基于強化學習的超參數(shù)優(yōu)化方法
2020-04-10 05:15:04陳森朋陳修云
小型微型計算機系統(tǒng) 2020年4期
陳森朋,吳 佳,陳修云
(電子科技大學 信息與軟件工程學院,成都 610054)
1 引 言
近年來,機器學習算法已成功應(yīng)用于眾多領(lǐng)域,但同時也面臨著巨大挑戰(zhàn).諸如隨機森林(Random Forest)[1]、XGBoost[2]和支持向量機(Support Vector Machines)[3]等機器學習算法在實際應(yīng)用的過程中存在繁瑣的超參數(shù)優(yōu)化過程.
超參數(shù)優(yōu)化對機器學習算法的性能起著至關(guān)重要的作用,然而機器學習算法的性能和超參數(shù)之間的函數(shù)關(guān)系尚不明確.在實際應(yīng)用中,往往通過不斷調(diào)整超參數(shù)的值來提高機器學習算法的實踐性能.當機器學習算法的超參數(shù)空間較大時,優(yōu)化過程將非常耗時和低效.因此,超參數(shù)優(yōu)化成為了機器學習算法應(yīng)用中的難點之一.
針對上述問題,本文提出了一種基于強化學習的超參數(shù)優(yōu)化方法(圖1).該方法將超參數(shù)優(yōu)化問題抽象為序列決策過程,即分步選擇待優(yōu)化算法的超參數(shù),這樣超參數(shù)選擇過程可建模為馬爾科夫決策過程(Markov Decision Process-MDP),進而采用強化學習來求解.具體的,該方法利用長短時記憶神經(jīng)網(wǎng)絡(luò)(Long Short-Term Memory Neural Network,LSTM)[4]構(gòu)建一個智能體(agent)來代替算法使用者設(shè)置超參數(shù)的值;然后,agent在訓練集上訓練算法模型,并在驗證數(shù)據(jù)集上得到該算法模型的驗證集性能,并以此為獎賞信號,利用策略梯度算法(Policy Gradient)[5]優(yōu)化agent的決策.
本文結(jié)構(gòu)如下:第2節(jié)介紹了超參數(shù)優(yōu)化問題的定義及相關(guān)工作;第3節(jié)詳細描述了本文所提出的超參數(shù)優(yōu)化方法以及如何減小訓練方差;第4節(jié)針對兩個具有代表性的機器學習算法,將本文所提出的方法與五種常用超參數(shù)優(yōu)化方法進行對比,并且討論了agent結(jié)構(gòu)和數(shù)據(jù)引導池的有效性;第5節(jié)總結(jié)全文并展望未來工作.
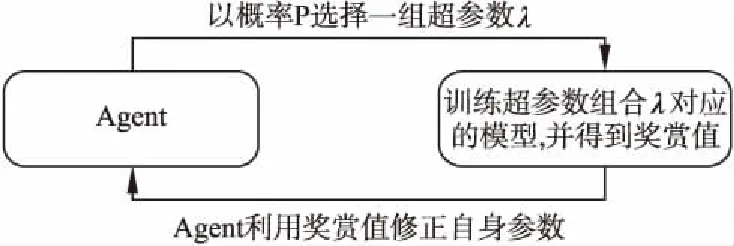
圖1 基于強化學習的超參數(shù)優(yōu)化方法Fig.1 Hyperparameter optimization method basedon deep reinforcement learning
2 背景及相關(guān)工作
超參數(shù)優(yōu)化問題(HPO)的通常定義為:假設(shè)一個機器學習算法M有N個超參數(shù),第n個超參數(shù)空間為Λn,那么算法的超參數(shù)搜索空間為Λ= Λ1×Λ2×…ΛN.Mλ表示超參數(shù)為λ的算法,其中向量λ∈Λ為算法M的一個超參數(shù)組合.當給定數(shù)據(jù)集D,HPO問題的優(yōu)化目標為最優(yōu)的超參數(shù)組合λ*:
λ*=argminE(Dtrain,Dvalid)~DL(Mλ,Dtrain,Dvalid)
(1)
其中,Dtrain和Dvalid分別表示訓練集和驗證集;L(Mλ,Dtrain,Dvalid)表示算法Mλ在數(shù)據(jù)集D上的交叉驗證誤差,以此作為損失函數(shù)值.
近年來,具有代表性的超參數(shù)優(yōu)化方法有隨機搜索(Random Search)、貝葉斯優(yōu)化(Bayesian Optimization),TPE(Tree-structured Parzen Estimator)以及自適應(yīng)協(xié)方差矩陣進化策略(CMA-ES)算法.隨機搜索方法[6]在超參數(shù)搜索空間中隨機采樣,執(zhí)行效率高且操作簡單,經(jīng)過多次搜索可以獲得性能較好的超參數(shù)組合.然而,隨機搜索方法穩(wěn)定性較差,且只有在達到或接近最優(yōu)值的超參數(shù)組合的比重超過5%時,搜索效率較高.自適應(yīng)協(xié)方差矩陣進化策略(CMA-ES)算法[7]是一種基于進化算法的改進算法,主要用來解決非線性、非凸的優(yōu)化問題,但算法運行具有一定的隨機性,優(yōu)化性能不穩(wěn)定.貝葉斯優(yōu)化[8,9]方法使用高斯過程對代理函數(shù)進行建模,以一組超參數(shù)λ為條件對優(yōu)化目標y進行建模,形成先驗?zāi)P蚉(y|λ).雖然該方法能夠達到很好優(yōu)化結(jié)果,但是隨著迭代次數(shù)增加,優(yōu)化過程耗費大量時間.文獻[10]實驗證明了基于高斯過程的貝葉斯優(yōu)化方法在一些標準任務(wù)上優(yōu)于隨機搜索方法.另一種貝葉斯優(yōu)化的變體是基于序列模型的優(yōu)化方法(SMAC)[11],該方法使用隨機森林對代理函數(shù)進行建模.與基于高斯過程的貝葉斯優(yōu)化方法類似,TPE[12]是一種基于樹狀結(jié)構(gòu)Parzen密度估計的非標準貝葉斯優(yōu)化算法,也能達到很好的優(yōu)化性能.
