基于圖表示學習的會話感知推薦模型
2020-03-21 01:10:28曾義夫牟其林
計算機研究與發展 2020年3期
曾義夫 牟其林 周 樂 藍 天 劉 嶠
1(電子科技大學信息與軟件工程學院 成都 610054) 2(提升政府治理能力大數據應用技術國家工程實驗室(中電科大數據研究院有限公司) 貴陽 550022) 3(中電科大數據研究院有限公司 貴陽 550022)(ifz@std.uestc.edu.cn)
基于會話的推薦系統(session-based recom-mender systems, SRS)是推薦系統領域的一個重要研究分支,因其在電子商務中的實用性而受到廣泛關注[1].SRS研究的基本問題是如何利用用戶會話日志中記錄的歷史行為(如瀏覽、購買等點擊行為)來預測用戶下一次將要點擊的物品.因此,SRS問題也被稱為點擊預測(next-click prediction)問題[2].
與傳統推薦系統相比,SRS問題的困難性主要體現在:1)SRS中的用戶通常是匿名的,僅通過當前會話很難獲得足夠的上下文信息對用戶興趣進行建模;2)SRS數據僅包含用戶瀏覽點擊行為,不包含用戶對物品的主觀意見(如評分),因此只能通過該數據對用戶興趣進行間接推測.簡言之,SRS需要根據有限的點擊行為序列所反映出的用戶隱含興趣,預測用戶的真實興趣并做出針對性推薦[2].
當前性能表現較好的SRS模型多為基于循環神經網絡(recurrent neural networks, RNNs)的深度學習模型,其共性在于對用戶點擊物品(item)采用實值向量進行表達(稱為embeddings),并且采用隨機值對embeddings向量進行初始化,通過對用戶點擊序列進行學習,迭代更新得到物品的向量表達[2-5].
本文認為這種基于會話子序列學習得到物品表達,并依據子序列編碼進行預測的方式會導致模型的注意力局限于會話中的已點擊物品,傾向于推薦與已點擊物品類似的物品,難以捕獲用戶瀏覽行為中隱含的興趣變化.例如用戶在瀏覽手機產品時可能注意力會自然地遷移到附件產品如耳機、手機殼,充電寶等,這種情況稱為興趣漂移[6].
為解決該問題,本文提出一種基于協同過濾思想的SRS算法模型,稱為基于圖表示學習的會話感知模型(graph embedding based session perception, GESP).該模型首先基于訓練數據構造一個全局的物品依賴關系圖(item dependency graph, IDG),用于描述用戶會話中物品的點擊先后順序.然后,利用本文提出的圖表示學習算法(graph embedding learning algorithm, GELA)對IDG進行學習,得到推薦系統中所有物品的向量表達.最后,再利用預訓練得到的物品表達,采用雙向LSTM(bidirectional long short-term memory, BiLSTM)構建一個混合記憶網絡模型,實現對用戶點擊行為的預測.由于GESP模型在訓練最后的預測模型時不對預訓練得到的物品向量表達進行更新,為區別于相關工作,我們將其稱為固定表達模型.
本文的主要貢獻有3個方面:
1) 提出將一種基于協同過濾思想的固定物品表達用于SRS任務,為推薦模型提供物品之間復雜的關聯信息與被點擊的規律信息,提高推薦模型的預測能力,緩解會話中的興趣漂移問題;
2) 提出了一個從全局角度表示用戶會話中物品點擊先后順序的物品依賴關系圖IDG,同時提出一種圖表示學習算法GELA從IDG中學習圖中的結構化信息,獲得物品的固定向量表達;
3) 提出了一種基于圖表示學習的會話感知推薦模型GESP.除了將物品固定表達作為輸入之外,GESP模型與相關工作的主要區別在于利用BiLSTM進行特征抽象,可以使模型從不同角度觀察用戶瀏覽行為并進行學習,更好地捕獲用戶會話中的興趣變化.在2個公開數據集上的實驗結果表明,GESP模型在準確性、泛化性和多樣性方面均優于相關工作.
1 相關工作
1.1 基于會話的推薦系統
SRS是推薦系統領域的近期研究熱點之一,其目標是根據歷史會話記錄中的潛在信息(如用戶的點擊瀏覽記錄)預測用戶下一次點擊.
傳統的推薦系統模型,如矩陣分解模型(matrix factorization, MF)[7]和Markov鏈模型(Markov chains, MC)[8],并不能很好地應用于SRS任務中,分別是因為用戶-物品矩陣中用戶評分的缺失和無法有效建模序列中的上下文信息(一階依賴問題).受MF和MC的啟發,一些研究人員提出結合二者優勢的混合模型[9-10],如Markov鏈個性化分解模型(factorization personalized Markov chains, FPMC),通過分解底層MC上的轉移矩陣來建模用戶的順序瀏覽行為,提供個性化推薦.
隨著深度學習模型近年來在各領域不斷取得的進展,SRS領域也提出利用深度學習的方法預測用戶的下一次點擊[11].Hidasi等人[5]使用帶有門控循環單元的深度循環神經網絡(GRU4Rec),利用歷史點擊記錄來建模會話數據.GRU4Rec在SRS任務中預測下一次點擊時會通過RNN的結構來綜合考慮用戶的歷史行為.在GRU4Rec的研究基礎上,Quadrana等人[12]在SRS任務中結合用戶畫像使用分層循環神經網絡進行個性化推薦.Li等人[4]提出一種物品注意力機制(item-level attention mecha-nism)來明確考慮會話中每個物品的重要程度,結合編碼器-解碼器(encoder-decoder)架構,來捕獲用戶在會話中的主要目的.Liu等人[2]提出了基于注意力/記憶機制的模型,該模型同時考慮了用戶的長、短期興趣,并在推薦時增強了短期興趣對推薦結果的影響.此外,一些研究將重點放在了物品間的關聯性上.Hu等人[3]提出一種淺層神經網絡結構,通過計算上下文物品之間的相對距離來捕獲其間的關聯性.本文與這些工作主要區別在于,本文采用圖表示學習的方法學習物品的向量表達,并將其作為預測模型的“固定”輸入,利用BiLSTM從不同角度對用戶瀏覽行為進行特征提取,同時考慮用戶的長短期興趣以緩解興趣漂移帶來的影響,最終在不犧牲預測準確性的前提下,為用戶提供多樣且新穎的選項.
1.2 圖表示學習
近期,表示學習在知識庫中的應用受到了各領域研究人員的關注,如推薦系統[7]、知識圖譜[13]、復雜網絡[14]和生物信息學[15]等.表示學習是學習使用各種大型真實網絡進行預測的基本步驟[16-17].與圖表示學習有關的模型可以根據他們的合成方式分為非線性模型和線性模型.評分函數中包含用于特征提取的非線性激活函數的ER-MLP[13],NTN[18],ConvE[19]等模型稱為非線性模型,反之,RESCALL[20],TransE[21],DistMult[22],HoIE[23],ComplEx[24]等模型則被稱為線性模型[25].
