敏感漸進不可區分的位置隱私保護
2020-03-21 01:11:06張國印
計算機研究與發展 2020年3期
關鍵詞:用戶
王 斌 張 磊 張國印
1(哈爾濱工程大學計算機科學與技術學院 哈爾濱 150001) 2(佳木斯大學信息電子技術學院 黑龍江佳木斯 154007)(jmsuwang@163.com)
隨著當今世界發展,定位技術和無線通信技術不斷進步,使得基于位置服務更多地被應用在連續查詢中,這種通過在設定的時間段或設定的路段連續獲得查詢結果的服務方式越來越多地被廣大用戶接受并使用.由于連續查詢需要用戶提供連續位置變更,以獲得精準的位置相關服務信息,因而導致在快照查詢時就不得不面對的隱私泄露形勢更為嚴峻.由于連續位置可被攻擊者關聯,進而獲得位置軌跡,而位置軌跡包含有相較于離散位置更多的時空屬性信息,導致用戶隱私受到更為嚴重的威脅.
對于連續位置隱私保護問題,當前的研究主要集中在軌跡泛化[1-5]、關聯屬性模糊[6-10]和關鍵位置隱藏[11-18]等3類方法上.1)軌跡泛化是將用戶產生的位置軌跡與其他匿名用戶或虛假用戶產生的軌跡相泛化,使攻擊者無法在眾多的匿名軌跡中準確的識別用戶的真實軌跡,以此來保護用戶的位置軌跡隱私;2)關聯屬性模糊是將用戶每次查詢提供的位置以及在該查詢過程中產生的屬性信息與匿名用戶相泛化,影響攻擊者將離散位置關聯獲得連續位置軌跡的攻擊行為,進而降低攻擊者獲得用戶位置軌跡的概率;3)關鍵位置隱藏則是將潛在構成位置軌跡中的關鍵位置采用轉移或者從cache或代理獲得查詢結果的方式降低這些位置發送給LBS(location based service)服務器的概率,進而在連續查詢過程中從LBS服務器的視野中隱藏,降低攻擊者獲得位置軌跡的成功率,并提高連續查詢服務的服務質量.由于這類方法可看作是從關聯屬性模糊中發展過來的一類方法,因此在一定程度上存在2種或多種方法的交叉使用[19-21].
然而,用戶在進行連續查詢時不可避免地要向著敏感目標移動,進而表現為用戶所處位置敏感程度的漸進性,且這種漸進性并不隨著用戶的軌跡匿名或者軌跡是否準確真實而改變.也就是說產生的軌跡或者割裂開的子軌跡之間仍然存在著敏感漸進性.攻擊者可利用這種漸進性識別用戶潛在的查詢目標,進而造成用戶個人隱私的泄露.因此,針對這樣一種情況,本文基于廣義的差分隱私提出了一種敏感程度不可區分的隱私保護方法.該方法首先通過Voronoi圖對敏感興趣點位置劃分建立敏感區域,然后在敏感區域內根據敏感程度差異設定的敏感等高線所表示的用戶移動敏感變化,并通過在逐次查詢過程中添加的噪聲位置,實現對用戶查詢目標敏感程度變化的隱私保護.最后,通過對歐氏空間和路網環境中的模擬數據和真實數據的實驗比較,給出了該算法的使用范圍和應用條件,并且通過提出的基于敏感漸進的攻擊算法對其他同類的連續位置隱私保護方法的攻擊比較,證明了本文算法的優越性.
1 相關工作
連續查詢的便捷特性令這類查詢方式更多地被用戶在日常生活中所采用,因而導致在快照查詢下使用的隱私保護方法諸如k-匿名[22]、l-多樣性[23]、P2P(peer to peer)用戶協作[24]以及PIR(private information retrieval)[25]等方法逐漸顯得力不從心.針對這種連續查詢泄露用戶隱私的問題,簡單且基本的方法是對每一個位置進行匿名處理[26]或者將多個位置泛化為位置集合[27].但是這種方式并不能有效防止攻擊者在獲得的多個軌跡中分辨出用戶的位置軌跡.文獻[1]認為用戶的位置軌跡需要與其他歷史軌跡相混淆,以使攻擊者無法在多條位置軌跡中準確地識別用戶位置軌跡.基于這一觀點,Gao等人[2]通過協作用戶相似的移動方式完成軌跡匿名;Zhang等人[3]提出使用實時生成的虛假相似軌跡完成匿名;而Kato等人[4]更是豐富了這一觀點,將用戶軌跡中的停留位置考慮進去,提高生成軌跡的相似性;Ye等人[5]通過聚類后隨機添加的假軌跡降低了這種方法的計算復雜程度.但是這類軌跡匿名方法的先決條件是用戶首先生成軌跡,然后才能進行匿名,這使得攻擊者仍可獲得用戶的位置軌跡.盡管準確識別用戶位置軌跡的概率相對較低,但在獲得用戶軌跡的情況下可通過其他手段分析識別,存在潛在風險,因而研究者考慮如何讓攻擊者無法獲得用戶軌跡.
通常,用戶連續查詢產生的位置是通過用戶的各種屬性相互關聯后鏈接生成軌跡的,若將這些屬性加以模糊或者泛化可在一定程度上降低攻擊者獲得用戶軌跡的概率.針對多種屬性泛化,Zhang等人[6]提出了一種屬性泛化模型,將各種屬性通過相似性計算來尋找參與匿名的用戶,并通過一種聚類方式提升計算速度[7];文獻[8-9]考慮到中心服務器在尋找相同屬性用戶時的計算負載,通過協作用戶解密的方式尋找匿名用戶,利用協作計算加快了相似屬性協作用戶的尋找進程;考慮到攻擊者可利用任意2位置之間的關聯概率這種特殊屬性進行關聯,Zhang等人[10]更是利用廣義差分隱私提出了關聯概率不可區分,以此降低連續位置之間的屬性關聯.
關聯屬性模糊盡管能夠提供較好的隱私保護,但是這類方法在實際部署時可能會影響到服務質量.因為連續的多次查詢都受到同樣的保護勢必會增加中心服務器或者協作用戶之間的計算量,進而產生服務瓶頸.而且研究者發現,通過對連續位置中的關鍵位置進行隱藏同樣能起到限制攻擊者關聯獲得用戶軌跡隱私的目的.在這種思想的指導下,研究者使用不可觀測的混合區域mix-zone[11]來實現關鍵位置的隱藏,并基于加密技術[12]提升了這種方式的隱私保護程度.同樣基于該思想,文獻[13-15]分別考慮到利用協作用戶可cache查詢結果的特點,利用從周圍協作用戶獲得查詢結果的方法,將關鍵位置隱藏,躲避以LBS服務器為潛在攻擊者的探測行為.而文獻[16-17]則采用在協作用戶中建立代理的方式,通過可信代理全程隱藏位置,將更多的關鍵位置隱藏于代理之后.Schlegel等人[18]則通過用戶選定的位置網格隱藏用戶自身查詢的真實意圖,使攻擊者在更多情況下僅能獲得隱藏后的位置區域,進一步保護位置軌跡.
為了發揮關聯屬性模糊和關鍵位置隱藏2種方法的共同優勢,文獻[19]將這2種方法結合,利用候選區域進行關聯屬性模糊,利用推測區域對關鍵位置隱藏,同時保留了2類算法的優點;而文獻[20]則通過加密路段匿名實現這樣觀點;Zhang等人[21]將這種加密匿名應用在最短路徑計算,也取得了不錯的效果.
