基于分數階灰色模型的農業用水量預測
2020-04-10 07:50:00宋松柏郭田麗王小軍
農業工程學報 2020年4期
李 俊,宋松柏,郭田麗,王小軍
基于分數階灰色模型的農業用水量預測
李 俊1,宋松柏1※,郭田麗1,王小軍2,3
(1. 西北農林科技大學水利與建筑工程學院,楊凌 712100;2. 南京水利科學研究院水文水資源研究所,南京 210029;3. 水利部應對氣候變化研究中心,南京 210029)
針對農業用水量序列的振蕩特性以及傳統灰色預測模型的過擬合問題,該文提出分數階灰色預測模型。將農業用水量振蕩序列轉化為單調遞減非負序列,并以轉化序列為基礎,根據“階數最大(或最小)”、“歷史數據擬合最好”2個目標函數構造優化模型,采用改進NSGA-II(non-dominated sorting genetic algorithm II,NSGA-II)進行模型求解。根據驗證集擬合結果優選出模型階數,結合分數階反向累加灰色模型(fractional order reverse accumulation grey model),以通遼市和寶雞市為例,進行農業用水量的預測。為了檢驗模型性能,將該文模型分別與傳統GM(1,1)模型、自回歸模型、基于小波分析理論組合模型進行對比。結果表明,該文模型對于通遼市、寶雞市與鄂爾多斯市的農業用水量預測的相對誤差分別為2.33%、0.31%和1.77%。同時,該文模型預測誤差最小(比自回歸模型分別低1.11%(通遼)、6.18%(寶雞);比傳統GM(1,1)模型分別低3.32%(通遼)、0.97%(寶雞)),具有一定實用性,研究結果可為區域農業用水量預測提供依據。
農業;水;模型;分數階;灰色預測;振蕩序列;過擬合;多目標優化
0 引 言
水資源優化配置是實現水資源可持續利用的重要手段[1]。準確預測通遼市、寶雞市用水量是發揮該地區水資源優化配置效用的關鍵[2]。在區域(通遼市、寶雞市)用水戶中,農業用水量占總用水量的70%以上[3],因此,農業用水量預測對于區域用水量預測具有重要的科學意義。
目前,農業用水量預測的方法主要有定額法[4]、BP神經網絡法[5]、自回歸滑動平均模型(autoregressive moving average model,ARMA)[6]、指數模型法[7]、灰色模型法[8-9]和系統動力學法[10]等200多種預測方法,其中常用方法有20~30種[11]。定額法主要依據作物特點與現行灌水定額進行預測,但灌水定額編制具有一定主觀性與不確定性,因此,定額法難以實現精確預測[12]。神經網絡法需要大量的數據進行模型訓練,同時還存在過擬合的問題[13-14]。ARMA模型與自回歸模型對數據的平穩性要求較高[15]。由于實際用水量序列并不完全符合指數關系,這也限制了指數模型法的應用范圍[16]。系統動力學方法需要的數據多、工作量大,而且對實際操作人員的要求高,影響了該方法的進一步推廣[16]。灰色模型是一種研究“貧信息”、“小樣本”和不確定性問題的方法[17],被廣泛應用于經濟、金融等領域。年農業用水量的歷史數據量不大,同時受到多種因素的影響,具有震蕩性,因此采用灰色模型對農業用水量進行預測具有一定適用性。
分數階灰色模型將模型階數從正整數擴展為正實數,能夠有效地提高灰色模型的預測精度[18]。在分數階灰色模型中,分數階反向累加灰色模型相對于傳統的GM(1,1)模型具有預測擾動小、能夠利用序列新信息等特點,受到許多學者關注[19]。雖然分數階反向累加灰色模型在某些情況下也適用于單調非負遞增數列[20],但主要是針對單調非負遞減序列[21],同時,實際的歷史用水數據具有一定的振蕩性。針對這些問題,需要將歷史用水數據轉化為單調非負遞減序列,文獻[22-24]提出將振蕩序列轉化為單調非負遞增序列的方法。為了適應分數階反向累加灰色模型對于單調非負遞減序列的要求,本文提出將振蕩序列轉化為單調非負遞減序列的方法,并以轉化后的數據為基礎,建立分數階反向累加GM(1,1)模型,進行未來農業用水量預測。