近期研究工作表明基于圖的向量表達已經被使用于一些推薦任務中.如Wang等人[26]提出了一種新聞推薦模型,利用知識圖譜中的實體向量表達提供有區分度的互補信息.并在進一步的研究中,將知識圖譜作為推薦系統的輔助信息源[27].然而,當前利用物品表達的相關SRS工作通常使用獨熱(one-hot)編碼,或者在深度學習結構中添加表示層,通過隨機初始向量表達來表示物品[2-5].對此,Li等人[28]提出異議,認為對于具有海量物品數據的大型電子商務平臺而言,上述方法會增加時間復雜度,使其失去性能優勢[5].為此,本文提出從圖表示學習的角度解決SRS中下一次點擊預測問題,并提出利用固定物品表達作為輸入構建SRS模型.
2 基于圖表示學習的會話感知模型
2.1 符號系統描述
符號約定.用集合S={s1,s2,…,s|S|}表示SRS中所有的會話數據,每個會話si對應一個順序點擊的物品序列,即si=〈v1,v2,…,vNi〉,Ni表示會話si的長度,vj表示在會話si中用戶第j次點擊的物品,另外利用物品字典(item dictionary, ID)V={v1,v2,…,v|V|}表示在會話集合S中出現的所有物品集合,有vj∈V.
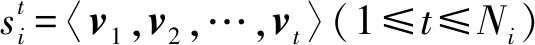
2.2 物品依賴圖(IDG)
本文中,IDG表示為G=(V,E),其中V表示物品字典,E表示物品間有向邊的集合.在本模型中,物品vi和vj之間的邊
IDG結構展示出物品vi∈V在歷史會話記錄中的順序依賴關系,可以用于相關物品的協同過濾.
2.3 基于圖的表示學習算法
圖表示學習在圖信息挖掘任務中十分重要[29],常用來作為機器學習前的特征工程,由這個過程得到的表示向量的質量在極大程度上決定了算法最終的實驗結果性能[16],因此受到學術界的廣泛關注[17].

score(vi,vj,vk)=(vi+vj)·vk.
(1)
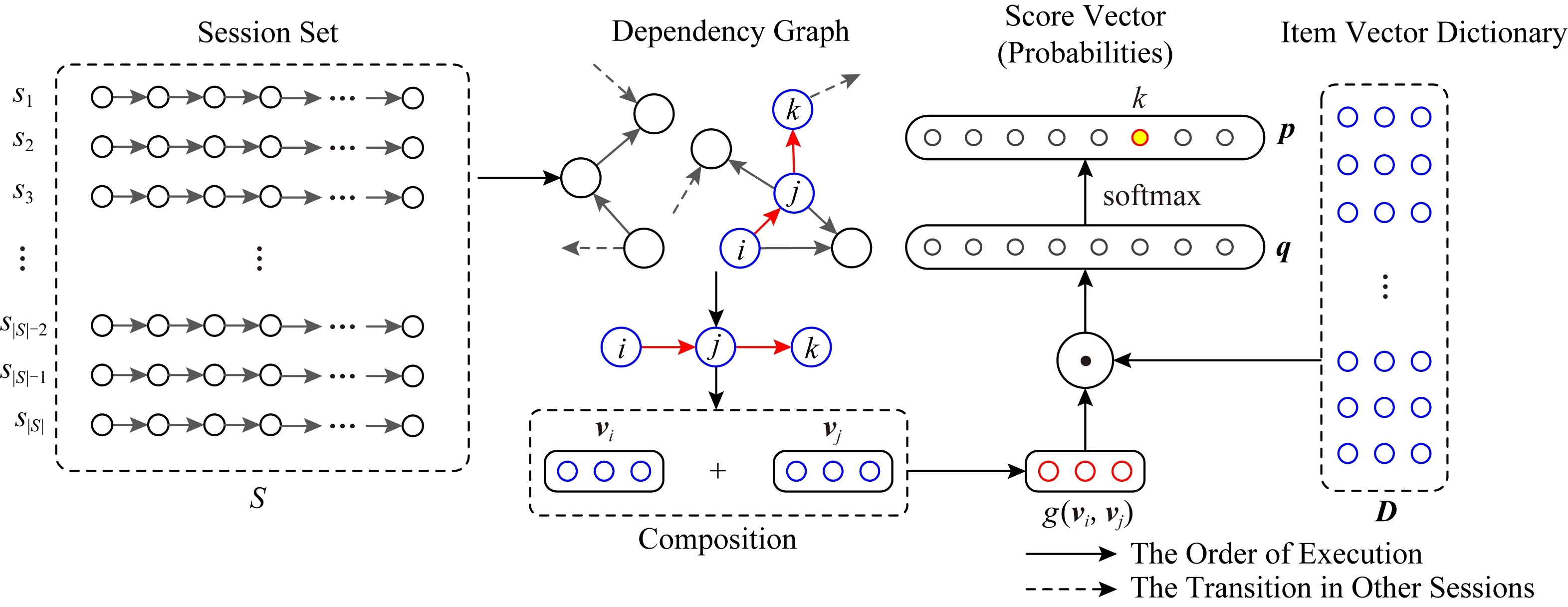
Fig.1 The graph embedding learning algorithm圖1 基于圖的表示學習算法
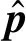
(2)
2.4 會話感知模型
近期研究表明,用戶的長期興趣和短期興趣在SRS任務中均具有重要意義[31],STAMP[2]模型通過結合這2種興趣記憶提高了對用戶的下一次點擊的預測準確性.受STAMP模型啟發,本文提出的GESP模型也包含2種類型的記憶,如圖2所示.