雖然上述提及的算法在其應用領域取得了較好的隱私保護效果,但是這些方法均忽略了用戶位置是否敏感這樣的關鍵問題,即在非敏感情況下用戶的位置不需要保護,而僅在用戶進入敏感區域才需要對用戶位置加以保護[28].Dewri等人[29]考慮到這種情況,對用戶提出的查詢進行了等高線劃分,在進入一定敏感等高劃分區域后進行隱私保護.而Sun等人[30]則將敏感區域進行了劃分,提出在匿名的過程中需要考慮對相同敏感類型區域中匿名用戶的要求.正如文獻[31-32]中所說的那樣,連續查詢之間的隱私保護是一個用戶與攻擊者之間的博弈,也可看作是一種敏感程度變化之間的變化博弈過程中.與完美匿名[33]不同,這種連續敏感程度變化過程不能被中心服務器或協作用戶所泛化,也不能通過諸如[34-36]計算集會地點的方式,僅通過有限輪次獲得結果并隱藏真實位置,而且這種敏感程度變化還可

Table 1 Statistical Table of Advantages and Disadvantages of Five Different Algorithms表1 5類不同算法優缺點統計表
因為匿名用戶的增加而變得更易被攻擊者所識別.因此,為了在敏感程度變化的過程中有效地保護用戶的查詢目標,進而保護用戶的個人隱私,本文基于Voronoi建立敏感程度等高線,并基于廣義差分隱私提出了敏感程度不可區分的隱私保護算法,以此在用戶連續查詢過程中位置敏感程度漸進的情況下保護用戶的位置和查詢隱私.各算法在隱私保護能力以及服務質量和對敏感攻擊等方面的優缺點如表1所示.
2 預備知識
為便于對本文所提出算法的理解,本節將對隱私保護所針對的攻擊模型、所采用的隱私保護基本思想和使用的系統架構加以簡要介紹.為便于讀者對本文中使用的各種變量符號的理解,表2對本文中使用的各種符號進行了描述:

Table 2 The Various Variable Symbols Involved in This Paper表2 文中涉及的各種變量符號
2.1 攻擊模型
考慮到在當前環境范圍內移動用戶存在的3種情況:1)向著敏感位置移動;2)背向敏感位置移動;3)在同一或較近敏感等高范圍內交替移動.這3種情況對應3種用戶:1)以該敏感位置為查詢目標的移動用戶;2)查詢結束后離開該敏感位置的移動用戶,且該用戶進行連續查詢的可能性較低;3)通過當前單元格向著其他敏感位置移動的經過用戶.由此,可認為在當前單元格中,以LBS服務器為主的攻擊者可利用連續查詢的敏感度漸進對用戶的查詢目標加以攻擊.為了說明敏感漸進的攻擊手段,同時也為了更好地分析本文所提出的隱私保護基本方法的重要性,本文在對用戶敏感程度變化的基礎上給出了基于敏感漸進的攻擊方法,該方法可用于對已有的隱私保護方法進行測試攻擊.
在用戶移動過程中,假設用戶進行n次連續查詢后可到達目標位置,則攻擊者利用當前提交的位置集合分析,可獲得n個連續提交位置組成的集合L={l1,l2,…,ln}以及每個子位置集合對應的敏感度集合SL.其中,敏感度Sl為當前位置與敏感目標位置之間相互關聯的百分比,表示為
Sl=p(l→ls).
(1)
對于當前位置集合,若存在|Sl1|≤|Sl2|≤…≤|Sln|,則攻擊者可認為用戶向著該敏感目標位置ls移動,用戶的查詢目標為該敏感點.進而攻擊者在連續查詢的過程中可獲知用戶隱私.
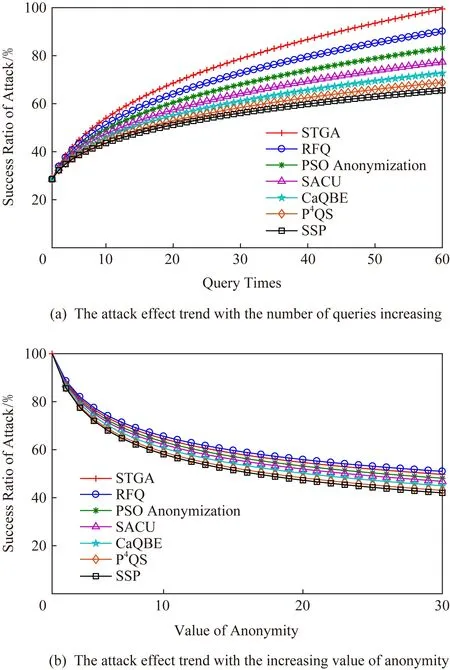
Fig.1 The attack effect for seven privacy protecion schemes圖1 針對7種隱私保護算法的攻擊效果
基于這樣的一種攻擊方式,本文對當前存在的7種主流隱私保護算法進行了嘗試性的攻擊測試,取得如圖1所示的攻擊效果.所測試的隱私保護算法有相似軌跡計算的STGA(similar trajectories generation algorithm)算法[3]和隨機插入假軌跡的RFQ(random fake queries)算法[5],有關聯屬性模糊的PSO Anonymization(particle swarm optimiza-tion anonymization)算法[7]和協作用戶屬性匿名的SACU(similar attribute collaborative users)算法[8],有關鍵位置隱藏的CaQBE(caching query blocks exchanging)算法[13]和使用代理的P4QS(peer to peer privacy preserving query service)算法[17],以及加密路段進行匿名的SSP(section shortest path)算法[21].其中,圖1(a)表示在匿名值固定為20情況下,隨查詢次數增加導致的攻擊效果變化;圖1(b)表示在連續10次查詢情況下,隨匿名值增加導致的攻擊效果變化.所有測試結果均通過2 000次隨機測試后,利用結果平均取值建立的攻擊效果圖.
綜合對比圖1(a)和圖1(b)可以看出,這種根據敏感程度漸進的攻擊方法對軌跡匿名、關聯屬性模糊和關鍵位置隱藏的隱私保護算法都取得了很好的攻擊效果,僅對于加密路段的隱私攻擊效果稍差.產生這種情況的主要原因是這些隱私保護算法主要針對的是如何混淆或防止攻擊者獲得用戶的位置軌跡,但未能有效地處理用戶向目標位置移動過程中產生的敏感程度漸近.而且,匿名用戶數量的增加所起到隱藏用戶的作用有限,反而因為查詢次數的增加而在一定程度上提升了攻擊效果,為攻擊者獲得用戶查詢目標提供了便利.
2.2 隱私保護思想
對于敏感程度漸進這種可利用的用戶特性,顯然傳統的基于k-匿名的隱私保護模型無法起到預期的隱私保護效果.對于這樣一種情況,較為有效的方法是令攻擊者可獲得的敏感漸進程度表現不明顯或者不可區分.基于這樣一種思想,本文首先以敏感位置為圖心建立當前區域的Voronoi圖,然后在每個單元格中根據敏感情況變化建立該單元格內的敏感等高線,并通過敏感等高線所表示的敏感程度劃分當前單元格內的敏感變化,泛化用戶提交位置的敏感程度.最后,通過噪聲位置覆蓋,使得用戶的真實位置與噪聲位置所產生的敏感程度在移動之后彼此不可區分,令攻擊者無法利用用戶在該單元格連續查詢過程中的敏感程度變化識別查詢目標,進而保護用戶的個人隱私.
2.3 系統架構
由于本文所提出的算法需要在指定區域建立Voronoi圖,且向該圖的單元格內添加噪聲,這使得分布式架構中的移動客戶端因其計算能力很難實現預定構想.因此,本文選擇如圖2所示的帶有中心服務器的集中式架構.在該架構中,共包含3種實體,分別是用戶、中心服務器和LBS服務器.其中,用戶主要指那些有連續查詢要求,并且配備了能夠完成定位與信息交互設備的移動用戶,該實體能夠與中心服務器和LBS服務器之間進行信息交互,且具有對查詢結果基本的接收處理能力,在本文中為保護用戶隱私,用戶只與中心服務器進行信息交互而不與LBS服務器進行信息交互;中心服務器是一種由政府部門或大型商業機構提供的可信的隱私保護服務實體,該實體能夠對用戶發送過來的查詢信息進行隱私保護處理,在完成對用戶提交信息的計算加工之后,將查詢信息發送給LBS服務器,并對LBS服務器反饋的查詢結果集合進行結果提取后返回給查詢提交用戶;最后,LBS服務器是指擁有位置服務數據,并能根據用戶要求提供查詢結果的服務提供商或數據擁有者,該實體一方面能夠按照協議完成用戶要求的查詢請求,另一方面又存在著對用戶隱私信息的好奇行為,同時可根據掌握的道路或區域情況等背景信息分析用戶連續查詢過程中的查詢目標.
