經濟評論情感分析與評分
2020-04-07 04:17:40劉志強余薇溫和銘孔樅李欣
經濟技術協作信息 2020年4期
◎劉志強 余薇 溫和銘 孔樅 李欣
一、引言
隨著人們參與經濟活動日益頻繁,人們每天會接觸到成百上千條經濟評論文本數據,評論者的情感傾向和態度往往會對讀者造成影響。有學者的研究表明人們在做出選擇或決策前,通常傾向于參考他人的評論信息。因此對經濟評論文本中經濟特征進行情感分析及評分可謂頗具意義,它能較好地反映了人們對某經濟事件的情感認知傾向,在個人的經濟決策,企業的經營決策,甚至國家的政治與經濟政策中發揮一定的作用,以實現個人經濟效用的最大化和社會經濟資源的最優配置。
文本情感分析,又稱為意見挖掘,是利用自然語言處理技術、數據挖掘算法等對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程。目前情感分析的主要方法有:基于情感詞典的情感分析方法、基于機器學習的情感分析方法和基于深度學習的情感分析方法。賈春光在卷煙評論方面應用基于情感詞典的方法進行情感分析,實驗明基于詞典的情感分析方法在具體領域文本情感分析中仍具有優勢。李明等使用樸素貝葉斯、支持向量機(SVM)、決策樹、K 最鄰近算法(KNN)四種機器學習分類方法對商品評論進行情感分析,比較結果之后發現支持向量機(SVM)算法具有較好的情感分類效果。高歡等在單一機器學習模型的基礎上使用集成學習進行情感分析,將邏輯回歸、隨機森林、輕量梯度提升機三種分類方法聚集在一起,以提高情感分類準確率。近年來,深度學習方法在情感分析領域引起了許多關注。顧軍華等提出一種基于卷積注意力機制的神經網絡模型(CNN_attention_LSTM),能夠突出文本關注重點的情感詞與轉折詞,在具有轉折詞的文本中能更精確地判別文本情感傾向。楊善良等將條件隨機場模型與循環神經網絡模型LSTM 相結合,形成基于注意力機制的LSTM-CRF-Attention 模型,能夠有效提高文本數據情感特征的抽取效果。Hossein Sadr 等將卷積和遞歸神經網絡合并到一個新的魯棒模型中,捕捉了長期的語句間語義依賴關系,并減少本地信息丟失,優于基本的卷積神經網絡和遞歸神經網絡模型。
本文將情感分析方法應用于經濟評論領域,考慮到經濟評論中情感詞的領域性、評論文本長度較短,采用基于情感詞典的情感分析方法。同時,采用該方法人工提取情感特征能夠從一定程度上減少情感特征提取環節模型中的誤差。另外,本文在傳統基于情感詞典的情感分析方法的基礎上進行改進,引入互信息和左右熵新詞發現方法提高分詞精度,將ITD*MI 算法[8]應用于情感詞加權,進一步提高該方法情感分析準確度,解決經濟評論領域的情感分析問題。
二、情感分析技術與方法
本文充分考慮經濟評論文本較短、含有趨勢詞詞組、含有經濟專業詞匯的特點,構建經濟評論情感分析體系。對于文本數據的分詞問題,采用中科院分詞系統NLPIR-ICTCLAS 進行分詞,再使用互信息和左右熵新詞發現方法對分詞結果進一步改進。對于領域情感詞典構建,本文在基礎情感詞、拓展情感詞的基礎上,加入人工篩選獲得的領域情感詞,共同構建領域情感詞詞典。在情感分析中,對于情感詞的加權問題,本文采用ITD*MI 方法對文本中的情感詞進行加權,對于趨勢詞詞組按該評論中的情感詞權重均值進行加權,將情感詞加權評分和趨勢詞詞組加權評分相加獲得該評論最終情感評分。
1.經濟評論文本數據的特點。