分數階反向累加灰色模型的階數對于模型預測效果有較大影響,以往階數的確定大多以“歷史數據擬合最好”為目標函數構造優化模型,使用智能優化算法對模型求解,并求得最終階數[20,25-27]。這種方法僅以歷史數據擬合程度作為目標函數,往往會造成過擬合,使模型對歷史數據中的噪聲過度學習。為解決這一問題,本文采用“階數最大(或最小)”、“歷史數據擬合最好”2個目標函數來構造多目標優化模型,應用Matlab編程,采用改進多目標遺傳算法(改進NSGA-II)對優化模型進行求解,獲得最優階數,構建分數階反向累加GM(1,1)模型。在此基礎上,選用內蒙古自治區通遼市和陜西省寶雞市為研究區,進行農業用水量預測。通過本文研究,以期為中國農業需水量預測研究提供新的研究手段和支撐。
1 改進分數階灰色預測模型
1.1 數據預處理
將收集到的歷史數據劃分為訓練數據、驗證數據和測試數據3種。由于歷史用水序列為振蕩序列,需要將訓練數據集、驗證數據集轉換為單調非負序列。
設訓練數據集、驗證數據集組成的有序序列為(1、2、…x、x1…x),其中,前個為訓練數據,為訓練數據集、驗證數據集數據的總量,記=max(x-x1|=1、2…),則通過式(1)可將振蕩序列轉化為單調非負遞減序列;
y=x-(-1)+│x-(-1)│+1(1)
式中y(=1、2…)為轉換后單調非負遞減的訓練數據序列。
1.2 分數階反向累加GM(1,1)模型
分數階反向累加GM(1,1)模型相對于傳統的GM(1,1)模型具有預測擾動小,能夠利用新信息的優點。根據分數階反向累加灰色模型原理,階反向累加算子可寫為[18]


模型的時間響應式為

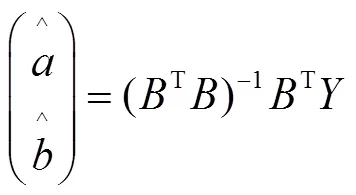
1.3 模型最優階數確定方法
1.3.1 基于歷史數據擬合確定最優階數
以歷史數據擬合最優為目標函數,可挖掘歷史數據的內在規律,為將來的預測奠定基礎[25-27],具體見式(5),但需要指出的是,過度依賴該式也會存在過擬合的風險。

式中2()表示模型對歷史數據擬合的程度。
1.3.2 最優階數確定方法的改進
為了克服計算模型過擬合問題,本文選用“階數最大(或最小)”為目標函數。同時結合式(5),構造多目標優化模型。

1()表示最大(或最小)階數。對于式(6),僅以式(5)為目標函數尋找模型階數會造成模型過擬合,因此,需要防止模型的過度學習,即防止對歷史數據的過度擬合。而歷史數據擬合效果與模型階數在不同區間會呈現出正相關或負相關關系。當兩者呈現正相關時,為了防止過擬合,需要減小階數以降低歷史數據擬合效果,即以階數最小為目標;而兩者呈現負相關時,則需要加大階數,即以階數最大為目標,因此,需要將式(6)的2種形式均進行試算,從而求出最優階數。
應用改進的NSGA-II對式(5)~(6)組成的優化模型進行求解,得到1個帕累托解集,將解集中的各階數代入分數階反向累加GM(1,1)模型,對驗證數據集中的數據預測,按照式(7)評價模擬效果,選出模擬效果最好的階數作為模型最終階數。

式中3()表示模型對驗證集數據預測的相對誤差。
根據求得的最終階數,結合分數階反向累加GM(1,1)模型對測試數據集的數據進行預測。
2 案例分析
2.1 研究區概況
本文選取內蒙古自治區通遼市(42°15′~45°59′N,119°14′~123°43′E)和陜西省寶雞市(33°35′~35°06′N,106°18′~108°03′E)為研究區域(見圖1),農業分別為2市的主要用水戶,占總用水量的70%以上,農業用水效率均在50%左右。2市分別為內蒙古自治區和陜西省糧食生產的主要基地之一[29-30],隨著社會經濟的發展,其他行業用水擠占了農業用水,水污染日益嚴重,2市的農業供水壓力加大。因此,有必要對2市的農業用水進行預測,以期為農業供水統籌規劃提供依據。根據《2007—2017年內蒙古自治區水資源公報》、《2007—2017年陜西省水資源公報》,收集通遼市和寶雞市2007—2017年農業用水量數據,參考文獻[31-33],按照6∶2∶2的比例設置為訓練數據、驗證數據和測試數據。研究區農業用水量見圖2。