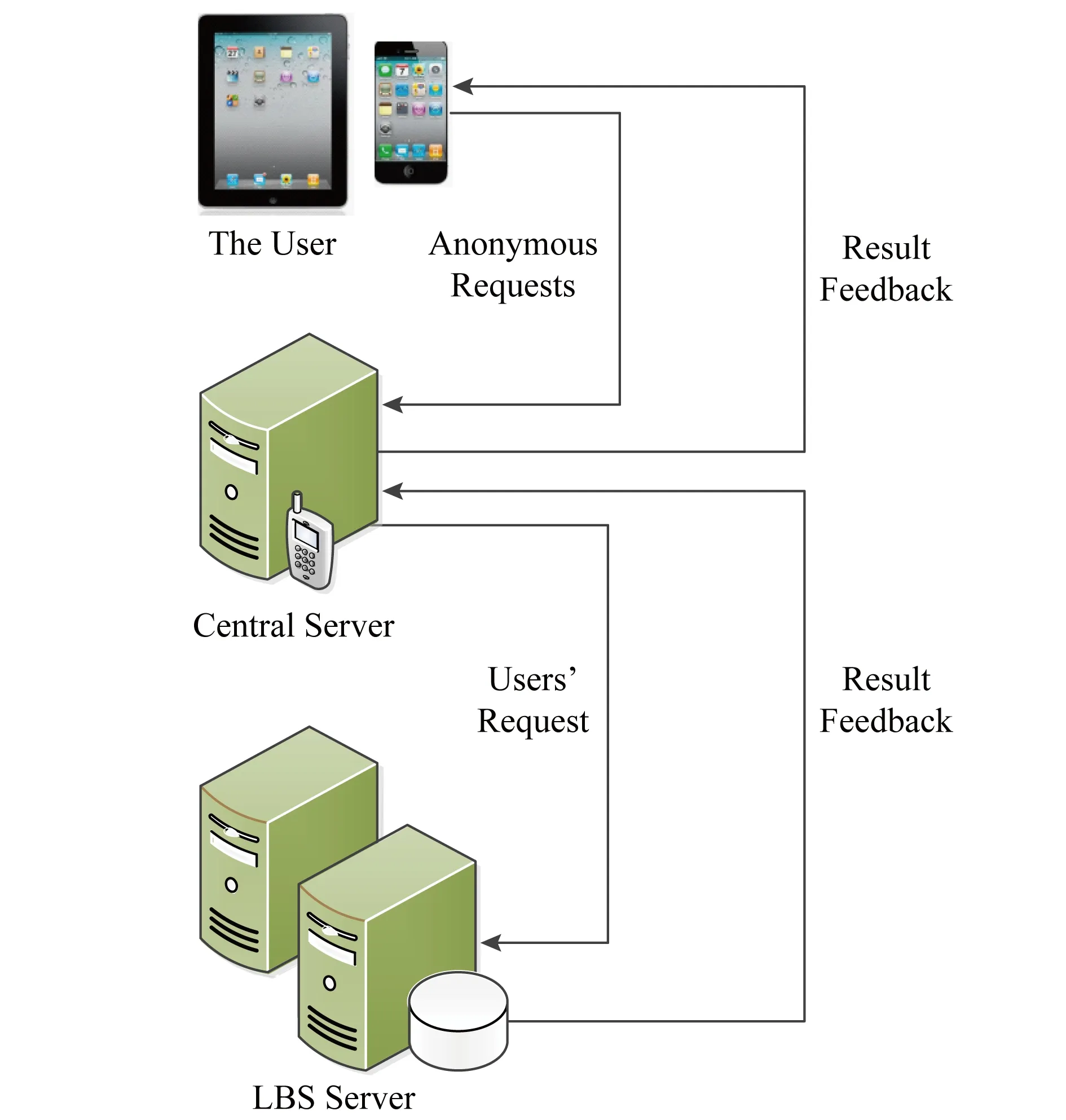
Fig.2 The system architecture of centralized model圖2 集中式系統架構
3 基于敏感程度不可區分的隱私保護方法
本文所提出的敏感程度不可區分的隱私保護方法分為2個主要處理階段:1)建立能夠表現用戶敏感程度漸近的位置變化區域;2)在這一確定區域按照廣義差分隱私的思想,通過添加噪聲建立敏感位置漸進程度的不可區分,以此實現對用戶的位置和查詢的隱私保護.
3.1 基于Voronoi的敏感等高線建立
通常情況下,用戶所在的區域是一個由各種不同的敏感點組成的位置環境,其中每個敏感點所在的區域都可用一個不規則的多邊形所限定.這令利用Voronoi圖建立不規則多邊形成為可能.按照用戶提供的敏感位置,在不考慮這些敏感位置是否具有相同敏感程度的情況下,完成Voronoi圖的繪制,因此不同敏感程度的Voronoi圖生成元并不會造成Voronoi單元格的差異,且不會影響算法效果.根據Voronoi圖的基本性質,即每個單元格中的任意位置距當前單元格的圖心距離要低于距離其他單元格圖心位置這一特性,可利用Voronoi圖來標識當前區域中的所有敏感位置.于是,中心服務器在收到由用戶發送的隱私保護請求之后,首先根據用戶所在空間存在的敏感位置建立基于該空間的Voronoi圖,如圖3所示;在建立完成Voronoi圖之后,考慮到用戶進行連續查詢時是需要向著某一敏感位置不斷移動,該移動將會導致敏感程度的不斷漸進.因此,對于建立完成的Voronoi圖,針對該圖中的全部單元格的敏感程度漸進變化情況,建立敏感等高線.建立完成的敏感等高線如圖3中的單元格A所示,其中的虛線部分分別代表不同的敏感度等高區域,等高線越接近該單元格的圖心則敏感程度越高.用戶在該單元格中向著敏感位置移動則會產生敏感程度漸進,攻擊者有可能分析獲得用戶位置和查詢隱私.
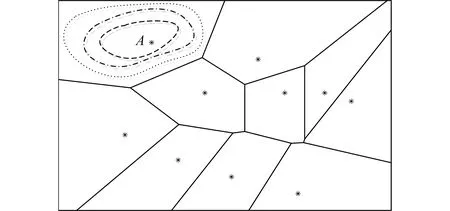
Fig.3 The Voronoi diagram of sensitive positions and cells with sensitive contour lines圖3 敏感位置Voronoi圖及單元格內敏感等高線
敏感等高線的建立是通過當前單元格內存在具有相同敏感程度的各位置相互連接所建立的.如圖4所示,在建立的Voronoi圖中的某一單元格內,存在如圖4中虛線所示的具有不同敏感程度的各個位置,將相同敏感程度的位置相互連接,即可獲得當前敏感度所指示的敏感等高線.為了便于計算,本文僅將敏感等高線限定在以20%為單位的遞進取值上.由此可獲得如算法1所示的敏感等高線建立過程.
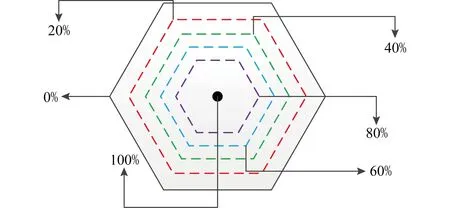
Fig.4 Degree of sensitivity in Voronoi cell圖4 Voronoi單元格內的敏感度
算法1.敏感等高線建立算法.
輸入:單元格內各位置的敏感度SL;
輸出:敏感等高線.
① for (i=1;i≤L.num;++i)
② while (lj不可鏈接且j≤L.num-1)
③ if (Si=Sj)
④ if (li.next=null)
⑤ 鏈接li和lj;
⑥ else
⑦ 鏈接lj-1和lj;
⑧ end if
⑨ else
⑩ ++j;
算法1通過敏感度之間的相似程度建立敏感等高線.在建立完成之后,可根據計算方面的便利性,按照敏感等級的百分比進行等高線劃分,進而獲得如圖4所示的多邊形單元格內的敏感等高線劃分.由此,利用Voronoi圖,我們建立了用戶在當前區域移動情況下的敏感程度變化等高線表示.在建立完成這種等高線之后,為了有效地保護用戶的位置和查詢隱私,需要在指定的等高線范圍內添加噪聲,而噪聲按照什么標準添加,將在3.2節加以說明.