經濟評論文本數據具有文本句子短、包含大量經濟趨勢詞、不完全遵循語法規則、難以通過有限句子信息在當前句子的語境給出明確判斷的特點,而且經濟評論文本數據有別于一般的評論數據的一大顯著特點是它涉及經濟金融領域各類專業術語,講究不同的詞語搭配方法和句式結構。
以下簡要舉例說明經濟評論文本數據一些顯著特點:
(1)經濟評論文本數據一般句子較短,但包含眾多信息,需要在特定的語境下才能全面理解,其中包含的不同情感色彩因句而異。
(2)經濟評論文本中有大量的專業術語有別于一般的評論文本,比如"做多"、"利好"、"通脹"等,這些專業詞匯在特定語境下都可以展示不同的情感色彩。
(3)經濟評論文本數據中涉及眾多趨勢詞詞組,比如"再創新高"、"漲勢低迷"、"觸底反彈"、"成本降低"等等,它們在經濟金融領域都涉及一定的情感色彩。
而且在經濟評論文本的情感分析中存在一些特殊情況。因經濟評論文本中有很多的特殊的詞語搭配,要結合語境分析情感傾向,如果通過分詞單獨分析個別詞語則會造成一定謬誤。因此注意不同詞語間的相互修飾,及詞語搭配,而不是單獨分析個別詞語的情感極性有助于提高文本情感分析的準確度。另外,經濟評論文本中否定詞也會影響分詞結果的情感傾向判斷,否定詞會改變整個句子的句意,如:"不 盡如人意",否定詞"不"將褒義詞"盡如人意"的反轉為貶義詞。
2.分詞方法。
對收集的語料進行分詞,英文單詞是以空格作為分隔符,而漢字詞語之間沒有明顯標記,因此中文分詞是文本情感分析不可或缺的一步。對比結巴分詞的效果,我們選擇使用中科院分詞系統NLPIR-ICTCLAS 進行分詞工作。NLPIR 分詞系統含有中文分詞、新詞發現、詞性標注等多種功能,可以較好得對我們的語料進行分詞。經濟領域內專有名詞較多,為了提高分詞精確度,在NLPIR 分詞系統的基礎上,再利用互信息與左右熵來對分詞結果進行完善。互信息指體現詞語間語義相關程度的量,其計算方法如公式(2-1)所示。
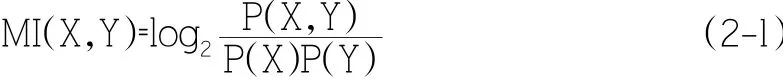
其中,MI(X,Y)指兩相鄰詞的互信息值,P(X)為詞X 出現的概率,P(Y)為詞Y 出現的概率,X 和Y 指兩相鄰詞,互信息值越高,表明兩相鄰詞相關性越高,其組成短語的可能性越大;同理,互信息值越低,則表明兩相鄰詞組成短語的可能性較小。
信息熵最初被定義為離散隨機事件的出現概率,左右熵則表示詞表達中左邊界的熵與右邊界的熵,用來體現詞表達中的自由程度。此處以左熵為例,其計算方法如公式(2-2)所示。
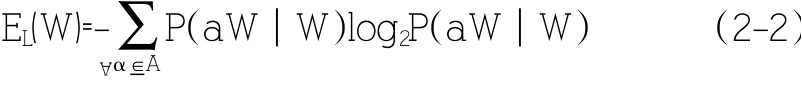
其中,EL(W)指預選詞左邊界的信息熵,W 指預選詞,aW 為位于預選詞左邊的詞匯,P(aW|W)為條件概率,即為預選詞為W時,左邊界出現的aW 的概率,左右熵值越大,表明預選詞左邊與右邊更換的詞越多,則該預選詞越有可能是單獨的詞。利用互信息與左右熵來提高新詞發現效果,從而達到較好的分詞精度。
3.領域情感詞典構建方法。
構建情感詞典,目前的研究有兩種思路:一種是基于語義計算,一般可根據知網情感詞計算語義相似度,計算目標詞語跟基準詞之間的緊密程度,得以判定情感極性;另一種是基于統計分析,計算目標詞語基準詞之間的點互信息值,確定兩個詞之間的緊密程度,從而獲取目標詞的情感傾向。
