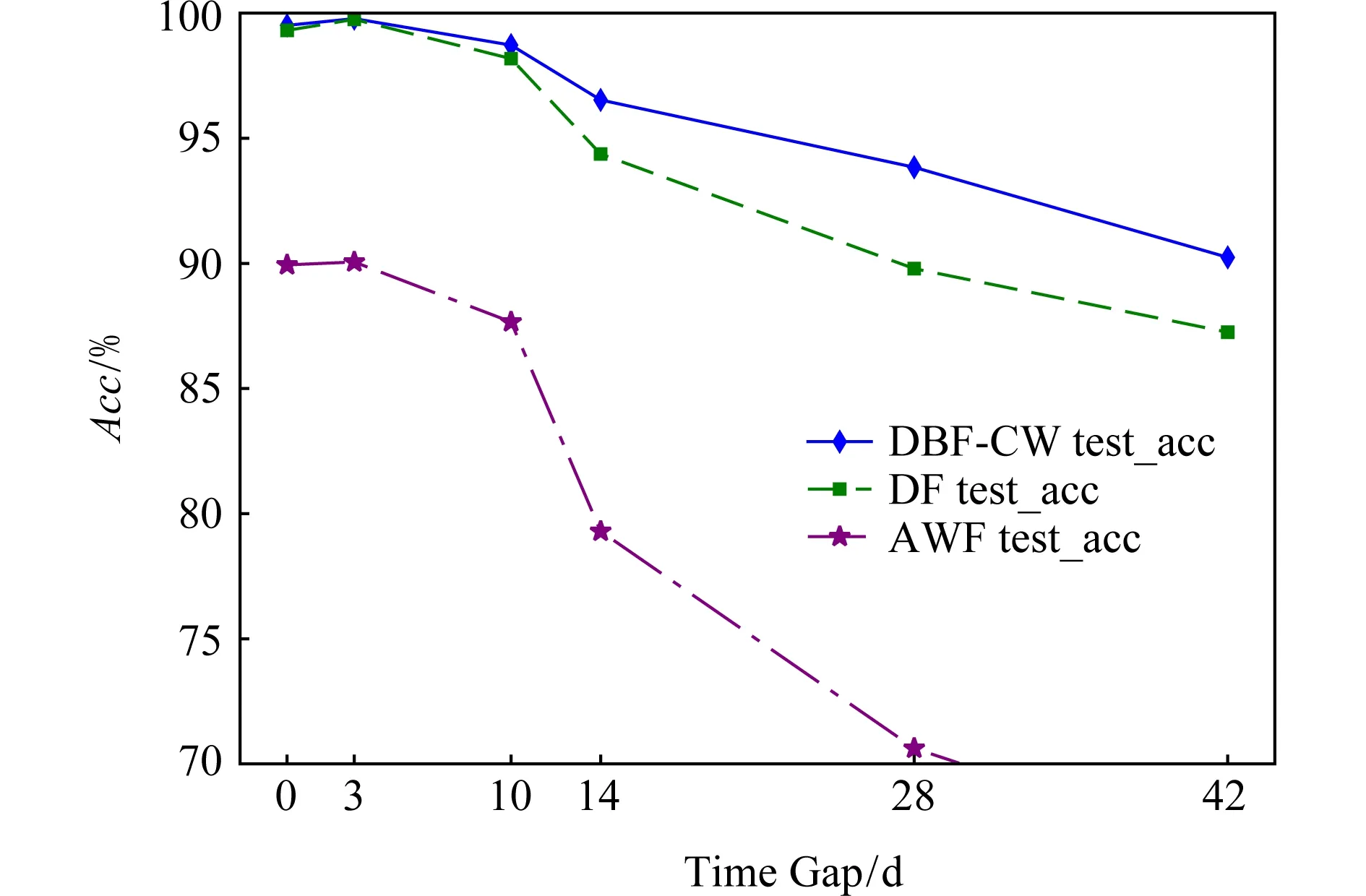
Fig. 14 Test accuracy of the algorithms on CW-Time dataset圖14 各算法在CW-Time數據集上的測試準確率
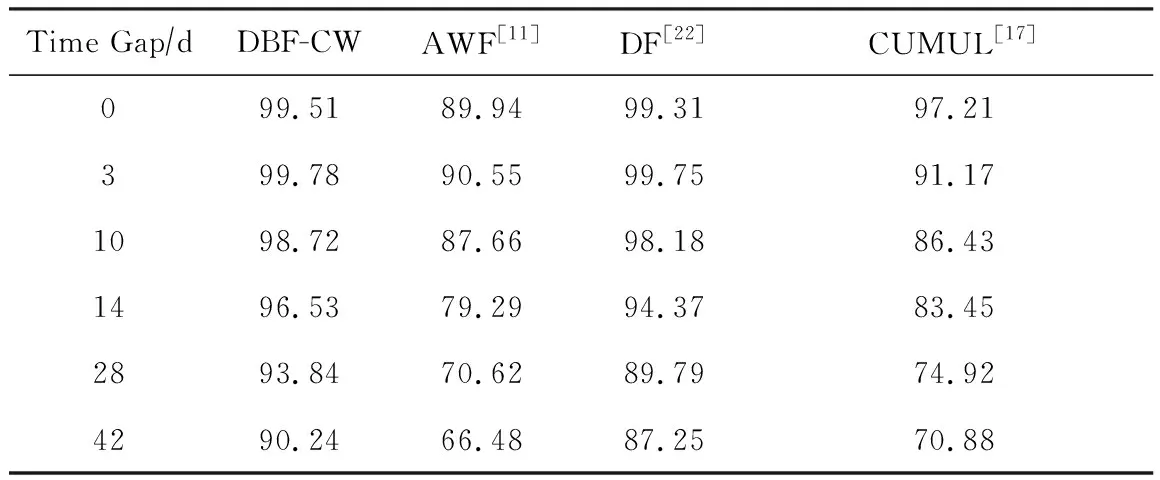
Table 6 Test Accuracy of the Algorithms on CW-Time Dataset
3.4.6 模型對Tor隱藏網站的檢測性能
實驗在Tor隱藏網站數據集上對模型的Tor隱藏網站檢測能力進行測試.如表7所示,DBF-CW在正常集CW-Normal和隱藏網站集CW-HS的準確率表現一般,分別為70.6%和80.66%.這可能是因為該數據集的訓練實例數和序列長度過短導致的,各類被監控網站的訓練實例數僅為70和60,遠遠少于其他2個數據集的900訓練實例和2375訓練實例;另一方面,該數據集的序列為數據包序列,而不是其他2個數據集的cell序列,這會導致模型對burst特征的提取和分析不足.相比之下,基于一般機器學習方法的k-FP[16]在小樣本情況下表現出了較強的學習能力.從縱向看,DBF-CW在隱藏網站數據集上的分類準確率高于正常數據集約10%,說明DBF-CW對Tor隱藏網站是有檢測能力的.從橫向上看,DBF-CW相比其他2個神經網絡模型的準確率是最高的,體現了DBF-CW的神經網絡結構在WF領域有更強的適應性.
Table 7 Test Accuracy on Tor Hidden Website Dataset