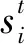
(3)
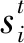
短期記憶mT基于雙向LSTM隱狀態構建.LSTM可以捕捉長距離依賴關系,但在序列過長的情況下,LSTM的隱狀態會聚焦在輸入序列較尾端的部分.為解決這個問題,本文選用BiLSTM獲取用戶的短期興趣.在時刻t,前向LSTM的網絡結構定義:
i=σ(Wixt+Uiht-1),
(4)
f=σ(Wfxt+Ufht-1),
(5)
o=σ(Woxt+Uoht-1),
(6)
g=tanh(Wgxt+Ught-1),
(7)
ct=f⊙ct-1+i⊙g,
(8)
ht=o⊙tanh(ct),
(9)
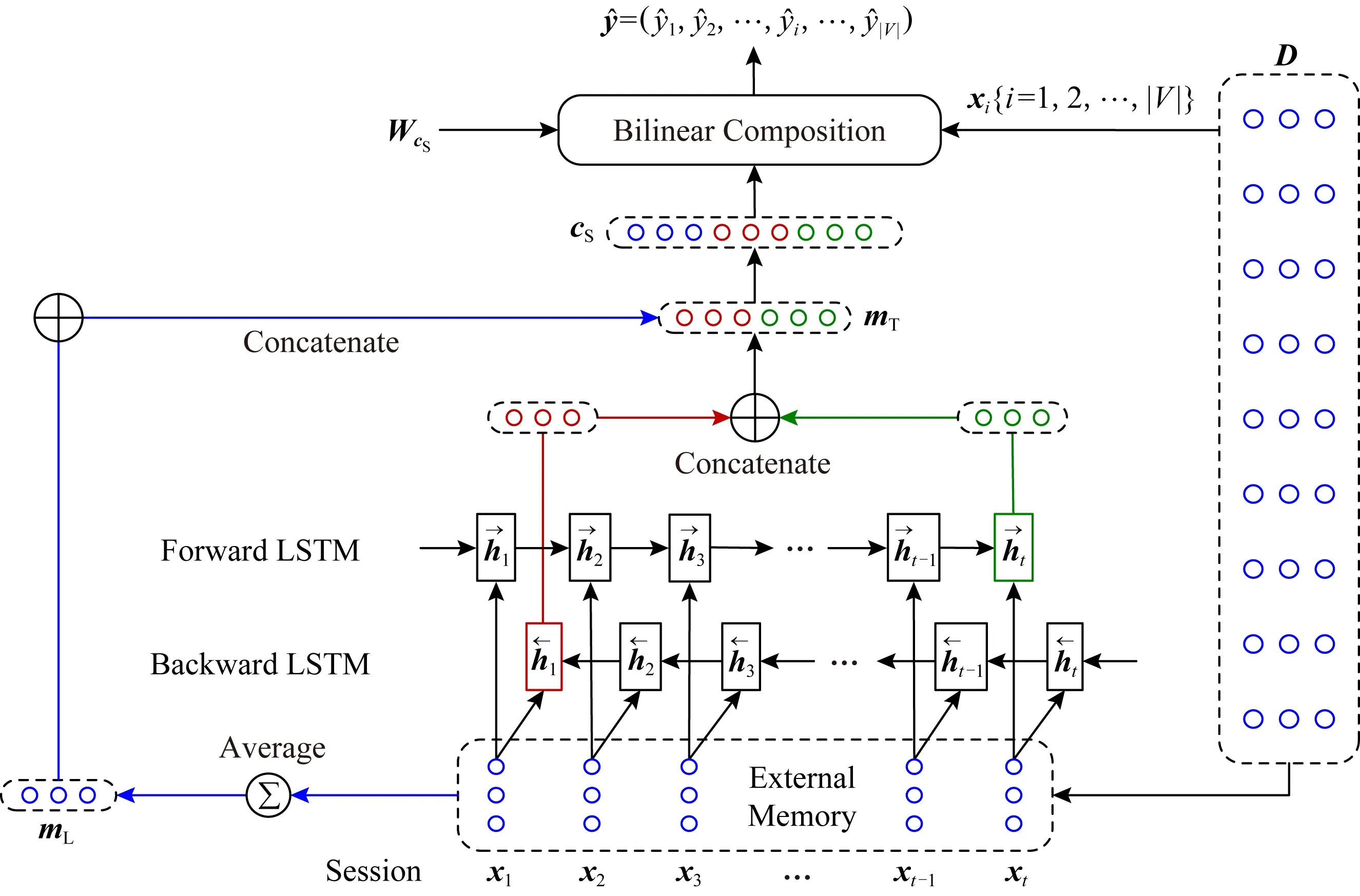
Fig.2 Schematic illustration of the GESP model圖2 GESP模型示意圖
mT=ht⊕h1,
(10)
其中,⊕表示連接操作,ht表示用戶的當前瀏覽興趣,h1表示用戶的初始瀏覽興趣,二者結合,可以更客觀地表示用戶近期的實際興趣,提高系統對用戶興趣漂移的敏感度.為了區別于先前定義的長期記憶mL,本文稱mT為表示用戶短期興趣的短期記憶.
長期記憶負責捕獲用戶的長期興趣,而短期記憶負責捕獲用戶的短期興趣,本文將二者結合在一起形成一個新的記憶向量cS:
cS=mT⊕mL.
(11)
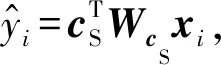
(12)
算法1.基于圖表示學習的會話感知推薦算法.
輸入:訓練集S={s1,s2,…,s|S|},si={v1,v2,…,vNi},vj∈V、向量維度d、batch1、batch2、學習率η、學習率衰減速率λ.
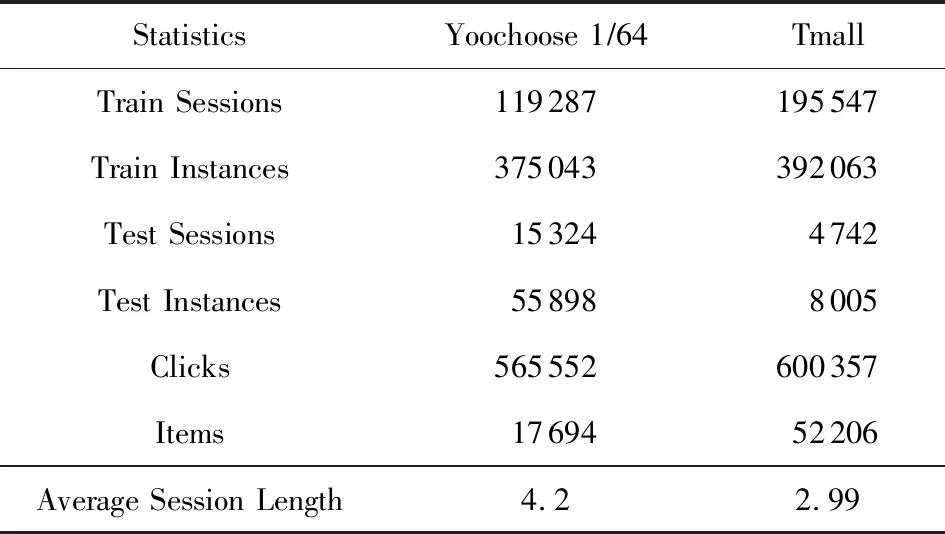
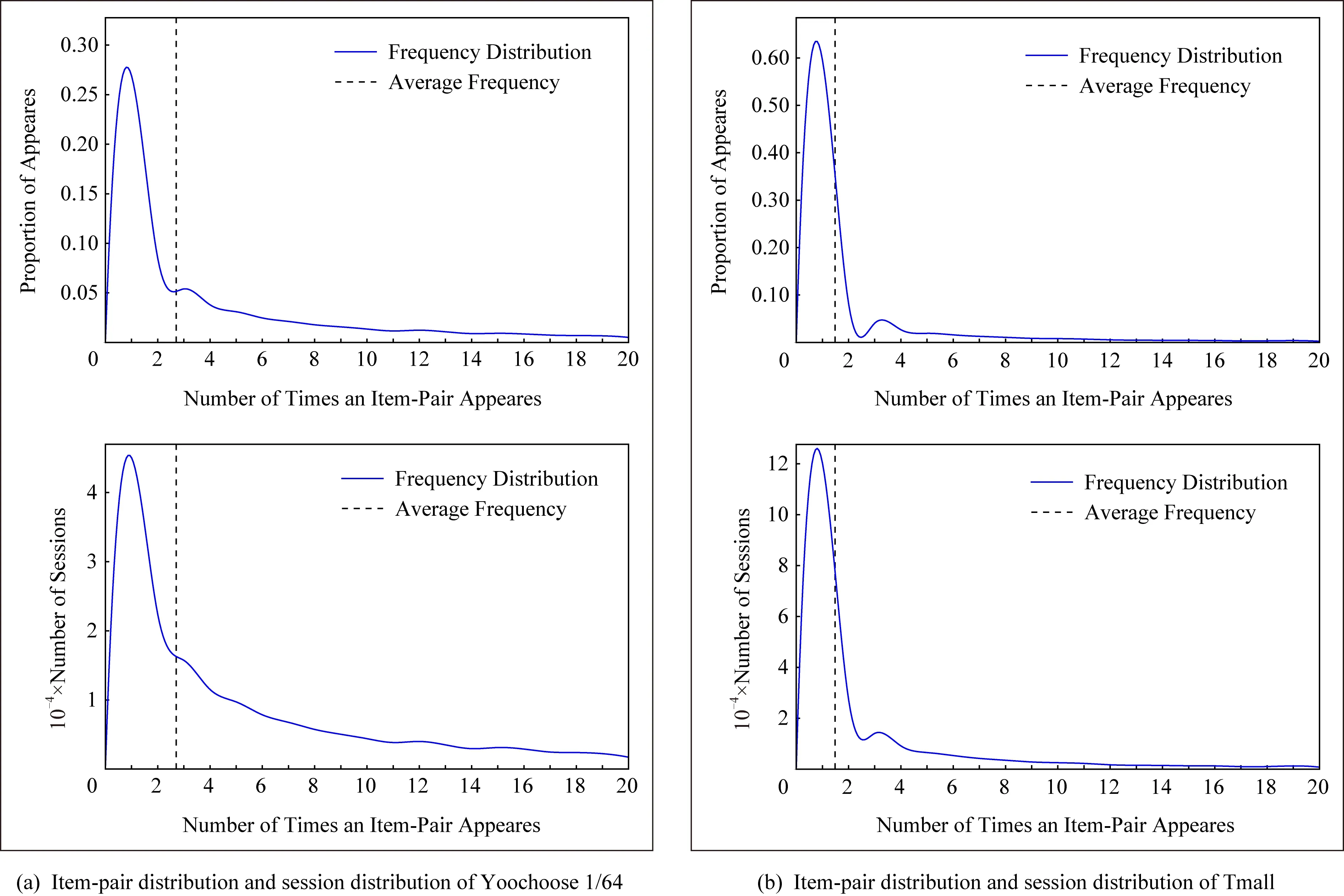
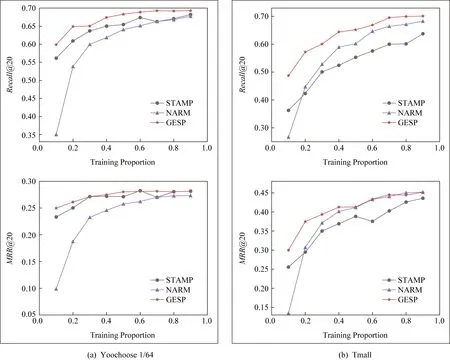
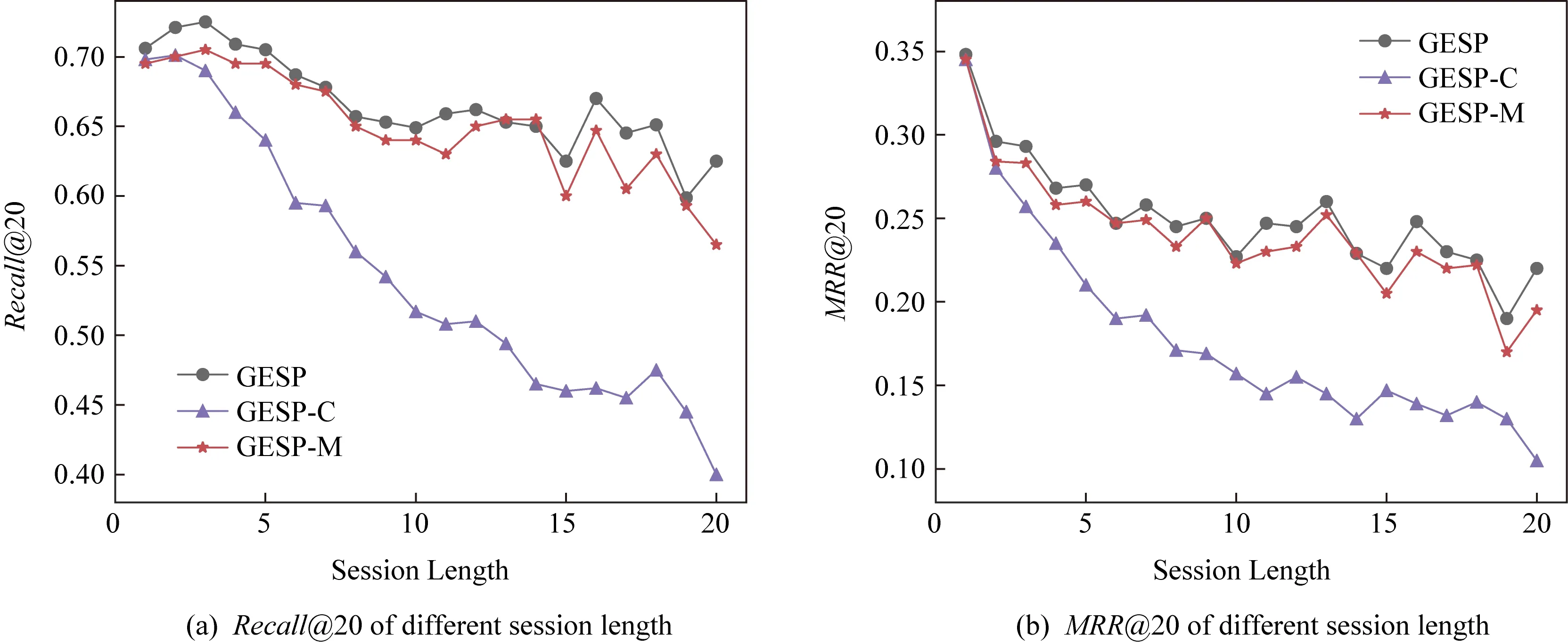
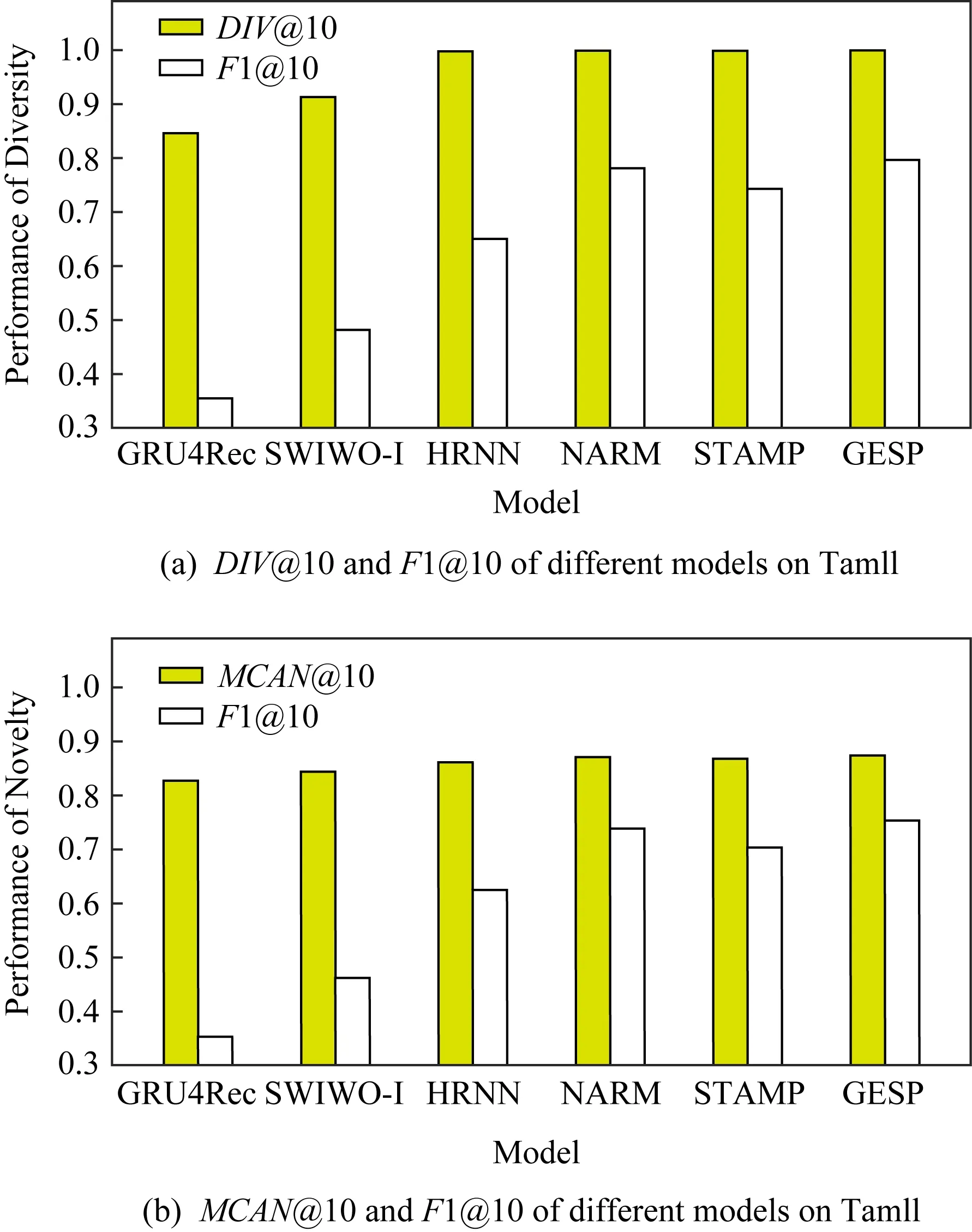
① 初始化S←S-si(?i,Ni vj(?j,Count(vj) ② loop ③Sbatch1←Sample(S,batch1); ④ foreach ⑤ foreachvk∈Vdo ⑥qk←scorevk=(vi+vj)·vk; ⑦ end foreach ⑧p←one-hot(V); 人生百年,歡嫛能幾?當其百昌,外鑠牢愁,中沍冥心,孤運往而不復。瓊樓夜冷,錦瑟春啼,結想所生,神光離合。作者、述者,各有會心。皇穹鑒其忠誠,圣人知其怨悱。辭取復意,何假蹄筌?莼農微旨,或在斯乎?[注](民國)王蘊章:《燃脂馀韻》,王英志主編《清代閨秀詩話叢刊》,第621-622頁。 為驗證基于圖表示學習的會話感知推薦模型的有效性,本文在Yoochoose和Tmall等2組公開數據集上進行了評估實驗. Yoochoose數據集來自RecSys’15挑戰賽,其數據包含yoochoose.com電子商務網站連續6個月的匿名用戶會話日志.Tmall數據集來自IJCAI’15競賽,其數據包含tmall.com在線購物網站連續6個月的脫敏用戶會話日志.2個數據集均沒有預先分為訓練集和測試集. 本文參照其他相關工作對數據進行了預處理.在Yoochoose數據集上,首先將用戶會話日志中最后一天的數據作為測試集,余下數據作為訓練集.過濾僅包含1次點擊的會話以及在訓練集和測試集中出現總次數少于5次的物品,然后過濾僅出現在測試集中的物品.在Tmall數據集上,針對購買記錄,首先過濾少于3次會話的用戶記錄以及僅包含一次點擊的會話數據,然后隨機選擇數據集中最后1個月內20%的會話作為測試集,余下數據作為訓練集.