文獻[22-24,34-35]提出,存在,∈(2,3,…)使x>x-1,x<x-1,則稱有序序列(1、2、…x、x1…x)為振蕩(波動)序列。按照振蕩(波動)序列的定義,從圖2可以看出,通遼市和寶雞市的農業用水量呈現一定的波動性(如通遼市2007年農業用水量大于2008年農業用水量,而2008年農業用水量小于2009年農業用水量,寶雞市2007年農業用水量小于2008年農業用水量,而2008年農業用水量大于2009年農業用水量)。

圖2 轉化后的數據與原始數據對比
2.2 模型應用及結果分析
2.2.1 數據預處理結果分析
為了使得訓練數據適應分數階反向累加灰色模型對于數據“平穩、單調遞減、非負”的要求,需要去除數據的波動性,轉化為單調遞減的非負序列。按照式(1)進行數據轉化,轉化后的數據與原始數據的對比見圖2,轉化結果見圖2。
由圖2可以看出,轉化后的數據為單調遞減序列,按照振蕩(波動)序列的定義,轉化后的序列不屬于振蕩序列,說明本文的轉化方法很好地去除數據的波動性。經過轉化后,使數據呈現單調遞減的趨勢,并且保持非負的特性,符合分數階反向累加模型對于基礎數據的要求。因此,數據轉化后在擴大模型適用范圍、提供模型較為合適的基礎數據等方面具有積極的作用。同時,最終預測結果需要逆向還原計算,消除轉化方式對模型的影響。
轉化后的數據符合“非負”和“單調遞減”的特性,可作為分數階反向累加模型的訓練與驗證數據集。
2.2.2 最優階數確定
為了確定最優階數,先以“階數最小”與“歷史數據擬合最好”為目標函數構造關于階數的多目標優化模型,并使用改進的NSGA-II對模型求解,求得帕累托前端。同樣,以“階數最大”與“歷史數據擬合最好”為目標函數構造關于階數的多目標優化模型,并使用改進的NSGA-II對模型進行求解,求得帕累托前端,見圖3。從圖3可以看出,解集都為帕累托解集,說明改進的NSGA-II具有較好求解效果。目前關于遺傳算法參數選擇問題并無統一的解決方法,主要通過全面試驗法等方法進行確定[36],本文參考文獻[37]的方法,通過數值模擬試驗,確定NSGA-II的參數。NSGA-II種群大小為1 000,進化代數為200代,最優前端個體系數為0.3,停止代數200,適應度函數偏差為e-1 000。

圖3 農業用水量模型最優階數確定帕累托解集
將帕累托前端中的階數逐個代入分數階反向累加GM(1,1)模型,進行驗證數據集數據模擬,并根據式(7)確定模型階數,驗證集預測誤差見圖4。由圖4可以得出,階數為0.976 1、0.006 2時,模型對于驗證數據集中數據的預測效果最好。因此,分別選定0.976 1、0.006 2為通遼市、寶雞市預測模型的最終階數。
2.2.3 模型比較與檢驗
為了對本文所提出模型的性能進行檢驗,將本文模型與傳統GM(1,1)模型[38]、自回歸模型[39]進行對比,其中各個模型對于測試集的預測效果見表1。

圖4 各個階數的預測誤差
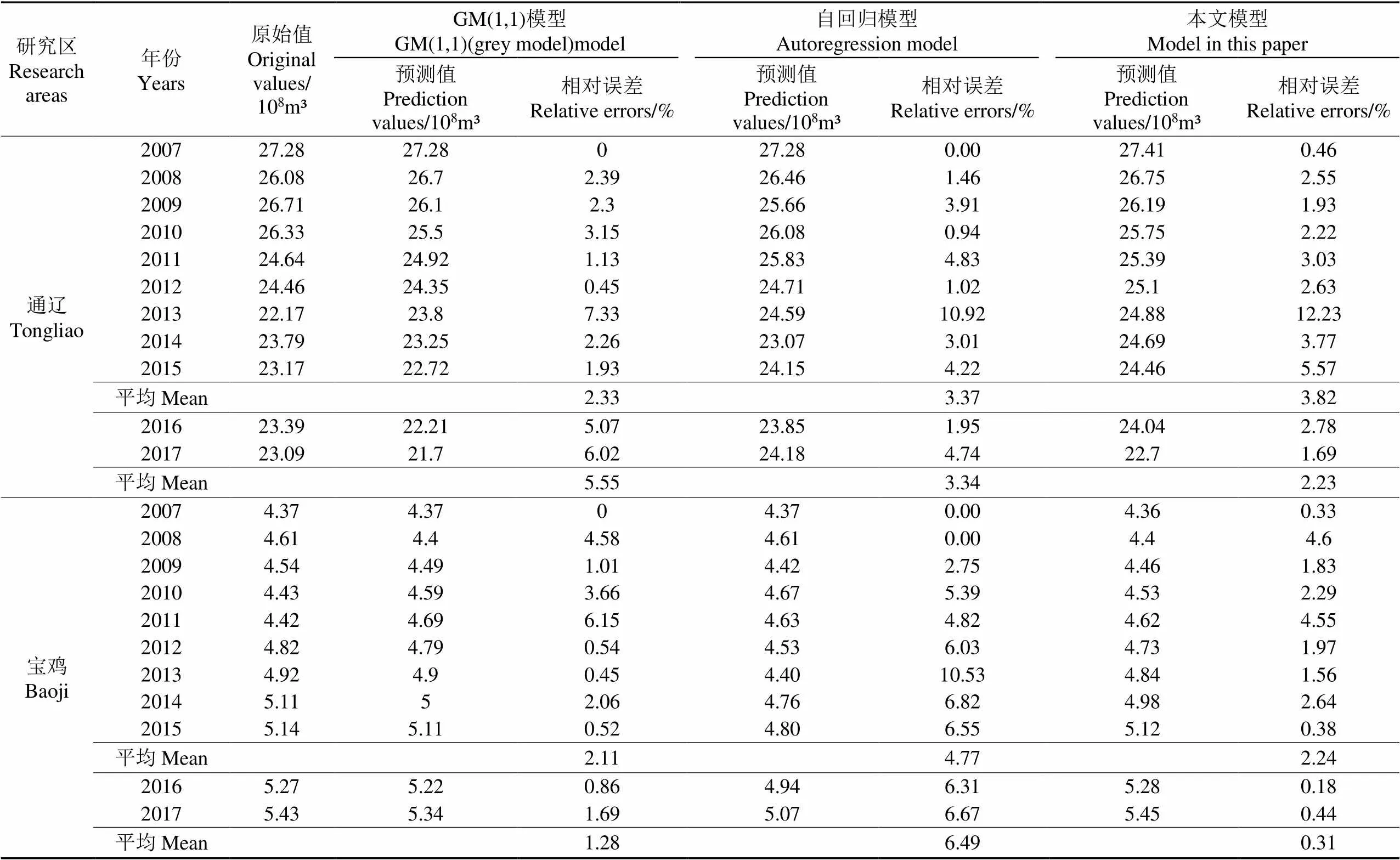
表1 各個模型預測效果對比
注:2016和2017年為測試集,其他年份為非測試集,用于模型率定。
Note: 2016 and 2017 belong to the test set, and other years belong to the non-test set for model parameters determination.