3.2 基于敏感程度不可區分的噪聲添加
在對用戶位置隱私進行攻擊的情況下,攻擊者將會掌握大量的背景知識,本文已在第2節給出了這種潛在的攻擊方式,并且對已有的隱私保護方法進行了嘗試性的攻擊.從其攻擊結果上不難看出這種攻擊方式相當有效.為了應對這種攻擊手段,本文已建立了基于敏感程度漸進的敏感等高線,因此需要在滿足敏感程度不可區分的前提下對用戶的隱私信息加以保護.
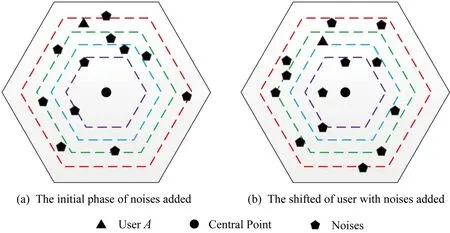
Fig.5 The variation of noises added in Voromoi cell圖5 Voronoi單元格內添加的噪聲變化
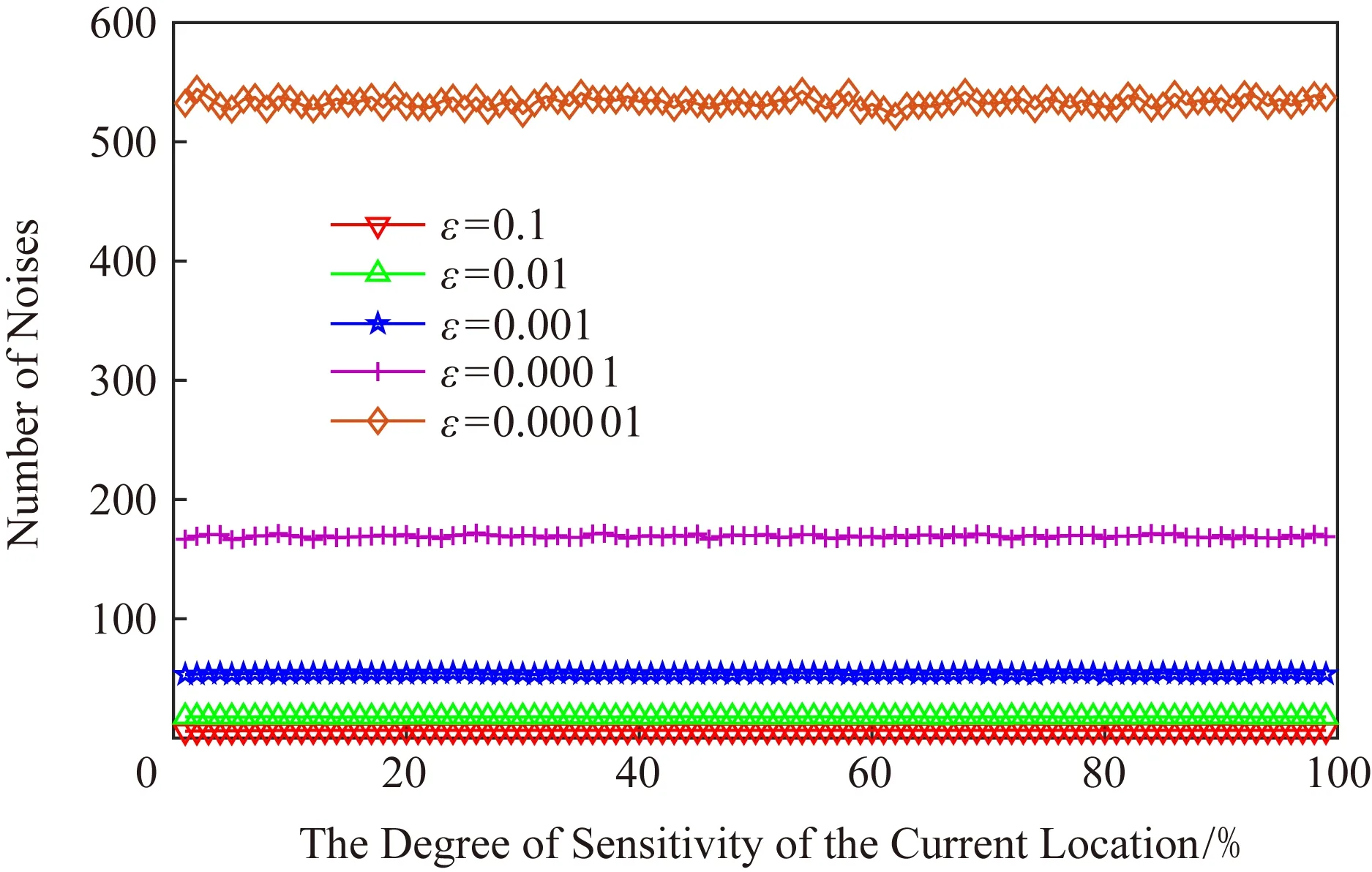
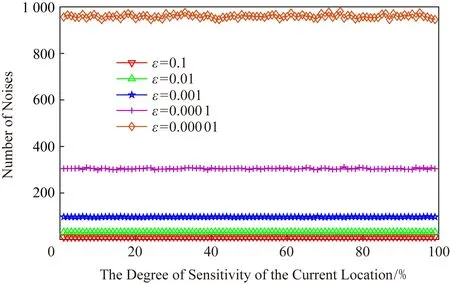
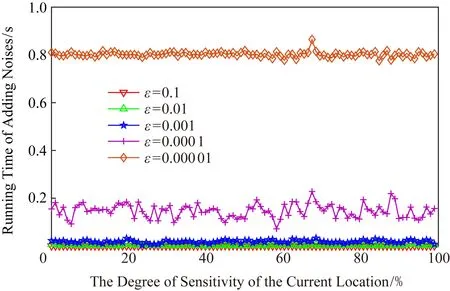
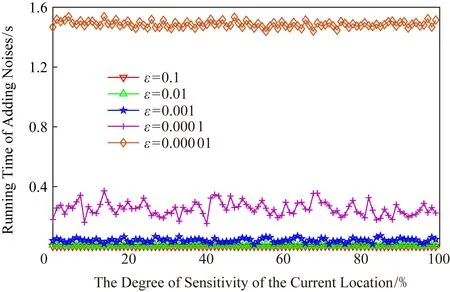
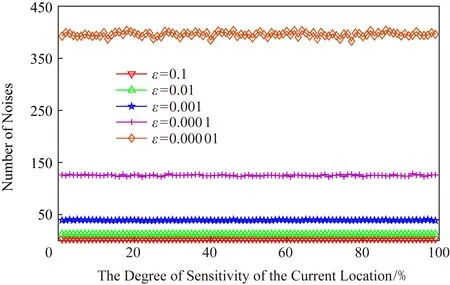
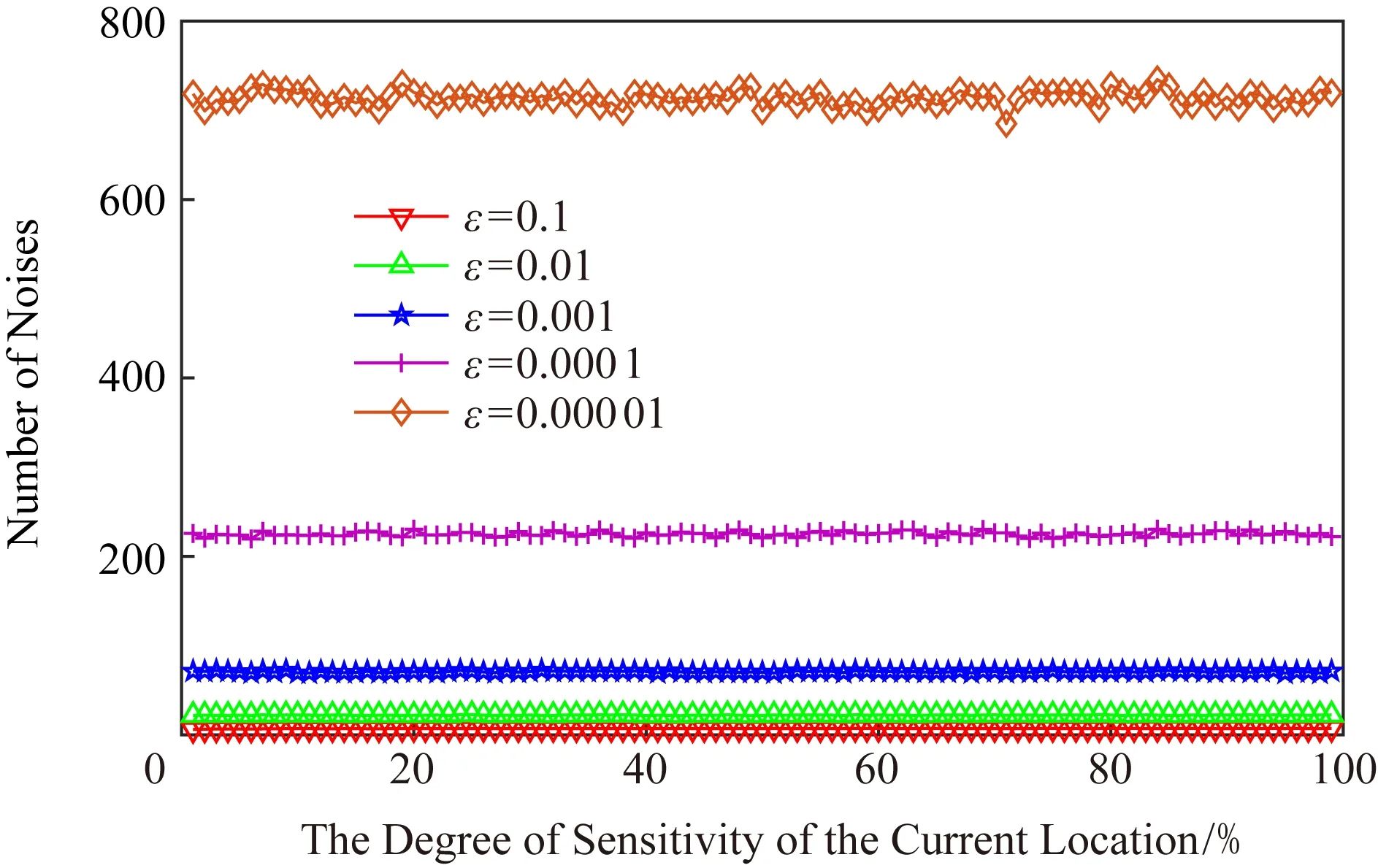
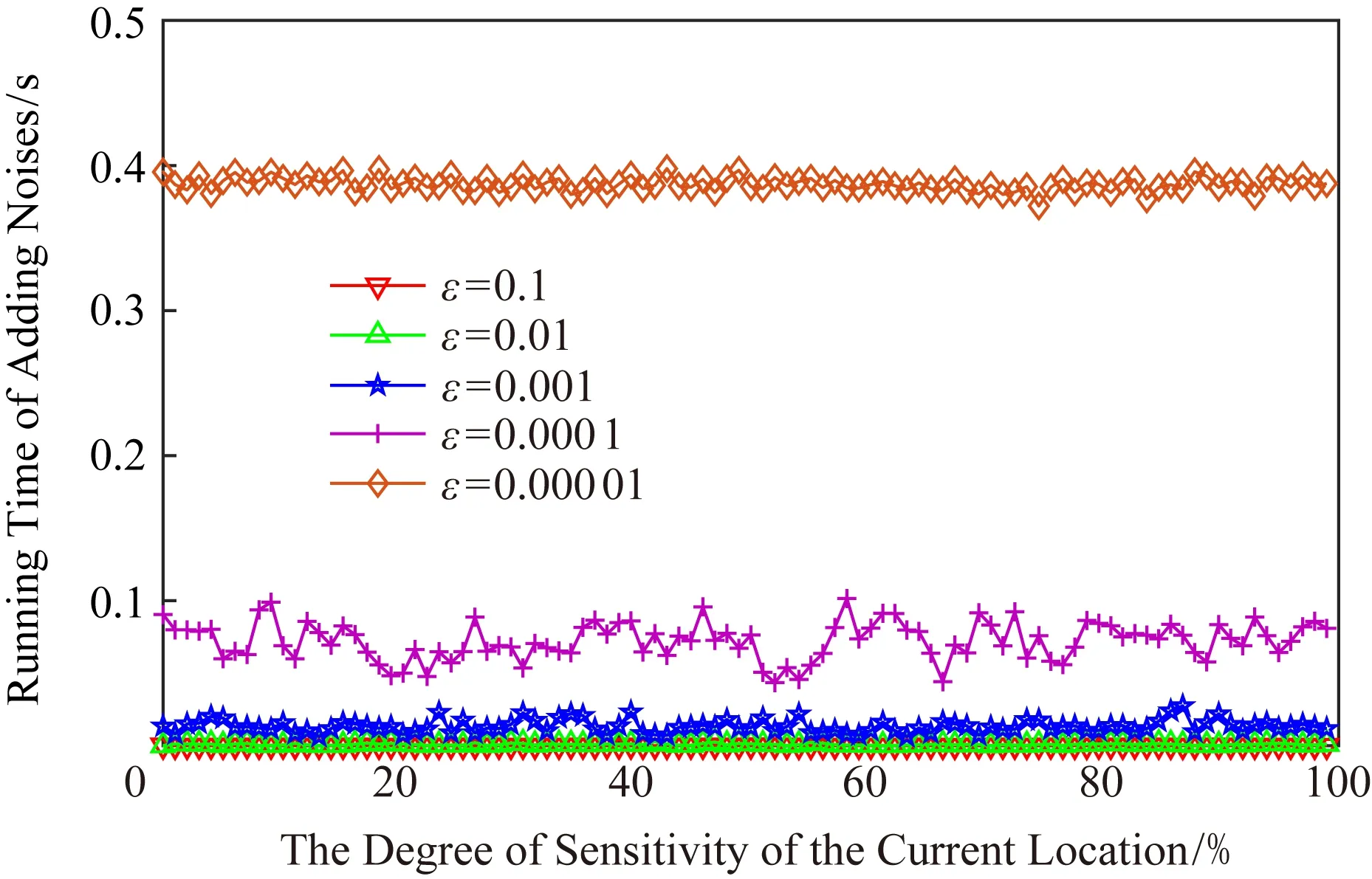
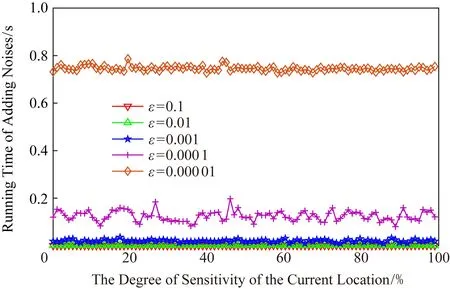
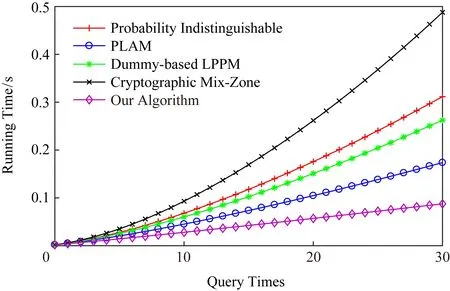
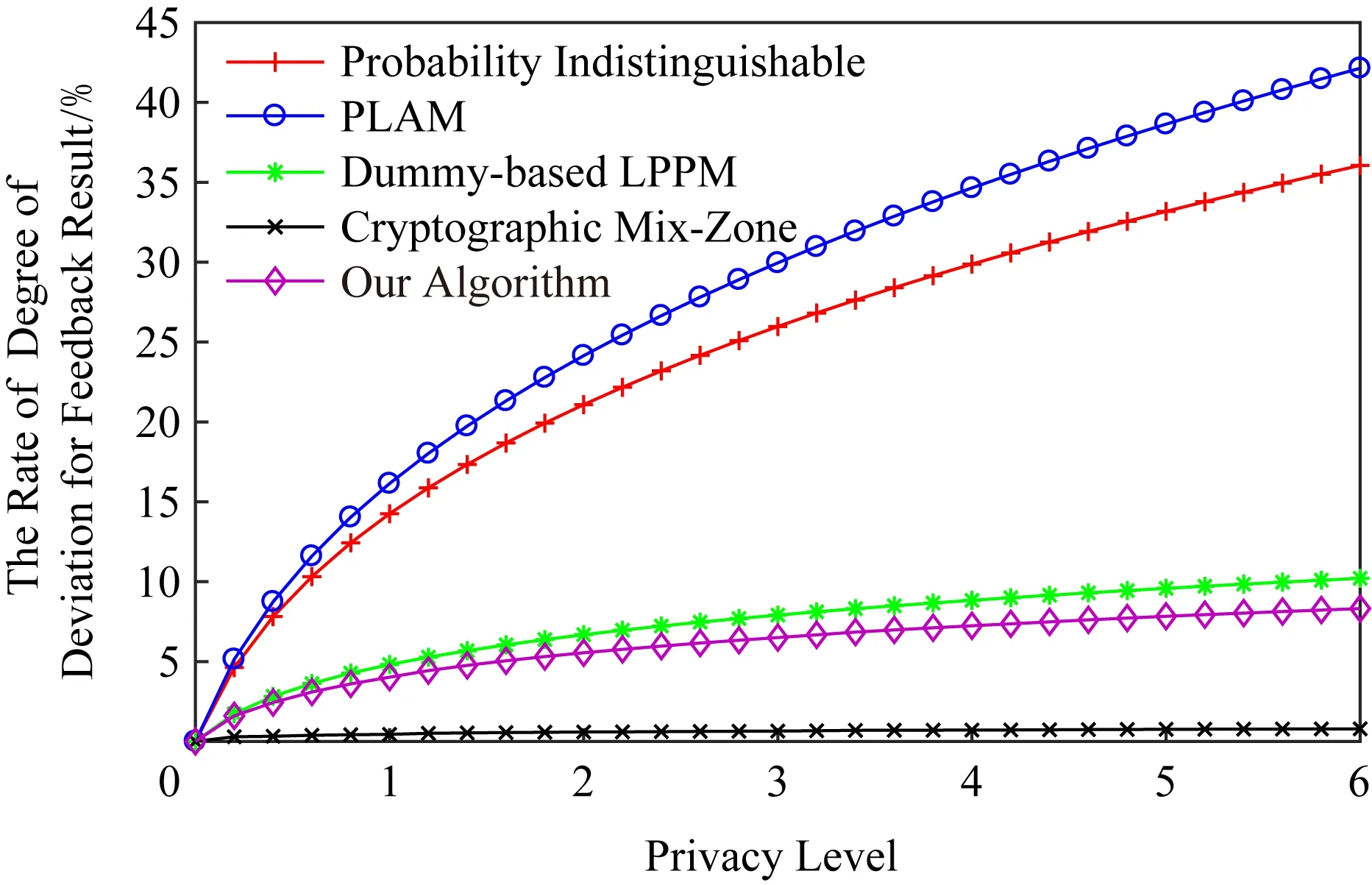
正如本文在攻擊模型中描述的那樣,攻擊者可利用當前區域內的敏感程度漸進分析獲得用戶隱私.設用戶當前位置的敏感程度為Sc,攻擊者所能掌握的該單元格內真實用戶敏感度集合為SL,則在用戶向著敏感位置移動過程中的敏感程度變化為Sc MP(μ1,μ2)=Supz∈Z|μ1(z)-μ2(z)|. 當μ1(z),μ2(z)同時為0或者∞時,|μ1(z)-μ2(z)|=0,即MP(μ1,μ2)在μ1,μ2對每個值z有相似概率.MP表示p和p′之間的不可區分級別,如果該值越小,表示2次提交的位置之間的敏感程度不可區分性越強.那么機制P(K(L)→ls)→P(Z)滿足ε-敏感度不可區分,當且僅當對于連續2次提交的位置集合li和lj之間的敏感度變化存在: MP(p(K(li)→ls),p(K(lj)→ls))≤ (2) 式(2)可等價表示為K(li→ls)(z)≤eεMP(p(li→ls),p(lj→ls))K(lj→ls)(z),對于所有z∈Z.參數ε可看作是對MP的縮放.代入式(2)可表示為 MP(p(K(li)→ls),p(K(lj)→ls))≤ (3) 即 MP(K(Sli),K(Slj))≤εMP(Sli,Slj). (4) 從式(4)中可知,通過函數K(·) 的處理,使得攻擊者獲得的連續2次查詢敏感度變化彼此不可區分,即|Sli-Slj|<ε.式(4)中,隱私參數ε的取值是通過用戶隱私需求設定的,對于該值的討論不在本文的研究范圍之內,本文不再探討如何選擇. 同樣,為了保證每次提交的位置集合,在攻擊者掌握最大背景知識的情況下,仍不能通過敏感程度差異識別用戶,還需保障提交位置集合中,真實位置與全部位置之間滿足|SL-Sr|<ε.其中,SL為提交的全部位置集合的敏感度,Sr為真實位置敏感度.由此可認為當前用戶的敏感程度在向著敏感位置移動過程中滿足ε-敏感程度不可區分.其中,敏感程度以敏感等高線建立的敏感百分比取值進行計算. 添加噪聲的基本要求已經通過圖5和分析加以說明,其具體的操作過程如算法2所示: 算法2.滿足ε-不可區分的連續噪聲添加算法. 輸入:當前用戶位置lc、前一次查詢位置lc-1、前一次查詢位置集合Lc-1、當前所有位置敏感度集合SL; 輸出:噪聲位置集合Ld. ① if (lc-1=null且Lc-1=null) ② while (|SL-Sc|≥ε) ③ 隨機添加噪聲ld; ④SL=(Sc+Sd)/L.num; ⑤Ld=Ld+ld; ⑥ end while ⑦ else ⑧ while (|SL-Sc|≥ε且|SL-SL-1|≥ε) ⑨ 隨機添加噪聲ld; ⑩SL=(Sc+Sd)/L.num; 在算法2中,利用代碼行③和⑨來添加隨機噪聲,即添加隨機位置與用戶真實位置混合,并通過添加的隨機噪聲利用當前位置集合與前一位置集合產生的共同敏感度之間的極小差異來實現敏感程度漸進的不可區分.