經過預處理,Yoochoose數據集包含7 966 257個會話,31 637 239次點擊,37 483個物品,Tmall數據集包含200 289個會話,600 289次點擊,52 206個物品. 根據Tan等人[32]的工作,本文在模型訓練之前,對實驗數據進行了數據擴充.例如對于給定輸入會話si=〈v1,v2,…,vNi〉,生成子序列〈([v1],v2),([v1,v2],v3),…,([v1,v2,…,vNi-1],vNi)〉,將每個子序列中括號內的物品作為輸入數據,而剩余一項(即該會話下一次點擊的實際結果)作為標簽數據.由于Yoochoose數據量過大,現有研究表明使用該數據集較后部分的數據可以獲得更好的預測結果[32],因此,本文只取訓練數據的最后1/64作為模型的實際訓練集,并稱之為Yoochoose 1/64.2個數據集的詳細統計數據如表1所示: Table 1 Statistics of the Experiment Datasets表1 實驗數據集的統計信息 實驗開始前,為驗證固定表達模型的合理性,本文首先將單個會話中按瀏覽順序依次取出的相鄰2項物品定義為物品對(item-pair),然后在2個公開數據集上按物品對出現的次數對其進行分類,分別統計在總點擊量中物品對出現次數的分布,以及在所有會話中包含該類物品對會話的分布情況,如圖3所示.結果表明,物品對出現次數的分布與含有該類物品對會話的分布高度相關,且具有某種規律性,此外,2種分布均顯示出與隨機分布的明顯偏差.因此,在本文構建的IDG上根據物品對來對這種規律性進行建模,學習固定的物品向量表達,這比隨機初始化embeddings向量產生的結果更有說服力. Fig.3 Item-pair distribution and session distribution圖3 物品項對分布以及會話分布 為評估GESP模型的性能,將在上述2個數據集上與相關工作中提及的8種模型進行對比. 1) POP.最簡單的SRS算法模型,始終根據訓練集中物品的出現頻率排名進行推薦. 2) FPMC.文獻[9]提出將MF和MC的相結合的模型,該模型為每個用戶生成單獨的轉移概率矩陣,生成轉移矩陣立方體.利用張量分解中的標準分解(canonical decomposition, CD)方法,分解該立方體.此后,引入貝葉斯個性排名(Bayesian personalized ranking, BPR)來優化模型參數,使推薦結果更為準確.為了使其適用于SRS,本文在計算其推薦分數時不考慮原模型中用戶的潛在表示. 3) SWIWO-I.文獻[3]提出的一個淺層神經網絡模型,該模型將會話中的物品以獨熱向量的形式,作為高維數據輸入到編碼層,生成低維向量,獲得會話上下文表達,用以生成多樣化的推薦結果. 4) GRU4Rec.文獻[5]提出的GRU模型,該模型將會話進行拼接,利用小批量的并行計算,提高訓練效率.并根據物品“熱門程度”進行采樣,對采樣結果劃分正負樣本,采用基于排名的損失函數. 5) HRNN Init.文獻[12]提出的基于GRU4Rec的分層模型,該模型引入了一個額外的GRU層來跟蹤用戶在整個會話中的興趣演變過程. 6) HRNN All.HRNN模型的另一個變體[12],具有更復雜的結構,其中附加的GRU層用于在模型初始化時生成用戶的向量表示并在會話之間傳遞信息. 7) NARM.文獻[4]提出的在RNN中加入了注意力機制的模型,該模型利用注意力機制從隱狀態捕捉用戶的意圖,并結合用戶瀏覽時的順序行為信息生成最終興趣表達來進行推薦物品選擇. 8) STAMP.文獻[2]提出的短期記憶/注意力優先的模型.該模型引入記憶力與注意力機制同時考慮用戶長/短期興趣,并通過提高短期興趣的重要性來緩解興趣漂移對推薦模型的影響. 其中,對于SWIWO-I,GRU4Rec,HRNN,NARM,STAMP,本文使用了原論文發布的代碼,在缺少相關結果的數據集上進行參數調優獲得最終的實驗結果,對于POP和FPMC模型,引用了相關論文中發布的結果. 