基于SVM和D-S證據理論的早期溢流智能識別方法
2020-03-09 13:42:50李玉飛孫偉峰
鉆采工藝 2020年5期
李玉飛, 張 博, 孫偉峰
(1中國石油集團川慶鉆探工程有限公司鉆采工程技術研究院 2中國石油大學海洋與空間信息學院·華東)
早期溢流監測是實現油氣井井噴預防的主要技術手段之一。鉆井過程中溢流的及時發現,能夠為排除溢流、重建壓力平衡贏得寶貴時間,大大降低二次井控的難度[1]。因此,優化溢流監測方法,提高溢流監測的可靠性對實現安全、高效、經濟鉆井具有十分重要的意義。
早期溢流監測方法主要分為地面監測與井下監測兩大類;從監測手段來講,分為鉆井液微流量監測、液面監測、綜合錄井參數監測、隨鉆壓力監測等。
各種早期溢流監測方法采用的技術原理不盡相同,具備的技術優勢也各不一樣,現場使用時都存在著一定的局限。目前的溢流監測方法大多以某種單一的手段為主,同時,簡單的閾值判別方法容易受到鉆井現場環境的干擾導致監測結果不穩定,溢流發現的實時性及準確性都有待進一步提高。
采用單一的監測手段進行溢流識別的可靠性不高,需要結合多手段對溢流發生進行綜合判別,但是直接應用多手段監測溢流可能會出現矛盾沖突導致溢流監測不可靠的問題。本文提出了一種基于支持向量機(Support Vector Machine, SVM)后驗概率模型和D-S證據理論的早期溢監測方法,結合鉆井液微流量參數、綜合錄井中的立管壓力、大鉤負荷、井底隨鉆測量參數中的井底環空壓力和溫度對溢流發生進行綜合判別;同時,有效解決應用各種監測參數識別溢流時會出現的判別結果矛盾沖突的問題,提高了溢流監測的可靠性及現場適用性。
一、支持向量機后驗概率模型
1. SVM的基本原理
支持向量機在給定訓練數據中尋找一個決策超平面將兩類樣本正確分類并使分類的間隔(Margin) 最大[2-3]。分類原理如圖1所示,其中S為最優分類平面,S1與S2的間距為分類間隔。
給定l個訓練樣本(xi,yi),i=1,2,…,l,其中xi∈Rn,yi∈{-1,+1}。SVM在訓練數據集上尋找分界面g(x)=(w,x)+b,并使得分類間隔最大,由此可得最優化問題[4]:
(1)
式中:φ(·)—非線性映射;ξi—松弛變量;ω—權值矢量;b—偏置量;C—懲罰因子。
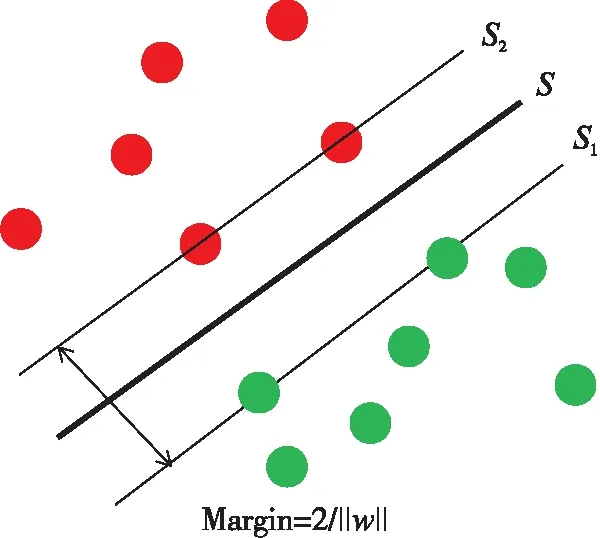
圖1 SVM分類算法
式(1)中的凸二次規劃問題通過其對偶形式求解。其對偶問題表達式如(2)[4]:
(2)
其中K(xi·xj)=[φ(xi),φ(xj)]為核函數,αi為拉格朗日乘子。最優解α*中大部分樣本對應的αi為零;若樣本所對應的αi不為零,則該樣本為支持向量[4],最優分類界面由這些支持向量確定。求得最優解后,可以根據如下函數進行分類判斷:
(3)
其中ω可由式(4)得到:
(4)
2. SVM后驗概率輸出
傳統SVM硬判定輸出結果缺乏對分類情況的定量描述,無法得到溢流發生的概率,不能為D-S證據理論的識別框架提供基本概率分配。因此,需要對傳統SVM的識別模型進行改進。
從SVM分類超平面的幾何角度,可通過待測樣本與分類超平面的距離遠近定量評價分類問題中樣本屬于所在類別的可能性大小。當確定某樣本的類別屬性時,該樣本與分類超平面的距離越遠,被錯分的可能性越小,屬于判定類別的概率越大。式(3)中的g(x)表示任意樣本到分類超平面的相對代數距離,反映對SVM模型判定類別結果的支持程度[5]。Sigmoid函數是一種常見的S型函數,Platt等人提出將SVM的后驗概率輸出視為sigmoid函數,因此可將g(x)通過sigmoid函數映射到[0,1]:
(5)
(6)
式中:p(y=+1|f(x))—SVM模型判定待測樣本屬于“+1”類時的后驗概率;p(y=-1|f(x))—SVM模型判定待測樣本屬于“-1”類時的后驗概率。
二、基于D-S證據理論的融合模型
1. D-S證據理論的基本原理
D-S證據理論作為一種決策層的信息融合方法,可以有效地利用鉆井液微流量參數、綜合錄井中的立管壓力、大鉤負荷、井底隨鉆測量中的井底環空壓力、溫度參數,對溢流的發生進行綜合研判。對于D-S證據理論有如下定義[6]:
設U為溢流識別結果的集合,即包含發生溢流與正常工況的事件集合,對于集合U中各子集發生的概率判別函數m:2u→[0,1],且滿足:
m(φ)=0,m(U)=1
(7)
式中:m—溢流監測參數的基本概率指派函數;m(φ)=0—對于空集的基本概率指派為0;m(U)=1—溢流發生與工況正常的概率和為1。
應用D-S融合準則對各溢流監測參數的基本概率指派函數進行融合,公式如下[6]:
(8)
式中:mx—各概率指派函數融合后的結果;mi—經模型i給出的溢流發生概率;m—正常工況的概率;n—參與融合的基本概率指派函數的個數。
2. 異常識別結果的剔除方法
當證據間高度沖突時,應用D-S證據理論得到的融合結果會與實際情況出現較大偏差[7],由于鉆井現場十分復雜,結合多種監測手段識別溢流時,識別結果有可能出現偏差。為了提高溢流識別的可靠性,在應用D-S證據理論進行決策融合之前需去除異常錯誤的識別結果。
通過計算各手段識別溢流結果間的相似度可以定量評價各溢流識別結果的差異程度,相似度的計算公式如下[7]:
R(mi,mj)=1-2|(mi-0.5)(mi-mj)|,
mi,mj?[0,1]
(9)
其中,m表示各監測手段給出的溢流發生概率,對于相似度R(mi,mj)有如下說明:R(mi,mj)?[0,1];當R(mi,mj)=R(mj,mi)=0時,說明局部決策mi,mj相互矛盾;當R(mi,mj)=R(mj,mi)=1時,說明局部決策mi,mj相互支持。
由于各種溢流監測手段識別溢流的可靠性不同,因此本節提出一種分級剔除異常溢流識別結果的方法,如圖2所示。
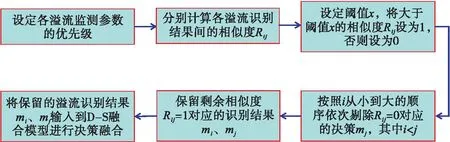
圖2 分級剔除溢流異常識別結果流程圖
圖2中,i,j為監測參數的優先級,被剔除的決策mj對應的Rij或Rji將不再參與決策剔除過程,本文設定的溢流監測參數優先級如表1所示。
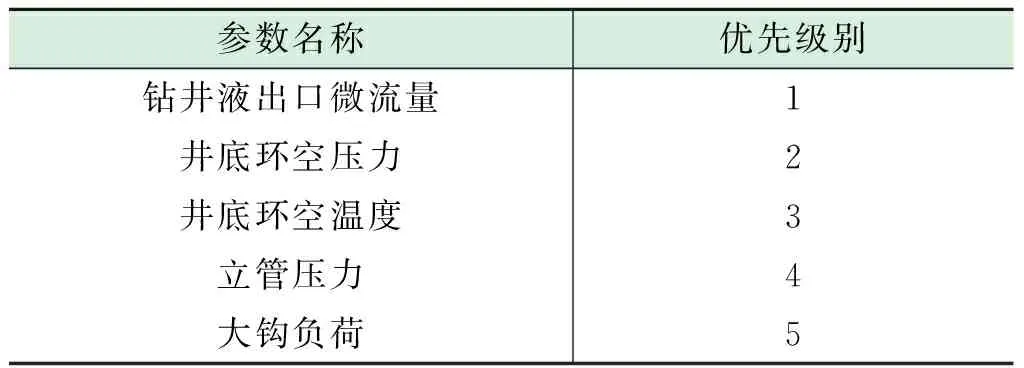
表1 溢流監測參數優先級的設定
基于以上方法可以有效剔除異常錯誤的溢流識別結果,解決了由于各手段監測結果不一致甚至出現矛盾沖突導致溢流監測不可靠的問題。