相比于上述工作,本文的創(chuàng)新點主要有以下幾點:
1)將超參數(shù)優(yōu)化問題抽象為序列決策問題并建模為MDP,分步選擇超參數(shù),提高優(yōu)化效率;
2)采用強化學習智能體(agent),并使用策略梯度算法進行訓練以避免直接求解超參數(shù)優(yōu)化的黑盒目標函數(shù),從而搜索到最優(yōu)超參數(shù)組合;
3)提出數(shù)據(jù)引導池技術(shù),降低訓練方差,提高方法穩(wěn)定性.
3 基于強化學習的超參數(shù)優(yōu)化方法
3.1 整體結(jié)構(gòu)
針對超參數(shù)優(yōu)化問題(HPO),本文提出了一種基于強化學習的優(yōu)化方法.該方法將超參數(shù)優(yōu)化問題抽象為序列決策問題(即每次決策只選擇一個超參數(shù))是基于以下原因:
1)一個復雜問題通常通過分解成多個易于求解的子問題來解決.由于一個復雜機器學習算法具有巨大的超參數(shù)空間,同時進行所有超參數(shù)的選擇極具困難.
2)相反的,如果agent分步進行超參數(shù)選擇,整個搜索空間可大大縮小,從而提高搜索效率.
我們將上述的序列決策過程建模為MDP,即M=(S,A,P,R):
·S表示狀態(tài)集合,st∈S,st表示t時刻環(huán)境的狀態(tài),即agent的輸入;
·A表示動作集合,at∈A,at表示t時刻的agent選擇的動作,即超參數(shù)選擇;
·P表示在當前狀態(tài)s下,執(zhí)行動作a后,環(huán)境轉(zhuǎn)移到下一狀態(tài)的概率.在HPO問題中它是未知的;
·R表示reward函數(shù),R:S×A→R,R表示在當前狀態(tài)s下執(zhí)行動作a的獎勵值,即為超參數(shù)配置的驗證集準確度.
Agent的目標是找到一個策略π:S→A使得累積收益最大化.Agent工作流程如下:對每一次迭代,agent以概率P為算法模型選擇一組超參數(shù)λ;然后在訓練數(shù)據(jù)集Dtrain上訓練算法模型Mλ;最后將Mλ在驗證數(shù)據(jù)集Dvalid上的準確率作為獎賞值,并利用策略梯度算法[5]來更新策略.經(jīng)過多次訓練,agent會以更高的概率選擇準確率高的超參數(shù)配置.為了確保該方法具有更好的穩(wěn)定性,提出了數(shù)據(jù)引導池以減小訓練方差.
3.2 詳細設(shè)計
3.2.1 Agent結(jié)構(gòu)設(shè)計
根據(jù)3.1節(jié),我們將超參數(shù)優(yōu)化問題看作一個序列決策問題,即每個時刻針對某個超參數(shù)進行選擇,因此不同時刻優(yōu)化了不同的超參數(shù),這樣可以大大減少每次決策的搜索空間.為了更加清晰的說明序列選擇超參數(shù)的優(yōu)勢,我們將進一步分析超參數(shù)優(yōu)化的搜索空間.假設(shè)一個算法具有N個待優(yōu)化的超參數(shù).一種簡單的方法是將超參數(shù)優(yōu)化問題看作一個多臂機問題(multi-armed bandit problem),直接在整個超參數(shù)搜索空間中選擇整個超參數(shù)配置,則決策的搜索空間為:Λ=Λ1×Λ2×…ΛN(×表示笛卡爾乘積).相反,如果我們將超參數(shù)優(yōu)化問題作為序列決策問題,基于前一次決策順序的選擇每一個超參數(shù),則決策的搜索空間為:Λ=Λ1∪Λ2∪…ΛN.顯然,后者能夠大大縮減超參數(shù)優(yōu)化問題的搜索空間,從而提高優(yōu)化效率.
為了適應(yīng)順序選擇超參數(shù)的方法,我們將agent設(shè)計為自循環(huán)的結(jié)構(gòu).每次循環(huán)時,我們將agent上一次的輸出作為agent下一次的輸入,以保持超參數(shù)優(yōu)化的整體性.同時,由于超參數(shù)之間可能存在相關(guān)性,也就是每個時刻的選擇可能是相互關(guān)聯(lián)的.若只將超參數(shù)優(yōu)化問題分步進行,而不考慮超參數(shù)之間的內(nèi)部關(guān)系,超參數(shù)的優(yōu)化順序則會成為一個影響因素.基于上述特點,我們利用LSTM構(gòu)造了一個強化學習agent(圖2).使用LSTM網(wǎng)絡(luò)作為agent的核心結(jié)構(gòu)的主要原因在于:LSTM網(wǎng)絡(luò)獨特的內(nèi)部設(shè)計能夠使agent保留或遺忘超參數(shù)之間的內(nèi)在聯(lián)系,從而有利于超參數(shù)選擇,也避免了由于超參數(shù)優(yōu)化順序而造成的影響.盡管LSTM 網(wǎng)絡(luò)的訓練比較困難,但是LSTM網(wǎng)絡(luò)被認為是解決時序問題的最好結(jié)構(gòu).