此時,2個臨近的由中心服務器發送給LBS服務的位置集合滿足|SLi-SLj|<ε,即攻擊者所能收到的2個位置集合產生的敏感程度集合之間不可區分.同時這種ε-敏感程度不可區分也保障了在當前提交的位置集合中,各位置敏感程度之間的不可區分性. 本文所提出的隱私保護方法,其安全性主要取決于建立的敏感區域是否能夠正確表示敏感程度漸進,以及通過添加噪聲滿足的ε-敏感程度不可區分是否能夠有效地抵抗基于敏感程度漸進的攻擊方法. 首先,Voronoi圖的圖心是由敏感位置所確定的,且距離圖心位置越近,其敏感程度越高.同時,Voronoi圖性質使得當前單元格中的位置據其圖心的距離低于該位置與其他單元格圖心的距離,這使得在當前單元格內的所有位置的敏感程度呈現一種從單元格邊緣到圖心的遞進趨勢,且這種趨勢并不受單元格之間的圖心所影響.因此,在這種敏感程度漸進基礎上建立的敏感等高線能夠真實地反映當前單元格內不同位置敏感程度的差異和漸進性. 其次,對于使用Voronoi建立的敏感程度等高線,在同一單元格內的用戶從位置li向圖心位置移動到lj,有其敏感程度變化Sli≤Slj.攻擊者在無法獲得該用戶準確位置的情況下,可根據當前單元格內全局敏感度變化來判斷用戶是否向圖心所代表的敏感位置移動,于是有連續2次查詢所提交的敏感度變化SLi≤SLj,進而攻擊者分析獲得用戶的移動目標.但是,由于本文算法基于ε-不可區分在每次查詢過程中對當前單元格添加了隨機噪聲,使得|SLi-SLj|<ε,即當ε取值足夠小時,有敏感程度變化百分比在2次查詢敏感程度集合中不可區分.進而攻擊者無法通過敏感程度之間的變化猜測用戶的移動目標. 最后,由于在連續2次查詢過程中,添加的噪聲分別滿足|Sli-Slj|<ε,使得在連續的2個敏感程度集合中,用戶敏感程度是否存在或者是否變化對整個敏感程度集合的影響低于ε取值.這進一步令攻擊者在掌握當前區域其他用戶敏感程度的前提下,仍不可通過敏感程度集合的差分運算獲得用戶的敏感程度百分比,因此在用戶未移動的情況下,攻擊者也無法通過其掌握的最大背景知識獲得用戶的位置和查詢隱私. 定理1.本文算法可保護用戶的敏感漸進隱私. 證明.對于2.1節中所提出的攻擊模型,以及攻擊者所能掌握的泛化后的位置集合La和Lb有2個位置集合的敏感度關聯百分比SL=p(La→Lb).攻擊者獲得的理想結果是能夠準確的獲得|SLa|≤|SLb|,從而分析用戶是向著Lb中的位置移動.但是,由于存在隨機函數K(·)對2個集合中添加噪聲數據,使得在滿足敏感度不可區分級別MP的基礎上有MP(p(K(li)→ls),p(K(lj)→ls))≤εMP(Sli,Slj),那么當隱私參數ε在取值足夠小的情況下,敏感度關聯百分比足夠小,甚至可忽略不計,此時SL與之前獲得的敏感度SL′之間的取值不可區分,因此攻擊者無法準確辨識出2個臨近位置集合之間的敏感程度變化,用戶的位置隱私得以獲得保護. 由此,可認為本文所提出的方法能夠有效地在攻擊者使用敏感程度變化作為攻擊手段的前提下保護用戶的位置和查詢隱私. 證畢. 在算法性能方面,針對用戶實體,由于算法的主要執行者是中心服務器,所有用戶實體僅需要將自身真實位置提交給中心服務器即可,此時用戶實體的算法時間復雜度為零;針對中心服務器,本文算法的整體是由中心服務器完成的,在中心服務器中執行算法1和算法2,且上述2個算法可看作是嵌套使用的,因此該實體的算法時間復雜度為O(n2).針對LBS服務器,LBS需要按照由中心服務器提交的噪聲和真實位置集合反饋查詢結果,因此其算法時間復雜度可認為是O(n). 為便于分析本文所提出方法的有效性和各參數對用戶的影響,本文將通過實驗測試對算法進行比較和模擬.實驗環境為筆記本電腦Intel core I5,4 GB內存,Windows7操作系統,并采用Matlab R2017a作為測試工具.同時,為了驗證在歐氏空間和路網環境的差異,實驗將基于這2種不同的環境進行分析對照.實驗測試將分別在提供隱私保護在隱私參數變化過程中的噪聲添加數量、算法執行時間、查詢結果提取時間和不同隱私參數下的攻擊成功率等幾個方面展開. Fig.6 The number of noises added in Euclidean space圖6 歐氏空間下添加噪聲數量 圖6給出了不同隱私參數ε取值在歐氏空間下滿足敏感程度不可區分所需添加的噪聲數量.由圖6可知,當前用戶所處位置的敏感并未對添加的噪聲數量有所影響,且在隱私參數ε>0.001的情況下,添加的噪聲數量僅略高于50,只有在隱私要求較高的ε取值下,才會需要大量的噪聲來滿足不可區分性,此時添加的噪聲數量較為巨大.