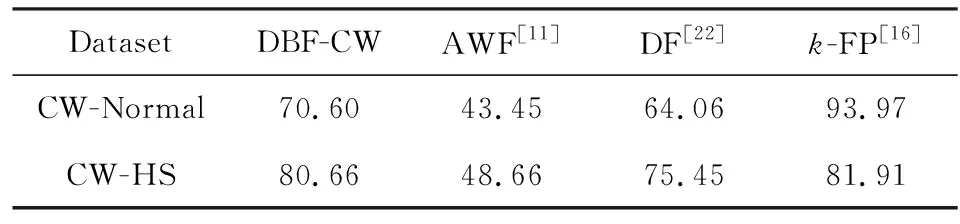
表7 各算法在Tor隱藏網站數據集上的測試準確率 %
3.4.7 模型對WF攻擊防御機制的突破能力驗證
實驗在無針對WF攻擊的防御機制、有W-T機制和有WTFPAD機制這3個數據集上進行.如表8所示,WTFPAD和W-T防御機制犧牲了一定的帶寬,分別為31%和64%,WTFPAD機制還有34%的傳輸延遲.從橫向比較上看,DBF-CW在CW-NoDef,CW-W-T和CW-WTFPAD這3個數據集上的準確率均為最高.對于WTFPAD防御機制,DBF-CW對各被監控網站的識別準確率達到了96.25%,表明WTFPAD對DBF-CW幾乎沒有防御能力.雖然DBF-CW在W-T防御機制數據集上的準確率只有52.06%,但考慮到該數據集的被監控集大小為100,該準確率仍能說明DBF-CW在一定程度上能夠突破W-T防御機制.

Table 8 Test Accuracy of the Algorithms on Defense Against WF Attack Dataset
3.5 開放世界場景實驗
開放世界場景的實驗目的,是檢驗WF攻擊模型是否能正確識別未知網頁流實例為被監控網站流或非監控網站流,檢驗的是模型的二分類性能.實驗主要分為參數驗證和性能測試2部分.參數驗證階段主要探討基于隨機森林算法的DBF-OW子分類器數和非監控網站訓練實例數對DBF模型性能的影響;性能測試階段主要分析模型的抗概念漂移能力、繞過WF攻擊防御機制能力以及對Tor隱藏網站的檢測能力.實驗中,DBF-OW的子分類器為被監控集大小的1/4,其余參數與封閉世界場景實驗的設置保持一致.