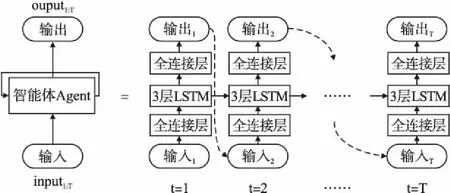
圖2 Agent結(jié)構(gòu)圖Fig.2 Structure of agent
圖2展示了agent內(nèi)部結(jié)構(gòu),圖中左邊部分表示agent整體結(jié)構(gòu),右邊部分 (“=”右)表示按時間步展開的agent結(jié)構(gòu).Agent的核心結(jié)構(gòu)由3層LSTM網(wǎng)絡(luò)構(gòu)成,且輸入、輸出與LSTM網(wǎng)絡(luò)之間各有一個全連接層,該全連接層用來調(diào)整前后輸入和輸出的維度.在每一時刻t(t∈[1,T],T為待優(yōu)化模型的超參數(shù)個數(shù)),agent選擇一個超參數(shù)at,并將at的one-hot編碼作為下一時刻agent的輸入,也就是t+1時刻狀態(tài)st+1為at.在t=1時刻,agent輸入狀態(tài)s1為全1向量.
通過這樣的設(shè)計,agent在不同時刻只需選擇對應(yīng)的超參數(shù),減小了超參數(shù)的搜索空間.同時,由于將前一時刻的輸出作為下一時刻的輸入,使得采用LSTM網(wǎng)絡(luò)作為核心結(jié)構(gòu)的agent能夠?qū)W習超參數(shù)之間的潛在關(guān)系.
3.2.2 Agent訓練
策略梯度方法[5]使用逼近器(函數(shù))來近似表示策略,通過不斷計算策略期望的總獎賞并基于梯度來更新策略參數(shù),最終收斂于最優(yōu)策略.它的優(yōu)點非常明顯:能夠直接優(yōu)化策略的期望總獎賞,并以端對端的方式直接在策略空間中搜索最優(yōu)策略,省去了繁瑣的中間環(huán)節(jié).因此,本文采用策略梯度方法訓練agent.
假設(shè)θ表示agent的模型參數(shù);R表示agent在每次選擇超參數(shù)組合a1:T后,與所選擇的超參數(shù)組合結(jié)合的待優(yōu)化模型在驗證數(shù)據(jù)集上的準確率.定義期望的總獎賞值為:
J(θ)=EP(a1:T;θ)[R]
(2)
其中,P(a1:T;θ)表示表示參數(shù)為θ的agent輸出超參數(shù)組合a1:T的概率.
Agent的訓練目標是找到一個合理的參數(shù)θ使得期望獎賞值J(θ)最大化:
(3)
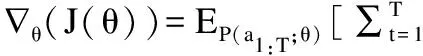
(4)
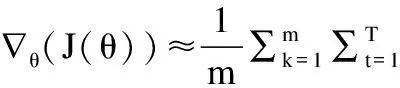
(5)
其中,T為待優(yōu)化算法的超參數(shù)個數(shù);Ri為在第i個超參數(shù)組合下模型的k-折交叉驗證結(jié)果;b是基準值,即模型交叉驗證結(jié)果的指數(shù)移動平均值.
3.2.3 數(shù)據(jù)引導池(Boot Pool)模塊
在使用本文所提出的方法進行超參數(shù)優(yōu)化時,雖然添加了基線函數(shù)b減小訓練誤差,但是仍存在訓練方差較大的問題,造成其優(yōu)化結(jié)果穩(wěn)定性較差.為此,我們提出了數(shù)據(jù)引導池模塊.
數(shù)據(jù)引導池是一個固定大小的存儲區(qū)域,用來保存最優(yōu)的K條(top-K)超參數(shù)組合及對應(yīng)獎勵值.在agent訓練過程中,引導池中的數(shù)據(jù)會根據(jù)新的采樣數(shù)據(jù)進行實時更新,并定期提供給agent進行學習.若K過大,則使得引導過強,陷入前期較差的局部最優(yōu)值;若K過小,則引導力度變?nèi)酰呗愿嗟倪M行探索,從而導致訓練不穩(wěn)定.事實上,通過對參數(shù)K的調(diào)整來平衡策略的利用和探索.
4 實驗結(jié)果及分析
在實驗中,我們將隨機森林和XGBoost兩種算法作為超參數(shù)優(yōu)化對象,使用UCI數(shù)據(jù)庫中的五個標準數(shù)據(jù)集作為實驗數(shù)據(jù)集(表1).為了驗證本文提出方法的性能,我們將本文所提出的方法與隨機搜索優(yōu)化方法、基于貝葉斯的優(yōu)化方法、TPE優(yōu)化方法、CM-AES優(yōu)化方法和SMAC優(yōu)化方法進行了對比.此外,通過一系列消融實驗來驗證agent結(jié)構(gòu)和數(shù)據(jù)引導池的有效性.
4.1 實驗細節(jié)
數(shù)據(jù)集:實驗中,我們選擇五個大小各異的UCI數(shù)據(jù)集作為優(yōu)化任務(wù)(詳細信息見表1).UCI數(shù)據(jù)集是常用的、種類豐富的數(shù)據(jù)集.在實驗中,每個數(shù)據(jù)集按照8:2的比例分成訓練集和測試集兩部分.實驗在訓練集下采用5-折交叉驗證的方法訓練待優(yōu)化模型;訓練完成后,使用測試集測試超參數(shù)優(yōu)化方法的最終性能.