從表1可以看出本文模型對于通遼市和寶雞市測試集用水量的平均預測誤差分別為2.23%、0.31%,誤差較小,說明本文模型具有較好的泛化能力。
由表1還可以看出,對于非測試集的模擬,GM(1,1)模型具有最好的模擬效果,相對誤差為2.33%(通遼)、2.11%(寶雞),低于自回歸模型(3.37%(通遼)、4.77%(寶雞))和本文模型(3.82%(通遼)、2.24%(寶雞)),這與該模型以“歷史數據擬合最好”為目標訓練GM(1,1)模型(其中,寶雞:模型階數為1,為0.022,為4.258;通遼:模型階數為1,為-0.023,為27.634)有關,但會造成模型的過擬合,而本文模型在“歷史數據擬合最好”這一目標的基礎上,增加了“階數最大(或最小)”目標函數,防止模型出現過擬合,這也是本文模型(其中,寶雞:模型階數為0.006,為0.046,為-0.010;通遼:模型階數為0.976,為0.055,為-27.185)關于非測試集的學習誤差大于傳統GM(1,1)模型的原因,但正是因為本文模型沒有對歷史數據過度學習,減少了對歷史數據中噪聲的學習,具有較好的預測效果。
本文模型采用實數階替代整數階改進傳統灰色模型以正整數作為階數的做法,能夠有效提高模型精度[39],同時本文模型采用反向累加的方法,加大了對新數據的利用,使模型能夠充分利用新信息,有效處理新舊信息不一致的問題。增加“階數最大(或最小)”這一目標函數,能夠防止模型過擬合,增強模型泛化能力,這些也是本模型對測試集預測誤差小于GM(1,1)模型預測誤差的原因。
由于農業用水數據具有一定的震蕩性,會對數據的自相關性產生影響,而自回歸模型主要根據時間序列的前后依存關系進行建模[40],數據的振蕩對模型性能產生影響[41],因此自回歸模型的預測效果較差。相對于未對數據進行轉化的自回歸模型,本文增加數據轉化方法,使得振蕩序列轉化為單調遞減的非負序列,降低了數據的波動性,這也有助于提高本文模型的預測精度,同時也能擴大模型的適用范圍。
總的來看,本文模型能夠很好地預測農業用水量,為了進一步檢驗模型的性能,引用文獻[8]中鄂爾多斯農業用水數據進行預測分析,各模型預測結果如表2。

表2 不同模型對鄂爾多斯市農業用水量的預測結果
由表2可以看出,除了傳統GM(1,1)模型外(GM(1,1)預測模型未通過檢測),各模型的預測效果都較好,本文模型、自回歸模型和文獻[8]模型的預測結果相對誤差分別為1.77%、4.17%和2.87%,其中,本文模型的預測誤差最小,這說明本文模型對農業用水量的預測具有一定的適應性。
3 結 論
1)本文建立了改進分數階反向累加灰色模型。針對農業用水序列的振蕩性特點和分數階反向累加灰色模型的數據要求,提出一種將振蕩序列轉化為單調遞減非負序列的方法。為了能夠充分利用新數據的信息,采用反向累加的方式構造模型,并采用分數階“in between”的思想,將階數擴展到實數范圍,增強模型的精度。同時,為防止模型過擬合,在傳統目標(“歷史數據擬合最好”)的基礎上,加入“階數最大(或最小)”這一目標函數,建立有關階數的多目標優選模型,使用改進的NSGA-II對模型進行求解,并根據驗證集擬合的結果,優選出最優階數,結合分數階反向累加GM(1,1)模型,實現對測試集農業用水量的預測。
2)為了對模型的性能進行對比檢驗,選用內蒙古自治區通遼市和陜西省寶雞市農業用水量為基礎數據,將本文模型分別與傳統GM(1,1)模型、自回歸模型、基于小波分析理論組合模型進行對比,結果表明,本文模型對測試集的預測誤差最小,說明本文模型對于農業用水量預測具有一定適用性,可為農業用水預測研究提供支撐。
3)農業用水受氣候條件的影響,而且當氣候條件發生顯著變化時,會對氣候變化前后農業用水數據的一致性造成影響,從而使得在氣候變化前后,歷史數據會呈現出不同的模式。模型在訓練過程中,如果對氣候變化前的模式過度學習,則會對預測結果造成一定影響。本文模型訓練采用分數階與反向累加的方式,可以給予新數據較大的權重,使得模型學習過程中能夠充分利用新信息,加大氣候變化后的模式數據學習,在一定程度上,考慮不同氣象條件對農業用水的影響。同時,在未來的模型研究中應該考慮加入氣候因素,建立更為合理的用水量預測模型。
區域農業用水常常被其他行業用水擠占,農業用水除了受到自身影響因素的影響外,還受到其他行業用水情況的影響。因此,農業用水數據的震蕩性也較大。針對這一問題,本文提出一種數據轉化方法,減少了數據的波動性,提高了模型預測的精度。但是,其他行業用水與農業用水需求之間存在許多關聯,而這些關聯具有不確定性,預測過程較為復雜,有待于進一步深入研究。
[1]王浩,游進軍. 水資源合理配置研究歷程與進展[J]. 水利學報,2008,39(10):1168-1175. Wang Hao, You Jinjun. Advancements and development course of research on water resources deployment[J]. Journal of Hydraulic Engineering, 2008, 39(10): 1168-1175. (in Chinese with English abstract)