3.5.1 DBF-OW子分類器數對模型準確率的影響
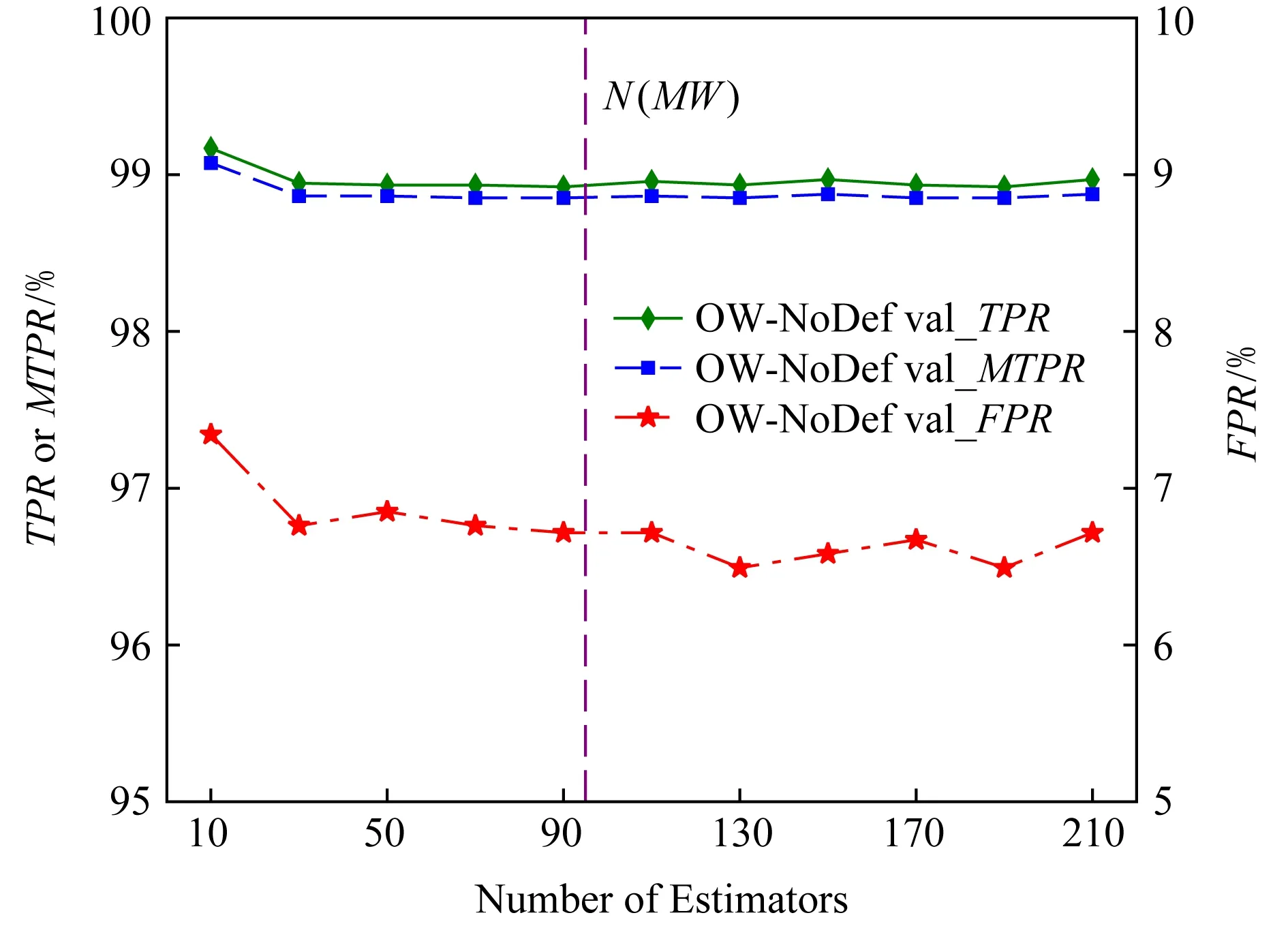
Fig. 15 Performance of DBF with different number of estimators on OW-NoDef圖15 DBF在OW-NoDef上子分類器個數不同時的性能
實驗在OW-NoDef和OW200數據集上對由不同子分類器構建的DBF-OW模型性能進行驗證,訓練集為訓練-驗證集的90%,驗證集為10%.如圖15和圖16所示,圖15為DBF-OW模型在OW-NoDef數據集上運行的結果,實驗選取了子分類器數分別為10~210(間隔為20)的11個模型進行評估;圖16為DBF-OW模型在OW200數據集上運行的結果,選取了子分類器數分別為10~410(間隔為40)的11個模型進行評估.從對比結果上看,2個實驗分別在分類器數為30和50時性能達到相對最優,此后模型性能幾乎沒有增長.需要注意的是,30和50個分類器分別約是各自所使用數據集的被監控網站集大小(N(MW))的31%和25%.因此,該實驗驗證了DBF-OW模型在分類器數取為被監控網站集大小的1/4時,性能能夠達到一個相對較好的水平.