參數(shù)設(shè)置:在實驗中,所有參數(shù)均是選擇多個隨機種子中的最優(yōu)參數(shù).針對不同的優(yōu)化任務(wù),我們設(shè)置了不同的學習率α和數(shù)據(jù)引導池大小K(詳細信息見表1).基準函數(shù)的折扣系數(shù)γ設(shè)置為0.8.以-0.2與0.2之間的隨機值對網(wǎng)絡(luò)中的權(quán)重進行初始化.
搜索空間:實驗中我們選擇對隨機森林(6個超參數(shù))和XGBoost(10個超參數(shù))兩種分類算法進行超參數(shù)優(yōu)化(詳細信息見表2),隨機森林和XGBoost算法的具體實現(xiàn)基于scikit-learn[13].選擇上述兩種算法進行優(yōu)化主要是由于:
1)文獻[14]中評估了179種機器學習分類算法在UCI數(shù)據(jù)集上的表現(xiàn),實驗結(jié)果表明隨機森林分類算法是最優(yōu)的分類器;XGBoost算法具有更多的待優(yōu)化超參數(shù),并且解決分類任務(wù)具有很大的潛力;
表1 數(shù)據(jù)集信息及對應(yīng)參數(shù)設(shè)置表
Table 1 Data sets information and parameter settings
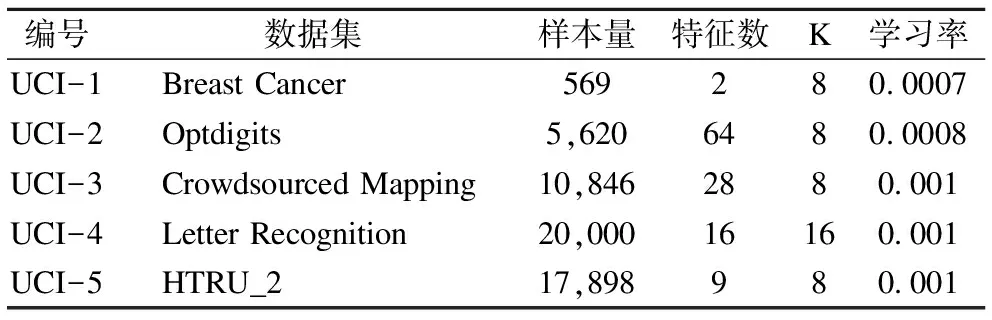
編號數(shù)據(jù)集樣本量特征數(shù)K學習率UCI-1Breast Cancer569280.0007UCI-2Optdigits5,6206480.0008UCI-3Crowdsourced Mapping10,8462880.001UCI-4Letter Recognition20,00016160.001UCI-5HTRU_217,898980.001
2)兩種算法均屬于先進的分類算法,廣泛應(yīng)用在數(shù)據(jù)科學競賽和工業(yè)界.
表2 隨機森林算法和XGBoost算法的超參數(shù)搜索空間
Table 2 Hyperparameters search spaces of the random forest
and the XGBoost
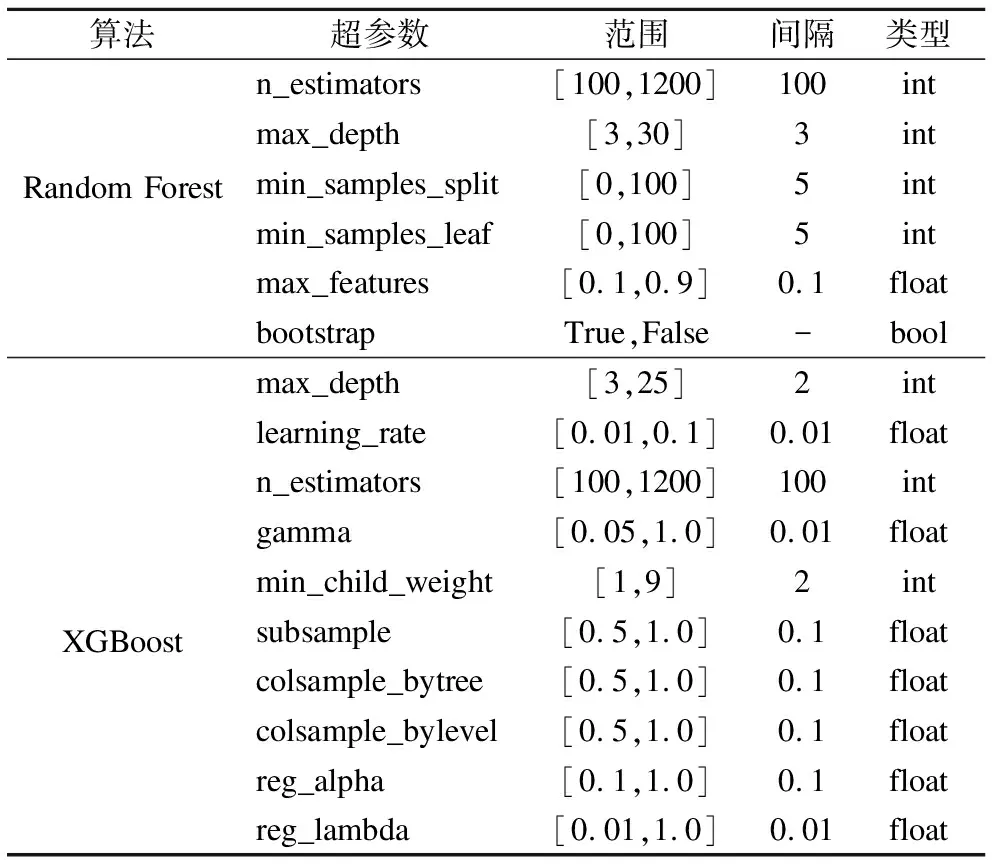
算法超參數(shù)范圍間隔類型Random Forestn_estimators[100,1200]100intmax_depth[3,30]3intmin_samples_split[0,100]5intmin_samples_leaf[0,100]5intmax_features[0.1,0.9]0.1floatbootstrapTrue,False-boolXGBoostmax_depth[3,25]2intlearning_rate[0.01,0.1]0.01floatn_estimators[100,1200]100intgamma[0.05,1.0]0.01floatmin_child_weight[1,9]2intsubsample[0.5,1.0]0.1floatcolsample_bytree[0.5,1.0]0.1floatcolsample_bylevel[0.5,1.0]0.1floatreg_alpha[0.1,1.0]0.1floatreg_lambda[0.01,1.0]0.01float
