大數據評論釆集分析系統的設計與實現
2020-04-14 04:54:29韓帥康江濤張順
電腦知識與技術 2020年4期
關鍵詞:機器學習
韓帥康 江濤 張順

摘要:該設計以機器學習為基礎,通過編寫爬蟲程序對網上各大平臺公開評論信息進行采集并根據評分同時進行數據標注,以樸素貝葉斯分類算法為基礎,通過對數據的分詞,擬合出文本情感與文本的關系模型,從而達到一個相較于傳統情感字典更好的效果。同時以該算法為基礎,設計開發一套大數據評論采集分析系統,通過分析互聯網上的相關評論,將分析結果可視化展示給企業,幫助企業更好地了解產品的市場情況,定位產品的優缺點,從而幫助企業優化決策,制定合適的策略,獲得更佳的市場表現。
關鍵詞:文本采集;樸素貝葉斯;機器學習;語義分析
中國分類號:TP391.1
文獻標識碼:A
文章編號:1009-3044(2020)04-0035-03
Design and Implementation of Big Data Comment Collection and Analysis System
HAN Shuai-kang,JIANG Tao,ZHANG Shun
(School of Information Engineering,Zhengzhou University of Science and Technology,Zhengzhou 450054,China)
Abstract:This design is Based on machine learning,by writing crawlers of the major online platform for public comment information acquisition and according to the score data annotations at the same time,Based on the naive bayesian classification algorithm,Based on the data of participles,fitting out text emotional and relationship model of text,so as to achieve a better effect than traditional emotional dictionary.At the same time,on the basis of the algorithm,designed and developed a set of big comment on data acquisition analysis system,through the analysis of the comments of the Internet,showed the visualization analysis results to the enterprises,help enterprises to better understand the product of the market situation,the advantages and disadvantages of positioning products,thereby helping enterprise optimization decisions,formulate the right strategy,obtain a better market performance.
Key words:text collection;naive Bayes;machine learning;semantic analysis
1 概述
隨著互聯網時代的發展,越來越多的傳統行業諸如餐飲,酒店,旅游業,電影等逐漸由線下轉移到線上。用戶可以在體驗過后自由地發揮評論,長期以來,散布在互聯網上大量的文字信息并未受到合理的利用。而傳統的情感字典在分析一段文字情感的時候僅僅是對詞語進行簡單的計算,在準確率和可靠性上效果往往不盡人意,而釆用樸素貝葉斯分類算法通過對文本的標注,分詞,去停用詞,詞向量處理之后,所生成的模型往往可以應對很多復雜的文本情況,從而比傳統情感字典方式不論在準確率還是可靠性上都具有明顯的優勢。
2 設計方案與實現
2.1 數據采集與標注處理
2.1.1 數據采集方法
通過分析相應平臺網頁端與移動端的請求信息,定位到請求用戶評論的API接口,通過對該接口的研究,分析出來請求該接口所要求的格式,例如需要某些字段等,然后使用Python語言配合第三方Requests網絡框架,使用程序模擬用戶真實的請求,從而獲得我們所需要的評論數據,根據評分存儲到不同的文件中,方便后續的分析與處理。
2.1.2 數據標注方法
由于大多數平臺用戶在評論的時候都會添加相應的評分信息,而評分大多數情況都代表了用戶的情感傾向,比如五星好評的評論往往代表該用戶對于該產品的情感特征是較為積極正向的,而一星差評則往往代表用戶對于該產品情感特征是消極負向的,所以我們根據用戶評分的情況將評論主要分為兩類,一類是正向評論,標記值為1,一類為負向評論,標記值為0,具體的標注工作通過爬蟲程序在爬取評論信息的同時根據評分信息自動完成分類與標注。
2.2 數據分析算法與實現
2.2.1 樸素貝葉斯算法
貝葉斯分析來源于18世紀的英國數學家托馬斯貝葉斯所提出的一個數學領域可行性分析理論,即我們常說的貝葉斯理論,貝葉斯理論是統計學中的一個重要定理,其原理主要是根據已經發生的事件來推斷尚未發生的事件的可能性。