Fig. 16 Performance of DBF with different number of estimators on OW200圖16 DBF在OW200上子分類器個數不同時的性能
3.5.2 DBF-OW有效性驗證
實驗在OW-NoDef和OW200數據集上通過比較DBF-OW和閾值法的性能以驗證DBF-OW模型思想的有效性,訓練集為訓練-驗證集的90%,驗證集為10%.如表9所示,DBF-OW模型在OW-NoDef數據集上的TPR與MTPR值要優于閾值法,而在OW200數據集上的TPR與MTPR值與閾值法持平,表明DBF-OW相比閾值法對正類的檢測率有所提高,但提升水平有限.而對于FPR值,閾值法在2個數據集上的表現均大于15%,表明閾值法將反類誤分類為正類的問題較為嚴重,而DBF-OW的FPR分別僅為傳統閾值法的43%和11%,表明DBF-OW有效緩解了該問題的出現,改進了閾值法的缺陷.
3.5.3 非監控網站訓練實例數對模型準確率的影響
實驗在OW200數據集上對模型的非監控網站訓練實例數與模型性能之間的關系進行驗證.實驗使用數量固定的被監控網站實例數和數量不定的非監控網站實例數對DBF模型進行訓練.被監控網站訓練實例數為訓練-驗證集中被監控集的一半,即190 000條數據,非監控網站訓練實例數依次取訓練-驗證集中非監控集的10%~90%,間隔10%,共9個點.實驗使用10%的訓練-驗證集(含監控集和非監控集,且與訓練數據不重復)作為驗證數據.如圖17所示,隨著非監控網站訓練實例的增多,模型的TPR,MTPR和FPR均有所下降.但整體上看,DBF在訓練數據不平衡的情況下,性能依舊是穩健的:在非監控網站訓練實例數約為被監控數的20%時,FPR只有4.5%;而在非監控數為被監控數1.8倍時,DBF的TPR和MTPR仍舊保持在97%以上.
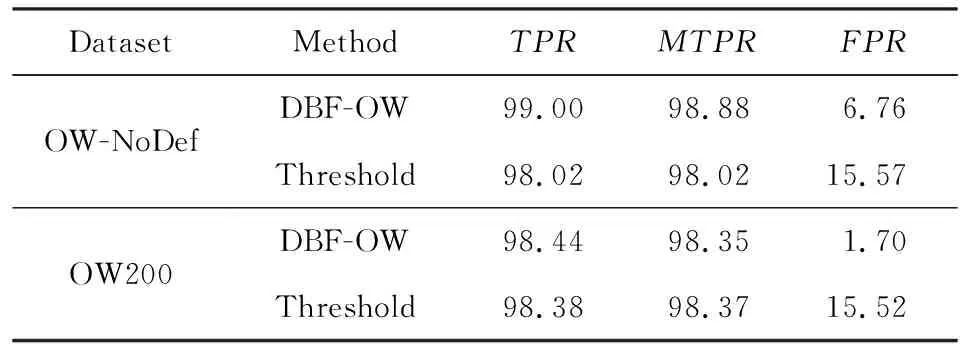
Table 9 Performance of DBF-OW and Threshold Method
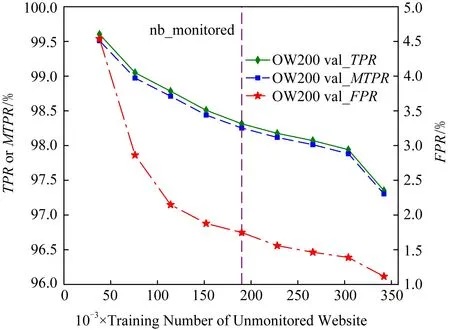
Fig. 17 Performance comparison of DBF with different number of training instances of unmonitored website 圖17 DBF在非監控網站訓練實例數不相同時的性能對比
3.5.4 模型的抗概念漂移能力驗證
實驗采用OW200-Time數據集驗證模型在開放世界場景下緩解概念漂移的能力.OW200-Time的被監控網站集部分與3.4.5節中使用的CW200-Time數據集完全相同,非監控網站集部分與OW200完全相同.由于實驗重點關注的是模型對被監控網站類的學習是否會隨著時間的變化與實際的類概念發生偏差,而不關心非監控網站是否出現概念漂移(各非監控網站實例只有一個,實際上構不成概念),因此實驗的非監控網站集沒有和被監控集一樣間隔多天采集一次,所以測試集中的非監控集部分沒有變化,如表10所示FPR始終為1.63%.如圖18和表10所示,模型性能隨著時間間隔的增大,有較明顯的下降.相比3.4.5節在封閉世界場景下驗證模型抗概念漂移能力的實驗,模型在開放世界場景下的性能下降得更快.但總的來說,模型在使用42 d前的數據進行訓練時仍能達到80%的TPR,表明模型具有較強的抗概念漂移能力.從實踐的角度分析,6周的時間足夠網絡管理員采集新的數據訓練模型.