但對于一般用戶而言,ε取0.001左右的值時,已經可以提供較好的隱私保護效果,因此算法可在實際歐氏空間下部署. 圖7給出了不同隱私參數ε取值在路網環境下滿足敏感程度不可區分所需添加的噪聲數量.與圖6進行對比分析可以看出,在路網環境下為滿足不可區分性,算法需要添加高于歐氏空間情況下的噪聲數量.造成這種現象的原因是,在路網環境下只有真實存在于道路上的噪聲位置才可以起到泛化作為,而路網中道路環境的限制遠高于歐氏空間.這使得為達到同樣的隱私保護不可區分性,路網環境需要添加近似于歐氏空間2倍的噪聲,以此實現敏感程度不可區分. Fig.7 The number of noise added in road network圖7 路網添加噪聲數量 Fig.8 The running time of adding noises in Euclidean space圖8 歐氏空間添加噪聲的計算時間 圖8給出了不同隱私參數ε取值在歐氏空間下添加滿足敏感程度不可區分所需的計算處理時間.從圖8中可以看出,與添加噪聲數量相似,算法計算處理時間同樣不因當前用戶所在位置的敏感程度變化而改變.在隱私參數ε>0.001的情況下,因添加噪聲數量相對較少,算法的執行時間均低于0.1 s,只有在隱私要求極高的情況下,算法需要計算選擇更多的噪聲位置以滿足敏感程度不可區分,此時才會導致較長的處理時間,但該處理時間仍低于0.9 s,基本能滿足基于位置服務實時反饋查詢結果的需求. 圖9給出了不同隱私參數ε取值在路網環境下添加滿足敏感程度不可區分所需的計算處理時間.同樣與圖8進行對比分析,可以看出在路網環境下,算法的處理計算時間要高于在歐氏空間下的處理計算時間.這主要是因為添加的噪聲數量在路網環境要高于歐氏空間,更多的計算處理時間主要是在對路網限制和噪聲選擇上所耗費的處理時間,因此相比歐氏空間產生了接近于2倍的計算處理時間. Fig.9 The running time of adding noises in road network圖9 路網環境添加噪聲的計算時間 從添加噪聲數量方面看,這種方法添加的噪聲數量很大,尤其當ε取值較小的情況下,噪聲數量十分巨大,在這種情況下有可能會使LBS服務器的負載過大,造成服務瓶頸.另外,隨著用戶隱私要求的提升其計算處理時間尤其是在現實的路網環境下的計算處理時間較高.因此,可適當對用戶提交位置進行可計算范圍內的偏移,利用中心服務器的計算處理能力,在獲得查詢結果后按照偏移距離對用戶查詢結果加以計算提取.由此,可獲得用戶位置偏移后在歐氏空間和路網環境的噪聲添加數量. 偏移的方向選擇為用戶當前位置向著前一次查詢位置方向進行偏移,以此降低敏感程度之間的變化,同時為了提升偏移的不可確定性,將偏移距離設定為當前位置與上一位置之間距離的1/2~ 3/4之間的隨機距離,一方面提升偏移距離的不確定性,另一方面在保障降低敏感程度變化的同時不至于造成過多的服務偏差.用戶的偏移過程如算法3所示. 算法3.偏移優化算法. 輸入:當前用戶位置lc、前一次查詢位置lc-1; 輸出:偏移后位置lc′. ① if (lc-1=null) ②lc′=lc; ③ else ④lc′=lc-1和lc之間1/2~3/4處任意偏移位置; ⑤ end if ⑥ returnlc′ 算法3給出了對用戶進行噪聲添加實現敏感漸進不可區分保護之前的用戶位置預處理過程,該偏移處理的目的是為了降低添加噪聲的數量,減少噪聲對中心服務器等實體的影響.由于偏移會造成反饋結果與真實結果之間的偏差,因此偏移距離不易過大,且為實現減少噪聲,設定偏移量為1/2~3/4處的任意偏移位置.如何有效地界定偏移上界將在今后的研究中具體展開.為了便于同無偏移方法進行比較,給出了在歐氏空間和路網環境下的添加噪聲數量測試以及算法執行時間測試. 圖10給出了不同隱私參數ε取值在歐氏空間下通過對用戶位置偏移后滿足敏感程度不可區分所需添加的噪聲數量.與圖6對比可以發現,經過用戶位置偏移之后,其噪聲添加數量同樣不隨著用戶所處位置的敏感程度變化而變化,并且所需要添加的噪聲數量明顯減少.這是因為隨著用戶位置向著上一查詢位置偏移,用戶的敏感程度變化減少,為滿足敏感程度不可區分所需要調節的敏感程度百分比同樣降低,因而導致所需要添加的噪聲數量同時減少.