4.2 Agent結(jié)構(gòu)的有效性
本小節(jié)中,我們將驗證agent結(jié)構(gòu)的有效性,即驗證將超參數(shù)優(yōu)化問題作為序列決策問題的正確性.實驗中,我們所提出的方法簡稱為BP-Agent,同時也設(shè)計了對比方法BP-FC:該方法使用全連接網(wǎng)絡(luò)(FC)作為agent的核心結(jié)構(gòu),并且直接使用全連接網(wǎng)絡(luò)一次輸出所有超參數(shù)的選擇,而不是逐步選擇超參數(shù).為了滿足對比實驗的公平性,我們確保BP-FC方法中的全連接網(wǎng)絡(luò)的可訓練參數(shù)的數(shù)量與本文提出的方法的可訓練參數(shù)量大致相等.另外,該方法也采用了引導池技術(shù)(BP)來減小訓練過程的方差.為充分利用計算資源,我們在UCI-(1-4)數(shù)據(jù)集上進行對比實驗,每組對比實驗獨立執(zhí)行3次,每種優(yōu)化方法每次獨立運行300分鐘.實驗結(jié)果如圖3和圖4所示.圖中,分別展示了本文所提出的方法(BP-Agent)和對比方法(BP-FC)在驗證集上的訓練過程.我們可以看出:BP-FC方法使用全連接網(wǎng)絡(luò)直接輸出所有超參數(shù)的選擇,在部分任務(wù)上具有優(yōu)化效果,但優(yōu)化效果較差,并且優(yōu)化效率低;相比于BP-Agent方法,BP-Agent方法具有更好的優(yōu)化效果和穩(wěn)定性,也具有更高的優(yōu)化效率.因此,上述實驗證明將超參數(shù)優(yōu)化問題序列化.并逐步選擇超參數(shù)的agent設(shè)計有利于提高優(yōu)化性能.
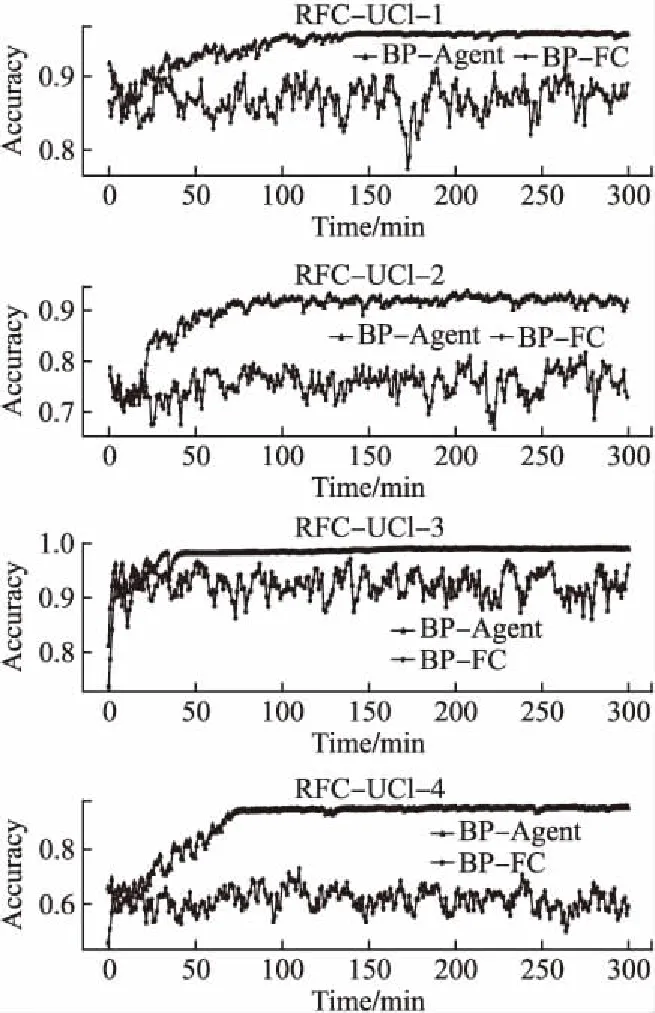
圖3 不同agent結(jié)構(gòu)在四個UCI數(shù)據(jù)集上優(yōu)化隨機森林的性能比較圖Fig.3 Performance comparison of agents with different structures for optimizing Random forests on four UCI datasets
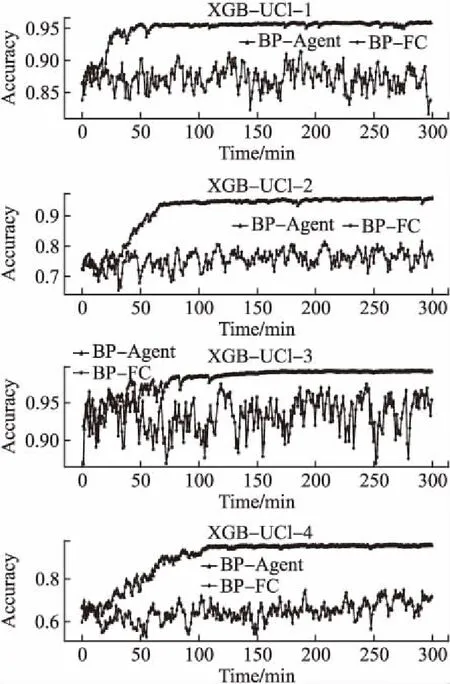
圖4 不同agent結(jié)構(gòu)在四個UCI數(shù)據(jù)集上優(yōu)化XGBoost的性能比較圖Fig.4 Performance comparison of agents with different structures for optimizing XGBoost on four UCI datasets
4.3 數(shù)據(jù)引導池模塊對優(yōu)化結(jié)果的影響
為了驗證數(shù)據(jù)引導池的有效性,我們設(shè)計了BP-Agent方法(含有BP模塊)與Agent方法(不含有BP模塊)的對比實驗.我們在UCI-(1-4)數(shù)據(jù)集下對隨機森林和XGBoost算法的超參數(shù)進行優(yōu)化,每種優(yōu)化方法在每個優(yōu)化任務(wù)上獨立運行5次,對比5次優(yōu)化的平均性能.