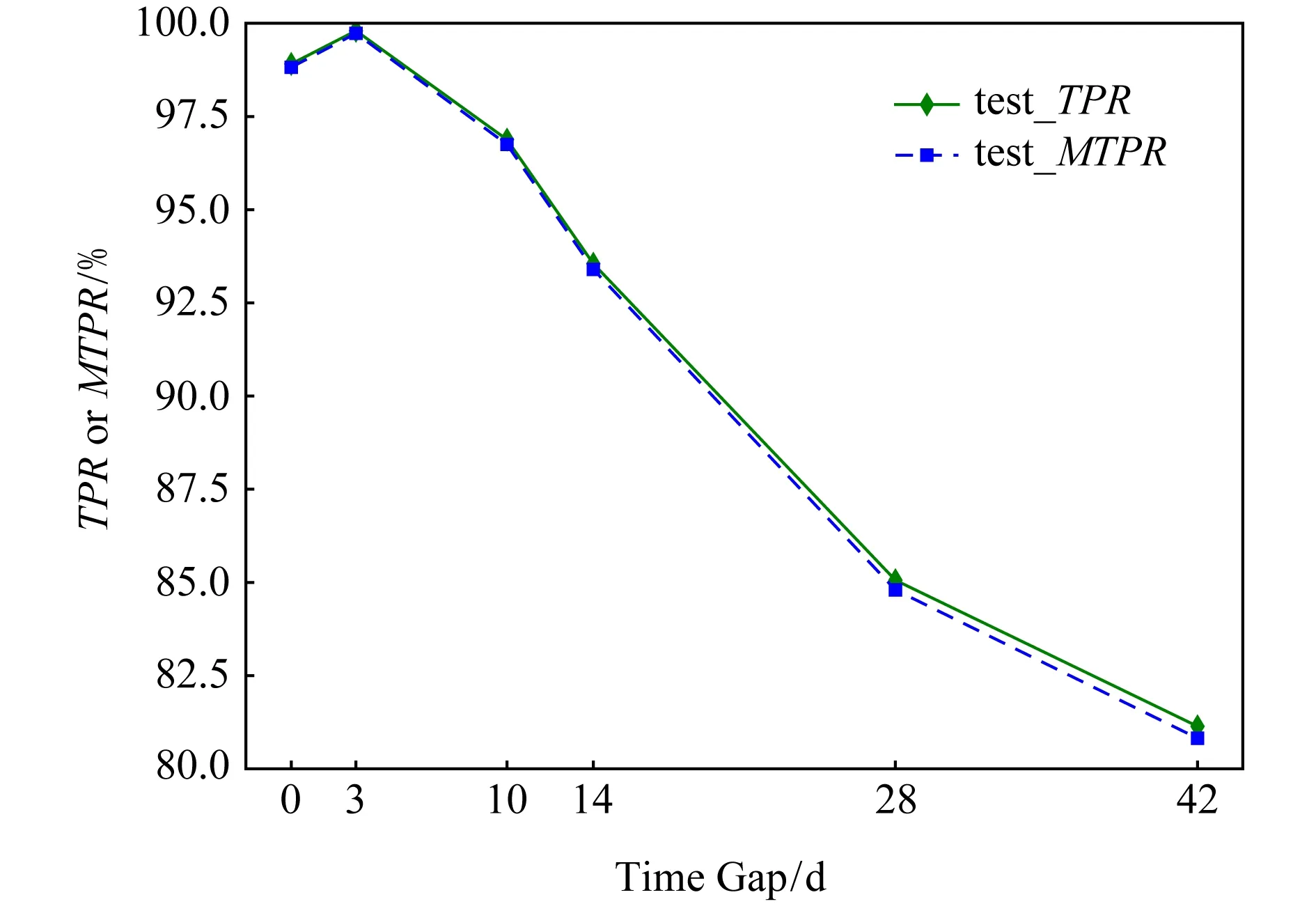
Fig. 18 DBF performance on the OW-Time dataset圖18 DBF在OW-Time數據集上的性能表現
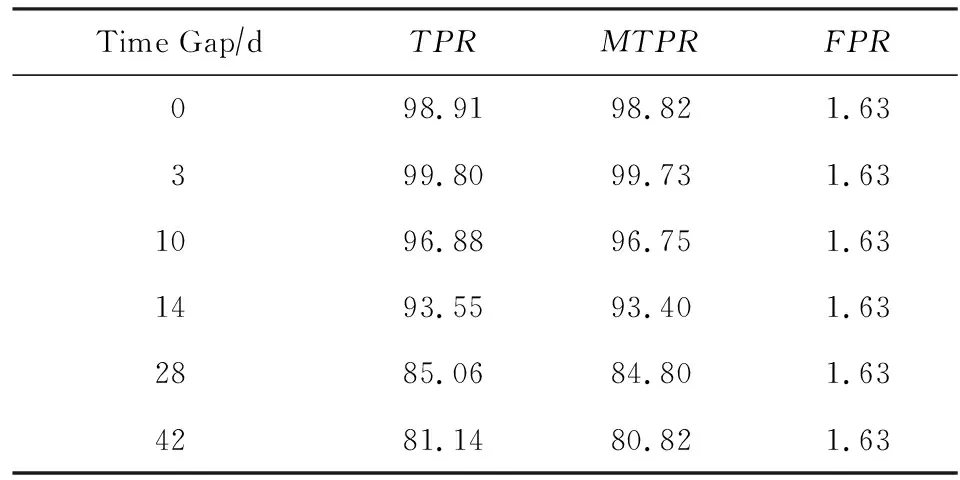
Table 10 DBF Performance on the OW-Time Dataset
3.5.5 模型對Tor隱藏網站的檢測能力
實驗在Tor隱藏網站數據集上對模型的Tor隱藏網站檢測能力進行測試,該數據集的被監控網站集部分與CW-Normal和CW-HS一致.如表11所示:
Table 11 Performance on Tor Hidden Website Dataset
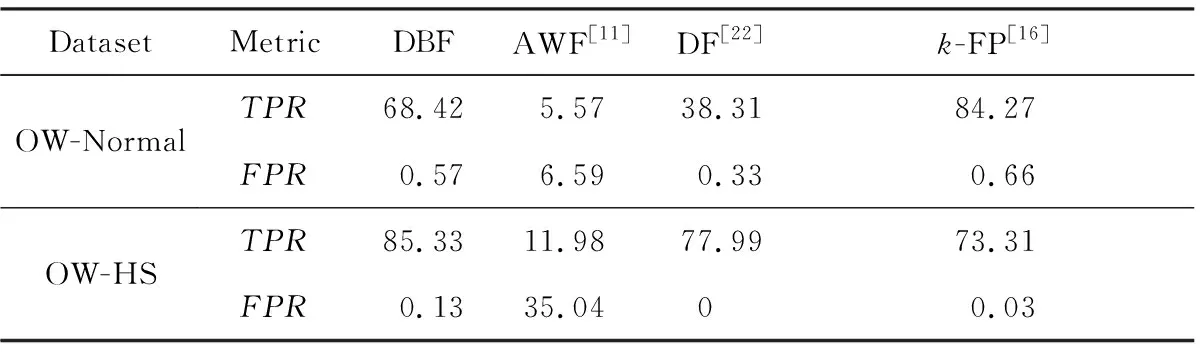
表11 各算法在Tor隱藏網站數據集上的性能測試對比 %
DBF對Tor隱藏網站的檢測效果是最好的,在FPR只有0.13的情況下FPR達到了85.33%,在各類監控網站訓練實例只有不到100的情況下,其性能比一般機器學習k-FP[16]還要出色.相比3.4.6節在封閉世界場景下DBF-CW檢測Tor隱藏網站較弱的準確率表現,DBF在開放世界場景下對Tor隱藏網站的識別有了很大的提高,而2個實驗的被監控集是相同的.出現這種的可能原因是DBF-OW起到了重要的作用.不同于AWF[11]僅使用被監控網站集訓練以及DF[22]同時使用被監控集和非監控集及相應的多分類標記同時訓練模型,DBF的子模型DBF-OW使用二分類標記訓練模型,使得DBF-OW能夠學習隱藏網站及非隱藏網站的二類特性.