為了提高情感分類的準確性,建立專門的經濟領域情感詞典,本文選擇基于語義計算構建情感詞典,該情感詞典由基礎詞和領域詞構成。基礎情感詞由現有的知網Hownet 情感詞典和臺灣大學簡體中文情感極性詞典構建。領域情感詞典是指用于某一特定領域文本語料進行分詞的情感詞典。其在基礎情感詞典的基礎上采取人工提取情感特征的方法,構建經濟評論情感詞典,這類基礎情感詞必須要人工標記,在基礎情感詞之上,配合爬取的經濟評論進行分詞、人工篩選劃分得到評論情感詞匯,將情感詞分類別歸納,得到適用于經濟評論的情感詞典。
4.情感詞加權方法。
(1)ITD*MI 算法介紹。
在文本情感分析范疇,情感詞權重通常考慮兩個影響因素:該詞在文本中的重要性(ITD)和其在表達情感上的重要性(ITS)。Deng 等人在情感詞加權測試中,將ITD 和基于交互信息(MI)的ITS 結合的算法效果最佳,記為ITD*MI 算法。
(2)公式表示。
首先引入相關定義,將積極評論的集合記為V1,消極評論的集合記為V2。設X={X1,X2...,Xn}為V1_V2中的所有情感詞。設待分析的經濟評論為Cj,情感詞Xi在經濟評論Cj中的加權為Wij,則Cj可由特征向量Cj={W1,W2j...,Wnj}表示。加權Wij由兩部分構成,一是ITD(Xi,Cj),表示情感詞Xi在經濟評論Cj中的重要程度,計算方法如公式(3):

其中,Xij表示Xi在Cj中出現的次數。
Wij的另一組成是ITS(Xi),表示Xi在情感傾向表達上的重要性,在ITD*MI 算法中,用MI(Mutual Information,交互信息)表示,計算方法如公式(2-1)。
其中概率的解釋見表2-1。

表2-1 概率含義解釋
對于給定的情感詞Xi,其ITS(Xi)定義為:
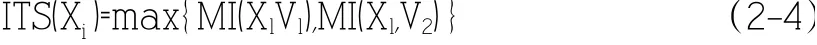
綜上,得到情感詞Xi在經濟評論Cj中的加權:
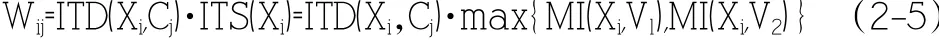
三、數據與實證
根據以上分析,本文構建經濟評論情感分析體系(如圖3-1)。
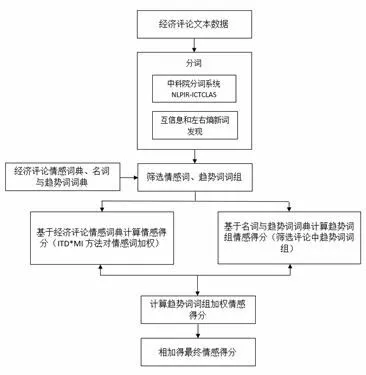
圖3-1 經濟評論情感分析流程圖
1.數據來源。(1)網站選擇。
Alexa 是世界權威的網絡流量統計機構,專業發布各大網站的世界排名,即Alexa 排名。本文考慮Alexa 排名,選擇排名較前的經濟網站作為語料庫的原始文本數據來源。
(2)話題選擇。
百度指數(index。baidu。com)是一個數據分享平臺,它以海量百度用戶的網絡行為作為基礎數據,是當今數據時代和互聯網十分重要的統計分析平臺之一。可以利用百度指數可以獲取當期人們對經濟熱詞的關心程度。近期由于豬肉價格的上漲人們對豬肉價格的關注度越來越高;國家對于發展區塊鏈技術高度重視,在未來的技術發展與產業變革中區塊鏈技術發揮著不容小視作用,是國內經濟發展的有效動力;科創板的設立給股市中股民一個新的投資方向,所以話題會相對較多;對于直播經濟來說,網絡直播在一定程度上能夠刺激公眾消費,帶動經濟發展,是一種新型的營銷手段,這其中有利有弊,成為了人們評論的焦點。因此,本文選取豬肉價格、區塊鏈、科創板、直播經濟這4個熱門話題進行實驗研究。
2.數據處理。
(1)數據獲得。
本文通過Alexa 綜合排名(2020 年3 月數據)查詢經濟評論類權威網站,最終選擇"財經騰訊網"、"新浪財經"、"搜狐財經",作為經濟評論原始文本數據來源。利用爬蟲獲得的原始評論分別為:區塊鏈1180 條、科創板1210 條、直播經濟863 條、豬肉價格1384 條。