由此可見,用戶位置偏移可實現減少添加噪聲數量的目的,降低了中心服務器的服務負載. Fig.10 The number of noises added in Euclidean space with location shifting圖10 偏移后歐氏空間的噪聲數量 圖11給出了不同隱私參數ε取值在路網環境下通過用戶位置偏移后滿足敏感程度不可區分所需添加的噪聲數量.與圖7相比較可見偏移后在路網環境下同樣降低了對噪聲數量的需求,滿足了敏感程度的不可區分.同樣,與圖10相比較,可見即使通過用戶的位置偏移,由于路網環境的限制作用,在路網環境下,仍需要添加相較于歐氏空間更多的噪聲,以滿足ε-敏感程度不可區分. Fig.11 The number of noise added in road network with location shifting圖11 偏移后路網添加噪聲數量 圖12給出了不同隱私參數ε取值在歐氏空間下通過用戶偏移后導致的添加滿足敏感程度不可區分所需的計算處理時間.與圖8相比較,經過用戶的偏移后,由于添加的噪聲數量發生了變化,致使其計算處理時間同樣減少,并且通過降低對添加噪聲的計算處理,中心服務器的服務負載被有效降低,其計算處理時間要低于相同環境下未進行偏移的用戶. Fig.12 The running time of adding noises in Euclidean space with location shifting圖12 偏移后歐氏空間添加噪聲的計算時間 圖13給出了不同隱私參數ε取值在路網環境下通過用戶偏移導致的滿足敏感程度不可區分所需的計算處理時間.與圖9相比,在偏移后,中心服務器的處理時間明顯降低,且在與圖12相比后也可發現在路網環境下即使經過偏移仍需要較長的計算處理時間.這主要是因為路網的限制以及偏移對敏感程度差異的影響.通過對比可見,偏移對用戶的隱私尤其是路網環境的用戶隱私能夠起到降低中心服務器負載,提高響應時間的較好影響.但是,由于用戶偏移距離的差異,勢必會造成節點反饋位置的精確性降低,進而反饋結果精確程度等服務質量受到影響. Fig.13 The running time of adding noises in road network with location shifting圖13 偏移后路網環境添加噪聲的計算時間 Fig.14 The trend of query result difference with the shifted圖14 查詢結果差異隨偏移的變化 由上述實驗可以看出通過偏移能夠很好地降低添加的噪聲數量、減少執行時間,但這樣勢必會在一定程度上影響用戶獲得查詢結果精確的性.因此,對偏移后造成的查詢結果差異進行了測試. 圖14給出了使用初始位置偏移和未使用偏移2種方式隨用戶查詢次數變化導致的查詢結果差異.從測試結果中可以看出,盡管通過用戶偏移會導致查詢結果與真實結果之間存在一定誤差,降低服務質量,但這種差異被很好地控制在可接受的范圍內,即使用戶連續進行50次查詢,這種差異仍被控制在40%以下.因此用戶可獲得相對較為準確的查詢結果,且偏移算法降低了服務器負載.同時減少了算法的計算處理時間,是用戶在對查詢結果精確程度要求不高的情況下的一種有效選擇. 為驗證本文算法與其他算法相比較的優勢,本文將該算法與同類算法進行了實驗比較,參與比較的算法有關聯概率不可區分的Probability Indistin-guishable算法[10]、用戶協作敏感位置標簽的PLAM(privacy local area mobile)算法[30]以及身份授權加密的Cryptographic Mix-Zone算法[12].上述5種算法將在敏感程度的漸進性、算法執行時間、反饋結果于真實結果之間的偏差量等方面展開. Fig.15 The comparison of the degree of sensitivity of various algorithms圖15 不同算法的敏感漸進性對比 圖15給出了5種比較算法在保護用戶連續移動過程中的敏感漸進差異.從圖15中可以看出,隨著用戶連續向目標移動,各種算法保護下的用戶所表現出的敏感漸進性都在增加.在這些算法中Pro-bability Indistinguishable算法的漸進程度最高,這是由于該算法主要關注于2位置之間的關聯概率,并沒有考慮到在移動過程中的敏感漸進問題.同樣Dummy-based LPPM算法只是利用用戶中心去分析潛在的用戶軌跡,進而實習軌跡泛化,在這個過程中并未有效地處理敏感漸進,因此敏感漸進程度較高.在剩余的3種算法中,PLAM算法盡管已關注用戶是否在敏感區間,但并未考慮敏感漸進的問題,其漸進程度相對較高.