另外,不同于人為隨機定義的被監控網站集,其整體的規律性比較弱,Tor隱藏網站作為一種特殊的網頁流天然地自成一類網頁流,因此Tor隱藏網站和非Tor隱藏網站具有可以學習的網頁流規律.實際上,在該實驗中DBF的MTPR只有66%,遠低于TPR值85.33%,從反向的角度也證明了DBF-OW在識別Tor隱藏網站中起到的重要作用.
3.5.6 模型對WF攻擊防御機制的突破能力驗證
實驗在無防御機制、有W-T機制和有WTFPAD機制這3個開放世界數據集上進行.如表12所示,DBF在WTFPAD數據集上對各被監控網站的MTPR和TPR分別達到了92.16%和93.66%,WTFPAD對DBF幾乎沒有防御能力,與3.4.7節在封閉世界場景下的結果相呼應;DBF-CW在W-T數據集上的TPR到達了93.92%,但MTPR為64.11%,超高的TPR值與3.5.5節中的實驗結果類似,這同樣歸功于DBF-OW對二類特性的學習能力.綜合來看,DBF在一定程度上繞過了W-T防御機制.與其他算法對比,DBF在3個數據集上的MTPR和TPR均為最高,且有較高的性能優勢.但DBF在2個數據集上的FPR均超過了15%,在非監控網頁流遠遠少于被監控網頁流的真實網絡中,這個FPR值是過高的,其主要原因是非監控網站集的訓練實例數(20 000)較少于監控集訓練數(90 000)且防御機制對模型起到了干擾作用.但在與對比算法的橫向比較上,DBF的FPR性能也不具備太大優勢,說明DBF-OW在分析經過防御機制加持的Tor流量時還存在一定問題,仍需要繼續改進.