(2)數據清洗。
由于網絡爬蟲獲取的原始數據格式混亂,有部分原始數據由于評論主題偏移、非經濟評論、重復等原因不可用。先對原始數據去重,再篩選關鍵詞,去掉不相關評論后,得到可用經濟評論:區塊鏈1111 條、科創板1111 條、直播經濟830 條、豬肉價格1359 條。
(3)分詞。
使用python 中的NLPIR 分詞包對文本數據進行分詞,再利用左右熵互信息新詞發現算法對分詞結果進一步細化。
3.經濟評論情感詞典。
(1)基礎情感詞與拓展情感詞。
通用情感詞典的構建主要通過現已開源的基礎情感詞典來構建,本文選擇知網Hownet 情感詞典以及臺灣大學簡體中文情感極性詞典去重及刪除無用詞后整合構建基礎情感詞典。Hownet 是一個以漢語和英語的詞語所代表的概念為描述對象,以揭示概念與概念之間以及概念所具有的屬性之間的關系為基本內容的常識知識庫。
(2)經濟領域情感詞。
領域情感詞典是指利用某一特定領域的大量語料所構建的情感詞典,用來對這一領域的文本語料進行分析。與通用情感詞典相比,領域情感詞典在用于特定領域的具體情感分析任務中精確度更高,總體更具實用性。本文通過分詞,人工篩選得到所選經濟名詞的1.033 個常用情感詞匯。
4.經濟評論情感詞加權。
為了直觀地反映情感詞的情感傾向,在爬取得到經濟評論里,對抽取出來的1000 多個情感詞,對比所構建的經濟評論情感詞典,劃分積極傾向和消極傾向,再根據ITD*MI 算法得到的加權分別排名。積極情感加權排名前五的情感詞有"創新"、"發展"、"復蘇"、"可觀"、"歡迎",消極情感加權排名前五的情感詞有"悲觀"、"虧損"、"危機"、"非理性"、"風險"。
對比加權結果發現,根據ITD*MI 算法,在經濟評論中出現次數較多的情感詞ITD 較高,而在兩類經濟評論頻率相差較大的情感詞普遍可以獲得更高的ITS,比如創新(973(積極評論頻率),13(消極評論頻率))、發展(658,9)、悲觀(18,834)、虧損(12,572)。綜合來看,加權較高的情感詞具有出現頻率高、情感極性明顯的特點。
5.趨勢詞詞組。
(1)名詞與趨勢詞詞典。
經濟評論中含有大量趨勢詞詞組,這些詞組所包含的情感傾向不可忽略。因此,為了計算趨勢詞詞組的情感評分,本文構建經濟領域的名詞詞典與趨勢詞詞典。通過常見的趨勢詞查找其近義詞,共同構成趨勢詞詞典。人工篩選曼昆《經濟學原理》一書中的經濟學名詞,結合語料庫中的經濟名詞,共同構成經濟名詞詞典。其中,定義與"增"趨勢搭配表達積極情感傾向的名詞為積極名詞,反之為消極名詞。與"減"趨勢搭配表達積極情感傾向的名詞為消極名詞,反之為積極名詞。
(2)趨勢詞詞組情感評分。
定義"增"趨勢詞評分為1,"減"趨勢詞評分為-1,積極名詞評分為1,消極名詞評分為-1,計算趨勢詞詞組原始情感評分,計算方法如公式(3-1)所示。

其中OSij,(Original Score)是第i 條經濟評論第j 個趨勢詞詞組的原始情感評分,TSij(Trend Score)是該詞組的趨勢詞評分,NSij(None Score)是該評論的名詞評分。
對趨勢詞詞組的原始評分進行加權,計算方法如公式(3-2)所示。

其中WTij,(Weighted Trend Score)為第i 條經濟評論第j個趨勢詞詞組的加權后情感評分,WEij(Weighted Emotion Score)為公式(2-5)中計算所得第i 條經濟評論第j 個情感詞加權情感評分,n 為該評論中的情感詞總數。