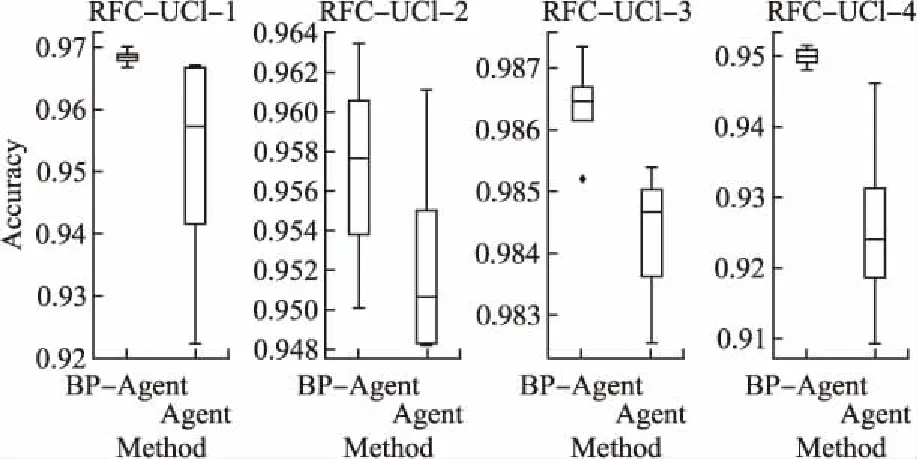
圖5 BP-Agent和Agent方法在四個UCI數(shù)據(jù)集上優(yōu)化隨機森林的性能比較圖Fig.5 Performance comparison of the BP-Agent and the Agent for optimizing Random forests on four UCI datasets
實驗結(jié)果以箱型圖的形式展示,如圖5和圖6所示.通過觀察可以發(fā)現(xiàn):Agent方法能夠達到很好優(yōu)化效果(即箱型圖的中位數(shù)),但是其穩(wěn)定性較差(即箱型圖的觸須);相比于Agent方法,BP-Agent方法具有更好的優(yōu)化結(jié)果,并且其穩(wěn)定性較好.因此,可以得出以下結(jié)論:添加方向引導池能夠把握優(yōu)化方向,增強方法的穩(wěn)定性.
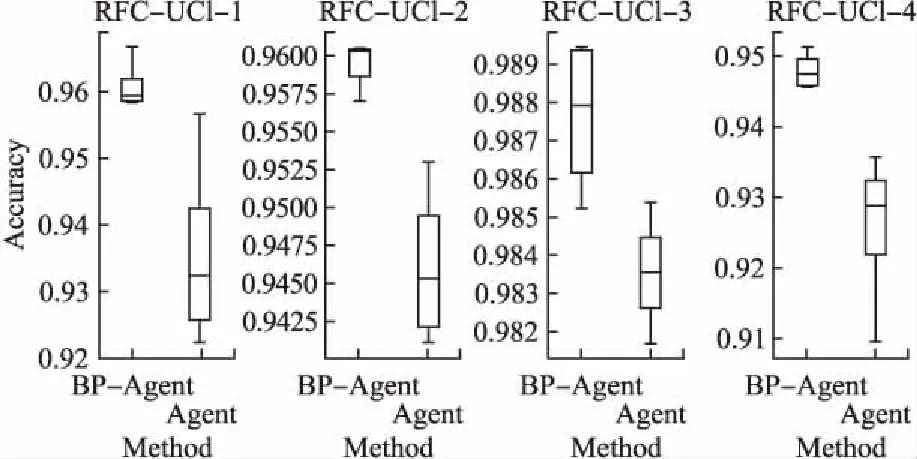
圖6 BP-Agent和Agent方法在四個UCI數(shù)據(jù)集上優(yōu)化XGBoost的性能比較圖Fig.6 Performance comparison of the BP-Agent and the Agent for optimizing XGBoost on four UCI datasets
4.4 對比BP-Agent方法與其他優(yōu)化方法
為了進一步驗證本文所提出的方法,我們將其與常用的且具有代表性的五種優(yōu)化方法(隨機搜索,TPE,貝葉斯優(yōu)化,CM-AES,SMAC)進行對比.除此之外,我們也將對比隨機森林和XGBoost兩個算法默認超參數(shù)配置的性能,默認的超參數(shù)配置基于scikit-learn[13].實驗在UCI-(1-5)數(shù)據(jù)集上分別優(yōu)化隨機森林和XGBoost兩個分類算法的超參數(shù),因此共包含10個優(yōu)化任務(wù).同樣的,為充分利用計算資源,每組對比實
1https://github.com/hyperopt/hyperopt-sklearn
2https://github.com/AIworx-Labs/chocolate
3https://github.com/mlindauer/SMAC3
驗獨立執(zhí)行3次,每種優(yōu)化方法每次獨立運行300分鐘.隨機搜索、TPE和貝葉斯優(yōu)化三種方法的具體實現(xiàn)基于Hyperopt1,CM-AES方法的具體實現(xiàn)基于Chocolate2,SMAC方法的具體實現(xiàn)基于SMAC33.