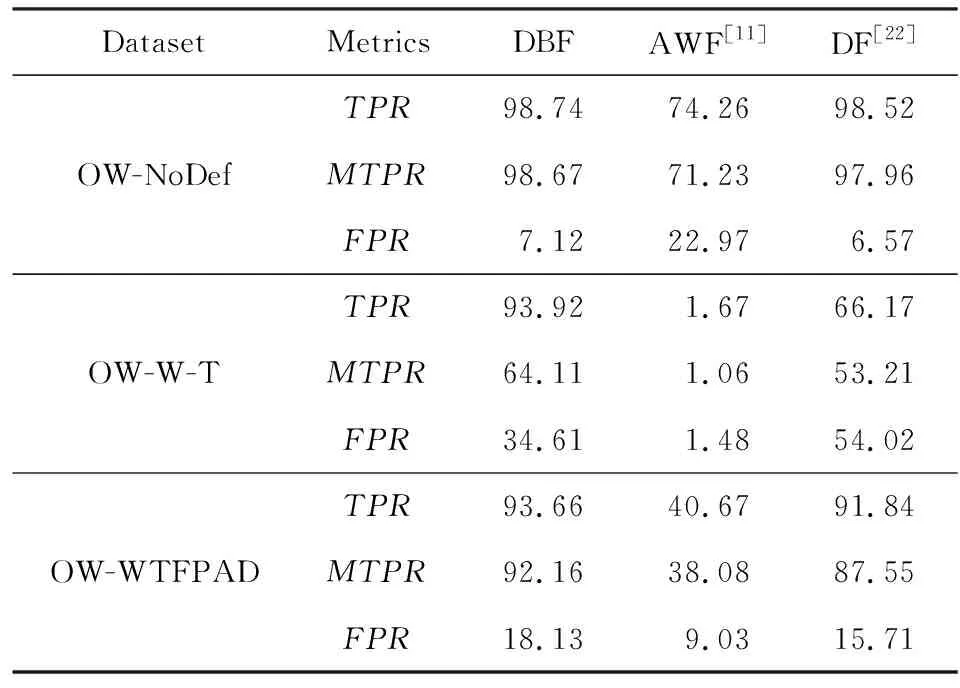
Table 12 Performances on Defense Against WF Attack Datasets
3.6 模型復雜度分析
DBF相比其他2個神經網絡方法要更加輕便、運行速度更快,其神經網絡結構簡化對比如圖19所示.DBF的簡化結構與DF相似(DBF的具體參數在2.3.3節已有描述;DF的4輪卷積網絡參數為:卷積窗口均為8,卷積步進均為1,卷積核數依次為32,64,128,256,池化步進均為4,池化窗口均為8),但DBF運算速度更快.一方面,DBF僅有3輪基本卷積網絡運算(即2層卷積層一層最大池化層),而DF有4輪.另一方面,DBF的第1輪卷積網絡用于burst特征提取,其結構遠比DF的第1輪卷積網絡要簡單,如第1層卷積層的核數僅為4(DF的卷積核數為32),第2層卷積層的卷積窗口大小僅為1(DF的卷積窗口大小為8).DBF由于深度分析burst特征的需要,密集連接網絡運算有4輪,要多于DF的2輪,但密集連接網絡的運算速度很快,時間消耗遠遠少于卷積網絡.DBF在簡化網絡結構的同時提高了模型性能,關鍵在于DBF充分結合了流量burst特征分析的需要和網站指紋攻擊技術的特點設計神經網絡結構,并且摒棄了以往研究中冗余的神經網絡結構.其中最具特色的是DBF的第1輪卷積網絡的第1層卷積層運算實際上包含了3個平行的卷積層,用于提取burst特征(DBF的具體結構如2.3.3節圖6所示),而這3個平行的卷積層是可以并行計算的,因此沒有增加時間消耗.AWF神經網絡結構雖然僅有7層,但長短時記憶網絡層(LSTM)屬于循環網絡層的一種,運算非常耗時,因此AWF的時間消耗要大于DBF和DF.
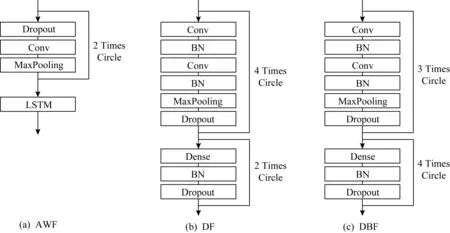
Fig. 19 Simplified neural network structures of the algorithms圖19 各算法的神經網絡結構簡化圖
DBF與對比算法具體的時間消耗如表13和表14所示,DBF每個epoch的訓練時間只有86.30 s,遠低于對比算法,可知DBF在模型效率上同樣優于對比算法.實際上DBF的訓練并不需要多達30個epoch,3.4.1節驗證了模型在15~20個epoch時就基本能達到最佳的性能效果.在減少訓練epoch的情況下,模型的訓練時間能進一步縮短.