四、送結果與檢驗
1.實驗結果。
本文對經濟評論情感評分采用二級分類,將第i 條評論的情感詞和趨勢詞詞組加權情感評分加總,得到第i 條評論的原始情感評分,將其0-1 標準化后與0.5 比較,大于0.5 分為積極情感,小于0.5 分為消極情感。對經濟熱詞評論的情感傾向分類統計得到,區塊鏈的積極評論占68.95%,科創板的積極評論占64.81%,直播經濟的積極評論占71.57%,豬肉價格的積極評論占32.89%。
2.結果檢驗。
(1)檢驗指標。
精確率、召回率、F1 分數是用來衡量二分類模型精確度的重要指標。精確率將積極(消極)評論判定為積極(消極)評論的數量,即正確判定評論數,占判定為積極(消極)的總評論數的比率。是指召回率是指正確判定積極(消極)評論數,占實際總積極(消極)情感傾向評論數的比率。而F1 分數兼顧了分類模型的精確率和召回率,可以看作兩者的一種調和平均數。
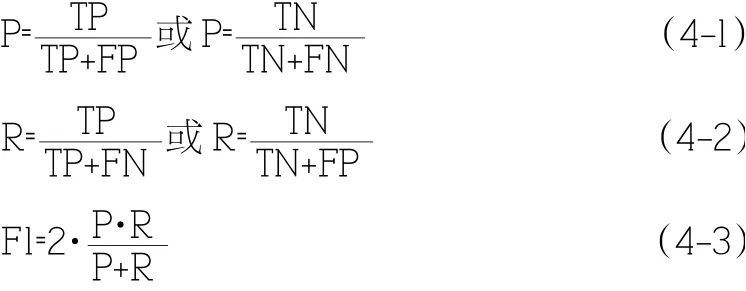
其中,P(Precision Ratio)為精確率,R(Recall Ratio)為召回率,F1(F1 Score)為F1 分數,TP(True Positive)為將積極評論判定為積極評論的數量,FP(False Positive)為將積極評論誤判為消極的數量,TN(True Negative)為將消極評論判定為消極的數量,FN(False Negative)為將消極評論誤判為積極的數量。
(2)檢驗結果。
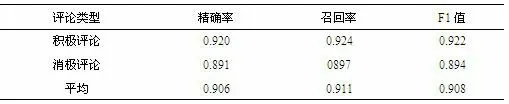
表4-1 經濟評論情感分析精確度檢驗結果表
從表4-1 可知上述經濟評論情感分析體系在實踐中有較好效果,精確率平均能達90.6%,召回率平均可達91.1%,F1 值平均可達90.8%,但負向情感極性判別精確度的各項指標基本低于正向情感極性判別,情感詞典中消極情感詞可能存在不完善等問題。
五、結論
本文采用基于情感詞典的情感分析方法解決經濟評論領域的情感分析與評分問題,通過人工提取特征構建經濟評論情感詞典,引用互信息和左右熵新詞發現方法優化分詞結果,引用ITD*MI 方法對情感詞加權,同時考慮經濟評論文本短和含有趨勢詞詞組特點,計算經濟評論綜合情感評分并進行情感極性判別。使用精確率、召回率、F1 值3 個情感極性判別精確度評價指標對實驗結果進行驗證,各項指標均高于90%,該方法較好地解決了經濟評論領域的情感分析問題。
本文將情感傾向簡單地進行二分類,評分并不能精確反映情感傾向程度,未來的研究重點是在完善經濟評論情感詞典、進一步提高判別精確度的基礎上,使情感評分能夠更好地反映文本的情感傾向程度。
本論文得到了江西財經大學科研課題
猜你喜歡
今日農業(2022年14期)2022-09-15 01:44:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
民生周刊(2020年13期)2020-07-04 02:49:22
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
華人時刊(2018年23期)2018-03-21 06:26:00
小學教學參考(2015年20期)2016-01-15 08:44:38