[2]王景雷,康紹忠,孫景生,等. 基于貝葉斯最大熵和多源數據的作物需水量空間預測[J]. 農業工程學報,2017,33(9):99-106. Wang Jinglei, Kang Shaozhong, Sun Jingsheng, et al. Spatial prediction of crop water requirement based on Bayesian maximum entropy and multi-source data[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(9): 99-106. (in Chinese with English abstract)
[3]黃修橋,高峰,王憲杰. 節水灌溉與21世紀水資源的持續利用[J]. 灌溉排水學報,2001,20(3):1-5. Huang Xiuqiao, Gao Feng, Wang Xianjie. Water saving irrigation and sustainable utilization of water resources in the 21st century[J]. Journal of Irrigation and Drainage, 2001, 20(3): 1-5. (in Chinese with English abstract)
[4]楊豐順,邵東國,顧文權,等. 基于Copula函數的區域需水量隨機模擬[J]. 農業工程學報,2012,28(18):107-112. Yang Fengshun, Shao Dongguo, Gu Wenquan, et al. Stochastic simulation of regional water requirement based on Copula function[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2012, 28(18): 107-112. (in Chinese with English abstract)
[5]張兵,袁壽其,成立,等. 基于L-M優化算法的BP神經網絡的作物需水量預測模型[J]. 農業工程學報,2004,20(6):73-76. Zhang Bing, Yuan Shouqi, Cheng Li, et al. Model for predicting crop water requirements by using L-M optimization algorithm BP neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2004, 20(6): 73-76. (in Chinese with English abstract)
[6]萬曉安,李析男,姚軍. 基于經濟定額法的農業灌溉需水預測研究[J]. 人民珠江,2018,39(4):25-31. Wan Xiaoan, Li Xinan, Yao Jun. Study on the prediction of agricultural irrigation water demand based on economic quota method[J]. Pearl River, 2018, 39(4): 25-31. (in Chinese with English abstract)
[7]常淑玲,尤學一. 天津市需水量預測研究[J]. 干旱區資源與環境,2008,22(2):14-19. Chang Shuling, You Xueyi. Prediction of water demand of Tianjin[J]. Journal of Arid Land Resources and Environment, 2008, 22(2): 14-19. (in Chinese with English abstract)
[8]佟長福,史海濱,包小慶,等. 基于小波分析理論組合模型的農業需水量預測[J]. 農業工程學報,2011,27(5):93-98. Tong Changfu, Shi Haibin, Bao Xiaoqing, et al. Application of a combined model based on wavelet analysis for predicting crop water requirement[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2011, 27(5): 93-98. (in Chinese with English abstract)
[9]Wu Hua’an, Zeng Bo, Zhou Meng. Forecasting the water demand in Chongqing, China using a grey prediction model and recommendations for the sustainable development of urban water consumption[J]. International Journal of Environmental Research and Public Health, 2017, 14(11): 1386.