三、基于支持向量機后驗概率模型與D-S證據理論的溢流識別方法
本文選取鉆井液出口微流量參數、綜合錄井中的立管壓力、大鉤負荷、井底隨鉆測量中的井底環空壓力和溫度作為溢流監測參數,以各監測參數在特定時間內的變化量作為特征,對各監測參數進行特征提取。對每一類溢流監測參數,分別采用訓練好的基于SVM的溢流智能識別模型進行溢流識別,各模型均以概率形式輸出溢流識別結果,剔除異常錯誤的溢流識別結果后,將較為一致的溢流識別結果分別輸入到D-S證據理論融合模型中進行決策融合,以獲得最終的溢流識別結果。
四、實驗結果及分析
1. 溢流智能識別模型的訓練
6個溢流智能識別模型分別記為SVM1、SVM2、SVM3、SVM4、SVM5、SVM6,其中,SVM1~SVM5依次表示通過識別鉆井液出口微流量、立管壓力、大鉤負荷、井底環空壓力、井底環空溫度判別溢流發生的SVM后驗概率模型,SVM6為直接識別以上五個參數判別溢流發生的SVM后驗概率模型。本文采用的部分模型訓練數據如表2所示。
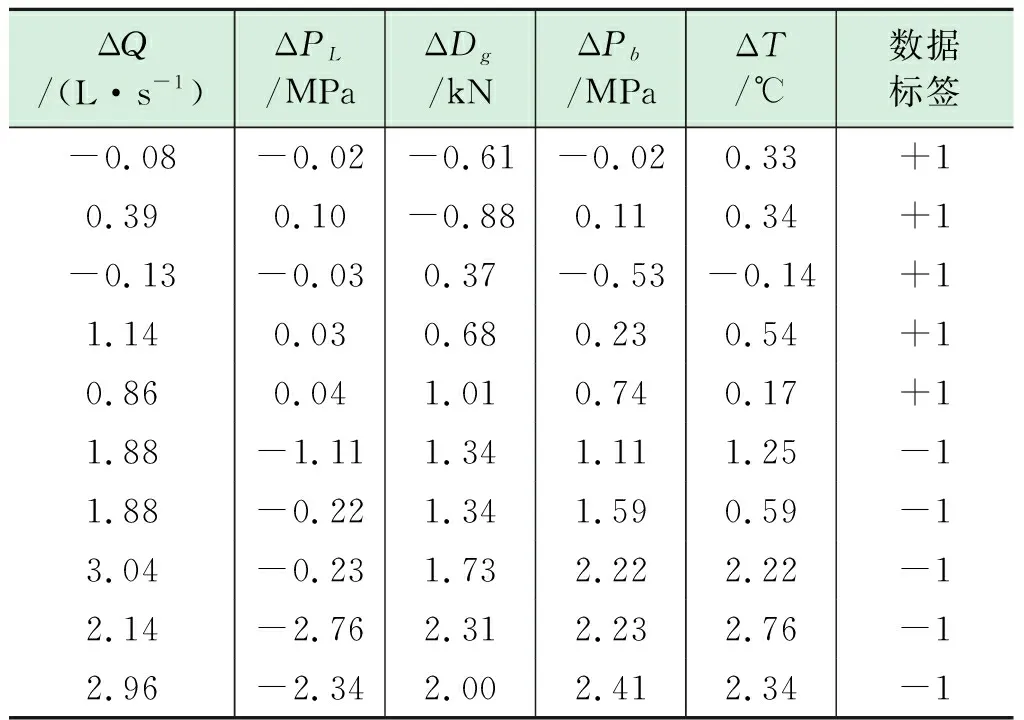
表2 溢流識別模型訓練數據
表2中,ΔQ、ΔPL、ΔDg、ΔPb、ΔT分別為鉆井液出口微流量、立管壓力、大鉤負荷、井底環空壓力、溫度在Δt=30 s內的幅值變化量,標簽為“+1”對應的數據代表正常工況下的訓練數據,標簽為“-1”對應的數據代表溢流過程的訓練數據。
2. 實驗結果對比與分析
采用測試集數據對模型測試,各溢流識別模型均以概率的形式輸出溢流識別結果,見表3。
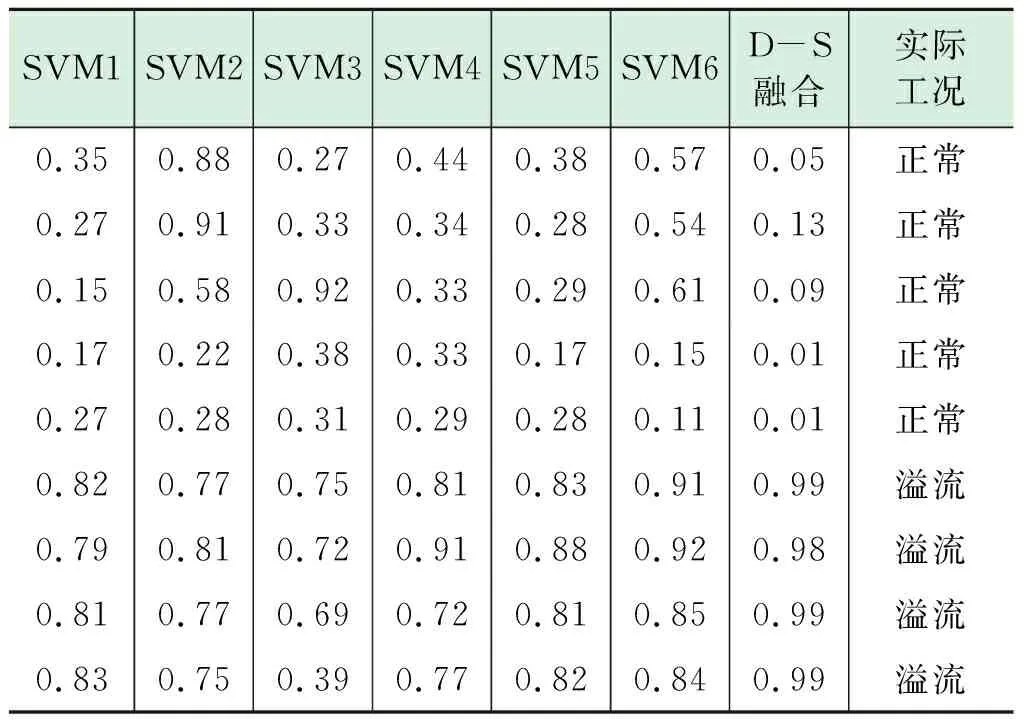
表3 溢流識別模型測試結果
由表3可以看出,當SVM2或SVM3的識別結果與其他結果矛盾時,說明立管壓力、大鉤負荷變化異常,此時SVM6的識別結果與實際工況不符。而應用本文D-S證據理論融合方法,則可以解決模型識別結果間的矛盾沖突,準確性不受影響。
為了直觀比較各溢流識別模型的準確性,將各模型的測試結果進行分類統計,實際工況為正常時,各溢流識別模型的輸出結果如圖3所示。