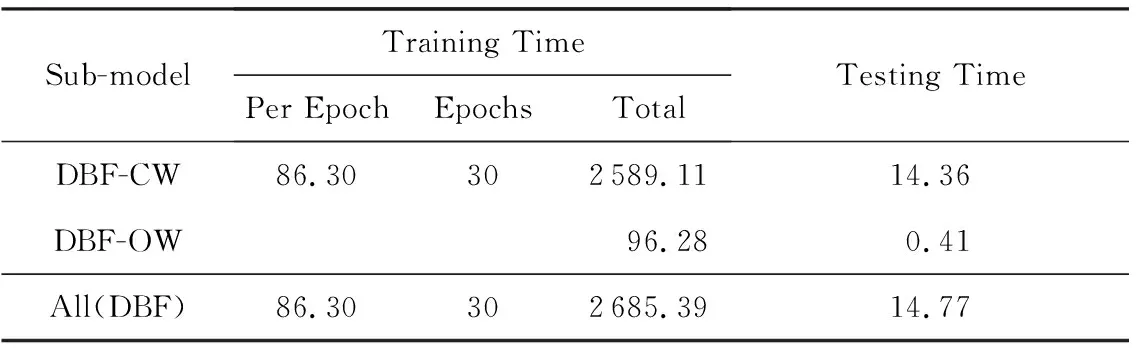
Table 13 Running Time of DBF on OW-NoDef Dataset
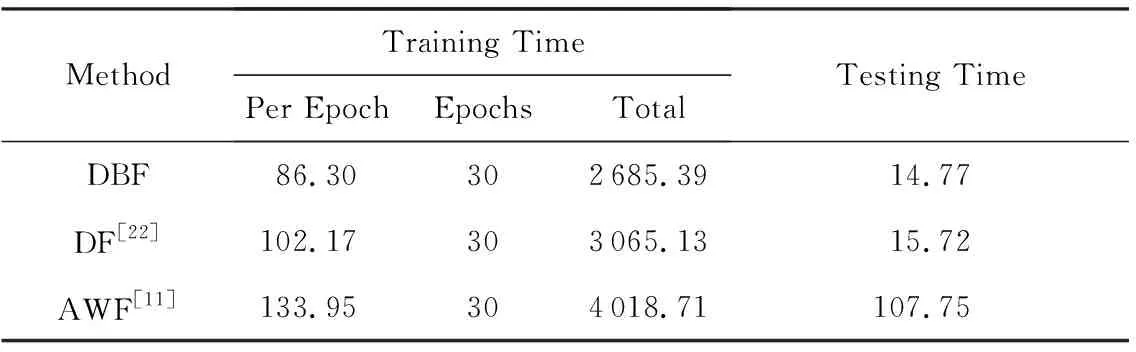
Table 14 Comparison of Running Time of the Algorithms on OW-NoDef Dataset
3.7 實驗討論
從場景的設置上看,實驗從封閉世界場景和開放世界場景2個角度對DBF進行了分析,模型均表現出了良好的性能.從功能性驗證上看,DBF在受被監控網站集大小影響、緩解真實網絡環境存在的概念漂移問題、繞過WF攻擊防御機制以及對Tor隱藏網站的檢測上有較好的性能表現,這些模型性能對WF攻擊技術應用到真實網絡環境中有很大幫助;同時DBF在3.5.2節的開放世界場景實驗驗證中,表現出對傳統閾值法的極大改進,相較傳統方法明顯降低了FPR值,但在3.5.6節的實驗出現了FPR值過高的情況,表明抵御WF攻擊的防御機制對帶寬的擾亂,在誤導WF模型將非監控網頁流誤分類為監控流方面起到了明顯的作用.雖然DBF一定程度上突破了防御機制,并表現出了較高的MTPR,但較高的FPR表示DBF-OW受防御機制加持的影響較大,說明模型在訓練階段對指紋向量的學習能力還有所欠缺.從模型自身的參數驗證上看,DBF對訓練輪次epoch、輸入的特征序列長度、被監控網站的訓練實例數、隨機森林算法的子分類器數等參數敏感度不高,說明模型本身的結構是健壯的,模型性能不容易受參數變化而影響.從模型對比上看,DBF模型在各方面的性能表現都要優于DF模型,但是在個別方面的優勢不明顯,如小樣本訓練下的模型準確率、輸入序列長度對模型的準確率影響等;而AWF模型的性能與DBF和DF模型相差較大,證明了神經網絡方法雖然是一個利器,但是如果沒有對經典架構做出改進以適應WF的特點,神經網絡的優勢也無法發揮出來.另外,DBF相比其他2個神經網絡方法要更加輕便、運行速度更快.綜上,DBF在保證模型運行效率的同時,全方位地提高了模型的分類性能.
4 結 論
本文提出了一個基于神經網絡深度分析burst特征的網站指紋攻擊模型DBF,提高了神經網絡應用到WF攻擊技術上的適應性.DBF有效緩解了概念漂移問題和提高了小樣本訓練下模型的分類準確率等,相比已有研究的方法要更加輕便、運行速度更快,從提升性能的角度提高了WF攻擊技術應用到實際的可行性.但在OW場景下驗證模型對WF攻擊防御機制的突破能力實驗中,DBF出現了FPR過高的情況,這將對實際中的網絡管理帶來一定困難,也表明了DBF對WF攻擊防御機制的突破還有很大的提升空間.該問題的出現與DBF-OW的設計是相關的,因此下一步將研究對DBF-OW作出改進,使DBF-OW的設計更加精細,以更加有效地應對WF攻擊防御機制,有效降低在加持了防御機制下的FPR值,進一步提高WF攻擊技術在WF攻擊防御機制下的性能表現.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