[10]祁洪剛,陳亞寧,李慧敏,等. 基于系統動力學的新疆焉耆縣水資源需求分析[J]. 第四紀研究,2010,30(1):209-215. Qi Honggang, Chen Yaning, Li Huimin, et al. Analysis of water resources based on SD model in yanqi county[J]. Quaternary Sciences, 2010, 30(1): 209-215. (in Chinese with English abstract)
[11]王清印. 預測與決策的不確定性數學模型[M]. 北京:冶金工業出版社,2000.
[12]劉迪,胡彩虹,吳澤寧. 基于定額定量分析的農業用水需求預測研究[J]. 灌溉排水學報,2008,27(6):88-91. Liu Di, Hu Caihong, Wu Zening. Predicting method for demand of agriculture water based on quantitative analysis[J]. Journal of Irrigation and Drainage, 2008, 27(6): 88-91. (in Chinese with English abstract)
[13]劉磊. 基于遺傳神經網絡的指數跟蹤優化方法[J]. 系統工程理論與實踐,2010,30(1):22-29. Liu Lei. Index tracking optimization method based on genetic neural network[J]. Systems Engineering-Theory & Practice, 2010, 30(1): 22-29. (in Chinese with English abstract)
[14]Tetko I V, Livingstone D J, Luik A I. Neural network studies. 1. comparison of overfitting and overtraining[J]. Journal of Chemical Information and Modeling, 1995, 35(5): 826-833.
[15]黃雄波,胡永健. 利用自回歸模型的平穩時序數據快速辨識算法[J]. 計算機應用研究,2018,35(9):2643-2647. Huang Xiongbo, Hu Yongjian. Fast identification algorithm for stationary time series data using autoregressive model[J]. Application Research of Computers, 2018, 35(9): 2643-2647. (in Chinese with English abstract)
[16]黃修橋,康紹忠,王景雷. 灌溉用水需求預測方法初步研究[J]. 灌溉排水學報,2004(4):11-15. Huang Xiuqiao, Kang Shaozhong. Wang Jinglei. A preliminary study on predicting method for the demand of irrigation water resource[J]. Journal of Irrigation and Drainage, 2004(4): 11-15. (in Chinese with English abstract)
[17]鄧聚龍. 灰色預測模型GM(1, 1)的三種性質:灰色預測控制的優化結構與優化信息量問題[J]. 華中科技大學學報:自然科學版,1987(5):1-6. Deng Julong. Properties of grey forecasting models GM(1, 1)[J]. Journal of Huazhong University of Science and Technology: Natural Science Edition, 1987(5): 1-6. (in Chinese with English abstract)
[18]吳利豐,劉思峰,劉健. 灰色GM(1,1)分數階累積模型及其穩定性[J]. 控制與決策,2014,29(5):919-924. Wu Lifeng, Liu Sifeng, Liu Jian. GM(1, 1) model based on fractional order accumulating method and its stability[J]. Control and Decision, 2014, 29(5): 919-924. (in Chinese with English abstract)
[19]劉解放,劉思峰,吳利豐,等. 分數階反向累加離散灰色模型及其應用研究[J]. 系統工程與電子技術,2016,38(3):719-724. Liu Jiefang, Liu Sifeng, Wu Lifeng, et al. Fractional order reverse accumulative discrete grey model and its application[J]. Systems Engineering and Electronics, 2016, 38(3): 719-724. (in Chinese with English abstract)
[20]吳利豐,付斌. 分數階反向累加GM(1,1)模型及其性質[J]. 統計與決策,2017(18):33-36. Wu Lifeng, Fu Bin. GM (1, 1) model with fractional order opposite-direction accumulated generation and its properties[J]. Control and Decision, 2017(18): 33-36. (in Chinese with English abstract)
[21]練鄭偉,黨耀國,王正新. 反向累加生成的特性及GOM(1, 1)模型的優化[J]. 系統工程理論與實踐,2013,33(9):2306-2312. Lian Zhengwei, Dang Yaoguo, Wang Zhengxin. Properties of accumulated generating operation in opposite-direction and optimization of GOM(1,1) model[J]. Systems Engineering-Theory & Practice, 2013, 33(9): 2306-2312. (in Chinese with English abstract)
[22]錢吳永,黨耀國. 基于振蕩序列的GM(1,1)模型[J]. 系統工程理論與實踐,2009,29(3):149-154. Qian Wuyong, Dang Yaoguo. GM(1, 1) model based on oscillation sequences[J]. Systems Engineering-Theory & Practice, 2009, 29(3): 149-154. (in Chinese with English abstract)
[23]崔立志. 灰色預測技術及其應用研究[D]. 南京:南京航空航天大學,2010. Cui Lizhi. Grey Forecast Technology and Its Application Research[D]. Nanjing: Nanjing University of Aeronautics and Astronautics, 2010. (in Chinese with English abstract)
[24]曹菲. 隨機振蕩序列的灰色預測模型及其在氣象系統中的應用[D].西安:西安建筑科技大學,2015. Cao Fei. Grey Forecasting Model of Stochastic Oscillation Sequence and Its Application in Weather System[D]. Xi’an: Xi’an University of Architecture and Technology, 2015. (in Chinese with English abstract)
[25]劉解放,劉思峰,吳利豐,等. 分數階反向累加NHGM(1, 1, k)模型及其應用研究[J]. 系統工程理論與實踐,2016,36(4):1033-1041. Liu Jiefang, Liu Sifeng, Wu Lifeng, et al. Research on fractional order reverse accumulative NHGM(1, 1, k) model and its application[J]. Systems Engineering-Theory & Practice, 2016, 36(4): 1033-1041. (in Chinese with English abstract)
[26]曾亮. 分數階反向累加非等間距GM(1,1)模型及應用[J]. 應用數學和力學,2018,39(7):841-854. Zeng Liang. Non-equidistant GM(1, 1) models based on fractional-order reverse accumulation and the application[J]. Applied Mathematics and Mechanics, 2018, 39(7): 841-854. (in Chinese with English abstract)
[27]楊保華,趙金帥. 分數階離散灰色GM(1,1)冪模型及其應用[J]. 控制與決策,2015,30(7):1264-1268. Yang Baohua, Zhao Jinshuai. Fractional order discrete grey GM(1, 1) power model and its application[J]. Control and Decision, 2015, 30(7): 1264-1268. (in Chinese with English abstract)
[28]鄧聚龍. 灰色系統理論教程[M]. 武漢:華中理工大學出版社,1990.