在評測模型性能時,本文采用Recall@K和MRR@K評價指標. Recall@K用于衡量會話推薦系統預測準確性的指標,表示推薦結果排名列表中排在前K個推薦物品中有正確答案數量占所有測試數的比例,該算法定義: (13) 其中,N表示測試集中的樣本數量,nhit表示前K個推薦物品有該樣本正確答案的樣本數. MRR@K指平均倒數排名(mean reciprocal ranks, MRR),表示如果某樣本推薦結果vt的排名大于或等于K,則將其MRR@K值設置為0,否則將保持該排名值,并用于平均計算: (14) MRR@K分數的值的范圍被限制在[0,1]區間內,其值越大,表明推薦的命中率越高. 本文在評價模型結果時取用K=10和K=20,因為在SRS的實際應用中,多數用戶僅關注出現在第一頁的推薦結果. 本文GESP模型的超參數通過網格參數尋優法進行選擇,其參數選擇范圍設定:學習率η∈{0.001,0.005,0.01,0.1,1}、學習率衰減速率λ∈{0.75,0.8,0.85,0.9,0.95,1.0}、物品向量表示維度d∈{50,100,200,300}.根據隨機選擇的測試集進行網格尋優,取Recall@20指標最優時的參數組合d=100,η=0.005,λ=1.0作為本文實驗參數.訓練批量設為512,Adam算法迭代次數設置為50輪.所有權重矩陣均采用服從N(0,0.052)的正態分布的隨機數初始化. 表2記錄了GESP模型和其他對比模型的實驗結果: Table 2 Next-Click Prediction on Yoochoose and Tmall表2 Yoochoose和Tmall數據集上點擊預測實驗結果 % Note: Best results are in bold. 通過實驗結果分析可以得出3方面認識: 1) 本文提出的GESP模型在Recall@20的測度上始終優于最先進的模型NARM和STAMP,與NARM模型相比,GESP模型在2個數據集上的準確率分別提高了1.05%,3.20%,與STAMP模型相比,分別提高了0.63%,7.93%.GESP模型的MRR@20得分在Tmall數據集上排名第1,在Yoochoose 1/64數據集上排名第2,與最優模型結果相近.本文認為準確率提升的結果源于GESP模型的2個特點:①它綜合考慮了用戶的短期興趣和長期興趣,這有助于緩解用戶興趣漂移的問題.已有研究可以證明這種長/短期記憶機制的有效性[2].此外,本文的實驗結果為研究SRS中用戶的行為模式提供了新的發現,例如基于圖生成的物品固定表達有助于構建長期記憶,使用BiLSTM網絡有助于對短期記憶建模,本文將在3.6節和3.7節深入討論這2個問題.②它從IDG學習物品向量的固定表達,這有助于GESP模型更好地從全局角度捕獲用戶瀏覽時的興趣變化規律.相較之下,傳統的采用隨機初始化物品向量表達的方法會忽視掉物品之間重要的隱式關聯信息. 2) 基于RNN的深度學習模型在測試集中均有較好表現,這表明在對序列會話建模時,RNN對捕捉會話序列中用戶的瀏覽模式起著重要作用.進一步對比發現,GESP模型、NARM模型、STAMP模型的表現明顯優于GRU4Rec模型和HRNN模型(即HRNN All和HRNN Init),由此推論,結合用戶長/短期興趣可能是提高SRS模型推薦準確性的必要條件. 3) 當采用不同的數據集評估時,我們發現FPMC的性能極不穩定,其評估結果在Tmall數據集上的表現特別差.考慮到Tmall數據集具有明顯的稀疏性問題(平均而言,Tmall數據集中每個會話只包含2.99次點擊),這個結果表明矩陣分解方法對數據的稀疏度非常敏感.相比之下,SWIWO-I模型在2個數據集上的表現都較為穩定,這進一步表明神經網絡解決方案比矩陣分解方法更適合解決基于會話的推薦問題,而基于記憶力機制的深度神經網絡模型在一定程度上可以提升這種優勢(如GESP和STAMP). 綜上,2個公開數據集上的實驗結果證明GESP模型在SRS中的有效性.為驗證模型各組成部分的有效性,本文設計了進一步的實驗. 