而Cryptographic Mix-Zone算法雖然并未針對敏感漸進而設計,但是加密后用戶信息在很大程度上阻止了攻擊者獲取用戶敏感程度信息,因此具有一定的敏感程度抵抗能力,其敏感漸進性較低.最后,本文算法主要是針對如何降低連續移動位置之間的敏感程度而提出的,并利用敏感程度不可區分性來防止攻擊者對位置展開關聯,因此其敏感程度的漸進性最低. 圖16給出了不同算法在查詢次數變化過程中的算法處理時間差異.從圖16中可以看出,隨查詢次數增加Cryptographic Mix-Zone算法的執行時間最長,這是由于該算法使用加密手段完成隱私保護,在加密過程中加密算法的執行占用了較長時間.同樣Probability Indistinguishable算法需要計算處理2位置之間的關聯概率,并實現關聯概率不可區分處理,因此其算法執行時間同樣較長.Dummy-based LPPM算法是通過添加大量噪聲完成隱私保護的,添加的噪聲數量以及用戶中心分析占用了一定的處理時間,其算法執行時間相對較長.PLAM算法采用的是利用用戶協作建立敏感區域標簽的方法,雖然在單一用戶處理上執行的時間較短,但是當多個用戶協作最終建立起敏感區域時,這個執行時間同樣較高.最后,本文算法主要執行隨機噪聲和隨機偏移操作,并不需要較多的計算量,因此其算法執行時間最短. Fig.16 The comparison of running time of various algorithms圖16 不同算法的執行時間對比 圖17給出了不同算法反饋結果的偏差程度,其中對于添加噪聲類的算法,這種偏差是通過噪聲結果和真實結果的均值計算得到的.從圖17中可以看出,Cryptographic Mix-Zone算法的反饋結果幾乎沒有偏差,這是由于該算法并不需要泛化或者隱藏等方式完成隱私保護,該算法完全是通過加密手段實現查詢結果的隱私獲取的,因此其反饋結果偏差最低,且并不隨著隱私級別的增加而變化.本文算法采用的是噪聲與偏移共存的方式完成隱私保護的,因此其結果偏移量要低于單獨使用上述2種策略的任何一種方法.Dummy-based LPPM算法是通過添加噪聲實現的,但是該算法主要是以k-匿名為隱私保護模型的,該模型添加的噪聲數量要低于差分隱私保護模型,因此其結果偏差要低于剩下的2種算法.Probability Indistinguishable算法是完全的采用偏移實現的關聯概率不可區分,因此其位置偏差較大.最后,PLAM算法反饋的結果是按照敏感區域反饋的,這導致獲得的查詢結果與真實結果之間存在最大的差異性的,因此其反饋差異最高. Fig.17 The comparison for deviation of feedback result of various algorithms圖17 不同算法的反饋結果對比 綜上,通過對2種不同類型的算法的實驗對比,使得用戶可根據自身需求選擇不同的隱私保護處理方法,進而滿足對用戶移動過程中敏感程度不可區分的隱私保護需求. 用戶在使用連續位置查詢并移動的過程中,隨著移動過程,其所經過并提交的位置呈敏感程度漸進的趨勢,這使得攻擊者可利用這種漸進識別用戶的潛在目標,進而獲得用戶的隱私.針對這種情況,基于Voronoi敏感區間劃分和敏感區域內敏感百分比等高線的劃定,本文提出了敏感程度不可區分的隱私保護方法.這種方法能夠有效防止攻擊者通過用戶移動過程中的敏感程度漸進識別用戶的目標位置,進而保護了用戶的個人隱私.同時,為了體現本文所提出算法的應用范圍和應用環境,在歐氏空間和路網環境分別對相應參數下的算法執行情況進行了模擬對比,進而算法在執行過程中可參照這些比對結果加以應用. 然而,本文所提出的算法同樣不能解決隱私保護全部問題,且由于用戶單次查詢過程中,通過添加隨機噪聲的方式使其敏感程度變化不可區分,將導致噪聲數量添加增大,進而對LBS服務器的響應時間和服務質量造成影響.所以今后工作的一個方面將在如何降低隱私保護對服務質量的影響方面展開.另一方面,由于用戶屬性仍可作為關聯用戶敏感程度變化的關聯,同時添加噪聲會造成反饋不精確以及保護過度的問題.因此,今后研究的另一個方面將在降低屬性關聯以及精確性和保護度量等方面展開.
εMP(p(li→ls),p(lj→ls)).
εMP(Sli,Slj),
3.3 安全性分析及性能分析
4 實驗驗證
5 偏移優化及其實驗驗證


6 結論及今后的工作展望
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