[29]阿努赫. 水資源短缺條件下現代農業發展的必由之路:以通遼市、赤峰市為例[J]. 北方經濟,2012(15):45-46. A Nuhe. Only way to develop modern agriculture under the condition of water resources shortage: taking tongliao city and chifeng city as examples[J]. Northern Economy, 2012(15): 45-46. (in Chinese with English abstract)
[30]魏紅俠. 寶雞市農業用水現狀及節水灌溉措施[J]. 節水灌溉,2013(8):73-74. Wei Hongxia. Current situation of agricultural water use in baoji city and water saving irrigation measures[J]. Water Saving Irrigation, 2013(8): 73-74. (in Chinese with English abstract)
[31]Yang L, Kang H S, Zhou Y C, et al. Intelligent discrimination of failure modes in thermal barrier coatings: wavelet transform and neural network analysis of acoustic emission signals[J]. Experimental Mechanics, 2015, 55(2): 321-330.
[32]陳萬成,戴浩然,金映含. 基于數據挖掘方法的HEDONIC房屋價格評估模型:以美國城市西雅圖為例[J]. 數據分析與知識發現,2019,3(5):19-26. Chen Wancheng, Dai Haoran, Jin Yinghan. Appraising home prices with hedonic model: case study of seattle, U.S.[J]. Data Analysis and Knowledge Discovery, 2019, 3(5): 19-26. (in Chinese with English abstract)
[33]于露,金龍哲,王夢飛,等. 基于深度學習的人體低氧狀態識別[J]. 工程科學學報,2019,41(6):817-823. Yu Lu, Jin Longzhe, Wang Mengfei, et al. Recognition of human hypoxic state based on deep learning[J]. Chinese Journal of Engineering, 2019, 41(6): 817-823. (in Chinese with English abstract)
[34]王正新,黨耀國,裴玲玲. 基于GM(1,1)冪模型的振蕩序列建模方法[J]. 系統工程與電子技術,2011,33(11):2440-2444. Wang Zhengxin, Dang Yaoguo, Fei Lingling. Modeling approach for oscillatory sequences based on GM (1, 1) power model[J]. Systems Engineering and Electronics, 2011, 33(11): 2440-2444. (in Chinese with English abstract)
[35]王正新. 基于傅立葉級數的小樣本振蕩序列灰色預測方法[J]. 控制與決策,2014,29(2):270-274. Wang Zhengxin. Grey forecasting method for small sample oscillating sequences based on Fourier series[J]. Control and Decision, 2014, 29(2): 270-274. (in Chinese with English abstract)
[36]方睿,朱碧穎,粟藩臣. 基于模擬退火思想的遺傳算法參數選擇[J]. 計算機應用,2014,34(S1):114-116,126. Fang Rui, Zhu Biying, Su Fanchen. Genetic algorithm parameter tuning based on simulated annealing[J]. Journal of Computer Applications, 2014, 34(S1): 114-116,126. (in Chinese with English abstract)
[37]Jacquez J A.Design of experiments[J]. Journal of the Franklin Institute, 1998, 335(2): 259-279.
[38]劉思峰. 灰色系統理論及其應用. [M]. 第5版,北京:科學出版社,2010.
[39]Wu Lifeng, Liu Sifeng, Yao Ligen, et al. Grey system model with the fractional order accumulation[J]. Communications in Nonlinear Science and Numerical Simulation, 2013, 18(7):1775-1785.
[40]湯成友,官學文,張世明. 現代中長期水文預報方法及其應用[M]. 北京:中國水利水電出版社,2008.