如引言所述,本文的主要貢獻在于提出了一種基于IDG的固定物品表達,并以此為基礎來進行推薦.現通過2個方面驗證利用圖表示學習方式生成固定物品表達的必要性:1)使用固定物品表達是否可以提高模型的穩定性;2)使用固定物品表達是否可以提高模型的準確率. 在SRS任務中,由于用戶和物品數量眾多,歷史會話數據常過于龐大,使用全部數據進行模型訓練會使訓練時間無法滿足在線推薦服務的需求.因此從有限的數據子集中訓練出一個性能較好的預測模型具有重要實際意義.本文利用固定物品表達作為GESP模型輸入的初衷源于IDG的結構可以反映物品之間復雜的關聯信息,使用這種表達的GESP模型比使用隨機初始化embedding的其他模型可以獲得更穩定的表現.為驗證這一猜想,本文將訓練集隨機劃分為10個子集,分別對GESP模型、STAMP模型、NARM模型進行10輪實驗,每輪實驗增加一個子集來擴充訓練集.使用相同的測試集進行評測,結果如圖4所示: Fig.4 Performance on different proportion of training data圖4 訓練集增量實驗效果 圖4顯示了3種模型在增量實驗中的結果,在Yoochoose和Tmall數據集上,GESP模型的預測準確性始終優于另外2個當前性能最好的模型,而且隨著訓練數據量的增加,GESP模型在保證了準確性的情況下具有更高的穩定性(折線圖的波動性相對更小).結果表明:利用圖表示學習從IDG中得到的固定物品表達,使GESP模型性能更優,且對數據稀疏性的敏感度降低,因此GESP更適用于實際SRS任務. 為進一步驗證由圖表示學習得到的物品表達的適用性,本文新增了一個基線模型GESP-G進行對比實驗,與GESP不同的是,GESP-G采用隨機初始化的方式生成物品表達,且在模型訓練過程中通過反向傳播進行更新,實驗結果如表3所示.實驗數據表明,基于IDG構建的物品表達在GESP模型中具有重要作用,在不采用這種機制的情況下,模型的性能顯著下降,尤其是在處理高度稀疏數據時(如Tmall數據集). Table 3 The Impact of the Graph-Based Item Embeddings表3 圖表示學習的影響 % Note: Best results are in bold. 本文所提出的混合記憶網絡模型利用了一種基于BiLSTM隱狀態構建的長/短期興趣建模機制,為驗證本文所提出的用戶興趣模型各部分的有效性,在相同的條件設計了1組對比實驗,結果如表4所示.其中,1)GESP是本文提出的標準模型;2)GESP-C是GESP的變體,無短期記憶mT;3)GESP-M是GESP的變體,無長期記憶mL. 由表4可知,GESP在2個數據集上的Recall@20和MRR@20得分,以及在更嚴苛條件下的Recall@10和MRR@10得分均優于其他2個變體.與此同時,GESP-M的性能整體優于GESP-C. Table 4 The Impact of General/Temporal User Interests表4 用戶長短期興趣的影響 % 由表4可以得出2個結論: 1) 短期記憶mT和長期記憶mL所攜帶的信息在預測下一次點擊時是互補的,這驗證了GESP使用的長/短期記憶組合機制的有效性. 2) 短期記憶mT所攜帶的短期興趣可能比長期記憶mL所攜帶的長期興趣更重要. 為了進一步研究這2種興趣(長期興趣、短期興趣)的作用,本文分別計算了這3個模型在不同長度會話(基于Yoochoose 1/64數據集)上的表現,結果如圖5所示.分析數據可以看到GESP-M的性能與GESP接近,但GESP-C的性能明顯弱于其他2個模型.并且隨著會話長度的增加,GESP-C模型的準確性顯著下降.