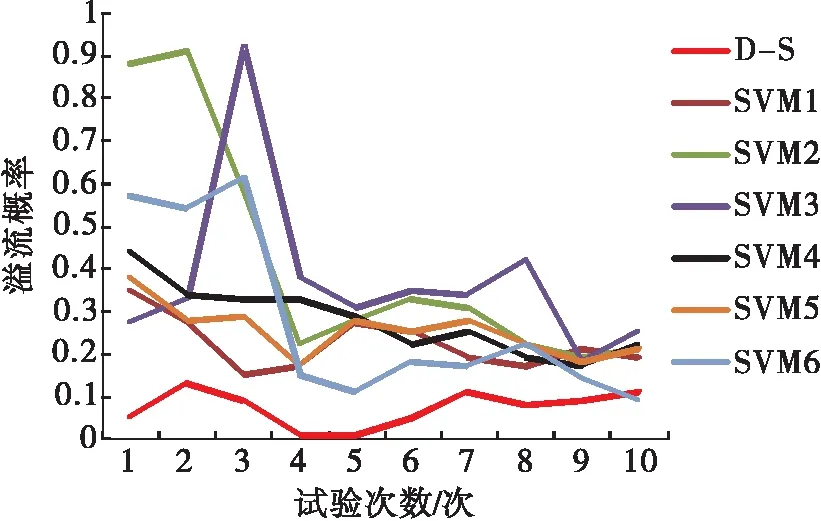
圖3 正常工況下各模型識別結果
溢流發生時,模型的輸出結果如圖4。
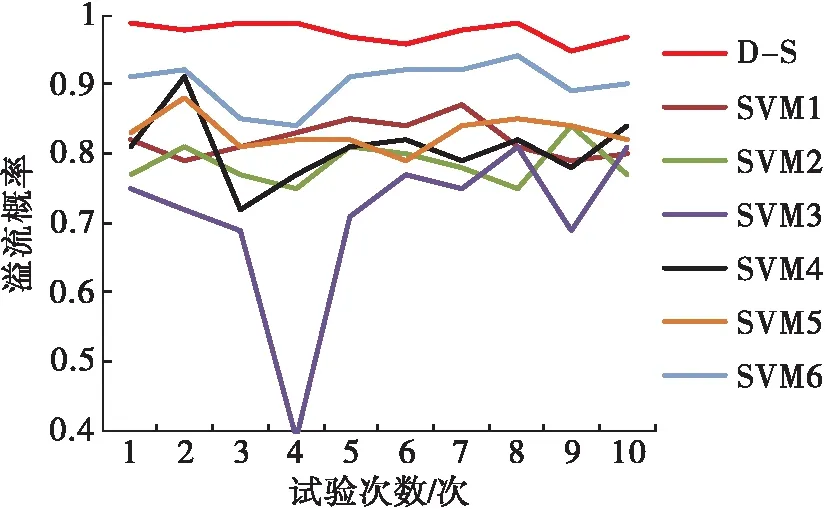
圖4 溢流發生時各模型識別結果對比
由圖3、圖4可知,本文提出的結合SVM后驗概率與D-S證據理論融合的溢流識別模型準確性最高,其次為SVM6模型,但當多個溢流監測結果間存在矛盾沖突時,其識別準確性明顯降低。本文提出的溢流識別模型可以處理多手段監測溢流時出現的矛盾沖突問題,提高了溢流識別的準確性。
3. 實測數據實驗結果
為了驗證該方法的現場適用性,基于現場實測數據開展了實驗。選取泥漿池體積、出口流量、入口流量、立管壓力、大鉤負荷、泵沖對溢流(氣侵)進行監測。
建立4個SVM模型,其中SVM1~SVM4為通過識別鉆井液出口流量、立管壓力、大鉤負荷、泥漿池體積判別溢流發生的SVM后驗概率模型。當SVM1判斷出的溢流概率較高時,要首先判斷入口流量和泵沖是否增加,如有增加,則說明由于人工操作所致,此時屏蔽掉SVM1輸出的概率。
當氣侵發生,泥漿池體積由102 m3緩慢增大到104 m3;大鉤負荷由123 kN上升到127 kN,立管壓力有所上升,經過D-S證據理論融合,綜合判別氣侵發生的概率為0.83,系統給出溢流報警,所給出的判別結果和鉆井事故分析報告一致。
五、結論
(1)基于SVM后驗概率與D-S證據理論結合的早期溢流識別方法,在傳統的SVM基礎上引入了后驗概率輸出模型,使其可以以概率的形式輸出分類結果。
(2)分級剔除異常溢流識別結果的方法,建立剔除模型,可有效解決多源監測信息間存在的矛盾沖突導致D-S融合結果不準確的問題。
(3)仿真及實測數據實驗結果表明,本文提出的溢流識別方法可以有效解決應用多種監測參數識別溢流時出現的識別結果矛盾、沖突的問題,提高了早期溢流識別的可靠性及現場適用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