[41]牛軍宜,馮平. 基于Markov狀態切換的水質時序自回歸預測模型[J]. 吉林大學學報:地球科學版,2010,40(3):657-664. Niu Junyi, Feng Ping. Water quality time series prediction based on markov switching autoregression model[J]. Journal of Jilin University:Earth Science Edition, 2010, 40(3): 657-664. (in Chinese with English abstract)
Prediction of agricultural water consumption based on fractional grey model
Li Jun1, Song Songbai1※, Guo Tianli1, Wang Xiaojun2,3
(1.,,712100,; 2.,,210029,; 3.,210029,)
Due to the shortage of water resources, serious water pollution, improper use of water and the occupation of agricultural water rights by other industries, China's agriculture will face the risk of water shortage in the future. Due to the amount of water resources in North China is relatively small compared with that in South China, coupled with extensive operating methods and the low level of agricultural irrigation technology, water resources are wasted seriously, the problem of agricultural water shortage in North China is more serious. Optimal allocation of water resources is one of the main measures to alleviate the shortage of agricultural water resources, and is an important means to achieve sustainable use of water resources. Accurate prediction of regional agricultural water consumption is the key to optimal allocation of water resources. Grey model is a method to study “poor information”, “small sample” and uncertainty problems, which is widely used in economics, finance and other fields. The amount of historical data of annual agricultural water consumption is not enough, which is affected by many factors, and has concussion. Therefore, it is suitable to use grey model to predict agricultural water consumption. The oscillation characteristics of agricultural water consumption data series have a certain impact on the prediction accuracy of the model. To resolve these problems, an improved fractional grey prediction model is proposed in this paper. Based on the monotonically decreasing non-negative series which transformed from the oscillation series of the agricultural water consumption, a multi-objective optimization model was constructed according to the two objective functions of “maximum (or minimum) order” and “the best fit of historical data”, which was solved by the improved non-dominated sorting genetic algorithm II (NSGA-II) method. Agricultural water consumption in the test set for the research areas of Tongliao city (42°15′N-45°59′N, 119°14′E-123°43′E), Ordos city (37°35′24″N-40°51′40″N, 106°42′40″E-111°27′20″E) of Inner Mongolia autonomous region and Baoji city(33°35′N-35°06′N,106°18′E-108°03′E) of Shaanxi province was predicted by the grey model (GM(1,1)) model of fractional order reverse accumulation, the order of which was optimized according to the results of the test set fitting. The average error of the prediction was 2.23%,1.77% and 0.31%, respectively. In order to test the performance of the model, the model proposed in this paper was compared with the traditional GM (1,1) model, traditional autoregressive model and the combined model based on the wavelet analysis theory respectively. Among them, the average prediction error of GM(1,1) model for the Tongliao and Baoji city is 5.55% and 1.28%, but the detection is failed for the Ordos city. The average prediction error of autoregressive model for the three research areas is 3.34%, 4.17% and 6.49%. The average prediction error of agricultural water consumption in Ordos City of Inner Mongolia Autonomous Region based on the combination model of wavelet analysis theory is 2.87%. The results show that compared with GM(1,1) model, the prediction effect of the model in this paper is better, which depends on the objective function of “the best fitting of historical data” and the objective function of “the largest (or the smallest) order” to reduce the learning degree of the model for noise, because the model in this paper transforms the oscillating data and reduces the uncertainty of the data, so compared with the autoregressive model without data processing, the model in this paper is less affected by data volatility. In this paper, the idea of fractional order “in between” is used to improve the traditional gray model with positive integer as order, which can effectively improve the accuracy of the model. At the same time, the method of reverse accumulation is used to increase the use of new data. On the whole, for the prediction of agricultural water consumption in all research areas, the model in this paper has the minimum error, strong generalization ability and certain practicability, which can provide a basis for the prediction of regional agricultural water consumption and the allocation of agricultural water resources in northern China.
agriculture; water; models; fractional order; grey prediction; oscillation sequence; overfitting; multi-objective optimization
李 俊,宋松柏,郭田麗,王小軍. 基于分數階灰色模型的農業用水量預測[J]. 農業工程學報,2020,36(4):82-89. doi:10.11975/j.issn.1002-6819.2020.04.010 http://www.tcsae.org
Li Jun, Song Songbai, Guo Tianli, Wang Xiaojun. Prediction of agricultural water consumption based on fractional grey model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(4): 82-89. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2020.04.010 http://www.tcsae.org
2019-05-06
2020-01-02
中央財政水資源節約、管理與保護項目(126302001000150005);國家自然科學基金項目(51479171、51179160、50879070)
李 俊,博士生,主要從事水資源優化配置研究。Email:13707513643@163.com
宋松柏,教授,博士,主要從事水文水資源研究。Email:ssb6533@nwsuaf.edu.cn
10.11975/j.issn.1002-6819.2020.04.010
TV213.4
A
1002-6819(2020)-04-0082-08
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
今日農業(2021年13期)2021-08-14 01:38:18
今日農業(2020年15期)2020-12-15 10:16:11
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