這種差異表明了長會話中存在的用戶興趣漂移問題對SRS的影響,并顯示出考慮用戶短期興趣的必要性;通過對GESP和GESP-M性能的比較,說明了同時考慮用戶的長短期興趣有助于進一步緩解用戶的興趣漂移問題;GESP模型也受會話長度的影響,隨著會話長度的增加,其預測準確率也會隨之降低,這表明本模型的短期興趣建模機制仍有改進的空間. Fig.5 Evaluation results calculated separately with regard to different session length on Yoochoose 1/64圖5 Yoochoose 1/64上不同會話長度的評測結果 除了推薦準確性之外,多樣性和新穎性也是SRS中重要的評估指標.推薦多樣且新穎的內容,可以提高SRS的用戶體驗,緩解由于模型過擬合(過度關注當前會話瀏覽內容)帶來的問題[33-34].本文通過引入IDG,利用一種基于協同過濾思想的圖表示學習算法構造物品的固定表達,從全局角度捕獲物品之間的復雜關聯,可有效緩解上述問題.本文設計了一組對比實驗,比較不同模型推薦結果的多樣性和新穎性. 盡管多數研究人員都認為在構建SRS模型時應將多樣性與新穎性考慮在內,但目前學術界關于多樣性與新穎性的衡量方法還沒有達成共識[33].根據之前的研究[3],本文列出DIV@K和MCAN@K指標作為參考. DIV@K得分是指在含有N個測試樣本的推薦結果中,任意2組推薦結果(Ri,Rj)之間的平均非重疊比率(每組推薦結果由推薦得分排名前K的物品組成).該指標常被用于衡量推薦內容的多樣性[3,35],其定義: (15) 其中,i≠j,N表示測試樣本的數量,因此所有可能組合的數量為N(N-1)/2. (16) F1@K得分是召回率和精確率的調和平均值.本實驗中引入的F1@K得分定義與F1得分類似,在評估推薦結果的多樣性時,精確率由DIV@K替換,在評估推薦結果的新穎性時,精確率由MCAN@K替換.因此,相應的F1@K得分可以綜合考慮推薦結果的準確性和多樣性及新穎性: (17) (18) 當K=10時,GESP與另外5個對比模型在Tmall數據集上的實驗結果如圖6所示,經過分析可以得出3個結論:1)本文提出的GESP模型與其他2個性能最優的NARM模型和STAMP模型表現不相上下,但在F1@10分數方面,GESP模型、NARM模型、STAMP模型都優于GRU4Rec模型、SWIWO-I模型、HRNN模型,這意味著后者的推薦結果雖然具有多樣性和新穎性但是犧牲了推薦準確性.2)除GRU4Rec模型外,其余模型的DIV@K分數都在90%以上;所有模型的MCAN@K分數都在80%以上,分析認為由于Tmall數據集的數據稀疏性導致了結果略有失真.3)值得注意的是,HRNN這種致力于個性化推薦的模型,其實驗結果比GESP模型和STAMP模型等基于長短期記憶的模型稍差,但始終優于GRU4Rec模型.這表明一方面長短期記憶機制能有效緩解用戶興趣漂移,帶來推薦準確性的提升;在另一方面,用戶的歷史會話信息是生成多樣且新穎的推薦結果的重要補充信息源. Fig.6 Diversity and novelty of different models on Tmall圖6 不同模型在Tmall數據集上的多樣性和新穎性 本文進一步通過與其他圖表示學習算法(包括TransE[21],DistMult[22],ComplEx[24],ConvE[19])進行比較來驗證GELA的有效性.實驗思路是分別使用不同的圖表示學習算法學習物品的向量表達,然后使用學到的物品向量表達作為GELA的輸入在測試集上進行推薦實驗,即根據模型的輸出得分得到推薦結果,實驗結果如表5所示: Table 5 Recall@20 of Different Graph Embedding Methods表5 不同圖表示學習方法的Recall@20得分 % 從表5可以看出,GELA模型始終優于其他模型,在處理極稀疏的Tmall數據集時,這種優勢更加明顯.這表明本文所提出的算法能更加有效的學習物品向量表達.此外,除了推薦的準確率,模型的運行時間也是衡量性能的重要指標.因此,本文將GELA模型與其他圖形嵌入方法在計算效率方面進行比較,使用相同100維的初始向量和GPU環境.