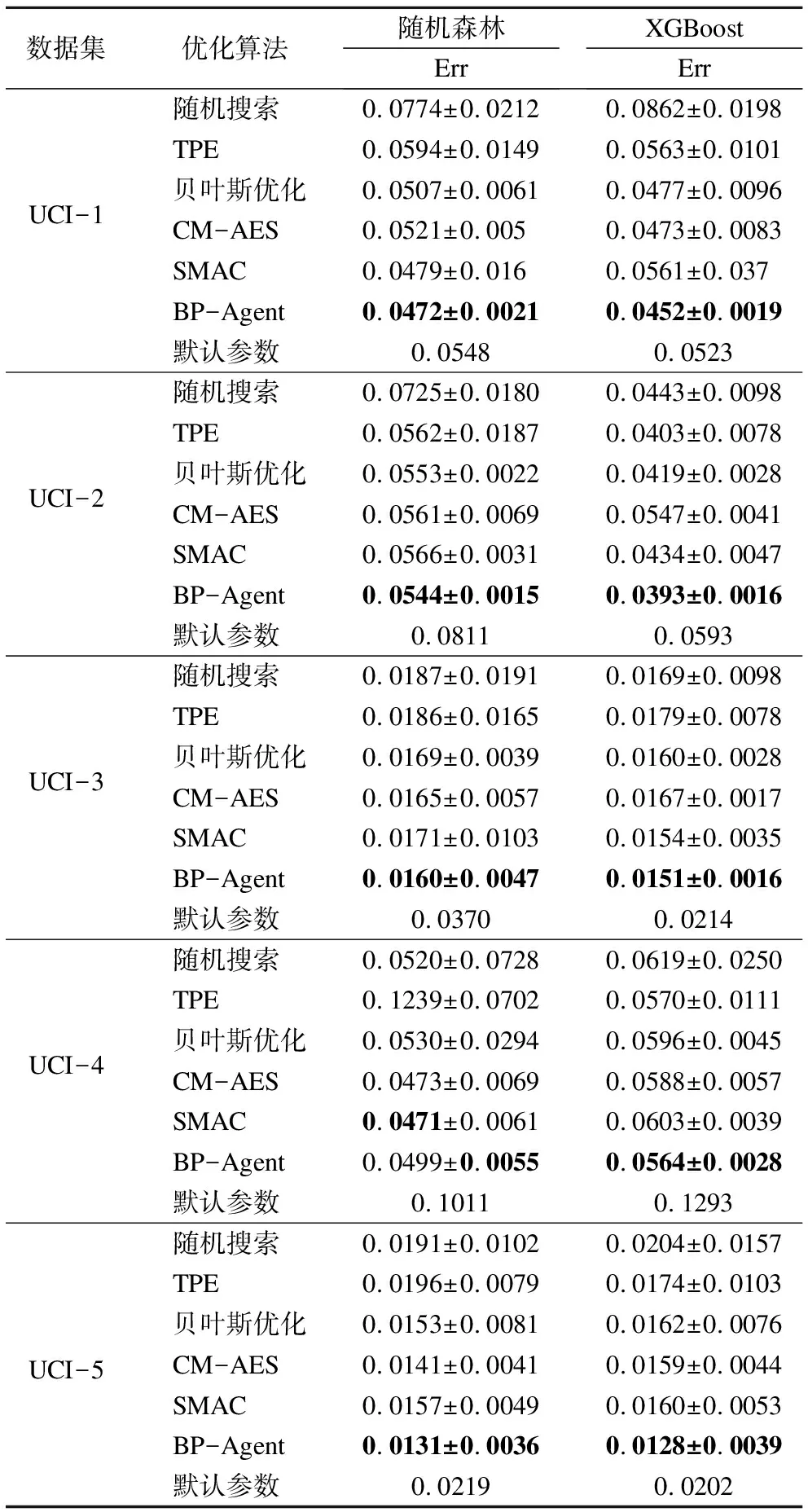
對比指標選取的是待優(yōu)化模型在測試集上的錯誤率(如表“Err”所示).實驗結(jié)果以3次對比實驗的Err平均值和方差進行展示(詳細實驗結(jié)果見表3),不僅能夠表示待優(yōu)化模型在測試集上的準確度,還能夠反映優(yōu)化方法的穩(wěn)定性.通過觀察表中實驗數(shù)據(jù),可以看出:所有的優(yōu)化方法在大部分優(yōu)化任務(wù)上都能得到優(yōu)于默認參數(shù)性能的超參數(shù)配置.具體的,在10個優(yōu)化任務(wù)中,貝葉斯優(yōu)化、CM-AES和SMAC三種優(yōu)化方法都達到了很好優(yōu)化結(jié)果,且具有很好的穩(wěn)定性,而隨機搜索和TPE兩種優(yōu)化方法的優(yōu)化性能相對較差;相比之下,BP-Agent方法在8個優(yōu)化任務(wù)中分別達到了最好的優(yōu)化結(jié)果和穩(wěn)定性.