同時貝葉斯理論在垃圾郵件過濾等領域已經得到了充足的驗證和廣泛的使用,而基于樸素貝葉斯的文本情感分類,則是通過學習已經標注過情感傾向的文本信息,來分析一個新的未標注的文本情感為正向或者負向的概率。
樸素貝葉斯算法則是在貝葉斯算法的基礎上進行了相應的簡化,也就是在所有給定的目標值中,屬性之間是相互獨立的,同時屬性變量對于最后的決策結果影響所占的比重較小,雖然該方法在一定程度上有可能降低傳統貝葉斯算法在文本分類上的分類表現,但是由于做了簡化操作,使得樸素貝葉斯算法相較于貝葉斯算法在方法的復雜性上有所降低。
通過樸素貝葉斯算法在分析的過程中不斷地添加新的訓練集,理論上來說,樸素貝葉斯算法所學習的文本數據越多,那么對于一個新文本的分類結果就會越準確O
2.2.2 數據預處理
由于文本信息是沒有辦法直接當作樸素貝葉斯算法的輸入,所以在正式的擬合模型之前需要對數據進行一定的預處理,首先使用Python的中文分詞框架Jieba對數據集進行整體的分詞操作,這一步的目的是便于后續對數據集的去停用詞處理以及詞向量的計算工作。
數據的處理和展示則使用了Python語言的Pandas庫和Jupyter開發環境,首先打開之前爬蟲自動化程序從網絡上抓取并標注處理的程序,數據已經隨機打亂,其中評論數據總數為5176條,其中情感為正向的評論(sentiment=1)為3733條,情感為負向的評論(sentiment=0)為1433條。
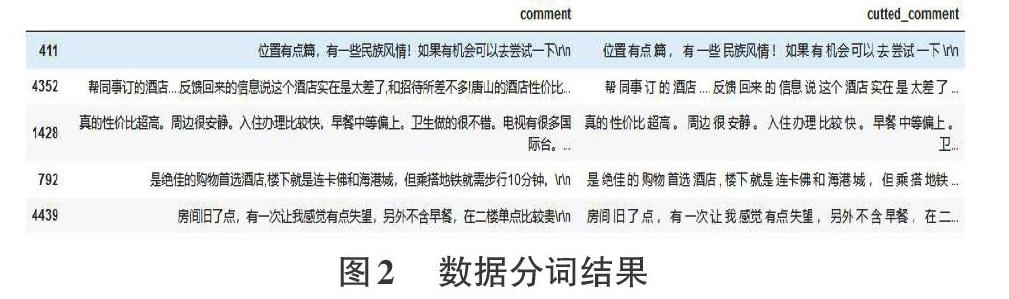
第二步是使用Jieba分詞庫對數據集進行分詞,并使用Sklearn庫對數據集進行隨機拆分,這一步分別將數據拆分成兩個部分,訓練集和測試集,其中訓練集和測試集根據標簽分別分為數據集和標簽集,分詞處理之后的數據如下:
如圖2所示,comment為評論數據,cutted_comment為分詞之后的評論數據,每組詞之間用空格作為分隔符。
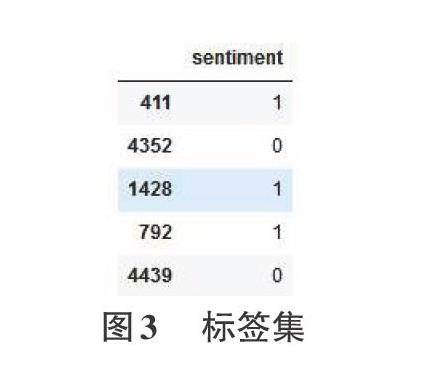
數據集對應的標簽集如圖3所示。
由于計算機本身并不能直接識別文本數據,所以最后一步則是對文本信息進行詞向量化處理,本例中則選用bag of words模型,即不考慮詞語的出現順序,也不考慮詞語和前后詞語之間的連接,每個詞都被當作一個獨立的特征來看待。同時去掉之前評論數據中的停用詞,停用詞是在計算機在處理文本數據時用于提高搜索效率會選擇過濾掉的特殊文本。比如中文中的“的”“這個”“吧”以及一些常見的標點符號都屬于停用詞。詞向量處理過之后的數據如下:
2.2.3 模型的生成與測試
經過數據預處理,下一步就可以將數據放入我們預先選擇好的算法之中了,在這里我們選擇的是Python語言Sklearn庫中的MultinomialNB,MultinomialNB是Sklearn庫提供的基于先驗為多項式分布的樸素貝葉斯算法。
將之前處理過的詞向量數據與訓練集中的標簽集作為輸入運行程序,利用Sklearn庫中的joblib類將模型保存為model,pkl文件,這樣在之后的預測計算中便無須每次進行訓練,即可直接使用,模型訓練出來之后便是測試模型的準確率,使用測試集進行測試之后,情感傾向分析的準確率為86.5%O
3 數據可視化展示
3.1 系統設計
模型構建好之后,下一步便是開發相應的可視化展示界面,即大數據評論采集分析系統的最后一個環節。整體的流程如下圖所示,用戶在客戶端輸入相應平臺的網址,爬蟲程序則根據網址去抓取相關的評論數據并進行數據清洗,標注等處理,之后將數據輸入到上文所構建的模型之中進行分析,最后將數據分析結果通過情感傾向分析、詞云展示、詞頻分析三個維度展示出來。
詞云制作使用Python詞云制作庫WordCloud庫,WordCloud是一款開源的基于Python語言的詞云制作框架,詞頻相關的分析則使用Matplotlib以及PIL庫。配合詞頻統計,最終將岀現頻率前十的詞匯,通過直方圖直觀地展示出來。
4 結束語
本文利用Python與Web自動化工具批量抓取互聯網各大平臺的評論數據依據評分策略進行數據的清洗和標注,并使用Jieba,Pandas,Numpy等數據分析工具將評論數據分詞,向量化,利用skleam中基于先驗為多項式分布的樸素貝葉斯算法以處理過的數據為輸入生成的機器學習模型并且保存到本地,并以此模型為基礎,使用Web開發技術完成大數據評論釆集分析系統的設計與實現,不論是企業或者個人,都可以通過在客戶端中輸入特定的鏈接,獲取到相關評論經過分析之后的情感傾向分析結果、詞云和詞頻分析的可視化展示,從而更好地挖掘評論數據中隱藏的信息,同時,該模型也可以用在互聯網輿情監控,非法言論攔截與檢測,用戶個性化推薦等領域。在今后的研究及實踐中,我們將加入更多例如影師評論,電商評論等行業數據,從而讓我們的系統獲得更高的準確率以及適用于更多的場景中。
參考文獻:
[1] 王龍龍.基于貝葉斯算法的垃圾郵件過濾系統設計與實現[D].長春:吉林大學,2014.
[2] 高雅,蘇艷,席方園.基于Python的新浪微博用戶數據采集與分析[J].電子設計工程,2019,27(20):157-160,165.
[3] 孟天樂.樸素貝葉斯在文本分類上的應用[J].通訊世界,2019(1):244-245.
[通聯編輯:謝媛媛]
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