得到各個模型在Yoochoose 1/64數據集上訓練迭代一次的時間開銷如表6所示: Table 6Time Cost of Training Different Graph Embedding Methods表6 Yoochoose 1/64上訓練不同圖模型的時間開銷 s 從表6可以發現,除了TransE模型之外,本文提出的GELA模型計算成本顯著低于其他圖表示學習方法,且TransE模型需近1 000次訓練迭代得到最好結果,而GELA模型設計簡單,只需要30次迭代.以上實驗結果證明GELA模型適用在大規模的IDG上進行物品的表示學習. 關于GELA算法中跳數的選擇問題.如2.3節所述,本文選用2跳路徑進行模型訓練.對于給定的物品點擊序列 Fig.7 The results of GESP by employing different hops embeddings on Yoochoose 1/64圖7 Yoochoose 1/64上使用不同跳數生成的embedding的GESP模型性能 從圖7可以看出,GESP在跳數為2時性能最佳,增加跳數長度將導致性能下降.這是因為當采樣路徑變長時,用戶的瀏覽興趣會隨著時間的推移而不斷改變.根據這一實驗結果,本文采用2跳路徑進行物品向量表達的學習. 本文首次提出一種利用協同過濾思想的基于圖表示學習的會話感知模型(GESP)用于基于會話的推薦系統任務.該模型基于用戶會話日志構造一個全局物品依賴關系圖,利用圖表示學習算法學習物品固定向量表達,以此為輸入,采用雙向LSTM構建一個混合記憶網絡模型,實現對用戶點擊行為的預測.采用固定的物品向量表達作為輸入,在不犧牲預測準確性的前提下,利用物品依賴圖中的結構信息,同時考慮用戶長短期興趣,緩解用戶的興趣漂移問題,生成多樣且新穎的推薦結果.本文為基于圖表示學習的會話推薦研究提供了新的建模思路和解決方案,同時也為后續研究留下了一些值得思考的問題,如在Yoochoose 1/64數據上,STAMP模型在MRR@K得分方面略優于GESP和NARM,這表明在構建SRS模型時需要對注意力機制進行進一步研究. 總體來說,本文實驗結果表明,在預測準確性方面,GESP模型優于其他相關先進模型,在長會話和稀疏數據集上也具有更穩定的表現.此外,與其他模型相比,本文提出的模型可以有效緩解用戶的興趣漂移對預測結果帶來的影響,能夠在不犧牲預測準確性的情況下,提供更加多樣新穎的推薦結果.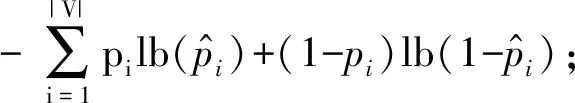
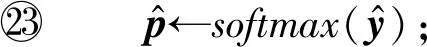
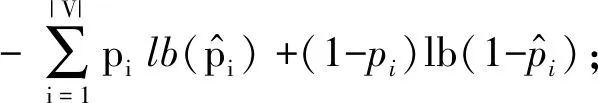
3 實驗結果與分析
3.1 數據集與預處理
3.2 對比模型
3.3 評價指標
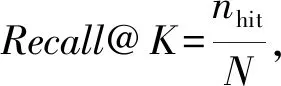
3.4 超參數
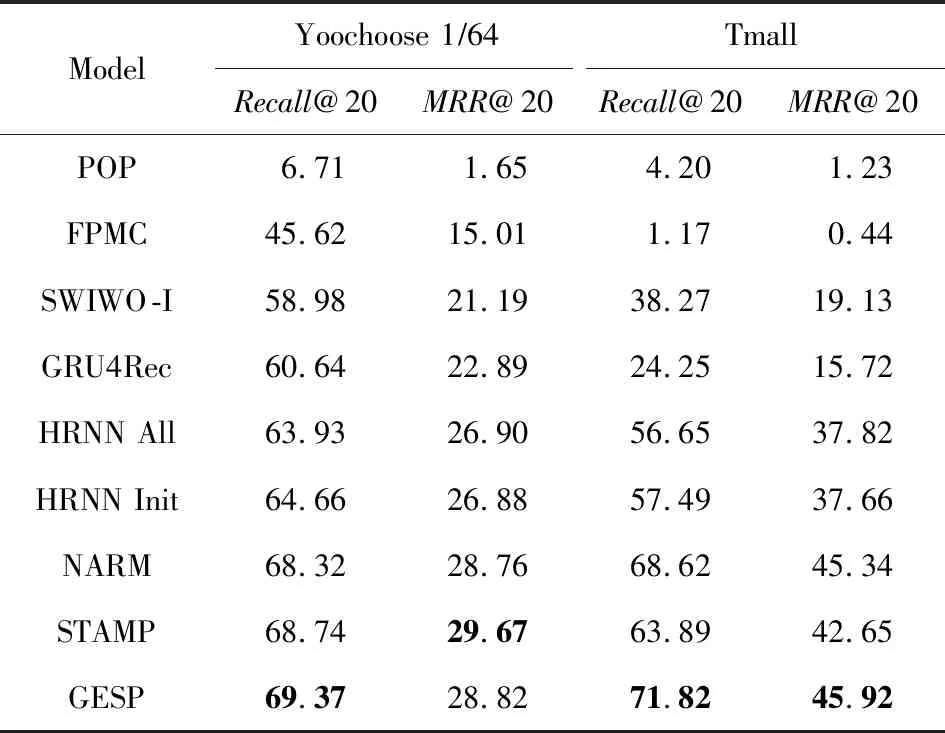
3.5 點擊預測
3.6 圖表示學習的必要性

3.7 對用戶興趣建模的有效性

3.8 推薦結果多樣性和新穎性分析
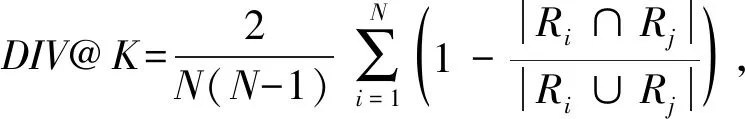
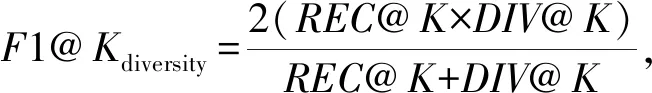
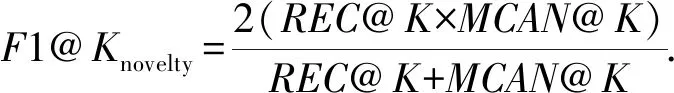
3.9 與其他圖表示學習算法的比較
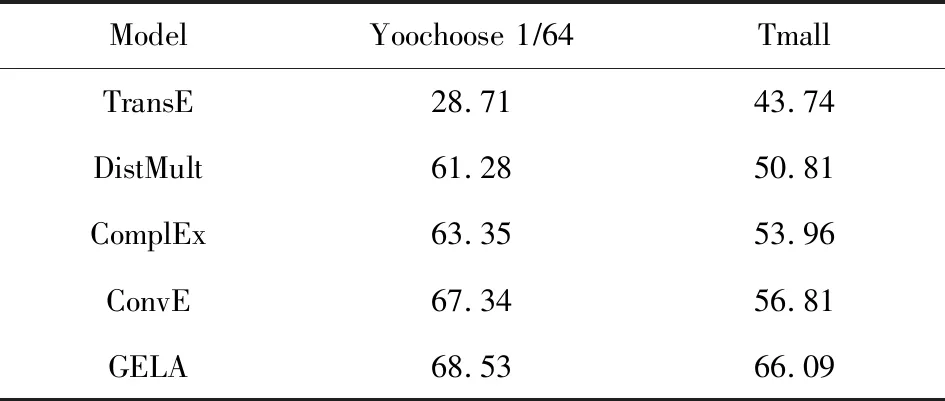

3.10 依賴圖采樣跳數的影響
4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50商用汽車(2016年11期)2016-12-19 01:20:16光學精密工程(2016年6期)2016-11-07 09:07:19發明與創新(2016年38期)2016-08-22 03:02:52太空探索(2016年5期)2016-07-12 15:17:55商用汽車(2016年6期)2016-06-29 09:18:54