表3 六種超參數(shù)優(yōu)化方法的性能對比表
Table 3 Performance comparison of five
HPO optimization methods
數(shù)據(jù)集優(yōu)化算法隨機森林ErrXGBoostErrUCI-1隨機搜索0.0774±0.02120.0862±0.0198TPE0.0594±0.01490.0563±0.0101貝葉斯優(yōu)化0.0507±0.00610.0477±0.0096CM-AES0.0521±0.0050.0473±0.0083SMAC0.0479±0.0160.0561±0.037BP-Agent0.0472±0.00210.0452±0.0019默認參數(shù)0.05480.0523UCI-2隨機搜索0.0725±0.01800.0443±0.0098TPE0.0562±0.01870.0403±0.0078貝葉斯優(yōu)化0.0553±0.00220.0419±0.0028CM-AES0.0561±0.00690.0547±0.0041SMAC0.0566±0.00310.0434±0.0047BP-Agent0.0544±0.00150.0393±0.0016默認參數(shù)0.08110.0593UCI-3隨機搜索0.0187±0.01910.0169±0.0098TPE0.0186±0.01650.0179±0.0078貝葉斯優(yōu)化0.0169±0.00390.0160±0.0028CM-AES0.0165±0.00570.0167±0.0017SMAC0.0171±0.01030.0154±0.0035BP-Agent0.0160±0.00470.0151±0.0016默認參數(shù)0.03700.0214UCI-4隨機搜索0.0520±0.07280.0619±0.0250TPE0.1239±0.07020.0570±0.0111貝葉斯優(yōu)化0.0530±0.02940.0596±0.0045CM-AES0.0473±0.00690.0588±0.0057SMAC0.0471±0.00610.0603±0.0039BP-Agent0.0499±0.00550.0564±0.0028默認參數(shù)0.10110.1293UCI-5隨機搜索0.0191±0.01020.0204±0.0157TPE0.0196±0.00790.0174±0.0103貝葉斯優(yōu)化0.0153±0.00810.0162±0.0076CM-AES0.0141±0.00410.0159±0.0044SMAC0.0157±0.00490.0160±0.0053BP-Agent0.0131±0.00360.0128±0.0039默認參數(shù)0.02190.0202
另外,我們對實驗結(jié)果進行統(tǒng)計檢驗.假設(shè)顯著性水平α=0.05,檢驗結(jié)果顯示:在具有優(yōu)勢的8個優(yōu)化任務(wù)中,BP-Agent的性能提升均具有顯著性差異(P<0.05).
上述實驗表明本文所提的BP-Agent方法能夠得到更好優(yōu)化結(jié)果,且具有最好的穩(wěn)定性.
4.5 討論與分析
對于超參數(shù)優(yōu)化問題,當前工作主要分類三類:基礎(chǔ)搜索方法[10]、基于采樣的方法[15,16]和基于梯度的方法[17-19].雖然當前新方法層出不窮,超參數(shù)優(yōu)化問題仍面臨以下難點:
1)優(yōu)化目標屬于黑盒函數(shù).對于給定任務(wù),超參數(shù)選擇與性能表現(xiàn)之間的函數(shù)無法顯式表達.
2)搜索空間巨大.由于每種待優(yōu)化算法都有相應(yīng)的超參數(shù)空間,選擇的可能性是指數(shù)級的.
3)耗費巨大的資源.當評估所選擇的超參數(shù)配置時,需要進行完整的訓練過程并在測試集上測試最終性能,整個優(yōu)化過程耗費大量計算資源和時間.
通過實驗可以看出,本文所提出的方法能夠在大部分任務(wù)達到最好的優(yōu)化結(jié)果,并具有很好的穩(wěn)定性.我們認為主要原因在于:在超參數(shù)選擇過程中,由于逐個選擇超參數(shù),因此每次選擇只需針對當前超參數(shù)的搜索空間進行探索,而不需要搜索整個超參數(shù)空間,這樣可以極大地提高搜索效率;同時,我們選擇LSTM網(wǎng)絡(luò)作為agent的核心結(jié)構(gòu),使agent能夠在分步?jīng)Q策過程中學習超參數(shù)選擇的內(nèi)在聯(lián)系;另外,訓練過程中添加了數(shù)據(jù)引導池(BP)模塊,在一定程度上平衡了策略的探索和利用,使得優(yōu)化方法性能更加穩(wěn)定.
5 結(jié)束語
隨著機器學習的廣泛應(yīng)用,快速高效的解決超參數(shù)優(yōu)化問題(HPO)越來越重要.針對超參數(shù)優(yōu)化問題(HPO),本文提出了一種基于強化學習的超參數(shù)優(yōu)化方法.該方法將超參數(shù)優(yōu)化問題看作序列決策問題,即將復雜問題分解為多個易于求解的子問題來解決.進一步將該問題抽象為MDP,利用強化學習算法來求解該問題.具體的,以LSTM網(wǎng)絡(luò)為核心構(gòu)造agent,逐步為待優(yōu)化的機器學習算法選擇超參數(shù).Agent的動作(action)為超參數(shù)的選擇;agent的輸入,即狀態(tài)(state)為上一時刻的動作選擇;待優(yōu)化算法在驗證數(shù)據(jù)集上的準確率作為獎賞值(reward).
為了驗證所提出方法的有效性,我們選擇了五個UCI數(shù)據(jù)集,分別對隨機森林和XGBoost這兩種算法的超參數(shù)進行優(yōu)化.通過對比隨機搜索、TPE、貝葉斯優(yōu)化、CM-AES和SMAC五種具有代表性的超參數(shù)優(yōu)化方法,我們發(fā)現(xiàn)本文提出的方法在優(yōu)化結(jié)果和穩(wěn)定性上均優(yōu)于對比方法.同時,一系列消融實驗驗證了agent結(jié)構(gòu)和數(shù)據(jù)引導池的有效性.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
